LangChain核心模块 Retrieval——文档加载器
Retrieval
许多LLM申请需要用户的特定数据,这些数据不属于模型训练集的一部分,实现这一目标的主要方法是RAG(检索增强生成),在这个过程中,将检索外部数据,然后在执行生成步骤时将其传递给LLM。
LangChain 提供了 RAG 应用程序的所有构建模块 - 从简单到复杂。文档的这一部分涵盖了与检索步骤相关的所有内容 - 例如数据的获取。这包含了几个关键模块:

Documents loaders
- 文档加载器
文档加载器提供了一种“load”方法,用于从配置的源将数据加载为文档。还可以选择实现”lazy load“,以便将数据延迟加载到内存中。
最简单的加载程序将文件作为文本读入,并将其全部放入一个文档中。
from langchain_community.document_loaders import TextLoaderloader = TextLoader("./index.md")
loader.load()
-
CSV
-
comma-separated values(CSV)文件是使用逗号分隔值的分隔文本文件,文件的每一行都是一条数据记录,每条记录由一个或多个字段组成,以逗号分隔。
-
加载每个文档一行的 CSV 数据
from langchain_community.document_loaders.csv_loader import CSVLoaderloader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv') data = loader.load() -
Customizing the CSV parsing and loading(自定义 CSV 解析和加载)
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={'delimiter': ',','quotechar': '"','fieldnames': ['MLB Team', 'Payroll in millions', 'Wins'] })data = loader.load() -
指定一列来标识文档来源
使用
source_column参数指定从每行创建的文档的源,否则file_path将用作从 CSV 文件创建的所有文档的源。如果使用从CSV文件加载的文档用于使用源回答问题的链时,很有用。
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', source_column="Team")data = loader.load()
-
-
File Directory
- 如何加载目录中的所有文档
在底层,默认情况下使用UnstructedLoader
from langchain_community.document_loaders import DirectoryLoader可以使用
glob参数来控制加载哪些文件,这里它不会加载.rst、.html文件loader = DirectoryLoader('../', glob="**/*.md") docs = loader.load()-
Show a progress bar(显示进度条)
要显示进度条,请安装
tqdm库(例如pip install tqdm),并将show_progress参数设置为 True。loader = DirectoryLoader('../', glob="**/*.md", show_progress=True) docs = loader.load() -
Use multithreading(使用多线程)
默认情况下,加载发生在一个线程。要使用多个线程,将
use_multithreading标志设置为 true。loader = DirectoryLoader('../', glob="**/*.md", use_multithreading=True) docs = loader.load() -
Change loader class(更改加载类)
默认情况下,这使用
UnstructedLoader类。from langchain_community.document_loaders import TextLoaderloader = DirectoryLoader('../', glob="**/*.md", loader_cls=TextLoader) docs = loader.load()如果需要加载Python源代码文件,使用
PythonLoader。from langchain_community.document_loaders import PythonLoaderloader = DirectoryLoader('../../../../../', glob="**/*.py", loader_cls=PythonLoader) docs = loader.load() -
Auto-detect file encodings with TextLoader(使用 TextLoader 自动检测文件编码)
-
Default Behavior
loader.load()loading()函数失败,会显示一条信息显示哪个文件解码失败在
TextLoader的默认行为下,任何文档加载失败都会导致整个加载过程失败,并且不会再加载任何文档。 -
Silent fail
可以将参数silent_errors传递给
DirectoryLoader来跳过无法加载的文件并继续加载过程。loader = DirectoryLoader(path, glob="**/*.txt", loader_cls=TextLoader, silent_errors=True) docs = loader.load()doc_sources = [doc.metadata['source'] for doc in docs] doc_sources -
Auto detect encodings
还可以通过将
autodetect_encoding传递给加载器类,要求TextLoader在失败之前自动检测文件编码。text_loader_kwargs={'autodetect_encoding': True} loader = DirectoryLoader(path, glob="**/*.txt", loader_cls=TextLoader, loader_kwargs=text_loader_kwargs) docs = loader.load()doc_sources = [doc.metadata['source'] for doc in docs] doc_sources
-
-
HTML
from langchain_community.document_loaders import UnstructuredHTMLLoaderloader = UnstructuredHTMLLoader("example_data/fake-content.html") data = loader.load()-
使用 BeautifulSoup4 加载 HTML
将HTML中的文本提取到
