Flink GateWay、HiveServer2 和 hive on spark
Flink SQL Gateway简介
从官网的资料可以知道Flink SQL Gateway是一个服务,这个服务支持多个客户端并发的从远程提交任务。Flink SQL Gateway使任务的提交、元数据的查询、在线数据分析变得更简单。
Flink SQL Gateway的架构如下图,它由插件化的Endpoints和SqlGatewayService两部分组成。SqlGatewayService是可复用的处理客户端请求的服务。Endpoint是对外暴露的用户可以连接的接口。
Flink SQL Gateway作业提交流程
Flink SQL Gateway的处理流程如下
1.创建Session
当客户端连接Flink SQL Gateway时,Flink SQL Gateway会创建一个Session来存储客户端和 SQL Gateway交互的信息。Session创建完成后Flink SQL Gateway会返回给客户端一个SessionHandle标识
2.提交SQL
客户端创建完Session后就可以提交SQL到SQL Gateway。提交SQL时,SQL会被翻译成一个Operation,并且每个Operation会对应一个OperationHandle标识。使用OperationHandle可以获取查询的结果、取消Operation的执行或者关闭Operation
3. 获取结果
用户可以通过OperationHandle获取Operation的执行结果。如果Operation准备好了,SQL Gateway会返回一批数据和一个获取下一批数据的URI。当所有数据都获取完了,SQL Gateway会将resultType的值设置为EOS,并且将获取下一批数据的URI设置为null。
如果想了解flink sql gateway连接hiveserver2,参考:
Flink SQL Gateway的使用 - 知乎 (zhihu.com)
本质上就是把hive变成flink的一个catalog,就像doris外部表集成mysql一样,mysql就是doris的一个catalog,可以直接用doris语句操作mysql了。这里也一样,hive变成了flinksql的一个catalog。
怎么连接hive并直接可以用hive的代码(虽然这个需求我们是执行flink来跑hive数据),用hiveserver2最高效,下面有hiveserver2的介绍。
那为什么不直接使用 Flink SQL 而使用 Gateway 呢?
-
远程访问需求: 有时用户可能需要从不同的位置或者不同的应用程序中访问 Flink SQL 引擎,这就需要一个中心化的访问点,而 Gateway 提供了这样的功能。
-
集中管理和监控需求: 在大型生产环境中,可能需要一个统一的管理界面来管理和监控 Flink SQL 作业,而 Gateway 提供了这样的功能。
-
安全性需求: 在企业环境中,安全性通常是一个重要考虑因素,而 Gateway 可以提供身份验证和授权机制,帮助确保系统的安全性。
Hiveserver2介绍:
在启动Hive的时候,除了必备的MetaStore服务外 , 我们前面还有提到过2种方式使用Hive :
- bin/hive , 就是Hive Shell的客户端 , 直接写SQL
- bin/hive --service hiveserver2
