数据结构面试题
1、数据结构三要素?
逻辑结构、物理结构、数据运算
2、数组和链表的区别?
- 数组的特点: 数组是将元素在内存中连续存放,由于每个元素占用内存相同,可以通过下标迅速访问数组中任何元素。数组的插入数据和删除数据效率低,插入数据时,这个位置后面的数据在内存中都要向后移。删除数据时,这个数据后面的数据都要往前移动。但数组的随机读取效率很高。因为数组是连续的,知道每一个数据的内存地址,可以直接找到给地址的数据。如果应用需要快速访问数据,很少或不插入和删除元素,就应该用数组。数组需要预留空间,在使用前要先申请占内存的大小,可能会浪费内存空间。并且数组不利于扩展,数组定义的空间不够时要重新定义数组。
- 链表的特点: 链表中的元素在内存中不是顺序存储的,而是通过存在元素中的指针联系到一起。比如:上一个元素有个指针指到下一个元素,以此类推,直到最后一个元素。如果要访问链表中一个元素,需要从第一个元素开始,一直找到需要的元素位置。但是增加和删除一个元素对于链表数据结构就非常简单了,只要修改元素中的指针就可以了。如果应用需要经常插入和删除元素你就需要用链表数据结构了。不指定大小,扩展方便。链表大小不用定义,数据随意增删。
- 数组的优点:随机访问性强;查找速度快。
- 数组的缺点: 插入和删除效率低;可能浪费内存;内存空间要求高,必须有足够的连续内存空间;数组大小固定,不能动态拓展。
- 链表的优点: 插入删除速度快;内存利用率高,不会浪费内存;大小没有固定,拓展很灵活。
- 链表的缺点: 不能随机查找,必须从第一个开始遍历,查找效率低。
3、排序有哪些分类?
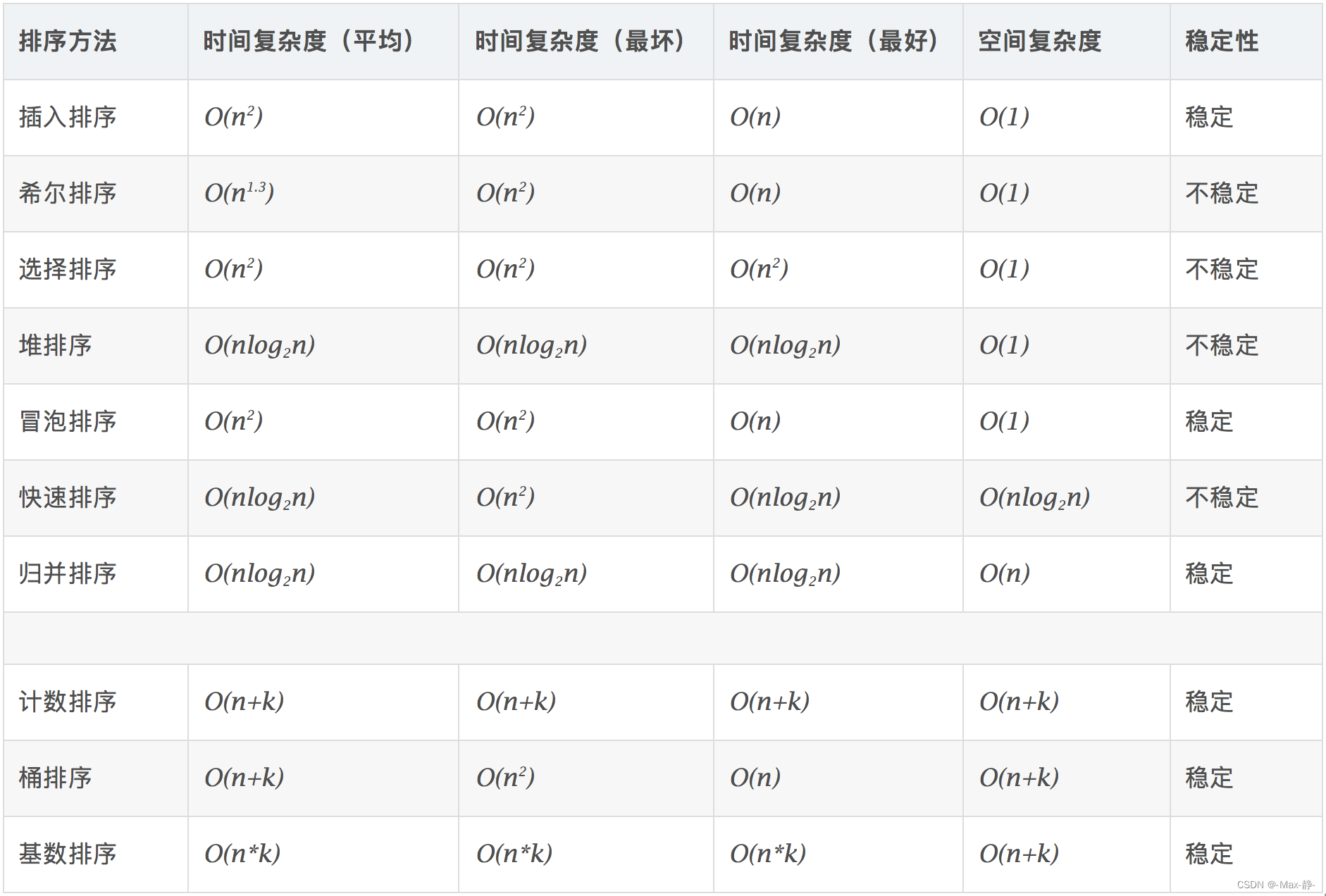
稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序;
不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序;
比较排序:冒泡排序、快速排序、归并排序;
非比较排序:基数排序、基数排序、桶排序;
内部排序:插入排序、归并排序、选择排序、交换排序、计数排序、桶排序、基数排序;
外部排序:暂时不知;
4、冒泡排序(Bubble Sort)
算法步骤:
- 从第一个元素开始,比较相邻的两个元素。如果前一个元素比后一个元素大(如果是升序排序的话),则交换它们的位置。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
5、插入排序(Insertion Sort)
算法步骤:
- 从第一个元素开始,该元素可以认为已经被排序。
- 取出下一个元素,在已经排序的元素序列中从后向前扫描。