page_content中,并将页面标题作为title提取到metadata中from langchain_community.document_loaders import BSHTMLLoaderloader = BSHTMLLoader("example_data/fake-content.html") data = loader.load()
-
-
JSON
JSON(JavaScript Object Notation)是一种开放标准文件格式和数据交换格式,它使用人类可读的文本来存储和传输由属性值对和数组组成的数据对象。
JSON Lines是一种文件格式,其中每一行都是有效的JSON值。
JSONLoader使用指定的jq架构来解析 JSON 文件。pip install jqfrom langchain_community.document_loaders import JSONLoaderimport json from pathlib import Path from pprint import pprintfile_path='./example_data/facebook_chat.json' data = json.loads(Path(file_path).read_text())-
使用
JSONLoader如果想要提取JSON数据的messages键中的内容字段下的值
-
JSON file
loader = JSONLoader(file_path='./example_data/facebook_chat.json',jq_schema='.messages[].content',text_content=False)data = loader.load() -
JSON Lines file
如果要从 JSON Lines 文件加载文档,请传递
json_lines=True并指定jq_schema以从单个 JSON 对象中提取 page_content。loader = JSONLoader(file_path='./example_data/facebook_chat_messages.jsonl',jq_schema='.content',text_content=False,json_lines=True)data = loader.load()-
另一个选项是设置
jq_schema='.'并提供content_key:loader = JSONLoader(file_path='./example_data/facebook_chat_messages.jsonl',jq_schema='.',content_key='sender_name',json_lines=True)data = loader.load()
-
-
JSON file with jq schema
content_key(带有jq架构content_key的 JSON 文件)要使用
jq架构中的content_key从 JSON 文件加载文档,要设置is_content_key_jq_parsable=True,确保content_key兼容并且可以使用jq模式进行解析。loader = JSONLoader(file_path=file_path,jq_schema=".data[]",content_key=".attributes.message",is_content_key_jq_parsable=True, )data = loader.load()
-
-
提取元数据(Extracting metadata)
前面示例中,并没有收集元数据,我们设法直接在架构中指定可以从中提取
page_content值的位置。.messages[].content在当前示例中,我们必须告诉加载器迭代消息字段中的记录。
jq_schema必须是:.messages[]这允许我们将记录(dict)传递到必须实现的
metadata_func中。metadata_func负责识别记录中的哪些信息应包含在最终 Document 对象中存储的元数据中。此外,还要在加载器中通过
content_key参数显式指定需要从中提取page_content值的记录中的键。# Define the metadata extraction function. def metadata_func(record: dict, metadata: dict) -> dict:metadata["sender_name"] = record.get("sender_name")metadata["timestamp_ms"] = record.get("timestamp_ms")return metadataloader = JSONLoader(file_path='./example_data/facebook_chat.json',jq_schema='.messages[]',content_key="content",metadata_func=metadata_func )data = loader.load() -
metadata_funcmetadata_func接受JSONLoader生成的默认元数据,这允许用户完全控制元数据的格式。例如,默认元数据包含
source和seq_num键。但是,JSON 数据也可能包含这些键。然后,用户可以利用metadata_func重命名默认键并使用JSON 数据中的键。下面的示例展示了如何修改源以仅包含相对于 langchain 目录的文件源信息:
# Define the metadata extraction function. def metadata_func(record: dict, metadata: dict) -> dict:metadata["sender_name"] = record.get("sender_name")metadata["timestamp_ms"] = record.get("timestamp_ms")if "source" in metadata:source = metadata["source"].split("/")source = source[source.index("langchain"):]metadata["source"] = "/".join(source)return metadataloader = JSONLoader(file_path='./example_data/facebook_chat.json',jq_schema='.messages[]',content_key="content",metadata_func=metadata_func )data = loader.load() -
具有
jq模式的常见 JSON 结构下面的列表提供了对可能的
jq_schema的引用,用户可以使用它根据结构从 JSON 数据中提取内容。JSON -> [{"text": ...}, {"text": ...}, {"text": ...}] jq_schema -> ".[].text"JSON -> {"key": [{"text": ...}, {"text": ...}, {"text": ...}]} jq_schema -> ".key[].text"JSON -> ["...", "...", "..."] jq_schema -> ".[]"
