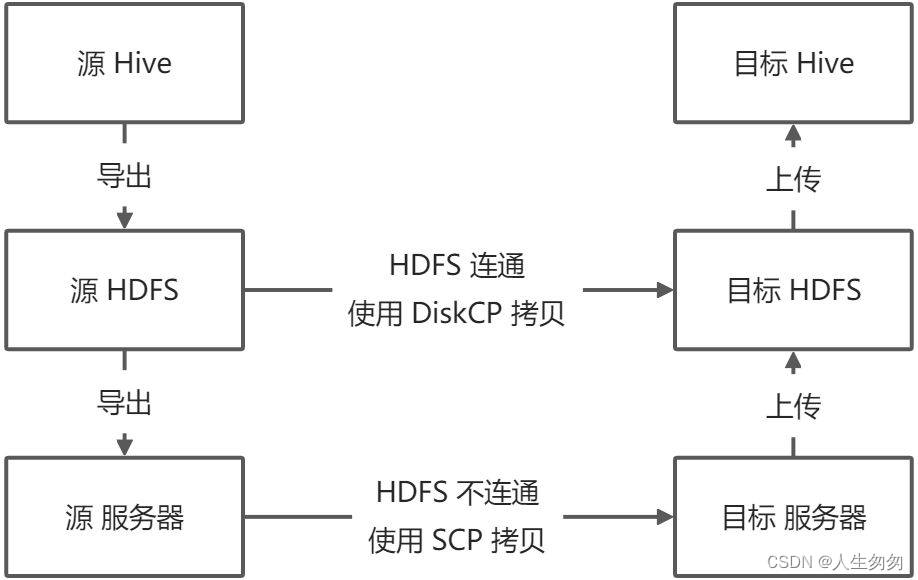
Hive 数据迁移与备份
迁移类型
同时迁移表及其数据(使用import和export)
迁移步骤
- 将表和数据从 Hive 导出到 HDFS
- 将表和数据从 HDFS 导出到本地服务器
- 将表和数据从本地服务器复制到目标服务器
- 将表和数据从目标服务器上传到目标 HDFS
- 将表和数据从目标 HDFS 上传到目标 Hive 库
- 如果原始 HDFS 和目标 HDFS 集群连通,可使用 DiskCP 工具直接跨集群复制,而跳过2~4步
一、Export、Import
Export导出,将Hive表中的数据,导出到外部
Import导入,将外部数据导入Hive表中
二、Export
1、语法
EXPORT TABLE tablename TO "export_target_path";
2、用法
#把tshang表导出到hdfs上
hive (default)> EXPORT TABLE lijia.tshang TO "/tmp/hive_data/lijia";
hive (default)> exit
[root@ /opt/PE/hive_data]# hadoop fs -ls /tmp/hive_data/lijia/tshang
Found 2 items
-rw-r--r-- 3 hive hdfs 1262 2024-03-18 17:35 /tmp/hive_data/lijia/tshang/_metadata
drwxr-xr-x - hive hdfs 0 2024-03-18 17:35 /tmp/hive_data/lijia/tshang/dataHDFS 集群连通时使用 DiskCP 进行拷贝
hadoop distcp hdfs://scrNmaeNode/tmp/<db_name> hdfs://targetNmaeNode/tmp
HDFS 集群不连通
hadoop fs -get /tmp/hive_data
scp -r hive_data root@targetAP:/tmp/
上传到目标 HDFS
hadoop fs -put /tmp/hive_data /tmp/
三、Import
1、语法
IMPORT TABLE tablename FROM "source_path";
2、用法
#先创建lijia库导入数据
hive (default)> create database lijia;
OK
Time taken: 0.012 seconds#导入
hive (db_hive)> import table lijia.tshang from "/tmp/hive_data/lijia";hive (db_hive)> select * from lijia.tshang;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
Time taken: 0.029 seconds, Fetched: 14 row(s)实施过程,迁移数据库,不在是一个表
目标集群和服务器检查
df -lh # 查看本地空间使用情况
hadoop dfsadmin -report # 查看HDFS集群使用情况
hadoop fs -find / -name warehouse # 查找Hive库位置
hadoop fs -du -h /user/hive/warehouse # 查看Hive库占用
同时迁移表及其数据(使用import和export)
- export 工具导出时会同时导出元数据和数据
- import 工具会根据元数据自行创建表并导入数据
- 如果涉及事物表需要预先开启目标库的事物机制
-- 开启事务
-- https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions#HiveTransactions-Configuration
SET hive.support.concurrency = true;
SET hive.enforce.bucketing = true;
SET hive.exec.dynamic.partition.mode = nonstrict;
SET hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
SET hive.compactor.initiator.on = true;
