ETL数据倾斜与资源优化
1.数据倾斜实例
数据倾斜在MapReduce编程模型中比较常见,由于key值分布不均,大量的相同key被存储分配到一个分区里,出现只有少量的机器在计算,其他机器等待的情况。主要分为JOIN数据倾斜和GROUP BY数据倾斜。
1.1GROUP BY数据倾斜优化
1.1.1set hive.map.aggr=true
开启map之后使用combiner,在map操作之后做局部聚合。
例如:在user表中有100亿条数据,按性别统计条数,select user.gender,count(1) from user group by user.gende
如果没有map端的部分聚合优化,map直接把groupby_key 当作reduce_key发送给reduce做聚合,就会导致计算不均衡的现象。虽然map有100万个,但是reduce只有两个在做聚合,每个reduce处理100亿条记录。
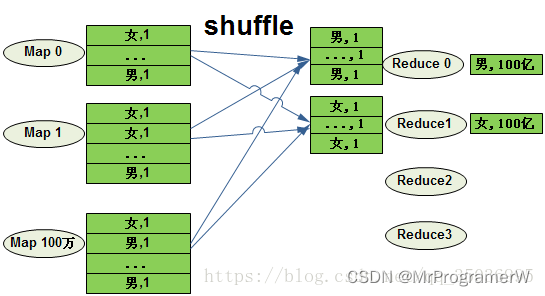
由于map端已经做了局部聚合,虽然还是只有两个reduce做最后的聚合,但是每个reduce只用处理100万行记录,相对优化前的100亿小了1万倍。
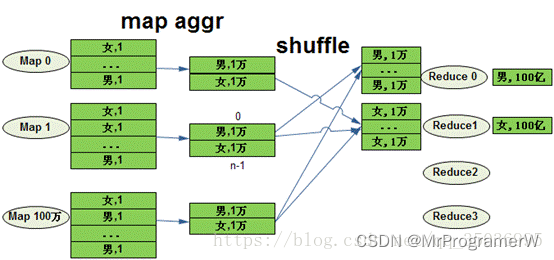
map端聚合打开map聚合开关缺省是打开的,但是不是所有的聚合都需要这个优化。因为group_by_key没有重复的map聚合没有太大意义,并且浪费资源。下面这两个参数控制关掉map聚合的策略。
set hive.groupby.mapaggr.checkinterval = 100000 (默认)尝试执行聚合的条数
set hive.map.aggr.hash.min.reduction=0.5(默认)如果hash表的容量与输入行数之比超过这个数,那么map端的hash聚合将被关闭,默认是0.5,设置为1可以保证hash聚合永不被关闭;
1.1.2set hive.groupby.skewindata=true
当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group ByKey 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce中),最后完成最终的聚合操作。

