大模型知识点汇总——分布式训练
PS:本篇只在宏观上介绍相关概念和技术,不做数学推导和过于细节介绍,旨在快速有一个宏观认知,不拘泥在细节上,导致很混乱。
涉及技术名词
分布式框架等涉及的技术名词很多,很容易让人眼花缭乱,整体可以概括如下:
1、混合精度训练。
2、并行维度:数据并行、张量并行、流水线并行、模型并行、3D并行、混合并行。
3、ZeRO 1、ZeRO 2、ZeRO 3、ZeRO-offload
4、框架(基本都有或就是基于pytorch):Megatron、DeepSpeed、Megatron-LM、Megatron-DeepSpeed 、pytorch 自带的FSDP。
5、关于Attention优化:Flash Attention、Flash Attention 2、 Paged Attention、Xformers、MHA、MQA、GQA。
6、硬件:nvlink、nvswitch、Infiniband。
1、混合精度训练
目的是降低显存消耗和加速推理过程。大致原理是模型参数、梯度、激活等使用FP16或BF16,然后再保存一份模型的状态(sgd,如果是Adam则包含模型、一阶专状态、二阶状态三份参数)用于梯度更新。原因是单纯半精度有如下问题:
1)溢出错误:由于FP16的动态范围比FP32位的狭窄很多,因此,在计算过程中很容易出现上溢出和下溢出,溢出之后就会出现"NaN"的问题。在深度学习中,由于激活函数的梯度往往要比权重梯度小,更易出现下溢出的情况。
2)舍入误差:当梯度过小时,小于当前区间内的最小间隔时,该次梯度更新可能会失败。
如下为不同精度的表示。由于 FP16 和 BF16 相较 FP32 精度低,训练过程中可能会出现梯度消失和模型不稳定的问题。因此,需要使用一些技术来解决这些问题,例如动态损失缩放(Dynamic Loss Scaling)和混合精度优化器(Mixed Precision Optimizer)。
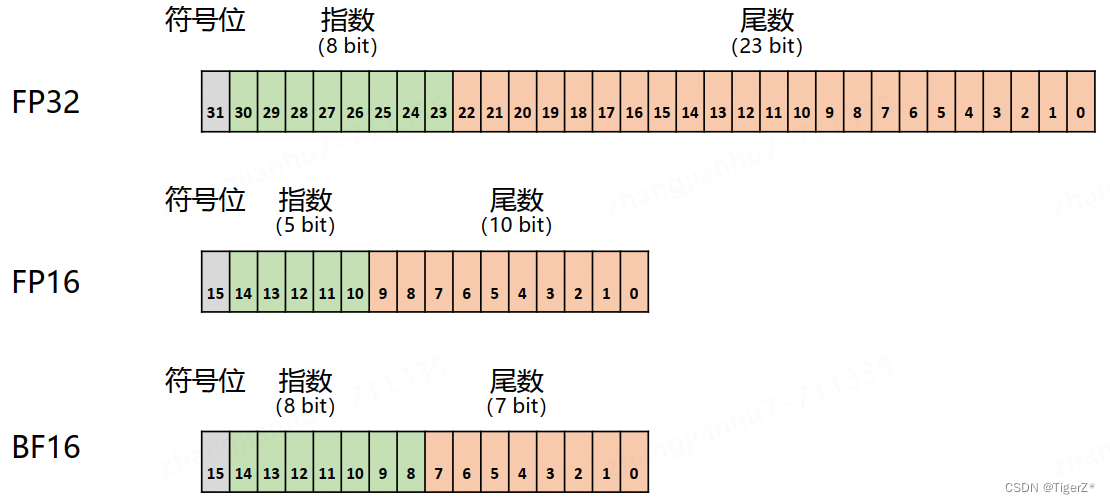
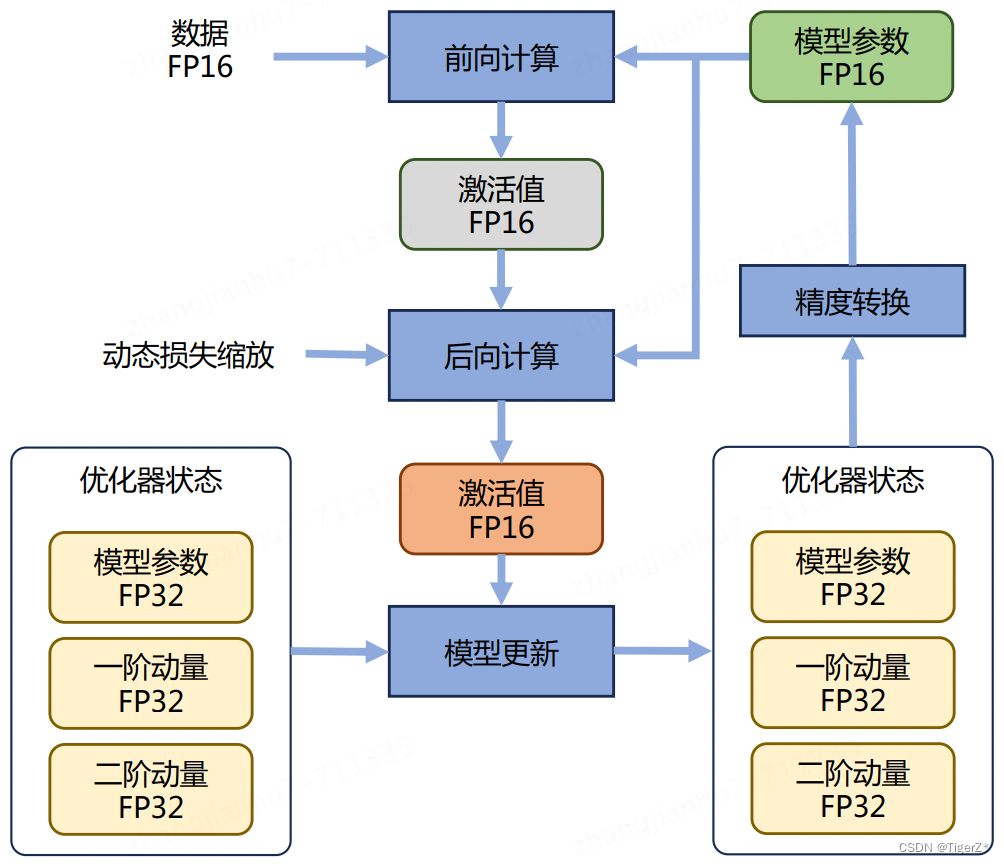
混合训练整体流程如下(Adam为例)。 Adam 优化器状态包括采用 FP32 保存的模型参数备份,一阶动量和二阶动量也都采用 FP32 格式存储。假设模型参数量为 Φ,模型参数和梯度都是用 FP16格式存储,则共需要 2Φ + 2Φ + (4Φ + 4Φ + 4Φ) = 16Φ 字节存储。其中 Adam 状态占比 75%。动态损失缩放反向传播前,将损失变化(dLoss)手动增大 2K 倍,因此反向传播时得到的激活函数梯度则不会溢出;反向传播后,将权重梯度缩小 2K 倍,恢复正常值。举例来说,对于包含 75 亿个参数模型,如果用 FP16 格式,只需要 15GB 计算设备内存,但是在训练阶段模型状态实际上需要耗费 120GB。
使用方式很简单(需要Tensor core 支持),如下
# amp依赖Tensor core架构,所以模型必须在cuda设备下使用
model = Model()
model.to("cuda") # 必须!!!