- 如果该元素(已排序)大于新元素,将该元素移到下一位置。
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置。
- 将新元素插入到该位置后。
- 重复步骤2~5,直到所有元素均排序完毕。
6、希尔排序(Shell Sort)
算法步骤:
- 选择增量序列:首先,需要选择一个增量序列t1,t2,…,tk,其中ti > tj, tk = 1。这个序列的选择对希尔排序的性能至关重要。常用的增量序列有Hibbard增量序列、Sedgewick增量序列等。
- 分组与预排序:按照当前的增量ti,将待排序序列分割成若干长度为m的子序列,分别对各子表进行直接插入排序。此时,整个序列是“基本有序”的。
- 逐步缩小增量并重复排序:每排序完一次子序列(即增量为ti的一趟排序)后,更新增量为ti-1,并重复步骤2,进行下一趟排序,直到增量减小到1。此时,整个序列已经基本有序,可以对整个序列进行一次直接插入排序,得到最终排序结果。
7、选择排序(Selection Sort)
算法步骤:
- 遍历待排序序列,设立一个指针,初始指向序列的第一个元素。
- 从当前指针位置开始,依次与后面的元素比较,找到最小(或最大)的元素,并记录其位置。
- 将找到的最小(或最大)元素与当前指针位置的元素进行交换。
- 将指针向后移动一位,重复步骤2和步骤3,直到指针移动到序列的倒数第二个元素。
- 此时,最后一个元素已经是序列中的最大(或最小)元素,排序完成。
8、快速排序(Quick Sort)
算法步骤:
- 从序列中选取一个元素作为基准(pivot)。
- 将序列中小于基准的元素放在基准的左边,大于基准的元素放在基准的右边。这个操作称为分区(partition)操作,完成后基准元素处于序列的中间位置。此时,该基准元素在排序后的最终位置已经确定。
- 递归地对基准左边和右边的两个子序列进行快速排序。
9、归并排序(Merge Sort)
算法步骤:
- 分解:将待排序的序列划分为若干个长度为1的子序列,每个子序列自然有序。
- 递归进行归并:递归地将相邻的子序列两两归并,得到若干个有序的较长子序列,直到最终合并为一个完整的有序序列。
10、堆排序(Heap Sort)
算法步骤:
- 建堆:将无序序列构造成一个大顶堆(或小顶堆)。此时,整个序列的最大值(或最小值)就是堆顶的根节点。
- 堆调整:将堆顶元素与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个序列重新构造成一个堆,这样会得到n个元素中的次大值。如此反复执行,便能得到一个有序序列了。
11、计数排序(Counting Sort)