SET hive.compactor.worker.threads = 1;
迁移步骤
#输入需要迁移的数据库default
执行
cat <<EOF > /opt/lijia/hive_sel_tables.HQL
use default;
show tables;
EOF# 罗列要迁移的表清单
执行
beeline -u jdbc:hive2://172.24.3.183:10000 -nhive -f /opt/lijia/hive_sel_tables.HQL \
| grep -e "^|" \
| grep -v "tab_name" \
| sed "s/|//g" \
| sed "s/ //g" \
> /opt/lijia/hive_table_list.txt# 生成导出脚本
cat /opt/lijia/hive_table_list.txt \
| awk '{printf "export table <db_name>.%s to |\"/tmp/lijia/<db_name>/%s\"|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /opt/lijia/hive_export_table.HQL执行
cat /opt/lijia/hive_table_list.txt \
| awk '{printf "export table default.%s to |\"/tmp/lijia/default/%s\"|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /opt/lijia/hive_export_table.HQL# 生成导入脚本
cat /opt/lijia/hive_table_list.txt \
| awk '{printf "import table <db_name>.%s from |\"/tmp/lijia/<db_name>/%s\"|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /opt/lijia/hive_import_table.HQL执行
cat /opt/lijia/hive_table_list.txt \
| awk '{printf "import table default.%s from |\"/tmp/lijia/default/%s\"|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /opt/lijia/hive_import_table.HQL# 创建 HDFS 导出目录
hadoop fs -mkdir -p /tmp/lijia/<db_name>/
hadoop fs -mkdir -p /tmp/lijia/default/# 导出表结构到数据到 HDFS
beeline -u jdbc:hive2://172.24.3.183:10000 -nhive -f /opt/lijia/hive_export_table.HQL## HDFS 集群连通时使用 DiskCP 进行拷贝
hadoop distcp hdfs://scrNmaeNode/tmp/<db_name> hdfs://targetNmaeNode/tmp## HDFS 集群不连通
hadoop fs -get /tmp/lijia/default/
scp -r /tmp/lijia/default/ root@targetAP:/tmp/lijia/## 目标服务器# 创建 HDFS 导出目录
hadoop fs -mkdir -p /tmp/lijia/# 上传到目标 HDFS
hadoop fs -put /tmp/lijia/default /tmp/lijia/# 导入到目标 Hive
beeline -u jdbc:hive2://172.24.3.183:10000 -nhive -f /opt/lijia/hive_import_table.HQL相关文章:
Hive 数据迁移与备份
迁移类型 同时迁移表及其数据(使用import和export) 迁移步骤 将表和数据从 Hive 导出到 HDFS将表和数据从 HDFS 导出到本地服务器将表和数据从本地服务器复制到目标服务器将表和数据从目标服务器上传到目标 HDFS将表和数据从目标 HDFS 上传到目标 Hiv…...

