Redis - 高并发场景下的Redis最佳实践_翻过6座大山
文章目录
- 概述
- 6座大山之_缓存雪崩 (缓存全部失效)
- 缓存雪崩的两种常见场景
- 如何应对缓存雪崩?
- 6座大山之_缓存穿透(查询不存在的 key)
- 缓存穿透的原因
- 解决方案
- 1. 数据校验
- 2. 缓存空值
- 3. 频控
- 4. 使用布隆过滤器
- 6座大山之_缓存击穿(热 key 突然失效)
- 解决思路1:永不过期
- 解决思路2:逻辑过期
- 解决思路3:互斥锁
- 6座大山之_缓存打满(内存空间不够)
- Redis的淘汰策略
- 发生场景
- 解决方案
- 6座大山之_Hot Key
- 发现热 Key
- 处理热 Key
- 6座大山之_Big Key
- 问题:
- 可能发生的场景:
- 发现大 Key的方法:
- 删除大 Key的方法:
- 避免产生大 Key的方法:

概述
在高并发系统中,Redis缓存通常被视为数据在存入数据库之前的重要中间层,其设计专注于缓存功能,性能往往比传统数据库高出一个数量级以上。以Redis单实例而言,其读取并发能力可达到10万QPS(官方理论值)。
然而,正因为Redis的高并发处理能力,它在系统链路中扮演着至关重要的角色。一旦系统遭遇高峰期,若我们在Redis处理方面稍有疏忽,可能会导致整个系统瘫痪。
因此,我们接下来将探讨在复杂、高并发的互联网系统中,缓存可能面临的一系列挑战,以及我们可以采取的措施来应对这些挑战。
6座大山之_缓存雪崩 (缓存全部失效)
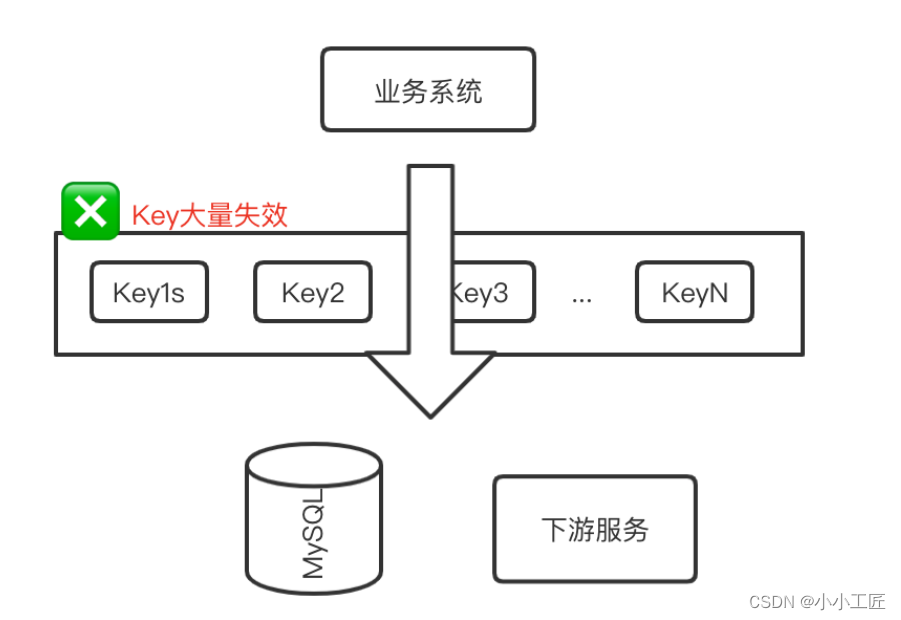
在高并发系统中,缓存(通常是Redis)扮演着重要的角色,它被视为数据库的保护伞,能够有效减轻数据库负载。然而,有时候我们可能会面临一个令人头疼的问题:缓存竟然完全失效了,而流量却突然间涌向了数据库,最终可能导致整个系统的不可用。这种情况被称为缓存雪崩。
缓存雪崩的两种常见场景
-
Redis集群不可用: 即使Redis是以集群模式部署,但当集群中的某个节点不可用时(如重启),如果没有合理的容错机制,可能会导致大量缓存同时失效,从而压垮数据库。
-
大量缓存集中失效: 在缓存预热过程中,如果将大量缓存集中预热或更新,那么这些缓存可能在同一时间突然失效,导致系统出现雪崩效应。
如何应对缓存雪崩?