首先,扫描待排序数组,确定数组的最大值和最小值;
然后,建立一个与最大值和最小值范围相对应的计数数组,并统计每个元素出现的次数;
最后,根据计数数组的信息,将待排序数组中的元素放到正确的位置上。
12、桶排序(Bucket Sort)
- 确定桶的数量和大小:首先,需要确定桶的数量以及每个桶的大小范围。桶的数量可以基于待排序数组的长度和数据分布来决定。每个桶的大小范围则是根据数据的最大值和最小值来划分的。
- 分配数据到桶中:遍历待排序数组,根据每个元素的值将其放入对应的桶中。这个过程需要根据桶的大小范围来判定每个元素应该放入哪个桶。
- 桶内排序:对每个桶内的元素进行排序。这里可以使用其他排序算法,如插入排序、归并排序或快速排序等,对桶内的元素进行进一步的排序。
- 合并桶中的数据:最后,按照桶的顺序,将桶内的元素依次合并起来,形成最终的排序结果。
13、基数排序(Radix Sort)
- 确定最大位数:首先,需要找到待排序数组中的最大值,确定其位数。这将决定需要进行多少轮排序。
- 从最低位开始排序:基数排序从最低位(个位)开始,对数组进行排序。在每一轮排序中,可以使用稳定的排序算法(如计数排序或桶排序)对相应位上的数字进行排序。
- 逐渐向高位排序:完成最低位的排序后,继续向更高位(十位、百位等)进行排序。每一轮排序都会根据当前位的数字值对数组进行重排。
- 合并排序结果:经过多轮排序后,数组中的元素将按照从最低位到最高位的顺序排列。由于每一轮排序都是稳定的,所以最终得到的数组将是一个有序数组。
14、数组和链表的区别?
从逻辑结构上来看,数组必须实现定于固定的长度,不能适应数据动态增减的情况,即数组的大小一旦定义就不能改变。当数据增加是,可能超过原先定义的元素的个数;当数据减少时,造成内存浪费;链表动态进行存储分配,可以适应数据动态地增减的情况,且可以方便地插入、删除数据项。
从内存存储的角度看;数组从栈中分配空间(用new则在堆上创建),对程序员方便快速,但是自由度小;链表从堆中分配空间,自由度大但是申请管理比较麻烦。
从访问方式类看,数组在内存中是连续的存储,因此可以利用下标索引进行访问;链表是链式存储结构,在访问元素时候只能够通过线性方式由前到后顺序的访问,所以访问效率比数组要低。
15、线性表的存储结构?
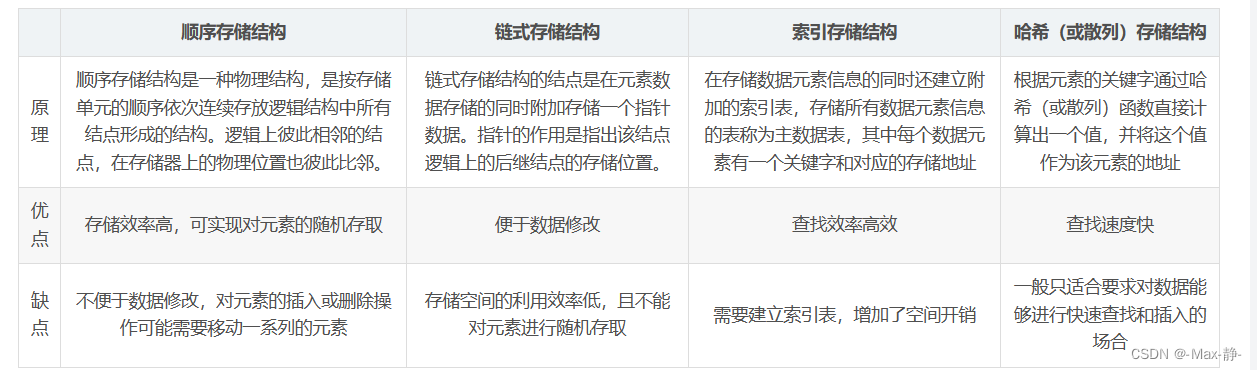
线性表存储结构可细分为顺序存储结构和链式存储结构
顺序存储结构:将数据依次存储在连续的整块物理空间中,这种存储结构称为顺序存储结构(简称顺序表);
链式存储结构:数据分散的存储在物理空间中,通过一根线保存着它们之间的逻辑关系,这种存储结构称为链式存储结构(简称链表);
16、头指针和头节点?
