Hbase备份与恢复工具Snapshot的基本概念与工作原理
数据库都有相对完善的备份与恢复功能。备份与恢复功能是数据库在数据意外丢失、损坏下的最后一根救命稻草。数据库定期备份、定期演练恢复是当下很多重要业务都在慢慢接受的最佳实践,也是数据库管理者推荐的一种管理规范。HBase数据库最核心的备份与恢复工具——Snapshot。
一、HBase备份与恢复工具的发展过程
HBase备份与恢复功能从无到有经历了多个发展阶段,从最早使用distcp进行关机全备份,到0.94版本使用copyTable工具在线跨集群备份,再到0.98版本推出在线Snapshot备份,每次备份与恢复功能的发展都极大地丰富了用户的备份与恢复体验。
1,使用distcp进行关机全备份
HBase的所有文件都存储在HDFS上,因此只要使用Hadoop提供的文件复制工具distcp将HBASE目录复制到同一HDFS或者其他HDFS的另一个目录中,就可以完成对源HBase集群的备份工作。但这种备份方式需要关闭当前集群,不提供所有读写操作服务,在现在看来这是不可接受的。
2,使用copyTable工具在线跨集群备份
copyTable工具通过MapReduce程序全表扫描待备份表数据并写入另一个集群。这种备份方式不再需要关闭源集群,但依然存在很多问题:
(1)全表扫描待备份表数据会极大影响原表的在线读写性能。
(2)备份时间长,不适合做频繁备份。
(3)备份数据不能保证数据的一致性,只能保证行级一致性。
3,使用Snapshot在线备份
Snapshot备份以快照技术为基础原理,备份过程不需要拷贝任何数据,因此对当前集群几乎没有任何影响,备份速度非常快而且可以保证数据一致性。笔者推荐在0.98之后的版本都使用Snapshot工具来完成在线备份任务。
二、Snapshot技术基础原理
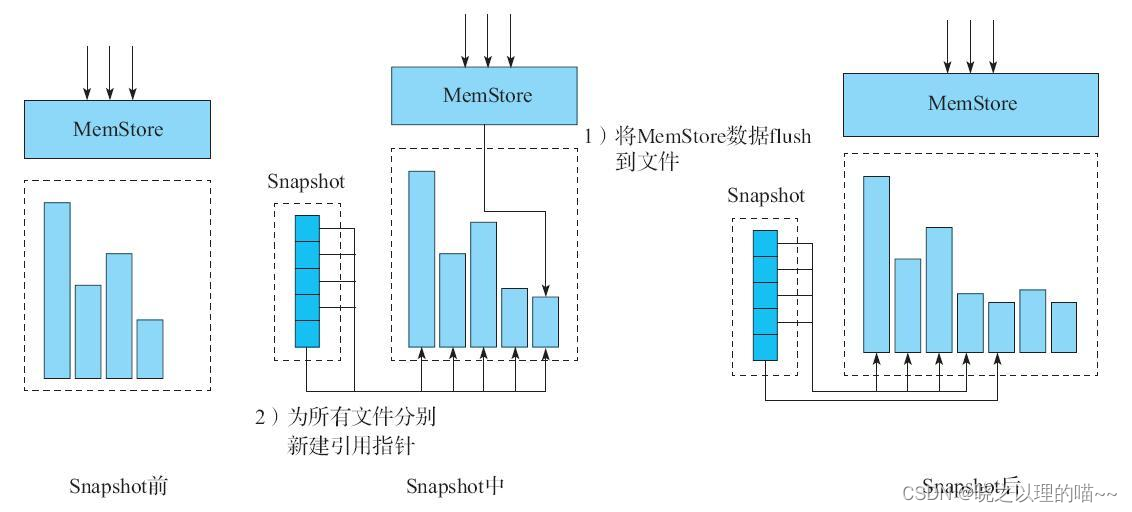
Snapshot是很多存储系统和数据库系统都支持的功能。一个Snapshot是全部文件系统或者某个目录在某一时刻的镜像。实现数据文件镜像最简单粗暴的方式是加锁拷贝(之所以需要加锁,是因为镜像得到的数据必须是某一时刻完全一致的数据),拷贝的这段时间不允许对原数据进行任何形式的更新删除,仅提供只读操作,拷贝完成之后再释放锁。这种方式涉及数据的实际拷贝,在数据量大的情况下必然会花费大量时间,长时间的加锁拷贝会导致客户端长时间不能更新删除,这是生产线上不能容忍的。
Snapshot机制并不会拷贝数据,可以理解为它是原数据的一份指针。在HBase的LSM树类型系统结构下是比较容易理解的,我们知道HBase数据文件一旦落到磁盘就不再允许更新删除等原地修改操作,如果想更新删除只能追加写入新文件。这种机制下实现某个表的Snapshot,只需为当前表的所有文件分别新建一个引用(指针)。对于其他新写入的数据,重新创建一个新文件写入即可。
Snapshot流程主要涉及2个步骤:
(1)将MemStore中的缓存数据flush到文件中。
(2)为所有HFile文件分别新建引用指针,这些指针元数据就是Snapshot。
三、在线Snapshot备份可实现的功能与使用场景
Snapshot是HBase非常核心的一个功能,使用在线Snapshot备份可以满足用户很多需求,比如增量备份和数据迁移。
1,全量/增量备份
任何数据库都需要具有备份的功能来实现数据的高可靠性,Snapshot可以非常方便地实现表的在线备份功能,并且对在线业务请求影响非常小。使用备份数据,用户可以在异常发生时快速回滚到指定快照点。
(1)使用场景一:通常情况下,对于重要的业务数据,建议每天执行一次Snapshot来保存数据的快照记录,并且定期清理过期快照,这样如果业务发生严重错误,可以回滚到之前的一个快照点。
(2)使用场景二:如果要对集群做重大升级,建议升级前对重要的表执行一次Snapshot,一旦升级有任何异常可以快速回滚到升级前。
2,数据迁移
可以使用ExportSnapshot功能将快照导出到另一个集群,实现数据的迁移。
(1)使用场景一:机房在线迁移。比如业务集群在A机房,因为A机房机位不够或者机架不够需要将整个集群迁移到另一个容量更大的B集群,而且在迁移过程中不能停服。基本迁移思路是,先使用Snapshot在B集群恢复出一个全量数据,再使用replication技术增量复制A集群的更新数据,等待两个集群数据一致之后将客户端请求重定向到B机房。
(2)使用场景二:利用Snapshot将表数据导出到HDFS,再使用Hive\Spark等进行离线OLAP分析,比如审计报表、月度报表等。
四、在线Snapshot备份与恢复的用法
在线Snapshot备份与恢复最常用的4个工具是snapshot、restore_snapshot、clone_snapshot以及ExportSnapshot。
1,snapshot
可以为表打一个快照,但并不涉及数据移动。例如为表’sourceTable’打一个快照’snapshotName’,可以在线完成
hbase> snapshot 'sourceTable', 'snapshotName'
2,restore_snapshot
用于恢复指定快照,恢复过程会替代原有数据,将表还原到快照点,快照点之后的所有更新将会丢失
hbase> restore_snapshot 'snapshotName'
3,clone_snapshot
可以根据快照恢复出一个新表,恢复过程不涉及数据移动,可以在秒级完成
hbase> clone_snapshot 'snapshotName', 'tableName'
4,ExportSnapshot