FFMpeg 获取音频音量、提高音量
查看音量 准备原生音频original.mp3 查看original.mp3的音量信息: ffmpeg -i original.mp3 -filter_complex volumedetect -c:v copy -f null /dev/null输出: Input #0, mp3, from original.mp3:Metadata:artist : Administratorencoder …...

【java数据结构】基于java提供的ArrayList实现的扑克牌游戏-(附源码~)
【Java数据结构】基于java泛型实现的二维数组完成三人扑克游戏 基本框架的实现创建一副牌如何进行洗牌:每个人抓的牌放到哪里: 源码具体实现cardcardsTest 个人简介:努力学编程 每日鸡汤:stay foolish,stay hungry-史蒂芬.乔布斯斯…...
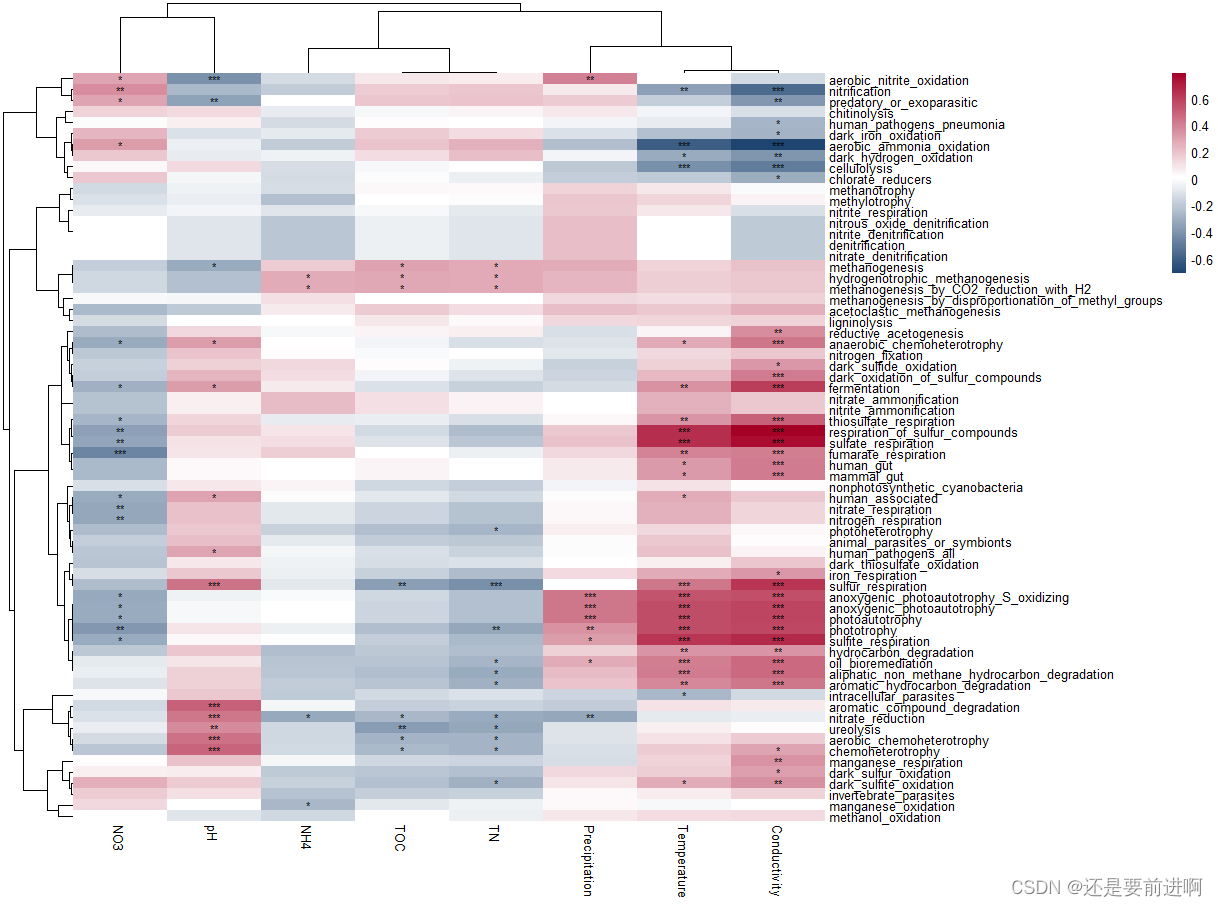
R语言:microeco:一个用于微生物群落生态学数据挖掘的R包,第八:trans_func class
# 生态学研究人员通常对微生物群落的功能特征感兴趣,因为功能或代谢数据对于解释微生物群落的结构和动态以及推断其潜在机制是强有力的。 # 由于宏基因组测序复杂且昂贵,利用扩增子测序数据预测功能谱是一个很好的选择。 # 有几个软件经常用于此目标&…...

