政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(四)—— 过拟合和欠拟合
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: Tensorflow与Keras实战演绎
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
通过增加容量或提前停止来提高性能。
在深度学习中,过拟合和欠拟合是两个常见的问题,它们可能会影响模型的性能和泛化能力。
过拟合(overfitting)指的是模型在训练数据上表现良好,但在新的未见过的数据上表现较差的现象。过拟合发生的原因通常是模型能够在训练数据上学习到过多的细节和噪声,导致模型对训练数据的特点过度拟合。过拟合的表现通常是模型在训练数据上表现很好,但在验证集或测试集上表现较差。
欠拟合(underfitting)指的是模型在训练数据和新的未见过的数据上表现都不理想的现象。欠拟合发生的原因通常是模型不能够充分拟合数据的特征或模型复杂度不够。欠拟合的表现通常是模型在训练数据和新数据上的表现都不够好,无法捕捉到数据的复杂性。
解决过拟合和欠拟合的方法有一些共同的基本原则。
首先,增加训练数据量可以减少过拟合和欠拟合的可能性,因为更多的数据能够提供更多的样本和变化情况,有助于模型学习到更好的特征。
其次,调整模型的复杂度可以避免过拟合和欠拟合。如果模型过于复杂,可以考虑减少模型的参数或使用正则化技术来约束模型的学习能力。如果模型过于简单,可以增加模型的层数或参数,提高模型的学习能力。此外,还可以使用数据增强、丢弃法(dropout)等技术来减少过拟合。
总之,过拟合和欠拟合是深度学习中常见的问题,需要根据具体情况采取相应的调整措施来提高模型的性能和泛化能力。
前言
回顾一下以前文章中的示例,Keras将会保存训练和验证损失的历史记录,这些损失是在训练模型的过程中逐个epoch记录的。
在本文中,我们将学习如何解释这些学习曲线,并如何利用它们来指导模型的开发。特别是,我们将检查学习曲线以寻找欠拟合和过拟合的迹象,并讨论一些纠正策略。
解读学习曲线
可能你可以将训练数据中的信息分为两种类型:信号和噪声。
信号是可以概括的部分,可以帮助我们的模型从新数据中进行预测。
噪声则是只在训练数据中存在的部分;噪声是来自现实世界数据的所有随机波动,或者是所有不能真正帮助模型进行预测的非相关模式。噪声是看起来有用但实际上并非如此的部分。
通过选择使损失函数最小化的权重或参数来训练模型。然而,您可能知道,为了准确评估模型的性能,我们需要在新的数据集上进行评估,即验证数据集。
当我们训练模型时,我们会将每个时期的训练集损失绘制成图表。此外,我们还会绘制验证数据的图表。这些图表被称为学习曲线。为了有效地训练深度学习模型,我们需要能够解读这些学习曲线。
(验证损失提供了对未见数据的预期错误的估计。)

现在,当模型学习到信号或噪声时,训练损失会下降。但是,只有当模型学习到信号时,验证损失才会下降。(模型从训练集中学到的噪声不会推广到新数据。)因此,当模型学习到信号时,两条曲线都下降,但是当模型学习到噪声时,曲线间会出现差距。差距的大小告诉您模型学到了多少噪声。
理想情况下,我们希望创建的模型能够学习到所有的信号,而不学习到任何噪音。
然而,实际上这几乎不可能发生。相反,我们要进行一种权衡。
我们可以让模型学习更多的信号,但代价是学习到更多的噪音。只要这种权衡对我们有利,验证损失就会继续减小。然而,在某一点之后,这种权衡可能会对我们不利,代价超过了收益,验证损失开始上升。
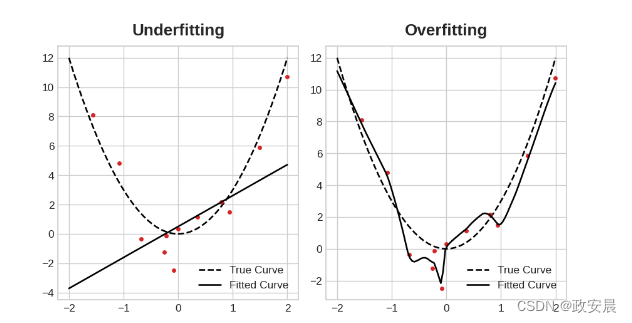
这种权衡表明,在训练模型时可能出现两个问题:信号不足或噪声过多。
欠拟合训练集是指由于模型没有学到足够的信号,导致损失值没有降低到最低。
过拟合训练集是指由于模型学到了过多的噪声,导致损失值没有降低到最低。
训练深度学习模型的关键是找到二者之间的最佳平衡点。
我们将探讨一些方法,既可以在减少噪音的同时提取更多的训练数据信号。
容量
模型的容量是指它能够学习的模式的大小和复杂性。对于神经网络来说,这主要取决于它拥有多少个神经元以及它们是如何相连的。如果你的网络似乎无法适应数据,你应该尝试增加它的容量。
您可以通过使网络更宽(增加现有层的单元数)或使网络更深(添加更多层)来增加网络的容量。更宽的网络更容易学习更多线性关系,而更深的网络更喜欢更多非线性关系。哪种方法更好取决于数据集。
model = keras.Sequential([layers.Dense(16, activation='relu'),layers.Dense(1),
])wider = keras.Sequential([layers.Dense(32, activation='relu'),layers.Dense(1),
])deeper = keras.Sequential([layers.Dense(16, activation='relu'),layers.Dense(16, activation='relu'),layers.Dense(1),
])(您将在本文的练习中探讨网络的容量如何影响其性能。)
早停止
我们提到,当模型过于迫切地学习噪声时,在训练过程中验证损失可能会开始增加。为了防止这种情况,我们可以在看到验证损失不再下降时简单地停止训练。以这种方式中断训练被称为早停止。