HiveServer2是Hive的一个服务组件,它提供了一个多客户端访问的接口,允许用户通
过多种方式 (如JDBC、ODBC等) 连接Hive,并执行HiveQL语句。HiveServer2可以
独立于Hive运行,并且可以与其他应用程序进行集成,使得用户可以更加灵活地使用H
ive.
HiveServer2的主要作用有:
1.支持多客户端连接
HiveServer2可以同时处理多个客户端的连接请求,每个客户端可以独立地执行HiveQ
L语句。这使得多个用户可以同时访问Hive,并且不会相互影响。同时,HiveServer2
还支持连接池,可以有效地管理连接资源,提高系统的并发性能。
2.提供安全访问控制
HiveServer2支持基于Kerberos的认证和授权机制,可以对用户进行身份验证,并目可
以通过角色和权限管理来限制用户的访问权限。这样可以确保数据的安全性,并且可
以按需控制用户对数据的访问和操作
3.支持长连接和会话管理
HiveServer2支持长连接和会话管理,客户端可以通过保持连接的方式避免多次建立和
关闭连接的开销,提高了系统的性能和响应速度。同时,HiveServer2还提供了会话管
理功能,可以为每个用户分配一个独立的会话,可以在会话级别上进行状态管理和资
源隔离。
4.支持异步查询和结果集缓存
HiveServer2支持异步查询和结果集缓存,客户端可以提交一个查询请求后立即返回
然后通过轮询的方式获取查询结果。这样可以减少客户端的等待时间,并且可以利用
结果集缓存提高查询的性能
启动Hive后,
此时后台执行脚本 : nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
bin/hive --service metastore , 启动的是元数据管理服务
bin/hive --service hiveserver2 , 启动的是hiveserver2服务
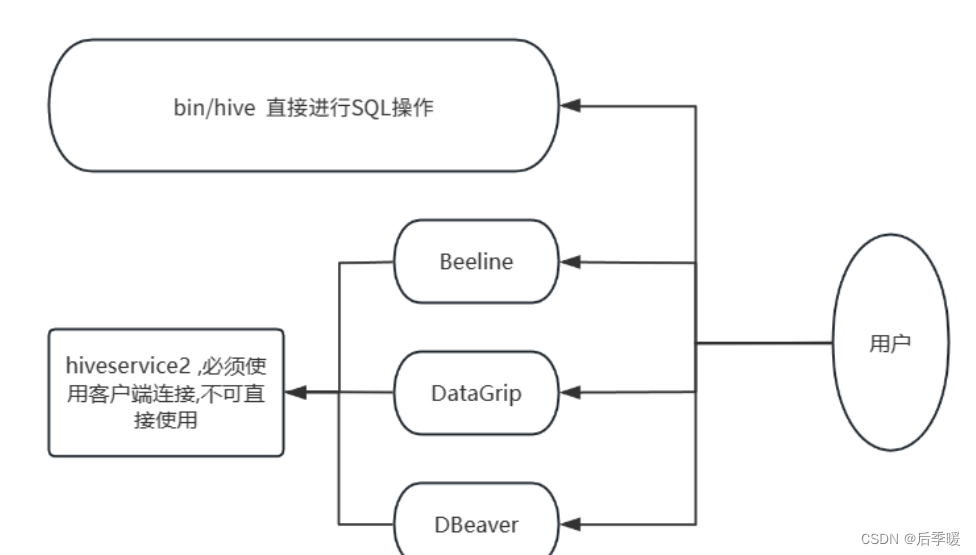
所以 , HiveServer2其实就是Hive内置的一个ThriftServer服务 , 提供Thrift端口供其他客户端连接
这时可以连接ThrifServer的客户端有 :
Hive内置的beeline客户端工具(命令行形式)
第三方的图形化工具 , 如DataGrip这些
下面就是它们之间的关系:
话不多说, 我们开始实际操作
在安装hive的服务器上, 首先启动metastore服务 , 然后启动hiveserver2服务
#启动metastore服务
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
#启动hiveserver2服务
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
Beeline连接
在hive的服务器上可以直接使用beeline客户端进行连接 , Beeline是JDBC的客户端 , 通过JDBC和HiveServer2进行通信, 协议的地址是 :
jdbc:hive2://node:10000
这个10000端口是hiveserver2默认向外开发的端口
#进入beeline的连接界面
bin/beeline
#开始连接
!connect jdbc:hive2://node:10000
#接下来会开始输入hive的启动用户名密码,然后就可以开始连接了
这是beeline客户端界面