王道c语言-二叉树前序、中序、后序、层次遍历
main.cpp #include "function.h"//abdhiejcfg 前序遍历深度优先遍历 abdhiejcfg void PreOrder(BiTree p) {if (p ! NULL) {printf("%c ", p->c);//等价于putchar(p->c);等价于visit函数伪代码PreOrder(p->lchild);PreOrder(p->rchild);} }//…...
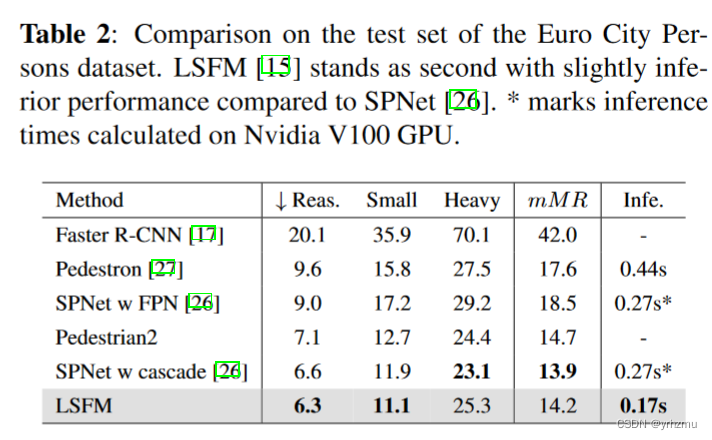
<REAL-TIME TRAFFIC OBJECT DETCTION FOR AUTONOMOUS DRIVING>论文阅读
Abstract 随着计算机视觉的最新进展,自动驾驶迟早成为现代社会的一部分,然而,仍有大量的问题需要解决。尽管现代计算机视觉技术展现了优越的性能,他们倾向于将精度优先于效率,这是实时应用的一个重要方面。大型目标检测…...

优化 - 排序算法
一、概念 冒泡排序从左往右比较相邻的两个元素,右比左小就换位,这样最大值就出现在了右边最后一个元素上,再从左边第一个元素开始往右比较到倒数第二个元素,如此重复...选择排序 通过线性查找(从左往右挨个查找&#…...

Python实战:深拷贝与浅拷贝
1. 引言 在Python中,对象是通过对内存中的数据进行引用来实现的。当我们创建一个对象并将其赋值给另一个变量时,实际上是将这个对象的引用复制给了另一个变量。这意味着,如果原始对象发生改变,引用该对象的变量也会受到影响。为了…...

rollup打包起手式
使用Rollup打包JavaScript rollup是一款小巧的javascript模块打包工具,更适合于库应用的构建工具;可以将小块代码编译成大块复杂的代码,基于ES6 modules,它可以让你的 bundle 最小化,有效减少文件请求大小,vue在开发的时候用的是webpack,但是…...

【笔记】语言实例比较 3. 无重复字符的最长子串 C++ Rust Java Python
语言实例比较 3. 无重复字符的最长子串 C Rust Java Python C C: 9ms O ( N 2 ) O(N^2) O(N2), 8.68MB mem O ( 1 ) O(1) O(1) 滑动窗口循环 class Solution { public:int lengthOfLongestSubstring(const string s) {//s[start,end) 前面包含 后面不包含int res(0);for (…...