optimizer = optim.SGD(model.parameters(), ...)# (新增)创建GradScaler对象
scaler = GradScaler(enabled=True) # 虽然默认为True,体验一下过程for epoch in epochs:for img, target in data:optimizer.zero_grad()# (新增)启动autocast上下文管理器with autocast(enabled=True):# (不变)上下文管理器下,model前向传播,以及loss计算自动切换数值精度output = model(img)loss = loss_fn(output, target)# (修改)反向传播scaler.scale(loss).backward()# (修改)梯度计算scaler.step(optimizer)# (新增)scaler更新scaler.update()但是注意并行训练时需要autocast装饰model的forward函数
MyModel(nn.Module):@autocast()def forward(self, input):...2、并行维度
单设备计算速度主要由单块计算加速芯片的运算速度和数据 I/O 能力来决定,对单设备训练效率进行优化,主要的技术手段有混合精度训练、算子融合、梯度累加等;多设备加速比需要综合考虑计算、显存、通信三方面因素。
并行大体上分为:数据并行、模型并行(细分为流水线并行和张量并行)、混合并行(也叫3D并行,混合使用数据并行和模型并行)。
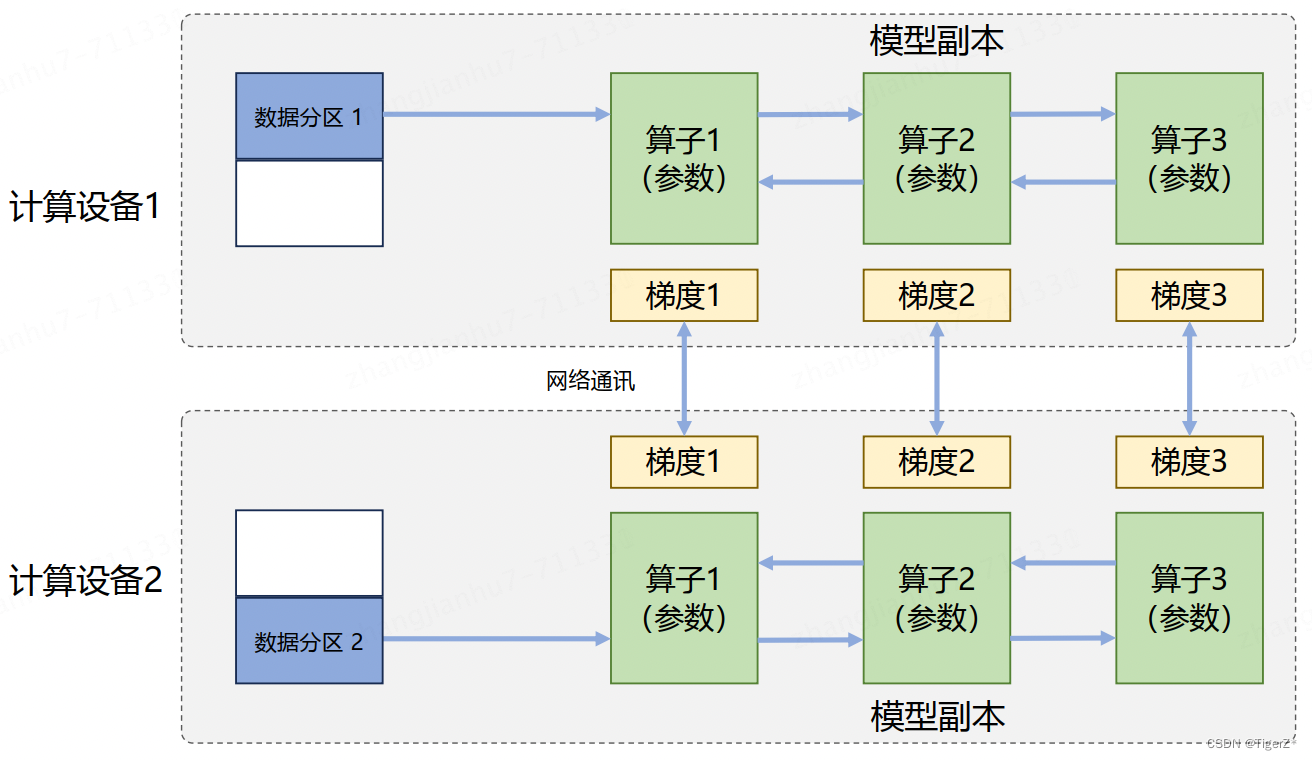
数据并行:对数据进行切分,并将同一个模型复制到多个设备上,并行执行不同的数据分片,这种方式通常被称为数据并行。它和单计算设备训练相比,最主要的区别就在于反向计算中的梯度需要在所有计算设备中进行同步,以保证每个计算设备上最终得到的是所有进程上梯度的平均值。
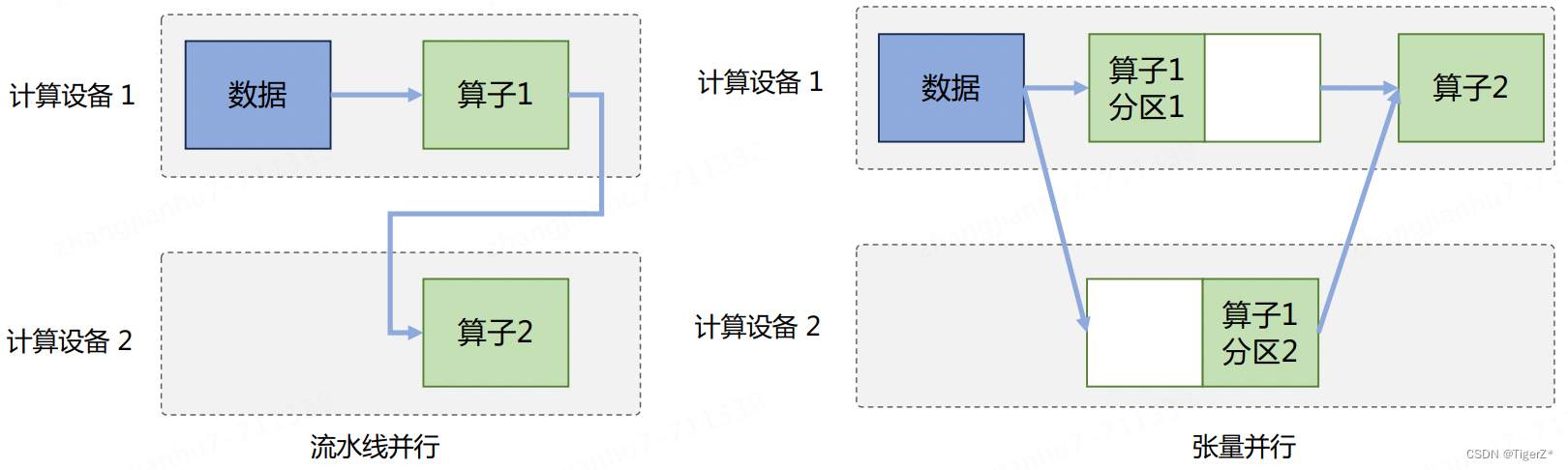
模型并行:对模型进行划分,将模型中的算子分发到多个设备分别完成,往往用于解决单节点内存不足的问题。模型并行从计算图角度分为如下两种:
1)按模型的层切分到不同设备,即层间并行或算子间并行(Inter-operator Parallelism),也称之为流水线并行(Pipeline Parallelism, PP);
2)将计算图层内的参数切分到不同设备,即层内并行或算子内并行(Intra-operator Parallelism),也称之为张量并行(Tensor Parallelism, TP)。需要根据模型的具体结构和算子类型,解决如何将参数切分到不同设备,以及如何保证切分后数学一致性两个问题。
其中流水线并行存在的问题就是并行气泡,改进方案有:Gpipe(数据分割成更小的micro-batch)、megtron里面的1F1B策略(每个设备可以并行执行不同阶段的计算任务)。
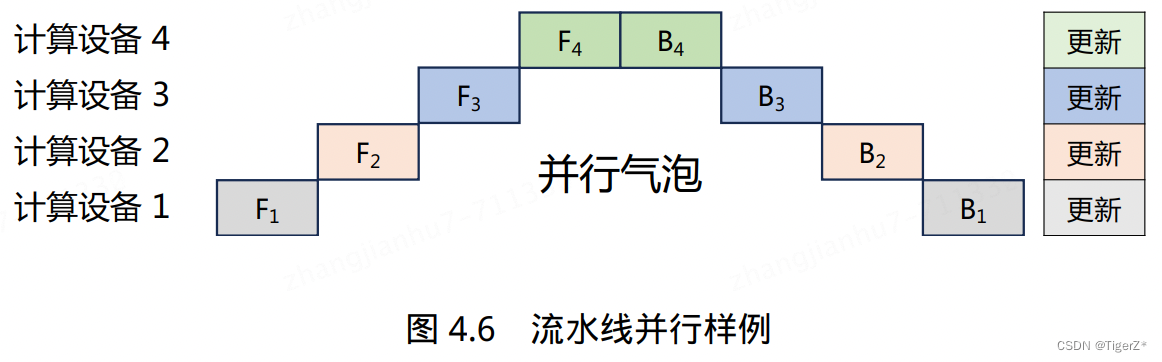

