Go——map操作及原理
一.map介绍和使用
map是一种无序的基于key-value的数据结构,Go语言的map是引用类型,必须初始化才可以使用。
1. 定义
Go语言中,map类型语法如下:
map[KeyType]ValueType- KeyType表示键类型
- ValueType表示值类型
map类型的变量默认初始值为nil,需要使用make函数来分配内存。语法为:
make(map[KeyType]ValueType, [cap])map[KeyType]ValueType{} //底层也是使用的makemap[KeyType]Value{ //底层也是使用的makekey:value,key:value,...
}其中cap表示map的容量,该参数虽然不是必须的,但是我们应该在初始化map的时候就为其指定一个合适的容量。
可以使用len()内置函数来获取map键值对的个数。
注意:map保存的键值对中,键不能被修改,只能修改值。
2.基本使用
package mainimport "fmt"func main() {scoreMap := make(map[string]int, 8)scoreMap["张三"] = 100scoreMap["小明"] = 90fmt.Println(scoreMap)fmt.Printf("key num is %d\n", len(scoreMap))fmt.Println(scoreMap["小明"])fmt.Printf("type(scoreMap)=%T\n", scoreMap)
}
map也支持在声明时填充元素:
package mainimport "fmt"func main() {userInfo := map[string]string{"username": "zhansan","password": "123456",}fmt.Println(userInfo)
}3. 判断某个键是否存在
Go语言中有个判断map中的键是否存在的特殊写法:
value, ok := map[key]例子:
package mainimport "fmt"func main() {userInfo := map[string]string{"username": "zhansan","passward": "123456",}value, ok := userInfo["passward"]if ok {fmt.Println(value)} else {fmt.Println("passward is not exit")}value, ok = userInfo["sex"]if ok {fmt.Println(value)} else {fmt.Println("sex is not exit")}
}
4. map的遍历
遍历key和value:
package mainimport "fmt"func main() {scoreMap := make(map[string]int, 8)scoreMap["小明"] = 100scoreMap["张三"] = 80scoreMap["李四"] = 60for key, value := range scoreMap {fmt.Printf("scoreMap[%s] = %d\n", key, value)}
}
只遍历key:

注意:遍历map时的元素顺序与添加键值对的顺序无关。
5. 删除键值对
使用delete()内置函数从map中删除一组键值对,格式如下:
delete(map, key)//map:为需要删除键值对的map
//key:表示要删除键值对的键package mainimport "fmt"func main() {scoreMap := make(map[string]int, 8)scoreMap["小明"] = 100scoreMap["张三"] = 80scoreMap["李四"] = 60value, ok := scoreMap["李四"]if ok {fmt.Println(value)} else {fmt.Println("李四 is not exit")}//删除键值对delete(scoreMap, "李四")value, ok = scoreMap["李四"]if ok {fmt.Println(value)} else {fmt.Println("李四 is not exit")}
}
6. 按照指定顺序遍历map
实际时先获取到所有的键,将键设置成指定顺序,再通过键来遍历map。
package mainimport ("fmt""math/rand""sort""time"
)func main() {rand.Seed(time.Now().UnixNano()) //初始化随机种子scoreMap := make(map[string]int, 200)for i := 0; i < 100; i++ {key := fmt.Sprintf("stu%02d", i)scoreMap[key] = rand.Intn(100) //获取0-100的随机数//fmt.Println(key, scoreMap[key])}keys := make([]string, 0, 200)//保存key//按照排序后的key遍历scoreMapfor key := range scoreMap {keys = append(keys, key)}//fmt.Println(keys)sort.Strings(keys) //对keys进行排序for _, key := range keys {fmt.Printf("scoreMap[%s] = %d\n", key, scoreMap[key])}
}7. 元素为map类型的切片