1.2JOIN数据倾斜优化
1.2.1
如果是由于key值为空或为异常记录,且这些记录不能被过滤掉的情况下,可以考虑给key赋一个随机值,将这些值分散到不同的reduce进行处理。
1.2.2
如果是一个大表和一个小表join的话,可以考虑使用mapjoin来避免数据倾斜,mapjoin的具体过程如下。
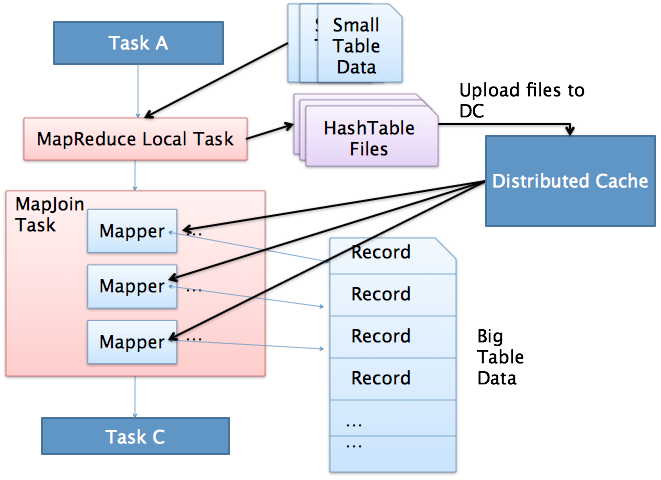
1.2.3 使用/+ MAPJOIN(smalltable)/显示声明MapJoin需要加载到内存中的小表
SELECT /*+mapjoin(b)*/ field1,field2 from a left join b
##MapJoin操作
set hive.auto.convert.join.noconditionaltask = true;#默认值:true;将普通的join转化为普通的mapjoin时,是否将多个mapjoin转化为一个mapjoin
set hive.mapjoin.smalltable.filesize=100000;#大表小表判断的阈值,如果表的大小小于该值则会被加载到内存中运行
set hive.ignore.mapjoin.hint = false;#默认值:true;是否忽略mapjoin hint 即mapjoin标记
set hive.auto.convert.join.noconditionaltask.size=100000;#将多个mapjoin转化为一个mapjoin时,其表的最大值
1.3大表关联大表数据倾斜
1.增加Reducer数量
2.把大表转换成小表做MapJoin
2.资源分配
2.1生产资源案例
例如生产上的某应用计算资源有3100CU,一共三个队列,两个机房,业务高峰期数据量大的业务线同时刷数会出现严重的资源不足的情况。
2.2调度策略
调度通常是一个难题,并没有一个所谓“最好”的策略,因此Yarn提供了多种调度策略;
2.2.1FIFO调度器
先到先分配资源,前一个应用执行完毕之后下一个应用开始执行。缺点是小作业很容易被阻塞,等大作业执行完毕才能执行。
2.2.2容量调度器
容量调度器以队列为单位划分资源,每个队列都有资源使用的下限和上限。每个用户可以设定资源使用上限。管理员可以约束单个队列、用户或者作业的资源使用、支持作业优先级,但不支持抢占。如果队列中有多个作业,并且队列资源不够用了,这是如果集群仍然有空闲资源,那么容量调度器可能会将空余的资源分配给队列中的作业,哪怕是超出队列的容量,这部分队列成为“弹性队列”。
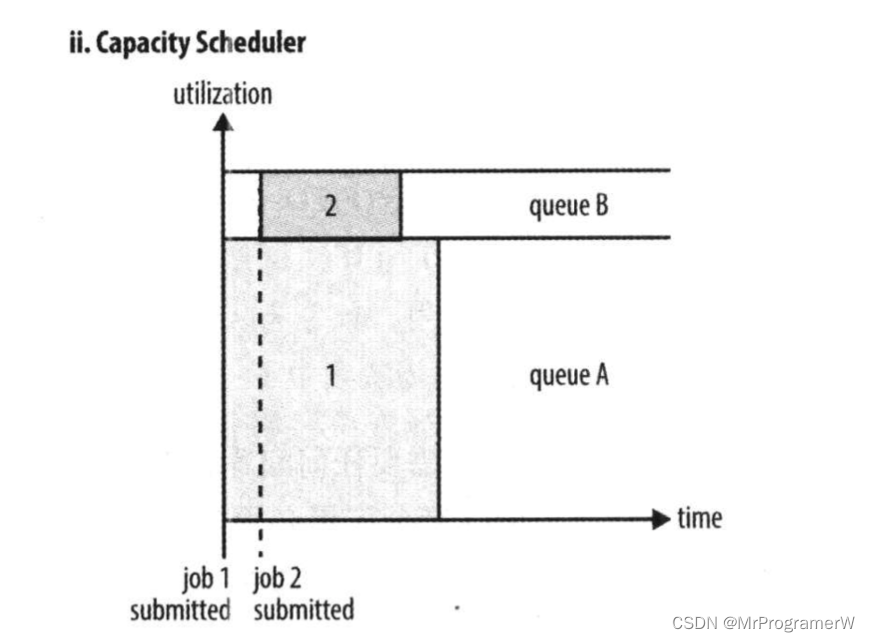
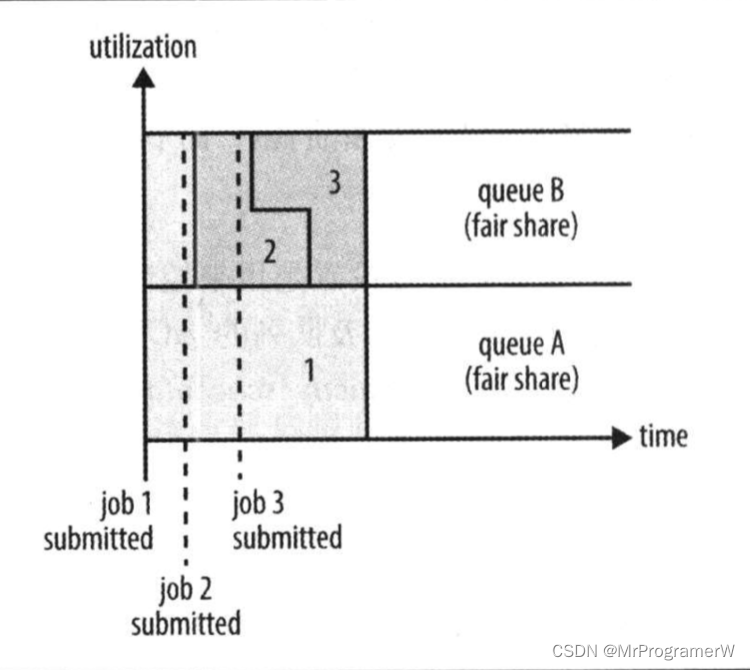
2.2.3公平调度器
想象两个队列A和B。A启动一个作业,在B没有需求时A会分配到全部可用资源;当A的作业仍在运行时B启动一个作业,一段时间后,按照我们先前看到的方式,每个作业都用到了一半的集群资源。这时,如果B启动第二个做作业且其他作业仍在运行,那么第二个作业将和B的其他作业(这里是第一个)共享资源,因此B的每个作业将占四分之一的集群资源,而A仍继续占用一半的集群资源。最终的结果就是资源在用户之间实现了公平共享。
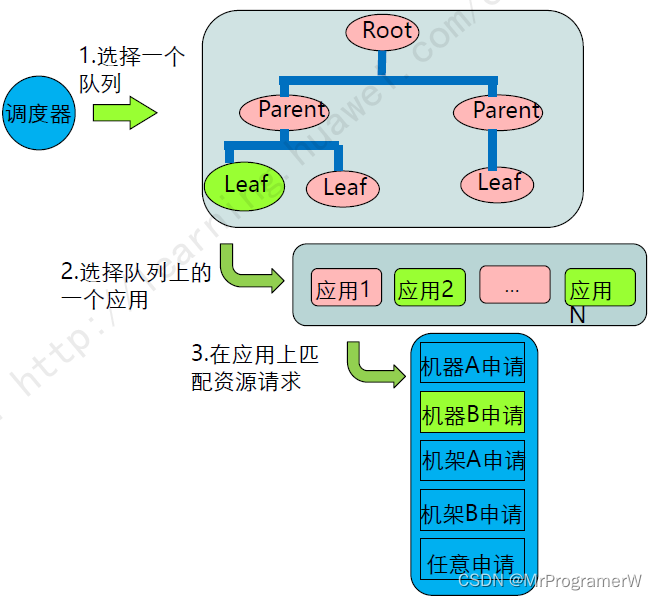
2.3机器申请
机器申请调度器会优先匹配本地资源的申请请求,其次是同机架的,最后是任意机器的。
2.4通过参数调节资源的使用
Hadoop最底层数据存储是HDFS,HDFS按文件存储,最小的存储单元是块。MapReduce输入的单位是分片,每个分片对应一个Mapper,每个Mapper或Reducer申请一个计算资源。资源申请的多少,可以通过修改输入数据的分片大小来控制。由于总体资源有限,需要控制各个阶段的申请资源数。离线表四-ETL参数优化
代码块
Python
##Map输入合并小文件
set mapred.max.split.size=256000000; ##每个Map最大输入大小 ,超过次大小进行文件拆分