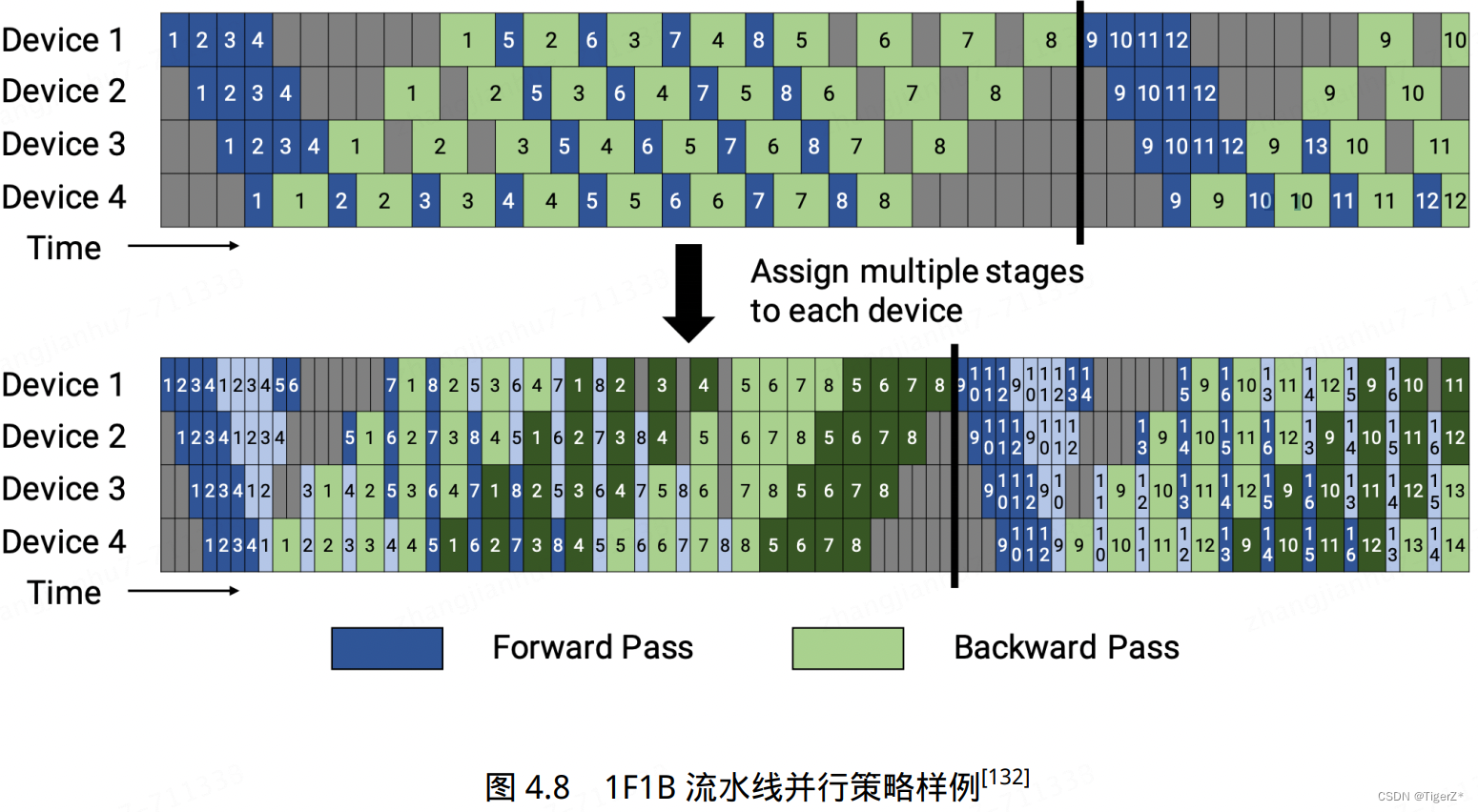
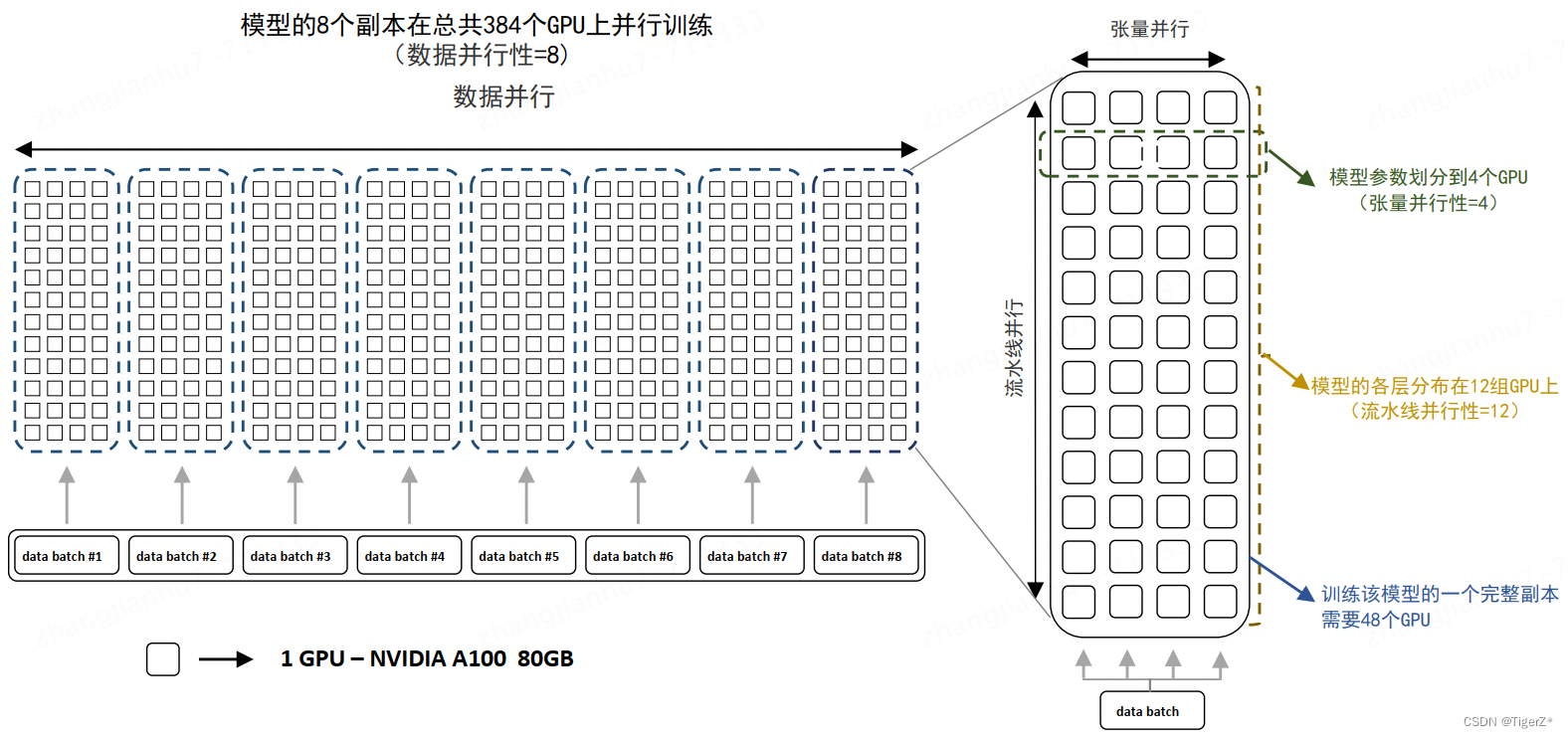
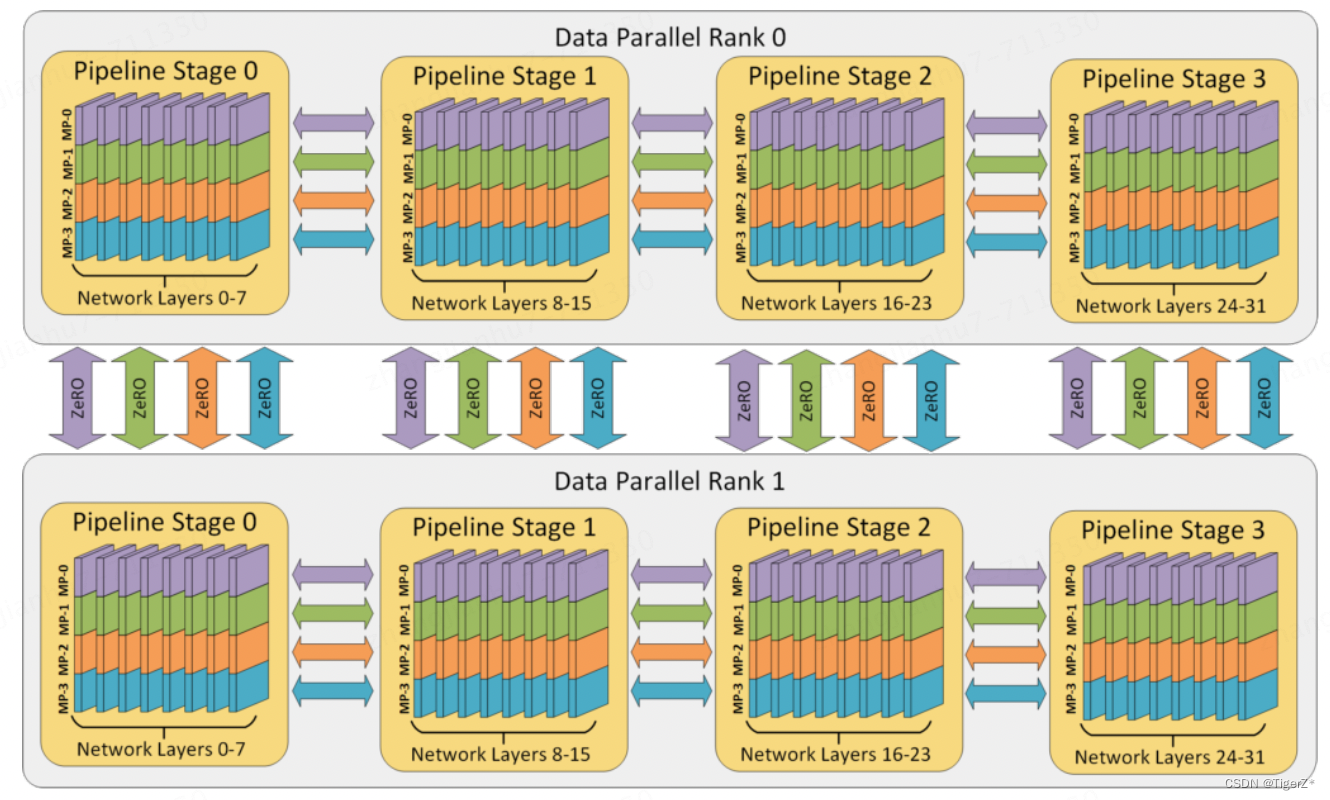
混合并行:训练超大规模语言模型时,往往需要同时对数据和模型进行切分,从而实现更高程度的并行,这种方式通常被称为混合并行。针对千亿规模的大语言模型,通常在每个服务器内部使用张量并行策略,由于该策略涉及的网络通信量较大,需要利用服务器内部的不同计算设备之间进行高速通信带宽。通过流水线并行,将模型的不同层划分为多个阶段,每个阶段由不同的机器负责计算。这样可以充分利用多台机器的计算能力,并通过机器之间的高速通信来传递计算结果和中间数据,以提高整体的计算速度和效率。最后,在外层叠加数据并行策略,以增加并发数量,提升整体训练速度。通过数据并行,将训练数据分发到多组服务器上进行并行处理,每组服务器处理不同的数据批次。参考下图BLOOM模型的训练结构。
3、zero系列优化
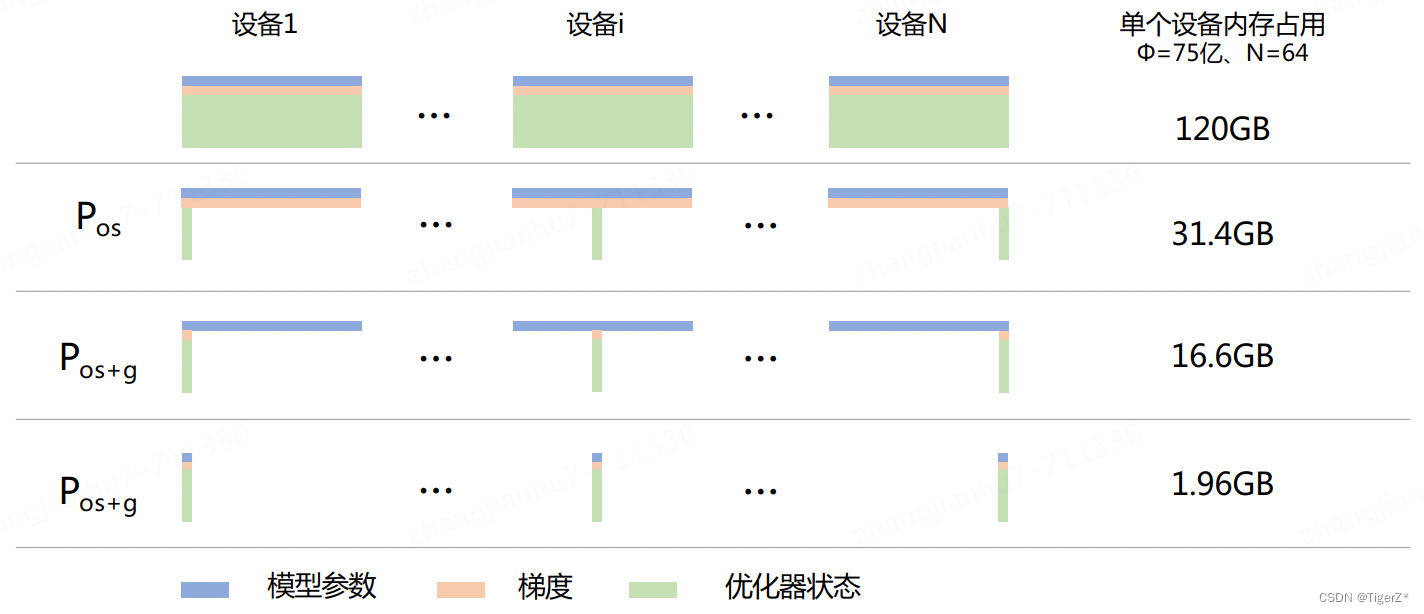
通过混合精度和并行维度前两部分的解读,对于数据并行而言,如果你使用的是Adam优化器(目前LLM几乎都是Adam),那么75%的参数都在存储FP32的模型状态。所以zero目标就是针对模型状态的存储进行去冗余的优化。本质而言是针对数据并行的优化,使用分区的方法,即将模型状态量分割成多个分区,每个计算设备只保存其中的一部分。这样整个训练系统内只需要维护一份模型状态,减少了内存消耗和通信开销。包含3种强度的去冗余(不同强度通信开销不同, Zero-1 和 Zero-2 对整体通信量没有影响,对通讯有一定延迟影响,但是整体性能影响很小。 Zero-3 所需的通信量则是正常通信量的1.5 倍。),对应下图的Pos、Pos+g、Pos+g+p:
*zero-1:对 Adam 优化器状态进行分区,图中的 Pos。模型参数和梯度依然是每个计算设备保存一份。此时,每个计算设备所需内存是 4Φ + 12Φ/N 字节,其中 N 是计算设备总数。当 N 比较大时,每个计算设备占用内存趋向于 4ΦB,也就是原来 16ΦB 的 1/4。
*zero-2:对模型梯度进行分区,图中的 Pos+g。模型参数依然是每个计算设备保存一份。此时,每个计算设备所需内存是 2Φ + (2Φ+12Φ)/N 字节。当 N 比较大时,每个计算设备占用内存趋向于2ΦB,也就是原来 16ΦB 的 1/8。
*zero-3: 对模型参数也进行分区,图中的 Pos+g+p。此时,每个计算设备所需内存是 (16Φ /N) * B。当 N比较大时,每个计算设备占用内存趋向于 0。
*ZeRO Infinity:可以看成是stage-3的进阶版本,需要依赖于NVMe的支持。他可以offload所有模型参数状态到CPU以及NVMe上。得益于NMVe协议,除了使用CPU内存之外,ZeRO可以额外利用SSD(固态),从而极大地节约了memory开销,加速了通信速度。
使用方法: DeepSpeed使用过程中的一个难点,就在于时间和空间的权衡。先使用下述代码,大概估计一下显存消耗,决定使用的GPU数目,以及ZeRO-stage。原则是,能直接多卡训练,就不要用ZeRO;能用ZeRO-2就不要用ZeRO-3。
from transformers import AutoModel
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live## specify the model you want to train on your device
model = AutoModel.from_pretrained("t5-large")## estimate the memory cost (both CPU and GPU)
