pandas的综合练习
事先说明:
由于每次都要导入库和处理中文乱码问题,我都是在最前面先写好,后面的代码就不在写了。要是copy到自己本地的话,就要把下面的代码也copy下。
# 准备工作import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import matplotlibmatplotlib.rc("font",family="FangSong")First
需求:给定最流行的1000部电影的相关的数据,统计Rating和runtime的分布情况
分析
- 毫无疑问,分布情况肯定是直方图
- 把所有数据中是
runtime和Rating的列选出来 - 求极差,设置组距
- 设置/绘制直方图
代码
# 统计最流行1000部电影的Rating和runtime分布情况file_path = "./IMDB-Movie-Data.csv"df = pd.read_csv(file_path)
# print(df.head(1))
# print(df.info())#rating,runtime分布情况
#选择图形,直方图
#准备数据
runtime_data = df["Runtime (Minutes)"].values# 计算极差
max_runtime = runtime_data.max()
min_runtime = runtime_data.min()# 计算组数
# print(max_runtime-min_runtime)
num_runtime = int((max_runtime-min_runtime)//5)#设置图形的大小
plt.figure(figsize=(20,8),dpi=200)
plt.hist(runtime_data,num_runtime)_x = [min_runtime]
i = min_runtime
while i<=max_runtime+25:i = i+5_x.append(i)
plt.xticks(_x,rotation=45)
plt.title("时长runtime的分布直方图")plt.show()# 准备数据
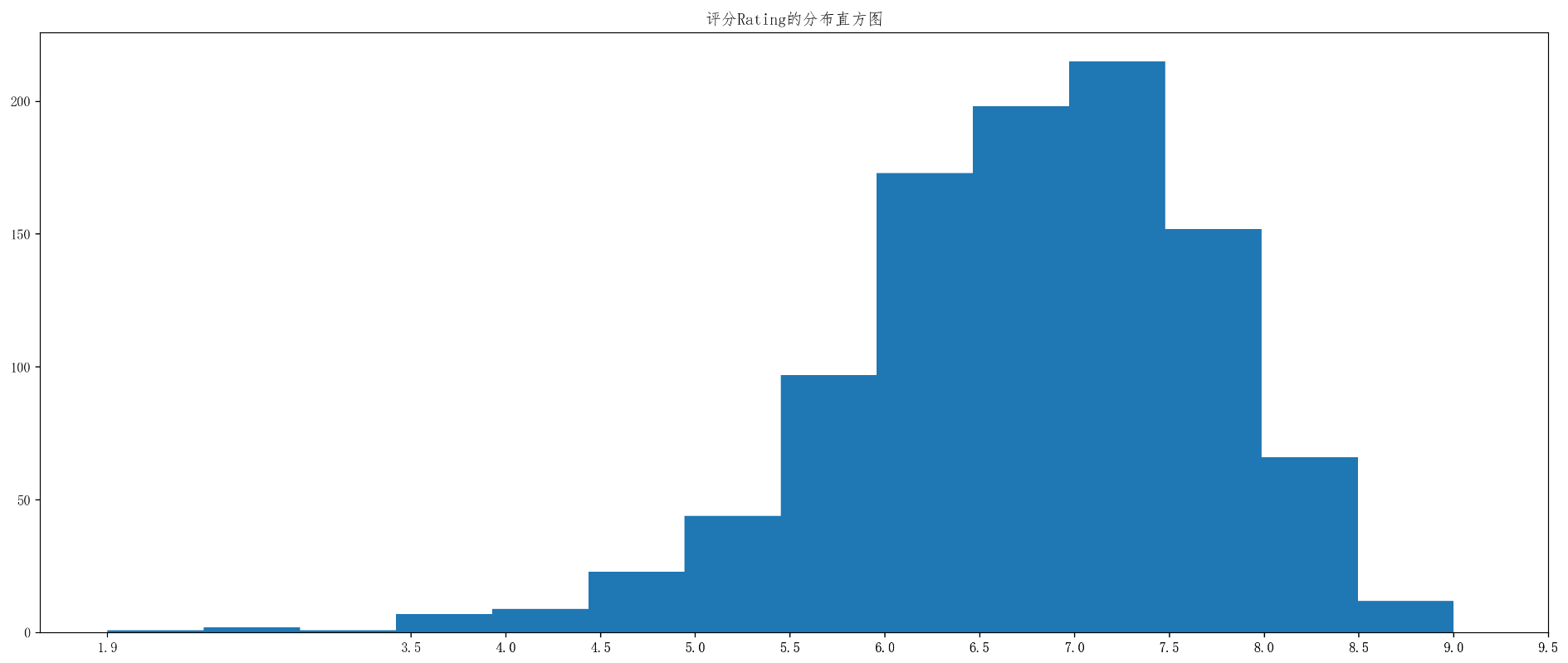
Ratint_data = df["Rating"].valuesmax_Rating = Ratint_data.max()
min_Rating = Ratint_data.min()num_Rating = int((max_Rating-min_Rating)//0.5)plt.figure(figsize=(20,8),dpi=200)
plt.hist(Ratint_data,num_Rating)# 设置不等宽组距_
x=[1.9,3.5]
i=3.5
while i<max_Rating+0.5:i+=0.5_x.append(i)
plt.xticks(_x)
plt.title("评分Rating的分布直方图")plt.show()效果

