I/O多路复用:select/poll/epoll
最基本的 Socket 模型
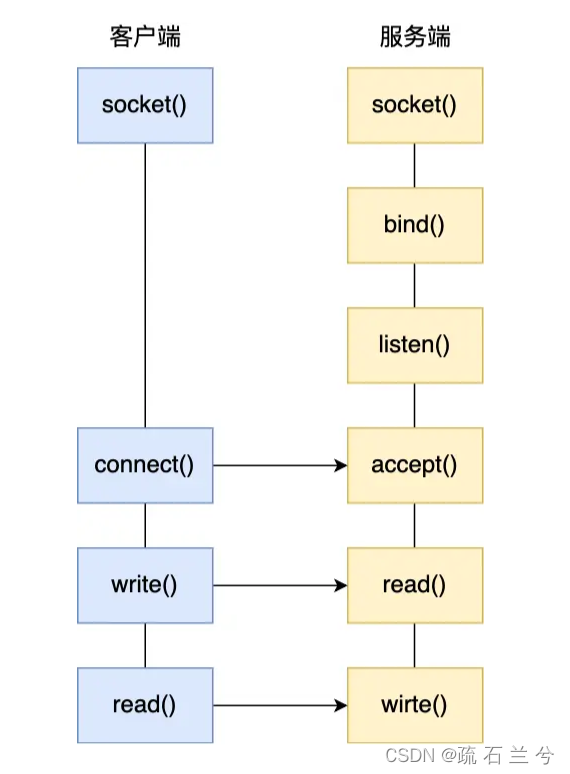
要想客户端和服务器能在网络中通信,那必须得使用 Socket 编程,它是进程间通信里比较特别的方式,特别之处在于它是可以跨主机间通信。
Socket 的中文名叫作插口,咋一看还挺迷惑的。事实上,双方要进行网络通信前,各自得创建一个 Socket,这相当于客户端和服务器都开了一个“口子”,双方读取和发送数据的时候,都通过这个“口子”。这样一看,是不是觉得很像弄了一根网线,一头插在客户端,一头插在服务端,然后进行通信。
创建 Socket 的时候,可以指定网络层使用的是 IPv4 还是 IPv6,传输层使用的是 TCP 还是 UDP。
UDP 的 Socket 编程相对简单些,这里我们只介绍基于 TCP 的 Socket 编程。
服务器的程序要先跑起来,然后等待客户端的连接和数据,我们先来看看服务端的 Socket 编程过程是怎样的。
服务端首先调用 socket() 函数,创建网络协议为 IPv4,以及传输协议为 TCP 的 Socket ,接着调用 bind() 函数,给这个 Socket 绑定一个 IP 地址和端口,绑定这两个的目的是什么?
- 绑定端口的目的:当内核收到 TCP 报文,通过 TCP 头里面的端口号,来找到我们的应用程序,然后把数据传递给我们。
- 绑定 IP 地址的目的:一台机器是可以有多个网卡的,每个网卡都有对应的 IP 地址,当绑定一个网卡时,内核在收到该网卡上的包,才会发给我们;
绑定完 IP 地址和端口后,就可以调用 listen() 函数进行监听,此时对应 TCP 状态图中的 listen,如果我们要判定服务器中一个网络程序有没有启动,可以通过 netstat 命令查看对应的端口号是否有被监听。
绑定完 IP 地址和端口后,就可以调用 listen() 函数进行监听,此时对应 TCP 状态图中的 listen,如果我们要判定服务器中一个网络程序有没有启动,可以通过 netstat 命令查看对应的端口号是否有被监听。
服务端进入了监听状态后,通过调用 accept() 函数,来从内核获取客户端的连接,如果没有客户端连接,则会阻塞等待客户端连接的到来。
那客户端是怎么发起连接的呢?客户端在创建好 Socket 后,调用 connect() 函数发起连接,该函数的参数要指明服务端的 IP 地址和端口号,然后万众期待的 TCP 三次握手就开始了。
在 TCP 连接的过程中,服务器的内核实际上为每个 Socket 维护了两个队列:
- 一个是「还没完全建立」连接的队列,称为 TCP 半连接队列,这个队列都是没有完成三次握手的连接,此时服务端处于
syn_rcvd的状态; - 一个是「已经建立」连接的队列,称为 TCP 全连接队列,这个队列都是完成了三次握手的连接,此时服务端处于
established状态;
当 TCP 全连接队列不为空后,服务端的 accept() 函数,就会从内核中的 TCP 全连接队列里拿出一个已经完成连接的 Socket 返回应用程序,后续数据传输都用这个 Socket。
注意,监听的 Socket 和真正用来传数据的 Socket 是两个:
- 一个叫作监听 Socket;
- 一个叫作已连接 Socket;
连接建立后,客户端和服务端就开始相互传输数据了,双方都可以通过 read() 和 write() 函数来读写数据。
至此, TCP 协议的 Socket 程序的调用过程就结束了,整个过程如下图:
看到这,不知道你有没有觉得读写 Socket 的方式,好像读写文件一样。
是的,基于 Linux 一切皆文件的理念,在内核中 Socket 也是以「文件」的形式存在的,也是有对应的文件描述符。
文件描述符的作用是什么?
每一个进程都有一个数据结构 task_struct,该结构体里有一个指向「文件描述符数组」的成员指针。该数组里列出这个进程打开的所有文件的文件描述符。数组的下标是文件描述符,是一个整数,而数组的内容是一个指针,指向内核中所有打开的文件的列表,也就是说内核可以通过文件描述符找到对应打开的文件。
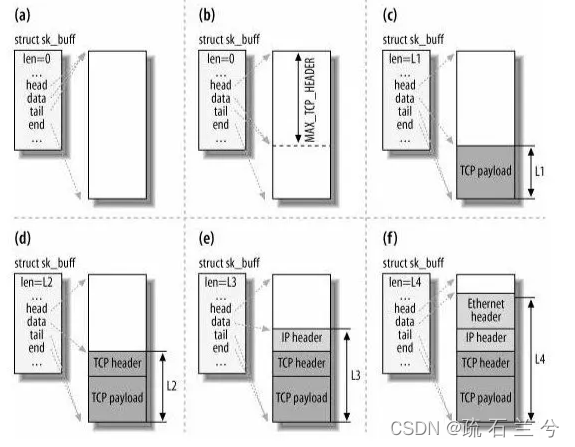
然后每个文件都有一个 inode,Socket 文件的 inode 指向了内核中的 Socket 结构,在这个结构体里有两个队列,分别是发送队列和接收队列,这个两个队列里面保存的是一个个 struct sk_buff,用链表的组织形式串起来。