头结点:
- 定义:在单链表的开始结点之前设立的一个节点,称为头结点。
- 数据域:可以不存储任何信息,也可以存储链表长度等附加信息。
- 指针域:存储指向第一个结点的指针。
- 作用:
- 方便链表操作,如插入、删除元素等。
- 减少代码量,因为通过头结点可以更容易地处理链表的各种操作,特别是当需要操作第一个结点时。
- 使得链表的某些操作(如遍历、查找等)更为统一和简洁。
头指针:
- 定义:指向链表第一个结点的指针。
- 作用:
- 具有标识作用,通常用头指针来命名链表。
- 提供链表的访问入口,通过头指针可以访问链表的第一个节点,进而遍历整个链表。
17、栈(stack)和队列(queue)的区别?
- 访问规则:栈是一种后进先出(LIFO,Last In First Out)的数据结构,即最后一个被添加到栈中的元素总是第一个被移出。而队列则是一种先进先出(FIFO,First In First Out)的数据结构,即队列中第一个被添加的元素总是第一个被移出。
- 操作方式:栈的主要操作包括压栈(push,向栈顶添加元素)和弹栈(pop,从栈顶移除元素)。而队列的主要操作则包括入队(enqueue,在队列尾部添加元素)和出队(dequeue,从队列头部移除元素)。
- 使用场景:由于栈的后进先出特性,它常被用于实现函数调用和递归等场景,因为这些操作通常需要后创建的对象先处理。而队列的先进先出特性则使其在需要按特定顺序处理元素的场景中非常有用,如打印任务、网络数据包处理等。
- 数据结构:栈通常使用数组或链表来实现。在数组实现中,栈底通常在数组的起始位置,栈顶在数组的末尾;而在链表实现中,栈顶的元素位于链表的头部。队列也可以使用数组或链表来实现,但在数组实现中,通常需要一个额外的变量来记录队列的头部和尾部位置;在链表实现中,队列的头部和尾部可以通过链表的头部和尾部节点来追踪。
18、什么是二叉树?平衡二叉树?
看这个:二叉树知识点最详细最全讲解-CSDN博客
19、如何唯一确定一棵二叉树?
中序 + 先序/后序/层序
20、图的存储方式有哪些?每一种方式优缺点?
21、树的存储结构?
22、图的遍历和树的遍历方式都是什么?
23、图的遍历与树的遍历有什么区别?
24、关键路径和关键活动是什么?
25、什么叫平衡二叉树?
26、什么叫搜索二叉树?
27、什么叫红黑树?
28、数据结构的4种逻辑结构各有什么特点?
(1)集合结构:结构中的数据元素之间除了同属于一种类型外,无其他关系。
(2)线性结构:结构中的数据元素之间存在一对一的关系。
(3)树形结构:结构中的数据元素之间存在一对多的关系。
(4)图状结构或网状结构:结构中的数据元素之间存在多对多的关系。
29、数据结构中的存储结构有哪几种?各有什么有优缺点?
30、什么是数据结构?C语言、数据结构、算法以及程序之间的关系是什么?
数据结构是指所有数据元素以及数据元素之间的关系,可以看作是相互之间存在着某种特定关系的集合,因此可以我们将数据结构看成是带结构的数据元素的集合。此外,在通常情况下,选择合适的数据结构可以带来提高运行效率或者存储效率。
数据结构、算法以及程序之间的关系是:数据结构 + 算法 = 程序。
算法不一定要求能够在计算机上直接运行,但程序必须要求能在计算机中运行。C语言只是对算法或者数据结构的描述,描述数据结构和算法不局限于C语言,也可以是C++语言和其他的计算机语言甚至也可以用人的自然语言。
31、常见数据结构?