set mapred.min.split.size.per.node=256000000; ##一个节点上split的至少的大小 ,每个节点上的文件小于此大小进行文件合并
set mapred.min.split.size.per.rack=256000000; ##一个交换机下split的至少的大小 ,每个交换机上小于此大小进行文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; ##一个data node节点上多个小文件会进行合并,合并文件数由mapred.max.split.size限制的大小决定
##输出合并
set hive.merge.mapfiles = true; ##在Map-only的任务结束时合并小文件 ,如果hadoop版本支持CombineFileInputFormat,则启动Map-only job for merge,否则启动 MapReduce merge job,map端combine file是比较高效的做法
set hive.merge.mapredfiles = true; ##在Map-Reduce的任务结束时合并小文件
set hive.merge.size.per.task = 128000000; ##控制每个任务合并小文件后的文件大小(默认256000000)
set hive.merge.smallfiles.avgsize=64000000; ##告诉hadoop什么样的文件属于小文件(默认16000000),这个值只有当hive.merge.mapfiles或hive.merge.mapredfiles设定为true时,才有效
##控制Reduce个数
set mapred.reduce.tasks = 1000;
set hive.exec.reducers.bytes.per.reducer=64000000;#用于设置在执行SQL的过程中每个reducer处理的最大字节数量。可以在配置文件中设置,也可以由我们在命令行中直接设置。如果处理的数据量大于,就会多生成一个reudcer。例如,number = 1024K,处理的数据是1M,就会生成10个reducer。
3.其他常见问题
3.1OOM
##Maper:
set mapred.map.child.java.opts=-Xmx2048m;#(默认参数,表示jvm堆内存)
set mapreduce.map.memory.mb=2304;#(默认参数,表示整个jvm进程占用的内存:堆内存+堆外内存=2048+256)
##Reducer:
set mapred.reduce.child.java.opts=-Xmx2048m;#(默认参数,表示jvm堆内存)
set mapreduce.reduce.memory.mb=2304;#(默认参数,表示整个jvm进程占用的内存:堆内存+堆外内存=2048+256)
##MRAppMaster:
set yarn.app.mapreduce.am.command-opts=-Xmx1024m;#(默认参数,表示jvm堆内存)
set yarn.app.mapreduce.am.resource.mb=1536;#(默认参数,表示整个jvm进程占用的内存:堆内存+堆外内存=1024+512)
3.2写文件超过10万个
平台限制写文件数不能超过10万个,distribute by顾名思义,是起分散数据作用的。distribute by col,则是按照col列为key分散到不同的reduce里去,默认采取的是hash算法。
distribute by deliver_date, source_system,source_system_table,cast(rand()*100 as int)
相关文章:
ETL数据倾斜与资源优化
1.数据倾斜实例 数据倾斜在MapReduce编程模型中比较常见,由于key值分布不均,大量的相同key被存储分配到一个分区里,出现只有少量的机器在计算,其他机器等待的情况。主要分为JOIN数据倾斜和GROUP BY数据倾斜。 1.1GROUP BY数据倾…...