sk_buff 可以表示各个层的数据包,在应用层数据包叫 data,在 TCP 层我们称为 segment,在 IP 层我们叫 packet,在数据链路层称为 frame。
你可能会好奇,为什么全部数据包只用一个结构体来描述呢?协议栈采用的是分层结构,上层向下层传递数据时需要增加包头,下层向上层数据时又需要去掉包头,如果每一层都用一个结构体,那在层之间传递数据的时候,就要发生多次拷贝,这将大大降低 CPU 效率。
于是,为了在层级之间传递数据时,不发生拷贝,只用 sk_buff 一个结构体来描述所有的网络包,那它是如何做到的呢?是通过调整 sk_buff 中 data 的指针,比如:
- 当接收报文时,从网卡驱动开始,通过协议栈层层往上传送数据报,通过增加 skb->data 的值,来逐步剥离协议首部。
- 当要发送报文时,创建 sk_buff 结构体,数据缓存区的头部预留足够的空间,用来填充各层首部,在经过各下层协议时,通过减少 skb->data 的值来增加协议首部。
你可以从下面这张图看到,当发送报文时,data 指针的移动过程。
如何服务更多的用户?
前面提到的 TCP Socket 调用流程是最简单、最基本的,它基本只能一对一通信,因为使用的是同步阻塞的方式,当服务端在还没处理完一个客户端的网络 I/O 时,或者 读写操作发生阻塞时,其他客户端是无法与服务端连接的。
可如果我们服务器只能服务一个客户,那这样就太浪费资源了,于是我们要改进这个网络 I/O 模型,以支持更多的客户端。
在改进网络 I/O 模型前,我先来提一个问题,你知道服务器单机理论最大能连接多少个客户端?
相信你知道 TCP 连接是由四元组唯一确认的,这个四元组就是:本机IP, 本机端口, 对端IP, 对端端口。
服务器作为服务方,通常会在本地固定监听一个端口,等待客户端的连接。因此服务器的本地 IP 和端口是固定的,于是对于服务端 TCP 连接的四元组只有对端 IP 和端口是会变化的,所以最大 TCP 连接数 = 客户端 IP 数×客户端端口数。
对于 IPv4,客户端的 IP 数最多为 2 的 32 次方,客户端的端口数最多为 2 的 16 次方,也就是服务端单机最大 TCP 连接数约为 2 的 48 次方。
这个理论值相当“丰满”,但是服务器肯定承载不了那么大的连接数,主要会受两个方面的限制:
- 文件描述符,Socket 实际上是一个文件,也就会对应一个文件描述符。在 Linux 下,单个进程打开的文件描述符数是有限制的,没有经过修改的值一般都是 1024,不过我们可以通过 ulimit 增大文件描述符的数目;
- 系统内存,每个 TCP 连接在内核中都有对应的数据结构,意味着每个连接都是会占用一定内存的;
那如果服务器的内存只有 2 GB,网卡是千兆的,能支持并发 1 万请求吗?
并发 1 万请求,也就是经典的 C10K 问题 ,C 是 Client 单词首字母缩写,C10K 就是单机同时处理 1 万个请求的问题。
从硬件资源角度看,对于 2GB 内存千兆网卡的服务器,如果每个请求处理占用不到 200KB 的内存和 100Kbit 的网络带宽就可以满足并发 1 万个请求。
不过,要想真正实现 C10K 的服务器,要考虑的地方在于服务器的网络 I/O 模型,效率低的模型,会加重系统开销,从而会离 C10K 的目标越来越远。
多进程模型
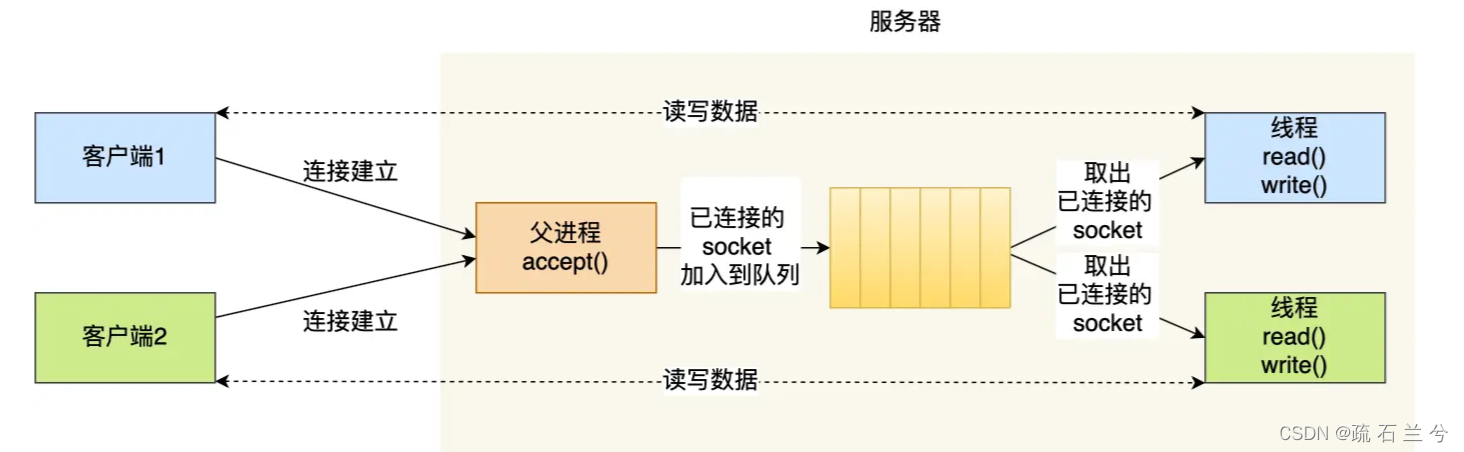
基于最原始的阻塞网络 I/O, 如果服务器要支持多个客户端,其中比较传统的方式,就是使用多进程模型,也就是为每个客户端分配一个进程来处理请求。
服务器的主进程负责监听客户的连接,一旦与客户端连接完成,accept() 函数就会返回一个「已连接 Socket」,这时就通过 fork() 函数创建一个子进程,实际上就把父进程所有相关的东西都复制一份,包括文件描述符、内存地址空间、程序计数器、执行的代码等。
这两个进程刚复制完的时候,几乎一模一样。不过,会根据返回值来区分是父进程还是子进程,如果返回值是 0,则是子进程;如果返回值是其他的整数,就是父进程。
正因为子进程会复制父进程的文件描述符,于是就可以直接使用「已连接 Socket 」和客户端通信了,
可以发现,子进程不需要关心「监听 Socket」,只需要关心「已连接 Socket」;父进程则相反,将客户服务交给子进程来处理,因此父进程不需要关心「已连接 Socket」,只需要关心「监听 Socket」。
下面这张图描述了从连接请求到连接建立,父进程创建生子进程为客户服务。