可以将A集群的快照数据迁移到B集群。ExportSnapshot是HDFS层面的操作,需使用MapReduce进行数据的并行迁移,因此需要在开启MapReduce的机器上进行迁移。Master和RegionServer并不参与这个过程,因此不会带来额外的内存开销以及GC开销。唯一的影响是DataNode在拷贝数据的时候需要额外的带宽以及IO负载,ExportSnapshot针对这个问题设置了参数bandwidth来限制带宽的使用。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \-snapshot MySnapshot -copy-from hdfs:// srv2:8082/hbase \ -copy-to hdfs:// srv1:50070/hbase -mappers 16 -bandwidth 1024
五、在线Snapshot的分布式架构——两阶段提交
HBase为指定表执行Snapshot操作,实际上真正执行Snapshot的是对应表的所有Region。这些Region分布在多个RegionServer上,因此需要一种机制来保证所有参与执行Snapshot的Region要么全部完成,要么都没有开始做,不能出现中间状态,比如某些Region完成了,而某些Region未完成。
1, 两阶段提交基本原理
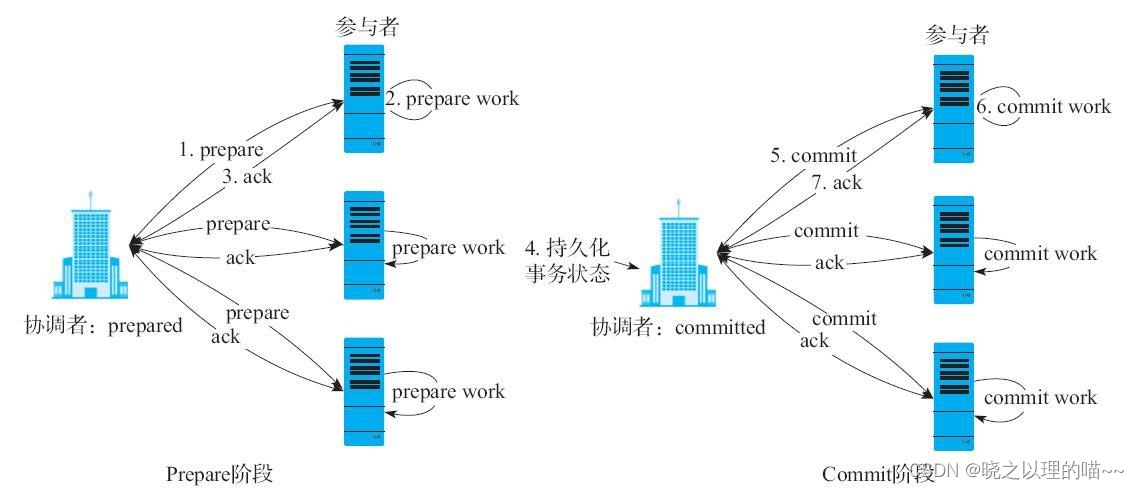
HBase使用两阶段提交(Two-Phase Commit,2PC)协议来保证Snapshot的分布式原子性。2PC一般由一个协调者和多个参与者组成,整个事务提交分为两个阶段:prepare阶段和commit阶段(或abort阶段)。
整个过程:
(1)prepare阶段协调者会向所有参与者发送prepare命令。
(2)所有参与者接收到命令,获取相应资源(比如锁资源),执行prepare操作确认可以执行成功。一般情况下,核心工作都是在prepare操作中完成。
(3)返回给协调者prepared应答。
(4)协调者接收到所有参与者返回的prepared应答(表明所有参与者都已经准备好提交),在本地持久化committed状态。
(5)持久化完成之后进入commit阶段,协调者会向所有参与者发送commit命令。
(6)参与者接收到commit命令,执行commit操作并释放资源,通常commit操作都非常简单。
(7)返回给协调者。
2,Snapshot两阶段提交实现
HBase使用2PC协议来构建Snapshot架构。
1,prepare阶段
(1)Master在ZooKeeper创建一个/acquired-snapshotname节点,并在此节点上写入Snapshot相关信息(Snapshot表信息)。
(2)所有RegionServer监测到这个节点,根据/acquired-snapshotname节点携带的Snapshot表信息查看当前RegionServer上是否存在目标表,如果不存在,就忽略该命令。如果存在,遍历目标表中的所有Region,针对每个Region分别执行Snapshot操作,注意此处Snapshot操作的结果并没有写入最终文件夹,而是写入临时文件夹。
(3)RegionServer执行完成之后会在/acquired-snapshotname节点下新建一个子节点/acquired-snapshotname/nodex,表示nodex节点完成了该RegionServer上所有相关Region的Snapshot准备工作。
2,commit阶段
(1)一旦所有RegionServer都完成了Snapshot的prepared工作,即都在/acquired-snapshotname节点下新建了对应子节点,Master就认为Snapshot的准备工作完全完成。Master会新建一个新的节点/reached-snapshotname,表示发送一个commit命令给参与的RegionServer。
(2)所有RegionServer监测到/reached-snapshotname节点之后,执行commit操作。commit操作非常简单,只需要将prepare阶段生成的结果从临时文件夹移动到最终文件夹即可。
(3)在/reached-snapshotname节点下新建子节点/reached-snapshotname/nodex,表示节点nodex完成Snapshot工作。
3,abort阶段
如果在一定时间内/acquired-snapshotname节点个数没有满足条件(还有RegionServer的准备工作没有完成),Master认为Snapshot的准备工作超时。Master会新建另一新节点/abort-snapshotname,所有RegionServer监听到这个命令之后会清理Snapshot在临时文件夹中生成的结果。
可以看到,在这个系统中Master充当了协调者的角色,RegionServer充当了参与者的角色。Master和RegionServer之间的通信通过ZooKeeper来完成,同时,事务状态也记录在ZooKeeper的节点上。Master高可用情况下主Master发生宕机,从Master切换成主后,会根据ZooKeeper上的状态决定事务是否继续提交或者回滚。
六、Snapshot核心实现
1,Region实现Snapshot
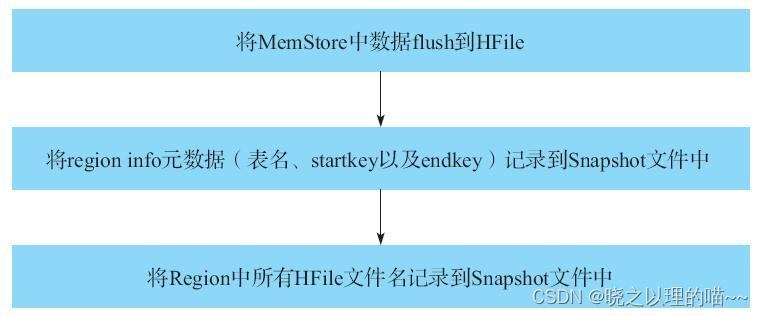
步骤分别对应debug日志中如下片段:
Snapshot.FlushSnapshotSubprocedure: Flush Snapshotting region yixin:yunxin,user1359,1502949275629.77f4ac61c4db0be9075669726f3b72e6. started...
