7.Java并发编程—掌握线程池的标准创建方式和优雅关闭技巧,提升任务调度效率
文章目录
- 线程池的标准创建方式
- 线程池参数
- 1.核心线程(corePoolSize)
- 2.最大线程数(maximumPoolSize)
- 3.阻塞队列(BlockingQueue)
- 向线程提交任务的两种方式
- 1.execute()
- 1.1.案例-execute()向线程池提交任务
- 2.submit()
- 2.1.submit(Callable<T> task)
- 2.2.案例-submit()向线程池提交任务
- 3.execute,submit对比
- 线程池的任务调度流程
- ThreadFactory
- 1.ThreadFactory源码
- 2.自定义简单线程工厂
- 3.defaultThreadFactory
- 任务阻塞队列
- 线程池的拒绝策略
- 优雅关闭线程池
- 1.(限时)等待线程池正在执行任务
- 2.等待队列任务全部执行完毕
- 3.测试两种关闭线程池方法
- 3.1.自定义Task任务
- 3.2.测试主类
- **测试限时等待,关闭线程池**
- **测试等待全部任务执行完毕,关系线程池**
线程池的标准创建方式
在企业开发中,大部分公司是禁止使用
快捷线程池,要求通过标准的构造器ThreadPoolExecutor去构造线程池。Executors创建线程池,其实也是通过构造ThreadPoolExecutor来完成的,只不过构造的相关参数是固定不变的。
ThraedPoolExecutor有多个重载的版本,我们下面来看一个比较重要的构造方法
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {// 校验输入参数是否合法if (corePoolSize < 0 || // 核心线程池大小不能小于0maximumPoolSize <= 0 || // 最大线程池大小必须大于0maximumPoolSize < corePoolSize || // 最大线程池大小不能小于核心线程池大小keepAliveTime < 0) // 非核心线程的空闲时间不能为负值throw new IllegalArgumentException();// 校验传入的对象参数是否为空if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();// 获取当前安全管理器的访问控制上下文this.acc = System.getSecurityManager() == null ?null :AccessController.getContext();// 设置核心线程池大小this.corePoolSize = corePoolSize;// 设置最大线程池大小this.maximumPoolSize = maximumPoolSize;// 设置任务阻塞队列,用于保存待执行的任务this.workQueue = workQueue;// 将传入的时间单位转换为纳秒,并将非核心线程的空闲时间设置为转换后的值this.keepAliveTime = unit.toNanos(keepAliveTime);// 设置用于创建新线程的线程工厂this.threadFactory = threadFactory;// 设置拒绝执行处理器,用于处理无法执行的任务this.handler = handler;
}
oh,原来构造一个线程池需要这么多的参数,虽然有点多,但是不要慌,下面我们就来一个一个了解这些的参数的意义!
线程池参数
1.核心线程(corePoolSize)
核心线程其实是线程池中固定数量的线程,它们一直存在不会被销毁,并且可以立即执行新任务。这种设计有助于减少线程创建和销毁的开销,提高响应速度。
2.最大线程数(maximumPoolSize)
最大线程数(maximumPoolSize)是线程池中允许存在的最大线程数量。它是线程池的一个重要参数,用于控制线程池的大小和并发处理能力。
- 当线程池接收到新的任务时,以下步骤可能会发生:
- 如果当前工作线程数目
小于核心线程数(corePoolSize),则创建一个新的核心线程来处理该任务。 - 如果当前工作线程数目已
达到核心线程数,并且任务队列未满,则将任务添加到任务队列中等待执行。 - 如果当前工作线程数目已
达到核心线程数,并且任务队列已满,但是总工作线程数目(包括核心线程和非核心线程)未达到最大线程数(maximumPoolSize),则创建一个新的非核心线程来处理该任务。 - 如果当前工作线程数目
已达到最大线程数,且任务队列已满,则根据线程池的拒绝策略来处理该任务,例如抛出异常或者执行其他自定义的处理逻辑。
- 如果当前工作线程数目
- 如果当前工作线程数目多于
核心线程数(corePoolSize),空闲的工作线程可能会根据一定的条件自动销毁,以减少资源占用。这可以根据线程池的实现策略来确定,例如线程空闲时间超过一定阈值等。 - 如果将
最大线程数(maximumPoolSize)设置为无界值(例如设置为整数的最大值),则线程池可以无限制地创建新的线程来处理任务,直到达到系统的资源限制为止。这种情况下,最大线程数不再起到限制线程数量的作用。 最大线程数(maximumPoolSize)和核心线程数(corePoolSize)可以在线程池创建后通过调用setCorePoolSize()和setMaximumPoolSize()进行动态设置。这允许根据实际需求进行线程池大小的调整,以适应不同的场景和负载。
3.阻塞队列(BlockingQueue)
阻塞队列(BlockingQueue)是一种特殊类型的队列,它在元素插入或者移除时提供了阻塞的操作。阻塞队列主要用于在多线程环境下进行线程间的安全、高效的数据传输和协作。阻塞队列的特点是当
队列为空时,试图从队列中获取元素的操作将被阻塞,直到队列中有可用元素;当队列已满时,试图向队列中插入元素的操作将被阻塞,直到队列有空闲位置。
BlockingQueue的实例用于暂时接收异步任务,如果线程池的核心线程都在执行任务,那么所接收到任务都是放在阻塞队列中的。
向线程提交任务的两种方式
向线程池提交任务的方式有两种
- 使用execute方法:
execute()方法用于提交不需要返回结果的任务- 使用submit方法:
submit()方法用于提交需要返回结果的任务
1.execute()
execute()方法是Executor接口的一个方法,用于向线程池提交一个不需要返回结果的任务。它的作用是将任务提交给线程池来执行,并且不会立即返回任务的执行结果。
public void execute(Runnable command) {// 判断Runnable的实例是否为空,为空就直接抛出异常if (command == null)throw new NullPointerException();/*** 分三步进行:* 1.如果运行的线程少于核心线程数,则尝试启动一个新线程,该线程的第一个任务是给定的命令。* 调用addWorker原子地检查runState和workerCount,因此通过返回false防止了错误警报,当不应该添加线程时,会添加线程* 2.如果可以成功排队任务,那么我们仍然需要再次检查是否应该添加线程(因为自上次检查以来现有线程已经死亡),* 或者自进入此方法以来池已关闭。因此,我们重新检查状态,如果必要,如果停止,则回滚排队,或者如果没有线程,则启动新线程。* 3.如果我们无法排队任务,那么我们尝试添加一个新线程。如果失败,我们知道我们已关闭或饱和,因此拒绝任务。*/int c = ctl.get();// 如果线程数小于核心线程数,尝试添加一个新的线程if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}// 判断线程池是否处于运行状态,如果是则将任务添加到队列中if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();// 再次检查线程池是否处于运行状态,如果不是则将任务从队列中移除if (!isRunning(recheck) && remove(command))reject(command);else if (workerCountOf(recheck) == 0)// 如果线程池处于运行状态并且worker的数量为0,则添加一个新的workeraddWorker(null, false);} else if (!addWorker(command, false))// 如果无法将任务添加到队列中,则添加一个新的worker// 如果添加失败,则拒绝任务reject(command);}/*** 添加工作线程* 检查是否可以根据当前池状态和给定的边界(核心或最大)添加新工作线程。* 如果可以,则相应地调整工作线程计数,并且如果可能,则创建并启动新工作线程,将firstTask作为其第一个任务运行。* 如果池已停止或有资格关闭,则此方法返回false。如果线程工厂在请求时无法创建线程,则也返回false。* 如果线程创建失败,要么是因为线程工厂返回null,要么是因为异常(通常是Thread.start()中的OutOfMemoryError),将干净地回滚。* 检查是否可以根据当前池状态和给定的边界(核心或最大)添加新工作线程。* 如果可以,则相应地调整工作线程计数,并且如果可能,则创建并启动新工作线程,将firstTask作为其第一个任务运行。* 如果池已停止或有资格关闭,则此方法返回false。如果线程工厂在请求时无法创建线程,则也返回false。*/private boolean addWorker(Runnable firstTask, boolean core) {retry:for (; ; ) {int c = ctl.get();int rs = runStateOf(c);// Check if queue empty only if necessary.// 检查队列是否为空只有在必要时才检查。if (rs >= SHUTDOWN &&!(rs == SHUTDOWN &&firstTask == null &&!workQueue.isEmpty()))return false;for (; ; ) {int wc = workerCountOf(c);// 如果工作线程数大于等于核心线程数或者最大线程数,则返回falseif (wc >= CAPACITY ||wc >= (core ? corePoolSize : maximumPoolSize))return false;// 如果工作线程数小于核心线程数,则返回falseif (compareAndIncrementWorkerCount(c))break retry;// 重新获取ctlc = ctl.get(); // Re-read ctl// 如果状态发生变化,则重新开始if (runStateOf(c) != rs)continue retry;}}// 创建worker是否启动成功boolean workerStarted = false;// worker是否添加成功boolean workerAdded = false;// 创建workerWorker w = null;try {// 将firstTask作为其第一个任务运行w = new Worker(firstTask);// 获取线程final Thread t = w.thread;if (t != null) {// ? 获取锁,注意mainLock是用来控制线程池的final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {// 重新检查是否可以添加worker// c & ~CAPACITY 其实就是runState,这里是判断线程池是否处于运行状态int rs = runStateOf(ctl.get());// 如果线程池处于运行状态或者线程池处于关闭状态并且firstTask为空if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {// 如果线程是活动的if (t.isAlive()) // precheck that t is startablethrow new IllegalThreadStateException();// 将worker添加到workers中workers.add(w);// 获取worker的数量int s = workers.size();// 如果worker的数量大于largestPoolSize,则将largestPoolSize设置为worker的数量if (s > largestPoolSize)largestPoolSize = s;workerAdded = true;}} finally {// 释放锁mainLock.unlock();}// 如果worker添加成功,那么就启动worker,并且将workerStarted设置为trueif (workerAdded) {t.start();workerStarted = true;}}} finally {// 如果worker创建失败,则将worker从workers中移除if (!workerStarted)addWorkerFailed(w);}// 返回worker是否启动成功return workerStarted;}
1.1.案例-execute()向线程池提交任务
@Test@DisplayName("threadPoolExecutor => 第一种提交方式 => execute")public void test2() throws InterruptedException {// 核心线程数(corePoolSize)为1// 最大线程数(maximumPoolSize)为1,最大线程 = 核心线程 + 救急线程(队列满的时候,核心线程也都满的时候,会被创建出来执行)// 队列长度为1 (即LinkedBlockingQueue的容量为1)// 这里 核心线程数 和 最大线程数 都是 1,队列长度是 1,所以这里的线程池的最大线程数是 2,队列长度是 1 一共可以执行 2 个任务,第三个任务就会被拒绝ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 1, 30, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(1));// 创建 三个任务,如果线程池中的线程数小于核心线程数,就会直接创建一个新的线程来执行任务// 然后模拟一下出现拒绝策略的情况// 任务1threadPoolExecutor.execute(() -> {logger.error("【hrfan-1】 开始执行啦~~~~~~~~~~");logger.error("【hrfan-1】 执行结束啦~~~~~~~~~~");});// 任务2threadPoolExecutor.execute(() -> {logger.error("【hrfan-2】 开始执行啦~~~~~~~~~~");logger.error("【hrfan-2】 执行结束啦~~~~~~~~~~");});// 任务3threadPoolExecutor.execute(() -> {logger.error("【hrfan-3】 开始执行啦~~~~~~~~~~");logger.error("【hrfan-3】 执行结束啦~~~~~~~~~~");});// 此时会报错// java.util.concurrent.RejectedExecutionException:elegantlyCloseThreadPool(threadPoolExecutor);}