另外,当「子进程」退出时,实际上内核里还会保留该进程的一些信息,也是会占用内存的,如果不做好“回收”工作,就会变成僵尸进程,随着僵尸进程越多,会慢慢耗尽我们的系统资源。
因此,父进程要“善后”好自己的孩子,怎么善后呢?那么有两种方式可以在子进程退出后回收资源,分别是调用 wait() 和 waitpid() 函数。
这种用多个进程来应付多个客户端的方式,在应对 100 个客户端还是可行的,但是当客户端数量高达一万时,肯定扛不住的,因为每产生一个进程,必会占据一定的系统资源,而且进程间上下文切换的“包袱”是很重的,性能会大打折扣。
进程的上下文切换不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源。
多线程模型
既然进程间上下文切换的“包袱”很重,那我们就搞个比较轻量级的模型来应对多用户的请求 —— 多线程模型。
线程是运行在进程中的一个“逻辑流”,单进程中可以运行多个线程,同进程里的线程可以共享进程的部分资源,比如文件描述符列表、进程空间、代码、全局数据、堆、共享库等,这些共享些资源在上下文切换时不需要切换,而只需要切换线程的私有数据、寄存器等不共享的数据,因此同一个进程下的线程上下文切换的开销要比进程小得多。
当服务器与客户端 TCP 完成连接后,通过 pthread_create() 函数创建线程,然后将「已连接 Socket」的文件描述符传递给线程函数,接着在线程里和客户端进行通信,从而达到并发处理的目的。
如果每来一个连接就创建一个线程,线程运行完后,还得操作系统还得销毁线程,虽说线程切换的上写文开销不大,但是如果频繁创建和销毁线程,系统开销也是不小的。
那么,我们可以使用线程池的方式来避免线程的频繁创建和销毁,所谓的线程池,就是提前创建若干个线程,这样当由新连接建立时,将这个已连接的 Socket 放入到一个队列里,然后线程池里的线程负责从队列中取出「已连接 Socket 」进行处理。
需要注意的是,这个队列是全局的,每个线程都会操作,为了避免多线程竞争,线程在操作这个队列前要加锁。
上面基于进程或者线程模型的,其实还是有问题的。新到来一个 TCP 连接,就需要分配一个进程或者线程,那么如果要达到 C10K,意味着要一台机器维护 1 万个连接,相当于要维护 1 万个进程/线程,操作系统就算死扛也是扛不住的。
I/O 多路复用
既然为每个请求分配一个进程/线程的方式不合适,那有没有可能只使用一个进程来维护多个 Socket 呢?答案是有的,那就是 I/O 多路复用技术。
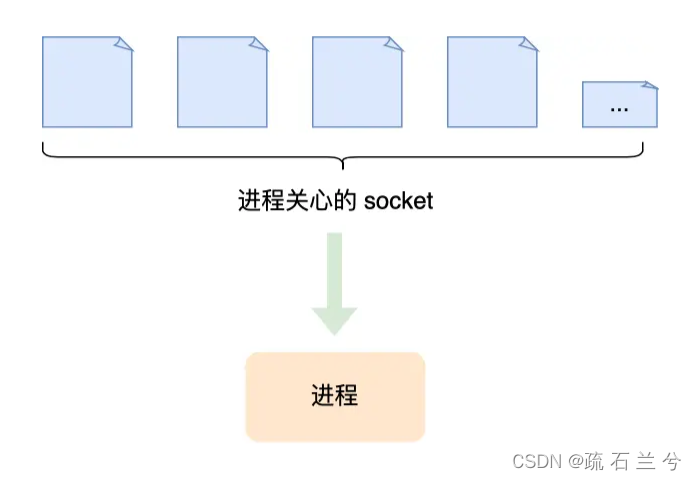
一个进程虽然任一时刻只能处理一个请求,但是处理每个请求的事件时,耗时控制在 1 毫秒以内,这样 1 秒内就可以处理上千个请求,把时间拉长来看,多个请求复用了一个进程,这就是多路复用,这种思想很类似一个 CPU 并发多个进程,所以也叫做时分多路复用。
我们熟悉的 select/poll/epoll 内核提供给用户态的多路复用系统调用,进程可以通过一个系统调用函数从内核中获取多个事件。
select/poll/epoll 是如何获取网络事件的呢?在获取事件时,先把所有连接(文件描述符)传给内核,再由内核返回产生了事件的连接,然后在用户态中再处理这些连接对应的请求即可。
select/poll/epoll 这是三个多路复用接口,都能实现 C10K 吗?接下来,我们分别说说它们。
select/poll
select 实现多路复用的方式是,将已连接的 Socket 都放到一个文件描述符集合,然后调用 select 函数将文件描述符集合拷贝到内核里,让内核来检查是否有网络事件产生,检查的方式很粗暴,就是通过遍历文件描述符集合的方式,当检查到有事件产生后,将此 Socket 标记为可读或可写, 接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的 Socket,然后再对其处理。
所以,对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ,而且还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的,在 Linux 系统中,由内核中的 FD_SETSIZE 限制, 默认最大值为 1024,只能监听 0~1023 的文件描述符。
poll 不再用 BitsMap 来存储所关注的文件描述符,取而代之用动态数组,以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。
但是 poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
epoll
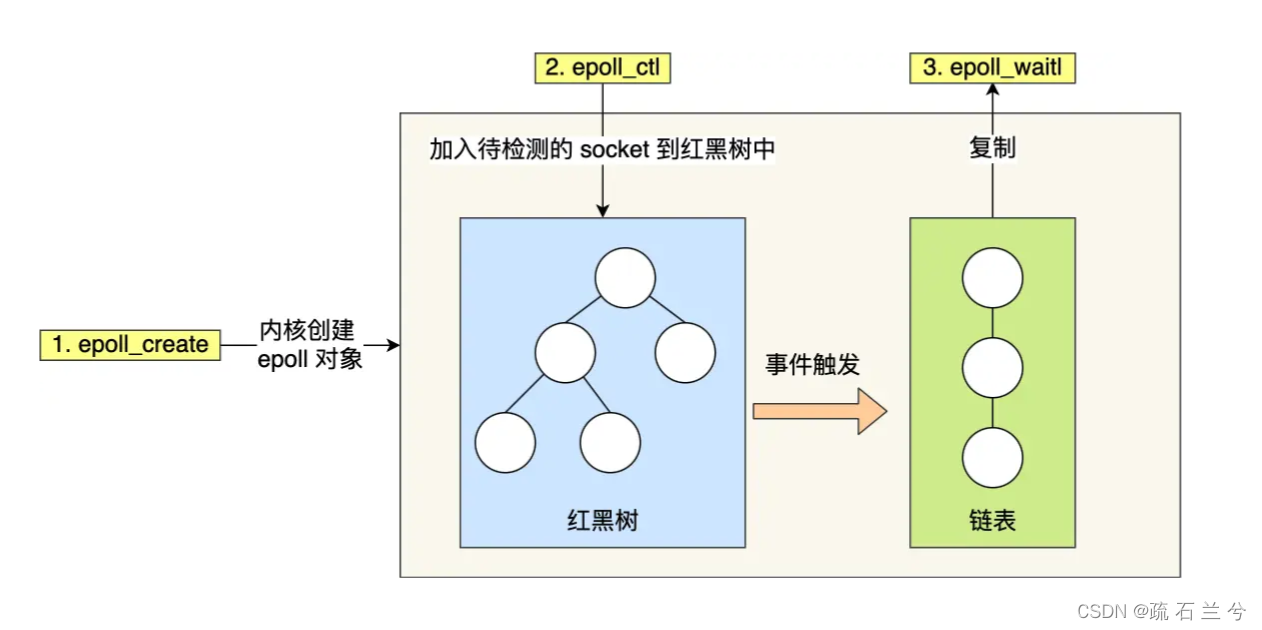
先复习下 epoll 的用法。如下的代码中,先用epoll_create 创建一个 epoll对象 epfd,再通过 epoll_ctl 将需要监视的 socket 添加到epfd中,最后调用 epoll_wait 等待数据。
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...);
listen(s, ...)int epfd = epoll_create(...);
epoll_ctl(epfd, ...); //将所有需要监听的socket添加到epfd中while(1) {int n = epoll_wait(...);for(接收到数据的socket){//处理}
}epoll 通过两个方面,很好解决了 select/poll 的问题。
第一点,epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过 epoll_ctl() 函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删改一般时间复杂度是 O(logn)。而 select/poll 内核里没有类似 epoll 红黑树这种保存所有待检测的 socket 的数据结构,所以 select/poll 每次操作时都传入整个 socket 集合给内核,而 epoll 因为在内核维护了红黑树,可以保存所有待检测的 socket ,所以只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。
第二点, epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用 epoll_wait() 函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