snapshot.SnapshotManifest: Storing 'yixin:yunxin,user1359,1502949275629.77f4ac61c4db0be9075669726f3b72e6.' region-info for snapshot.
snapshot.SnapshotManifest: Creating references for hfiles
snapshot.SnapshotManifest: Adding snapshot references for [] hfiles
Region生成的Snapshot文件是临时文件,在/hbase/.hbase-snapshot/.tmp目录下,因为Snapshot过程通常特别快,所以很难看到单个Region生成的Snapshot文件。
2,Master汇总所有Region Snapshot的结果
Master会在所有Region完成Snapshot之后执行一个汇总操作(consolidate),将所有region snapshot manifest汇总成一个单独manifest,汇总后的Snapshot文件可以在HDFS目录下看到的,路径为:/hbase/.hbase-snapshot/snapshotname/data.manifest。
Snapshot目录下有3个文件:
hadoop@hbase19:~/cluster-data/hbase/logs$ ./hdfs dfs -ls /hbase/.hbase-snapshot/music_snapsho
Found 3 items-rw-r--r-- 3 hadoop hadoop 0 2017-08-18 17:47 /hbase/.hbase-snapshot/music_snapshot/.inprogress
-rw-r--r-- 3 hadoop hadoop 34 2017-08-18 17:47 /hbase/.hbase-snapshot/music_snapshot/.snapshotinfo
-rw-r--r-- 3 hadoop hadoop 34 2017-08-18 17:47 /hbase/.hbase-snapshot/music_snapshot/data.manifest
其中.snapshotinfo为Snapshot基本信息,包含待Snapshot的表名称以及Snapshot名。data.manifest为Snapshot执行后生成的元数据信息,即Snapshot结果信息。可以使用hadoop dfs-cat/hbase/.hbase-snapshot/snapshotname/data.manifest查看具体的元数据信息。
七、Snapshot恢复
Snapshot可以实现很多功能,比如restore_snapshot可以将当前表恢复到备份的时间点,clone_snapshot可以使用快照恢复出一个新表,ExportSnapshot可以将备份导出到另一个集群实现数据迁移等。
clone_snapshot可以概括为如下六步:
(1)预检查。确认当前目标表没有执行snapshot以及restore等操作,否则直接返回错误。
(2)在tmp文件夹下新建目标表目录并在表目录下新建.tabledesc文件,在该文件中写入表schema信息。
(3)新建region目录。根据snapshot manifest中的信息新建Region相关目录以及HFile文件。
(4)将表目录从tmp文件夹下移到HBase Root Location。
(5)修改hbase:meta表,将克隆表的Region信息添加到hbase:meta表中,注意克隆表的Region名称和原数据表的Region名称并不相同(Region名称与table名称相关,table名不同,Region名则肯定不同)。
(6)将这些Region通过round-robin方式均匀分配到整个集群中,并在ZooKeeper上将克隆表的状态设置为enabled,正式对外提供服务。
在实现中HBase借鉴了类似于Linux系统中软链接的概念,使用一种名为LinkFile的文件指向了原文件。LinkFile文件本身没有任何内容,它的所有核心信息都包含在它的文件名中。LinkFile的命名方式为’table=region-origin_hfile’,通过这种方式就可以很容易定位到原始文件的具体路径:/${hbase-root}/table/region/origin_hfile。所有针对新表的读取操作都会转发到原始表执行,因此就不需要移动数据了。
示例:
hadoop@hbase19:~/hbase-current/bin ./hdfs dfs
-ls /hbase/data/default/music/fec3584ec3ea8766ffda5cb8ed0d7/cf
Found 1 items
-rw-r-r-r- - 3 hadoop hadoop 0 2017-08-23 07:27 /hbase/data/default/music/fec3584ec3ea8766ffda5cb8ed0d7/cf/music=5e54d8620eae123761e5290e618d556b-f928e045bb1e41ecbef6fc28ec2d571
其中,LinkFile文件名为music=5e54d8620eae123761e5290e618d556b-f928e045bb1e41ecbef6fc28ec2d5712,根据定义可以知道,music为原始文件的表名,与引用文件所在的Region、引用文件名的关系。