-
-
Markdown
from langchain_community.document_loaders import UnstructuredMarkdownLoadermarkdown_path = "../../../../../README.md" loader = UnstructuredMarkdownLoader(markdown_path) data = loader.load()-
Retain Elements
在底层,非结构化为不同的文本块创建不同的“元素”。默认情况下,我们将它们组合在一起,但可以通过指定 mode=“elements” 轻松保持这种分离。
loader = UnstructuredMarkdownLoader(markdown_path, mode="elements") data = loader.load()
-
-
PDF
-
PyPDF
使用 pypdf 将 PDF 加载到文档数组中,其中每个文档包含页面内容和带有页码的元数据。
pip install pypdffrom langchain_community.document_loaders import PyPDFLoaderloader = PyPDFLoader("example_data/layout-parser-paper.pdf") pages = loader.load_and_split()这种方法的优点是可以使用页码检索文档。
from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddingsfaiss_index = FAISS.from_documents(pages, OpenAIEmbeddings()) docs = faiss_index.similarity_search("How will the community be engaged?", k=2) for doc in docs:print(str(doc.metadata["page"]) + ":", doc.page_content[:300])-
提取图像(Extracting images)
使用
rapidocr-onnxruntime包可以将图像提取为文本:pip install rapidocr-onnxruntimeloader = PyPDFLoader("https://arxiv.org/pdf/2103.15348.pdf", extract_images=True) pages = loader.load() pages[4].page_content
-
-
MathPix
from langchain_community.document_loaders import MathpixPDFLoader loader = MathpixPDFLoader("example_data/layout-parser-paper.pdf") -
Unstructured
from langchain_community.document_loaders import UnstructuredPDFLoader loader = UnstructuredPDFLoader("example_data/layout-parser-paper.pdf")-
Retain Elements
loader = UnstructuredPDFLoader("example_data/layout-parser-paper.pdf", mode="elements") -
使用非结构化获取远程 PDF
将在线 PDF 加载为我们可以在下游使用的文档格式
其他 PDF 加载器也可用于获取远程 PDF,但
OnlinePDFLoader是一个遗留函数,专门与UnstructedPDFLoader配合使用。from langchain_community.document_loaders import OnlinePDFLoader loader = OnlinePDFLoader("https://arxiv.org/pdf/2302.03803.pdf")
-
-
PyPDFium2
from langchain_community.document_loaders import PyPDFium2Loader loader = PyPDFium2Loader("example_data/layout-parser-paper.pdf") -
PDFMiner
from langchain_community.document_loaders import PDFMinerLoader loader = PDFMinerLoader("example_data/layout-parser-paper.pdf")-
使用 PDFMiner 生成 HTML 文本
这有助于将文本在语义上分块为多个部分,因为输出的 html 内容可以通过 BeautifulSoup 进行解析,以获得有关字体大小、页码、PDF 页眉/页脚等的更结构化和丰富的信息。
-
-
PyMuPDF
最快的 PDF 解析选项,包含有关 PDF 及其页面的详细元数据,并且每页返回一个文档。
from langchain_community.document_loaders import PyMuPDFLoader loader = PyMuPDFLoader("example_data/layout-parser-paper.pdf")此外,您可以在加载调用中将 PyMuPDF 文档中的任何选项作为关键字参数传递,并将其传递给 get_text() 调用。
-
PyPDF Directory
从目录加载 PDF
from langchain_community.document_loaders import PyPDFDirectoryLoaderloader = PyPDFDirectoryLoader("example_data/") -
PDFPlumber
与 PyMuPDF 一样,输出文档包含有关 PDF 及其页面的详细元数据,并每页返回一个文档。
from langchain_community.document_loaders import PDFPlumberLoader loader = PDFPlumberLoader("example_data/layout-parser-paper.pdf") -
AmazonTextractPDFParser
AmazonTextractPDFLoader调用Amazon Textract Service将 PDF 转换为文档结构。该加载程序目前执行纯 OCR,并根据需求计划提供更多功能,例如布局支持。支持最多 3000 页和 512 MB 大小的单页和多页文档。
-
相关文章:
LangChain核心模块 Retrieval——文档加载器
Retrieval 许多LLM申请需要用户的特定数据,这些数据不属于模型训练集的一部分,实现这一目标的主要方法是RAG(检索增强生成),在这个过程中,将检索外部数据,然后在执行生成步骤时将其传递给LLM。 LangChain 提供…...