从下图你可以看到 epoll 相关的接口作用:
在 Linux 内核中,当发生事件时,相关信息会被放入就绪链表中。这个过程是通过内核将事件信息复制到就绪链表中完成的,而不是简单地取出或者移动已有的节点。
具体地说,当事件发生时,内核会在内部维护的数据结构中记录这些事件的相关信息,然后将这些信息复制到就绪链表中。这样做的好处是,就绪链表是一个用户空间与内核空间共享的数据结构,应用程序可以直接访问这个链表,而不需要直接操作内核的数据结构,从而确保了安全性和稳定性。
总之,事件信息是在内核和用户空间之间通过复制操作传递的,而不是简单地取出或者移动已有的节点。
epoll 的方式即使监听的 Socket 数量越多的时候,效率不会大幅度降低,能够同时监听的 Socket 的数目也非常的多了,上限就为系统定义的进程打开的最大文件描述符个数。因而,epoll 被称为解决 C10K 问题的利器。
插个题外话,网上文章不少说,epoll_wait 返回时,对于就绪的事件,epoll 使用的是共享内存的方式,即用户态和内核态都指向了就绪链表,所以就避免了内存拷贝消耗。
这是错的!看过 epoll 内核源码的都知道,压根就没有使用共享内存这个玩意。你可以从下面这份代码看到, epoll_wait 实现的内核代码中调用了 __put_user 函数,这个函数就是将数据从内核拷贝到用户空间。
边缘触发和水平触发
epoll 支持两种事件触发模式,分别是边缘触发(edge-triggered,ET)和水平触发(level-triggered,LT)。
这两个术语还挺抽象的,其实它们的区别还是很好理解的。
- 使用边缘触发模式时,当被监控的 Socket 描述符上有可读事件发生时,服务器端只会从 epoll_wait 中苏醒一次,即使进程没有调用 read 函数从内核读取数据,也依然只苏醒一次,因此我们程序要保证一次性将内核缓冲区的数据读取完;
- 使用水平触发模式时,当被监控的 Socket 上有可读事件发生时,服务器端不断地从 epoll_wait 中苏醒,直到内核缓冲区数据被 read 函数读完才结束,目的是告诉我们有数据需要读取;
举个例子,你的快递被放到了一个快递箱里,如果快递箱只会通过短信通知你一次,即使你一直没有去取,它也不会再发送第二条短信提醒你,这个方式就是边缘触发;如果快递箱发现你的快递没有被取出,它就会不停地发短信通知你,直到你取出了快递,它才消停,这个就是水平触发的方式。
这就是两者的区别,水平触发的意思是只要满足事件的条件,比如内核中有数据需要读,就一直不断地把这个事件传递给用户;而边缘触发的意思是只有第一次满足条件的时候才触发,之后就不会再传递同样的事件了。
如果使用水平触发模式,当内核通知文件描述符可读写时,接下来还可以继续去检测它的状态,看它是否依然可读或可写。所以在收到通知后,没必要一次执行尽可能多的读写操作。
如果使用边缘触发模式,I/O 事件发生时只会通知一次,而且我们不知道到底能读写多少数据,所以在收到通知后应尽可能地读写数据,以免错失读写的机会。因此,我们会循环从文件描述符读写数据,那么如果文件描述符是阻塞的,没有数据可读写时,进程会阻塞在读写函数那里,程序就没办法继续往下执行。所以,边缘触发模式一般和非阻塞 I/O 搭配使用,程序会一直执行 I/O 操作,直到系统调用(如 read 和 write)返回错误,错误类型为 EAGAIN 或 EWOULDBLOCK。
一般来说,边缘触发的效率比水平触发的效率要高,因为边缘触发可以减少 epoll_wait 的系统调用次数,系统调用也是有一定的开销的的,毕竟也存在上下文的切换。
select/poll 只有水平触发模式,epoll 默认的触发模式是水平触发,但是可以根据应用场景设置为边缘触发模式。
多路复用 API 返回的事件并不一定可读写的,如果使用阻塞 I/O, 那么在调用 read/write 时则会发生程序阻塞,因此最好搭配非阻塞 I/O,以便应对极少数的特殊情况。
面试题
前两天在面试时候,面试官问了我一个问题,在多线程的环境下面,使用epoll需要注意一些什么
当时我在想epoll不就是为了解决多线程或者是多进程的环境下,资源调度浪费过大的问题吗?没有想过为什么会有多线程的环境,所以没打出来。现在想想估计是为了问多线程应该注意什么
多线程环境下要注意:
-
线程安全性:由于 epoll 实例可以在多个线程中使用,因此需要确保对 epoll 实例的操作是线程安全的,可以通过加锁等方式实现。
-
资源管理:需要注意及时释放不再需要的资源,例如关闭套接字、释放线程等,以避免资源泄漏问题。
-
错误处理:需要适当地处理可能出现的错误情况,例如套接字连接失败、接收数据失败等,以确保程序的稳定性和可靠性。
-
性能优化:尽量减少 epoll_wait() 的阻塞时间,可以使用超时参数避免长时间阻塞,或者考虑使用边缘触发模式以提高性能。
-
合理的事件处理:需要合理地处理事件,例如新连接到达时需要将客户端套接字加入 epoll 实例中并启动新的线程处理连接,而不是在主循环中直接处理连接。
-
适当的调试和测试:在使用 epoll 时需要进行充分的调试和测试,以确保程序的正确性和稳定性,尤其是在多线程环境中。
相关文章:
I/O多路复用:select/poll/epoll
最基本的 Socket 模型 要想客户端和服务器能在网络中通信,那必须得使用 Socket 编程,它是进程间通信里比较特别的方式,特别之处在于它是可以跨主机间通信。 Socket 的中文名叫作插口,咋一看还挺迷惑的。事实上,双方要…...
使用ansible批量修改操作系统管理员账号密码
一、ansible server端配置 1、对于Linux主机配置免密登录ssh-copy-id -i ~/.ssh/id_rsa.pub rootremote_ip 2、在/etc/ansible/hosts文件中添加相应主机IP 3、对于Windows主机需要在/etc/ansible/hosts文件中进行以下配置 192.168.83.132 ansible_ssh_useradministrator an…...
webpack5零基础入门-13生产模式
1.生产模式介绍 生产模式是开发完成代码后,我们需要得到代码将来部署上线。 这个模式下我们主要对代码进行优化,让其运行性能更好。 优化主要从两个角度出发: 优化代码运行性能优化代码打包速度 2.生产模式准备 我们分别准备两个配置文件来放不同的…...
一篇复现Docker镜像操作与容器操作
华子目录 Docker镜像操作创建镜像方式1docker commit示例 方式2docker import示例1:从本地文件系统导入示例2:从远程URL导入注意事项 方式3docker build示例1:构建镜像并指定名称和标签示例2:使用自定义的 Dockerfile 路径构建镜像…...