2.submit()
submit()方法是ExecutorService接口中定义的一个方法,它允许向线程池提交任务,并且可以获取任务的执行结果。submit()方法有两个重载版本:
submit(Runnable task)submit(Callable<T> task)这两个版本的
submit()方法都用于向线程池提交任务,但是它们之间有一些区别:
submit(Runnable task)方法接受一个Runnable对象作为参数,用于表示一个不需要返回结果的任务。它会返回一个Future<?>对象,这个对象可以用来监视任务的执行状态,但是无法获取任务执行的结果。(因为两个方法区别不是很多,所以主要以下面为例进行学习)submit(Callable<T> task)方法接受一个Callable<T>对象作为参数,用于表示一个需要返回结果的任务。Callable是一个泛型接口,它的call()方法可以返回一个结果。submit(Callable<T> task)方法会返回一个Future<T>对象,通过这个对象可以获取任务执行的结果。
2.1.submit(Callable task)
/*** 从代码中来看,submit的方法其实也是调用的execute方法* 只不过submit方法可以获取到任务返回值或任务异常信息,execute方法不能获取任务返回值和异常信息。*/public <T> Future<T> submit(Callable<T> task) {// 判断是否提交的任务为空,如果为空则抛出异常if (task == null) throw new NullPointerException();// 将传入的Callable任务封装成RunnableFuture对象RunnableFuture<T> ftask = newTaskFor(task);// 调用execute方法执行任务execute(ftask);return ftask;}/*** 通过传入一个 Runnable 对象和一个结果值,创建一个用于执行任务的 RunnableFuture 对象,并返回该对象。* 这样做的目的是为了能够获取任务的返回值或者任务的异常信息。*/protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {return new FutureTask<T>(callable);}
2.2.案例-submit()向线程池提交任务
@Test@DisplayName("threadPoolExecutor => 第二种提交方式 => submit")public void testSubmit(){// 核心线程数(corePoolSize)为1// 最大线程数(maximumPoolSize)为1,最大线程 = 核心线程 + 救急线程(队列满的时候,核心线程也都满的时候,会被创建出来执行)// 队列长度为2 (即LinkedBlockingQueue的容量为1)// 这里 核心线程数 和 最大线程数 都是 1,队列长度是 1,所以这里的线程池的最大线程数是 2,队列长度是 2 一共可以执行 3 个任务,第四个任务就会被拒绝ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 1, 30, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(2));// 创建 三个任务,如果线程池中的线程数小于核心线程数,就会直接创建一个新的线程来执行任务// 然后模拟一下出现拒绝策略的情况// 任务1Future<String> future1 = threadPoolExecutor.submit(() -> {logger.error("【hrfan-1】 开始执行啦~~~~~~~~~~");logger.error("【hrfan-1】 执行结束啦~~~~~~~~~~");return "hrfan-1-execute-success";});// 任务2Future<String> future2 = threadPoolExecutor.submit(() -> {logger.error("【hrfan-2】 开始执行啦~~~~~~~~~~");logger.error("【hrfan-2】 执行结束啦~~~~~~~~~~");return "hrfan-2-execute-success";});// 任务3Future<String> future3 = threadPoolExecutor.submit(() -> {logger.error("【hrfan-3】 开始执行啦~~~~~~~~~~");logger.error("【hrfan-3】 执行结束啦~~~~~~~~~~");return "hrfan-3-execute-success";});// 优雅关闭线程池elegantlyCloseThreadPool(threadPoolExecutor);// 这个时候,我们是可以获取线程执行的结果logger.error("future1:{}", JSONObject.toJSONString(future1));logger.error("future2:{}", JSONObject.toJSONString(future2));logger.error("future3:{}", JSONObject.toJSONString(future3));}