依据规则,根据LinkFile的文件名定位到引用文件所在位置,${hbaseroot}/music/5e54d8620eae123761e5290e618d556b/cf/f928e045bb1e41ecbef6fc28ec2d5712。
九、Snapshot进阶-在线Snapshot原理深入解析
Snapshot实际上是一系列原始表的元数据,主要包括表schema信息、原始表所有Region的region info信息、Region包含的列簇信息,以及Region下所有的HFile文件名、文件大小等。
HBase的实现方案比较简单,在原始表发生Compaction操作前会将原始表数据复制到archive目录下再执行compact(对于表删除操作,正常情况也会将删除表数据移动到archive目录下),这样Snapshot对应的元数据就不会失去意义,只不过原始数据不再存在于数据目录下,而是移动到了archive目录下。
示例:
1)使用Snapshot工具给一张表做快照:snapshot’test’,‘test_snapshot’。
2)查看archive目录,确认不存在这个目录:hbase-root-dir/archive/data/default/test。
3)对表test执行major_compact操作:major_compact’test’。
4)再次查看archive目录,就会发现test原始表移动到了该目录,/hbase-root-dir/archive/data/default/test存在。
同理,如果对原始表执行delete操作,比如delete’test’,也会在archive目录下找到该目录。这里需要注意的是,和普通表删除的情况不同,普通表一旦删除,刚开始是可以在archive中看到删除表的数据文件,但是等待一段时间后archive中的数据就会被彻底删除,再也无法找回。这是因为Master上会启动一个定期清理archive中垃圾文件的线程(HFileCleaner),定期对这些被删除的垃圾文件进行清理。但是Snapshot原始表被删除之后进入archive,并不可以被定期清理掉,上节说过clone出来的新表并没有clone真正的文件,而是生成了指向原始文件的链接,这类文件称为LinkFile,很显然,只要LinkFile还指向这些原始文件,它们就不可以被删除。
注意有两个问题:
(1)什么时候LinkFile会变成真实的数据文件?HBase会在新表执行compact的时候将合并后的文件写到新目录并将相关的LinkFile删除,理论上讲是借着compact顺便做了这件事。
(2)系统在删除archive中原始表文件的时候怎么知道这些文件还被LinkFile引用着?HBase使用back-reference机制完成这件事情。HBase会在archive目录下生成一种新的back-reference文件,来帮助原始表文件找到引用文件。
back-reference文件:
(1)原始文件:/hbase/data/table-x/region-x/cf/file-x。
(2)clone生成的LinkFile:/hbase/data/table-cloned/region-y/cf/{table-x}={region-x}-{file-x}。
(3)back-reference文件:/hbase/archive/data/table-x/region-x/cf/.links-{file-x}/{region-y}.{table-cloned}。
back-reference文件路径前半部分是原文件信息,后半部分是新文件信息.