-
合理部署Redis集群: 将Redis部署为集群模式,确保数据在多个节点上存在,即使某个节点不可用,也不至于导致所有缓存失效。跨机房部署可以进一步提高容灾能力。
-
持久化数据并预热缓存: 在重启Redis等操作前,通过SAVE指令将数据持久化,或者在重启后人工触发缓存预热,确保缓存不会因为重启而全部失效。
-
随机设置过期时间: 对于集中预热的缓存数据,设置过期时间时增加一定的随机性,使得缓存失效时间分散,避免集中失效导致的雪崩效应。


6座大山之_缓存穿透(查询不存在的 key)
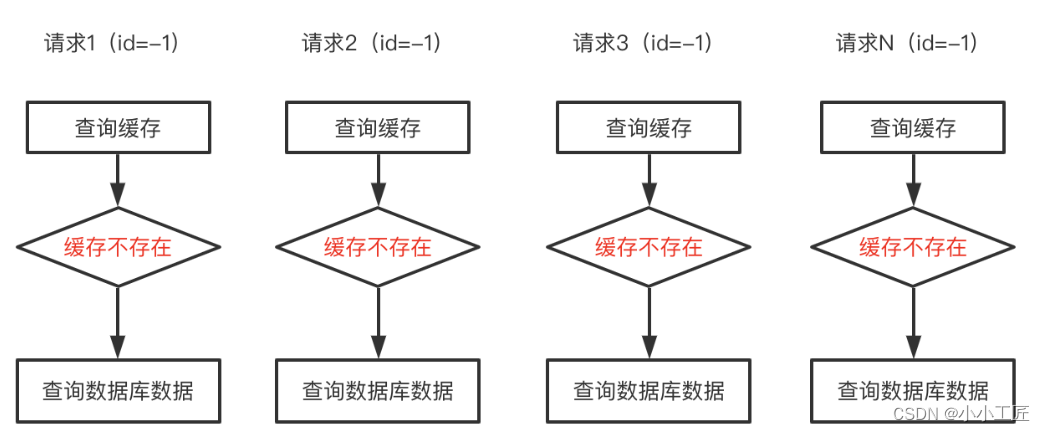
在缓存系统中,缓存穿透是一种常见而又令人头疼的问题。当用户请求查询缓存中不存在的数据时,这些请求会直接穿透缓存打到数据库,可能导致数据库负载过大,甚至引发系统崩溃。特别是在攻击者持续发起此类请求的情况下,这种攻击行为会对系统造成严重影响。
缓存穿透的原因
缓存穿透通常发生在以下情况下:
-
查询不存在的数据: 当用户请求查询缓存中不存在的数据时,如果缓存未命中,请求就会直接打到数据库,导致缓存穿透现象的发生。
-
恶意攻击: 攻击者可能会利用此漏洞,不断发起查询不存在数据的请求,造成数据库压力过大,甚至拖垮整个系统。
解决方案
1. 数据校验
在接入层对请求数据进行严格的校验,例如检查ID是否为正整数、参数范围是否合法等,以过滤掉非法请求,避免其穿透缓存直接访问数据库。
2. 缓存空值
对于查询不到的数据,可以在缓存中存储一个特殊的“null”值,下次请求命中缓存时直接返回。但需注意设置空值缓存的过期时间,避免缓存空间被占满。
3. 频控
针对恶意攻击者,可实施频率限制策略,例如基于IP地址进行频控,及时拒绝异常请求,以保护数据库不受攻击。
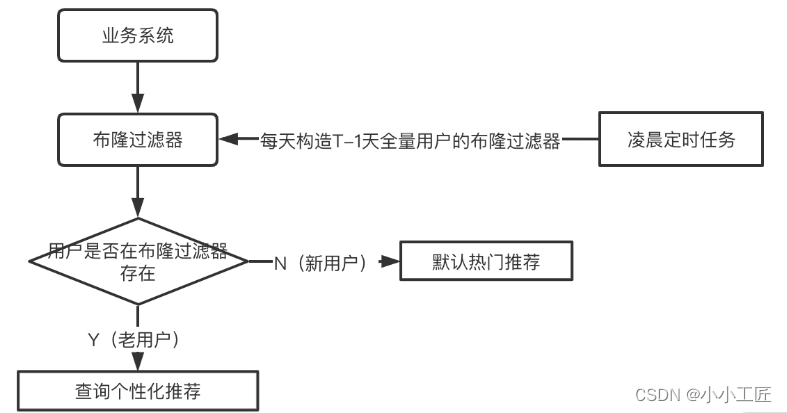
4. 使用布隆过滤器
布隆过滤器是一种高效的数据结构,可用于判断元素是否存在,但有一定的误判率。可以将所有数据存储在布隆过滤器中,查询缓存前先检查布隆过滤器,如果不存在则直接返回,从而避免不必要的缓存/数据库查询。
–
缓存穿透是高并发系统中常见的问题,但通过合理的预防措施和技术手段,我们可以有效地减轻其影响。在设计和开发过程中,应注重数据校验、缓存空值设置、频率限制以及布隆过滤器等措施的应用,以确保系统的稳定和安全运行。
6座大山之_缓存击穿(热 key 突然失效)
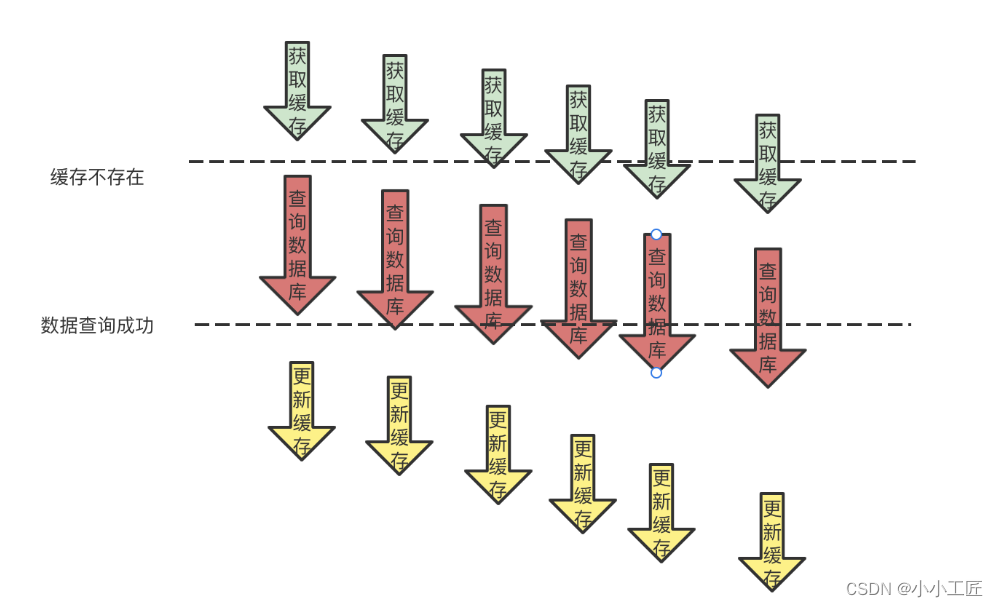
在缓存系统中,缓存击穿是一种常见但十分危险的现象。当一个热门的缓存 key 在失效瞬间,大量请求同时打到数据库,可能会导致数据库压力过大,甚至引发系统崩溃。
为应对这一挑战,我们可以采取以下解决方案:
解决思路1:永不过期
针对某些热门的 key,可以选择不设置过期时间,而是采用定时任务或定时更新的方式,以避免 key 失效的情况。
解决思路2:逻辑过期
对于不适合永不过期的全量 key,可以设置一个逻辑过期时间。即在缓存中存储数据的同时,记录数据的逻辑过期时间,定时任务异步地重新刷新缓存,并重新设置其物理过期时间和逻辑过期时间。
例如 Key1=Value1 这样的缓存,过期时间是 2024.10.01.00:00,那么物理过期时间可能设置在 2024.10.01.01:00,但是我们将 value 这样存储