【LevelDB】memtable、immutable memtable的切换源码
本文主要分析leveldb项目的MakeRoomForWrite方法及延伸出的相关方法。 努力弄清memtable 和 immutable memtable的切换过程细节, 背景总结: LevelDB 是一个基于 Log-Structured Merge-Tree (LSM Tree) 的高性能键值存储系统。 在 LevelDB 中࿰…...
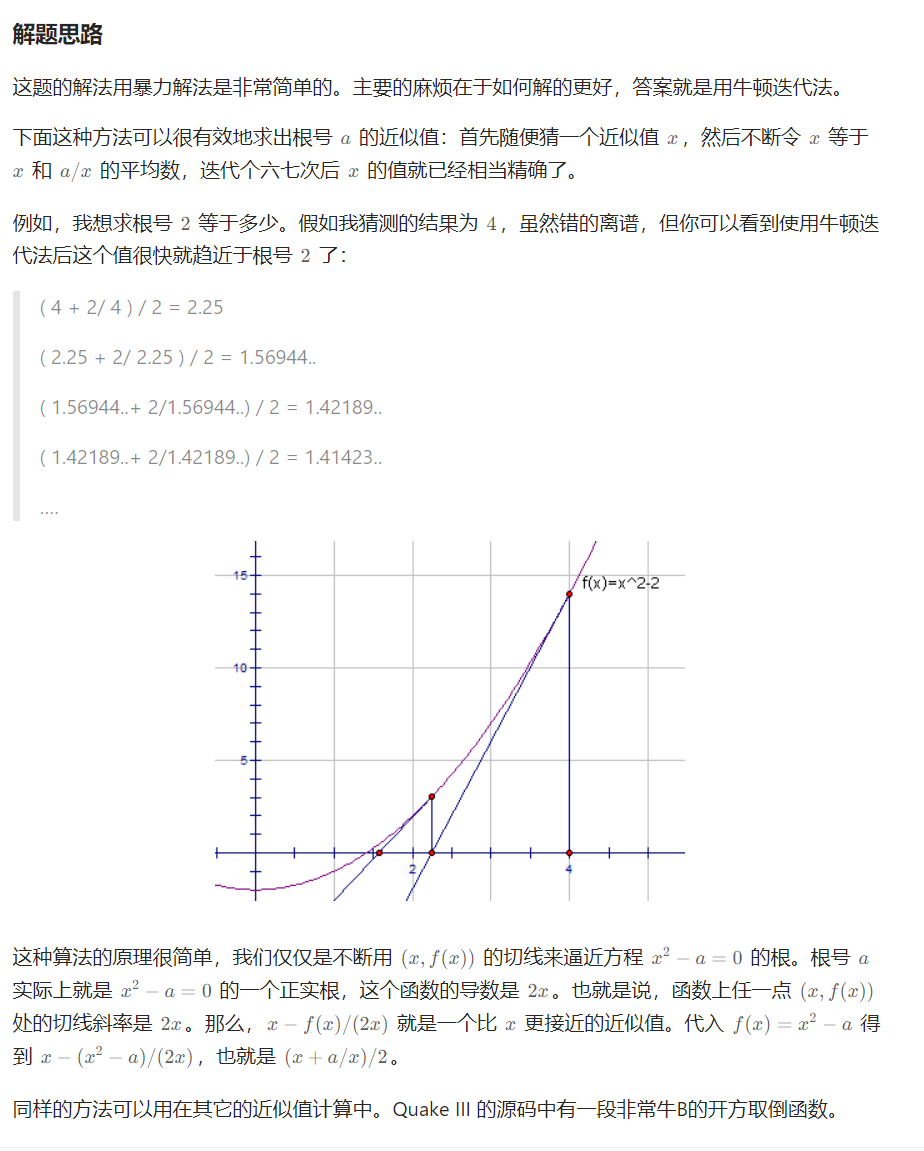
力扣面试150 x 的平方根 二分 换底法 牛顿迭代法 一题多解
Problem: 69. x 的平方根 思路 👨🏫 参考题解 💖 袖珍计算器算法 class Solution {public int mySqrt(int x){if (x 0)return 0; // Math.exp(3):e的三次方int ans (int) Math.exp(0.5 * Math.log(x));return (long) (an…...
【JavaScript】JavaScript 程序流程控制 ⑤ ( 嵌套 for 循环 | 嵌套 for 循环概念 | 嵌套 for 循环语法结构 )
文章目录 一、嵌套 for 循环1、嵌套 for 循环概念2、嵌套 for 循环语法结构 二、嵌套 for 循环案例1、打印三角形2、打印乘法表 一、嵌套 for 循环 1、嵌套 for 循环概念 嵌套 for 循环 是一个 嵌套的 循环结构 , 其中一个 for 循环 位于另一个 for 循环的内部 , 分别是 外层 f…...