力扣爆刷第104天之CodeTop100五连刷6-10
力扣爆刷第104天之CodeTop100五连刷6-10 文章目录 力扣爆刷第104天之CodeTop100五连刷6-10一、15. 三数之和二、53. 最大子数组和三、912. 排序数组四、21. 合并两个有序链表五、1. 两数之和 一、15. 三数之和 题目链接:https://leetcode.cn/problems/3sum/descrip…...

Docker操作基础命令
注意:以下命令在特权模式下进行会更有效! 进入特权模式 sudo -ssudo su拉取镜像 sudo docker pull [镜像名] # sudo docker pull baiduxlab/sgx-rust:2004-1.1.3进入容器 端口开启服务: sudo docker start 3df9bf5dbd0c进入容器…...

穿越地心:3D可视化技术带你领略地球内部奇观
在广袤无垠的宇宙中,地球是一颗充满生机与奥秘的蓝色星球。我们每天都生活在这颗星球上,感受着它的温暖与恩赐,却往往忽略了它深邃的内部世界。 想象一下,你能够穿越时空,深入地球的核心,亲眼目睹那些亿万年…...

蓝桥杯刷题_day1_回文数_水仙花数_进制转换
文章目录 特殊的回文数回文数水仙花数十六进制转八进制_n次 特殊的回文数 问题描述 123321是一个非常特殊的数,它从左边读和从右边读是一样的。 输入一个正整数n, 编程求所有这样的五位和六位十进制数,满足各位数字之和等于n 。 解题…...
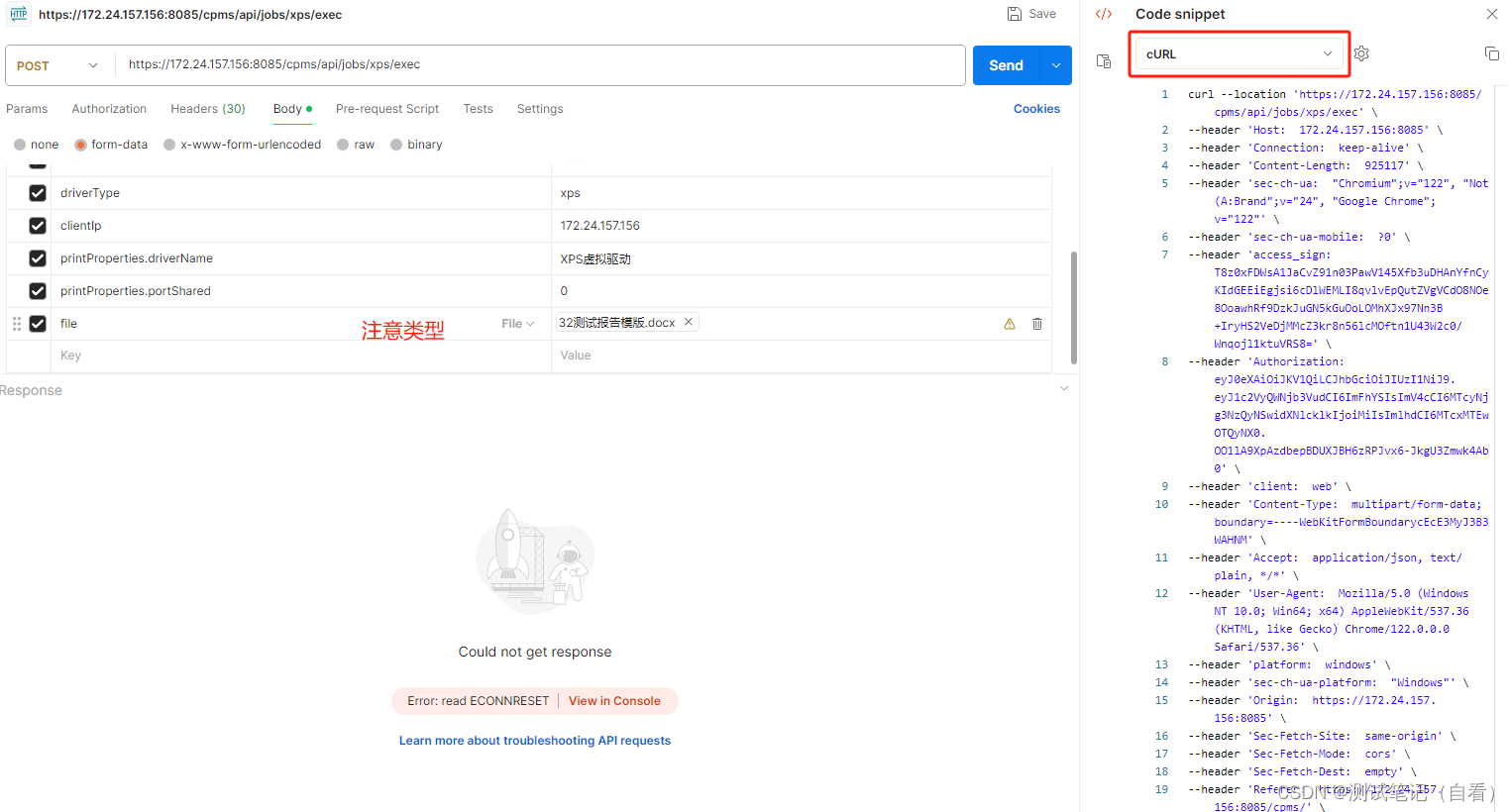
jmeter接口导入方式
curl直接导入 1、操作页面后,F12查看接口,右击接口-copy-copy as cURL 2、jmeter 工具-import from cURL,粘贴上面复制的curl 根据接口文档导入 1、接口文档示例如下: Path: /api/jobs/xps/exec Method…...
)
设计模式(行为型设计模式——状态模式)
设计模式(行为型设计模式——状态模式) 状态模式 基本定义 对有状态的对象,把复杂的“判断逻辑”提取到不同的状态对象中,允许状态对象在其内部状态发生改变时改变其行为。 模式结构 Context(环境类)&…...

