政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(五)—— Dropout和批归一化
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras实战演绎
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
Dropout和批归一化是深度学习领域中常用的正则化技术,旨在提高模型的泛化能力和防止过拟合。
Dropout是由Hinton等人在2012年提出的一种正则化技术。它通过在训练过程中随机地将一部分神经元的输出设置为零,来减少神经网络中神经元之间的依赖关系。具体来说,对于每个训练样本,每个神经元都有一定的概率被丢弃,这样可以防止某些特定的神经元过于依赖于其他神经元,从而使得整个网络的泛化能力更强。在测试时,不再进行随机丢弃,而是将所有神经元的输出都保留下来,但要乘上一个与训练时丢弃概率成反比的因子,以保持输出值的期望不变。
批归一化是由Ioffe和Szegedy在2015年提出的一种归一化技术。它主要解决深度神经网络中的内部协变量转移问题,即前一层的参数更新会影响到后一层的输入分布,使得训练过程变得复杂。批归一化通过在每一层的输入上进行归一化操作,将每一层的输入都尽量保持在较小的范围内,可以加快训练速度并提高模型的泛化能力。具体来说,批归一化将每个特征维度的输入都减去其均值,并除以其标准差,然后再乘以一个可学习的缩放系数和位移系数。
总之,Dropout和批归一化是深度学习领域中常用的正则化技术。
Dropout在训练过程中随机丢弃神经元的输出,减少网络的依赖关系,提高泛化能力;
批归一化通过归一化每层的输入,解决内部协变量转移问题,加快训练速度并提高模型的泛化能力。
Dropout和批归一化的作用:添加这些特殊的层来防止过拟合并稳定训练。
前言
深度学习的世界远不止稠密层(dense layer)。您可以在模型中添加几十种不同类型的层(layer)。(尝试浏览一下Keras文档来了解一些示例!)有些层类似于稠密层,用于定义神经元之间的连接,而其他类型的层则可以进行预处理或其他形式的转换操作。
在本文中,我们将学习两种特殊的层,它们本身不包含任何神经元,但可以为模型添加一些功能,有时可以以各种方式受益。这两种层在现代架构中经常使用。
Dropout
其中一种层是“dropout层”,它可以帮助纠正过拟合。
在上一篇文章中,我们讨论了过拟合是由网络在训练数据中学习到的虚假模式引起的。为了识别这些虚假模式,网络通常会依赖于非常特定的权重组合,一种“诱骗”权重。由于非常特定,它们往往很脆弱:去除其中一个,“诱骗”就会瓦解。
这就是Dropout的理念。为了打破这些诱骗,我们在训练的每一步中随机丢弃一部分层的输入单元,使网络更难学习训练数据中的那些虚假模式。相反,它必须搜索广泛、普遍的模式,这些模式的权重模式往往更加稳定。
(在这里,在两个隐藏层之间添加了50%的Dropout。)
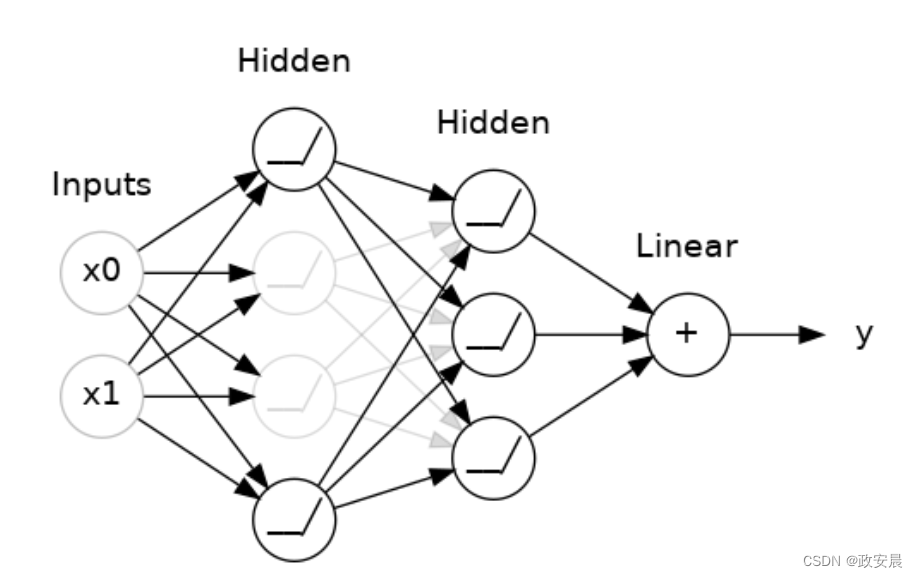
你也可以将dropout看作是创建了一种网络集合。
预测不再由一个大网络完成,而是由一组较小的网络委员会完成。委员会中的个体往往会犯不同类型的错误,但同时也会做出正确的判断,使得整个委员会的性能比任何一个个体网络都要好。(如果你熟悉随机森林作为决策树的集合,那就是相同的思想。)
增加 Dropout
在Keras中,dropout率参数rate定义了要关闭的输入单元的百分比。
将Dropout层放在希望应用dropout的层之前:
keras.Sequential([# ...layers.Dropout(rate=0.3), # apply 30% dropout to the next layerlayers.Dense(16),# ...