(我们保留验证损失最小的模型。)
一旦我们检测到验证损失开始再次上升,我们可以将权重重置回最小值出现的位置。这样可以确保模型不会继续学习噪音并过度拟合数据。
使用提前停止的训练方法意味着我们不太容易在网络学习信号完成之前过早停止训练。因此,除了防止过长训练导致过拟合外,提前停止还可以防止训练时间不足导致的欠拟合。只需将训练轮数设置为一个较大的数值(超过实际需要的轮数),提前停止将处理剩下的部分。
添加早停止
【政安晨】注:
早停止是一种在训练机器学习模型时常用的技术。它的目的是在模型在训练数据上达到最佳性能之前就停止训练,以防止过拟合。
实现早停止的方法有很多种,其中一种常用的方法是通过监控模型在验证集上的性能来决定何时停止训练。通常,我们会定义一个指标,例如验证集上的损失函数或准确率,并设置一个阈值。当模型在连续若干次迭代中都没有达到这个指标时,就可以认为模型已经过拟合,可以停止训练了。
另一种常用的方法是使用早停止的模型来评估测试数据上的性能。如果模型在测试数据上的性能开始下降,那么就可以认为模型已经过拟合,并停止训练。
通过添加早停止技术,可以避免模型在训练数据上过拟合,从而提高模型的泛化能力。注意,早停止并不是一种完全可靠的方法,因为有时模型在训练数据上的性能可能仍然可以提升,但它仍然是一个非常有用的技术,可以帮助我们平衡模型的拟合程度和泛化能力。
在Keras中,我们通过回调函数来包含早停机制。回调函数是在网络训练过程中想要定期运行的函数。早停回调函数将在每个时期后运行。(Keras有许多有用的预定义回调函数,但你也可以自己定义。)
from tensorflow.keras.callbacks import EarlyStoppingearly_stopping = EarlyStopping(min_delta=0.001, # minimium amount of change to count as an improvementpatience=20, # how many epochs to wait before stoppingrestore_best_weights=True,
)这些参数的意思是:“如果在之前的20个迭代中,验证损失没有至少改善0.001,那么停止训练并保留你找到的最佳模型。”
有时候很难判断验证损失是由于过拟合还是由于随机批次变异导致的上升。这些参数允许我们设置一些容忍度来确定何时停止训练。
正如我们将在我们的示例中看到的那样,我们将把这个回调函数与损失函数和优化器一起传递给fit方法。
示例 - 使用提前停止训练模型
【政安晨】注:
在机器学习中,提前停止是一种常用的训练模型的技术。它的原理是在训练过程中监测模型在验证集上的性能,并在性能不再提升时停止训练,以防止过拟合。
以下是一个使用提前停止训练模型的示例:
准备数据集:首先,需要准备一个数据集,其中包含用于训练和验证的样本。可以使用真实数据集或合成数据集。
构建模型:选择一个合适的模型结构,并根据数据集的特点构建一个模型。可以选择各种机器学习算法或深度学习模型。
分割数据集:将数据集分成训练集和验证集。训练集用于训练模型,验证集用于监测模型的性能。
定义停止条件:定义一个停止条件,例如当验证集上的性能在一定的连续迭代中没有提升时停止训练。
训练模型:使用训练集对模型进行训练,并在每次迭代后使用验证集评估模型的性能。
检测性能:在每次迭代后,对模型在验证集上的性能进行检测。如果性能没有提升,则记录当前的迭代次数。
停止训练:如果模型在一定数量的连续迭代中性能没有提升,停止训练。
使用提前停止训练模型的好处是能够避免过拟合,并在模型性能达到最佳时停止训练,节省时间和计算资源。同时,提前停止还可以对模型进行验证,并提供模型的性能指标。
让我们继续开发上篇文章中示例中的模型。
政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(三)—— 随机梯度下降![]() https://blog.csdn.net/snowdenkeke/article/details/136903006我们将增加该网络的容量,同时添加一个提前停止的回调函数,以防止过拟合。
https://blog.csdn.net/snowdenkeke/article/details/136903006我们将增加该网络的容量,同时添加一个提前停止的回调函数,以防止过拟合。
这是数据准备的步骤:
import pandas as pd
from IPython.display import displayred_wine = pd.read_csv('../input/dl-course-data/red-wine.csv')# Create training and validation splits
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)
display(df_train.head(4))# Scale to [0, 1]
max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)
df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)# Split features and target
X_train = df_train.drop('quality', axis=1)
X_valid = df_valid.drop('quality', axis=1)
y_train = df_train['quality']
y_valid = df_valid['quality']
现在让我们增加网络的容量。我们将选择一个相当大的网络,但依靠回调函数在验证损失开始增加时停止训练。
from tensorflow import keras
from tensorflow.keras import layers, callbacksearly_stopping = callbacks.EarlyStopping(min_delta=0.001, # minimium amount of change to count as an improvementpatience=20, # how many epochs to wait before stoppingrestore_best_weights=True,
)model = keras.Sequential([layers.Dense(512, activation='relu', input_shape=[11]),layers.Dense(512, activation='relu'),layers.Dense(512, activation='relu'),layers.Dense(1),
])
model.compile(optimizer='adam',loss='mae',
)在定义好回调函数之后,将其作为参数添加到fit函数中(你可以有多个回调函数,所以将其放入一个列表中)。在使用early stopping时选择一个较大的epoch数量,大于你实际需要的数量。
history = model.fit(X_train, y_train,validation_data=(X_valid, y_valid),batch_size=256,epochs=500,callbacks=[early_stopping], # put your callbacks in a listverbose=0, # turn off training log
)history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();
print("Minimum validation loss: {}".format(history_df['val_loss'].min()))结果如下:Minimum validation loss: 0.09269220381975174