Second
需求:给定最流行的1000部电影的相关的数据,统计这些电影的类型
分析
- 毫无疑问,连续数据的分布用条形图
- 选出电影中类型的那一列数据
- 用相关方法把其变成列表
- 构造全零数组
- 遍历每个电影。如果有该类型,则赋值为1,否则不变
- 排序
- 绘制条形图
代码
# 统计最流行1000部电影的类型# 准备数据
file_path="IMDB-Movie-Data.csv"df=pd.read_csv(file_path)
# print(df["Genre"].head())# 统计电影的类型
temp_list=df["Genre"].str.split(",").tolist()
# print(temp_list)
genre_list=list(set(i for j in temp_list for i in j))
# print(genre_list)# 构造全零的数组
zeros_df=pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
# print(zeros_df.head())# 给每个电影存在的类型赋值为1
for i in range(df.shape[0]):zeros_df.loc[i,temp_list[i]]=1
# print(zeros_df.head())# 统计每种类型的电影的和
genre_count=zeros_df.sum(axis=0)
# print(genre_count)# 排序
genre_count=genre_count.sort_values()
# print(genre_count)
_x=genre_count.index
_y=genre_count.values
# print(_x,_y)# 绘制条形图
plt.figure(figsize=(20,8),dpi=200)
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
plt.xlabel("电影类型")
plt.ylabel("电影数量")
plt.title("最流行的1000部电影的分类")
plt.show()效果

