JVM垃圾收集器你会选择吗?
目录
一、Serial收集器
二、ParNew收集器
三、Paralle Scavenge
四、Serial Old
五、Parallel Old
六、CMS收集器
6.1 CMS对处理器资源非常敏感
6.2 CMS容易出现浮动垃圾
6.3 产生内存碎片
七、G1 收集器
八、如何选择合适的垃圾收集器
JVM 垃圾收集器是Java虚拟机(JVM)中至关重要的组件,负责自动管理程序运行时产生的内存分配与回收。垃圾收集器通过检测并回收堆内存中不再使用的对象,从而保证了 Java 应用程序在持续运行过程中拥有足够的内存空间。
如果说收集算法是内存回收的方法论,那垃圾收集器就是内存回收的实践者。各款经典的收集器之间的关系如下图,如果两个收集器之间存在连线,就说明他们可以搭配使用,收集器所处的区域,则表示它是属于新生代还是老年代。

一、Serial收集器
Serial 收集器是最基础、历史最悠久的收集器,这个收集器是单线程工作的收集器,他的“单线程”意义并不仅仅是说明它只会是有一个处理器或一条收集器线程去完成垃圾收集工作,更重要的是强调它在垃圾收集时,必须暂停其他所有工作线程,直到它收集结束。
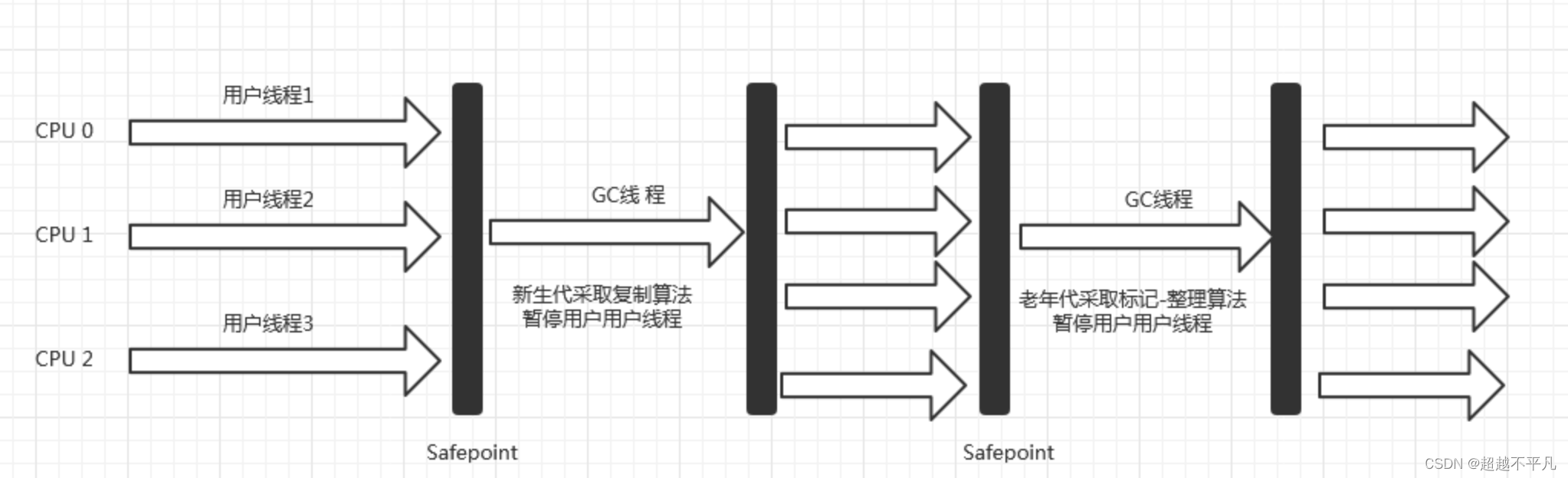
Serial 收集器依然是 HotSpot 虚拟机运行在客户端模式下的默认新生代收集器,有着优于其他收集器的地方,那就是简单而高效,对于内存资源受限的环境,他是所有收集器里额外内存消耗最小的。
对于单核处理器或处理器核心数较少的环境来说,Serial 收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得最高单线程收集效率。近年来流行的微服务应用中,分配给虚拟机的内存一般来说并不大,收集十兆甚至几百兆的新生代,垃圾收集的停顿时间完全可以控制在十几、几十毫秒内,只要不是频繁发生收集,是可以接受的。
二、ParNew收集器
ParNew 收集器实质上是 Serial 收集器多线程的并行版本,除了同时使用多线程进行垃圾收集外,其余的行为包括 Serial 收集器可用的所有控制参数都与 Serial 完全一致。