3.execute,submit对比
- 返回值类型:
execute()方法没有返回值,因为它用于提交不需要返回结果的任务。submit()方法返回一个Future对象,可用于获取任务执行的结果,或者取消任务的执行。
- 接受的参数类型:
execute()方法接受一个Runnable对象,用于表示一个不需要返回结果的任务。submit()方法有两个重载版本,一个接受Runnable对象,另一个接受Callable对象。Callable对象用于表示一个需要返回结果的任务。
- 异常处理:
execute()方法不会捕获任务执行过程中的异常,而是将异常传递给线程的未捕获异常处理器进行处理。submit()方法会捕获任务执行过程中的异常,并将其包装到Future对象中,可以通过调用get()方法来获取异常或者任务的执行结果。
- 任务的取消:
execute()方法提交的任务一旦被提交给线程池,就无法取消或中断任务的执行。submit()方法返回的Future对象可以用于取消任务的执行,通过调用cancel()方法来实现。
- 使用场景:
execute()方法适用于简单的、不需要返回结果的任务提交。submit()方法适用于需要返回结果、需要更多控制和灵活性的任务提交。
线程池的任务调度流程
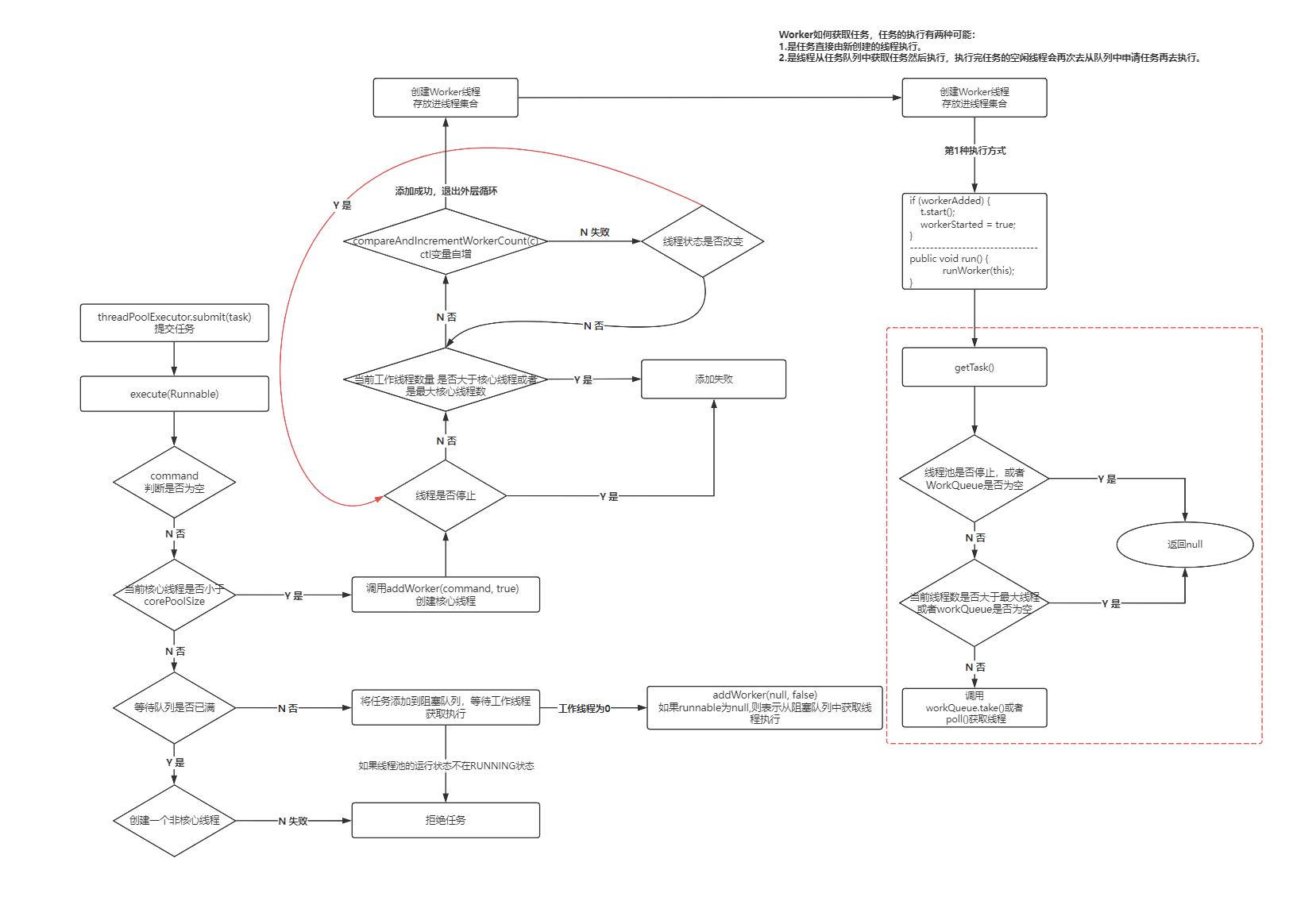
Java线程池的任务调度流程,流程主要分为以下几个步骤:
1. 提交任务
- 用户通过
ThreadPoolExecutor.submit()或execute()方法提交任务。 - 线程池会检查当前工作线程数量是否小于
核心线程数 (corePoolSize)。- 如果小于,则创建一个新的工作线程来执行任务。
- 如果大于或等于,则将任务放入任务队列 (
workQueue) 中等待执行。
2. 获取任务
- 空闲的工作线程会从任务队列中获取任务执行。
- 如果任务队列为空,则线程会进入阻塞状态,等待任务入队。
- 如果任务队列非空,则线程会获取队首任务并开始执行。
3. 执行任务
- 工作线程执行任务。
- 任务执行完成后,工作线程会释放资源,并回到空闲状态。
4. 拒绝策略
- 当线程池无法为新任务创建工作线程时,会触发拒绝策略。
- Java线程池提供了四种拒绝策略:
AbortPolicy:直接抛出RejectedExecutionException异常。CallerRunsPolicy:由调用者所在的线程执行任务。DiscardOldestPolicy:丢弃任务队列中最旧的任务,然后尝试再次执行新任务。DiscardPolicy:直接丢弃新任务。
addWoker源代码在上面
ThreadFactory
ThreadFactory是一个接口,用于创建线程的工厂。它提供了一种方式来自定义线程创建过程,允许您在创建线程时指定一些特定的配置,比如线程名称、优先级、是否为守护线程等。在 Java 中,通常是通过Executors工厂类的静态方法来创建线程池,而这些方法通常会接受一个ThreadFactory对象作为参数,用来创建线程。
1.ThreadFactory源码
这里我们先来看一下 Java为我们提供的线程工厂源代码,通过实现这个工厂,我们可以创建自定义的线程工厂。
public interface ThreadFactory {/*** ThreadFactory接口是一个线程工厂接口,用于创建新线程。* 使用线程工厂可以避免直接调用Thread的构造方法,从而使应用程序可以使用特殊的线程子类、优先级等。* 其中newThread方法负责接收一个Runnable对象,将其封装成一个Thread对象并返回。* 这样,应用程序就可以使用特殊的线程子类、优先级等。*/Thread newThread(Runnable r);
}2.自定义简单线程工厂
通过自定义线程工程,我们来对工厂中线程的名称 和优先级进行统一更改
public class ThreadPoolFactoryDemo {private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());@Test@DisplayName("threadFactory => 线程工厂")public void testThreadPoolFactory(){ExecutorService executorService = Executors.newSingleThreadExecutor( new MyThreadFactory());Future<String> future = executorService.submit(()->{// 这里即使发生了异常,也不会报错,因为线程池会捕获异常,不会抛出// 只有通过future.get()方法获取结果时才会抛出异常,这个时候需要我们自己捕获异常// int i = 1/0;logger.error("开始执行任务了!");return "ok";});// 程序运行期间 并不会报错,即使发生了异常,这个时候需要通过 get去获取时 进行捕获异常try {String s = future.get();logger.error("获取结果 :{}",s);} catch (InterruptedException e) {throw new RuntimeException(e);} catch (ExecutionException e) {throw new RuntimeException(e);}}static class MyThreadFactory implements ThreadFactory {@Overridepublic Thread newThread(Runnable r) {// 这里我们从新设置线程的名称 ,这里一定要传入Runnable的实现类 不然不会报错,但是线程不会执行// 因为线程池会通过这个Runnable实现类来创建线程Thread thread = new Thread(r,"my-thread-" + r.hashCode());// 还可以自定义线程的其他属性,比如优先级等thread.setPriority(Thread.MAX_PRIORITY);return thread;}}
}