果然,Keras在完整的500个epochs之前就停止了训练!
练习:过拟合与欠拟合
介绍
在这个练习中,您将学习如何通过包含早停止回调来提高训练结果,以防止过拟合。
# Setup plotting
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',titleweight='bold', titlesize=18, titlepad=10)
plt.rc('animation', html='html5')# Setup feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.deep_learning_intro.ex4 import *首先加载Spotify数据集。你的任务是根据各种音频特征(如“节奏”,“舞蹈性”和“模式”)预测一首歌的流行程度。
import pandas as pd
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import make_column_transformer
from sklearn.model_selection import GroupShuffleSplitfrom tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import callbacksspotify = pd.read_csv('../input/dl-course-data/spotify.csv')X = spotify.copy().dropna()
y = X.pop('track_popularity')
artists = X['track_artist']features_num = ['danceability', 'energy', 'key', 'loudness', 'mode','speechiness', 'acousticness', 'instrumentalness','liveness', 'valence', 'tempo', 'duration_ms']
features_cat = ['playlist_genre']preprocessor = make_column_transformer((StandardScaler(), features_num),(OneHotEncoder(), features_cat),
)# We'll do a "grouped" split to keep all of an artist's songs in one
# split or the other. This is to help prevent signal leakage.
def group_split(X, y, group, train_size=0.75):splitter = GroupShuffleSplit(train_size=train_size)train, test = next(splitter.split(X, y, groups=group))return (X.iloc[train], X.iloc[test], y.iloc[train], y.iloc[test])X_train, X_valid, y_train, y_valid = group_split(X, y, artists)X_train = preprocessor.fit_transform(X_train)
X_valid = preprocessor.transform(X_valid)
y_train = y_train / 100 # popularity is on a scale 0-100, so this rescales to 0-1.
y_valid = y_valid / 100input_shape = [X_train.shape[1]]
print("Input shape: {}".format(input_shape))结果看到:
Input shape: [18]
让我们从最简单的网络开始,线性模型。这个模型的容量较低。
运行下面的代码,不做任何更改,训练一个线性模型在 Spotify 数据集上。
model = keras.Sequential([layers.Dense(1, input_shape=input_shape),
])
model.compile(optimizer='adam',loss='mae',
)
history = model.fit(X_train, y_train,validation_data=(X_valid, y_valid),batch_size=512,epochs=50,verbose=0, # suppress output since we'll plot the curves
)
history_df = pd.DataFrame(history.history)
history_df.loc[0:, ['loss', 'val_loss']].plot()
print("Minimum Validation Loss: {:0.4f}".format(history_df['val_loss'].min()));