package mainimport "fmt"func main() {mapSlice := make([]map[string]string, 3, 10) //并没有为map分配地址空间for index, val := range mapSlice {fmt.Printf("mapSlice[%d] = %v\n", index, val)}//分配地址空间for index, _ := range mapSlice {mapSlice[index] = make(map[string]string, 10)}fmt.Println("---------插入键值对后---------")//插入键值对mapSlice[0]["name"] = "张三"mapSlice[0]["passwd"] = "123123"mapSlice[1]["name"] = "李四"mapSlice[1]["passwd"] = "321321"mm := map[string]string{"name": "小明","passwd": "123465",}mapSlice = append(mapSlice, mm)for index, val := range mapSlice {fmt.Printf("mapSlice[%d] = %v\n", index, val)}
}
8. 值为切片类型的map
package mainimport "fmt"func main() {sliceMap := make(map[string][]string, 10) //没有为slice分配空间sliceMap["中国"] = make([]string, 0, 10)sliceMap["中国"] = append(sliceMap["中国"], "北京", "上海", "长沙")key := "美国"value, ok := sliceMap[key]if !ok {value = make([]string, 0)}value = append(value, "芝加哥", "华盛顿")sliceMap[key] = valuefor key, val := range sliceMap {fmt.Printf("sliceMap[%s] = %v\n", key, val)}
}
二.map底层原理
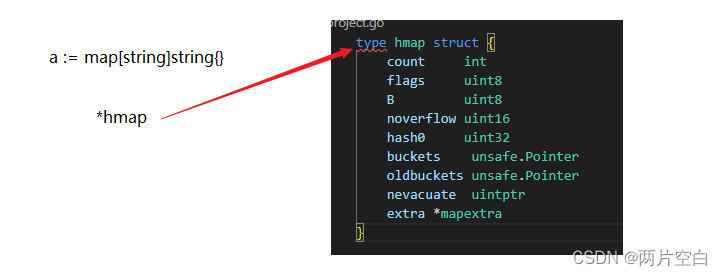
Go语言的map底层数据结构为哈希表(散列表),但是与C++的哈希表实现不同。想要了解Go语言map的底层实现,需要先了解两个重要的数据结构 hmap和bmap。
2.1 map头部数据结构——hmap
hmap中有几个重要的属性:
- count:记录了map中实际元素的个数
- B:控制哈希桶的个数为2^B个
- buckets:是一个指向长度为2^B大小的类型为bmap的数组
- oldbuckets:与buckets一样也是指向一个多桶的数组,不同的是oldbuckets指向的是旧桶的地址,当oldbuckets不为空时,表示map正处于扩容阶段。
type hmap struct {// map中元素的个数,使用len返回就是该值count int// 状态标记// 1: 迭代器正在操作buckets// 2: 迭代器正在操作oldbuckets // 4: go协程正在像map中写操作// 8: 当前的map正在增长,并且增长的大小和原来一样flags uint8// buckets桶的个数为2^BB uint8 // 溢出桶的个数noverflow uint16 // key计算hash时的hash种子hash0 uint32// 指向的是桶的地址buckets unsafe.Pointer// 旧桶的地址,当map处于扩容时旧桶才不为niloldbuckets unsafe.Pointer //扩容之后数据迁移的计数器,记录下次迁移的位置,当nevacuate>旧桶元素个数,数据迁移完nevacuate uintptr // 额外的map字段,存储溢出桶信息// 这个字段是为了优化GC扫描而设计的。当key和value均不包含指针,并且都可以inline时使用。extra是指向mapextra类型的指针。extra *mapextra
}创建一个map实际是创建一个指针,指向hmap结构。
mapextra结构:
如果一个哈希表要分配桶的数目大于2^4个,就认为使用溢出桶的几率比较大,就会预分配2^(B-4)个溢出桶备用,这些溢出桶与常规桶内存中是连续的,只是前2^B个作为常规桶。
type mapextra struct {// 如果 key 和 value 都不包含指针,并且可以被 inline(<=128 字节)// 就使用 hmap的extra字段 来存储 overflow buckets,这样可以避免 GC 扫描整个 map// 然而 bmap.overflow 也是个指针。这时候我们只能把这些 overflow 的指针// 都放在 hmap.extra.overflow 和 hmap.extra.oldoverflow 中了// overflow 包含的是 hmap.buckets 的 overflow 的 buckets// oldoverflow 包含扩容时的 hmap.oldbuckets 的 overflow 的 bucketoverflow *[]*bmap //记录已使用的溢出桶的地址oldoverflow *[]*bmap //扩容阶段旧桶使用的溢出桶地址// 指向空闲的 overflow bucket 的指针nextOverflow *bmap //指向下一个空闲溢出桶
}2.2 bmap
bmap是每一个桶的数据结构,每一个bmap包含8个key和value。
type bmap struct {tophash [bucketCnt]uint8 // len为8的数组,用来快速定位key是否在这个bmap中// 一个桶最多8个槽位,如果key所在的tophash值在tophash中,则代表该key在这个桶中
}上面是bmap的静态结构,在编译过程中runtime.bmap会扩展成以下结构:
- topbits :用来快速定位桶中键值对的位置。
- keys:键值对的键
- values:键值对的值
- overflow:当8个key满的时候,需要新创建一个桶,overflow保存下一个桶的地址。
细节:
这里将键和键保存到了一起,值和值保存在了一起,为什么不讲键和值保存在一起?