【Flutter学习笔记】10.3 组合实例:TurnBox
参考资料:《Flutter实战第二版》 10.3 组合实例:TurnBox 这里尝试实现一个更为复杂的例子,其能够旋转子组件。Flutter中的RotatedBox可以旋转子组件,但是它有两个缺点: 一是只能将其子节点以90度的倍数旋转二是当旋转…...

性能测试入门 —— 什么是性能测试PTS?
性能测试PTS(Performance Testing Service)是一款简单易用,具备强大的分布式压测能力的SaaS压测平台。 PTS可以模拟复杂的业务场景,并快速精准地调度不同规模的流量,同时提供压测过程中多维度的监控指标和日志记录。您…...
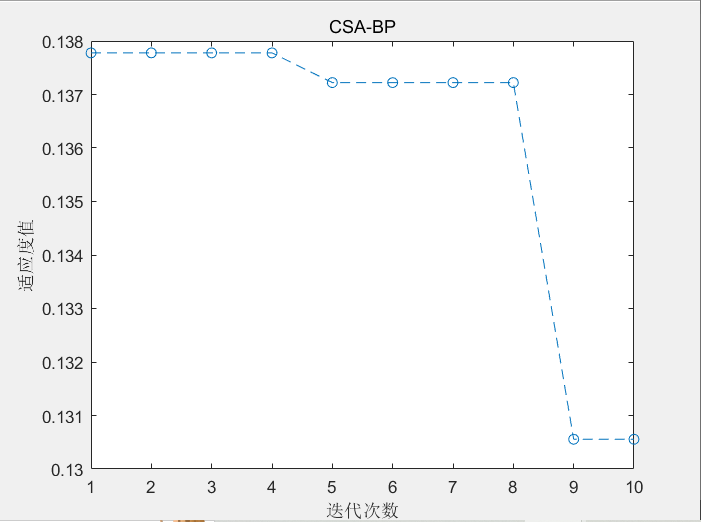
【机器学习】基于变色龙算法优化的BP神经网络分类预测(SSA-BP)
目录 1.原理与思路2.设计与实现3.结果预测4.代码获取 1.原理与思路 【智能算法应用】智能算法优化BP神经网络思路【智能算法】变色龙优化算法(CSA)原理及实现 2.设计与实现 数据集: 数据集样本总数2000 多输入多输出:样本特征24ÿ…...

pytorch中tensor类型转换的几个函数
目录 IntTensor转FloatTensor FloatTensor转IntTensor Tensor类型变为python的常规类型 IntTensor转FloatTensor .float函数: FloatTensor转IntTensor .int函数 Tensor类型变为python的常规类型 item函数...