曲线呈现“曲棍球杆”形状并不罕见,就像您在这里所看到的一样。这使得训练的最后阶段很难看清楚,所以让我们从第10个周期开始:
# Start the plot at epoch 10
history_df.loc[10:, ['loss', 'val_loss']].plot()
print("Minimum Validation Loss: {:0.4f}".format(history_df['val_loss'].min()));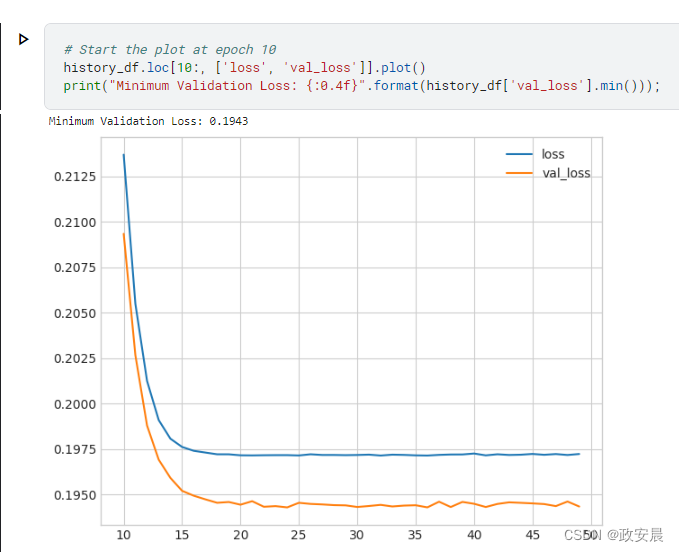
1. 评估基准线
您可以自己判断一下。你会说这个模型是欠拟合、过拟合还是刚刚好?
# View the solution (Run this cell to receive credit!)
q_1.check()现在让我们给我们的网络增加一些能力。我们将添加三个隐藏层,每个隐藏层有128个单元。运行下一个单元格来训练网络并查看学习曲线。
model = keras.Sequential([layers.Dense(128, activation='relu', input_shape=input_shape),layers.Dense(64, activation='relu'),layers.Dense(1)
])
model.compile(optimizer='adam',loss='mae',
)
history = model.fit(X_train, y_train,validation_data=(X_valid, y_valid),batch_size=512,epochs=50,
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot()
print("Minimum Validation Loss: {:0.4f}".format(history_df['val_loss'].min()));2. 添加容量
对于这些曲线,你如何评估?是欠拟合、过拟合还是恰到好处?
# View the solution (Run this cell to receive credit!)
q_2.check()3. 定义早停止回调函数
现在定义一个早停回调函数,它等待5个epoch(patience)以至少0.001的验证损失变化(min_delta),并保留具有最佳损失的权重(restore_best_weights)。
from tensorflow.keras import callbacks# YOUR CODE HERE: define an early stopping callback
early_stopping = ____# Check your answer
q_3.check()# Lines below will give you a hint or solution code
#q_3.hint()
#q_3.solution()现在运行这个单元格以训练模型并获得学习曲线。注意模型.fit中的callbacks参数。
model = keras.Sequential([layers.Dense(128, activation='relu', input_shape=input_shape),layers.Dense(64, activation='relu'), layers.Dense(1)
])
model.compile(optimizer='adam',loss='mae',
)
history = model.fit(X_train, y_train,validation_data=(X_valid, y_valid),batch_size=512,epochs=50,callbacks=[early_stopping]
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot()
print("Minimum Validation Loss: {:0.4f}".format(history_df['val_loss'].min()));4. 训练和解释
与没有早停训练相比,这是一个改进吗?(呵呵)
# View the solution (Run this cell to receive credit!)
q_4.check()如果喜欢的话,可以尝试使用耐心和min_delta进行实验,看看可能会有什么不同。
相关文章:
政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(四)—— 过拟合和欠拟合
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: Tensorflow与Keras实战演绎 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 通过增加容量或提前停止来提高性能。 在深度学习中&…...
RuoYi-Vue若依框架-代码生成器的使用
代码生成器 导入表 在系统工具内找到代码生成,点击导入,会显示数据库内未被导入的数据库表单,选择自己需要生成代码的表,友情提醒,第一次使用最好先导入一张表进行试水~ 预览 操作成功后可以点击预览查看效果&…...