int的大小你知道时4个字节,那么类的大小你知道怎么计算吗?
文章目录 1、如何计算类对象的大小2、类对象的存储方式猜测3、结构体内存对齐规则1、如何计算类对象的大小 class A { public: void PrintA() { cout<<_a<<endl; } private: char _a; };问题: 类中既可以有成员变量,又可以有成员函数,那么一个类的对象中包含了…...
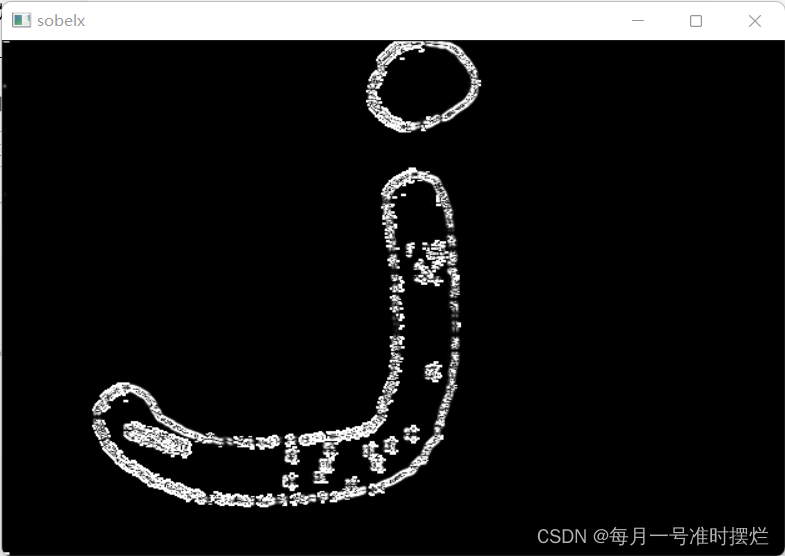
OpenCV学习笔记(十一)——利用Sobel算子计算梯度
Sobel算子是基于一阶导数的离散差分算子,其中Sobel对于像素值的变化是十分敏感的,在进行边缘检测的时候,Sobel算子常用于对周围像素的重要性进行检测。 Sobel算子包括检验水平方向的算子和检测竖直方向的算子 计算机梯度值的操作如下&#x…...

扩展一下BenchmarkSQL,新增支持ASE/HANA/DB2/SQLServer,可以随便用了
1 背景 提到数据库的性能,自然就避不开性能测试。有专用于测试OLTP的,也有偏重于OLAP的。本文介绍的BenchmarkSQL就属于测试OLTP中的一个,基于TPCC的。网上有很多介绍TPC*的相关测试的文章,大家可以自行脑补。而PostgreSQL自带的pgbench是属于TPCC的前一个基准测试程序,偏…...

Android 静默安装成功后自启动
近期开发上线一个常驻app,项目已上线,今天随笔记录一下静默安装相关内容。我分三篇静默安装(root版)、静默安装(无障碍版)、监听系统更新、卸载、安装。 先说说我的项目需求:要求app一直运行&am…...

计算机二级真题讲解每日一题:《format格式化》
描述 在右侧答题模板中修改代码,删除代码中的横线,填写代码,完成如下功能。 接收用户输入的一个小于 20的正整数,在屏幕上逐行递增显示从 01 到该正整数,数字显示的宽度为 2,不足位置补 0,后面追…...
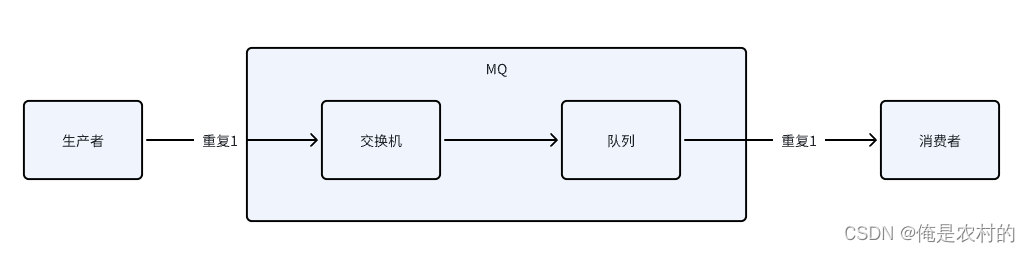
RabbitMQ问题
如何实现顺序消费? 消息放入到同一个队列中消费 如何解决消息不丢失? 方案: 如上图:消息丢失有三种情况,解决了以上三种情况就解决了丢失的问题 1、丢失1--->消息在到达交换机的时候;解决࿱…...