{v:"Value1",t:1727715600}当读取到这个数据过期的时候,我们让任务异步地去重新刷新这个缓存,并重新设置其物理过期时间和逻辑过期时间,这样击穿到数据库的线程就可控为一条异步线程了。
这里的原则是物理过期时间一定要比逻辑过期时间久
解决思路3:互斥锁
使用互斥锁,在发现缓存不存在时加锁,只允许一条线程去数据库查询真实数据,其他线程等待。通过双重检查机制,确保数据在锁被释放前已被写入缓存,从而避免多次数据库访问。

public String query(String key) {String data = stringRedisTemplate.opsForValue().get(key);if (StringUtils.isEmpty(data)) {RLock locker = redissonClient.getLock("locker_" + key);if (locker.tryLock()) {try {data = stringRedisTemplate.opsForValue().get(key);if (StringUtils.isEmpty(data)) {data = getDataFromDB(key);stringRedisTemplate.opsForValue().set(key, data, 5, TimeUnit.SECONDS);}} finally {locker.unlock();}} else {Thread.sleep(100);return query(key);}}return data;
}
以上是利用 Redisson 实现的分布式锁示例,确保只有一条线程去数据库查询数据,其他线程等待或递归查询缓存,以防止缓存击穿。
之所以使用 1 个分布式锁,这样才能放 1 条线程去数据库访问,但是真实使用的时候并不需要做得这么重,只需要进程级别的加锁即可,因为我们服务的数量通常是有限且不大的,那么有限的并发打到数据库,做一些重复的工作也并不会太影响。

缓存击穿是高并发系统中常见的问题,但通过合理的策略和技术手段,我们可以有效地预防和应对这一挑战。重视缓存设计和管理,结合适当的方案,可以有效地保护数据库并确保系统的稳定运行。
6座大山之_缓存打满(内存空间不够)

在Redis中,内存是有限的,当内存使用达到上限时,需要采取一些策略来淘汰一定不使用的key,以释放空间存储新的key。这个上限由配置的maxmemory参数决定,无论是否开启持久化,都会触发淘汰策略。
maxmemory 100mb
Redis的淘汰策略
-
noeviction(默认): 不删除任意数据,但根据引用计数器进行释放,当内存不足时直接返回错误。
-
volatile-lru: 选择最近最少使用的带过期时间的数据进行淘汰。
-
allkeys-lru: 选择最近最少使用的数据进行淘汰,包括带过期时间和不带过期时间的数据。
-
volatile-lfu: 选择使用频率最低的带过期时间的数据进行淘汰。
-
allkeys-lfu: 选择使用频率最低的数据进行淘汰,包括带过期时间和不带过期时间的数据。
-
volatile-random: 随机选择一个带过期时间的数据进行淘汰。
-
allkeys-random: 随机选择一个数据进行淘汰,包括带过期时间和不带过期时间的数据。
-
volatile-ttl: 选择最接近过期的数据进行释放操作,只从带过期时间的数据集中选择。
发生场景
-
把Redis当存储使用: 部分场景下,将Redis用作数据存储,不设置过期时间,可能导致内存持续增长,触发淘汰策略,不正确的淘汰策略可能导致数据丢失。