AI PPT生成工具 V1.0.0
AI PPT是一款高效快速的PPT生成工具,能够一键生成符合相关主题的PPT文件,大大提高工作效率。生成的PPT内容专业、细致、实用。 软件特点 免费无广告,简单易用,快速高效,提高工作效率 一键生成相关主题的标题、大纲、…...

进程和线程,线程实现的几种基本方法
什么是进程? 我们这里学习进程是为了后面的线程做铺垫的。 一个程序运行起来,在操作系统中,就会出现对应的进程。简单的来说,一个进程就是跑起来的应用程序。 在电脑上我们可以通过任务管理器可以看到,跑起来的应用程…...
返回False的问题)
【PyTorch】解决PyTorch安装中torch.cuda.is_available()返回False的问题
最近在安装PyTorch时遇到torch.cuda.is_available() False的问题,特此记录下解决方法,以帮助其他遇到相同问题的人。 问题描述 Ubuntu 20.04,3060 Laptop,安装了CUDA 11.4,在Anaconda下新建了Python 3.8的环境&…...
95% 的公司面临 API 安全问题
API 对企业安全发挥着关键作用,但绝大多数企业都为此遭受日益严重的安全风险。据安全公司 Fastly最近做的一项调查显示,84% 的受访企业缺乏足够的API安全措施,95%的企业在过去1年中遇到过 API 安全问题。 此外,79%的受访企业出于A…...

mysql的基本知识点-排序和分组
分组(GROUP BY) GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。例如,假设你有一个包含销售数据的表,并且你想按产品类别计算总销售额。你可以使用 GROUP BY 和 SUM() 函数来实现这一点。 SELECT…...
使用uniapp 的 plus.sqlite 操作本地数据库报错:::table xxx has no column named xxxx
背景: 1、使用uniapp 的 plus.sqlite 进行APP本地数据库操作 2、SQLite 模块用于操作本地数据库文件,可实现数据库文件的创建,执行SQL语句等功能。 遇到:在之前创建的表上进行新增字段的操作时候,出现问题:…...
)
第十五届蓝桥杯模拟赛 第三期 (C++)
第二次做蓝桥模拟赛的博客记录,可能有很多不足的地方,如果大佬有更好的思路或者本文中出现错误,欢迎分享思路或者提出意见 题目A 请问 2023 有多少个约数?即有多少个正整数,使得 2023 是这个正整数的整数倍。 答案&…...
Linux中的常用基础操作
ls 列出当前目录下的子目录和文件 ls -a 列出当前目录下的所有内容(包括以.开头的隐藏文件) ls [目录名] 列出指定目录下的子目录和文件 ls -l 或 ll 以列表的形式列出当前目录下子目录和文件的详细信息 pwd 显示当前所在目录的路径 ctrll 清屏 cd…...
【SpringMVC】知识汇总
SpringMVC 短暂回来,有时间就会更新博客 文章目录 SpringMVC前言一、第一章 SpingMVC概述二、SpringMVC常用注解1. Controller注解2. RequestMapping注解3. ResponseBody注解4. RequestParam5. EnableWebMvc注解介绍6. RequestBody注解介绍7. RequestBody与RequestP…...

android13实现切换导航模式功能
支持android13以上系统,需要系统签名。 public class NavigationHelper {/*** 设置导航模式** param context* param mode GESTURAL:手势 TWOBUTTON:二按钮 THREEBUTTON:三按钮*/public static void setNavigationMode(Contex…...