数组 ;栈;队列;链表;图;树;前缀树;哈希
32、解决哈希冲突的方法
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。
1) 线性探测法
2) 平方探测法
3) 伪随机序列法
4) 拉链法
33、什么是KMP算法?
在一个字符串中查找是否包含目标的匹配字符串。其主要思想是每趟比较过程让子串先后滑动一个合适的位置。当发生不匹配的情况时,不是右移一位,而是移动(当前匹配的长度– 当前匹配子串的部分匹配值)位。
34、什么是B树?
根据B类树的特点,构造一个多阶的B类树,然后在尽量多的在结点上存储相关的信息,保证层数尽量的少,以便后面我们可以更快的找到信息,磁盘的I/O操作也少一些,而且B类树是平衡树,每个结点到叶子结点的高度都是相同,这也保证了每个查询是稳定的。
B树和B+树的区别,以一个m阶树为例。
- 关键字的数量不同;B+树中分支结点有m个关键字,其叶子结点也有m个,其关键字只是起到了一个索引的作用,但是B树虽然也有m个子结点,但是其只拥有m-1个关键字。
- 存储的位置不同;B+树中的数据都存储在叶子结点上,也就是其所有叶子结点的数据组合起来就是完整的数据,但是B树的数据存储在每一个结点中,并不仅仅存储在叶子结点上。
- 分支结点的构造不同;B+树的分支结点仅仅存储着关键字信息和儿子的指针(这里的指针指的是磁盘块的偏移量),也就是说内部结点仅仅包含着索引信息。
- 查询不同;B树在找到具体的数值以后,则结束,而B+树则需要通过索引找到叶子结点中的数据才结束,也就是说B+树的搜索过程中走了一条从根结点到叶子结点的路径。
感谢博主:线性表的存储结构详解_为什么在线性表中结点所占存储量和结构本身所占存储量是一样的-CSDN博客
感谢博主:https://xgqngu.blog.csdn.net/article/details/112134686
感谢博主:数据结构常见面试题,一网打尽!_数据结构面试题-CSDN博客
感谢博主:数据结构面试题(史上最全基础面试题,精心整理100家互联网企业面经) - 知乎
感谢博主:数据结构面试常见问题总结-CSDN博客
相关文章:
数据结构面试题
1、数据结构三要素? 逻辑结构、物理结构、数据运算 2、数组和链表的区别? 数组的特点: 数组是将元素在内存中连续存放,由于每个元素占用内存相同,可以通过下标迅速访问数组中任何元素。数组的插入数据和删除数据效率低…...
python爬虫之xpath入门
文章目录 一、前言参考文档: 二、xpath语法-基础语法常用路径表达式举例说明 三、xpath语法-谓语表达式举例注意 四、xpath语法-通配符语法实例 五、选取多个路径实例 六、Xpath Helper安装使用说明例子: 七、python中 xpath 的使用安装xpath 的依赖包xm…...
TikTok云手机是什么原理?
社交媒体的快速发展和普及,TikTok已成为全球最受欢迎的短视频平台之一,吸引了数以亿计的用户。在TikTok上,许多用户和内容创作者都希望能够更灵活地管理和运营多个账号,这就需要借助云手机技术。那么,TikTok云手机究竟…...

24.3.24 《CLR via C#》 笔记10
第十三章 接口 类和接口继承 CLR不支持多继承,因此所有托管编程语言都不支持任何类都从且只能从一个类派生(最终从Object类派生)定义接口实际只是对一组方法进行了统一的命名,类通过指定接口名称来继承接口,且必须显式…...
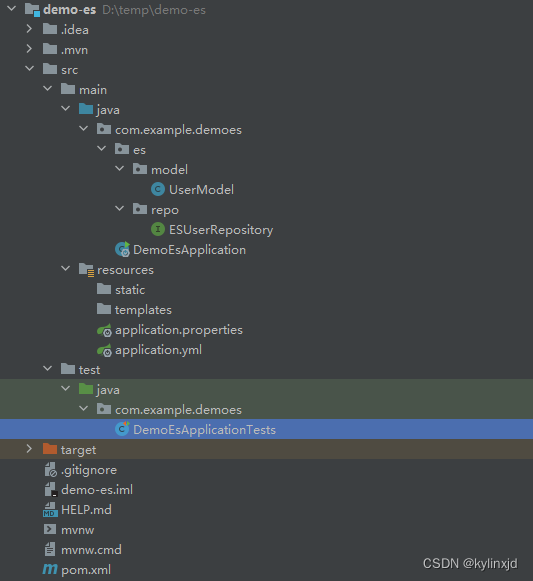
SpringBoot 3整合Elasticsearch 8
这里写自定义目录标题 版本说明spring boot POM依赖application.yml配置新建模型映射Repository简单测试完整项目文件目录结构windows下elasticsearch安装配置 版本说明 官网说明 本文使用最新的版本 springboot: 3.2.3 spring-data elasticsearch: 5.2.3 elasticsearch: 8.1…...