-
Bug数据逐步污染缓存: 开发人员忘记设置过期时间,或设置过期时间过长,导致缓存内存被占满。
解决方案
-
存储隔离: 对于永不过期的数据,要与正常的缓存数据做集群的分离,以便设置不同的淘汰策略。
-
容量监控:
- 预估使用容量,给予足够的冗余应对业务发展。
- 实时监控使用量变化,一旦超过阈值,立即扩容并排查原因。
- 监控key的过期时间,定期扫描,发现未设置过期时间或设置不合理的key,并及时修复。
在实际应用中,结合合适的淘汰策略和监控手段,能够更好地管理Redis缓存,保障系统的稳定性和可靠性。
6座大山之_Hot Key
热 Key 是指在Redis中频繁访问的某些特定key,可能导致单个实例的性能问题。即使对Redis进行扩容,也无法完全解决热 Key 问题,因为对于同一个key的访问通常会集中在同一个实例上。
热 Key 问题可能导致接口超时、网络负载过大、连接数达到上限等一系列问题,严重影响系统稳定性和性能。
发现热 Key
-
按业务场景预估热点 key: 根据业务特点预估一些热门key,如促销商品、秒杀商品等。这种方法简单但依赖于人工经验,无法发现意外的热点。
-
客户端收集: 封装代码统计Redis的所有访问命令,对命令进行统计分析。简单方便但需要代码修改。
-
代理层收集: 在访问Redis之前添加访问代理层,代理层收敛请求并进行统计。无代码侵入但架构复杂。
-
Redis监控命令: 使用Redis提供的监控命令,如
hotkeys命令,实时监控热 Key。无代码侵入但对大集群扫描较慢。
# 统计间隔0.1秒输出一次hotkeysredis-cli --hotkeys -i 0.1root@root:~# redis-cli --hotkeys -i 0.1# Scanning the entire keyspace to find hot keys as well as# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec# per 100 SCAN commands (not usually needed).[00.00%] Hot key 'aaa' found so far with counter 1-------- summary -------Sampled 4 keys in the keyspace!hot key found with counter: 1 keyname: aaa- 网络抓包分析: 抓取Redis服务器侧的包进行分析,发现流量倾斜和热 Key。无代码侵入但可能恶化现有问题。
处理热 Key
-
本地缓存: 在访问Redis之前加一层本地缓存,将部分热 Key 存储在本地。需要合理设计淘汰策略和热 Key 发现机制。
-
本机Redis备机: 将Redis备机部署在本地,充当本地缓存的角色。需要考虑一致性和维护成本。
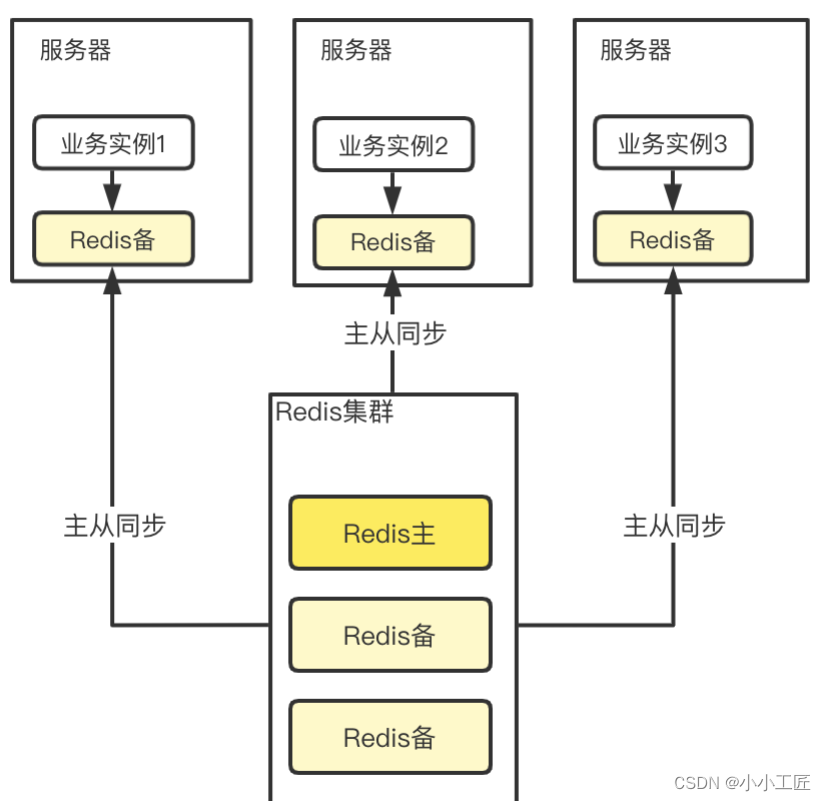
-
备份存储: 将热 Key 备份成多份,分布在不同实例上,分散流量。需要设计合适的备份策略。
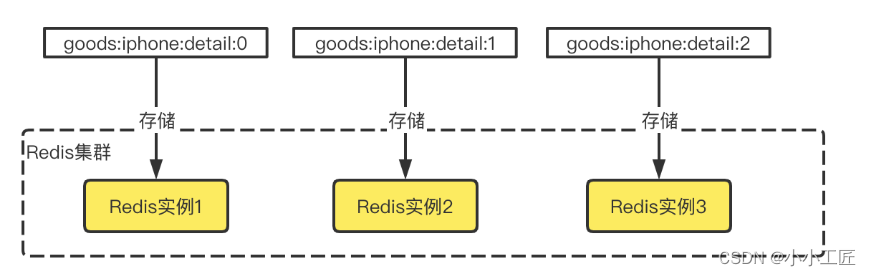
Cluster 模式下某个 key 是存储在固定的某个实例上的,所以热 key 才如此棘手,因为所有流量都打到同一个实例上。那么有没有可能打散这些流量呢?