因为键和值的类型可能不同,结构体内存对齐会浪费空间。
type bmap struct{topbits [8]uint8keys [8]keytypevalues [8]valuetypepad uintptr // 内存对齐使用,可能不需要overflow uintptr // 当bucket 的8个key 存满了之后// overflow 指向下一个溢出桶 bmap,// overflow是uintptr而不是*bmap类型,保证bmap完全不含指针,是为了减少gc,溢出桶存储到extra字段中
}
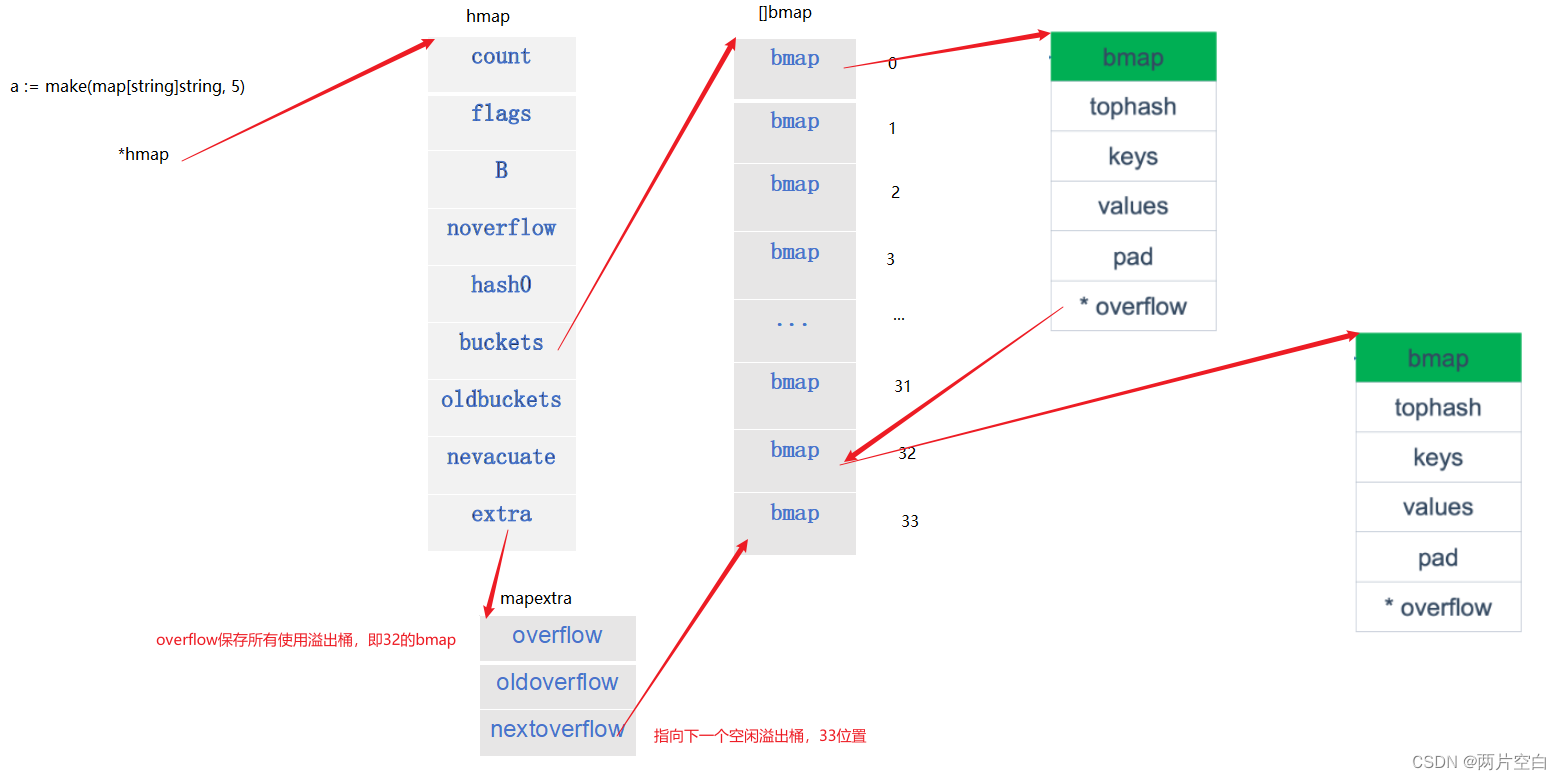
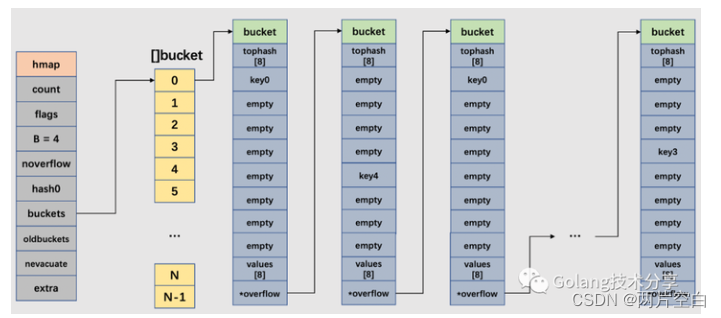
2.3 整体结构示意图
- 如下图,创建一个容量为5的map,此时B=5,分配桶数为2^5=32个(为[]bmap下标0-31),则备用溢出桶数为2^(5-4)=2个(为[]bmap下标32,33)。
- 此时,0号的bmap桶满了,overflow指向下一个溢出桶地址,即[]bmap下标为32位置。
- hmap中的noverflow表示使用溢出桶数量,这里为1,extra字段记录溢出桶mapextra结构体。
- mapextra中的overflow保存使用的溢出桶,nextoverflow指向下一个空闲溢出桶33号。
创建一个map,Go语言底层实际调用的是makemap函数,主要做的工作就是初始化hmap结构体的各个字段。比如:计算B的大小,设置哈希种子hash0,给buckets分配内存等。
func makemap(t *maptype, hint int, h *hmap) *hmap {//计算内存空间和判断是否内存溢出mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)if overflow || mem > maxAlloc {hint = 0}// initialize Hmapif h == nil {h = new(hmap)}h.hash0 = fastrand()//计算出指数B,那么桶的数量表示2^BB := uint8(0)for overLoadFactor(hint, B) {B++}h.B = Bif h.B != 0 {var nextOverflow *bmap//根据B去创建对应的桶和溢出桶h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)if nextOverflow != nil {h.extra = new(mapextra)h.extra.nextOverflow = nextOverflow}}return h
}
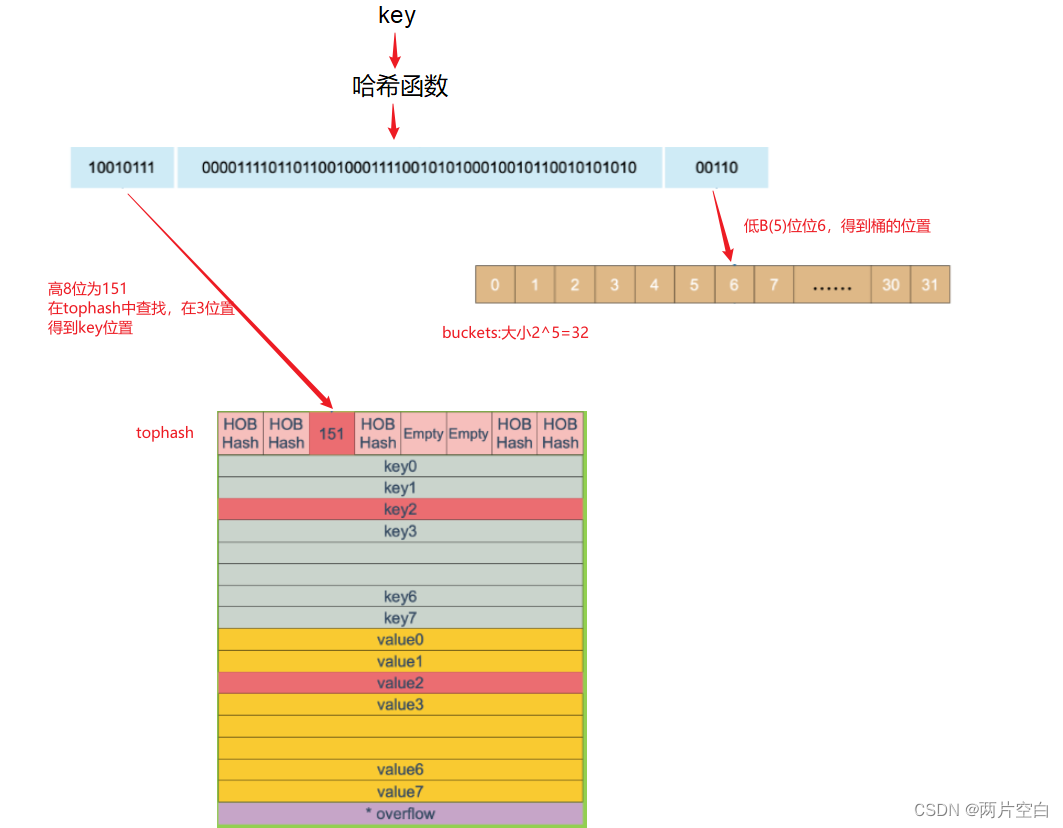
2.4 key定位原理
key通过哈希计算后得到哈希值,哈希值的低B位用于确定桶,哈希值的高8位,用于在一个独立的桶中找到键的位置。
例子:
当在6号buckets中每有找到对应的tophash,并且overflow不为空,还需要继续到overflow指向的buckets中的tophash中查找,直到找到或者所有的key槽位都找遍,包括该buckets下的所有溢出桶(overflow)。
2.5 插入元素
- 插入
key通过哈希函数得到哈希值,通过低B位确定桶位置,在桶中按顺序找空位置,找到后,将高8位保存在tophash中,key和value保存到keys和values中。如果当前桶中没有空闲位置,查看是否有溢出桶,有的话,在溢出桶中找空位置保存。没有溢出桶,添加溢出桶,将数据保存到第一个空位置。
- 哈希冲突
当两个不同的key键通过哈希函数落到了同一个桶中,这时就发生了哈希冲突。
Go语言的解决办法是链地址法:由于桶(bmap)的数据结构,一个桶保存8个键和值。在桶中按顺序寻找第一个空位,若有空位,则将其置于其中;若没有空位,判断是否有溢出桶;若有溢出桶,在溢出桶中寻找空位。若没有溢出桶,则添加溢出桶,并将其置于溢出桶的第一个空位(非扩容的情况)。
当不同的key通过哈希函数得到的哈希值相同时,低位和高位都相同,如何查找到对应的键值对?