这时hive的原生界面

DataGrip连接
这种第三方的客户端页面美观大方 , 操作简洁 , 更重要的是sql编辑环境优雅 , sql语法智能提示补全 , 关键字高亮 , 查询结果智能显示 , 按钮操作大于命令操作
接下来是具体的连接步骤
打开DataGrip
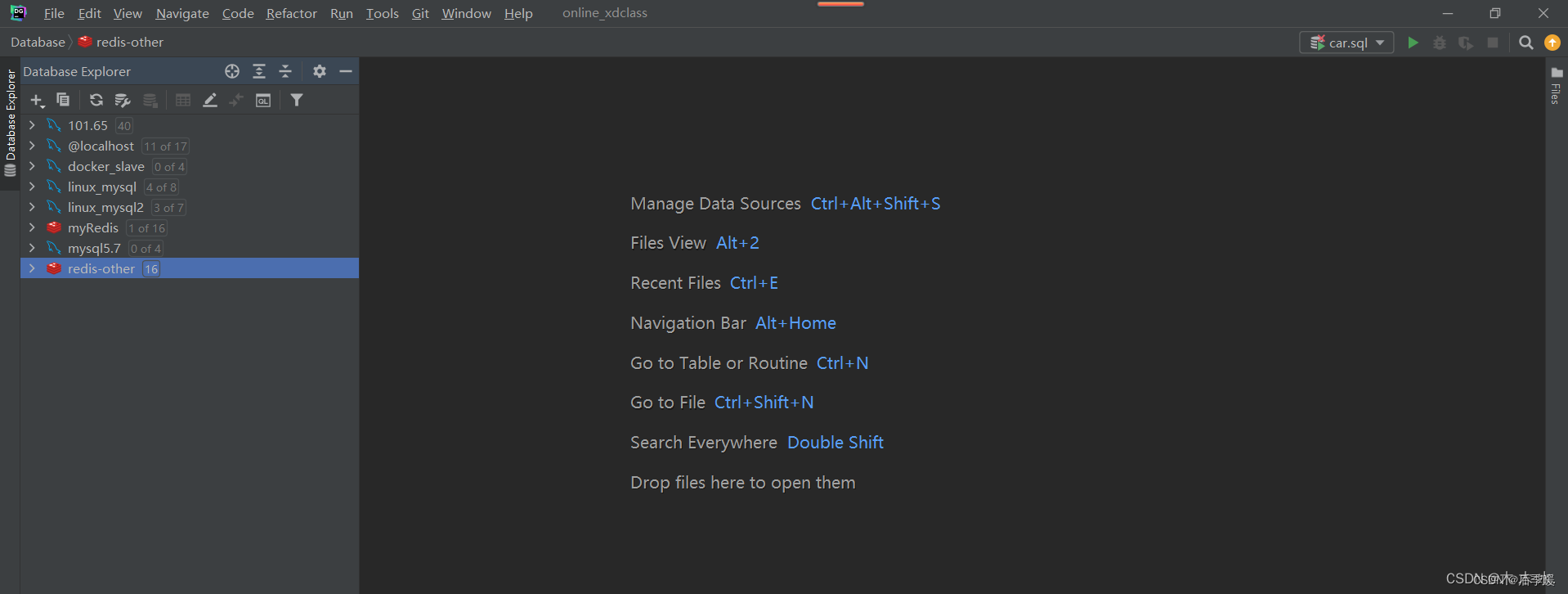
选择Apach Hive进行连接