])批归一化
下一个我们要看的特殊层是执行“批量归一化”(或“batchnorm”)的层,它可以帮助纠正训练过程中的缓慢或不稳定的问题。
在神经网络中,通常将所有数据放在一个共同的尺度上是一个好主意,例如使用scikit-learn的StandardScaler或MinMaxScaler。原因是SGD会按照数据产生的激活大小的比例来调整网络权重。产生非常不同大小激活的特征可能导致训练不稳定。
现在,如果在数据进入网络之前归一化是好的,那么在网络内部也进行归一化可能会更好!事实上,我们有一种特殊的层可以实现这一点,即批量归一化层。批量归一化层在每个批次进来时,首先使用自己的均值和标准差对批次进行归一化,然后还用两个可训练的重新缩放参数将数据放在一个新的尺度上。批量归一化实际上执行了一种协调的输入尺度调整。
大多数情况下,批量归一化被添加为优化过程的辅助手段(尽管它有时也可以帮助预测性能)。具有批量归一化的模型通常需要更少的轮次来完成训练。此外,批量归一化还可以修复导致训练“陷入困境”的各种问题。如果在训练过程中遇到问题,考虑将批量归一化添加到您的模型中。
增加批量归一化
批量标准化似乎可以在网络的几乎任何位置使用。
可以将其放在一个层之后...
layers.Dense(16, activation='relu'),
layers.BatchNormalization(),...或者在一层和其激活函数之间:
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),如果你将它添加为网络的第一层,它可以充当一种自适应的预处理器,类似于Sci-Kit Learn的StandardScaler。
示例 - 使用Dropout和批归一化
在看TensorFlow和Keras的例子之前,我们先对比看一下pyTorch的例子:
import torch
import torch.nn as nn
import torch.optim as optim# 定义神经网络模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(10, 20)self.dropout = nn.Dropout(0.2)self.fc2 = nn.Linear(20, 10)self.bn = nn.BatchNorm1d(10)self.fc3 = nn.Linear(10, 1)def forward(self, x):x = self.fc1(x)x = self.dropout(x)x = self.fc2(x)x = self.bn(x)x = self.fc3(x)return x# 定义训练和测试数据
train_data = torch.randn(100, 10)
train_labels = torch.randn(100, 1)test_data = torch.randn(10, 10)
test_labels = torch.randn(10, 1)# 初始化模型和优化器
model = Net()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
model.train()
for epoch in range(100):optimizer.zero_grad()output = model(train_data)loss = nn.MSELoss()(output, train_labels)loss.backward()optimizer.step()# 测试模型
model.eval()
with torch.no_grad():test_output = model(test_data)test_loss = nn.MSELoss()(test_output, test_labels)print("Test Loss:", test_loss.item())
在上面这个示例中,我们定义了一个简单的神经网络模型。在模型的定义中,我们添加了一个Dropout层和一个批归一化层。在训练过程中,我们使用了随机梯度下降优化器和均方误差损失函数对模型进行训练。在测试过程中,我们使用了带有梯度的测试数据来评估模型的性能。
通过使用Dropout和批归一化,我们可以有效地避免过拟合和梯度消失问题,提高模型的性能和泛化能力。在实际应用中,可以根据具体情况调整Dropout和批归一化的参数以获得更好的效果。
接下来,我正式看一下TF与Keras的例子:
我们继续开发前面文章的红酒模型。现在我们将进一步增加容量,但添加丢弃以控制过拟合,并添加批归一化来加速优化。这次,我们还将不标准化数据,以展示批归一化如何稳定训练。
# Setup plotting
import matplotlib.pyplot as pltplt.style.use('seaborn-whitegrid')
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',titleweight='bold', titlesize=18, titlepad=10)import pandas as pd
red_wine = pd.read_csv('../input/dl-course-data/red-wine.csv')# Create training and validation splits
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)# Split features and target
X_train = df_train.drop('quality', axis=1)
X_valid = df_valid.drop('quality', axis=1)
y_train = df_train['quality']
y_valid = df_valid['quality']当添加dropout时,可能需要增加密集层中的神经元数量。
from tensorflow import keras
from tensorflow.keras import layersmodel = keras.Sequential([layers.Dense(1024, activation='relu', input_shape=[11]),layers.Dropout(0.3),layers.BatchNormalization(),layers.Dense(1024, activation='relu'),layers.Dropout(0.3),layers.BatchNormalization(),layers.Dense(1024, activation='relu'),layers.Dropout(0.3),layers.BatchNormalization(),layers.Dense(1),