步骤和上面相同,低B为找到对应的桶,高8位找到对应的tophash位置,拿出key与要找的key比较是否相同,相同的话取出,不同的话,再在tophash中查找哈希值高8位的值,没找到,在溢出桶中找,直到找完所有key或者找到对应的key为止。
2.6 扩容
为什么要进行扩容:
当元素越来越多或者溢出桶的数量越来越多,导致查找的效率会变低。
2.6.1 负载因子
负载因子是决定哈希表是否进行扩容的关键指标。负载因子的值为6.5(经验所得),意思是平均每个桶中键值对的数量。当 总键值对个数 >= 桶总数 * 6.5,这个时候说明大部分的桶可能快满了。这个时候就可能需要扩容。
2.6.2 扩容的条件
扩容的条件有两个:
- 判断负载因子是否达到临界点(6.5),如果达到了,如果插入新的元素,大概率会需要挂在溢出桶上了。
- 判断溢出桶是否过多,当正常桶总数< 2^15时,如果溢出桶总数>=正常桶总数,则认为溢出桶过多。当正常桶总数>=2^15时,直接与2^15比较,当溢出桶总数>=2^15时,则认为溢出桶总数过多。
其实第二点是对第一点的补充。因为在负载因子比较小的情况下,有可能map的查找和插入的效率也可能很低。即map里的元素少,但是桶数量多(真实分配的桶数量多,包括大量的溢出桶)。
导致上面这种情况的原因是:对map中的元素不断的增删,增加会导致桶的数量变多,删除导致负载因子不高。
这样导致桶的使用率不高,存储的值比较稀疏,导致查找的效率变低。
2.6.3 解决方案
-
针对超过负载因子的情况:将B+1,新建一个buckets数组,新的buckets大小是原来的2倍,然后将旧buckets数据搬迁到新的buckets。该方法我们称之为增量扩容。
-
针对桶数量过多的情况:并不扩大容量,buckets数量维持不变,重新做一遍类似增量扩容的操作,就是将键值对重新映射到新buckets中,使得buckets的使用率变高。该方法我们称为等量扩容。
对于等量扩容,其实存在一种极端情况:如果插入map的key通过哈希函数后得到的哈希值一样,那它们就会落到同一个buckets中,查过8个就会产生overflow,结果也会照成溢出桶过多,移动元素其实解决不了问题,此时哈希表退化成了一个链表,操作效率编程了O(n),但Go的每一个map都会在初始阶段的makemap是定义一个随机哈希种子,所以要构成这种冲突是没有那么容易的。
扩容:首先分配新的buckets(不管增量扩容还是等量扩容都要新分配buckets),将老的buckets挂到oldbuckets字段上。buckes挂上新的buckets。然后将oldbuckets上的键值对重新哈希到buckets上,直到旧桶中的键值对全部搬迁完毕后,删除oldbuckets。 当oldbuckets值为nil表示扩容完毕。
2.6.4 渐进式扩容
由于map扩容需要使用将原有的键值对重新搬迁到新的内存地址,如果map储存了数以亿计的键值对,一次性搬迁会照成比较大的延时。因此Go语言map扩容采取了一种渐进式的方式。
原有的key不会一次性搬迁完毕,每次最多搬迁2个buckets,并且只有在插入,修改或删除key的时候,才会进行搬迁buckets工作。
参考文档:深入解析Golang的map设计 - 知乎
相关文章:
Go——map操作及原理
一.map介绍和使用 map是一种无序的基于key-value的数据结构,Go语言的map是引用类型,必须初始化才可以使用。 1. 定义 Go语言中,map类型语法如下: map[KeyType]ValueType KeyType表示键类型ValueType表示值类型 map类型的变量默认…...
网络安全实训Day9
写在前面 访问控制和防火墙桌面端安全检测与防御 网络安全实训-网络安全技术 网络安全概述 访问控制 定义:通过定义策略和规则来限制哪些流量能经过防火墙,哪些流量不能通过。本质是包过滤 可以匹配的元素 IP协议版本 源区域和目的区域 源IP地址和目…...
之虚拟机centos搭建k8s集群)
kubernetes实战(1)之虚拟机centos搭建k8s集群
一,环境准备 centos7系统,每个系统2c2g,40g,centos7下载地址:centos-7.9.2009-isos-x86_64安装包下载_开源镜像站-阿里云 # 每个节点分别设置对应主机名 hostnamectl set-hostname master hostnamectl set-hostname …...
基于python+vue分类信息服务平台移动端的设计与实现flask-django-php-nodejs
分类信息服务平台是在Android操作系统下的应用平台。为防止出现兼容性及稳定性问题,框架选择的是django,Android与后台服务端之间的数据存储主要通过MySQL。用户在使用应用时产生的数据通过 python等语言传递给数据库。通过此方式促进分类信息服务平台信…...
【蓝牙协议栈】【BLE】低功耗蓝牙配对绑定过程分析(超详细)
1. 精讲蓝牙协议栈(Bluetooth Stack):SPP/A2DP/AVRCP/HFP/PBAP/IAP2/HID/MAP/OPP/PAN/GATTC/GATTS/HOGP等协议理论 2. 欢迎大家关注和订阅,【蓝牙协议栈】和【Android Bluetooth Stack】专栏会持续更新中.....敬请期待!…...
