python爬虫之xpath入门
文章目录
- 一、前言
- 参考文档:
- 二、xpath语法-基础语法
- 常用路径表达式
- 举例说明
- 三、xpath语法-谓语
- 表达式举例
- 注意
- 四、xpath语法-通配符
- 语法
- 实例
- 五、选取多个路径
- 实例
- 六、Xpath Helper
- 安装
- 使用说明
- 例子:
- 七、python中 xpath 的使用
- 安装xpath 的依赖包
- xml节点的获取
- xpath解析 html内容
- 1. 以读取 html文件的方式进行解析
- 2、对 html的内容进行解析
一、前言
XPATH(XML Path Language),它可以在 XML 和 HTML文档中对元素和属性进行查找和遍历。
- XPath 使用路径表达式来选取 XML 文档中的节点或节点集。
- 这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常类似。
- 使用chrome 插件选择标签时候,选中时,选中的标签会添加属性class=“xh-highlight”
参考文档:
基础语法:https://www.w3school.com.cn/xpath/index.asp
python使用 xpath:https://blog.csdn.net/q1246192888/article/details/123649072
二、xpath语法-基础语法
常用路径表达式
| 表达式 | 说明 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 绝对路径,如果写在最前面则从根节点选取,否则是当前节点下的子节点 |
| // | 相对路径,和绝对路径/不同的是整个文本下的直接或间接节点,而不考虑他们的位置。 |
| . | 当前节点,类似于 linux 的当前目录 |
| .. | 当前节点的父节点,类似与 linux 的上一级目录 |
| text() | 一个开闭标签之间的文本内容 |
| @ | 某个节点标签内的属性 |
举例说明
- footer: 获取 footer 节点下的所有子节点
- /title: 根节点下所有title 标签
- //div:根节点下所有的div 标签
- ./div[@class=test-class].text():当前节点下,属性class=test-class的所有div 的文本内容
- ./div[@id=test-id]…//a.text(): 当前节点下,属性id=test-id的div的 所有上一级a 标签的文本内容
三、xpath语法-谓语
可以根据标签的属性值、下标等来获取特定的节点
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
表达式举例
| 路径表达式 | 结果 |
|---|---|
| //title[@lang=“eng”] | 选择lang 属性值为 eng 的所有 title元素 |
| //bookstore/book[1] | 选取属于 bookstore 子元素的第一个book 元素 |
| //bookstore/book[last()] | 选取属于 bookstore子元素的最后一个 book 元素 |
| //bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素 |
| //bookstore/book[position()>1] | 选择所有 bookstore 下面的 book元素,从第二个开始选择 |
| //book/title[text()=‘Harry Potter’] | 选择所有 book下的title元素,仅仅选择文本为 Harry Potter 的 title 元素 |
| //div[@id=“test-div-1”]/span | 选择 id="test-div-1"下的 div下的所有 span 节点 |
| /bookstore/book[price>35]/title | 选取 bookstore元素的所有 title节点,且其中的 price 子节点的值必须大于35 |
| //div[@id=“test-container”]/span/@class | 找到 id="test-container"的div下 的 span节点的所有class的值 |
| //span[i>2000] | 找到所有 span 节点,且其中的 i子节点的text()大于2000 |