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)真实使用主要就是三点:安装DeepSpeed、编写配置文件、训练shell命令。具体可以参考:DeepSpeed使用指南(简略版)-CSDN博客
1)安装(transformers 默认已经集成了deepspeed):
pip install deepspeed # 或 pip install transformers2)编写配置文件,以zero-2为例,命名为ds_config.json
{"bfloat16": {"enabled": "auto"},"fp16": {"enabled": "auto","loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"optimizer": {"type": "AdamW","params": {"lr": "auto","betas": "auto","eps": "auto","weight_decay": "auto"}},"scheduler": {"type": "WarmupLR","params": {"warmup_min_lr": "auto","warmup_max_lr": "auto","warmup_num_steps": "auto"}},"zero_optimization": {"stage": 2,"offload_optimizer": {"device": "cpu","pin_memory": true},"allgather_partitions": true,"allgather_bucket_size": 2e8,"overlap_comm": true,"reduce_scatter": true,"reduce_bucket_size": 2e8,"contiguous_gradients": true},"gradient_accumulation_steps": "auto","gradient_clipping": "auto","train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","steps_per_print": 1e5}3)编写启动shell脚本
deepspeed --master_port 29500 --num_gpus=2 run_s2s.py --deepspeed ds_config.json4、框架
Megatron、DeepSpeed、Megatron-LM、Megatron-DeepSpeed 、pytorch 自带的FSDP。目前网上已有总结也不是很清楚,其中DeepSpeed是微软的,Megtron是NVIDIA的,用的最多的是deepspeed, transformers库很多也是用Deepspeed。然后DeepSpeed也集成了megatron,所以目前我的理解是用DeepSpeed作为基础(本身基于pytorch),再集成使用megatron、pytorch、flash Attention2是202303xx最优解?
PS:在 DeepSpeed 框架个人理解最大的优势就是zero优化(zero论文和DeepSpeed都是微软团队), Pos 对应 Zero-1, Pos+g 对应 Zero-2, Pos+g+p 对应 Zero-3。
如下给出了 DeepSpeed 3D 并行策略示意图。图中给出了包含 32 个计算设备进行 3D 并行的例子。神经网络的各层分为 4 个流水线阶段。每个流水线阶段中的层在 4 个张量并行计算设备之间进一步划分。最后,每个流水线阶段有两个数据并行实例,使用 ZeRO 内存优化在这 2 个副本之间划分优化器状态量。
5、关于Attention优化