3.defaultThreadFactory
如果我们在创建线程池,没有指定自定义工厂,那么就会使用JDK提供的自定义工厂
默认情况下,ThreadPoolExecutor 使用的是 Executors.defaultThreadFactory() 方法提供的线程工厂。这个默认线程工厂创建的线程将具有如下特性:
- 线程名称: 默认情况下,线程的名称将以 “pool-” 为前缀,后跟递增的数字。
- 线程优先级: 默认情况下,线程的优先级将与创建它的线程相同。
- 是否为守护线程: 默认情况下,创建的线程将不是守护线程(daemon thread)。
源码如下:
如果不传递参数那么就会使用默认线程工厂
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue) {this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,Executors.defaultThreadFactory(), defaultHandler);
public static ThreadFactory defaultThreadFactory() {return new DefaultThreadFactory();}
/*** The default thread factory* 默认线程工厂*/static class DefaultThreadFactory implements ThreadFactory {// 线程池编号private static final AtomicInteger poolNumber = new AtomicInteger(1);// 线程组private final ThreadGroup group;// 线程编号private final AtomicInteger threadNumber = new AtomicInteger(1);// 线程名称前缀private final String namePrefix;DefaultThreadFactory() {// 这里首先获取了当前线程的安全管理器,如果安全管理器不为空,则获取当前线程的线程组,否则获取当前线程的线程组SecurityManager s = System.getSecurityManager();group = (s != null) ? s.getThreadGroup() :Thread.currentThread().getThreadGroup();// 重新设置线程名称前缀namePrefix = "pool-" +poolNumber.getAndIncrement() +"-thread-";}public Thread newThread(Runnable r) {// 创建线程Thread t = new Thread(group, r,namePrefix + threadNumber.getAndIncrement(),0);// 判断是否是守护线程if (t.isDaemon())// 设置为非守护线程t.setDaemon(false);// 设置线程优先级(这里设置为普通优先级)if (t.getPriority() != Thread.NORM_PRIORITY)t.setPriority(Thread.NORM_PRIORITY);return t;}}
当我们需要创建具有统一特性的线程时,使用线程池和工厂方法是一种更优雅、更有效的方式,使用线程工厂创建线程有以下优势
1. 代码简洁:
- 无需在每个线程类中重复定义相同的属性和方法。
- 只需在工厂方法中定义一次即可。
2. 代码复用:
- 可以将创建线程的逻辑封装在工厂方法中,方便复用。
- 可以根据不同的需求创建不同的线程池和工厂方法。
3. 易于管理:
- 可以通过线程池统一管理线程的创建、销毁和生命周期。
- 可以方便地监控线程池的运行状态。
4. 提高性能:
- 可以通过线程池复用线程,减少线程创建和销毁的开销。
- 可以通过线程池优化线程调度,提高线程的执行效率。
任务阻塞队列
关于常见的阻塞队列,后面会有专门的文章去详细比较,这里这是单纯列举一下
| 队列类别 | 描述 | 重点信息 |
|---|---|---|
| ArrayBlockingQueue | 基于数组的有界阻塞队列,按照 FIFO(先进先出)原则操作。 | 有界阻塞队列,容量固定,当队列满时插入操作将被阻塞。 |
| LinkedBlockingQueue | 基于链表的可选有界或无界阻塞队列,按照 FIFO(先进先出)原则操作。 | 默认为无界队列,但可指定容量创建有界队列。插入操作可能会阻塞,取决于队列的大小限制。 |
| PriorityBlockingQueue | 基于优先级堆的无界阻塞队列,按照元素的优先级顺序操作,可自定义元素比较器。 | 无界阻塞队列,支持优先级排序,使用 Comparator 或元素自然顺序。 |
| DelayQueue | 存储实现了 Delayed 接口的元素,需要等待一段时间后才能被取出,常用于任务调度。 | 存储延迟元素,只有延迟期满后才能被取出。 |
| SynchronousQueue | 不存储元素的阻塞队列,每个插入操作必须等待一个对应的移除操作,反之亦然。 | 每个插入操作必须等待一个对应的移除操作,是一种直接传递的队列。 |
| LinkedTransferQueue | 无界阻塞队列,支持生产者和消费者的对等交换。提供了 transfer 方法以支持等待插入或移除。 | 支持生产者和消费者的对等交换,可用于实现直接的请求/应答模式。 |
| LinkedBlockingDeque | 基于链表的双端阻塞队列,支持在两端进行插入和移除操作,可作为栈或双端队列使用。 | 双端队列,支持在两端进行插入和移除操作,可用于栈或双端队列。 |
线程池的拒绝策略
线程池的拒绝策略定义了当任务无法被提交到线程池执行时应该采取的行为。当线程池的工作队列已满且无法再接受新任务时,就会触发拒绝策略。Java中的ThreadPoolExecutor类允许开发者指定拒绝策略
这里我们也是简单列举一下,后面章节会详细介绍
| 拒绝策略 | 描述 |
|---|---|
| ThreadPoolExecutor.AbortPolicy | 默认策略,抛出RejectedExecutionException异常来拒绝新任务的提交。 |
| ThreadPoolExecutor.CallerRunsPolicy | 在调用者线程上执行被拒绝的任务。如果线程池已关闭,则任务会被丢弃。 |
| ThreadPoolExecutor.DiscardPolicy | 直接丢弃被拒绝的任务,不提供任何反馈。 |
| ThreadPoolExecutor.DiscardOldestPolicy | 丢弃工作队列中等待时间最长的任务,然后尝试重新提交当前任务。 |
| 自定义拒绝策略 | 开发者可以实现RejectedExecutionHandler接口来定义自己的拒绝策略,以满足特定需求。 |
优雅关闭线程池
1.(限时)等待线程池正在执行任务