深入理解Elasticsearch高效原理
在当今数据驱动的世界中,能够快速有效地存储、搜索和分析庞大数据集变得至关重要。Elasticsearch是一个强大的开源搜索和分析引擎,专为云计算中心而设计,能够提供快速的搜索功能,并且能够扩展到包含数百个服务器的集群,…...

http和socks5代理哪个隐蔽性更强?
HTTP代理和SOCKS5代理各有其优缺点,但就隐蔽性而言,SOCKS5代理通常比HTTP代理更隐蔽。以下是它们的比较: HTTP代理: 透明性较高:HTTP代理在HTTP头中会透露原始客户端的IP地址,这使得它相对不太隐蔽。…...

邮箱的正则表达式
一、 背景 项目中要给用户发送邮件,这时候需要校验用户输入的邮箱的有有效性,这肯定用正则呀。 虽然没有统一的邮箱账号格式,但是所有邮箱都符合“名称域名”的规律。对于名称和域名的字符限制,我们可以根据项目的情况定义一个&a…...

blender插件笔记
目录 文件拖拽导入 smpl导入导出 好像可以导入动画 smpl_blender_addon导入一帧 保存pose 导入导出完整代码 文件拖拽导入 https://github.com/mika-f/blender-drag-and-drop 支持格式: *.abc*.bvh*.dae*.fbx*.glb*.gltf*.obj*.ply*.stl*.svg*.usd*.usda*.…...

解释关系型数据库和非关系型数据库的区别
一、解释关系型数据库和非关系型数据库的区别 关系型数据库和非关系型数据库在多个方面存在显著的区别。 首先,从数据存储方式来看,关系型数据库采用表格形式,数据存储在数据表的行和列中,且数据表之间可以关联存储,…...