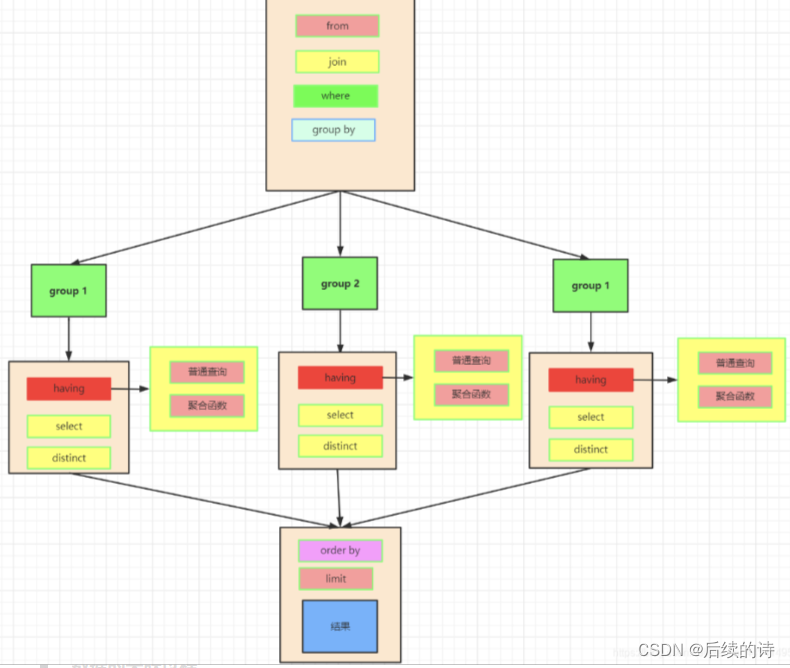
MySQL表内容的增删查改
在前面几章的内容中我们学习了数据库的增删查改,表的增删查改,这一篇我们来学习一下对表中的内容做增删查改。 CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除) 1.创建Create 我们先创建…...

Java的三大特性之一——多态(完)
前言 http://t.csdnimg.cn/0CAuc 在上一篇我们已经详讲了继承特性,在这我们将进行最后一个也是最重要的特性讲解——多态 在讲解之前我们需要具备对向上转型以及方法重写的初步了解,这有助于我们对多态的认识 1.向上转型 即实际就是创建一个子类对象…...
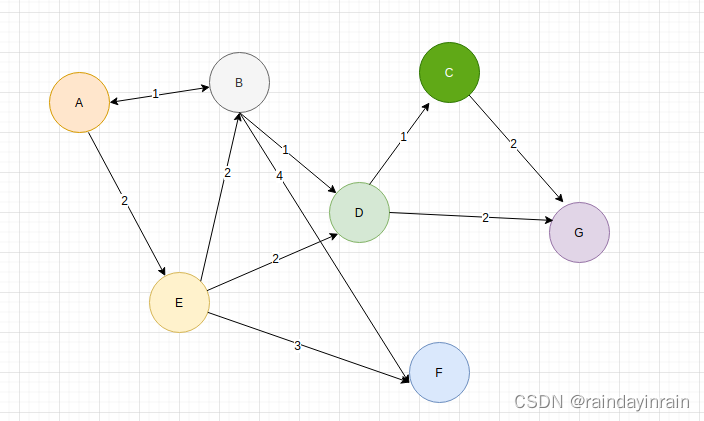
算法-最短路径
图的最短路径问题是一个经典的计算机科学和运筹学问题,旨在找到图中两个顶点之间的最短路径。这种问题在多种场景中都有应用,如网络路由、地图导航等。 解决图的最短路径问题有多种算法,其中最著名的包括: 1.迪杰斯特拉算法 (1).…...