| //div[span[2]>=9.4] | 找到所有的 div 节点,且子节点中第二个 span 的text()内容大于9.4 |
| //div[contains(@id,“test_div_”)] | 找到所有 div节点,且id包含了"test_div_" |
| //div[@class=“pagination”]//span[contains(text(),“下一页”)] | 先找到class="pagination"的 div,再找其子节点span,且文本内容包下一页 |
注意
- 只要涉及到条件的加[],只要涉及到加属性值加@
- 凡事 /text(),/@ 加在最后,是取值,取的是前面
标签的属性值 - text(),@ 加在
[]中,则是修饰符,表示使用标签的属性名或属性值 来筛选节点, - xpath 的索引下标是从1开始
- 常用函数 text()取标签之间的文本,contains(属性,“内容”)表示某节点属性包含的内容
四、xpath语法-通配符
xpath 的通配符用来选取未知的 html/xml 元素
语法
| 通配符 | 说明 |
|---|---|
| * | 匹配任何的元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型的节点 |
实例
| 路径表达式 | 说明 |
|---|---|
| /bookstore/* | 选取bookstore节点下的所有子节点 |
| //* | 选取文档中的所有文档 |
| //tittle[@*] | 选取所有带有属性的 title元素 |
五、选取多个路径
通过 xpath 的运算符|,选取多个路径,表示多个路径的并集
实例
| 路径表达式 | 说明 |
|---|---|
| //book/title | //book/price | 选取 book元素下的所有title和 price元素 |
| //title | //price | 选取文档中的所有title和 price元素 |
| /bookstore/book/title | //price | 选取属于 bookstore节点下 book 节点下的所有 title节点 以及文档中所有的 price 元素 |
六、Xpath Helper
Xpath Helper是一个免费的 chrom插件,是用来方便调试 xpath 用的,可以提高效率,由日本的一名程序员开发,只是目前只有外网可以访问。
我是使用了CMYNetwork加速器 VPN通道来进行安装。当然往上免费的也可以下载到。
扩展链接地址
注:VPN节点最好选择美国的节点
安装
使用说明
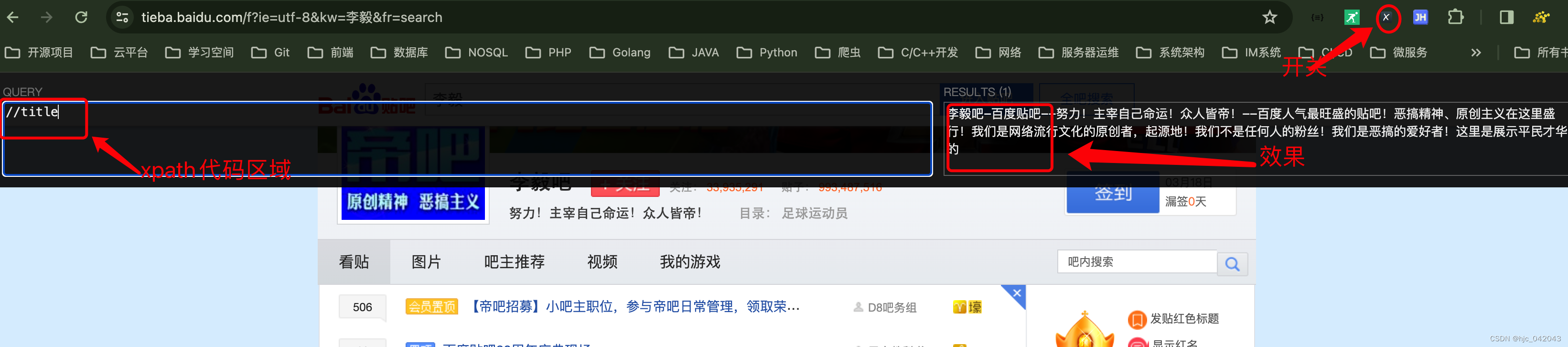
- 打开一个任意网站,百度贴吧为例,https://tieba.baidu.com/p/8940673717
- 可以在浏览器的右上角点击图标按钮,或按下 Ctrl+Shift+X快捷键(mac os 上是 Command+Shift+X)就可以开启 xpath helper,如下图
左侧区域显示的是 xpath 语法来筛选,右侧区域就来显示效果。
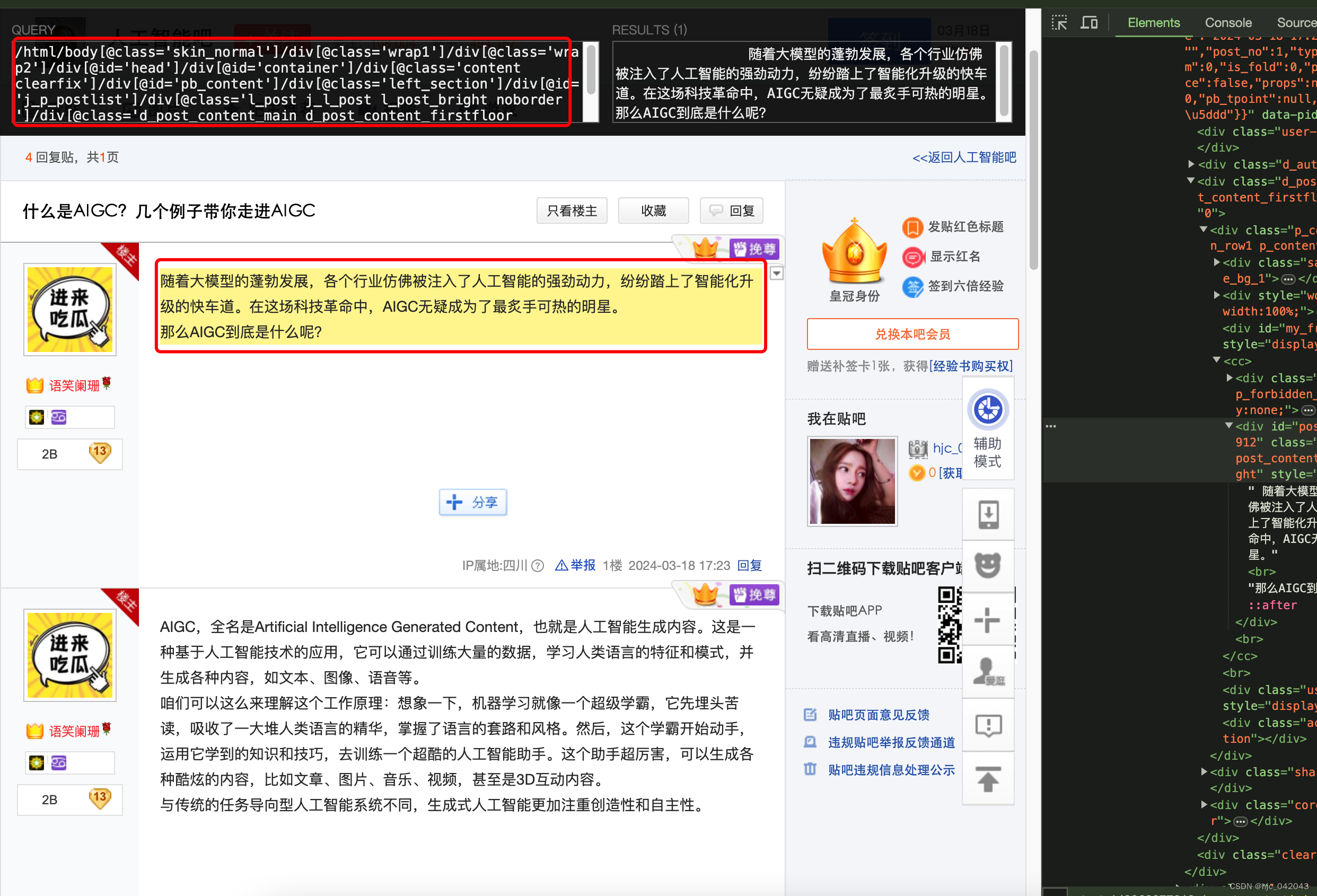
- 查找某一个或某一块节点元素的 xpath,可以按 Shift键,将鼠标移动到指定节点元素的位置就可以看到xpath了
- 也可以在右键—>检查,选择具体的节点,然后右键—>Copy—>Copy Xpath
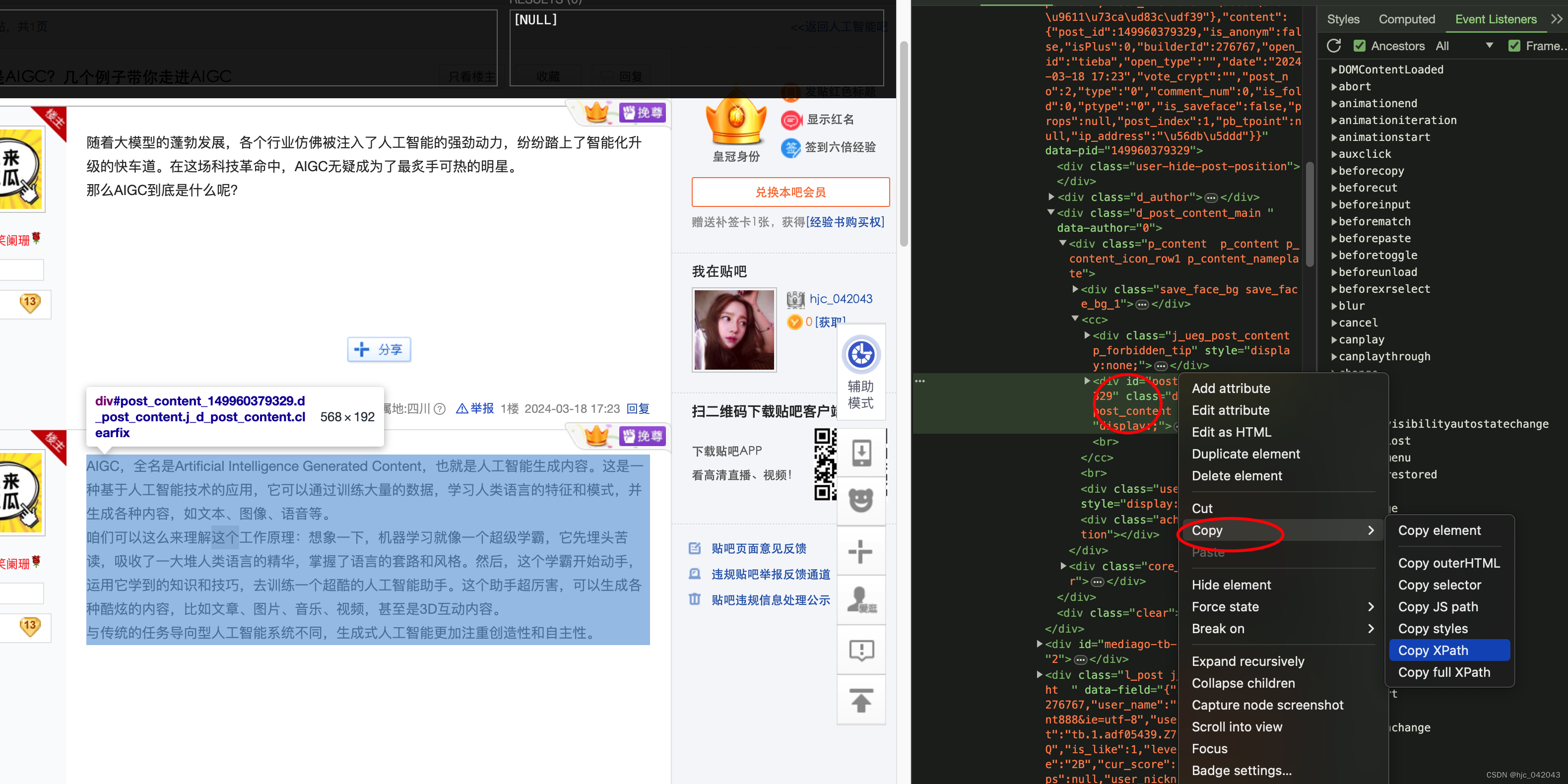
将 copy的xpath复制到 xpath helper的查询框,就可以看结果是否正确了
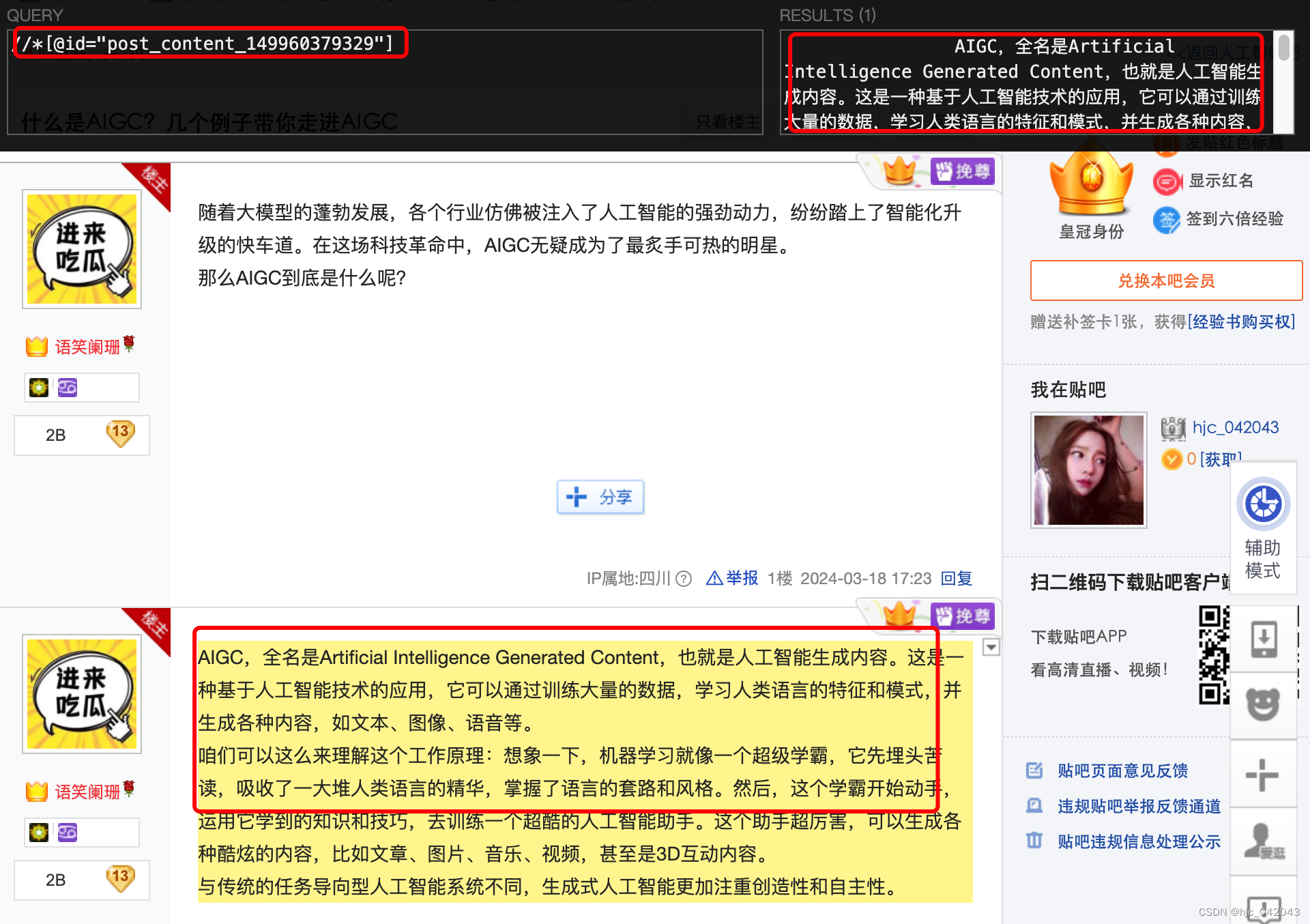
例子:
- 以查看人工智能贴吧的某一条内容为例子:
<!--查看 class="d_post_content_main"节点下的 id="post_content_149887537934"节点的内容-->
//div[@class="d_post_content_main"]//div[@id="post_content_149887537934"]
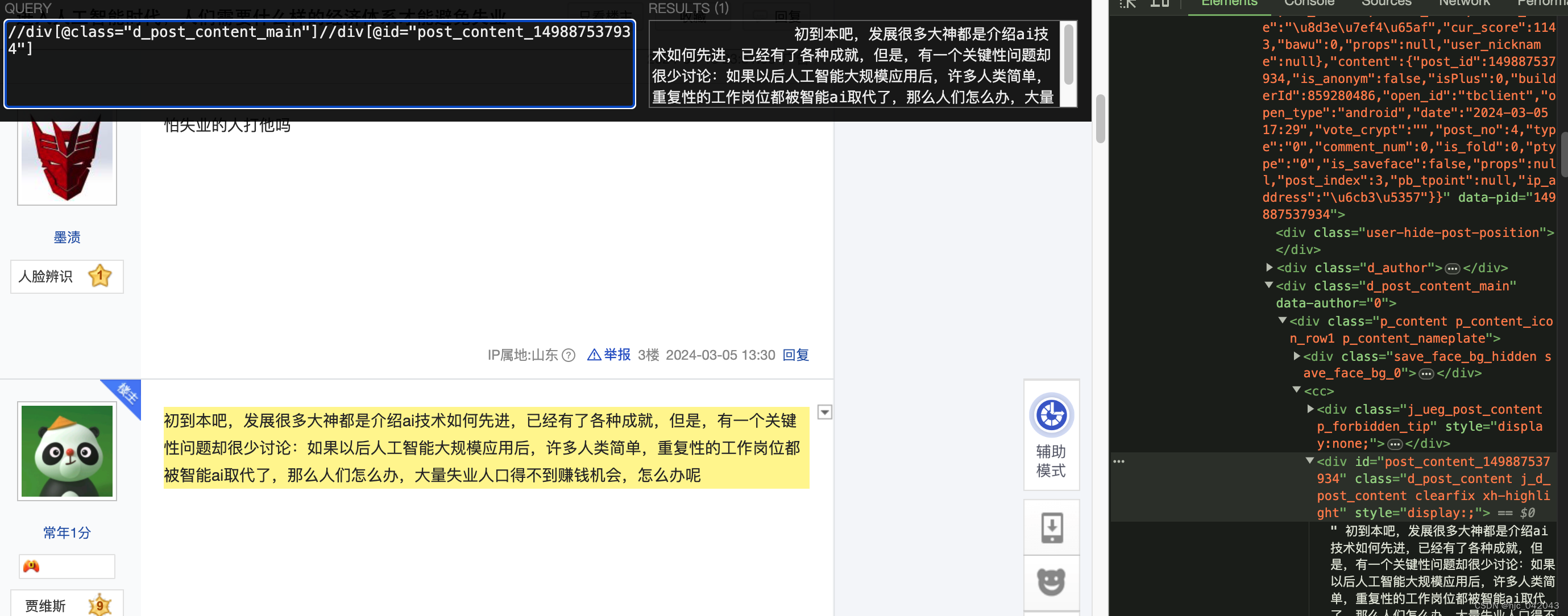
- 查看分页
如下是来查找分页的 下一页的href的链接值
//div[@id="thread_theme_5"]//ul[@class="l_posts_num"]//a[text()="下一页"]/@href