ParNew 除了支持多线程并行收集外,其他与 Serial 收集器相比没有太多创新,除了 Serial收集器外,目前只有它能与 CMS 收集器配合工作。
CMS 收集器是 HotSpot 虚拟机中第一款真正意义上支持并发的垃圾收集器,他首次实现了让垃圾收集线程和用户线程同时工作。
三、Paralle Scavenge
Paralle Scavenge 收集器也是一款新生代收集器,它同样是基于标记-复制算法实现的收集器,也是能够并行收集的多线程收集器。
Paralle Scavenge 收集器的特点是它的关注点与其他收集器不同,CMS 等收集器关注点是尽可能缩短垃圾收集时用户线程的停顿时间,而 Paralle Scavenge 收集器的目标则是达到一个可控的吞吐量。所谓吞吐量就是处理器用于运行用户代码的时间与处理器总消耗时间的比值,即:

Paralle Scavenge 提供了参数来用于精确控制吞吐量,被称为是吞吐量优先处理器。默认吞吐量的值为 99,即允许最大 1% 的垃圾回收时间。
四、Serial Old
Serial Old 是 Serial 收集器老年代版本,他同样是一款单线程收集器,使用标记-整理算法。
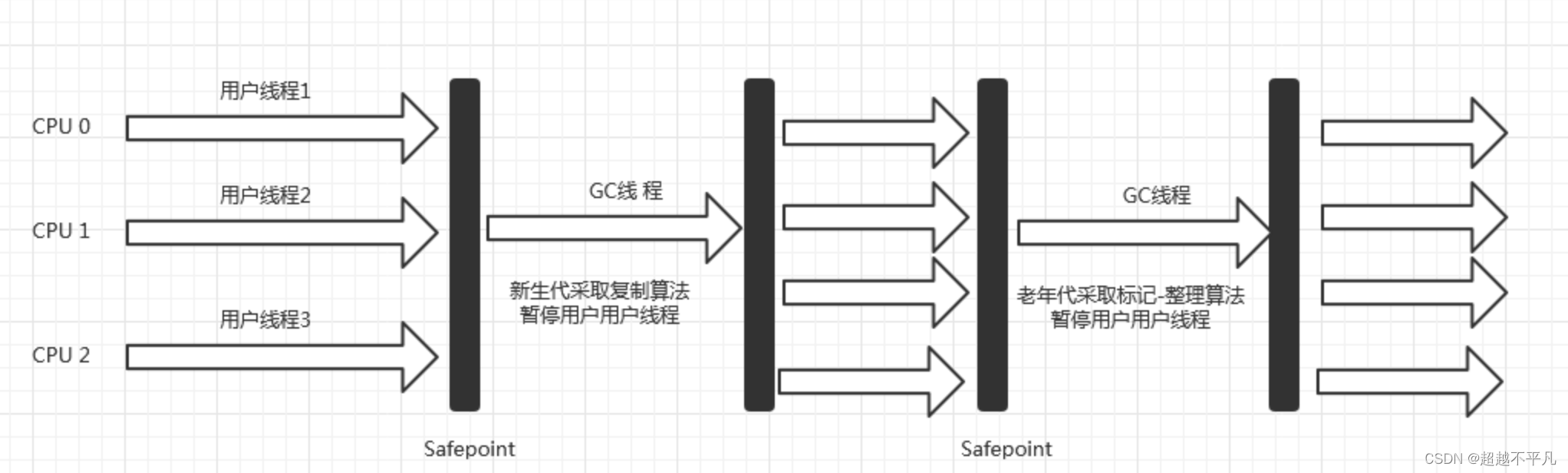
五、Parallel Old
Parallel Old 是 Parallel Scavenge 收集器的老年代版本,支持多线程并发收集,基于标记-整理算法。
六、CMS收集器
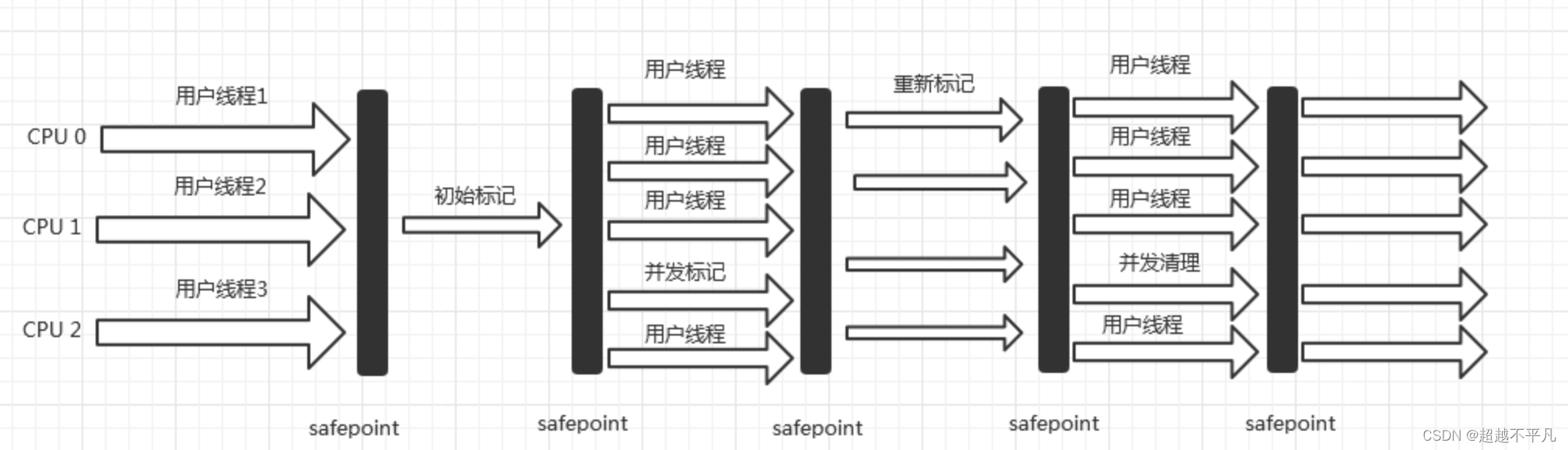
CMS(Concurrent Mark Sweep)收集器是一种以获取最短停顿时间为目标的收集器。从名字可以看出 CMS 是基于标记清除算法实现的。整个过程分为四个步骤:
- 初始标记:初始标记仅仅只是标记一下 GC Roots 能直接关联到的对象,速度很快。
- 并发标记:并发标记阶段就是从 GC Roots 的直接关联对象开始遍历整个对象的过程,这个过程耗时较长但不需要停顿用户线程,可以与垃圾收集线程一起并发运行。
- 重新标记:是为了修正并发标记期间,因为用户继续运作而导致标记产生变动的那一部分对象的标记记录。
- 并发清除:清理删除掉标记阶段判断的已经死亡的对象,由于不需要移动存活对象,所以整个阶段也是可以与用户线程同时并发。
由于整个过程中耗时最长的并发标记与并发清除中,垃圾收集线程都可以与用户线程一起工作,所以从整体上看,CMS 收集器的内存回收过程与用户线程一起并发执行。
但是 CMS 也有一些明显的缺点:
6.1 CMS对处理器资源非常敏感
事实上面向并发设计的程序都对处理器资源比较敏感。在并发阶段,它虽然不会导致用户线程停顿,但却会因为占用了一部分线程而导致应用程序变慢,降低吞吐量。CMS 默认启动的回收线程数是(处理器核心数量 + 3)/ 4。也就是说如果处理器核心数在4个以上,并发回收时垃圾回收线程只占用不超过 25% 的处理器运算资源。但是如果处理器核心不足4个时,CMS对用户程序的影响就可能变得很大。如果应用的负载本来很高,还要分出一半的运算能力去执行垃圾回收,可能导致用户程序的执行速度大幅降低。为了缓解这种情况,虚拟机提出了“增量式并发收集器 i-CMS”,在并发标记、清理的时候让收集器线程、用户线程抢占式交替运行,尽量减少收集线程的独占资源时间,虽然垃圾收集时间会变成长,但对用户影响小一些。实践证明这种方式效果很一般,在jdk7开始,i-CMS标记为过时,不提倡使用。