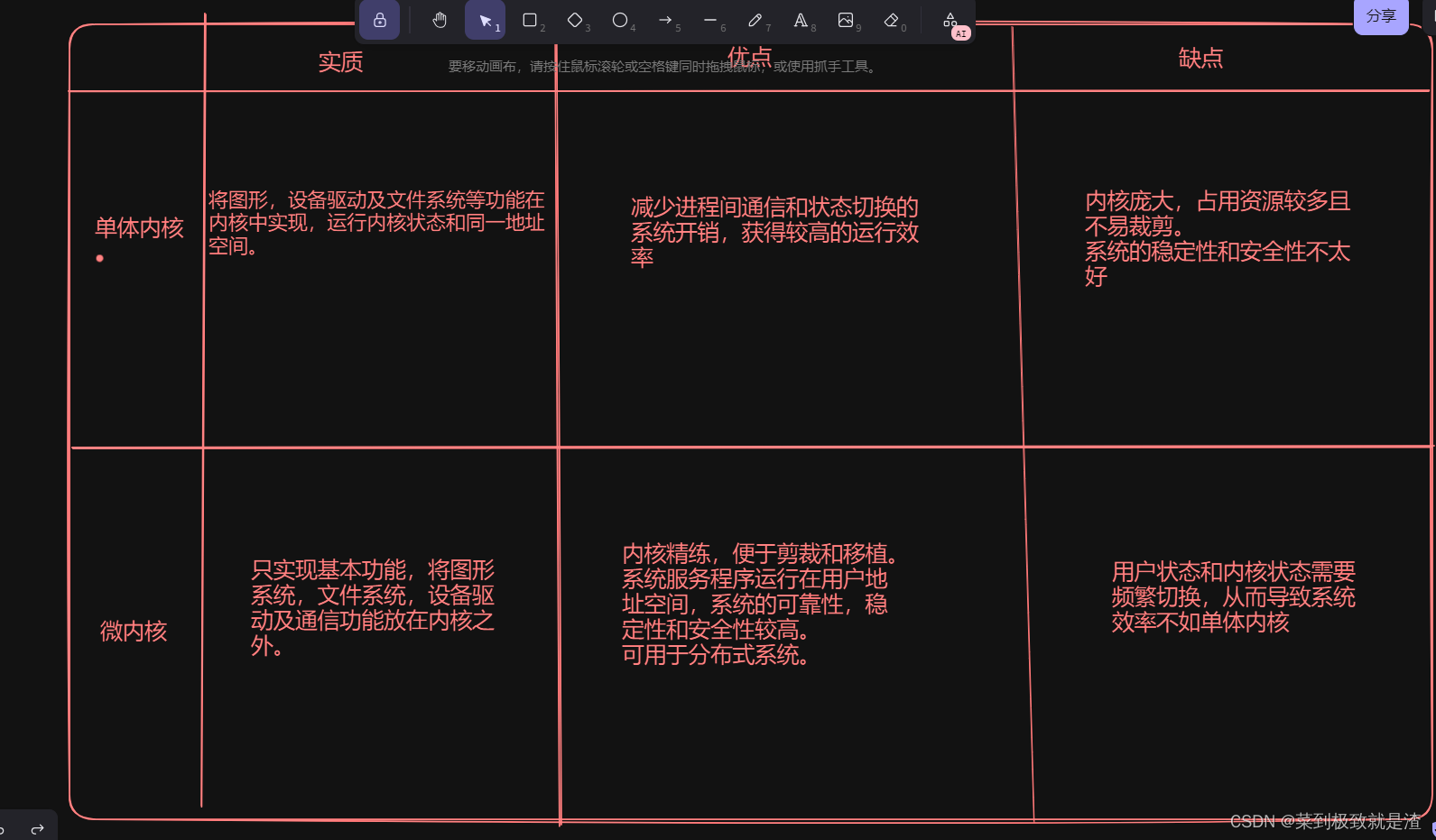
【软考---系统架构设计师】特殊的操作系统介绍
目录 一、嵌入式系统(EOS) (1)嵌入式系统的特点 (2)硬件抽象层 (3)嵌入式系统的开发设计 二、实时操作系统(RTOS) (1)实时性能…...
)
大模型: 提示词工程(prompt engineering)
文章目录 一、什么是提示词工程二、提示词应用1、提示技巧一:表达清晰2、提示词技巧2:设置角色 一、什么是提示词工程 提示词工程主要是用于优化与大模型交互的提示或查询操作,其目的在于能够更加准确的获取提问者想要获取的答案,…...

RabbitMQ的事务机制
想要保证发送者一定能把消息发送给RabbitMQ,一种是通过Confirm机制,另一种就是通过事务机制。 RabbitMQ的事务机制,允许生产者将一组操作打包成一个原子事务单元,要么全部执行成功,要么全部失败。事务提供了一种确保消…...
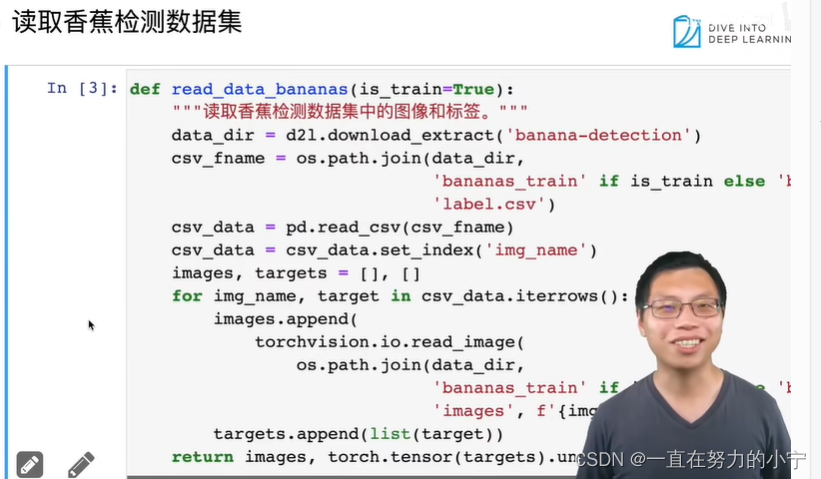
41 物体检测和目标检测数据集【李沐动手学深度学习v2课程笔记】
目录 1. 物体检测 2. 边缘框实现 3.数据集 4. 小结 1. 物体检测 2. 边缘框实现 %matplotlib inline import torch from d2l import torch as d2ld2l.set_figsize() img d2l.plt.imread(../img/catdog.jpg) d2l.plt.imshow(img);#save def box_corner_to_center(boxes):&q…...