YAML-02-yml 配置文件 java 整合使用 yamlbeans + snakeyaml + jackson-dataformat-yaml
java 中处理 yml 的开源组件是什么? 在Java中处理YAML(YAML Aint Markup Language)格式的开源组件有很多,其中一些比较常用的包括: SnakeYAML: SnakeYAML 是一个Java库,用于解析和生成YAML格式…...
【综述+LLMs】国内团队大语言模型综述:A Survey of Large Language Models (截止2023.11.24)
Github主页: https://github.com/RUCAIBox/LLMSurvey 中文版v10:https://github.com/RUCAIBox/LLMSurvey/blob/main/assets/LLM_Survey_Chinese.pdf 英文版v13: https://arxiv.org/abs/2303.18223 解析:大语言模型LLM入门看完你就懂了(一&…...
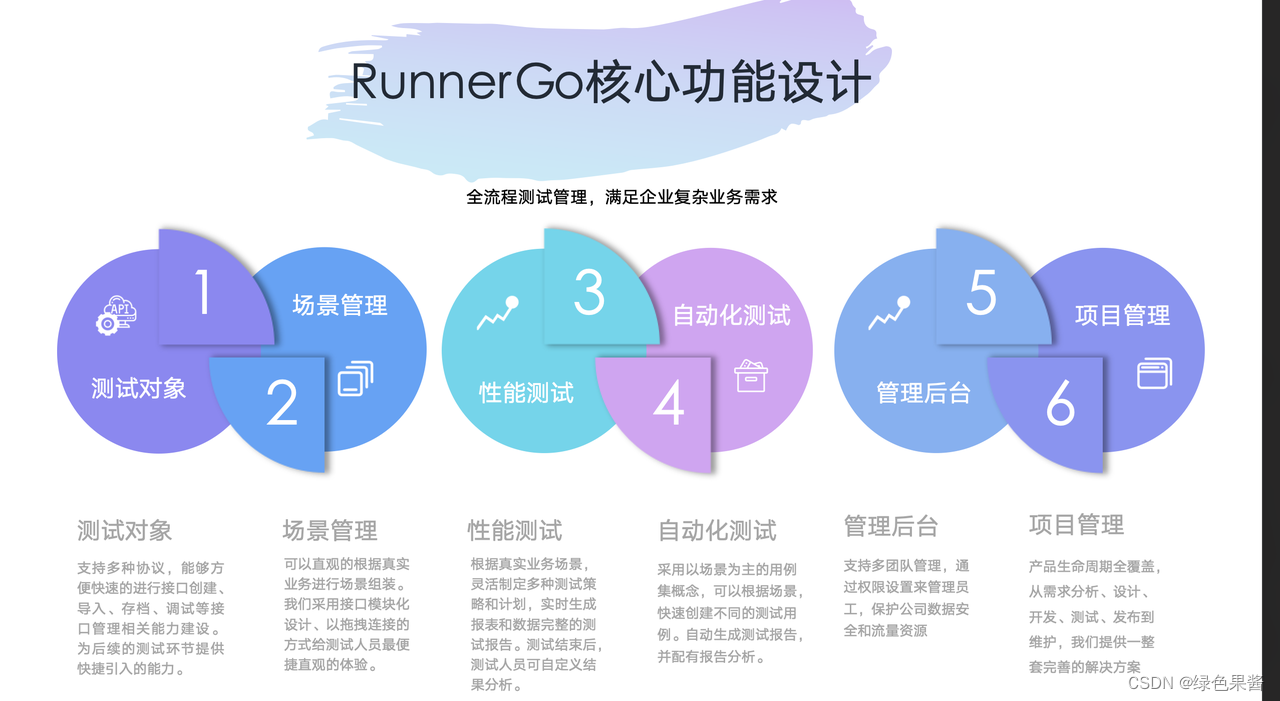
开始喜欢上了runnergo,JMeter out了?
RunnerGo是一款基于Go语言、国产自研的测试平台。它支持高并发、分布式性能测试。和JMeter不一样的是,它采用了B/S架构,更灵活、更方便。而且,除了API测试和性能测试,RunnerGo还加上了UI测试和项目管理等实用功能,让测…...
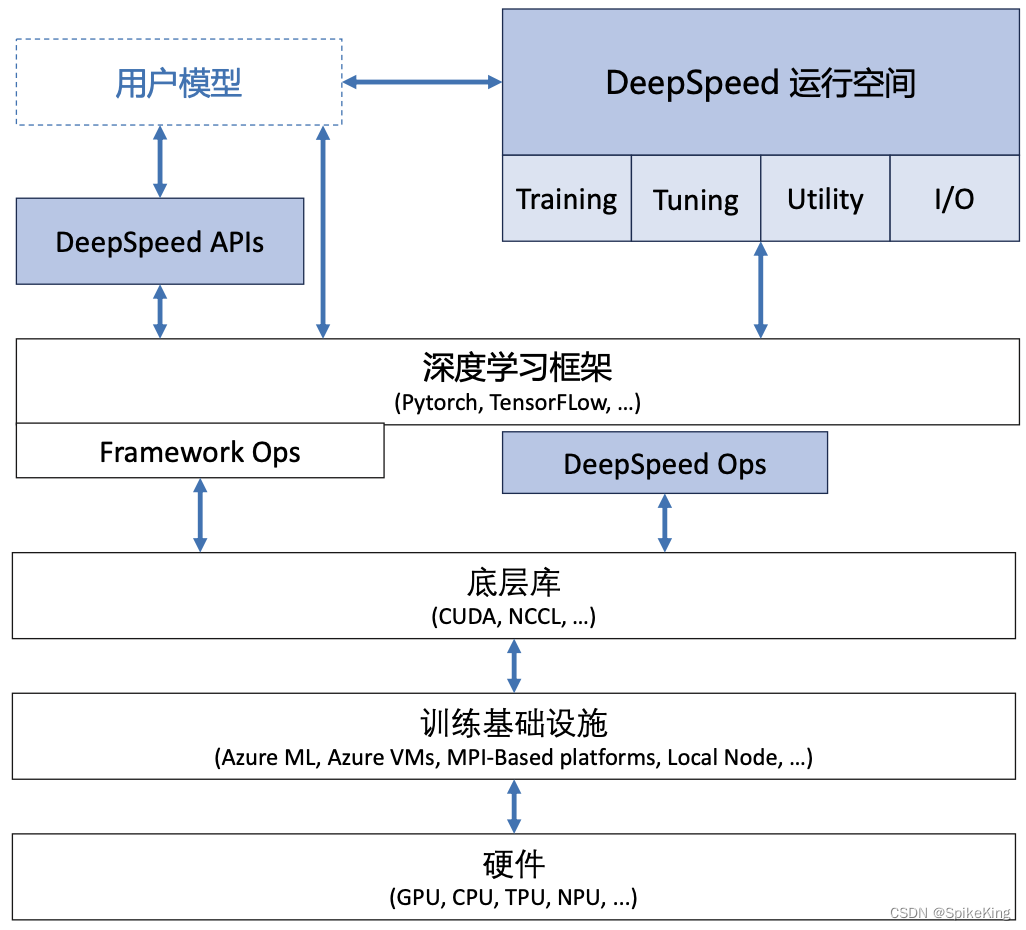
LLM - 大语言模型的分布式训练 概述
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/136924304 大语言模型的分布式训练是一个复杂的过程,涉及到将大规模的计算任务分散到多个计算节点上。这样做的目的是为了处…...