])这次我们在训练设置上没有任何改变。
model.compile(optimizer='adam',loss='mae',
)history = model.fit(X_train, y_train,validation_data=(X_valid, y_valid),batch_size=256,epochs=100,verbose=0,
)# Show the learning curves
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();
如果在训练之前对数据进行标准化,通常可以获得更好的性能。然而,我们能够使用原始数据,显示了批量归一化在更困难的数据集上的有效性。
练习:Dropout与批量归一化
介绍
在这个练习中,你将给咱们前面文章练习中的Spotify模型添加dropout,并看看批量归一化如何使你能够成功地训练困难的数据集上的模型。
前面文章:
政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(四)—— 过拟合和欠拟合![]() https://blog.csdn.net/snowdenkeke/article/details/136919080小伙们拉到最后来看示例代码。
https://blog.csdn.net/snowdenkeke/article/details/136919080小伙们拉到最后来看示例代码。
现在,我们继续:
# Setup plotting
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',titleweight='bold', titlesize=18, titlepad=10)
plt.rc('animation', html='html5')# Setup feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.deep_learning_intro.ex5 import *首先加载Spotify数据集。
import pandas as pd
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import make_column_transformer
from sklearn.model_selection import GroupShuffleSplitfrom tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import callbacksspotify = pd.read_csv('../input/dl-course-data/spotify.csv')X = spotify.copy().dropna()
y = X.pop('track_popularity')
artists = X['track_artist']features_num = ['danceability', 'energy', 'key', 'loudness', 'mode','speechiness', 'acousticness', 'instrumentalness','liveness', 'valence', 'tempo', 'duration_ms']
features_cat = ['playlist_genre']preprocessor = make_column_transformer((StandardScaler(), features_num),(OneHotEncoder(), features_cat),
)def group_split(X, y, group, train_size=0.75):splitter = GroupShuffleSplit(train_size=train_size)train, test = next(splitter.split(X, y, groups=group))return (X.iloc[train], X.iloc[test], y.iloc[train], y.iloc[test])X_train, X_valid, y_train, y_valid = group_split(X, y, artists)X_train = preprocessor.fit_transform(X_train)
X_valid = preprocessor.transform(X_valid)
y_train = y_train / 100
y_valid = y_valid / 100input_shape = [X_train.shape[1]]
print("Input shape: {}".format(input_shape))1. 为Spotify Model增加Dropout
这是上篇文章练习中的最后一个模型。在具有128个单元的Dense层之后添加一个dropout层,并在具有64个单元的Dense层之后再添加一个dropout层。将两个dropout层的丢弃率都设为0.3。
# YOUR CODE HERE: Add two 30% dropout layers, one after 128 and one after 64
model = keras.Sequential([layers.Dense(128, activation='relu', input_shape=input_shape),layers.Dense(64, activation='relu'),layers.Dense(1)
])# Check your answer
q_1.check()# Lines below will give you a hint or solution code
#q_1.hint()
#q_1.solution()现在您可以运行下一个代码来训练模型并观察添加dropout的效果。
model.compile(optimizer='adam',loss='mae',
)
history = model.fit(X_train, y_train,validation_data=(X_valid, y_valid),batch_size=512,epochs=50,verbose=0,
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot()
print("Minimum Validation Loss: {:0.4f}".format(history_df['val_loss'].min()))2.评估Dropout
再次回顾一下上篇文章的练习,这个模型在第5个epoch附近容易过拟合数据。这次添加dropout似乎有助于防止过拟合吗?