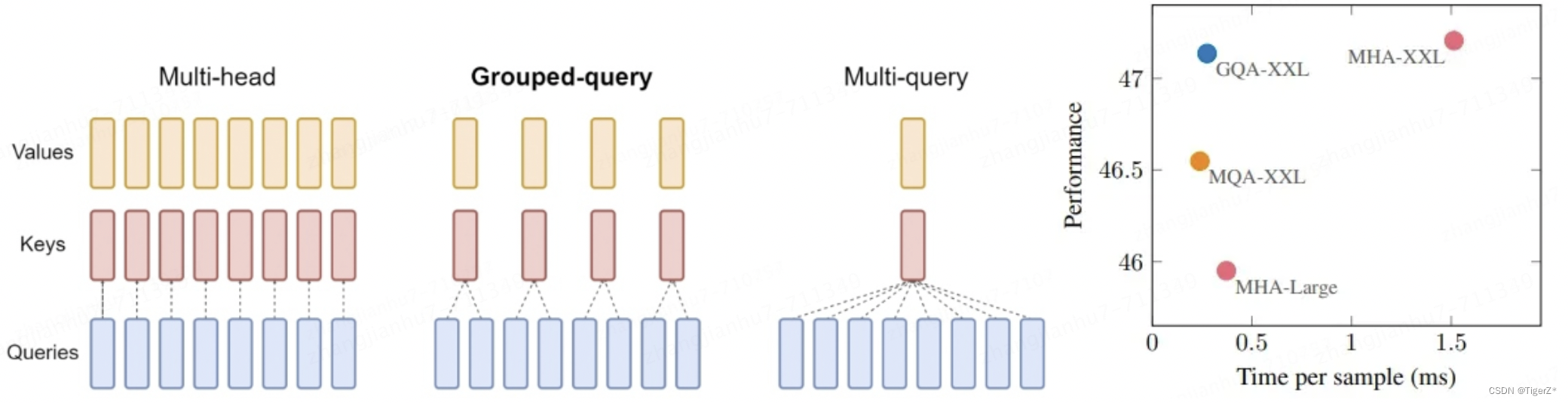
MHA、MQA、GQA
是算法上的概念,对应不同的注意力机制,如下图。
1)MHA(Multi Head Attention)中,每个头有自己单独的 key-value 对;
2)MQA(Multi Query Attention)中只会有一组 key-value 对;
3)GQA(Grouped Query Attention)中,会对 attention 进行分组操作,query 被分为 N 组,每个组共享一个 Key 和 Value 矩阵。GQA-N 是指具有 N 组的 Grouped Query Attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。
flash Attention、 flash Attention 2、xformer、 Paged Attention
工程实现优化Attention的推理性能。
Flash Attention、Flash Attention 2:主要是利用GPU的并行特性从循环角度进行优化。
Paged Attention:主要是针对KV的缓存(cache)的优化。
Xformer:虽然有优化显存等,底层也用了flash Attention,我的理解是个库,有很多实现。
使用都很简单,都是一句话直接调用,参考:速度飙升200%!Flash Attention 2一统江湖,注意力计算不再是问题! - 知乎,涉及代码如下:
import torch
import torch.nn.functional as F
from flash_attn import flash_attn_func
from xformers.ops import memory_efficient_attention, LowerTriangularMaskdef pytorch_func(q, k, v, causal=False):o = F._scaled_dot_product_attention(q, k, v, is_causal=causal)[0]return odef flash_attention(q, k, v, causal=False):o = flash_attn_func(q, k, v, causal=causal)return odef xformers_attention(q, k, v, causal=False):attn_bias = xformers_attn_bias if causal else Noneo = memory_efficient_attention(q, k, v, attn_bias=attn_bias)return o6、硬件架构
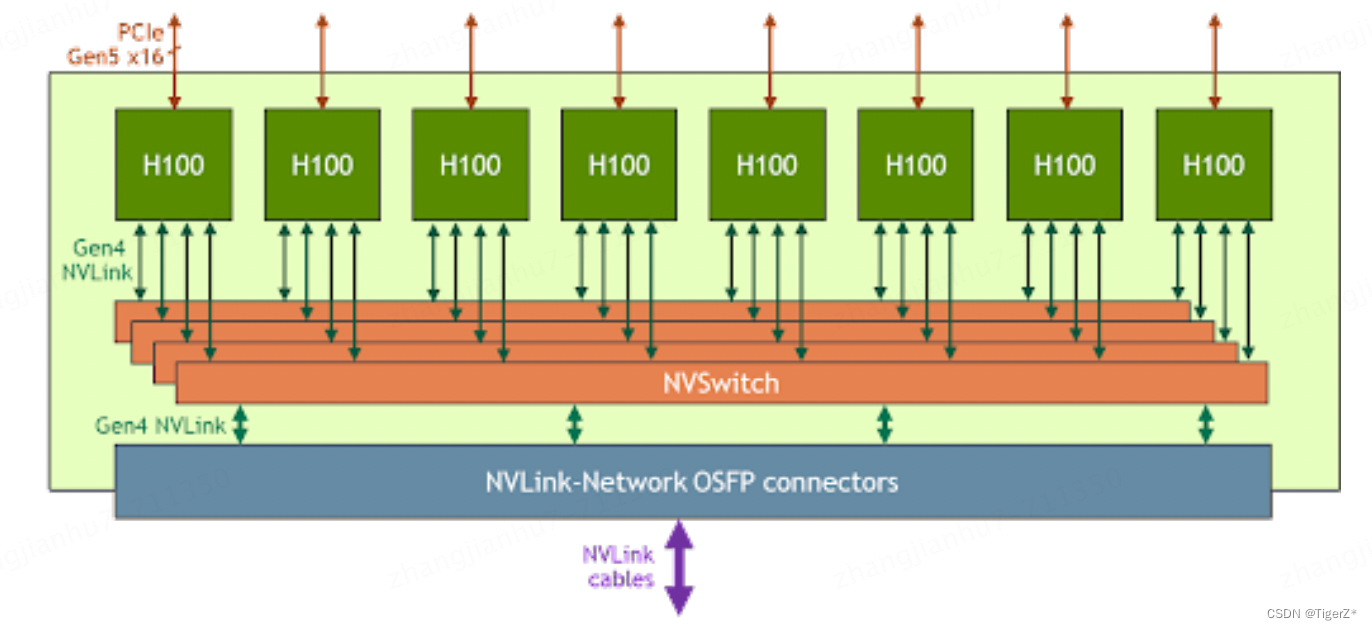
NVLink可以简单理解是GPU卡上有通信接口(网口网线的概念)。nv switch可以理解为是交换机(确实是一个硬件),同一台机器(pod)不同GPU使用nvswich 底层通过nvlink链接(如果卡很少,我的理解其实可以不使用nvswtich,直接卡间互联)。可以参考如下图
不同机器(pod)之间通过采用InfiniBand网络通信标准的交换机链接,如下图: 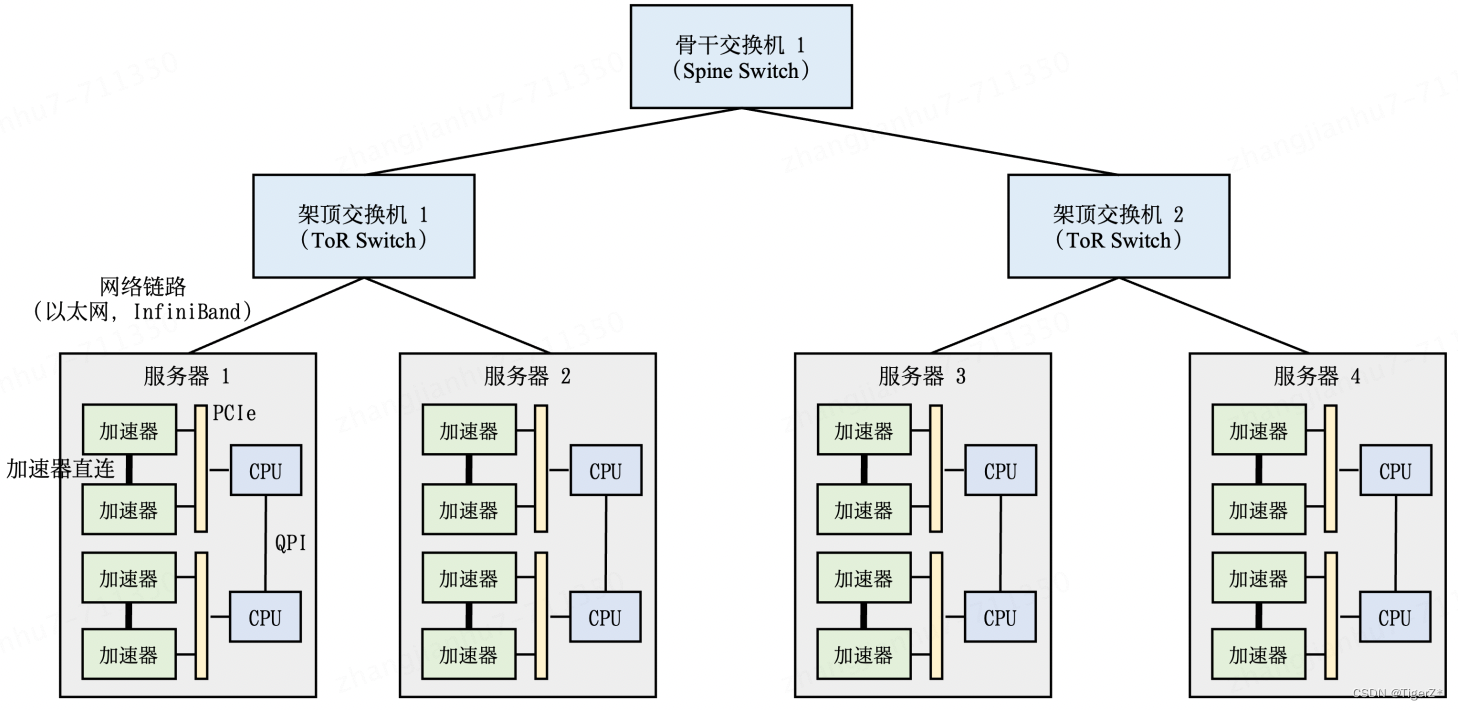
参考链接:
[LLM]大模型训练(一)--DeepSpeed介绍-CSDN博客
LLM(十七):从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能 - 知乎
相关文章:
大模型知识点汇总——分布式训练
PS:本篇只在宏观上介绍相关概念和技术,不做数学推导和过于细节介绍,旨在快速有一个宏观认知,不拘泥在细节上,导致很混乱。 涉及技术名词 分布式框架等涉及的技术名词很多,很容易让人眼花缭乱,…...