back-reference文件第一部分表示该文件所在目录为{hbase-root}/archive/data。第二部分表示原文件路径,其中非常重要的子目录是.links-{file-x},用来标识该路径下的文件为back-reference文件。这部分路径实际上只需要将原始文件路径(/table-x/region-x/cf/file-x)中的文件名file-x改为.link-file-x。第三部分表示新文件路径,新文件的文件名可以根据原文件得到,因此只需要得到新文件所在的表和Region即可,可以用{region-y}.{table-cloned}表征。
可见,在删除原文件的时候,只需要简单地拼接就可以得到back-reference目录,查看该目录下是否有文件就可以判断原文件是否还被LinkFile引用,进一步决定是否可以删除。
文章来源:《HBase原理与实践》 作者:胡争;范欣欣
文章内容仅供学习交流,如有侵犯,联系删除哦!
相关文章:
Hbase备份与恢复工具Snapshot的基本概念与工作原理
数据库都有相对完善的备份与恢复功能。备份与恢复功能是数据库在数据意外丢失、损坏下的最后一根救命稻草。数据库定期备份、定期演练恢复是当下很多重要业务都在慢慢接受的最佳实践,也是数据库管理者推荐的一种管理规范。HBase数据库最核心的备份与恢复工具——Sna…...
RTOS中事件集的实现原理以及实用应用
事件集的原理 RTOS中事件集的实现原理是通过位掩码来实现的。事件集是一种用于在任务之间传递信号的机制。在RTOS中,事件集通常是一个32位的二进制位向量。每个位都代表一个特定的事件,例如信号、标志、定时器等。 当一个任务等待一个或多个事件时&…...
计及新能源出力不确定性的电气设备综合能源系统协同优化(Matlab代码实现)
运行视频及运行结果: 计及碳排放成本的电-气-热综合能源系纷充节点能价计算方法研究(Matlab代码实现)目录 第一部分 文献一《计及新能源出力不确定性的电气设备综合能源系统协同优化》 0 引言 1 新能源出力不确定性处理 1.1 新…...