七、python中 xpath 的使用
安装xpath 的依赖包
pip install lxml
xml节点的获取
源码上 xml 解析的源码,https://gitee.com/allen-huang/python/blob/master/crawler/do-parse/test_xml_xpath.py
- xml 文件的内容
<?xml version="1.0" encoding="UTF-8" ?>
<root><head><title>xml的 xpath 测试</title></head><bookstore><book><title lang="zh">图解 HTTP 协议</title><price>59</price></book><book><title lang="zh">网络爬虫开发实战</title><price>139</price></book></bookstore>
</root>
- xml的解析文本内容
def test_xml(self):tree = etree.parse('book.xml')# 获取 head 节点下的 title 节点的文本内容print(tree.xpath('head/title/text()'))# 获取 bookstore 节点下的 book 的内容for element in tree.xpath('//bookstore'):# 当前节点下的 book 节点的 title 节点的文本内容print(element.xpath('book/title/text()'))# 当前节点下的 book 节点的 price 节点的文本内容print(element.xpath('book/price/text()'))pass
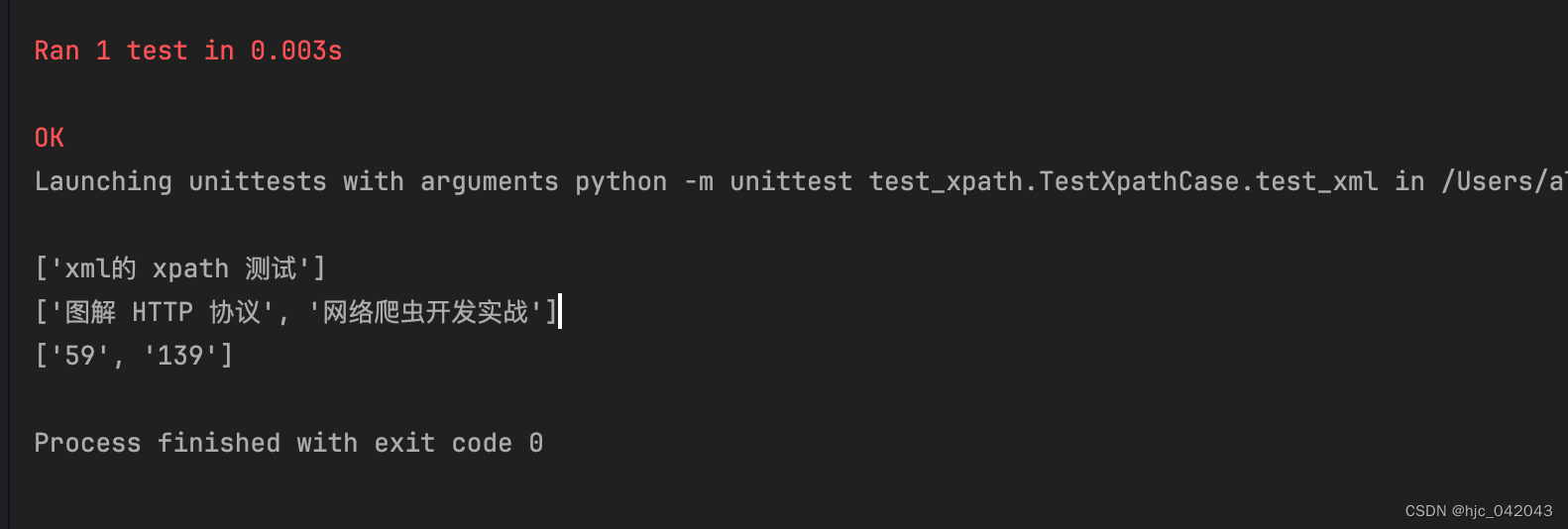
- xml的属性筛选
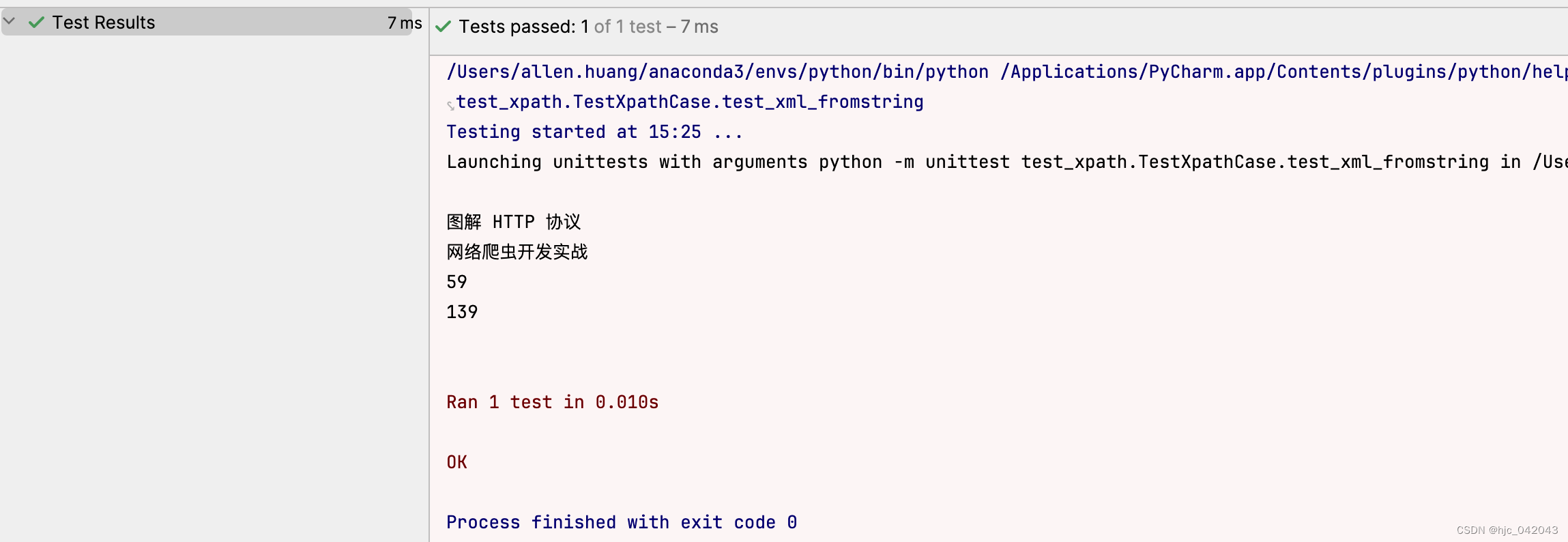
def test_xml_fromstring(self):"""加载 xml 字符串,筛选属性的所有 title 的节点内容@return:"""xml_str = """<root><head><title>xml的 xpath 测试</title></head><bookstore><book><title lang="zh">图解 HTTP 协议</title><price>59</price></book><book><title lang="zh">网络爬虫开发实战</title><price>139</price></book></bookstore></root>"""tree = etree.fromstring(xml_str)title_nodes = tree.xpath("//title[@lang='zh']")for node in title_nodes:print(node.text)price_nodes = tree.xpath("//price")for node in price_nodes:print(node.text)pass
xpath解析 html内容
解析 html的内容的源码地址:https://gitee.com/allen-huang/python/blob/master/crawler/do-parse/test_html_xpath.py
1. 以读取 html文件的方式进行解析
文件也一同放在码云上,book.html
读取一个html文档,需要是标准的html,对于标签不全的html,就会报错,而HTML()会修复html的标签
- html文件的结构
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta http-equiv="content-type" content="text/html; charset=utf-8"/><title>豆瓣阅读</title>
</head>
<body>