(限时内)等待线程池正在执行的任务结束后,立即关闭线程池(超时任务全部执行完毕)
-
首先,定义了一个
shutdownHook线程,它会在JVM关闭时被调用。这个线程的目的是在JVM关闭之前执行一系列操作,包括关闭线程池和等待任务执行完毕。 -
在
shutdownHook线程的执行体中,定义了一个重试次数retry,初始值为2。这表示在关闭线程池之前最多会进行两次重试。 -
调用
threadPoolExecutor.shutdown()方法来关闭线程池。需要注意的是,这里并不会等待队列中的任务执行完毕,因为队列中的任务可能还没有开始执行,直接关闭线程池即可。 -
使用
threadPoolExecutor.awaitTermination(3, TimeUnit.MINUTES)方法等待线程池中的任务执行完毕,等待时间为3分钟。如果超过等待时间仍有任务未执行完毕,并且重试次数大于0(retry-- > 0),则执行下一步。 -
在超时且仍有任务未执行完毕的情况下,调用
threadPoolExecutor.shutdownNow()方法取消正在执行的任务,并强制关闭线程池。 -
如果任务执行完毕或超时后线程池成功关闭,程序继续执行。如果任务未正常执行结束,会打印错误日志。
-
最后,通过
Runtime.getRuntime().addShutdownHook(shutdownHook)方法注册shutdownHook线程,使其在JVM关闭时被调用。
/*** 优雅关闭线程池* @param threadPoolExecutor 线程池 实例对象*/
private static void elegantlyCloseThreadPool(ThreadPoolExecutor threadPoolExecutor) {// 优雅关闭线程池// 一个线程池,提交了五个任务去执行,执行完得需要一段时间。// 增加一个JVM的钩子,这个钩子可以简单理解为监听器,注册后,JVM在关闭的时候就会调用这个方法,调用完才会正式关闭JVM。// 优雅关闭线程池 ,这里是注册一个JVM的钩子,当JVM关闭的时候,会调用这个方法,这个方法里面是关闭线程池,等待线程池中的任务执行完毕Thread shutdownHook = new Thread(() -> {// 设定最大重试次数int retry = 2;// 关闭线程池 这里如果超时 不会等待队列中的任务执行完毕,因为队列中的任务还没有开始执行,所以直接关闭// 如果没超时,还会继续执行队列中的任务logger.error("剩余【{}】次尝试关闭线程池!",retry);threadPoolExecutor.shutdown();try {// 这个方法是等待线程池中的任务执行完毕,如果超时了,就直接关闭 retry-- > 0 是为了防止死循环if(!threadPoolExecutor.awaitTermination(3, TimeUnit.MINUTES) && retry-- > 0){// 调用shutdownNow()取消正在执行的任务,SHUTDOWN->STOP是被允许的threadPoolExecutor.shutdownNow();}else {logger.error("线程池任务未正常执行结束");}} catch (InterruptedException e) {// 等待超时logger.error("等待超时,直接关闭:{}",e.getMessage());// 立即关闭线程池threadPoolExecutor.shutdownNow();}});// 注册JVM钩子Runtime.getRuntime().addShutdownHook(shutdownHook);
}
- shutdown()方法:调用该方法后,线程池进入SHUTDOWN状态,不再接受新的任务提交,但会执行队列中已有的任务和在执行的任务。
- awaitTermination()方法:该方法会等待线程池中的任务执行完毕,或者等待超时,由于设置了3分钟的等待时间,如果在规定时间内线程池中的任务都执行完毕了,那么线程池就会被正常关闭。
- 如果线程池在规定时间内仍然有未完成的任务,则会调用
shutdownNow()方法来尝试取消正在执行的任务,并立即关闭线程池。
2.等待队列任务全部执行完毕
要实现等待所有任务执行完毕再关闭线程池,可以按照以下步骤进行操作:
-
首先,创建一个线程池对象,可以使用Executors类提供的工厂方法之一创建线程池。
-
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 2, 30, TimeUnit.SECONDS,new LinkedBlockingQueue<Runnable>(100));
-
-
在向线程池提交任务之前,创建一个计数器,用于跟踪任务的完成情况。可以使用CountDownLatch类来实现计数器。
-
// 总任务数 public static final int totalTasks = 8; // 使用CountDownLatch来等待线程执行完毕,CountDownLatch是一个同步工具类,用来协调多个线程之间的同步。 public static final CountDownLatch latch = new CountDownLatch(totalTasks);
-
-
提交任务到线程池执行,并在每个任务的最后调用计数器的countDown()方法,表示任务已完成。
-
for (int i = 0; i < totalTasks; i++) {executor.submit(() -> {// 执行任务的代码 // ............// 任务执行完毕后调用计数器的countDown()方法ThreadPoolExecutorProductDemo.latch.countDown(); });
-
-
在所有任务提交完成后,调用计数器的await()方法,阻塞当前线程,直到所有任务完成。
-
// 优雅关闭线程池 // 关闭线程池前 等待所有线程执行结束 try {latch.await(); // 等待所有任务完成logger.error("所有任务执行完毕,关闭线程池");// 关闭线程池threadPoolExecutor.shutdown(); } catch (InterruptedException e) {// 处理中断异常logger.error("等待线程池中的任务执行结束时发生异常:{}",e.getMessage());threadPoolExecutor.shutdownNow();}
-
-
当所有任务完成后,可以关闭线程池。调用线程池对象的shutdown()方法来优雅地关闭线程池。
-
// 这里其实在4中就已经体现了 threadPoolExecutor.shutdown();
-
3.测试两种关闭线程池方法
3.1.自定义Task任务
/*** 自定义task任务(有返回值)*/