)
突破编程_C++_查找算法(分块查找)
1 算法题 :使用分块算法在有序数组中查找指定元素 1.1 题目含义 在给定一个有序数组的情况下,使用分块查找算法来查找数组中是否包含指定的元素。分块查找算法是一种结合了顺序查找和二分查找思想的算法,它将有序数组划分为若干个块&#x…...

学习java第二十二天
IOC 容器具有依赖注入功能的容器,它可以创建对象,IOC 容器负责实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。通常new一个实例,控制权由程序员控制,而"控制反转"是指new实例工作不由程序员来做而是交给Sp…...

每天学习一个Linux命令之systemctl
每天学习一个Linux命令之systemctl 介绍 在Linux系统中,systemctl命令是Systemd初始化系统的核心管理工具之一。systemd是用来启动、管理和监控运行在Linux上的系统的第一个进程(PID 1),它提供了一整套强大的工具和功能…...

【机器学习入门】人工神经网络(二)卷积和池化
系列文章目录 第1章 专家系统 第2章 决策树 第3章 神经元和感知机 识别手写数字——感知机 第4章 线性回归 第5章 逻辑斯蒂回归和分类 第5章 支持向量机 第6章 人工神经网络(一) 文章目录 系列文章目录前言一、卷积神经连接的局部性平移不变性 二、卷积处理图像的效果代码二、…...

公司内部局域网怎么适用飞书?
随着数字化办公的普及,企业对于内部沟通和文件传输的需求日益增长。飞书作为一款集成了即时通讯、云文档、日程管理、视频会议等多种功能的智能协作平台,已经成为许多企业提高工作效率的首选工具。本文将详细介绍如何在公司内部局域网中应用飞书…...
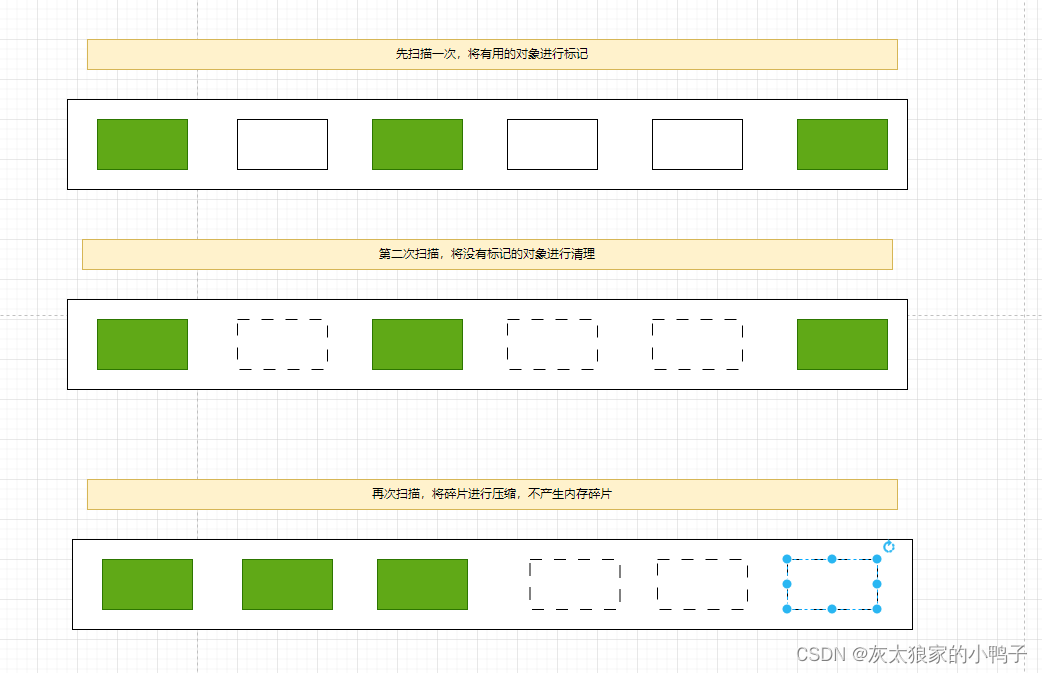
JVM的知识
什么是JVM 1.JVM: JVM其实就是运行在 操作系统之上的一个特殊的软件。 2.JVM的内部结构: (1)因为栈会将执行的程序弹出栈。 (2)垃圾99%的都是在堆和方法区中产生的。 类加载器:加载class文件。…...