答案是有可能的。如果我们把热 key 备份成 N 份,例如,原 key 是 goods📱detail,那么这 N 份的 key 就分为 goods:iphone:detail:0,goods:iphone:detail:1,goods:iphone:detail:2,……,goods:iphone:detail:N-1,分散在集群的多个节点,查询的时候可以按照一定的散列规则分散去访问不同的 key 副本,规则可以选择随机散列、按用户散列等。
随机散列的示意 Java 代码如下:
int N = M * 2//M是集群里的节点数,得到备份数量//生成随机数int random = new Random().nextInt(N);//构造备份新keyString bakHotKey = hotKey + “_” + random;String data = getFromRedis(bakHotKey);if (data == null) {//查询不到缓存,从数据库查询出来放到对应的备份Keydata = getFromDB();saveToRedis(bakHotKey, expireTime);}注:以上代码中 N 取了节点数 2 倍的原因是,由于 Redis 的散列存储算法是内置固定的,我们无法 100% 保证不同的备份 key 肯定落在不同副本上,所以 N 的取值上取了一点冗余。
-
读写分离: 开启读写分离,利用备节点扛住读流量。适用于热 Key 主要是读场景的情况。
-
京东hotkeys框架: 京东开源的hotkeys框架可用于实时侦测热 Key,并自动推送到本地缓存。适用于电商等场景的热 Key 发现和处理。
6座大山之_Big Key
大 Key在Redis中是一项棘手的问题,因为它会导致多种性能和稳定性问题,包括内存倾斜、网络阻塞和阻塞查询。以下是关于大 Key的问题以及解决方案的详细说明:
问题:
-
内存倾斜: 大 Key存在于集群的某个实例上,导致该实例的内存占用和CPU负载过大,成为系统的隐患点。
-
网络阻塞: 大 Key的操作可能导致网络I/O成为瓶颈,尤其是涉及到hgetall、get、hmget等操作时。
-
阻塞查询: Redis内部处理大 Key时是单线程处理的,大 Key的操作耗时,会阻塞其他语句的执行,影响整个集群的服务能力。
可能发生的场景:
-
部分列表类存储: 例如,存储粉丝列表或商品列表的大型数据结构。
-
统计类的集合: 需要按天统计某类用户的集合,随着用户数量的增加,该Key的大小也会增加。
-
大数据缓存类: Redis作为数据库缓存,若缓存的数据量过大,例如将几万行的数据存储为一个JSON,就会产生大Key。
发现大 Key的方法:
-
分析RDB文件: 对RDB文件进行分析,找出其中的大Key。
-
scan+debug: 结合scan命令和debug object命令,筛选出当前实例所有Key的大小,找到大Key。
-
redis-cli --bigkeys: 使用redis-cli的bigkeys命令,找到实例中各种数据类型的最大Key。
删除大 Key的方法:
-
Lazy Free: Redis 4.0提供了异步延时释放Key内存的功能,将释放操作放在后台线程处理,减少对主线程的阻塞。
-
UNLINK命令: Redis 4.0.0引入了UNLINK命令,其时间复杂度是O(1),能够快速删除大Key。
-
集合scan命令: 对于低版本的Redis,可以使用集合配套的scan命令分批删除大Key的元素。
避免产生大 Key的方法:
拆分: 在设计阶段,针对可能成为大 Key的数据结构,采取拆分策略,将大数据集拆分成多个子集,避免单个Key过大。
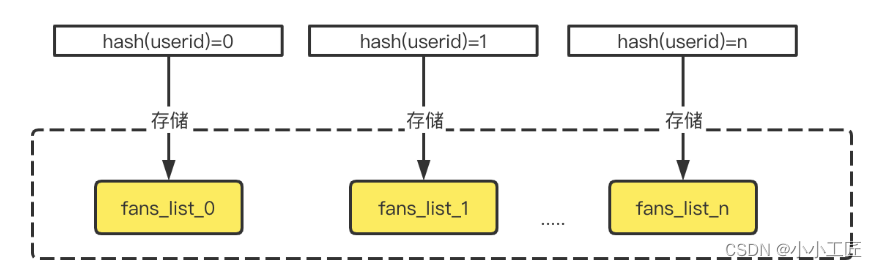
例如一个粉丝列表 list。针对一些大 V 博主,我们可以按照粉丝的 userid 决定其存在于哪个 list,拆分成 list0、list1、list2、list3 等。针对一个大的 hash,我们也可以将不同的 field 分散成多个子 hash,并且要先计算在哪个子 hash 中进行获取.
解决大 Key问题需要综合考虑系统设计、数据存储和操作方式等多个方面,以确保系统的性能和稳定性。

相关文章:
Redis - 高并发场景下的Redis最佳实践_翻过6座大山
文章目录 概述6座大山之_缓存雪崩 (缓存全部失效)缓存雪崩的两种常见场景如何应对缓存雪崩? 6座大山之_缓存穿透(查询不存在的 key)缓存穿透的原因解决方案1. 数据校验2. 缓存空值3. 频控4. 使用布隆过滤器 6座大山之_…...

数字乡村发展策略:科技引领农村实现跨越式发展
随着信息技术的迅猛发展和数字经济的崛起,数字乡村发展策略已经成为引领农村实现跨越式发展的重要手段。科技的力量正在深刻改变着传统农业的生产方式、农村的社会结构以及农民的生活方式,为农村经济发展注入了新的活力和动力。本文将从数字乡村的内涵、…...