情感计算:大模型在情感识别与交互优化中的作用
情感计算:大模型在情感识别与交互优化中的作用 1. 背景介绍 情感计算(Affective Computing)是人工智能领域的一个重要分支,它致力于使计算机能够识别、理解、处理和模拟人类的情感。随着深度学习、大数据和计算能力的飞速发展&a…...
集合系列(十四) -ConcurrentHashMap详解
一、摘要 在之前的集合文章中,我们了解到 HashMap 在多线程环境下操作可能会导致程序死循环的线上故障! 既然在多线程环境下不能使用 HashMap,那如果我们想在多线程环境下操作 map,该怎么操作呢? 想必阅读过小编之前…...
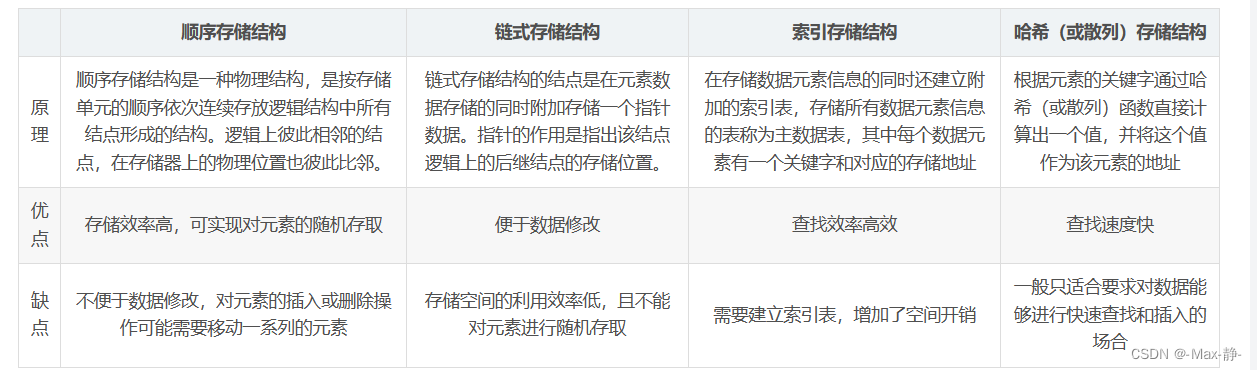
数据结构面试题
1、数据结构三要素? 逻辑结构、物理结构、数据运算 2、数组和链表的区别? 数组的特点: 数组是将元素在内存中连续存放,由于每个元素占用内存相同,可以通过下标迅速访问数组中任何元素。数组的插入数据和删除数据效率低…...
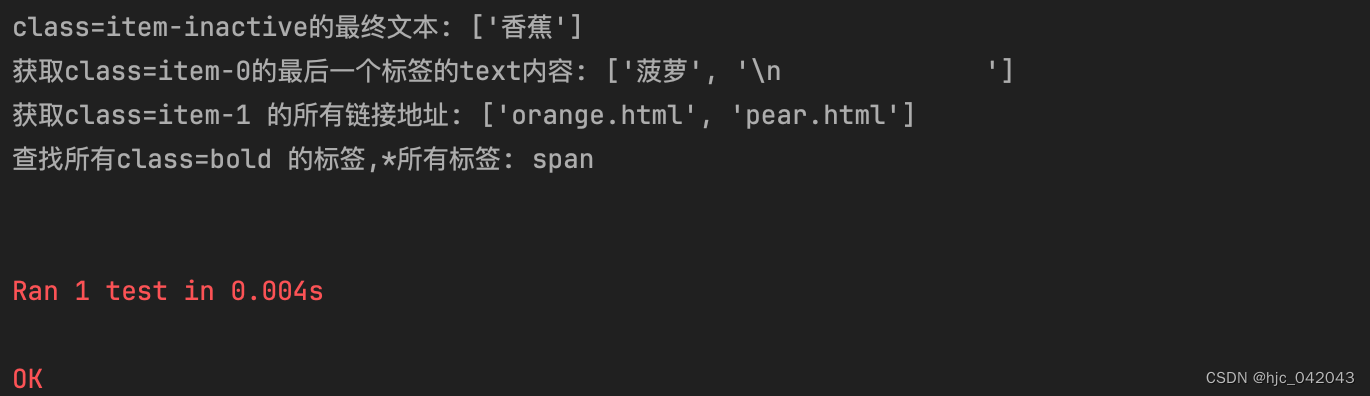
python爬虫之xpath入门
文章目录 一、前言参考文档: 二、xpath语法-基础语法常用路径表达式举例说明 三、xpath语法-谓语表达式举例注意 四、xpath语法-通配符语法实例 五、选取多个路径实例 六、Xpath Helper安装使用说明例子: 七、python中 xpath 的使用安装xpath 的依赖包xm…...
TikTok云手机是什么原理?
社交媒体的快速发展和普及,TikTok已成为全球最受欢迎的短视频平台之一,吸引了数以亿计的用户。在TikTok上,许多用户和内容创作者都希望能够更灵活地管理和运营多个账号,这就需要借助云手机技术。那么,TikTok云手机究竟…...