Python的asyncio:异步编程的利器
在Python中,asyncio模块为开发者提供了强大的异步编程支持,使得编写高效且并发的代码变得更加容易。本文将深入探讨asyncio的核心概念、工作原理以及如何快速入门,通过文字与代码结合,带您领略异步编程的魅力。 1. 协程与事件循环…...
nodejs+vue高校奖助学金系统python-flask-django-php
高校奖助学金系统的目的是让使用者可以更方便的将人、设备和场景更立体的连接在一起。能让用户以更科幻的方式使用产品,体验高科技时代带给人们的方便,同时也能让用户体会到与以往常规产品不同的体验风格。 与安卓,iOS相比较起来,…...

已解决redis.clients.jedis.exceptions.JedisMovedDataException异常的正确解决方法,亲测有效!!!
已解决redis.clients.jedis.exceptions.JedisMovedDataException异常的正确解决方法,亲测有效!!! 目录 问题分析 报错原因 解决思路 解决方法 使用JedisCluster自动处理MOVED错误 手动更新客户端缓存 总结 博主vÿ…...
政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(五)—— Dropout和批归一化
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: TensorFlow与Keras实战演绎 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! Dropout和批归一化是深度学习领域中常用的正则化技术…...

nodejs+vue高校会议室预订管理系统python-flask-django-php
伴随着我国社会的发展,人民生活质量日益提高。于是对系统进行规范而严格是十分有必要的,所以许许多多的信息管理系统应运而生。此时单靠人力应对这些事务就显得有些力不从心了。所以本论文将设计一套高校会议室预订管理系统,帮助学校进行会议…...

文件夹读取不到文件:深度解析与高效恢复策略
一、遭遇文件夹读取难题:文件离奇失踪 在日常使用电脑或移动设备的过程中,我们有时会遇到一个令人头疼的问题:原本存储着重要数据的文件夹突然变得“空空如也”,其中的文件仿佛凭空消失一般,无法正常读取。这种文件夹…...
python—接口编写部分
最近准备整理一下之前学过的前端小程序知识笔记,形成合集。顺便准备学一学接口部分,希望自己能成为一个全栈嘿嘿。建议关注收藏,持续更新技术文档。 目录 前端知识技能树http请求浏览器缓存 后端知识技能树python_api:flaskflask…...