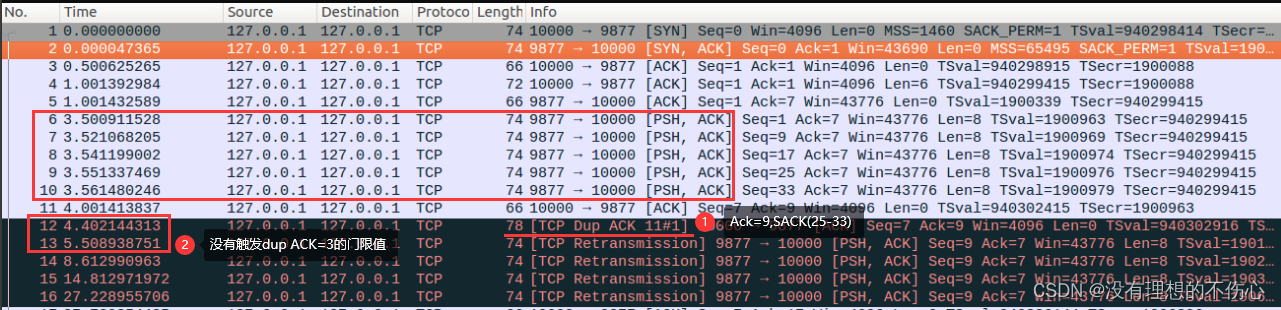
TCP重传机制详解——04FACK
文章目录 TCP重传机制详解——04FACK什么是FACKFACK的发展为什么要引入FACK实战抓包讲解开启FACK场景,且达到dup ACK门限值开启FACK场景,未达到dup ACK门限值 为什么要淘汰FACK总结REF TCP重传机制详解——04FACK 什么是FACK FACK的全称是forward ackn…...

安卓Java面试题 206- 210
206. 简述如何统计Activity的工作时间 ?如何统计Activity启动所用的时间? 可以通过分析Log得到(这个就是DDMS的那个Log)。 当我们点击触摸时会了类似以下的Log A: 03-06 03:36:47.865: VERBOSE/InputDevice(2486): ID[0]=0(0) Dn (0=>1) 03-06 03:36:47.865: INFO/Powe…...
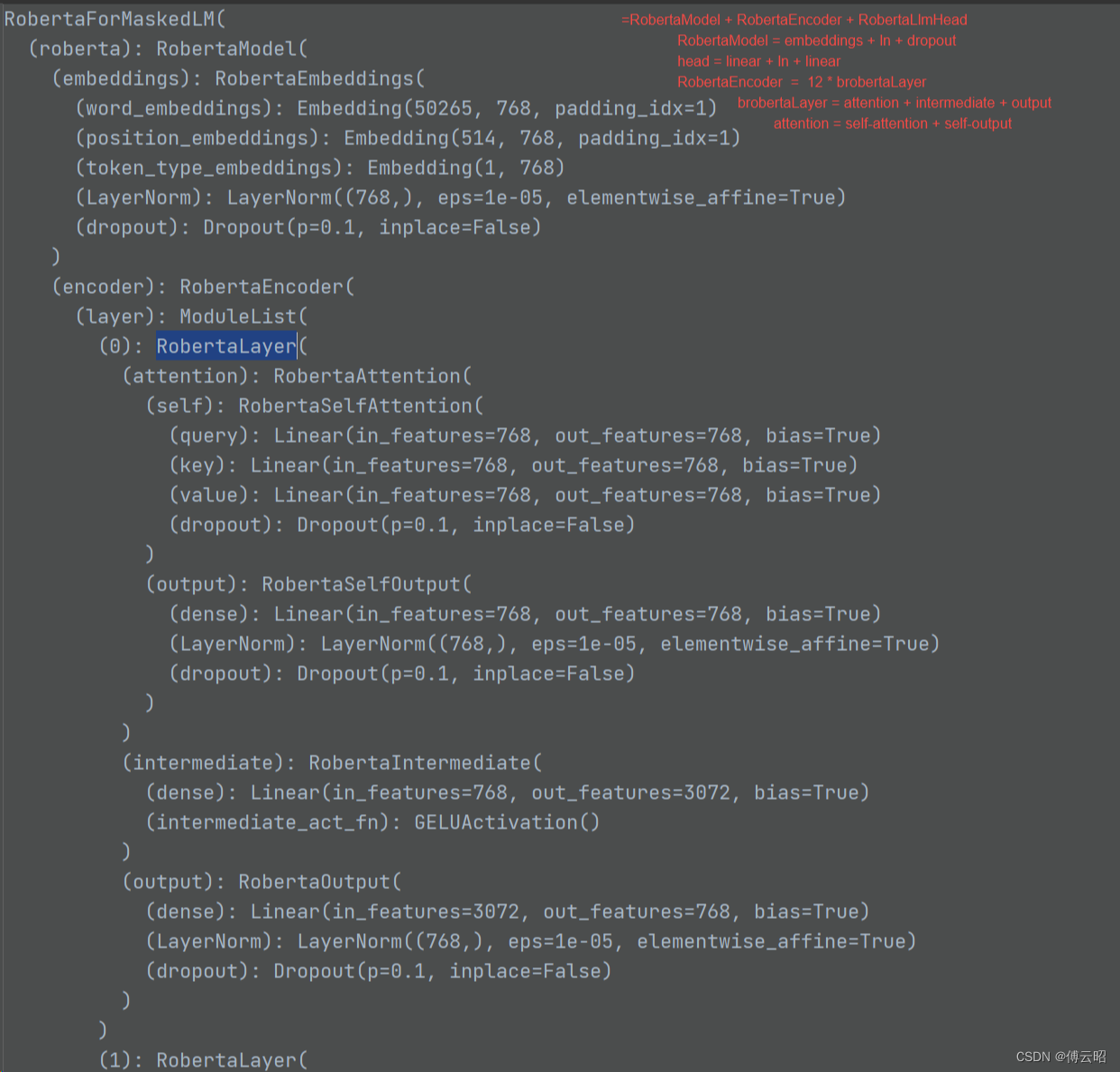
huggingface的transformers训练bert
目录 理论 实践 理论 https://arxiv.org/abs/1810.04805 BERT(Bidirectional Encoder Representations from Transformers)是一种自然语言处理(NLP)模型,由Google在2018年提出。它是基于Transformer模型的预训练方法…...