java之网络编程
网络编程之TCP/IP协议 网络编程分为两个不同的层次:一是基于Socket的低层次网络编程,二是基于URL的高层次网络编程 高低层次就是通信协议的高低层次,Socket采用TCP、UDP等协议,这些协议属于低层次的通信协议;URL采用H…...
【Linux】Centos7安装redis
目录 下载安装包安装1.解压2.环境安装3.查看redis的安装路径4.将之前redis的配置文件,复制到安装路径下(新建一个文件夹并复制)5.redis 设置默认后台启动,修改配置文件6.启动redis服务默认启动通过配置文件启动查看进程 7.开放637…...

蓝桥杯(2):python基础算法【上】
时间复杂度、枚举、模拟、递归、进制转换、前缀和、差分、离散化 1 时间复杂度 重要是看循环,一共运行了几次 1.1 简单代码看循环 #时间复杂度1 n int(input()) for i in range(1,n1):for j in range(0,i):pass ###时间复杂度:123....nn(1n)/2 所以…...

一个js正则,轻松去除字符串里的\n\t空格
推荐一款AI网站,免费使用GPT3.5,戳此入👇:AI写作 在Node.js中,如果你想要从字符串中全局去除换行符(\n)、制表符(\t)和空格,你可以使用正则表达式与String.prototype.replace()方法结合使用。下面是一个简…...
政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(四)—— 过拟合和欠拟合
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: Tensorflow与Keras实战演绎 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 通过增加容量或提前停止来提高性能。 在深度学习中&…...
RuoYi-Vue若依框架-代码生成器的使用
代码生成器 导入表 在系统工具内找到代码生成,点击导入,会显示数据库内未被导入的数据库表单,选择自己需要生成代码的表,友情提醒,第一次使用最好先导入一张表进行试水~ 预览 操作成功后可以点击预览查看效果&…...