填写相关信息
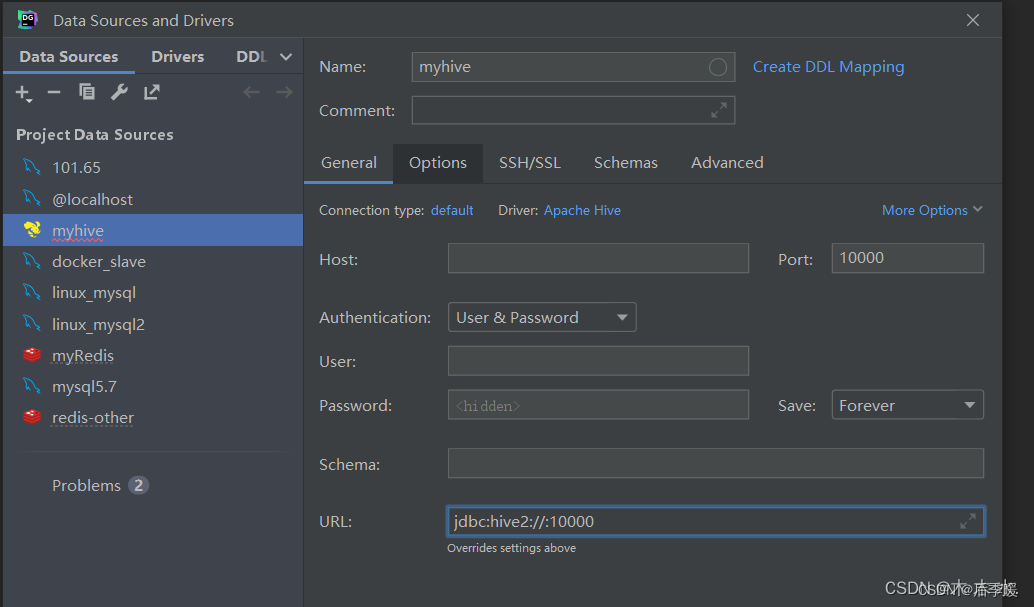
连上后的操作就跟平常操作mysql一样了。
Hive on Spark
spark和hive本质上是没有关系的,两者可以互不依赖。但是在企业实际应用中,经常把二者结合起来使用。而业界spark和hive结合使用的方式,主要有以下三种:
-
hive on spark。在这种模式下,数据是以table的形式存储在hive中的,用户处理和分析数据,使用的是hive语法规范的 hql (hive sql)。 但这些hql,在用户提交执行时(一般是提交给hiveserver2服务去执行),底层会经过hive的解析优化编译,最后以spark作业的形式来运行。事实上,hive早期只支持一种底层计算引擎,即mapreduce,后期在spark 因其快速高效占领大量市场后,hive社区才主动拥抱spark,通过改造自身代码,支持了spark作为其底层计算引擎。目前hive支持了三种底层计算引擎,即mr, tez和spark.用户可以通过set hive.execution.engine=mr/tez/spark来指定具体使用哪个底层计算引擎。
-
spark on hive。上文已经说到,spark本身只负责数据计算处理,并不负责数据存储。其计算处理的数据源,可以以插件的形式支持很多种数据源,这其中自然也包括hive。当我们使用spark来处理分析存储在hive中的数据时,这种模式就称为为 spark on hive。这种模式下,用户可以使用spark的 java/scala/pyhon/r 等api,也可以使用spark语法规范的sql ,甚至也可以使用hive 语法规范的hql 。而之所以也能使用hql,是因为 spark 在推广面世之初,就主动拥抱了hive,通过改造自身代码提供了原生对hql包括hive udf的支持(其实从技术细节来将,这里把hql语句解析为抽象语法书ast,使用的是hive的语法解析器,但后续进一步的优化和代码生成,使用的都是spark sql 的catalyst),这也是市场推广策略的一种吧。
-
spark + spark hive catalog。这是spark和hive结合的一种新形势,随着数据湖相关技术的进一步发展,这种模式现在在市场上受到了越来越多用户的青睐。其本质是,数据以orc/parquet/delta lake等格式存储在分布式文件系统如hdfs或对象存储系统如s3中,然后通过使用spark计算引擎提供的scala/java/python等api或spark 语法规范的sql来进行处理。由于在处理分析时针对的对象是table, 而table的底层对应的才是hdfs/s3上的文件/对象,所以我们需要维护这种table到文件/对象的映射关系,而spark自身就提供了 spark hive catalog来维护这种table到文件/对象的映射关系。注意这里的spark hive catalog,其本质是使用了hive 的 metasore 相关 api来读写表到文件/对象的映射关系(以及一起其他的元数据信息)到 metasore db如mysql, postgresql等数据库中。(由于spark编译时可以把hive metastore api等相关代码一并打包到spark的二进制安装包中,所以使用这种模式,我们并不需要额外单独安装hive);
-
Hive 2.0 之后,MR执行引擎已经出于deprecated 状态,“It may be removed without further warning.”,hive官方推荐使用的是 hive on tez 或 hive on spark; Hiv3.0 之后, hive官方推荐使用的是 hive on tez,并在Hive4.0中,移除了 hive on spark;
概括起来,SparkOnHive和 HiveOnSpark的核心区别:
- 不在于是否访问HIVE数仓中的数据(二者都访问);
- 也不在于客户端的SQL语法规范是 HIVE SQL 还是 SPARK SQL(Spark支持绝大部分HiveSqly语法);
- 二者的核心区别在于,客户端的 SQL 是否提交给了服务角色 HiveServer2 (org.apache.hive.service.server.HiveServer2),且该hs2配置了 hive.execution.engine=spark;
Spark SQL gateway 的解决方案-Kyuubi
•HiveServer2 本质上是 HIVE 提供的 SQL gateway服务;
•Spark原生提供的 SQL gateway 服务,只有 spark thrift Server($SPARK_HOME/sbin/start-thriftserver.sh) ,但因为功能和稳定性等各种原因,不推荐在生产环境使用($SPARK_HOME/bin/spark-sql 只是一个spark 应用,不是服务);
•网易的开源组件 Kyuubi,起到了 Spark SQL gateway服务的角色,该项目目前已经是 Apache 顶级开源项目,可以在生产环境使用;
相关文章:
Flink GateWay、HiveServer2 和 hive on spark
Flink SQL Gateway简介 从官网的资料可以知道Flink SQL Gateway是一个服务,这个服务支持多个客户端并发的从远程提交任务。Flink SQL Gateway使任务的提交、元数据的查询、在线数据分析变得更简单。 Flink SQL Gateway的架构如下图,它由插件化的Endpoi…...
)
阿里云国际设置黑白名单(针对高防实例IP)
DDoS高防支持针对高防实例设置黑名单和白名单,以拦截或放行指定IP的访问请求,配置后对该实例所有的业务生效。本文九河云介绍如何配置黑白名单。 功能介绍 黑名单IP的访问流量将被DDoS高防实例直接丢弃。白名单IP的访问流量将被DDoS高防实例直接放行。…...