思考学习
- 某一列是字符串类型,并且有多个值。我们可以通过此题学到一种解决办法(以后可以套用):
-
- 用字符串方法进行切割
- 转化成列表
- 两层循环取出类型
# 通过字符串的方法,进行切割
temp_list=df["Genre"].str.split(",").tolist()# 套用两层循环,用set是去重
genre_list=list(set(i for j in temp_list for i in j))- 对于某一特征有多个属性,而我们要统计属性的数量。我们可以通过此题学到一种解决办法(以后可以套用):
-
- 构造全零数组(维度根据实际情况来,一般情况下,0轴是样本数量,1轴是属性数量,列标签也是属包含所有属性),
0表示没有这种属性 - 遍历每个样本的该特征的所有属性,如果有,则将该位置的值变为
1 - 统计,求和
- 构造全零数组(维度根据实际情况来,一般情况下,0轴是样本数量,1轴是属性数量,列标签也是属包含所有属性),
# 构造全零的数组
zeros_df=pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
# print(zeros_df.head())# 给每个电影存在的类型赋值为1
for i in range(df.shape[0]):zeros_df.loc[i,temp_list[i]]=1
# print(zeros_df.head())# 统计每种类型的电影的和
genre_count=zeros_df.sum(axis=0)
# print(genre_count)Third
需求:给定Starbucks所有店铺的相关数据,求中美两国Starbucks的数量,绘制店铺总数前十的国家的图,绘制中国每个城市(省市)的店铺数量的图
分析
- 统计中美两国Starbucks的数量:
- 用
pandas自带的分组操作,按国家Country分类 - 用聚合
count方法 - 选出中美两国
- 绘制店铺总数前十的国家的图:
- 根据第一问的数据,进行排序
- 绘制图形
- 绘制图形呈现中国每个城市的店铺数量:
- 找出中国的数据
- 用
pandas自带的分组操作,按省市State/Province分类 - 用聚合
count方法 - 绘制图形
代码
# 统计中美两国Starbucks的数量# 准备数据
file_path="starbucks_store_worldwide.csv"
df=pd.read_csv(file_path)
# print(df.head())# 根据国家分组
country_data=df.groupby(by="Country")
# print(country_data)
# for country,values in country_data:
# print(country)
# print(values)# 测试,看country_data统计出来的是什么数据
# t=country_data["Ownership Type"]
# t=country_data["Brand"]
# print(t)
# for i in t:
# print(i)# 调用聚合方法,得到答案
# country_count=country_data["Ownership Type"].count().sort_values()
country_count=country_data["Brand"].count().sort_values()
# print(country_count)
print("美国Starbucks数量:"+str(country_count["US"]))
print("中国Starbucks数量:"+str(country_count["CN"]))# 绘制店铺总数前十的国家的图country_max=country_count[-10:]
# print(country_max)
_x=country_max.index
_y=country_max.values
# print(_x)
# print(_y)plt.figure(figsize=(20,8),dpi=200)
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
plt.title("starbucks店铺总数前十的国家")
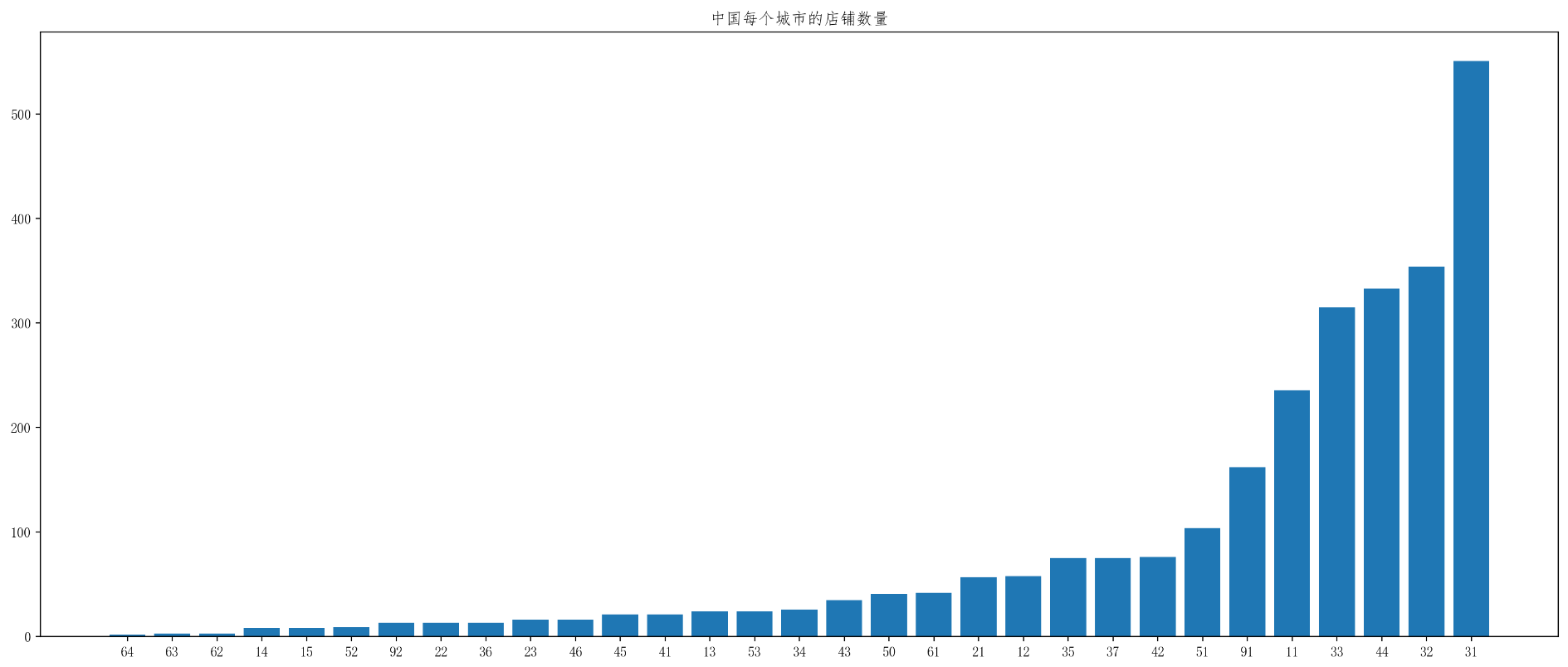
plt.show()# 绘制图形呈现中国每个城市的店铺数量china_data=df[df["Country"]=="CN"]
# print(china_data)china_province=china_data.groupby(by="State/Province")
# for province,values in china_province:
# if(int(province)==31):
# print(province)
# print(values)china_province=china_province["Brand"].count().sort_values()
# print(china_province)_x=china_province.index
_y=china_province.valuesplt.figure(figsize=(20,8),dpi=200)
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
plt.title("中国每个城市的店铺数量")
plt.show()效果
![]()