AI PPT生成工具 V1.0.0
AI PPT是一款高效快速的PPT生成工具,能够一键生成符合相关主题的PPT文件,大大提高工作效率。生成的PPT内容专业、细致、实用。 软件特点 免费无广告,简单易用,快速高效,提高工作效率 一键生成相关主题的标题、大纲、…...

进程和线程,线程实现的几种基本方法
什么是进程? 我们这里学习进程是为了后面的线程做铺垫的。 一个程序运行起来,在操作系统中,就会出现对应的进程。简单的来说,一个进程就是跑起来的应用程序。 在电脑上我们可以通过任务管理器可以看到,跑起来的应用程…...
返回False的问题)
【PyTorch】解决PyTorch安装中torch.cuda.is_available()返回False的问题
最近在安装PyTorch时遇到torch.cuda.is_available() False的问题,特此记录下解决方法,以帮助其他遇到相同问题的人。 问题描述 Ubuntu 20.04,3060 Laptop,安装了CUDA 11.4,在Anaconda下新建了Python 3.8的环境&…...
95% 的公司面临 API 安全问题
API 对企业安全发挥着关键作用,但绝大多数企业都为此遭受日益严重的安全风险。据安全公司 Fastly最近做的一项调查显示,84% 的受访企业缺乏足够的API安全措施,95%的企业在过去1年中遇到过 API 安全问题。 此外,79%的受访企业出于A…...