Docker 入门使用说明
Docker 入门使用说明 Docker 安装 Docker 官网:Docker Docker 安装说明:Docker 安装说明 这里由于 Docker 在实时更新,所以每次安装 Docker 用来导入 key 的链接可能会有变化,这里就参考官方的安装方法即可 Docker 常用命令说…...
UE5 LiveLink 自动连接数据源,以及打包后不能收到udp消息的解决办法
为什么要自动连接数据源,因为方便打包后接收数据,这里我是写在了Game Instance,也可以写在其他地方,自行替换成Beginplay和Endplay 关于编辑器模式下能收到udp消息,打包后不能收到消息的问题有两点需要排查,启动打包后…...

国内ip切换是否合规?
在网络使用中,IP地址切换是一种常见的行为,可以用于实现隐私保护、访问地域限制内容等目的。然而,对于国内用户来说,IP地址切换是否合规一直是一个备受关注的话题。在中国,网络管理严格,一些IP切换行为可能…...

Flutter 3.13 之后如何监听 App 生命周期事件
在 Flutter 中,您可以监听多个生命周期事件来处理应用程序的不同状态,但今天我们将讨论 didChangeAppLifecycleState 事件。每当应用程序的生命周期状态发生变化时,就会触发此事件。可能的状态有 resumed 、 inactive 、 paused 、 detached …...

基于docker创建深度学习开发环境
基于docker创建深度学习开发环境 记录几个链接 第一步:配置docker环境,此处大把教程,不再赘述第二步:拉取nvidia做好的cuda和cudnn镜像: docker pull nvcr.io/nvidia/cuda:12.2.0-devel-ubuntu20.04如果有其他需求&a…...
Linux系统——硬件命令
目录 一.网卡带宽 1.查看网卡速率——ethtool 网卡名 2.查看mac地址——ethtool -P 网卡名 二、内存相关 1.显示系统中内存使用情况——free -h 2.显示内存模块的详细信息——dmidecode -t memory 三、CPU相关 1.查看CPU架构信息——lscpu 2.性能模式 四、其他硬件命…...
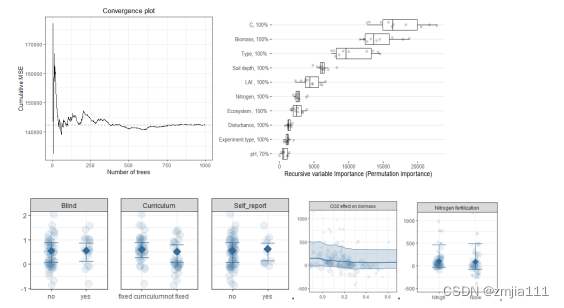
R语言Meta分析核心技术:回归诊断与模型验证
R语言作为一种强大的统计分析和绘图语言,在科研领域发挥着日益重要的作用。其中,Meta分析作为一种整合多个独立研究结果的统计方法,在R语言中得到了广泛的应用。通过R语言进行Meta分析,研究者能够更为准确、全面地评估某一研究问题…...
动态规划Dynamic Programming
上篇文章我们简单入门了动态规划(一般都是简单的上楼梯,分析数据等问题)点我跳转,今天给大家带来的是路径问题,相对于上一篇在一维中摸爬滚打,这次就要上升到二维解决问题,但都用的是动态规划思…...