# View the solution (Run this cell to receive credit!)
q_2.check()现在,我们将切换话题,探讨批标准化如何解决训练中的问题。
加载混凝土数据集。这次我们不进行任何标准化处理。这将使批标准化的效果更加明显。
import pandas as pdconcrete = pd.read_csv('../input/dl-course-data/concrete.csv')
df = concrete.copy()df_train = df.sample(frac=0.7, random_state=0)
df_valid = df.drop(df_train.index)X_train = df_train.drop('CompressiveStrength', axis=1)
X_valid = df_valid.drop('CompressiveStrength', axis=1)
y_train = df_train['CompressiveStrength']
y_valid = df_valid['CompressiveStrength']input_shape = [X_train.shape[1]]运行以下代码来对非标准化的混凝土数据进行网络训练。
model = keras.Sequential([layers.Dense(512, activation='relu', input_shape=input_shape),layers.Dense(512, activation='relu'), layers.Dense(512, activation='relu'),layers.Dense(1),
])
model.compile(optimizer='sgd', # SGD is more sensitive to differences of scaleloss='mae',metrics=['mae'],
)
history = model.fit(X_train, y_train,validation_data=(X_valid, y_valid),batch_size=64,epochs=100,verbose=0,
)history_df = pd.DataFrame(history.history)
history_df.loc[0:, ['loss', 'val_loss']].plot()
print(("Minimum Validation Loss: {:0.4f}").format(history_df['val_loss'].min()))你最后得到了一张空白图吗?试图在这个数据集上训练这个网络通常会失败。即使它收敛了(因为有了幸运的权重初始化),它也倾向于收敛到一个非常大的数值。
3. 添加批归一化层
批量归一化可以帮助纠正这类问题。
在每个全连接层之前添加四个批量归一化层。(记得将input_shape参数移到新的第一层。)
# YOUR CODE HERE: Add a BatchNormalization layer before each Dense layer
model = keras.Sequential([layers.Dense(512, activation='relu', input_shape=input_shape),layers.Dense(512, activation='relu'),layers.Dense(512, activation='relu'),layers.Dense(1),
])# Check your answer
q_3.check()# Lines below will give you a hint or solution code
#q_3.hint()
#q_3.solution()运行一下代码,看看批量归一化是否能让我们训练模型。
model.compile(optimizer='sgd',loss='mae',metrics=['mae'],
)
EPOCHS = 100
history = model.fit(X_train, y_train,validation_data=(X_valid, y_valid),batch_size=64,epochs=EPOCHS,verbose=0,
)history_df = pd.DataFrame(history.history)
history_df.loc[0:, ['loss', 'val_loss']].plot()
print(("Minimum Validation Loss: {:0.4f}").format(history_df['val_loss'].min()))4. 评估批量归一化
您可以通过反复对比,观察批量归一化对您的模型改善是否有用。
# View the solution (Run this cell to receive credit!)
q_4.check()相关文章:
政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(五)—— Dropout和批归一化
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: TensorFlow与Keras实战演绎 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! Dropout和批归一化是深度学习领域中常用的正则化技术…...

nodejs+vue高校会议室预订管理系统python-flask-django-php
伴随着我国社会的发展,人民生活质量日益提高。于是对系统进行规范而严格是十分有必要的,所以许许多多的信息管理系统应运而生。此时单靠人力应对这些事务就显得有些力不从心了。所以本论文将设计一套高校会议室预订管理系统,帮助学校进行会议…...

文件夹读取不到文件:深度解析与高效恢复策略
一、遭遇文件夹读取难题:文件离奇失踪 在日常使用电脑或移动设备的过程中,我们有时会遇到一个令人头疼的问题:原本存储着重要数据的文件夹突然变得“空空如也”,其中的文件仿佛凭空消失一般,无法正常读取。这种文件夹…...
python—接口编写部分
最近准备整理一下之前学过的前端小程序知识笔记,形成合集。顺便准备学一学接口部分,希望自己能成为一个全栈嘿嘿。建议关注收藏,持续更新技术文档。 目录 前端知识技能树http请求浏览器缓存 后端知识技能树python_api:flaskflask…...

手机IP地址如何更换
手机IP地址的修改方法可以通过以下几种方式实现: 1. 手动更改IP地址:打开手机设置,进入网络设置页面,找到IP地址更改选项。在此页面输入新的IP地址和子网掩码,并启用DHCP服务器。请注意,并非所有手机都支持…...

【R包开发:包的组件】 第4章 包的元数据
DESCRIPTION(描述文件) 的作用是存储包中重要的元数据。当第一次开发包时, 你会 使用这个文件记录包运行时所需要的包。然而,随着时间的流逝,当开始与他人分享包 时,元数据文件变得越来越重要,因为它指定了谁可以使用它…...
Office办公软件之word的使用(一)
前几天调整公司招标文件的格式,中途遇到一些问题,感觉自己还不是太熟悉操作,通过查阅资料,知道了正确的操作,就想着给记下来。如果再次遇到,也能很快地找到解决办法。 一、怎么把标题前的黑点去掉 解决办法…...