6.2 CMS容易出现浮动垃圾
有可能出现“Concurrent Mode Dailure”失败而导致另一次完全“stop the word”的 Full GC 的产生。在 CMS 的并发标记和并发清理阶段,用户线程还在继续进行,程序在运行自然就还会伴随着垃圾对象的不断产生,但这一部分垃圾对象是出现在标记过程结束以后,CMS 无法清理掉它们,之后等到下一次清理,这部分垃圾被称为浮动垃圾。
同样也是由于在垃圾收集期间用户线程还需要持续运行,那就还需要预留足够内存空间提供给用户线程,因此 CMS 收集器不能像其他收集器那样,等待老年代几乎快被填满了在进行垃圾收集,必须预留一部分空间供并行收集时程序运行使用。在JDK5的默认配置下,CMS收集器老年代使用68%的空间后会被激活。到JDK6,提升到92%。
6.3 产生内存碎片
基于标记清除算法实现,会产生大量内存碎片。往往会出现老年代还有很多空间,但就是无法找到连续空间分配给当前对象,而不得不提前触发一次 Full GC。
七、G1 收集器
Garbage First 简称 G1 收集器,是一款主要面向服务端的垃圾收集器,最初赋予他的期望是未来可以替换掉 JDK5 中发布的 CMS 收集器。JDK9 发布之日,G1 宣告取代 Parrallel Scavenge和 Parrallel Old 组合,成为服务端模式下默认垃圾收集器。而 CMS 沦落为不被推荐使用的收集器。
它开创了收集器面向局部收集的设计思路和基于 Region 的内存布局形式。在 G1 收集器出现之前的所有收集器,包括 CMS 在内,垃圾收集器的目标范围要么是整个新生代(Minor GC),要么就是整个老年代(Major GC),要么就是整个 Java 堆(Full GC)。而 G1 跳出了这个樊笼,它可以面向堆内存任何部分来组成回收集进行回收,衡量的标准不再是它属于哪个分代而是哪块内存中存放的垃圾数量最多,回收收益最大,这就是 G1 收集器的 Mixed GC 模式。
G1 不在坚持固定大小以及固定数量的分代区域划分,而是把连续的 Java 堆划分为多个大小相等的独立区域(Region),每个 Region 都可以根据需要,扮演新生代的 Eden 空间、Survior空间,或者老年代空间。收集器能够扮演不同角色的 Region 采用不同的策略去处理。Region 中还有一类 Hunongous 区域,专门用来存储大对象。G1 认为只有大小超过了一个 Region 容量一半的对象即可判定为大对象。每个 Region 的大小可以通过参数设定。
虽然 G1 仍然保留新生代和老年代的概念,但新生代和老年代不再是固定的,他们都是一系列区域的动态集合。G1 之所以能够建立可预测的停顿时间模型,是因为它将 Region 作为最小的回收单元,即每次收集到的内存空间都是 Region 大小的整数倍。更具体的处理思路是让 G1 去跟踪各个 Region 里面垃圾堆积的“价值”大小,价值即回收所获得的空间大小以及回收所需的时间的经验值,然后在后台维护一个优先级列表,每次根据用户设定的停顿时间,优先处理回收价值最大的那些 Region,这也是 Garbage First 名字的由来。