<div class="bookstore-container"><ul class="bookstore-list"><li id="book-1" class="bookstore-item"><a href="https://read.douban.com/reader/ebook/52497819/" class="bookstore-cover"><div class="bookstore-info"><div class="title">Java高并发编程:多线程与架构设计</div><div class="author">王文君</div><div class="price">59.00</div><div class="score">8.7</div><div class="publisher">机械工业出版社</div></div></a></li><li id="book-2" class="bookstore-item"><a href="https://read.douban.com/reader/ebook/153139284/" class="bookstore-cover"><div class="bookstore-info"><div class="title">Java高并发编程详情</div><div class="author">王文君</div><div class="price">55.00</div><div class="score">8.2</div><div class="publisher">机械工业出版社</div></div></a></li><li id="book-3" class="bookstore-item"><a href="https://read.douban.com/reader/ebook/128052544/" class="bookstore-cover"><div class="bookstore-info"><div class="title">深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)</div><div class="author">周志明</div><div class="price">99</div><div class="score">9.4</div><div class="publisher">机械工业出版社</div></div></a></li></ul>
</div>
</body>
</html>
- 单元测试中的前置操作,设置共用对象
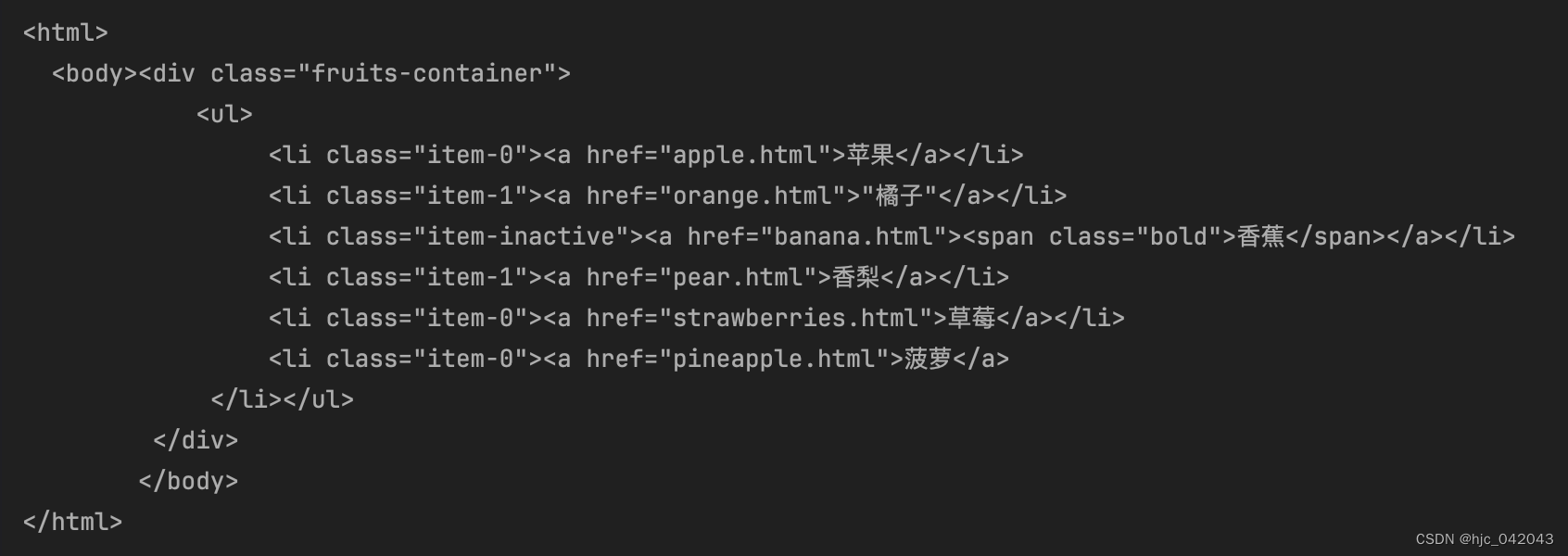
def setUp(self):"""前置操作@todo 1.将一个html文件转化成html对象,etree.parse()默认只能读取一个标准的html文档,对于标签不全的html,需要加上etree.HTMLParser(),否则就会报错,而使用HTML()会修复html的标签@todo 2.将html字符串转化成html对象,并使用etree.HTML()读取@return:"""# 从本地文件中读取 book.html 文档,并使用标准的html解析器self.html_load = etree.parse("book.html", etree.HTMLParser())# 这里在末尾特意少了一个</li>,用来测试,最后是否自动补全self.html_str = """<div class="fruits-container"><ul><li class="item-0"><a href="apple.html">苹果</a></li><li class="item-1"><a href="orange.html">"橘子"</a></li><li class="item-inactive"><a href="banana.html"><span class="bold">香蕉</span></a></li><li class="item-1"><a href="pear.html">香梨</a></li><li class="item-0"><a href="strawberries.html">草莓</a></li><li class="item-0"><a href="pineapple.html">菠萝</a></ul></div>"""pass
- 将 Element对象转为字符串
def test_tostring(self):"""获取 html中的最外层的div标签@return:"""html_div = self.html_load.xpath('//div[@class="bookstore-container"]')print(html_div)# 将 html对象转换成字符串是 bytes 类型,并且格式化输出,并进行解码print(etree.tostring(html_div[0], pretty_print=True, encoding="utf-8").decode())pass