推荐几个超实用的开源自动化测试框架
有什么好的开源自动化测试框架可以推荐?为了让大家看文章不蒙圈,文章我将围绕3个方面来阐述: 1、通用自动化测试框架介绍 2、Java语言下的自动化测试框架 3、Python语言下的自动化测试框架 随着计算机技术人员的大量增加,通过编写…...

Mac 上解压缩 RAR 文件
RAR 在十几年前的互联网曾叱咤风云般的存在。在那时,你所能见到的压缩文件几乎都是 RAR 格式,大家在 Windows 上使用的压缩、解压缩软件基本都是 WinRAR。虽然这些年使用 RAR 格式的压缩包的情况在逐渐减少,但是你还是经常能在国内各种网站下…...
)
C++核心编程<引用>(2)
c核心编程<引用>2.引用2.1引用的基本使用2.2引用注意事项2.3引用做函数参数2.4引用做函数返回值2.5引用的本质2.6常量引用2.引用 2.1引用的基本使用 作用: 给变量起别名语法:数据类型 &别名 原名演示#include<iostream> using namespace std; void func();i…...

零入门kubernetes网络实战-20->golang编程syscall操作tun设备介绍
《零入门kubernetes网络实战》视频专栏地址 https://www.ixigua.com/7193641905282875942 本篇文章视频地址(稍后上传) 本篇文章主要是使用golang自带的syscall包来创建tun类型的虚拟网络设备。 注意: 目前只能使用syscall包来创建tun类型的虚拟设备。 tun虚拟网…...
springboot之自动配置
文章目录前言一、配置文件及自动配置原理1、配置文件2、yaml1、注解注入方式给属性赋值2、yaml给实体类赋值3、Properties给属性赋值二、springboot的多环境配置四、自动配置总结前言 1、自动装配原理 2、多种方式给属性赋值 3、多环境配置 4、自动配置 一、配置文件及自动配置…...
wxpython设计GUI:wxFormBuilder工具常用布局结构介绍之布局四—面板拼接式
python借助wxFormBuilder工具搭建基础的GUI界面—wxFormBuilder工具使用介绍:https://blog.csdn.net/Logintern09/article/details/126685315 布局四:面板拼接式,先Panel面板构图,再使用程序代码在Frame框架上拼接面板 下面讲一下…...