手机IP地址如何更换
手机IP地址的修改方法可以通过以下几种方式实现: 1. 手动更改IP地址:打开手机设置,进入网络设置页面,找到IP地址更改选项。在此页面输入新的IP地址和子网掩码,并启用DHCP服务器。请注意,并非所有手机都支持…...

【R包开发:包的组件】 第4章 包的元数据
DESCRIPTION(描述文件) 的作用是存储包中重要的元数据。当第一次开发包时, 你会 使用这个文件记录包运行时所需要的包。然而,随着时间的流逝,当开始与他人分享包 时,元数据文件变得越来越重要,因为它指定了谁可以使用它…...
Office办公软件之word的使用(一)
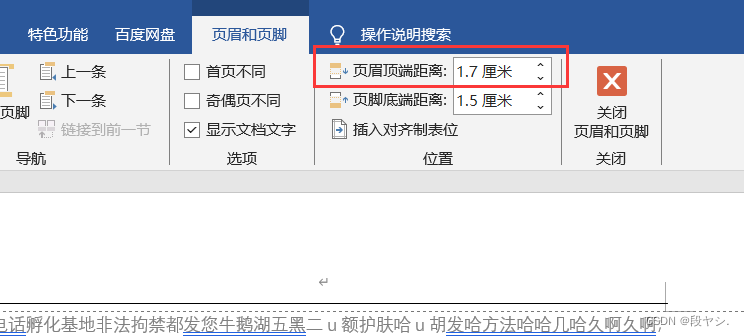
前几天调整公司招标文件的格式,中途遇到一些问题,感觉自己还不是太熟悉操作,通过查阅资料,知道了正确的操作,就想着给记下来。如果再次遇到,也能很快地找到解决办法。 一、怎么把标题前的黑点去掉 解决办法…...
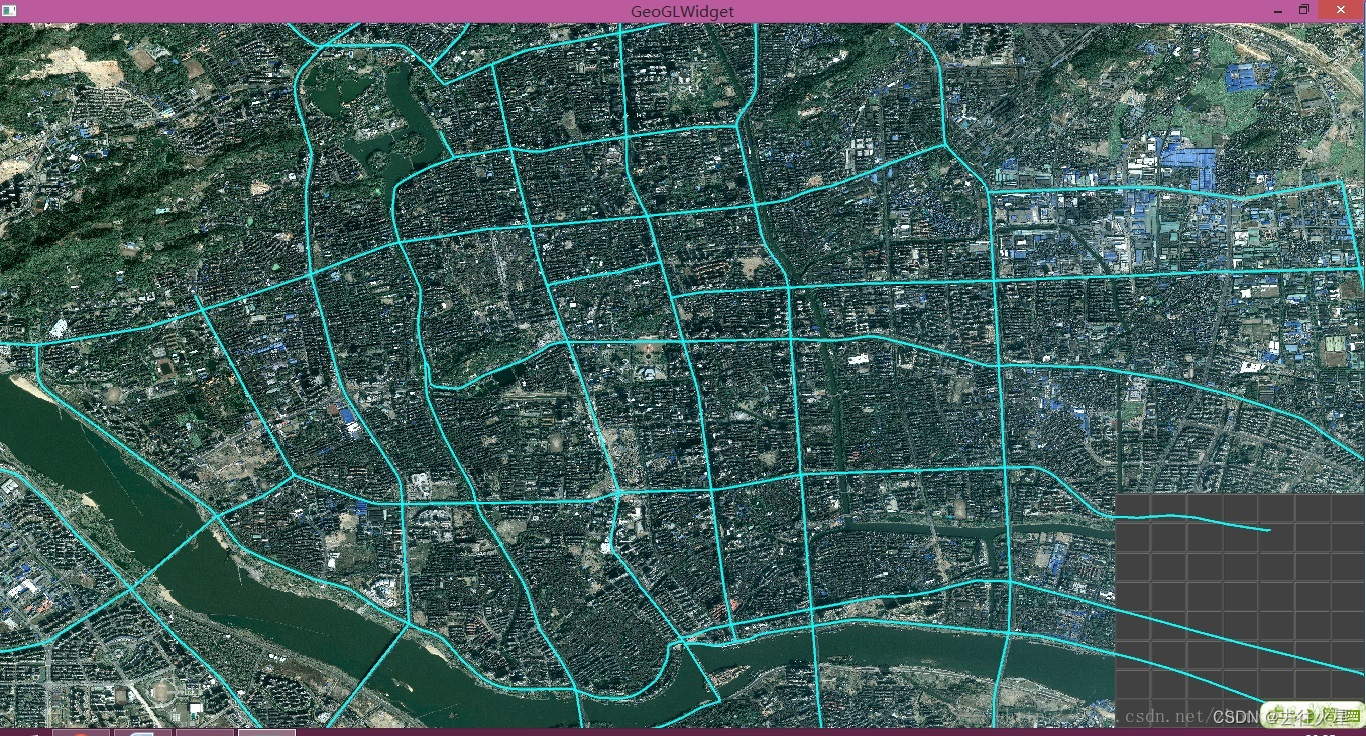
OpenGL+QT实现矢量和影像的叠加绘制
一、QT下OpenGL框架的初始化 OpenGL的介绍我在这里就没有必要介绍了,那OpenGL和QT的结合在这里就有必要先介绍一下,也就是怎么使用QT下的OpenGL框架。要想使用QT下的OpenGL框架,就必须要子类化QGLWidget,然后实现。 void initia…...
)
vue基础——java程序员版(vuex)
vuex可以定义共享数据。 1、主要结构 src/store/index.js 是使用vuex的核心js文件。 定义数据:state 修改数据(同步):mutations 修改数据(异步):action调用>mutations 下面定义了一个公共数据msg ,mutations方法setName…...