思考学习
- 学会使用
pandas自带的分组操作,注意操作之后得到的迭代器(应该是迭代器,毕竟不能直接看数据,但是支持遍历等操作) - 对于上一步得到的迭代器,使用聚合
count可以直接统计出各个组内的数据数量
Fourth
需求:给出全球排名前10000本书相关数据,统计不同年份的书籍数量,不同年份的书籍的平均评分情况
分析
相信经过前面三个案例的练习,这个案例应该可以轻松解决👀。所以,我就偷个懒,不写分析了😝
代码
# 不同年份书籍的数量file_path="books.csv"df=pd.read_csv(file_path)
year_data=df[pd.notnull(df["original_publication_year"])].groupby(by="original_publication_year").count()["id"]
# year_data=df.groupby(by="original_publication_year").count()["id"]
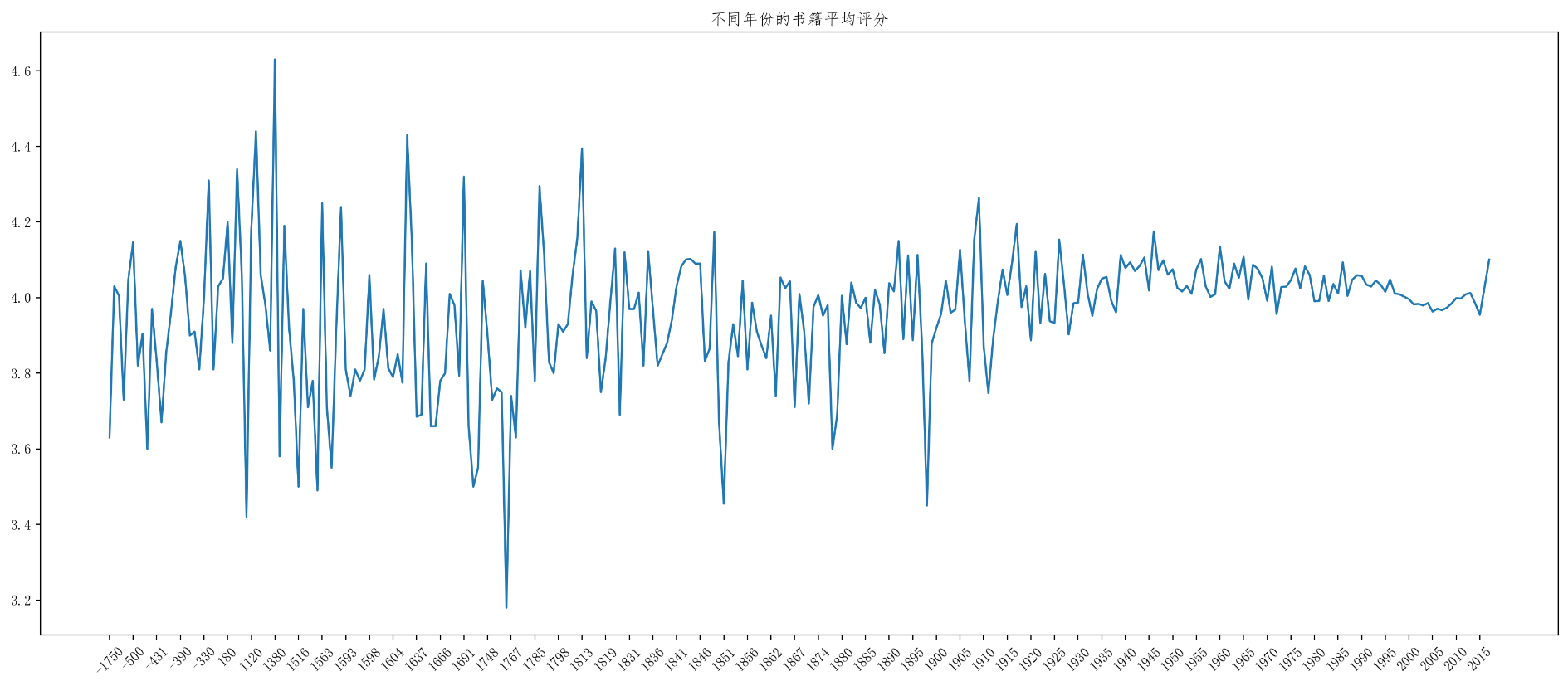
print(year_data)# 不同年份的书籍平均评分rating_data=df[pd.notnull(df["original_publication_year"])]
rating_mean=rating_data["average_rating"].groupby(by=rating_data["original_publication_year"]).mean()_x=rating_mean.index
_y=rating_mean.valuesplt.figure(figsize=(20,8),dpi=200)
plt.plot(range(len(_x)),_y)
plt.xticks(list(range(len(_x)))[::5],_x[::5].astype(int),rotation=45)
plt.title("不同年份的书籍平均评分")
plt.show()效果