)
软件包管理(rpm+yum)
1.介绍软件包安装方式 rpm包安装: rpm是个软件包管理工具,通过.rpm后缀来操作 -i #安装 -q #查询 -l #列出软件包下的文件 -e #卸载 -h, #软件包安装的时候列出哈希标记 (和 -v 一起使用效果更好) -v, #提供更多的详细信息输出 rpm的痛点&#…...

网关层针对各微服务动态修改Ribbon路由策略
目录 一、介绍 二、常规的微服务设置路由算法方式 三、通过不懈努力,找到解决思路 四、验证 五、总结 一、介绍 最近,遇到这么一个需求: 1、需要在网关层(目前使用zuul)为某一个服务指定自定义算法IP Hash路由策…...
)
如何从零开始拆解uni-app开发的vue项目(二)
昨天书写了一篇如何从零开始uni-app开发的vue项目,今天准备写一篇处理界面元素动态加载的案例: 背景:有不同类别的设备,每个设备有每日检查项目、每周检查项目、每年检查项目,需要维保人员,根据不同设备和检查类别对检查项目进行处理,提交数据。 首先看一下界面: &l…...
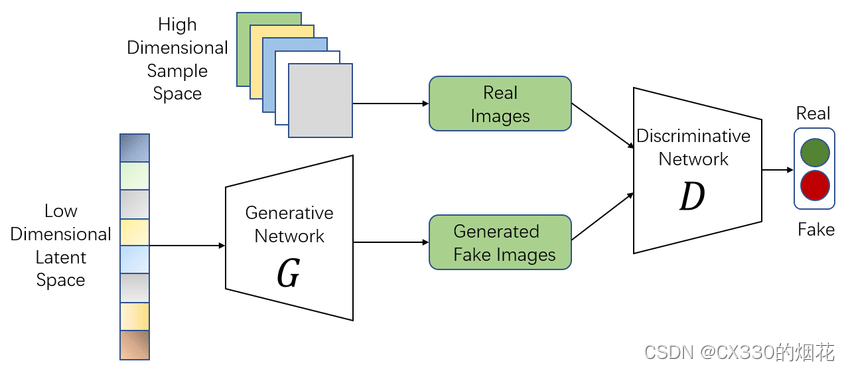
【生成对抗网络GAN】一篇文章讲透~
目录 引言 一、生成对抗网络的基本原理 1 初始化生成器和判别器 2 训练判别器 3 训练生成器 4 交替训练 5 评估和调整 二、生成对抗网络的应用领域 1 图像生成与编辑 2 语音合成与音频处理 3 文本生成与对话系统 4 数据增强与隐私保护 三、代码事例 四、生成对抗…...

【设计模式】Java 设计模式之模板命令模式(Command)
命令模式(Command)的深入分析与实战解读 一、概述 命令模式是一种将请求封装为对象从而使你可用不同的请求把客户端与接受请求的对象解耦的模式。在命令模式中,命令对象使得发送者与接收者之间解耦,发送者通过命令对象来执行请求…...

如何在Flutter中实现一键登录
获取到当前手机使用的手机卡号,直接使用这个号码进行注册、登录,这就是一键登录。 可以借助极光官方的极光认证实现 1、注册账户成为开发者 2、创建应用开通极光认证 (注意开通极光认证要通过实名审核) 3、创建应用获取appkey、 …...

Amazon SageMaker + Stable Diffusion 搭建文本生成图像模型
如果我们的计算机视觉系统要真正理解视觉世界,它们不仅必须能够识别图像,而且必须能够生成图像。文本到图像的 AI 模型仅根据简单的文字输入就可以生成图像。 近两年,以ChatGPT为代表的AIGC技术崭露头角,逐渐从学术研究的象牙塔迈…...

FPGA数字信号处理前沿
生活在这个色彩斑斓的世界里,大家的身边存在太多模拟信号比如光能、电压、电流、压力、声音、流速等。数字信号处理作为嵌入式研发的一个经久不衰热门话题,可以说大到军工武器、航空航天,小到日常仪器、工业控制,嵌入式SOC芯片数字…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

Windows文件夹共享
目标:同一局域网实现在一台计算机上共享文件夹,在另一台电脑访问一、电脑A 1.点击要共享的文件夹 -> 属性 -> 共享2.添加Everyone用户组3.控制面板中网络共享关闭密码保存,在访问时不用输入账号密码。二、电脑B 1.在文件资源管理器路径…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对?
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

树莓派工业GPIO接口板:电气隔离与电平转换实战指南
1. 项目概述:为什么需要一块工业级GPIO接口板?如果你用树莓派做过一些硬件项目,尤其是涉及到控制继电器、电机或者连接工业设备(比如PLC、变频器)时,大概率踩过这样的坑:直接用树莓派的GPIO引脚…...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...

Lovable电商网站搭建:如何用不到3人技术团队,72小时内上线PCI-DSS合规MVP版本?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署能力。本章将指导你从零开始搭建一个具备商品展示、…...