class AsyncTask implements Callable<String> {private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());private String name;public AsyncTask(String name){this.name = name;}@Overridepublic String call() throws Exception {logger.error("【{}】 开始执行啦~~~~~~~~~~",name);// 随机睡眠int sleepTime = new Random().nextInt(10000);Thread.sleep(sleepTime);// 任务执行完毕后调用计数器的countDown()方法ThreadPoolExecutorProductDemo.latch.countDown();logger.error("【{}】 执行结束啦~~~~~~~~~~",name);return "task" + name + "completed successfully! current task sleep :"+sleepTime;}
}/*** 自定义Task无返回值*/
class AsyncRunnable implements Runnable{private String name;AsyncRunnable(String name){this.name = name;}private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());@Overridepublic void run() {logger.error("【{}】 开始执行啦~~~~~~~~~~",name);// 随机睡眠int sleepTime = new Random().nextInt(10000);try {Thread.sleep(sleepTime);} catch (InterruptedException e) {throw new RuntimeException(e);}// 任务执行完毕后调用计数器的countDown()方法ThreadPoolExecutorProductDemo.latch.countDown();logger.error("【{}】 执行结束啦~~~~~~~~~~",name);}
}3.2.测试主类
public class ThreadPoolExecutorProductDemo {// 总任务数public static final int totalTasks = 8;// 使用CountDownLatch来等待线程执行完毕,CountDownLatch是一个同步工具类,用来协调多个线程之间的同步。public static final CountDownLatch latch = new CountDownLatch(totalTasks);private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());@Testpublic void test() throws InterruptedException {ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 2, 30, TimeUnit.SECONDS,new LinkedBlockingQueue<Runnable>(100)) {// beforeExecute: 线程执行之前调用@Overrideprotected void beforeExecute(Thread t, Runnable r) {super.beforeExecute(t, r);logger.error("beforeExecute,线程名称:{}", t.getName());}// afterExecute: 线程执行之后调用@Overrideprotected void afterExecute(Runnable r, Throwable t) {super.afterExecute(r, t);}// terminated: 线程池关闭之后调用@Overrideprotected void terminated() {super.terminated();logger.error("terminated");}};// 创建任务AsyncTask task1 = new AsyncTask("hrfan-1");AsyncTask task2 = new AsyncTask("hrfan-2");AsyncTask task3 = new AsyncTask("hrfan-3");AsyncTask task4 = new AsyncTask("hrfan-4");AsyncTask task5 = new AsyncTask("hrfan-5");// 提交任务threadPoolExecutor.submit(task1);threadPoolExecutor.submit(task2);threadPoolExecutor.submit(task3);threadPoolExecutor.submit(task4);threadPoolExecutor.submit(task5);AsyncRunnable asyncRunnable1 = new AsyncRunnable("hrfan-run-6");AsyncRunnable asyncRunnable2 = new AsyncRunnable("hrfan-run-7");AsyncRunnable asyncRunnable3 = new AsyncRunnable("hrfan-run-8");// 创建任务threadPoolExecutor.execute(asyncRunnable1);threadPoolExecutor.execute(asyncRunnable2);threadPoolExecutor.execute(asyncRunnable3);//【submit】 和 【execute】的区别// 基本没有区别,在submit方法中仍然是调用的execute方法进行任务的执行或进入等待队列或拒绝。// submit方法比execute方法多的只是将提交的任务(不管是runnable类型还是callable类型)包装成RunnableFuture然后传递给execute方法执行。// submit方法和execute方法最大的不同点在于submit方法可以获取到任务返回值或任务异常信息,execute方法不能获取任务返回值和异常信息。// 需要等待阻塞队列中线程 全部执行完毕 再关闭线程池// 等待正在执行的线程全部执行结束,然后就关闭线程池// elegantlyCloseThreadPool(threadPoolExecutor);// 等待队列中的任务都执行完毕,在去关闭线程池waitingQueueExecuteClose(threadPoolExecutor);}
}
测试限时等待,关闭线程池
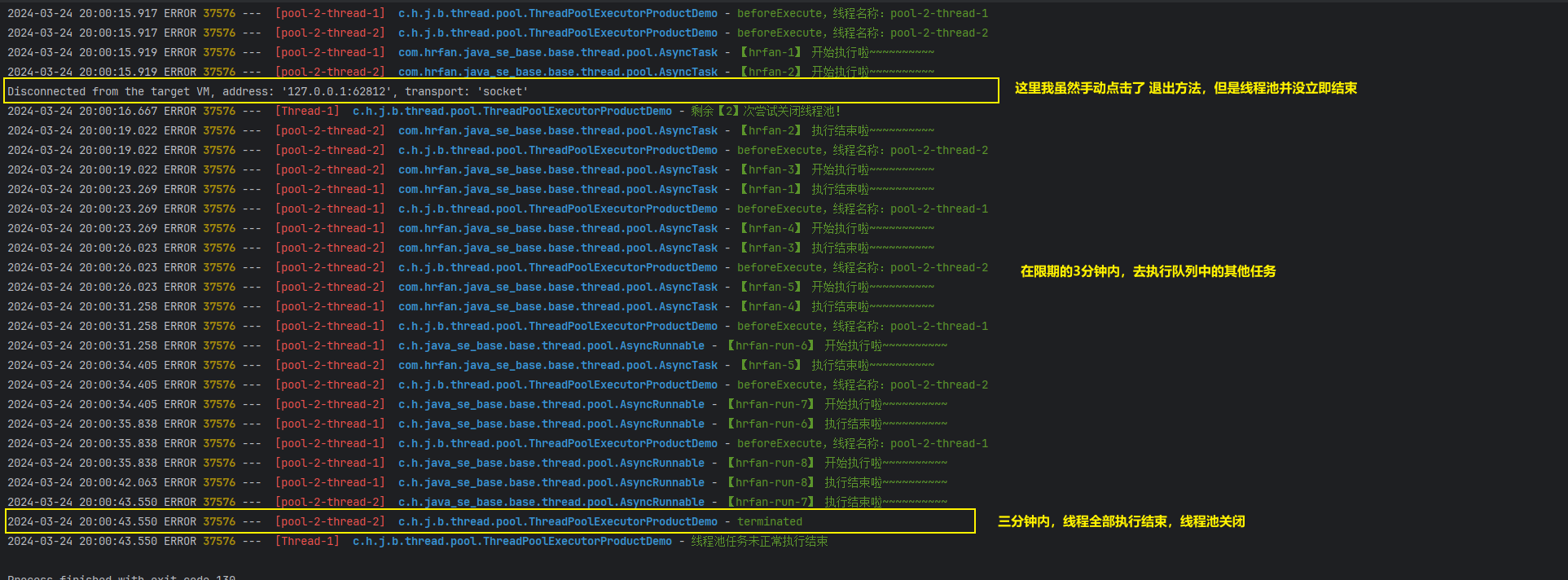
测试等待全部任务执行完毕,关系线程池