G1 主要划分为以下四个步骤:
- 初始标记:仅仅只是标记一下 GC Roots 能直接关联到的对象
- 并发标记:从 GC Roots 开始对堆中对象进行可达性分析,递归整个堆里的对象图,找出要回收的对象
- 最终标记:对用户线程做另一个短暂的暂停,用于处理并发阶段结束后仍遗留下来的数据。
- 筛选回收:负责更新 Region 的统计数据,对各个 Region 的回收价值和成本进行排序,根据用户所期望的停顿时间来指定回收计划。因为涉及到存活对象的移动,所以是必须要暂停用户线程的。
G1 从整体看使用了标记-整理算法,避免了 CMS 标记清除产生的内存空间碎片,垃圾收集完成后能提供规整的可用内存。不过,G1 相比 CMS 也有缺点,G1 无论是为了垃圾收集产生的内存占用还是程序运行时额外执行负载都比 CMS 要高。
就内存而言,虽然 G1 和 CMS 都使用卡表来处理跨代指针,但 G1 的卡表实现更为复杂,而且堆中每个 Region,无论扮演的是新生代还是老年代角色,都必须有一份卡表,这导致 G1 的记忆集占用更多的内存。
八、如何选择合适的垃圾收集器
衡量垃圾收集器的三项重要指标是:内存占用、吞吐量和延迟。
除了以上介绍的垃圾收集器,还有些比较新的垃圾收集器,如ZGC、Epsilon收集器,有十多种收集器,那么该如何选择呢?主要从这3点考虑:
- 应用程序的主要关注点是什么?如果是数据分析、科学计算类的任务,目标是能尽快算出结果,那吞吐量就是主要的关注点;如果是 SLA 应用,那停顿时间直接影响服务质量,严重的甚至导致事务超时,这样延迟就是主要关注点;而如果是客户端或者嵌入式应用,那垃圾收集的内存占用则是不可忽视的。
- 运行应用的基础设施如何?譬如硬件规格,要设计系统架构;处理器的数量是多少,分配内存大小;选择的操作系统是 Linux、Solaris 还是 Windows 等。
- 使用JDK的发行商是什么版本号是多少?
选择垃圾收集器时,还需要进行基准测试和监控,以确定哪种收集器在实际运行环境中性能最佳。可以根据应用程序的实际内存分配和回收情况、CPU 利用率、响应时间和吞吐量指标等进行评估和调整。在生产环境中,还可以通过 JMX 或者其他监控工具实时监控垃圾收集器的表现,以便进行调优。
往期经典推荐
JVM 垃圾回收机制:探秘对象生死判定与高效回收算法-CSDN博客
JVM内存模型深度解读-CSDN博客
Spring循环依赖的成因与破局-CSDN博客
Spring Cloud + Nacos 引领服务治理新航向-CSDN博客
揭秘Redis中AOF与RDB的协同作战,确保数据万无一失-CSDN博客
相关文章:
JVM垃圾收集器你会选择吗?
目录 一、Serial收集器 二、ParNew收集器 三、Paralle Scavenge 四、Serial Old 五、Parallel Old 六、CMS收集器 6.1 CMS对处理器资源非常敏感 6.2 CMS容易出现浮动垃圾 6.3 产生内存碎片 七、G1 收集器 八、如何选择合适的垃圾收集器 JVM 垃圾收集器是Java虚…...