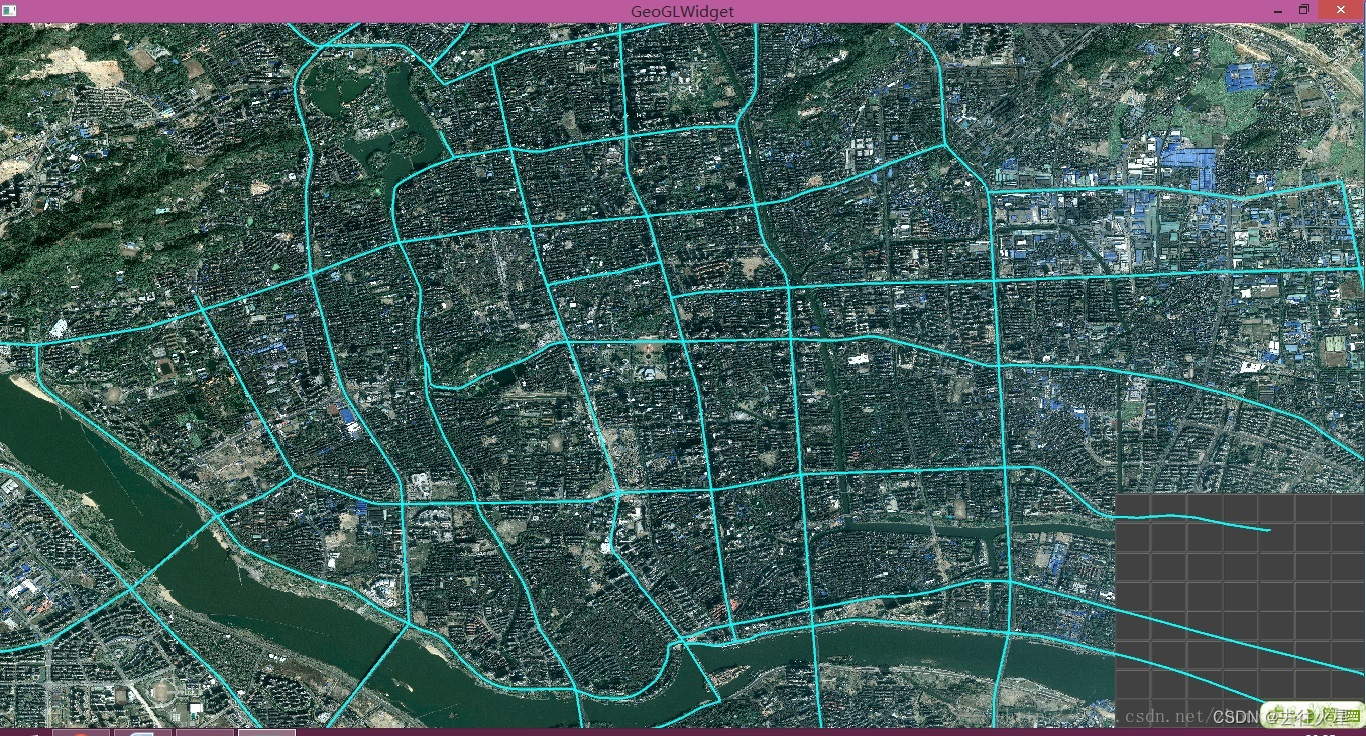
OpenGL+QT实现矢量和影像的叠加绘制
一、QT下OpenGL框架的初始化 OpenGL的介绍我在这里就没有必要介绍了,那OpenGL和QT的结合在这里就有必要先介绍一下,也就是怎么使用QT下的OpenGL框架。要想使用QT下的OpenGL框架,就必须要子类化QGLWidget,然后实现。 void initia…...
)
vue基础——java程序员版(vuex)
vuex可以定义共享数据。 1、主要结构 src/store/index.js 是使用vuex的核心js文件。 定义数据:state 修改数据(同步):mutations 修改数据(异步):action调用>mutations 下面定义了一个公共数据msg ,mutations方法setName…...
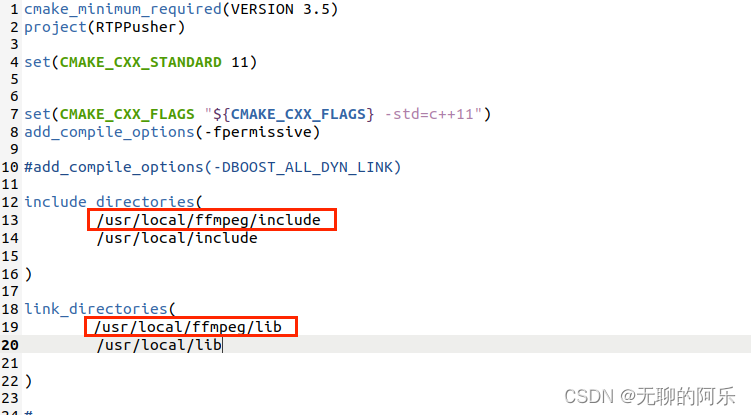
ubuntu20.04安装 ffmpeg 开发环境
参考:参考1 一些相关软件包,已打包整理好,如下 源码包 1、安装步骤 创建安装目录 sudo mkdir -p /usr/local/ffmpeg/lib 解压源码 tar -jxf ffmpeg-4.3.2.tar.bz2 到指定ffmpeg目录进行配置 cd ffmpeg-4.3.2/ 配置:会报错很多…...