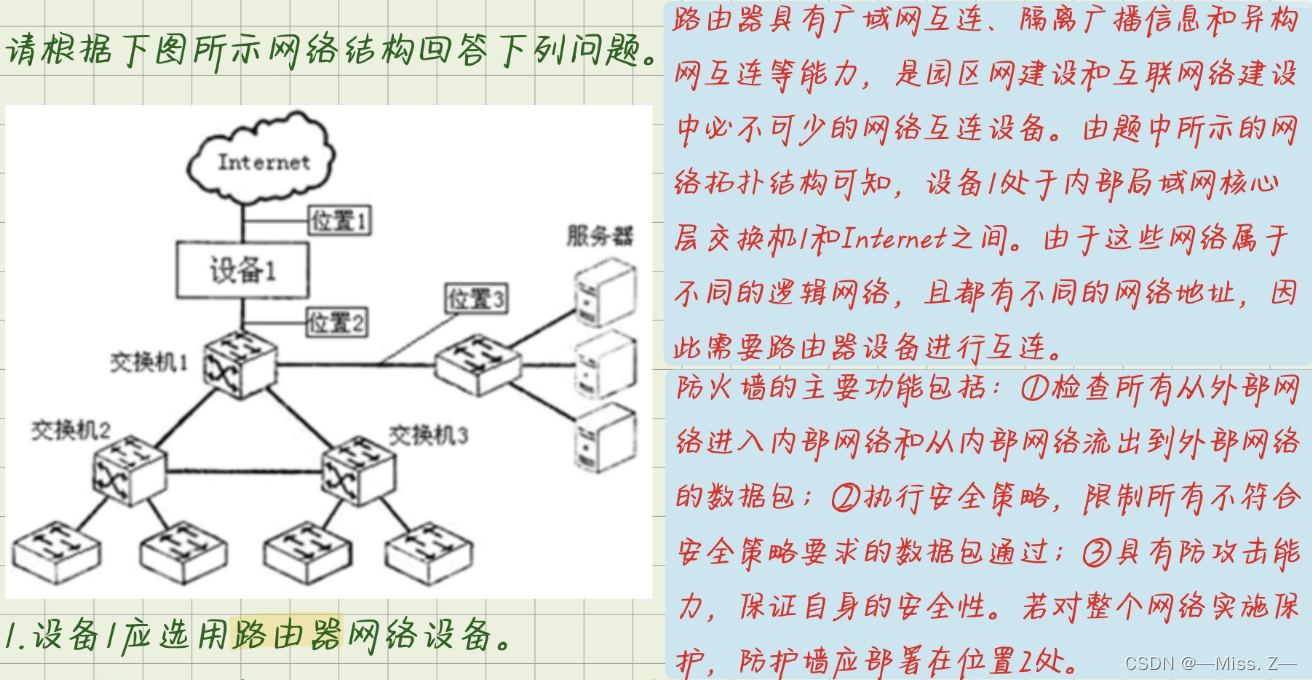
计算机三级——网络技术(综合题第五题)
第一题 填写路由器RG的路由表项①至④。 目的网络/掩码长度输出端口输出端口172.19.63.192/30S0(直接连接)172.19.63.188/30S1(直接连接) 路由器RG的S0的IP地址是172.19.63.193,路由器RE的S0的IP地址是172.19.63.194。 【解析】…...
)
C#使用ASP.NET Core Razor Pages构建网站(三)
上一篇文章了解Razor Pages 链接:C#使用ASP.NET Core Razor Pages构建网站(二) 接下来继续了解ASP.NET Core Razor Pages构建网站的后续内容 一、将Entity Framework Core配置为服务 要在 ASP.NET Core 项目中配置 Entity Framework Core 服…...
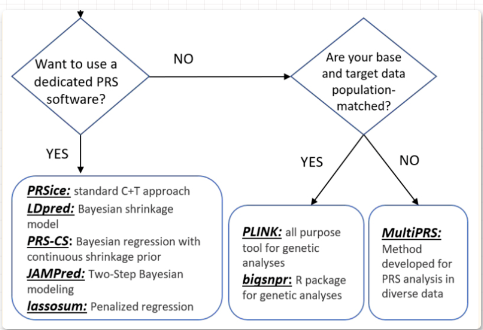
R语言迅速计算多基因评分(PRS)
Polygenic Risk Scores in R 最朴素的理解PRS: GWAS分析结果中,有每个SNP的beta值、se值、P值,因为GWAS分析中将SNP变为0-1-2编码,所以这些显著的SNP的beta值,就可以用于预测。 比如:GWAS分析中…...

蓝桥杯刷题_day3
文章目录 DAY301字串判断闰年Fibonacci数列圆的面积序列求和 DAY3 01字串 【题目描述】 对于长度为5位的一个01串,每一位都可能是0或1,一共有32种可能。它们的前几个是: 00000 00001 00010 00011 00100 请按从小到大的顺序输出这32种01串。…...

Dubbo源码解析-Provider服务暴露Export源码解析
上篇我们介绍了ServiceBean初始化和依赖注入过程,地址如下 Dubbo源码-Provider服务端ServiceBean初始化和属性注入-CSDN博客 本文主要针Dubbo服务端服务Export过程,从dubbo源码角度进行解析。 Dubbo 服务端暴露细节流程比较长,也是面试过程中…...