mysql的基本知识点-排序和分组
分组(GROUP BY) GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。例如,假设你有一个包含销售数据的表,并且你想按产品类别计算总销售额。你可以使用 GROUP BY 和 SUM() 函数来实现这一点。 SELECT…...
使用uniapp 的 plus.sqlite 操作本地数据库报错:::table xxx has no column named xxxx
背景: 1、使用uniapp 的 plus.sqlite 进行APP本地数据库操作 2、SQLite 模块用于操作本地数据库文件,可实现数据库文件的创建,执行SQL语句等功能。 遇到:在之前创建的表上进行新增字段的操作时候,出现问题:…...
)
第十五届蓝桥杯模拟赛 第三期 (C++)
第二次做蓝桥模拟赛的博客记录,可能有很多不足的地方,如果大佬有更好的思路或者本文中出现错误,欢迎分享思路或者提出意见 题目A 请问 2023 有多少个约数?即有多少个正整数,使得 2023 是这个正整数的整数倍。 答案&…...
Linux中的常用基础操作
ls 列出当前目录下的子目录和文件 ls -a 列出当前目录下的所有内容(包括以.开头的隐藏文件) ls [目录名] 列出指定目录下的子目录和文件 ls -l 或 ll 以列表的形式列出当前目录下子目录和文件的详细信息 pwd 显示当前所在目录的路径 ctrll 清屏 cd…...
【SpringMVC】知识汇总
SpringMVC 短暂回来,有时间就会更新博客 文章目录 SpringMVC前言一、第一章 SpingMVC概述二、SpringMVC常用注解1. Controller注解2. RequestMapping注解3. ResponseBody注解4. RequestParam5. EnableWebMvc注解介绍6. RequestBody注解介绍7. RequestBody与RequestP…...

android13实现切换导航模式功能
支持android13以上系统,需要系统签名。 public class NavigationHelper {/*** 设置导航模式** param context* param mode GESTURAL:手势 TWOBUTTON:二按钮 THREEBUTTON:三按钮*/public static void setNavigationMode(Contex…...

Pycharm服务器配置python解释器并结合内网穿透实现公网远程开发
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

vue3+vite+Electron构建跨平台应用
1.搭建第一个 electron-vite 项目 electron-vite 是一个新型构建工具,旨在为 Electron 提供更快、更精简的开发体验。它主要由五部分组成: 一套构建指令,它使用 Vite 打包你的代码,并且它能够处理 Electron 的独特环境,包括 Node.js 和浏览器环境。 集中配置主进程、渲染…...
学习次模函数-第1章 引言
许多组合优化问题可以被转换为集合函数的最小化,集合函数是在给定基集合的子集的集合上定义的函数。同样地,它们可以被定义为超立方体的顶点上的函数,即,其中是基集合的基数-它们通常被称为伪布尔函数[27]。在这些集合函数中&…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...
)
毕业设计 yolov11骨折检测医疗辅助系统(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景2.1 研究背景2.2 国内外研究现状2.3 研究意义 3 设计框架(骨折检测系统设计框架说明)3.1. 系统架构图3.2. 技术选型3.2.1 核心组件3.2.2 辅助工具 3.3. 核心模块设计3.3.1 YOLO模型训练模块训练流程图关键伪代码…...

在Hermes Agent项目中接入Taotoken作为自定义模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Hermes Agent项目中接入Taotoken作为自定义模型供应商 基础教程类,针对使用Hermes Agent框架的开发者,详…...

危急时刻的六条基本安全提示
人机协作,AI模型:Deepseek 仅供参考 危急时刻的六条基本安全提示 以下内容仅为通用性安全建议,供在紧急情况下保持冷静、保护自身安全时参考。所有建议均基于常理和公共安全常识,不包含任何具体操作细节或可能被不当使用的信息…...

我们公司全员把 Cursor 换成了自研的 全开源AtomCode
【引子】这是一篇实录——一位 CTO 用 28 天,用 Claude GLM 双模型调度,造出了一个让全公司放弃 Cursor 的工具。然后我意识到我们正在经历的事情,比"换工具"大得多。【读者承诺】接下来 15 分钟,你会拿到三件东西:一个真实案例(28 天 1,146 commits 是怎么做出来的…...
)
DeepSeek安全测试辅助Prompt工程白皮书(含17个CVE靶场验证指令模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek安全测试辅助 DeepSeek系列大模型在代码生成、漏洞模式识别与安全上下文理解方面展现出独特优势,可作为安全测试工程师的智能协作者。其对OWASP Top 10、CWE分类体系及常见PoC结构具…...

Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案
Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 厌倦了繁琐的Switch游戏安…...
)
告别复杂模型:用Python+OpenCV+dlib实现简易驾驶员疲劳监测(附完整代码)
轻量级驾驶员疲劳监测系统:PythonOpenCVdlib实战指南 在长途驾驶或夜间行车时,疲劳是导致交通事故的重要因素之一。传统基于嵌入式设备的疲劳监测系统往往需要专用硬件,增加了开发成本和部署难度。本文将介绍如何利用Python生态中的OpenCV和d…...

AI Agent 为什么必须有“记忆系统”?
导语:大模型不是没有智商,而是经常没有“记性”。真正能长期干活的 Agent,不是靠无限拉长上下文,而是靠一套会压缩、会检索、会遗忘、会治理的外置记忆系统。一、先给结论:Agent 的记忆系统,本质是“上下文…...
和Python脚本,5分钟批量生成你的分割数据集)
告别手动标注!用SAM(Segment Anything)和Python脚本,5分钟批量生成你的分割数据集
5分钟批量生成分割数据集:SAM自动化标注全流程实战 在计算机视觉领域,数据标注一直是制约模型开发效率的瓶颈。传统手工标注不仅耗时费力,还容易引入人为误差。Meta开源的Segment Anything Model(SAM)彻底改变了这一局…...