详解机器学习概念、算法
目录 前言 一、常见的机器学习算法 二、监督学习和非监督学习 三、常见的机器学习概念解释 四、深度学习与机器学习的区别 基于Python 和 TensorFlow 深度学习框架实现简单的多层感知机(MLP)神经网络的示例代码: 欢迎三连哦! 前言…...
语音转文字——sherpa ncnn语音识别离线部署C++实现
简介 Sherpa是一个中文语音识别的项目,使用了PyTorch 进行语音识别模型的训练,然后训练好的模型导出成 torchscript 格式,以便在 C 环境中进行推理。尽管 PyTorch 在 CPU 和 GPU 上有良好的支持,但它可能对资源的要求较高&#x…...
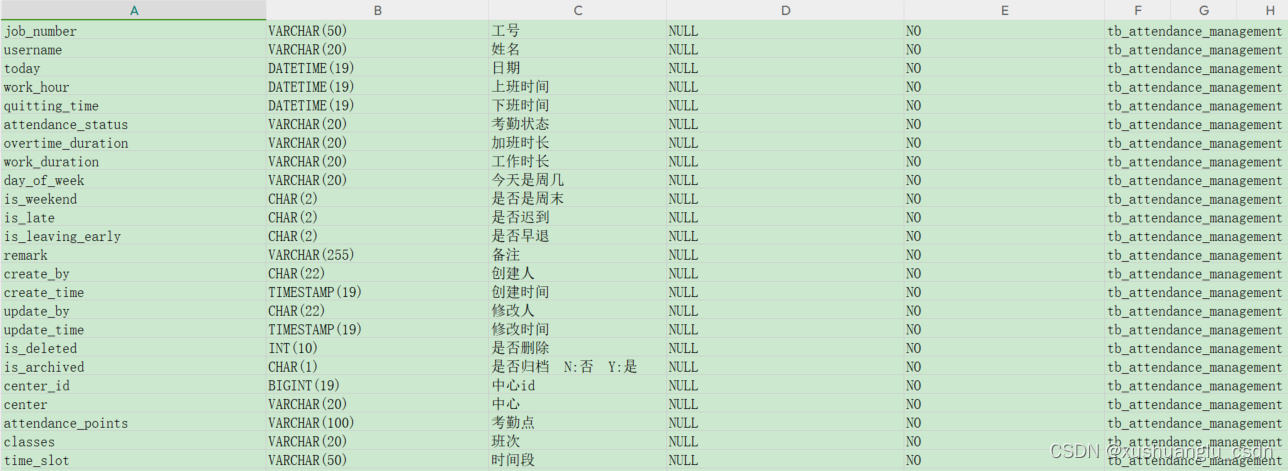
第1篇:Mysql数据库表结构导出字段到Excel(一个sheet中)
package com.xx.util;import org.apache.poi.ss.usermodel.*; import org.apache.poi.xssf.usermodel.XSSFWorkbook;import java.sql.*; import java.io.*;public class DatabaseToExcel {public static void main(String[] args) throws Exception {// 数据库连接配置String u…...

Request请求参数----中文乱码问题
一: GET POST获取请求参数: 在处理为什么会出现中文乱码的情况之前, 首先我们要直到GET 以及 POST两种获取请求参数的不同 1>POST POST获取请求参数是通过输入流getReader来进行获取的, 通过字符输入流来获取响应的请求参数, 并且在解码的时候, 默认的情况是 ISO_885…...

labelImg安装方法
labelImg安装方法(简单方法) - 知乎 (zhihu.com) 1. lableImg下载 git clone https://github.com/tzutalin/labelImg.git 2. 制作lableImg所需的"condapython"环境(conda需要先安装,最好再设置下下载源) 打开Anaconda Prompt对话框 # 创建环境 conda create -n …...
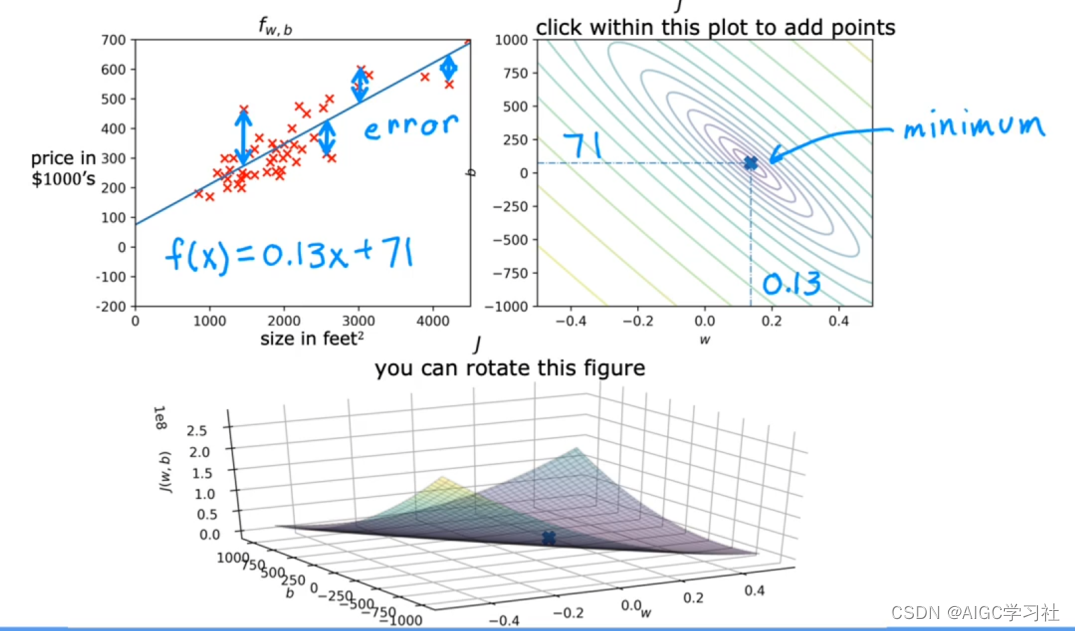
吴恩达2022机器学习专项课程(一) 3.6 可视化样例
问题预览 1.本节课主要讲的是什么? 2.不同的w和b,如何影响线性回归和等高线图? 3.一般用哪种方式,可以找到最佳的w和b? 解读 1.课程内容 设置不同的w和b,观察模型拟合数据,成本函数J的等高线…...