24.3.24 《CLR via C#》 笔记10
第十三章 接口 类和接口继承 CLR不支持多继承,因此所有托管编程语言都不支持任何类都从且只能从一个类派生(最终从Object类派生)定义接口实际只是对一组方法进行了统一的命名,类通过指定接口名称来继承接口,且必须显式…...
SpringBoot 3整合Elasticsearch 8
这里写自定义目录标题 版本说明spring boot POM依赖application.yml配置新建模型映射Repository简单测试完整项目文件目录结构windows下elasticsearch安装配置 版本说明 官网说明 本文使用最新的版本 springboot: 3.2.3 spring-data elasticsearch: 5.2.3 elasticsearch: 8.1…...
)
突破编程_C++_查找算法(分块查找)
1 算法题 :使用分块算法在有序数组中查找指定元素 1.1 题目含义 在给定一个有序数组的情况下,使用分块查找算法来查找数组中是否包含指定的元素。分块查找算法是一种结合了顺序查找和二分查找思想的算法,它将有序数组划分为若干个块&#x…...

学习java第二十二天
IOC 容器具有依赖注入功能的容器,它可以创建对象,IOC 容器负责实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。通常new一个实例,控制权由程序员控制,而"控制反转"是指new实例工作不由程序员来做而是交给Sp…...