- 解析获取豆瓣读书的基本信息:
通过 xpath 将书的链接,书名,作者等存入到 mongodb 中
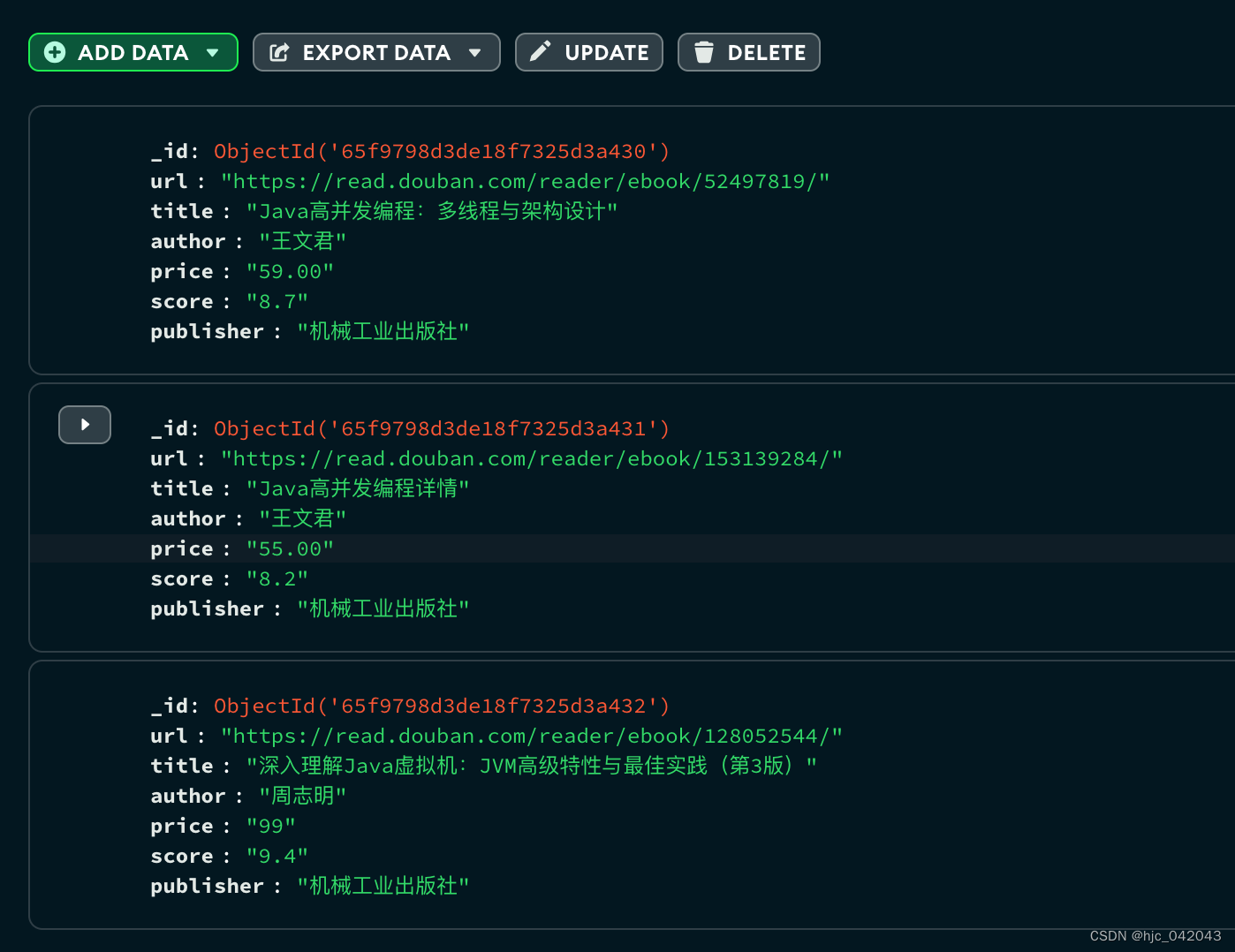
def test_load_file(self):"""获取 html中所有的li标签@return:"""html_li = self.html_load.xpath('//li[@class="bookstore-item"]')# 遍历 class="bookstore-item" 的所有li标签book_list = []for key, li in enumerate(html_li):# 获取当前li标签下的a标签的href属性url = li.xpath("./a/@href")# 获取当前li 标签下的 div=title的文本内容title = li.xpath(".//div[@class='title']/text()")# 获取当前 li 标签下的 div=author的文本内容author = li.xpath(".//div[@class='author']/text()")# 获取当前li 标签下的 div=price的文本内容price = li.xpath(".//div[@class='price']/text()")# 获取当前li 标签下的 div=score的文本内容score = li.xpath(".//div[@class='score']/text()")# 获取当前li 标签下的 div=publisher的文本内容publisher = li.xpath(".//div[@class='publisher']/text()")book_dict = {# "_id": key, # 主键"url": Tools.get_list_element(url, 0),"title": Tools.get_list_element(title, 0),"author": Tools.get_list_element(author, 0),"price": Tools.get_list_element(price, 0),"score": Tools.get_list_element(score, 0),"publisher": Tools.get_list_element(publisher, 0)}book_list.append(book_dict)# 格式化打印数据pprint(book_list)# 将数据存入到 mongodb中res = MongoPool().test.bookstore.insert_many(book_list)print(res.inserted_ids)
- 结果:

- mongo 的数据
2、对 html的内容进行解析
这是直接使用 etree.HTML()进行分析,它一般是来解析来自远程响应的内容,并自带修复 html 标签的功能
- html的结构
<div class="fruits-container"><ul><li class="item-0"><a href="apple.html">苹果</a></li><li class="item-1"><a href="orange.html">"橘子"</a></li><li class="item-inactive"><a href="banana.html"><span class="bold">香蕉</span></a></li><li class="item-1"><a href="pear.html">香梨</a></li><li class="item-0"><a href="strawberries.html">草莓</a></li><li class="item-0"><a href="pineapple.html">菠萝</a></ul></div>
- 代码:
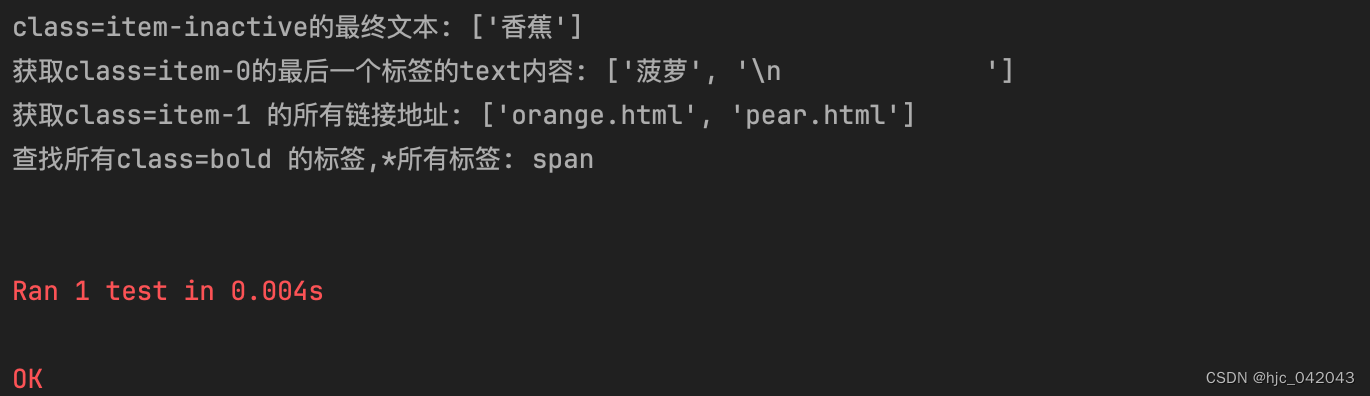
def test_parse_html(self):"""使用 etree.HTML() 解析 html 文档etree.HTML() 会修复 html 标签,并且将 html 转化成 html 对象@return:"""html = etree.HTML(self.html_str)print(etree.tostring(html, pretty_print=True, encoding="utf-8").decode())# 获取class=item-inactive的 标签最终的 text 内容text_list = html.xpath('//li[@class="item-inactive"]//text()')print(text_list)# 获取class=item-0 的最后一个标签的 text 内容itme0_last_text = html.xpath('//li[@class="item-0"][last()]//text()')print(itme0_last_text)# 获取class=item-1 的所有链接地址item1_href = html.xpath('//li[@class="item-1"]//a/@href')print(item1_href)# 查找所有class=bold 的标签,*所有标签bold_info = html.xpath('//*[@class="bold"]')# 将 bold_tag 转化成字符串print(etree.tostring(bold_info[0], pretty_print=True, encoding="utf-8").decode())print(bold_info[0].tag)pass
经过测试,打印出来的内容,自动补全为标准化 html
解析的结果:
相关文章:
python爬虫之xpath入门
文章目录 一、前言参考文档: 二、xpath语法-基础语法常用路径表达式举例说明 三、xpath语法-谓语表达式举例注意 四、xpath语法-通配符语法实例 五、选取多个路径实例 六、Xpath Helper安装使用说明例子: 七、python中 xpath 的使用安装xpath 的依赖包xm…...
TikTok云手机是什么原理?
社交媒体的快速发展和普及,TikTok已成为全球最受欢迎的短视频平台之一,吸引了数以亿计的用户。在TikTok上,许多用户和内容创作者都希望能够更灵活地管理和运营多个账号,这就需要借助云手机技术。那么,TikTok云手机究竟…...