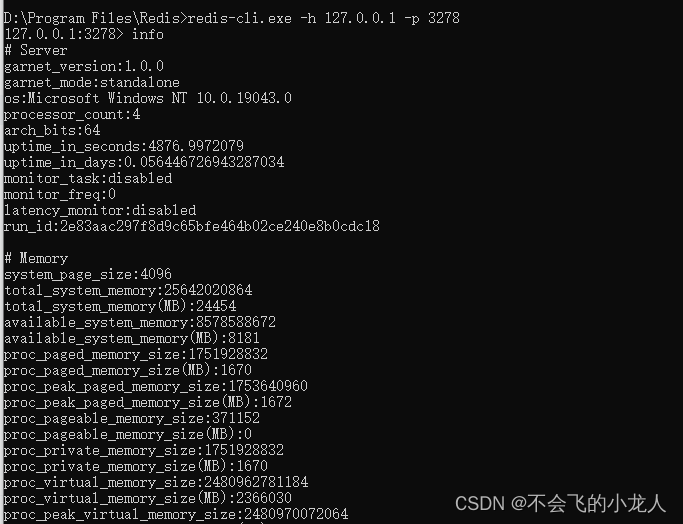
微软开源Garnet高性能缓存服务安装
Garnet介绍 Garnet是一款微软研究院基于C#开发而开源的高性能缓存服务,支持Windows、Linux多平台部署,Garnet兼容Redis服务API,在性能和使用架构上较Redis有很大提升(官方说法),并提供与Redis一样的命令操…...
)
云计算系统管理(ADMIN)
01. 公司需要将/opt/bjcat3目录下的所有文档打包备份,如何实现? 答案: # tar -czf /tmp/bjcat3.tar.gz /opt/bjcat302. 简述创建crontab计划任务的流程 答案: 利用crontab –e -u 用户名 进入计划任务编辑模式 分 时 日 月 周 …...
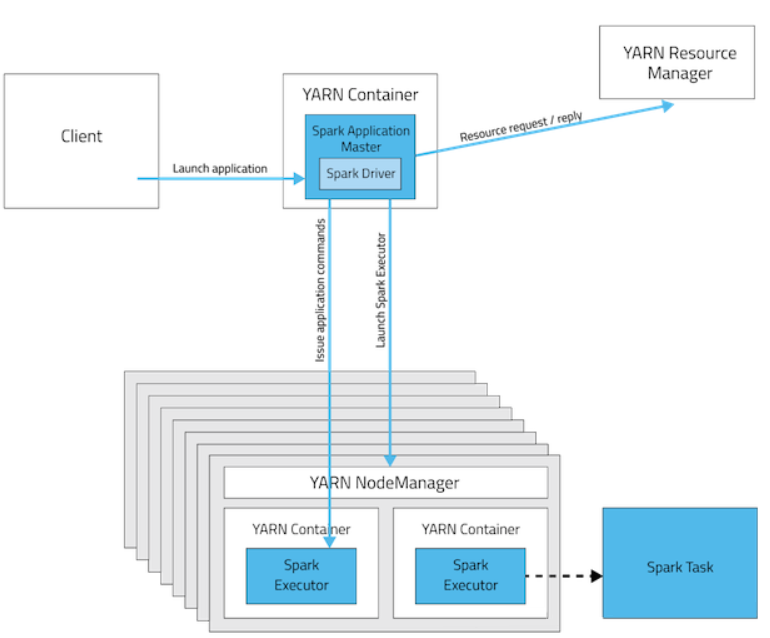
Spark spark-submit 提交应用程序
Spark spark-submit 提交应用程序 Spark支持三种集群管理方式 Standalone—Spark自带的一种集群管理方式,易于构建集群。Apache Mesos—通用的集群管理,可以在其上运行Hadoop MapReduce和一些服务应用。Hadoop YARN—Hadoop2中的资源管理器。 注意&…...

IOS面试题编程机制 51-55
51. 在iPhone应用中如何保存数据?有以下几种保存机制: 1).通过web服务,保存在服务器上 2).通过NSCoder固化机制,将对象保存在文件中 3).通过SQlite或CoreData保存在文件数据库中52. 阐述Block 的理解?并写出一个使用Block执行UIVew动画?Block是可以获取其他函数局部变量的…...