游戏防沉迷系统相关内容
网站地址:网络游戏防沉迷实名认证系统 PHP代码: 创建对应文件,在需要的位置get传参请求即可,具体参数参考 网络游戏防沉迷实名认证系统接口对接技术规范v2.0 1、上传信息 <?php $url "https://wlc.nppa.gov.cn/test…...
每日OJ题_牛客_JD1 年终奖(动态规划)
目录 牛客_JD1 年终奖 解析代码 牛客_JD1 年终奖 年终奖_牛客题霸_牛客网 解析代码 #include <vector> class Bonus { public: int getMost(vector<vector<int> > board) {int m board.size(), n board[0].size();vector<vector<int>> dp(m…...
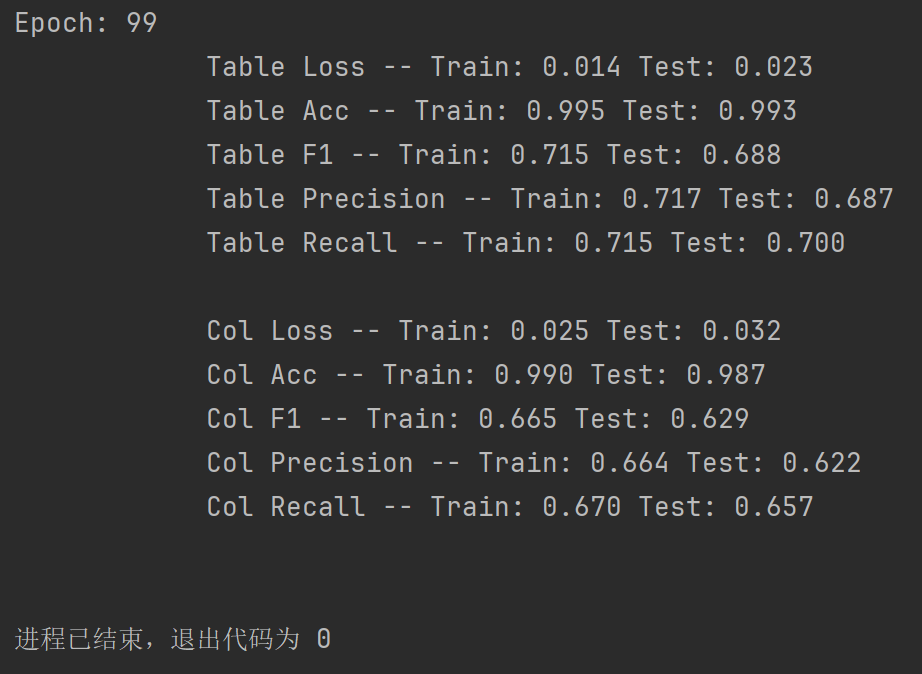
深度学习 tablent表格识别实践记录
下载代码:https://github.com/asagar60/TableNet-pytorch 下载模型:https://drive.usercontent.google.com/download?id13eDDMHbxHaeBbkIsQ7RSgyaf6DSx9io1&exportdownload&confirmt&uuid1bf2e85f-5a4f-4ce8-976c-395d865a3c37 原理&#…...
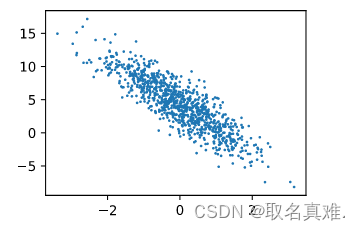
深度学习 线性神经网络(线性回归 从零开始实现)
介绍: 在线性神经网络中,线性回归是一种常见的任务,用于预测一个连续的数值输出。其目标是根据输入特征来拟合一个线性函数,使得预测值与真实值之间的误差最小化。 线性回归的数学表达式为: y w1x1 w2x2 ... wnxn …...
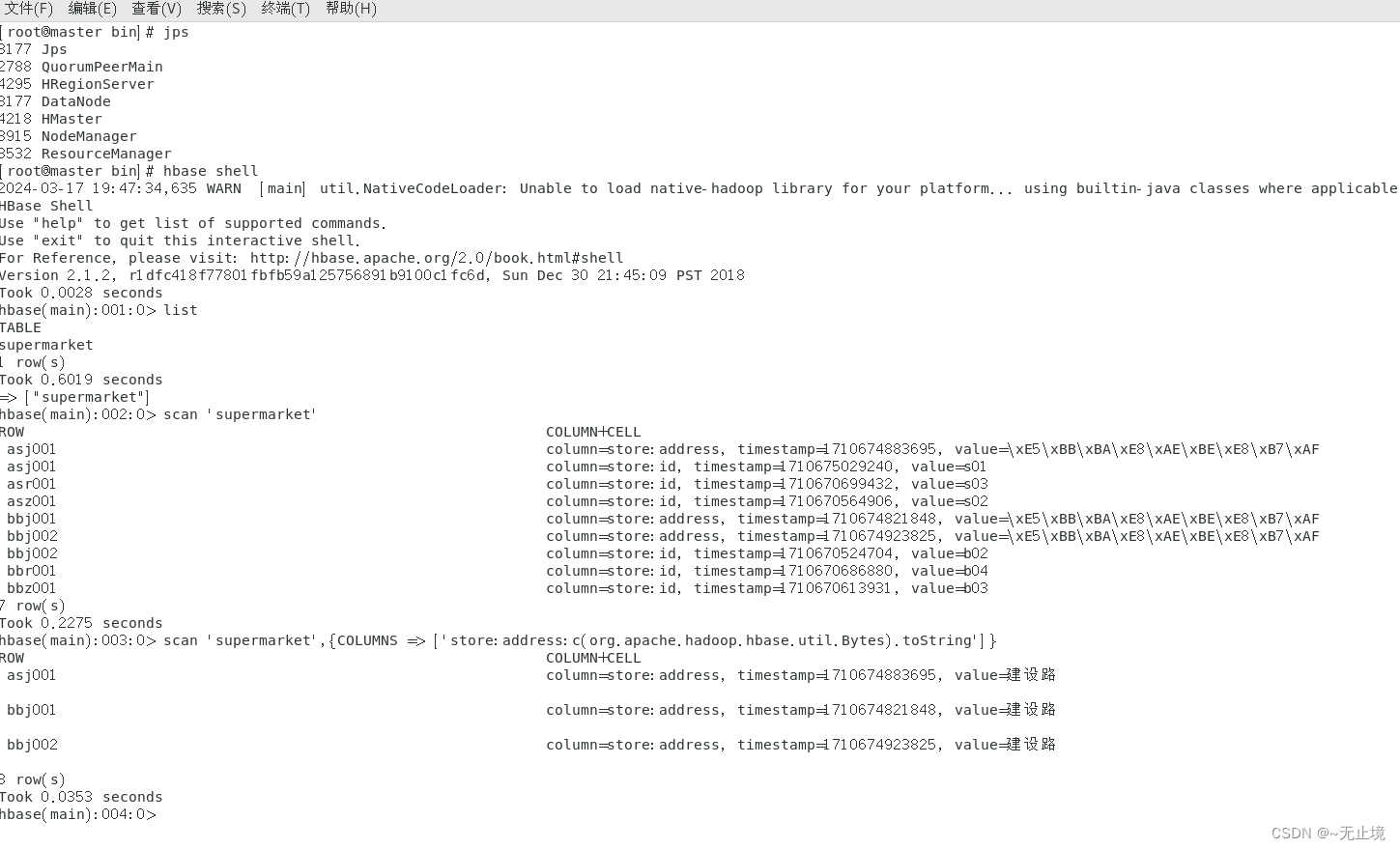
HBase在表操作--显示中文
启动HBase后,Master和RegionServer两个服务器,分别对应进程为HMaster和HRegionServe。(可通过jps查看) 1.进入表操作 hbase shell 2.查看当前库中存在的表 list 3.查看表中数据(注:学习期间可用&#…...
基于BusyBox的imx6ull移植sqlite3到ARM板子上
1.官网下载源码 https://www.sqlite.org/download.html 下载源码解压到本地的linux环境下 2.解压并创建install文件夹 3.使用命令行配置 在解压的文件夹下打开终端,然后输入以下内容,其中arm-linux-gnueabihf是自己的交叉编译器【自己替换】 ./config…...
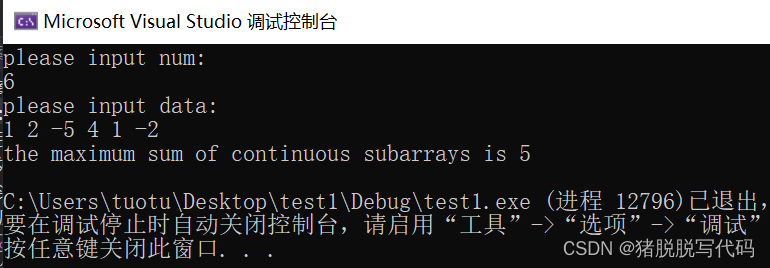
连续子数组的最大和
问题描述: 输入一个整型数组,数组里有正数也有负数。求连续子数组中的最大和为多少。 举例: 数组:arry{1 , 2 ,-5 , 4 , 1 ,-2} 输出:5,数组中连续的位置相加最大值为5, 41 方法…...