Pycharm服务器配置python解释器并结合内网穿透实现公网远程开发
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

vue3+vite+Electron构建跨平台应用
1.搭建第一个 electron-vite 项目 electron-vite 是一个新型构建工具,旨在为 Electron 提供更快、更精简的开发体验。它主要由五部分组成: 一套构建指令,它使用 Vite 打包你的代码,并且它能够处理 Electron 的独特环境,包括 Node.js 和浏览器环境。 集中配置主进程、渲染…...
学习次模函数-第1章 引言
许多组合优化问题可以被转换为集合函数的最小化,集合函数是在给定基集合的子集的集合上定义的函数。同样地,它们可以被定义为超立方体的顶点上的函数,即,其中是基集合的基数-它们通常被称为伪布尔函数[27]。在这些集合函数中&…...

实在数字员工,助力菜鸟智慧物流高效腾飞,领航行业新高度
秉承人人都有一个智能助理的发展愿景,自2023年首个数字员工落地以来,菜鸟数字员工累计运行时长已达10万小时。 在智能物流科技不断飞速迭代的今天,物流行业作为社会经济运行的重要支柱和电子商务生态链的关键环节,面临着前所未…...

【from PIL import Image】PIL库和Image的功能及用法
from PIL import Image代码 from PIL import Image 是 Python 中导入 PIL 库中的 Image 模块。PIL 是 Python Imaging Library 的缩写,它是 Python 中用于图像处理的一个强大的库。而 Image 模块则是 PIL 库中的一个子模块,提供了处理图像的各种功能。 …...
【python从入门到精通】--第一战:安装python
🌈 个人主页:白子寰 🔥 分类专栏:python从入门到精通,魔法指针,进阶C,C语言,C语言题集,C语言实现游戏👈 希望得到您的订阅和支持~ 💡 坚持创作博文…...

MySQL的利用分区功能将数据存储到不同的磁盘
MySQL支持将不同的分区存储在不同的磁盘或目录上,这可以进一步优化I/O性能和存储利用率。具体的操作步骤如下: 首先需要确保MySQL的数据目录配置允许在不同目录存储数据文件。在MySQL配置文件(my.cnf或my.ini)中添加以下配置项: [mysqld] innodb_file_per_table1 这个配置项…...

KDB+Q | D1 | 学习资源 基础数据类型
官网会是主要的学习资源:https://code.kx.com/q/ 中文教程可能读起来会快一点: https://kdbcn.gitee.io/ 参考了还不错的学习经验帖:https://www.jianshu.com/p/488764d42627 KDB擅长处理时序数据, KDB数据库是后端数据库&…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

如何用HsMod解锁炉石传说60+项隐藏功能:终极优化指南
如何用HsMod解锁炉石传说60项隐藏功能:终极优化指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx开发的炉石传说功能增强插件,为玩家提供…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...

超低功耗电池电压监控电路设计:从LM324到LPV324的硬件方案优化
1. 项目概述与核心需求解析在捣鼓各种电池供电的电子设备时,无论是自己做的无线传感器节点、便携式小工具,还是给孩子改装的玩具,有一个问题总是绕不开:你怎么知道电池快没电了?总不能每次都等到设备彻底罢工ÿ…...

学了几天 Web 安全,终于搞懂什么是 XSS 了
xss的详细介绍最近开始正式学习 Web 安全。前面陆续学了:HTTPCookieSessionJWT RBAC然后发现很多地方都会提到一个东西:XSS以前一直感觉这个漏洞很抽象。网上很多文章一上来就是:<script>alert(1)</script>然后说:“弹…...

避坑指南:Unity动态加载模型时,TriLib插件材质丢失、缩放异常的5个常见问题解决
Unity动态加载模型避坑指南:TriLib插件材质丢失与缩放异常的深度解决方案当你在Unity项目中尝试使用TriLib插件动态加载外部模型时,是否遇到过这些令人抓狂的情况:模型加载后材质全部变成刺眼的粉红色,贴图神秘消失,或…...

鸿蒙HarmonyOS 5与Unity跨运行时通信实战指南
1. 这不是“调个API”那么简单:为什么鸿蒙Unity通信总在临门一脚卡住我第一次把Unity打包的AR模块塞进HarmonyOS 5 App里时,信心满满——毕竟文档里写着“支持JS/ArkTS调用Native能力”,Unity也标榜“跨平台通用”。结果呢?App一启…...

茉莉花插件:如何让中文文献管理效率提升300%
茉莉花插件:如何让中文文献管理效率提升300% 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为中文文献的元数据抓…...