话题——AI大模型学习
AI大模型学习 在当前技术环境下,AI大模型学习不仅要求研究者具备深厚的数学基础和编程能力,还需要对特定领域的业务场景有深入的了解。通过不断优化模型结构和算法,AI大模型学习能够不断提升模型的准确性和效率,为人类生活和工作…...

MySQL基础复习
目录 一、简单的命令 二、SQL语句分类 三、简单查询 四、条件查询 五、排序 一、简单的命令 net start 服务名称 net stop 服务名称 mysql -uroot -p123456 显示密码形式 mysql -uroot -p 隐藏密码形式 exit 退出 show databases; 查看MySQL中的数据库有哪些 use test…...
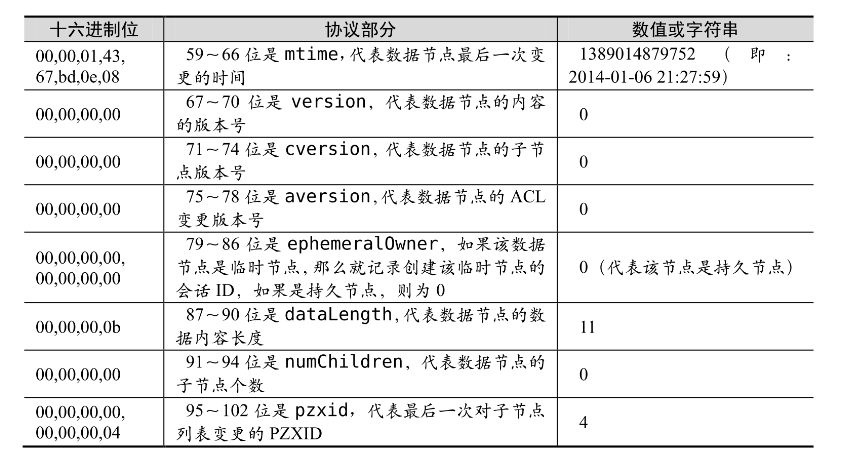
Zookeeper(八)序列化与协议
目录 一 序列化与反序列化1.1 Jute序列化工具1.1 Recor接口1.2 OutputArchive和InputArchive 二 通信协议2.1 请求部分2.1.1 请求头2.2.2 请求体2.1.3 案例分析 2.2 响应部分2.2.1 响应头2.2.2 响应内容2.2.3 案例分析 官网:Apache ZooKeeper 一 序列化与反序列化 …...
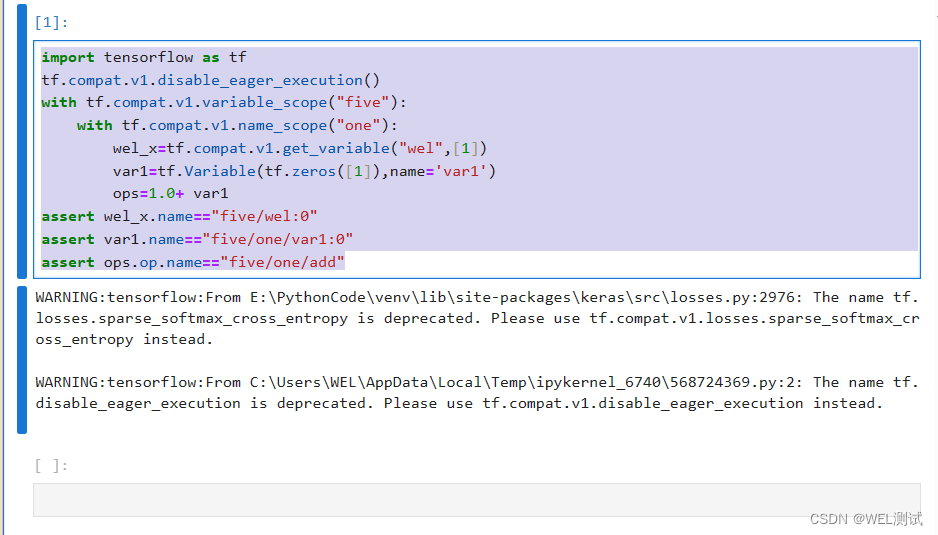
人工智能之Tensorflow变量作用域
在TensoFlow中有两个作用域(Scope),一个时name_scope ,另一个是variable_scope。variable_scope主要给variable_name加前缀,也可以给op_name加前缀;name_scope给op_name加前缀。 variable_scope 通过所给的名字创建或…...