相关文章:
pandas的综合练习
事先说明: 由于每次都要导入库和处理中文乱码问题,我都是在最前面先写好,后面的代码就不在写了。要是copy到自己本地的话,就要把下面的代码也copy下。 # 准备工作import pandas as pd import numpy as np from matplotlib impor…...

北京中科富海低温科技有限公司确认出席2024第三届中国氢能国际峰会
会议背景 随着全球对清洁能源的迫切需求,氢能能源转型、工业应用、交通运输等方面具有广阔前景,氢能也成为应对气候变化的重要解决方案。根据德勤的报告显示,到2050年,绿色氢能将有1.4万亿美元市场。氢能产业的各环节的关键技术突…...

非插件方式为wordpress添加一个额外的编辑器
在WordPress中,要添加一个额外的区块编辑器(通常指的是Gutenberg区块编辑器中的一个自定义区块),你需要编写一些PHP代码来注册新的区块,并可能还需要一些JavaScript来处理前端的逻辑。下面是一个简单的示例,展示了如何注册一个自定…...
Spark Stage
Spark Stage 什么是Stage Spark中的一个Stage只不过是物理执行计划其中的一个步骤,它是物理执行计划的一个执行单元。一个Job会被拆分为多组Task,每组任务被称为一个Stage,可以简单理解为MapReduce里面的Map Stage, Reduce Stag…...
【国家计算机二级考试C语言.2024】学习备忘录
说明 分值 4060100 40分: 这里面有一大堆程序结果选这题,如果手速还可以。那遇到有疑问的情况就自己去倒计算器的ad E上面去打一打。能够跑出来,结果那是100%的没问题。 有些概念题比较讨厌,只能自己去记忆了。要去背诵熟熟的。…...

十分钟掌握redis精髓指令
编译安装 git clone https://gitee.com/mirrors/redis.git cd redis make make test make install # 默认安装在 /usr/local/bin # redis-server 是服务端程序 # redis-cli 是客户端程序启动 mkdir redis-data # 把redis文件夹下 redis.conf 拷贝到 redis-data # 修改 redis.…...