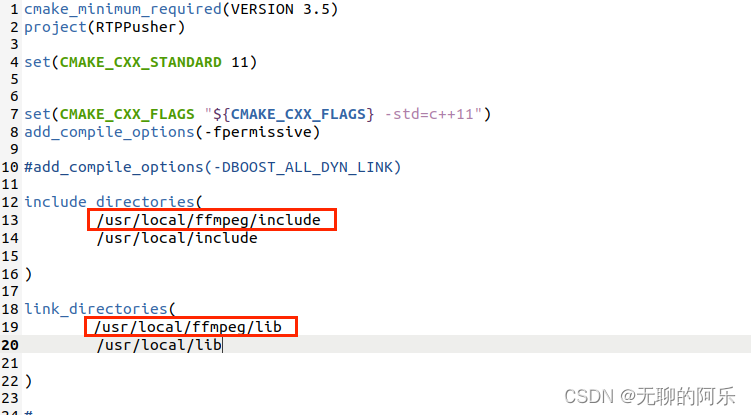
ubuntu20.04安装 ffmpeg 开发环境
参考:参考1 一些相关软件包,已打包整理好,如下 源码包 1、安装步骤 创建安装目录 sudo mkdir -p /usr/local/ffmpeg/lib 解压源码 tar -jxf ffmpeg-4.3.2.tar.bz2 到指定ffmpeg目录进行配置 cd ffmpeg-4.3.2/ 配置:会报错很多…...
微软开源Garnet高性能缓存服务安装
Garnet介绍 Garnet是一款微软研究院基于C#开发而开源的高性能缓存服务,支持Windows、Linux多平台部署,Garnet兼容Redis服务API,在性能和使用架构上较Redis有很大提升(官方说法),并提供与Redis一样的命令操…...
)
云计算系统管理(ADMIN)
01. 公司需要将/opt/bjcat3目录下的所有文档打包备份,如何实现? 答案: # tar -czf /tmp/bjcat3.tar.gz /opt/bjcat302. 简述创建crontab计划任务的流程 答案: 利用crontab –e -u 用户名 进入计划任务编辑模式 分 时 日 月 周 …...
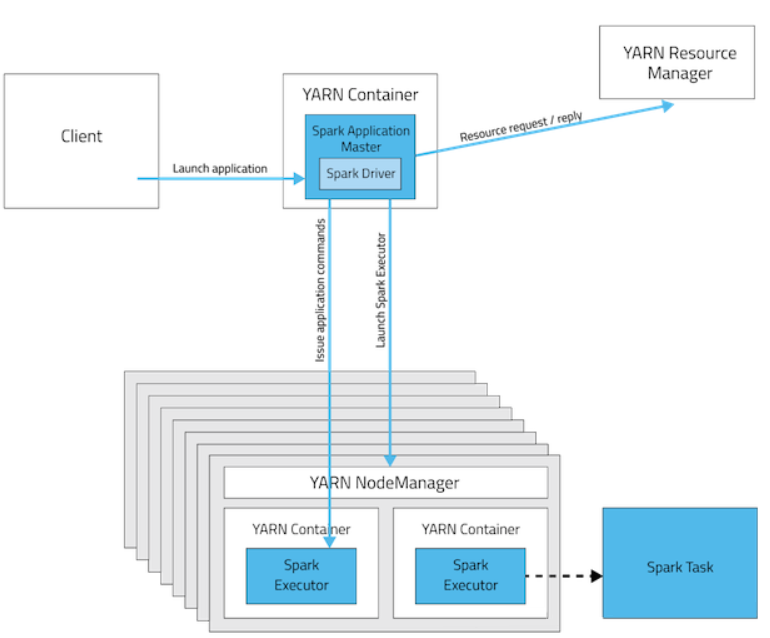
Spark spark-submit 提交应用程序
Spark spark-submit 提交应用程序 Spark支持三种集群管理方式 Standalone—Spark自带的一种集群管理方式,易于构建集群。Apache Mesos—通用的集群管理,可以在其上运行Hadoop MapReduce和一些服务应用。Hadoop YARN—Hadoop2中的资源管理器。 注意&…...