Photoshop 工具使用详解(全集 · 2024版)
全面介绍 Photoshop 工具箱里的工具,点击下列表格中工具名称或图示,即可查阅工具的使用详解。 移动工具Move Tool移动选区、图层和参考线。画板工具Artboard Tool创建、移动多个画布或调整其大小。moVe快捷键:V 矩形选框工具 Rectangular Mar…...
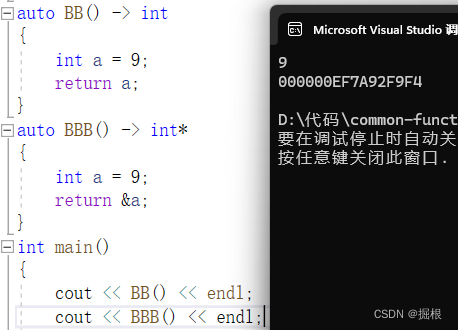
C++函数返回机制,返回类型
return语句终止当前正在执行的函数并将控制权返回到调用该函数的地方。 return语句有两种形式 return;return expression; 无返回值函数 没有返回值的return语句只能用在返回类型是void的函数中。 返回void的函数不要求必须有return语句,因为这类函数的最后一句…...

[linux] Key is stored in legacy trusted.gpg keyring
修复 Ubuntu 中的 “Key is stored in legacy trusted.gpg keyring” 问题_key is stored in legacy trusted.gpg keyring (/etc/-CSDN博客 复制到trusted.gpd.d 目录中(快速但不优雅的方法) 如果你觉得手动做上面的事情不舒服,那么,你可以忽略这个警告…...