C#入门及进阶教程|Windows窗体属性及方法
1.Windows窗体 窗体本身是一个对象,对应于System.Windows.Forms名称空间的Form类。它有自己的属性、方法和事件,用于控制窗体的外观和行为。窗体又是各种控件的容器,用于容纳各种窗体控件。如果想生成窗体,必须从Form类派生出自己…...
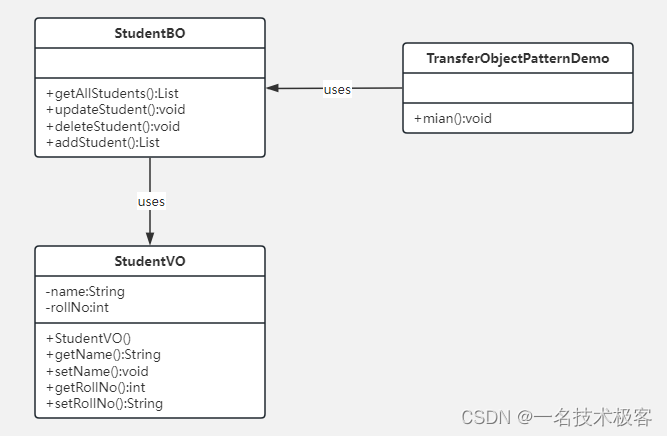
34-Java传输对象模式 ( Transfer Object Pattern )
Java传输对象模式 实现范例 传输对象模式(Transfer Object Pattern)用于从客户端向服务器一次性传递带有多个属性的数据传输对象也被称为数值对象,没有任何行为传输对象是一个具有 getter/setter 方法的简单的 POJO 类,它是可序列…...
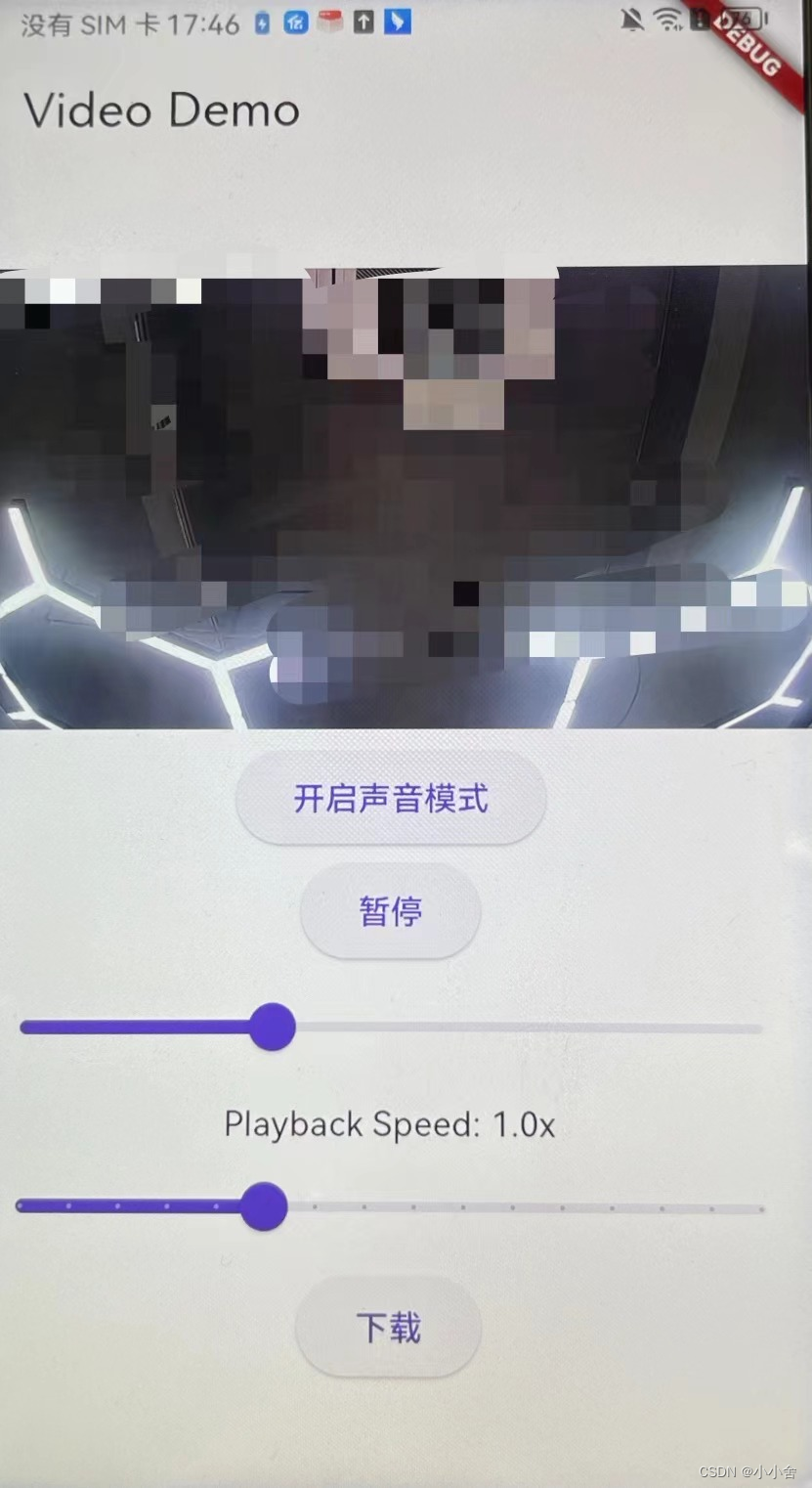
flutter实现视频播放器,可根据指定视频地址播放、设置声音,进度条拖动,下载等
需要装依赖: gallery_saver: ^2.3.2video_player: ^2.8.3 AndroidManifest.xml <uses-permission android:name"android.permission.INTERNET"/> 实现代码 import dart:async; import dart:io;import package:flutter/material.dart; import pa…...