ElasticSearch插件安装及配置
Docker安装ElasticSearch docker compose 安装直接看步骤三:新建索引 1、安装elasticsearch (1)下载elasticsearch和kibana docker pull elasticsearch:7.9.1 docker pull kibana:7.9.1(2)配置 mkdir -p /mydata/…...
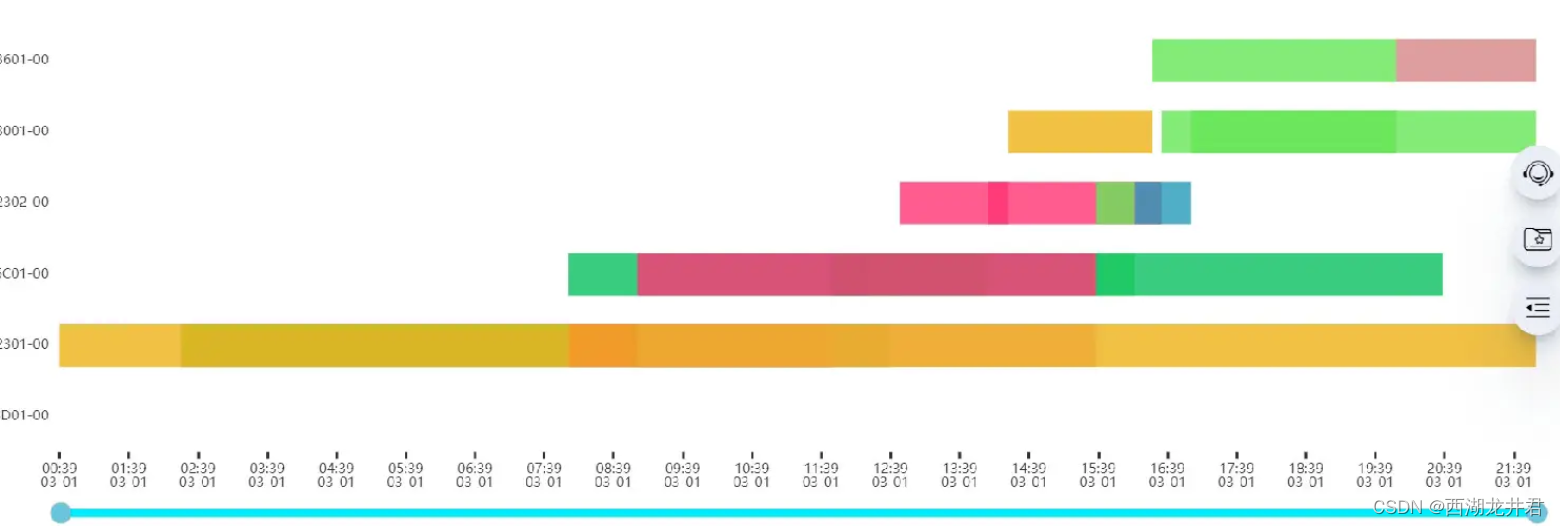
vue+Echarts实现多设备状态甘特图
目录 1.效果图 2.代码 3.注意事项 Apache ECharts ECharts官网,可在“快速上手”处查看详细安装方法 1.效果图 可鼠标滚轮图表和拉动下方蓝色的条条调节时间细节哦 (注:最后一个设备没有数据,所以不显示任何矩形)…...

3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐
3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在使用功能单一的网易云音乐吗?想不想让你的播放器拥…...

DMA-330地址空间限制与扩展方案解析
1. DMA-330地址空间限制解析DMA-330作为Arm CoreLink系列中的直接内存访问控制器,其物理寻址能力直接由AxADDR信号宽度决定。这个32位地址总线宽度意味着它原生仅支持4GB(2^32字节)的物理地址空间访问。在实际嵌入式系统设计中,这…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南
如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南 【免费下载链接】moveit2 :robot: MoveIt for ROS 2 项目地址: https://gitcode.com/gh_mirrors/mo/moveit2 想要为你的机器人实现智能运动规划吗?MoveIt2作为ROS 2生态中最强大…...

如何用HsMod解锁炉石传说60+项隐藏功能:终极优化指南
如何用HsMod解锁炉石传说60项隐藏功能:终极优化指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx开发的炉石传说功能增强插件,为玩家提供…...

终极免费音乐解锁工具:5步轻松解密你的加密音乐文件
终极免费音乐解锁工具:5步轻松解密你的加密音乐文件 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...

Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间
Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦…...

Python到Android的魔法之旅:5步将你的代码变成移动应用
Python到Android的魔法之旅:5步将你的代码变成移动应用 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 想象一下,你花了几个月时间精心…...