相关文章:
7.Java并发编程—掌握线程池的标准创建方式和优雅关闭技巧,提升任务调度效率
文章目录 线程池的标准创建方式线程池参数1.核心线程(corePoolSize)2.最大线程数(maximumPoolSize)3.阻塞队列(BlockingQueue) 向线程提交任务的两种方式1.execute()1.1.案例-execute()向线程池提交任务 2.submit()2.1.submit(Callable<T> task)2.2.案例-submit()向线程池…...

从边缘设备丰富你的 Elasticsearch 文档
作者:David Pilato 我们在之前的文章中已经了解了如何丰富 Elasticsearch 本身和 Logstash 中的数据。 但如果我们可以从边缘设备中做到这一点呢? 这将减少 Elasticsearch 要做的工作。 让我们看看如何从具有代理处理器的 Elastic 代理中执行此操作。 E…...

day29|leetcode|C++|491. 非递减子序列|46. 全排列|47. 全排列 II
Leetcode 491. 非递减子序列 链接:491. 非递减子序列 thought: 设 stack 中最后一个值的位置为 last。如果 stack 为空,则 last -1。 设当前正在处理的位置为 pos。如果在 nums 的子区间 [last1, pos) 中,存在和 nums[pos] 相同的值&…...

[Java、Android面试]_12_java访问修饰符、抽象类和接口
文章目录 1. java访问修饰符2. 抽象类和接口2.1 抽象类2.2 接口2.3 抽象类和接口的区别 本人今年参加了很多面试,也有幸拿到了一些大厂的offer,整理了众多面试资料,后续还会分享众多面试资料。 整理成了面试系列,由于时间有限&…...
Linux:Prometheus的源码包安装及操作(2)
环境介绍 三台centos 7系统,运行内存都2G 1.prometheus监控服务器:192.168.6.1 主机名:pm 2.grafana展示服务器:192.168.6.2 主机名:gr 3.被监控服务器:192.168.6.3 …...