大模型日报2024-03-24
利用LLMs评分及解释K-12科学答案 摘要: 本文研究了在K-12级科学教育中使用大型语言模型(LLMs)对短答案评分及解释。研究采用GPT-4结合少量样本学习和活跃学习,通过人机协作提供有意义的评估反馈。 MathVerse:多模态LLM解数学题效果…...

Android kotlin全局悬浮窗全屏功能和锁屏页面全屏悬浮窗功能一
1.前言 在进行app应用开发中,在实现某些功能中要求实现悬浮窗功能,分为应用内悬浮窗 ,全局悬浮窗和 锁屏页面悬浮窗功能 等,接下来就来实现这些悬浮窗全屏功能,首选看下第一部分功能实现 2.kotlin全局悬浮窗全屏功能和锁屏页面全屏悬浮窗功能一分析 悬浮窗是属于Androi…...

图像识别在安防领域的应用
图像识别技术在安防领域有着广泛的应用,它通过分析和理解图像中的视觉信息,为安防系统提供了强大的辅助功能。以下是一些主要的应用领域: 人脸识别:人脸识别技术是安防领域中最常见的应用之一。它可以帮助系统识别和验证个人身份…...

前端面试集中复习 - http篇
1. http请求方式 HTTP请求方式有哪些:GET POST PUT DELETE OPTIONS 1) GET POST 的区别? 场景上: GET 用于获取资源而不对服务器资源做更改提交的请求,多次执行结果一致。用于获取静态数据,幂等。 POST࿱…...
C++ - 类和对象(上)
目录 一、类的定义 二、访问限定符 public(公有) protected(保护) private(私有) 三、类声明和定义分离 四、外部变量和成员变量的区别与注意 五、类的实例化 六、类对象的模型 七、类的this指针…...

mysql基础4sql优化
SQL优化 插入数据优化 如果我们需要一次性往数据库表中插入多条记录,可以从以下三个方面进行优化。 insert into tb_test values(1,tom); insert into tb_test values(2,cat); insert into tb_test values(3,jerry);-- 优化方案一:批量插入数据 Inser…...

实现Spring Web MVC中的文件上传功能,并处理大文件和多文件上传
实现Spring Web MVC中的文件上传功能,并处理大文件和多文件上传 在Spring Web MVC中实现文件上传功能并处理大文件和多文件上传是一项常见的任务。下面是一个示例,演示如何在Spring Boot应用程序中实现这一功能: 添加Spring Web依赖&#x…...