微服务(基础篇-001-介绍、Eureka)
目录 认识微服务(1) 服务架构演变(1.1) 单体架构(1.1.1) 分布式架构(1.1.2) 微服务(1.1.3) 微服务结构 微服务技术对比 企业需求 SpringCloud(1.2) …...

多自由度冗余空间机械臂位姿一体化规划与控制【附代码】
✨ 长期致力于空间机械臂、对偶四元数、位姿一体化、路径规划、跟踪控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于对偶四元数的冗余机械臂运…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

CPU架构启发的智能仓储布局优化实践
1. 仓库布局优化的核心挑战与创新机遇在物流仓储领域,拣货环节通常占据运营成本的55%-65%,而其中约50%的时间消耗在无效行走路径上。传统矩形仓库布局虽然易于规划和施工,但其正交的通道设计导致拣货员需要频繁进行90度转向,这种&…...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...

十年以上经验的建站公司推荐|策划强、落地稳的网站制作公司盘点
互联网时代,企业官网已从单纯的信息展示窗口升级为集品牌价值传递、用户体验连接与业务高效转化于一体的核心数字阵地。行业报告显示,优质官网可帮助企业线上转化率提升35%-60%,而低效官网则可能导致潜在客户大量流失。面对市场上众多的网站建…...
)
Claude端到端测试设计终极清单:覆盖17类非功能需求(含延迟敏感度分级、幻觉熔断阈值、多轮对话状态持久化验证)
更多请点击: https://kaifayun.com 第一章:Claude端到端测试设计的演进逻辑与核心范式 Claude端到端测试并非静态产物,而是随模型能力边界拓展、交互场景复杂化及可靠性要求升级而持续演化的工程实践。其演进逻辑根植于三个关键张力…...