阿里云部署OneApi
基于 Docker 进行部署 # 使用 SQLite 的部署命令: docker run --name one-api -d --restart always -p 3000:3000 -e TZAsia/Shanghai -v /home/ubuntu/data/one-api:/data justsong/one-api # 使用 MySQL 的部署命令,在上面的基础上添加 -e SQL_DSN&qu…...
MapReduce学习问题记录
1、如何跳过对某行数据的处理 第一行数据是字段名不需要处理,我们知道第一行偏移量是0(行记录的时候是从数组首地址开始,到了行标识符进行一次计数,这个计数就是行偏移量,从0开始),我们根据偏移…...

Elasticsearch优化
集群配置 1、调整副本数:考虑数据的可用性和读取性能,合理配置分片的副本数。 2、合理配置分片大小(分片的合理容量:10GB-50GB):避免分片过大,以确保更好的性能和均衡的负载。 3、监控集群状态:使用监控工…...
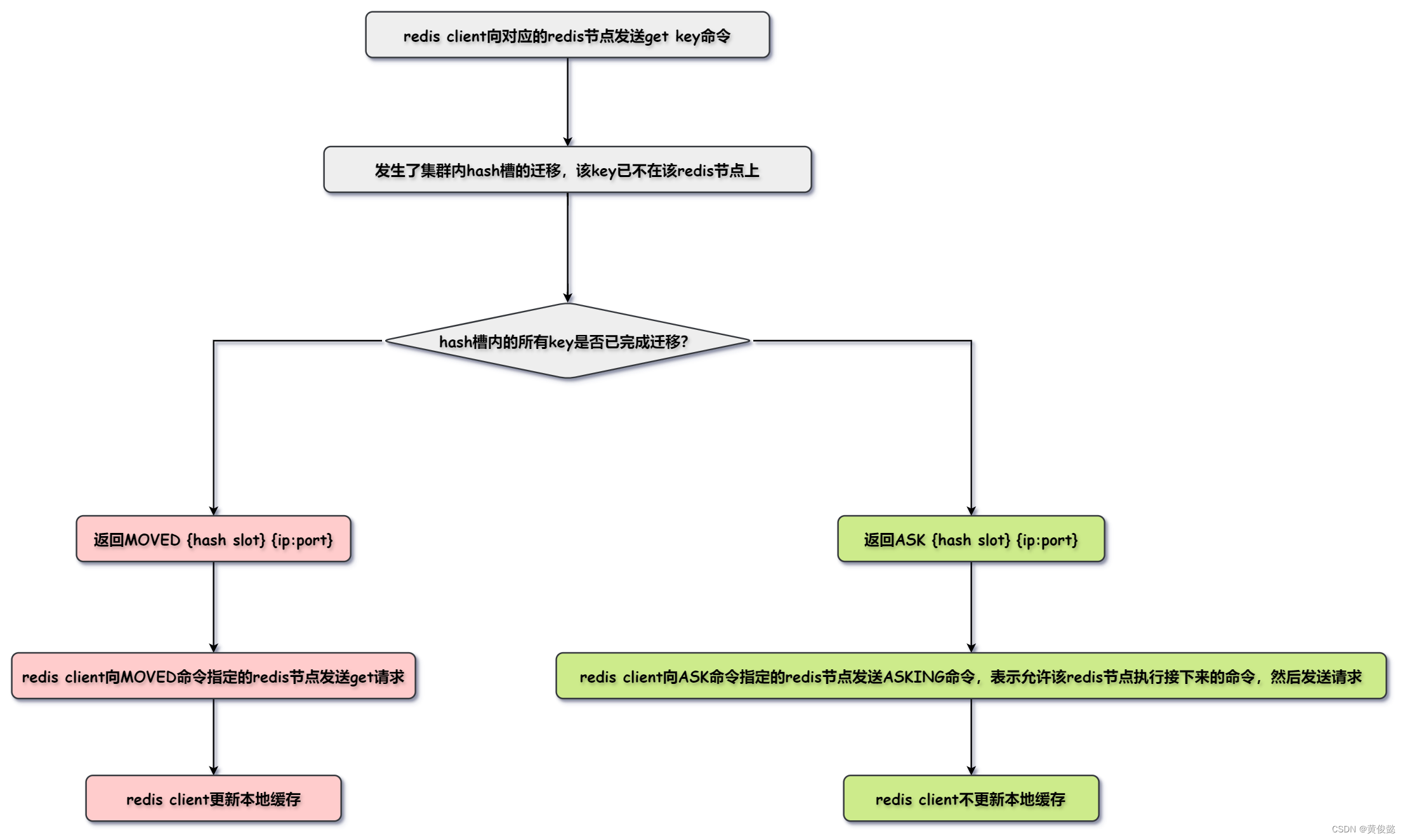
【Redis知识点总结】(六)——主从同步、哨兵模式、集群
Redis知识点总结(六)——主从同步、哨兵模式、集群 主从同步哨兵集群 主从同步 redis的主从同步,一般是一个主节点,加上多个从节点。只有主节点可以接收写命令,主节点接收到的写命令,会同步给从节点&#…...