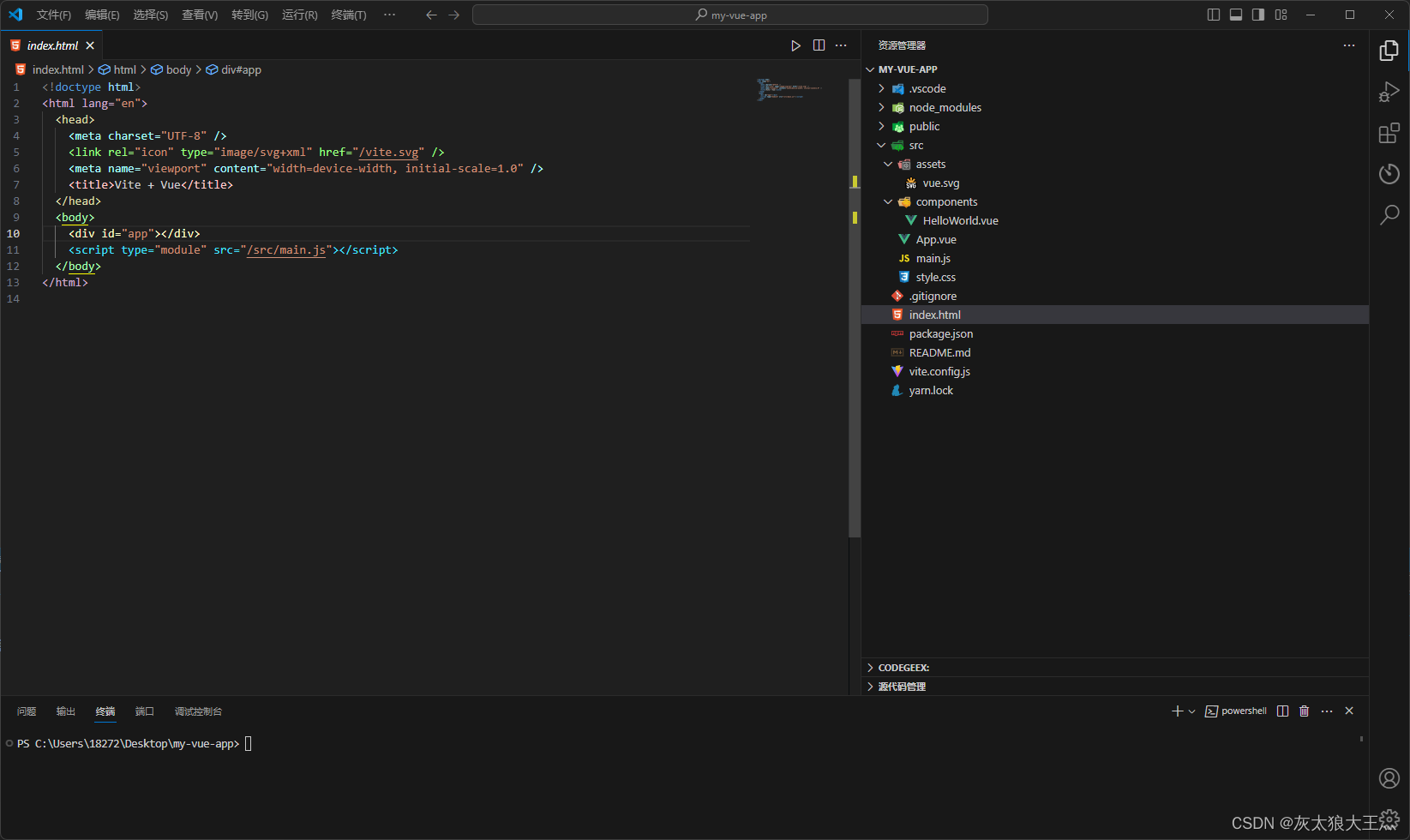
搭建vite项目
文章目录 Vite 是一个基于 Webpack 的开发服务器,用于开发 Vue 3 和 Vite 应用程序 一、创建一个vite项目二、集成Vue Router1.安装 vue-routernext插件2.在 src 目录下创建一个名为 router 的文件夹,并在其中创建一个名为 index.js 的文件。在这个文件中…...

Docker 安装mysql 主从复制
目录 1 MySql主从复制简介 1.1 主从复制的概念 1.2 主从复制的作用 2. 搭建主从复制 2.1 pull mysql 镜像 2.2 新建主服务器容器实例 3307 2.2.1 master创建 my.cnf 2.2.2 重启master 2.2.3 进入mysql 容器,创建同步用户 2.3 新建从服务器容器实例 3308…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...

浏览器指纹识别机制深度剖析与反识别技术实现
一、浏览器指纹技术基础认知1.1 浏览器指纹的核心定义在数字化时代,每一台接入互联网的设备都会留下独特的数字标识,浏览器指纹便是其中最关键的识别凭证之一。浏览器指纹是网站通过 JavaScript 脚本、HTTP 请求头、硬件接口调用等多种技术手段ÿ…...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

如何优化 MySQL 千万级数据分页查询的性能?
它的本质是:**传统 LIMIT offset, size 在大数据量下性能急剧下降,是因为 MySQL 必须 扫描并丢弃 前 offset 行数据。当 offset 很大时(如 LIMIT 1000000, 10),MySQL 需要读取 1,000,010 行记录,执行 1,000…...