flutter->Scaffold左侧/右侧侧边栏和UserAccountsDrawerHeader的使用
//appBar的 leading/actions 和 Scaffold的drawer/endDrawer 冲突只能存在一个 import package:flutter/material.dart;void main() {runApp(MyApp()); }class MyApp extends StatelessWidget {const MyApp({super.key});overrideWidget build(BuildContext context) {retur…...
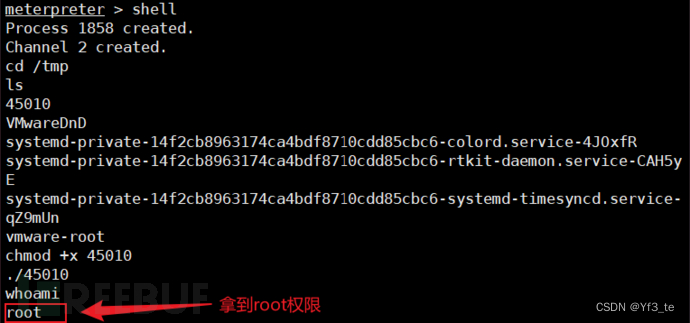
vulnhub prime1通关
目录 环境安装 1.信息收集 收集IP 端口扫描 目录扫描 目录文件扫描 查找参数 打Boss 远程文件读取 木马文件写入 权限提升 方法一 解锁密钥 方法二: linux内核漏洞提权 总结 环境安装 Kali2021.4及其prime靶机 靶机安装:Prime: 1 ~ Vul…...
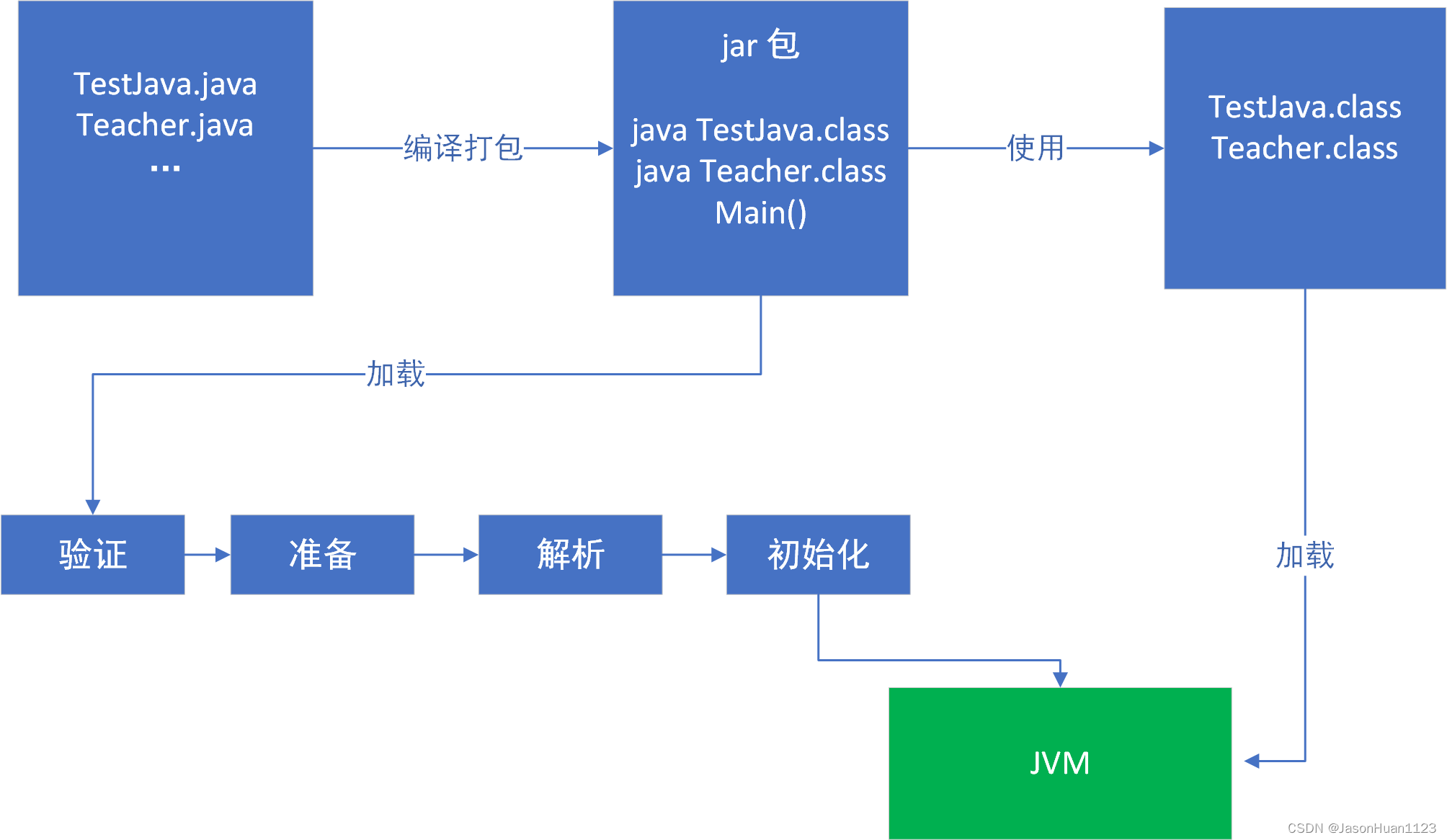
JVM快速入门(1)JVM体系结构、运行时数据区、类加载器、线程共享和独享、分区、Java对象实例化
5.1 JVM体系结构 线程独占区-程序计数器(Program Counter Register) 程序计数器是一块较小的内存空间,它可以看做是当前线程所执行的字节码的行号指示器;在虚拟机的概念模型里,字节码解释器工作时就是通过改变这个计数…...