突然断电导致git损坏修复
背景 使用ide开发时突然断电启动后所有文件都成了没有提交的文件。打开git视图日志也消失不见 # git命令执行结果如下 git status No commits yetChanges to be committed:(use "git rm --cached <file>..." to unstage)new file: .github/FUNDING.ymlnew …...

MATLAB入门指南:从零开始进行数学建模竞赛
第1部分:认识MATLAB 1.1 什么是MATLAB? MATLAB(Matrix Laboratory的缩写)是一个高性能的数值计算环境和第四代编程语言。由MathWorks公司开发,它提供了一个便捷的数学解决框架,主要用于算法开发、数据可视…...

【JavaEE初阶系列】——带你了解volatile关键字以及wait()和notify()两方法背后的原理
目录 🚩volatile关键字 🎈volatile 不保证原子性 🎈synchronized 也能保证内存可见性 🎈Volatile与Synchronized比较 🚩wait和notify 🎈wait()方法 💻wait(参数)方法 🎈noti…...
GitHub配置SSH Key(详细版本)
GitHub配置SSH Key的目的是为了帮助我们在通过git提交代码是,不需要繁琐的验证过程,简化操作流程。比如新建的仓库可以下载, 但是提交需要账号密码。 步骤 一、设置git的user name和email 如果你是第一次使用,或者还没有配置过的话需要操作…...
JavaScript 权威指南第七版(GPT 重译)(六)
第十五章:JavaScript 在 Web 浏览器中 JavaScript 语言是在 1994 年创建的,旨在使 Web 浏览器显示的文档具有动态行为。自那时以来,该语言已经发生了显著的演变,与此同时,Web 平台的范围和功能也迅速增长。今天&#…...

Learning to summarize from human feedback
Abstract 人工参考总结以及 ROUGE 指标只是我们真实关心的目标(总结质量)的粗略代表。通过优化人工偏好来显著提升总结质量使用大量高质量的人类比较来训练一个模型来预测人类偏好的总结使用这个模型作为奖励函数对总结策略进行强化学习微调我们模型的效果在 TL;DR 数据集上显…...

数据库迁移测试
数据迁移测试 在进行项目重构或者更新的时候或多或少会对数据库进行变更,为了保证业务的稳定性对数据进行迁移测试是很有必要的,因为数据就是业务的基石,没有数据业务都是空中楼阁,形同虚设,小编结合近期的工作对数据…...

ASP .Net Core ILogger日志服务
🐳简介 ILogger日志服务是.NET平台中的一个内置服务,主要用于应用程序的日志记录。它提供了灵活的日志记录机制,允许开发者在应用程序中轻松地添加日志功能。以下是其主要特点和组件: ILogger接口:这是ILogger日志服…...

LeetCode 2657.找到两个数组的前缀公共数组
给你两个下标从 0 开始长度为 n 的整数排列 A 和 B 。 A 和 B 的 前缀公共数组 定义为数组 C ,其中 C[i] 是数组 A 和 B 到下标为 i 之前公共元素的数目。 请你返回 A 和 B 的 前缀公共数组 。 如果一个长度为 n 的数组包含 1 到 n 的元素恰好一次,我…...

【jvm】jinfo使用
jinfo介绍 jinfo 是一个命令行工具,用于查看和修改 Java 虚拟机(JVM)的配置参数。它通常用于调试和性能调优。 使用 jinfo 命令,你可以查看当前 JVM 的配置参数,包括堆大小、线程数、垃圾回收器类型等。此外…...
C++ Thread 源码 观后 自我感悟 整理
Thread的主要数据成员为_Thr 里面存储的是线程句柄和线程ID 先看看赋值运算符的移动构造 最开始判断线程的ID是否不为0 _STD就是使用std的域 如果线程ID不为0,那么就抛出异常 这里_New_val使用了完美转发,交换_Val和_New_val的值 _Thr _STD exchange(_…...

2024阿里云2核2G服务器租用价格99元和61元一年
阿里云2核2G服务器配置优惠价格61元一年和99元一年,61元是轻量应用服务器2核2G3M带宽、50G高效云盘;99元服务器是ECS云服务器经济型e实例ecs.e-c1m1.large,2核2G、3M固定带宽、40G ESSD entry系统盘,阿里云活动链接 aliyunfuwuqi.…...