全网最全之接口测试【加密解密攻防完整版】实战教程详解
看视频讲的更详细:https://www.bilibili.com/video/BV1zr4y1E7V5/? 一、对称加密 对称加密算法是共享密钥加密算法,在加密解密过程中,使用的密钥只有一个。发送和接收双方事先都知道加密的密钥,均使用这个密钥对数据进行加密和解…...
 常用操作)
Python - 目录文件(OS模块) 常用操作
目录os模块的方法os.path()模块的方法使用示例示例一:简单使用示例二:获取文件夹下指定条件的文件os模块的方法 方法说明os.listdir(path)取得指定文件夹下的文件列表os.mkdir(path)创建一个名为path的文件夹os.open(file, flags)打开一个文件ÿ…...

把本地代码初始化到远程git仓库
本地代码,推送到远程的git仓库。第一种方法第一步:建立远程的git仓库第二步:拉取git仓库到本地第三步:将本地代码复制到本地的git拉下来的文件夹中第四步:代码提交即可git add . --> git commit -m 初始化 --> g…...

关于angular中的生命周期函数
生命周期函数,也叫生命周期钩子。 Angular的每个组件(包括根组件和子组件)都存在一个生命周期,从创建、更新、到销毁,Angular提供组件生命周期钩子函数, 组件的生命周期从实例化组件类并渲染组件视图及其…...

【拼图】拼图游戏-微信小程序开发流程详解
还记得小时候玩过的经典拼图游戏吗,上小学时,在路边摊用买个玩具,是一个正方形盒子形状,里面装的是图片分割成的很多块,还差一块,怎么描述好呢,和魔方玩具差不多,有没有听说叫二维的…...
)
第六章 opengl之光照(颜色)
OpenGL光照颜色创建一个光照场景光照 颜色 颜色由RGB组成,分别是红色,绿色,蓝色。举例定义一个颜色向量: glm::vec3 coral(1.0f, 0.5f, 0.31f);而在现实中,人眼看到的是 物体反射后的颜色,也就是说不能被…...

C语言-基础了解-19-C位域
C位域 一、C位域 如果程序的结构中包含多个开关量,只有 TRUE/FALSE 变量,如下: struct {unsigned int widthValidated;unsigned int heightValidated; } status;这种结构需要 8 字节的内存空间,但在实际上,在每个变…...

MapReduce全排序和二次排序
排序是MapReduce框架中最重要的操作之一。MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。对于MapTask…...

【Vue3】封装数字框组件
数量选择组件-基本结构 (1)准备基本结构 <script lang"ts" setup name"Numbox"> // </script> <template><div class"numbox"><div class"label">数量</div><div cla…...

C++-简述strcpy、sprintf 和 memcpy 的区别
回答如下: strcpy 函数:用于将一个字符串(以 NULL 结尾)从源地址复制到目标地址。函数原型为 char* strcpy(char* destination, const char* source)。需要注意的是,该函数会复制整个字符串,包括 NULL 终止…...

用CPU大法忽悠ChatGPT写前端,油猴子工具库+1
文章目录用CPU大法忽悠ChatGPT写前端,油猴子工具库1源起对话1. 作为一名天才js程序员,开发一个油猴子脚本,实现所有浏览器网页的自动下滑功能,每一个步骤都加上中文注释2. 加一个按钮,只有我点击了按钮才会开始自动下滑…...