24.3.24 《CLR via C#》 笔记10
第十三章 接口 类和接口继承 CLR不支持多继承,因此所有托管编程语言都不支持任何类都从且只能从一个类派生(最终从Object类派生)定义接口实际只是对一组方法进行了统一的命名,类通过指定接口名称来继承接口,且必须显式…...
SpringBoot 3整合Elasticsearch 8
这里写自定义目录标题 版本说明spring boot POM依赖application.yml配置新建模型映射Repository简单测试完整项目文件目录结构windows下elasticsearch安装配置 版本说明 官网说明 本文使用最新的版本 springboot: 3.2.3 spring-data elasticsearch: 5.2.3 elasticsearch: 8.1…...
)
突破编程_C++_查找算法(分块查找)
1 算法题 :使用分块算法在有序数组中查找指定元素 1.1 题目含义 在给定一个有序数组的情况下,使用分块查找算法来查找数组中是否包含指定的元素。分块查找算法是一种结合了顺序查找和二分查找思想的算法,它将有序数组划分为若干个块&#x…...

学习java第二十二天
IOC 容器具有依赖注入功能的容器,它可以创建对象,IOC 容器负责实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。通常new一个实例,控制权由程序员控制,而"控制反转"是指new实例工作不由程序员来做而是交给Sp…...