MongoDB聚合运算符:$integral
文章目录 语法使用举例 $integral聚合运算符只能用在$setWindowField阶段,返回曲线下面积的近似值,该曲线是使用梯形规则计算的,其中每组相邻文档使用以下公式形成一个梯形: $setWindowFields阶段中用于积分间隔的sortBy字段值$i…...

手撕算法-买卖股票的最佳时机 II(买卖多次)
描述 分析 使用动态规划。dp[i][0] 代表 第i天没有股票的最大利润dp[i][1] 代表 第i天持有股票的最大利润 状态转移方程为:dp[i][0] max(dp[i-1][0], dp[i-1][1] prices[i]); // 前一天没有股票,和前一天有股票今天卖掉的最大值dp[i][1] max(dp[i-1…...

技术创新与产业升级
在政府工作报告中,新兴技术如云计算、大数据、人工智能等被多次提及,这反映了政府高度重视新一代信息技术在推动经济社会发展中的重要作用。对于计算机行业而言,抓住这些新兴技术的发展机遇,推动技术创新和产业升级,将是未来发展的关键所在。 云计算作为一种新兴的计算模式,正…...
透视未来工厂:山海鲸可视化打造数字孪生新篇章
在信息化浪潮的推动下,数字孪生工厂项目正成为工业制造领域的新宠。作为一名山海鲸可视化的资深用户,我深感其强大的数据可视化能力和数字孪生技术在工厂管理中的应用价值,同时我们公司之前也和山海鲸可视化合作制作了一个智慧工厂项目&#…...

三.寄存器(内存访问)
1.内存中字的存储 2.并不是所有cpu都支持将数据段送入段寄存器,所以有时候用个别的寄存器先把数据段存储起来,再把该寄存器mov到段寄存器。 3.字的传送 4.栈 5.栈机制 举例说明 6.栈顶超界问题 push超界 pop超界 7.栈段...

Day31 贪心算法
Day31 贪心算法 455.分发饼干 我的思路: 小孩数组g指针一直前移,只有饼干数组s满足条件时,才前移,并且更新num 解答: class Solution {public int findContentChildren(int[] g, int[] s) {Arrays.sort(g);Arrays.…...
【WEEK4】 【DAY5】AJAX - Part Two【English Version】
2024.3.22 Friday Following the previous article 【WEEK4】 【DAY4】AJAX - Part One【English Version】 Contents 8.4. Ajax Asynchronous Data Loading8.4.1. Create User.java8.4.2. Add lombok and jackson support in pom.xml8.4.3. Change Tomcat Settings8.4.4. Mo…...
力扣100热题[哈希]:最长连续序列
原题:128. 最长连续序列 题解: 官方题解:. - 力扣(LeetCode)题解,最长连续序列 :哈希表 官方解题思路是先去重,然后判断模板长度的数值是否存在,存在就刷新,…...
)
python笔记基础--文件和存储数据(7)
目录 1.从文件中读取数据 2.写入文件 3.存储数据 3.1使用json.dump()和json.load() 3.2保存和读取用户生成的数据 3.3重构 1.从文件中读取数据 读取整个文件 with open(data.txt) as file_object: contents file_object.read()print(contents)print(contents.rstrip…...
)
Vue黑马笔记(最新)
VUE vue是一个用于构建用户界面的渐进式框架 创建一个VUE实例 核心步骤: 准备容器引包(官网)-开发版本/生产版本创建一个vue实例 new vue()指定配置项->渲染数据 el指定挂载点(选择器),指定管理的是哪个容器。dat…...

安全工具介绍 SCNR/Arachni
关于SCNR 原来叫Arachni 是开源的,现在是SCNR,商用工具了 可试用一个月 Arachni Web Application Security Scanner Framework 看名字就知道了,针对web app 的安全工具,DASTIAST吧 安装 安装之前先 sudo apt-get update sudo…...

赋能数据收集:从机票网站提取特价优惠的JavaScript技巧
背景介绍 在这个信息时代,数据的收集和分析对于旅游行业至关重要。在竞争激烈的市场中,实时获取最新的机票特价信息能够为旅行者和旅游企业带来巨大的优势。 随着机票价格的频繁波动,以及航空公司和旅行网站不断推出的限时特价优惠ÿ…...
【大模型】在VS Code(Visual Studio Code)上安装中文汉化版插件
文章目录 一、下载安装二、配置显示语言(一)调出即将输入命令的搜索模式(二)在大于号后面输入:Configure Display Language(三)重启 三、总结 【运行系统】win 11 【本文解决的问题】 1、英文不…...

自定义WordPress顶部的菜单的方法
要自定义WordPress顶部的菜单,你需要使用WordPress的菜单系统。首先,你需要创建自定义菜单,然后将其设置为顶部导航菜单。 以下是创建自定义菜单并设置其为顶部导航菜单的步骤: 登录到WordPress管理界面。转到“外观”>“菜单…...

独孤思维:流量暴涨,却惨遭违规
最近独孤操作虚拟资料短视频,有个很深的感悟。 每天发10条短视频,积累到20天左右,播放量和粉丝数开始暴涨。 虽然很多牛比的比我数据好,但是对于刚做短视频的独孤来说,我已经满足了。 但是又发了10来天,…...
)
告别网盘客户端!用Alist+RaiDrive把百度云盘变成电脑本地文件夹(保姆级图文教程)
用AlistRaiDrive实现网盘本地化管理的终极方案 你是否厌倦了电脑上安装多个网盘客户端,不仅占用系统资源,操作还繁琐割裂?每次上传下载文件都要在不同客户端间切换,效率低下。现在,通过Alist和RaiDrive的组合…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

从RD、CS到WK:一文讲透SAR主流成像算法的演进与选型实战
从RD、CS到WK:SAR成像算法选型实战指南 当无人机掠过灾区上空,或卫星扫描地球表面时,合成孔径雷达(SAR)正通过电磁波穿透云层和黑暗,将地面信息转化为高分辨率图像。而决定图像质量的关键,在于工…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案
OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 在惠…...

大厂校招变了:AI 能力正在进入笔试和面试
最近不少同学投递校招时,应该已经发现一个变化: 以前 JD 里写的是“熟悉 Python / Java / SQL / Office 优先”。 现在越来越多岗位开始出现新的描述: “熟练使用 AI 工具者优先” “了解大模型应用者优先” “具备 AI 辅助编程经验优先” “…...