Claude智能优化器:提升大模型工具调用准确性的工程实践
1. 项目概述与核心价值最近在折腾大语言模型应用开发时,我一直在思考一个问题:如何让像Claude这样的顶级AI助手,在回答复杂问题时,能更稳定、更聪明地调用外部工具和函数?直接调用API,模型有时会“犯懒”或…...

大语言模型微调实战:从LoRA到QLoRA,一站式开源框架详解
1. 项目概述与核心价值 如果你正在寻找一个能够一站式搞定主流大语言模型微调的开源项目,那么 ssbuild/llm_finetuning 绝对值得你花时间深入研究。这个项目本质上是一个基于 PyTorch 和 Hugging Face Transformers 生态的、高度工程化的微调框架。它最大的魅力在…...

Drogon框架数据库连接监控终极指南:性能指标与智能告警机制
Drogon框架数据库连接监控终极指南:性能指标与智能告警机制 【免费下载链接】drogon Drogon: A C14/17/20 based HTTP web application framework running on Linux/macOS/Unix/Windows 项目地址: https://gitcode.com/gh_mirrors/dr/drogon Drogon是一个基于…...
、node = MyNode() 、rclpy.spin(node))
[具身智能-670]:ROS2 Node内部的工作原理:rclpy.init()、node = MyNode() 、rclpy.spin(node)
一、三个函数的一句话功能rclpy.init()初始化 ROS2 全局系统(上下文、信号处理、DDS)。node MyNode()创建节点对象,注册名字,分配通信句柄,不创建线程。rclpy.spin(node)进入主线程死循环,不断检查消息 / …...

用Matplotlib heatmap分析你的数据:从农产品收成到商品销量的实战案例拆解
用Matplotlib heatmap解锁业务洞察:从农场到电商的数据可视化实战 热力图(heatmap)远不止是颜色方块的排列——它是数据与商业决策之间的视觉桥梁。想象一下,你面前有一张农场作物产量的热力图,颜色从深绿渐变到亮黄&a…...

Kubernetes配置管理神器Monokle:可视化IDE提升YAML开发效率
1. 项目概述:一个被低估的Kubernetes配置管理神器如果你和我一样,每天都在和成堆的YAML文件、复杂的Kubernetes资源关系以及让人头疼的配置漂移问题打交道,那你一定理解那种在终端、IDE和Dashboard之间反复横跳的疲惫感。几年前,当…...

基于多平台行为数据构建AI Agent深度用户画像:Know Your Owner项目解析
1. 项目概述:从“你是谁”到“我懂你”的智能跨越在AI助手日益普及的今天,我们面临着一个核心矛盾:用户期望获得高度个性化的服务,而AI助手在初次接触时却对用户一无所知。传统的解决方案,比如让用户填写冗长的问卷&am…...

windows构建mamba环境
收集必要的whl文件 在某🐟等平台或者是精密搜索找到以下whl文件 对于3.10 python triton-2.0.0-cp310-cp310-win_amd64.whl causal_conv1d-1.1.1-cp310-cp310-win_amd64.whl mamba_ssm-1.1.3-cp310-cp310-win_amd64.whl 对于3.11 python FuouM/mamba-ssm-windo…...

016、气压计原理与高度测量
飞控算法从入门到精通 016 气压计原理与高度测量 一、一次炸机带来的教训 去年夏天,我在一个四轴飞行器上调试定高悬停。气压计用的是MS5611,数据手册翻烂了,滤波算法也上了,地面站里高度曲线看着挺平滑。结果一上天,飞机像喝醉了酒——先是莫名其妙往下掉半米,然后猛…...

ClawSuite:模块化网络安全工具集在渗透测试中的实战应用
1. 项目概述:ClawSuite,一个被低估的网络安全工具集如果你在网络安全领域摸爬滚打了一段时间,尤其是在渗透测试或者红队评估的圈子里,你大概率听说过或者用过像 Metasploit、Nmap、Burp Suite 这些耳熟能详的“瑞士军刀”。但今天…...