IOS面试题编程机制 51-55
51. 在iPhone应用中如何保存数据?有以下几种保存机制: 1).通过web服务,保存在服务器上 2).通过NSCoder固化机制,将对象保存在文件中 3).通过SQlite或CoreData保存在文件数据库中52. 阐述Block 的理解?并写出一个使用Block执行UIVew动画?Block是可以获取其他函数局部变量的…...

话题——AI大模型学习
AI大模型学习 在当前技术环境下,AI大模型学习不仅要求研究者具备深厚的数学基础和编程能力,还需要对特定领域的业务场景有深入的了解。通过不断优化模型结构和算法,AI大模型学习能够不断提升模型的准确性和效率,为人类生活和工作…...

MySQL基础复习
目录 一、简单的命令 二、SQL语句分类 三、简单查询 四、条件查询 五、排序 一、简单的命令 net start 服务名称 net stop 服务名称 mysql -uroot -p123456 显示密码形式 mysql -uroot -p 隐藏密码形式 exit 退出 show databases; 查看MySQL中的数据库有哪些 use test…...

为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析
更多请点击: https://intelliparadigm.com 第一章:为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析 在对17个采用DeepSeek-R1/VL模型开展定制化开发的工业级项目进行回溯审计后,我…...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...

InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制
InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一个基于Unreal Engine 5开发的RTSP视频播放插件࿰…...
从模糊到电影级景深:Midjourney + Topaz Gigapixel联调方案(含LUT预设包+PSD分层模板)
更多请点击: https://codechina.net 第一章:从模糊到电影级景深:Midjourney Topaz Gigapixel联调方案(含LUT预设包PSD分层模板) 当Midjourney生成的图像存在主体边缘柔化、背景层次缺失或分辨率不足等问题时…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

从配置到运行时:Forge Admin 的动态 API 配置管理是怎么做的
问题:同一个接口,今天要加认证、明天要加加密、后天要限流,这些行为散落在拦截器、过滤器、注解里,改一次牵一发动全身,怎么集中管理和动态刷新? 1. 这个问题在企业后台里为什么常见 在企业后台开发中&am…...

UnityExplorer:如何在游戏运行时实时调试和修改Unity项目
UnityExplorer:如何在游戏运行时实时调试和修改Unity项目 【免费下载链接】UnityExplorer An in-game UI for exploring, debugging and modifying IL2CPP and Mono Unity games. 项目地址: https://gitcode.com/gh_mirrors/un/UnityExplorer UnityExplorer是…...

暗黑破坏神2存档编辑器:d2s-editor免费可视化编辑终极指南
暗黑破坏神2存档编辑器:d2s-editor免费可视化编辑终极指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 想要轻松修改暗黑破坏神2存档却不懂十六进制?d2s-editor是你的完美解决方案!这款基于…...

Unity场景交互动画工程化实践:触发、动画、物理与渲染四层协同
1. 这不是“加个动画”那么简单:为什么90%的Unity场景交互动画最终显得廉价又生硬? “用 Unity 打造超酷场景交互动画”——这句话在B站、知乎和独立游戏开发群里的出现频率,大概和“三分钟学会Python”差不多。但真正跑完一个完整流程、让玩…...