每天学习一个Linux命令之systemctl
每天学习一个Linux命令之systemctl 介绍 在Linux系统中,systemctl命令是Systemd初始化系统的核心管理工具之一。systemd是用来启动、管理和监控运行在Linux上的系统的第一个进程(PID 1),它提供了一整套强大的工具和功能…...

【机器学习入门】人工神经网络(二)卷积和池化
系列文章目录 第1章 专家系统 第2章 决策树 第3章 神经元和感知机 识别手写数字——感知机 第4章 线性回归 第5章 逻辑斯蒂回归和分类 第5章 支持向量机 第6章 人工神经网络(一) 文章目录 系列文章目录前言一、卷积神经连接的局部性平移不变性 二、卷积处理图像的效果代码二、…...

公司内部局域网怎么适用飞书?
随着数字化办公的普及,企业对于内部沟通和文件传输的需求日益增长。飞书作为一款集成了即时通讯、云文档、日程管理、视频会议等多种功能的智能协作平台,已经成为许多企业提高工作效率的首选工具。本文将详细介绍如何在公司内部局域网中应用飞书…...
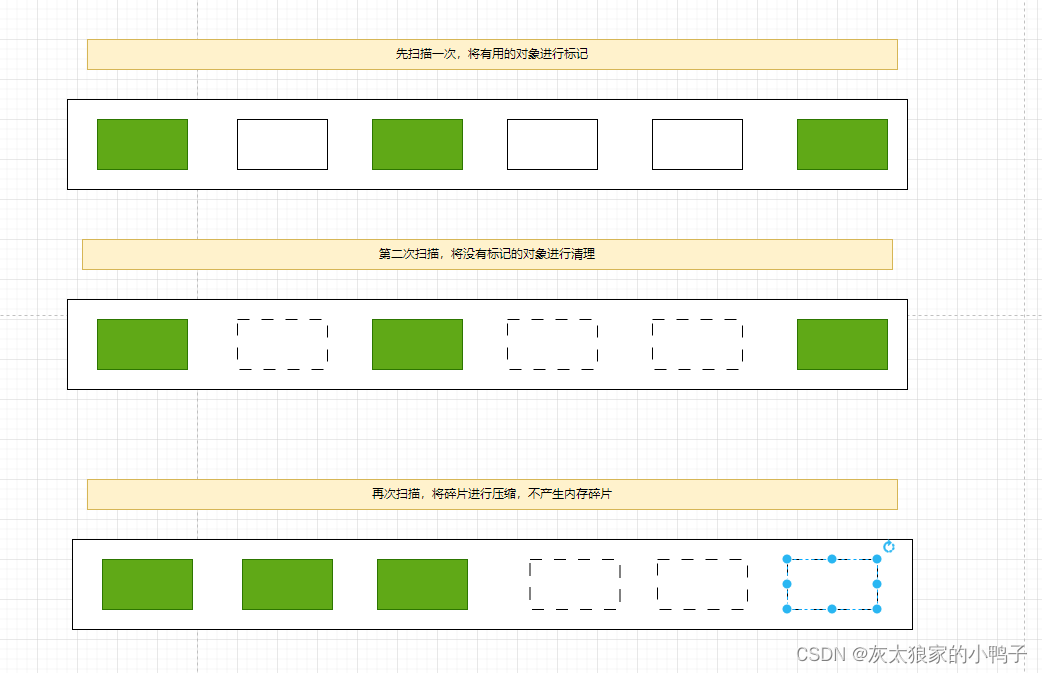
JVM的知识
什么是JVM 1.JVM: JVM其实就是运行在 操作系统之上的一个特殊的软件。 2.JVM的内部结构: (1)因为栈会将执行的程序弹出栈。 (2)垃圾99%的都是在堆和方法区中产生的。 类加载器:加载class文件。…...

DISMTools企业部署:在组织中大规模应用的最佳实践
DISMTools企业部署:在组织中大规模应用的最佳实践 【免费下载链接】DISMTools The connected place for Windows system administration 项目地址: https://gitcode.com/GitHub_Trending/di/DISMTools DISMTools是一款专为Windows系统管理设计的连接平台&…...

SwitchyOmega+Burp无感抓包实战:解决HTTPS拦截与流量路由难题
1. 为什么“无感抓包”是BurpSuite日常使用的分水岭刚接触Web安全测试的朋友常有个错觉:装上Burp Suite,配好代理,打开浏览器,点几下网页——流量就该自动进来了。结果现实是:首页打不开、登录态丢失、HTTPS报错满屏、…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

从入门到实践:EEG公开数据集分类与应用场景全解析
1. EEG公开数据集入门指南刚接触脑电信号分析的研究者,常常会被一个问题困扰:"我应该从哪里获取可靠的EEG数据?"作为一个在这个领域摸爬滚打多年的研究者,我完全理解这种困惑。记得我第一次接触EEG研究时,光…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

第三卷第4章:原型模式设计思想
第三卷第4章:原型模式设计思想 目录介绍 01.案例引入与思考 1.1 痛点场景 1.2 它哪里不舒服 1.3 引出本篇主角 02.原型模式介绍 2.1 原型模式由来 2.2 原型模式定义...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

Ubuntu经常安装软件
1、垃圾清理工具stacer sudo apt updatesudo apt install stacer apt cleanapt autocleanapt autoremove 2、类似与everything的工具Fsearcch 1sudo add-apt-repository ppa:christian-boxdoerfer/fsearch-stable 2sudo apt update 3sudo apt install fsearch (注…...

风控系统如何全维度识别爬虫:IP、账号与行为的协同决策机制
1. 这不是“反爬失败”,而是风控系统在对你做全维度画像你写完一段 requests BeautifulSoup 的代码,本地跑通了,开开心心部署到服务器,结果第二天早上发现:所有请求返回 403,日志里全是空响应;…...

BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器
BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...