Java面试题:设计一个线程安全的单例模式,并解释其内存占用和垃圾回收机制;使用生产者消费者模式实现一个并发安全的队列;设计一个支持高并发的分布式锁
Java深度面试题:设计模式、内存管理与并发编程的综合考察 随着Java技术的不断发展,对Java开发者的技术要求也在不断提高。设计模式、内存管理、多线程工具类以及并发工具包和框架等都是Java开发者必须掌握的核心知识点。本文将通过三道综合性的面试题&a…...

【硬件设计】以立创EDA举例——持续更新
【硬件设计】以立创EDA举例——持续更新 文章目录 前言立创EDA官网教程一、原理图二、PCB1.布局2.设计规则3.电流与线宽 4.PCB走线5.Polar Si90006.过孔7.铺铜总结 前言 提示:以下是本篇文章正文内容,下面案例可供参考 立创EDA官网教程 立创EDA使用教程…...

Chain of Note-CoN增强检索增强型语言模型的鲁棒性
Enhancing Robustness in Retrieval-Augmented Language Models 检索增强型语言模型(RALMs)在大型语言模型的能力上取得了重大进步,特别是在利用外部知识源减少事实性幻觉方面。然而,检索到的信息的可靠性并不总是有保证的。检索…...

Uniapp 的 uni.request传参后端
以下是使用Uniapp的交互数据的两种方式 后端使用Parameter接收数据 后端使用RequestBody接收Json格式数据 后端: CrossOrigin RestController RequestMapping("/user") public class UserController {GetMapping("/login")public String lo…...
数据可视化-ECharts Html项目实战(5)
在之前的文章中,我们学习了如何设置滚动图例,工具箱设置和插入图片。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢 数据可视化-ECharts…...

Godot PCK解包原理与专业逆向实践指南
1. 这不是“解压软件”,而是Godot游戏逆向工程的第一把手术刀你刚下载了一款用Godot引擎开发的独立游戏,想研究它的UI动效逻辑,或者复刻一段粒子特效,又或者只是单纯好奇——那个让你反复通关三次的像素风过场动画,图层…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

机器学习与SHAP在教育公平研究中的应用:精准定位学业困境根源
1. 项目概述:当机器学习遇见教育公平,我们如何精准定位学业困境的根源?在拉丁美洲的教育研究领域,一个长期困扰政策制定者和研究者的核心问题是:究竟是什么因素,在复杂的社会经济背景下,系统性地…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

DragonBones与Godot集成:骨骼动画的可编程化实践
1. 为什么在Godot里用DragonBones不是“锦上添花”,而是“绕不开的刚需” 去年上线一个横版动作手游Demo时,美术团队交来一套20个角色、每个角色含8套动画(待机/跑动/跳跃/攻击/受击/死亡/闪避/必杀)的Spine资源。我兴冲冲导入God…...

AI圈内火热的Agent、MCP、Skill、CLI是啥?用装修房子讲透,看完秒懂
本文用装修房子的比喻,详细解释了AI领域的四个核心概念:Agent如同会自主规划任务的私人助理;MCP是AI与外部工具数据的统一接口,类似USB-C;Skill是指导AI按标准操作执行的手册;CLI则是不依赖图形界面的命令行…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...