刚刚!奥特曼剧透GPT-5,将在高级推理功能上实现重大进步
奥特曼:“GPT-5的能力提升幅度将超乎人们的想象…” 自 Claude 3 发布以来,外界对 GPT-5 的期待越来越强。毕竟Claude 3已经全面超越了 GPT-4,成为迄今为止最强大模型。 而且距离 GPT-4 发布已经过去了整整一年时间,2023年3月14…...

uniapp使用Canvas给图片加水印把临时文件上传到服务器
生成的临时路径是没有完整的路径没办法上传到服务器 16:37:40.993 添加水印后的路径, _doc/uniapp_temp_1710923708347/canvas/17109238597881.png 16:37:41.041 添加水印后的完整路径, file://storage/emulated/0/Android/data/com.jingruan.zjd/apps/__UNI__BE4B000/doc/…...

除了排错,你可能不知道OPC Expert v8.1还能做这些:数据归档、计算与冗余实战
解锁OPC Expert v8.1的隐藏潜力:数据归档、实时计算与冗余架构实战指南在工业自动化领域,OPC Expert常被视为故障排查的"急救箱",但它的能力远不止于此。当大多数工程师还在用它解决DCOM配置问题时,少数先行者已经用它重…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...

通用物联网开发板设计:基于ESP8266的硬件集成与开发实践
1. 项目概述:为什么我们需要一块“通用”的物联网开发板?在捣鼓了几年物联网项目之后,我发现自己桌面上堆满了各种开发板:ESP8266、ESP32、Arduino Uno、STM32 Nucleo……每个项目都要重新连线、配置电源、焊接传感器接口…...

XXPermissions:Android权限管理框架的架构设计与最佳实践
XXPermissions:Android权限管理框架的架构设计与最佳实践 【免费下载链接】XXPermissions Android Permissions Framework, Adapt to Android 16 项目地址: https://gitcode.com/GitHub_Trending/xx/XXPermissions 在Android应用开发中,权限管理一…...

荣耀出征离线挂机深度攻略:吃透隐性机制,告别无效挂机碾压同级
作为混迹游戏圈二十余年、从街机厅搓摇杆到网吧通宵刷端游,日均稳坐游戏6小时以上的老玩家,实测过无数网游的挂机体系。《荣耀出征》的离线挂机看似门槛极低、操作简单,但全网九成攻略都只停留在“开自动、挂地图”的基础层面,完全…...

描述它,不要画它:通过 MCP 和 ES|QL 实现 AI-native Kibana dashboards
作者:来自 Elastic Stratoula Kalafateli 从 prompt 到 dashboard。学习如何使用自然语言构建 Kibana dashboards,使用 example-mcp-dashbuilder:一个开源 MCP 应用,它可以编写 ES|QL 查询,创建交互式图表,…...

如何告别城通网盘龟速下载:三步获取高速直连的终极方案
如何告别城通网盘龟速下载:三步获取高速直连的终极方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘那令人抓狂的下载速度而苦恼吗?每次点击下载按钮后&#x…...
实现微秒级时间同步的完整流程)
实战避坑:在Linux服务器上配置PTP(ptp4l)实现微秒级时间同步的完整流程
实战避坑:在Linux服务器上配置PTP(ptp4l)实现微秒级时间同步的完整流程在分布式系统、金融交易和高频计算场景中,毫秒级的时间同步早已无法满足需求。当系统需要跨多个节点协调操作时,微秒级甚至纳秒级的时间同步成为刚…...

以书香润心,借坚韧前行
一书一山海,一心一乾坤。身处车马喧嚣的世间,我们时常被生活的压力裹挟,被前路的未知困扰,在重复的日常里消磨热忱,在跌宕的波折中心生怯懦。而书籍,是治愈心灵、滋养成长的最好良方,于无声处给…...

高能物理实时触发系统:HGQ与LGN算法在FPGA上的极致优化实践
1. 项目概述:当粒子对撞遇见实时AI在大型强子对撞机(LHC)每秒数千万次的质子对撞中,CMS探测器会捕获海量的高维数据。第一级触发系统(L1T)的任务,是在3.8微秒的极短时间内,将事件率从…...