CSS3新属性(学习笔记)
一、. 圆角 border-radius:; 可以取1-4个值(规则同margin) 可以取px和% 一般用像素,画圆的时候用百分比:border-radius:50%; <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8&q…...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...
实战选型指南)
别再乱用分支了!Flowable四种网关(排他/并行/包容/事件)实战选型指南
Flowable四大网关实战选型:从混乱到精准的决策艺术当你在设计一个请假审批流程时,是否遇到过这样的困惑:部门经理审批后需要同时通知HR和财务,但某些特殊情况下又需要跳过财务直接归档?这种看似简单的业务需求…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...
的原理、演进与未来)
车载诊断系统(OBD)的原理、演进与未来
本文约8,167字,建议收藏阅读 作者 | 北湾南巷 出品 | 汽车电子与软件 引 言 在现代汽车中,越来越多的故障不再表现为明显的机械损坏,而是以“亮灯”“报码”“性能异常”等电子信号的形式出现。发动机为什么亮起故障灯?排放是否达…...

179个核心职位,50个公司分类,中国大模型产业全栈
最后 对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大? 答案只有一个:人工智能(尤其是大模型方向)…...

InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制
InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一个基于Unreal Engine 5开发的RTSP视频播放插件࿰…...

企业云盘签章技术方案:从数字签名原理到工程落地
背景 电子签章在企业云盘中的落地,不只是一个"上传盖章图片"的功能实现。本质上,它是一套涉及数字签名、PKI基础设施、文档完整性校验的综合性技术方案。本文从技术选型角度,说清楚企业云盘内置签章需要解决哪些问题、主流实现方案…...