每天学习一个Linux命令之systemctl
每天学习一个Linux命令之systemctl 介绍 在Linux系统中,systemctl命令是Systemd初始化系统的核心管理工具之一。systemd是用来启动、管理和监控运行在Linux上的系统的第一个进程(PID 1),它提供了一整套强大的工具和功能…...

【机器学习入门】人工神经网络(二)卷积和池化
系列文章目录 第1章 专家系统 第2章 决策树 第3章 神经元和感知机 识别手写数字——感知机 第4章 线性回归 第5章 逻辑斯蒂回归和分类 第5章 支持向量机 第6章 人工神经网络(一) 文章目录 系列文章目录前言一、卷积神经连接的局部性平移不变性 二、卷积处理图像的效果代码二、…...

公司内部局域网怎么适用飞书?
随着数字化办公的普及,企业对于内部沟通和文件传输的需求日益增长。飞书作为一款集成了即时通讯、云文档、日程管理、视频会议等多种功能的智能协作平台,已经成为许多企业提高工作效率的首选工具。本文将详细介绍如何在公司内部局域网中应用飞书…...
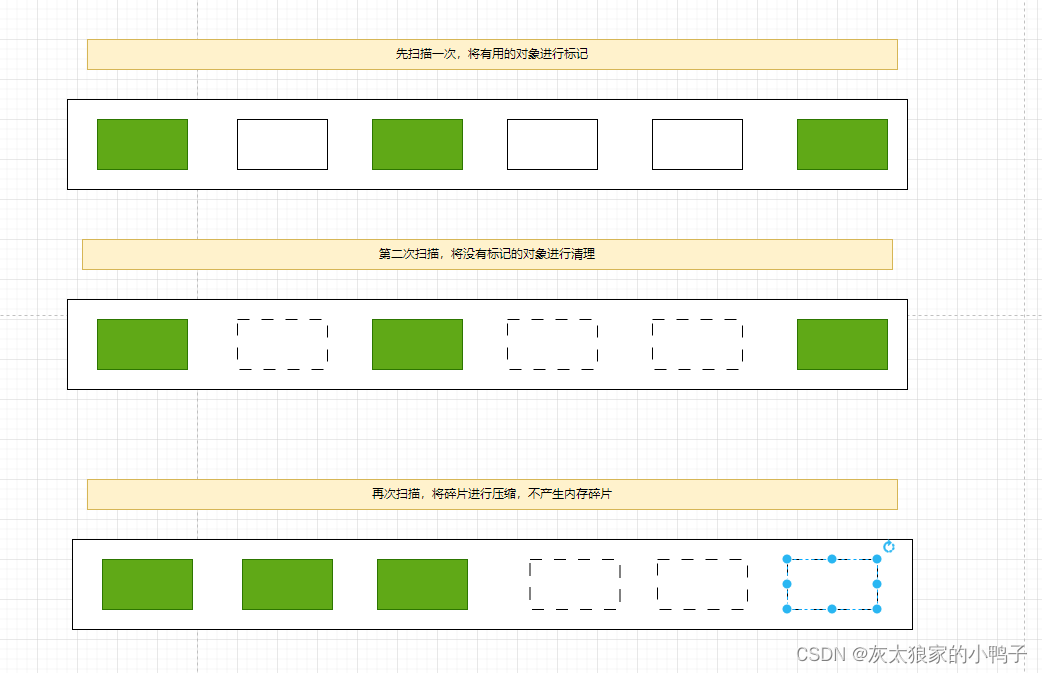
JVM的知识
什么是JVM 1.JVM: JVM其实就是运行在 操作系统之上的一个特殊的软件。 2.JVM的内部结构: (1)因为栈会将执行的程序弹出栈。 (2)垃圾99%的都是在堆和方法区中产生的。 类加载器:加载class文件。…...

大模型日报2024-03-24
利用LLMs评分及解释K-12科学答案 摘要: 本文研究了在K-12级科学教育中使用大型语言模型(LLMs)对短答案评分及解释。研究采用GPT-4结合少量样本学习和活跃学习,通过人机协作提供有意义的评估反馈。 MathVerse:多模态LLM解数学题效果…...

Android kotlin全局悬浮窗全屏功能和锁屏页面全屏悬浮窗功能一
1.前言 在进行app应用开发中,在实现某些功能中要求实现悬浮窗功能,分为应用内悬浮窗 ,全局悬浮窗和 锁屏页面悬浮窗功能 等,接下来就来实现这些悬浮窗全屏功能,首选看下第一部分功能实现 2.kotlin全局悬浮窗全屏功能和锁屏页面全屏悬浮窗功能一分析 悬浮窗是属于Androi…...

图像识别在安防领域的应用
图像识别技术在安防领域有着广泛的应用,它通过分析和理解图像中的视觉信息,为安防系统提供了强大的辅助功能。以下是一些主要的应用领域: 人脸识别:人脸识别技术是安防领域中最常见的应用之一。它可以帮助系统识别和验证个人身份…...

前端面试集中复习 - http篇
1. http请求方式 HTTP请求方式有哪些:GET POST PUT DELETE OPTIONS 1) GET POST 的区别? 场景上: GET 用于获取资源而不对服务器资源做更改提交的请求,多次执行结果一致。用于获取静态数据,幂等。 POST࿱…...
C++ - 类和对象(上)
目录 一、类的定义 二、访问限定符 public(公有) protected(保护) private(私有) 三、类声明和定义分离 四、外部变量和成员变量的区别与注意 五、类的实例化 六、类对象的模型 七、类的this指针…...

mysql基础4sql优化
SQL优化 插入数据优化 如果我们需要一次性往数据库表中插入多条记录,可以从以下三个方面进行优化。 insert into tb_test values(1,tom); insert into tb_test values(2,cat); insert into tb_test values(3,jerry);-- 优化方案一:批量插入数据 Inser…...

实现Spring Web MVC中的文件上传功能,并处理大文件和多文件上传
实现Spring Web MVC中的文件上传功能,并处理大文件和多文件上传 在Spring Web MVC中实现文件上传功能并处理大文件和多文件上传是一项常见的任务。下面是一个示例,演示如何在Spring Boot应用程序中实现这一功能: 添加Spring Web依赖&#x…...
搭建vite项目
文章目录 Vite 是一个基于 Webpack 的开发服务器,用于开发 Vue 3 和 Vite 应用程序 一、创建一个vite项目二、集成Vue Router1.安装 vue-routernext插件2.在 src 目录下创建一个名为 router 的文件夹,并在其中创建一个名为 index.js 的文件。在这个文件中…...

Docker 安装mysql 主从复制
目录 1 MySql主从复制简介 1.1 主从复制的概念 1.2 主从复制的作用 2. 搭建主从复制 2.1 pull mysql 镜像 2.2 新建主服务器容器实例 3307 2.2.1 master创建 my.cnf 2.2.2 重启master 2.2.3 进入mysql 容器,创建同步用户 2.3 新建从服务器容器实例 3308…...

GPT每日面试题—如何实现二分查找
充分利用ChatGPT的优势,帮助我们快速准备前端面试。今日问题:如何实现二分查找? Q:如果在前端面试中,被问到如何实现二分查找,如果回答比较好,给出必要的代码示例 A:当被问到如何实…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

基于双T振荡器的正弦波LED调光电路设计与实践
1. 项目概述:用双T振荡器实现正弦波LED调光最近在捣鼓一些氛围灯项目,总感觉用单片机PWM做的呼吸灯效果有点“硬”,那种线性的明暗变化看久了难免审美疲劳。于是翻出以前模拟电路的老本行,琢磨着能不能用纯硬件的方式,…...

如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南
如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download 在数字时代,百度网盘已成为我们存储和分享大型文件的默认…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案
OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 在惠…...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...

国内大学生常用的AI写作辅助平台有哪些?
国内高校学生常用的 AI 写作辅助平台,以本土化全流程工具为主,结合通用大模型与专项功能模块,覆盖选题构思、大纲搭建、初稿撰写、语言润色、降重处理、查重检测及格式排版等关键环节,以下是主流平台详解与对比: 一、本…...

抖音内容批量下载实战:从零开始构建个人视频资料库
抖音内容批量下载实战:从零开始构建个人视频资料库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...