3分钟上手:NBTExplorer终极指南 - 可视化编辑Minecraft游戏数据的免费神器
3分钟上手:NBTExplorer终极指南 - 可视化编辑Minecraft游戏数据的免费神器 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经想要修改Minecraf…...

CA-CFAR、GO-CFAR、SO-CFAR怎么选?一张图看懂三种恒虚警检测算法的适用场景与避坑指南
CA-CFAR、GO-CFAR、SO-CFAR工程选型指南:从算法原理到场景适配 雷达信号处理工程师常常面临一个经典难题:在复杂环境中如何选择合适的恒虚警检测算法?当海面杂波、多目标干扰或低信噪比条件同时出现时,CA、GO、SO三种CFAR变体的性…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...

终极虚拟显示器解决方案:ParsecVDisplay完整使用指南
终极虚拟显示器解决方案:ParsecVDisplay完整使用指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一个基于Parsec虚拟显示驱动(VDD)的独立应用程序…...

具身智能的发展对人类社会的影响有哪些?
具身智能对人类社会影响一、经济产业层面产业重构:催生机器人、智能制造、自动驾驶新产业,重塑生产链条效率跃升:替代重复繁重劳作,工厂、农业、物流产能大幅提升就业结构变化:低端体力岗位缩减,运维、研发…...

告别硬编码!在UE5 GAS中实现动态技能键位绑定:从DataAsset配置到运行时热更新的完整流程
告别硬编码!在UE5 GAS中实现动态技能键位绑定:从DataAsset配置到运行时热更新的完整流程在当代RPG游戏开发中,技能系统的灵活性和可配置性往往决定了项目的迭代效率。传统硬编码的键位绑定方式不仅增加了程序与策划的沟通成本,更在…...
)
DeepSeek注释质量跃迁路径(附12个真实项目对比数据+可复用Prompt模板)
更多请点击: https://codechina.net 第一章:DeepSeek注释质量跃迁路径(附12个真实项目对比数据可复用Prompt模板) 高质量代码注释不再是“锦上添花”,而是模型理解意图、团队高效协同与长期可维护性的核心基础设施。…...

如何快速上手SoundMind:10分钟完成音频逻辑推理模型训练
如何快速上手SoundMind:10分钟完成音频逻辑推理模型训练 【免费下载链接】SoundMind We introduce the Audio Logical Reasoning (ALR) dataset, consisting of 6,446 text-audio annotated samples specifically designed for complex reasoning tasks. Building o…...

5个高效技巧:重新定义你的Chrome书签管理体验
5个高效技巧:重新定义你的Chrome书签管理体验 【免费下载链接】neat-bookmarks A neat bookmarks tree popup extension for Chrome [DISCONTINUED] 项目地址: https://gitcode.com/gh_mirrors/ne/neat-bookmarks 你是否曾花费数分钟在混乱的书签海洋中寻找那…...

ThriftPy性能测试与基准对比:Cython加速效果分析
ThriftPy性能测试与基准对比:Cython加速效果分析 【免费下载链接】thriftpy Thriftpy has been deprecated, please migrate to https://github.com/Thriftpy/thriftpy2 项目地址: https://gitcode.com/gh_mirrors/th/thriftpy ThriftPy是一款高效的Python T…...