在微信小程序中或UniApp中自定义tabbar实现毛玻璃高斯模糊效果
backdrop-filter: blur(10px); 这一行代码表示将背景进行模糊处理,模糊程度为10像素。这会导致背景内容在这个元素后面呈现模糊效果。 background-color: rgb(255 255 255 / .32); 这一行代码表示设置元素的背景颜色为白色(RGB值为0, 0, 0)&a…...
【JavaScript】JavaScript 程序流程控制 ⑥ ( while 循环概念 | while 循环语法结构 )
文章目录 一、while 循环1、while 循环概念2、while 循环语法结构 二、while 循环 - 代码示例1、打印数字2、计算 1 - 10 之和 一、while 循环 1、while 循环概念 在 JavaScript 中 , while 循环 是一种 " 循环控制语句 " , 使用该语句就可以 重复执行一段代码块 , …...

Keil笔记(缘更)
Keil 一、使用Keil时可能会出现的问题1.Project框不见了2.添加文件时找不到3.交换文件位置4.main.c测试报1 warning5.搜索CtrlF 二、模电常识(白话随便版)一、名词解释二、基础门电路 三、STLINK点灯操作1.配置寄存器进行点灯2.使用库函数进行点灯 四.GPIO1.LED闪烁4.按键控制L…...
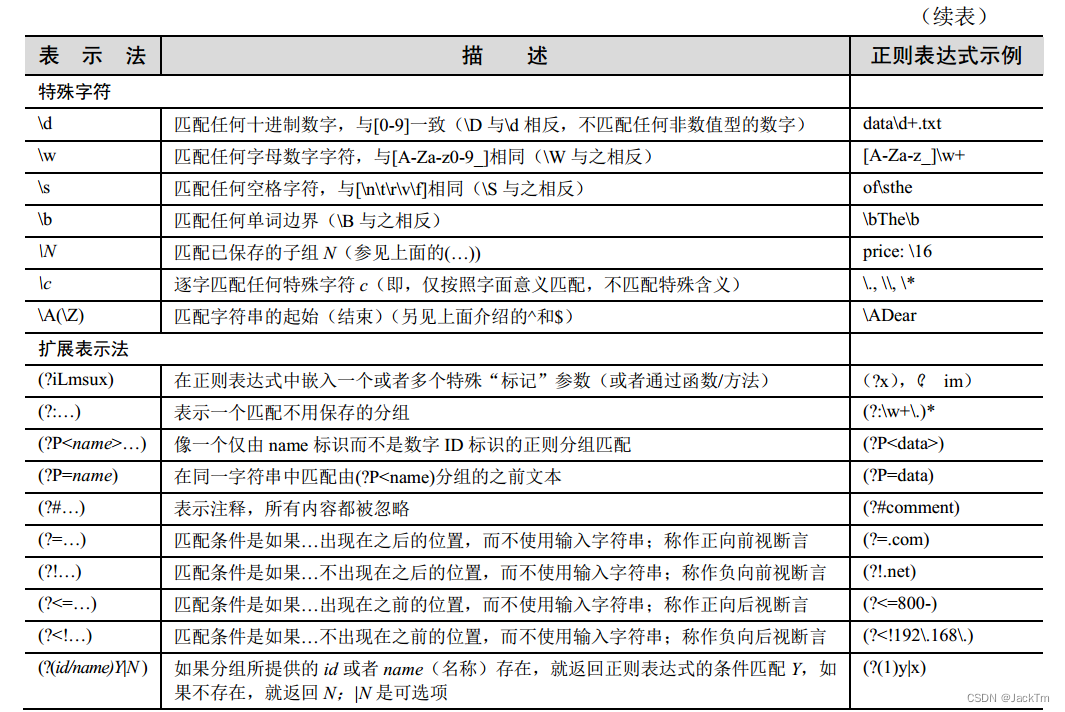
举4例说明Python如何使用正则表达式分割字符串
在Python中,你可以使用re模块的split()函数来根据正则表达式分割字符串。这个函数的工作原理类似于Python内置的str.split()方法,但它允许你使用正则表达式作为分隔符。 示例 1: 使用单个字符作为分隔符 假设你有一个由逗号分隔的字符串,你可…...
 等于多少?)
Java 中的 Math. round(-1. 5) 等于多少?
在 Java 中,Math.round() 方法用于四舍五入一个浮点数。这个方法的工作原理是,它会查看要舍入数值的小数点后第一位。如果这一位是 5 或更大,那么整数部分加 1;如果小于 5,整数部分保持不变。 对于 Math.round(-1.5)&…...
MFC界面美化第三篇----自绘按钮(重绘按钮)
1.前言 最近发现读者对我的mfc美化的专栏比较感兴趣,因此在这里进行续写,这里我会计划写几个连续的篇章,包括对MFC按钮的美化,菜单栏的美化,标题栏的美化,list列表的美化,直到最后形成一个完整…...

设计模式|工厂模式
文章目录 1. 工厂模式的三种实现2. 简单工厂模式和工厂方法模式示例3. 抽象工厂模式示例4. 工厂模式与多态的关系5. 工程模式与策略模式的关系6. 面试中可能遇到的问题6.1 **工厂模式的概念是什么?**6.2 **工厂模式解决了什么问题?**6.3 **工厂模式的优点…...
CHAT~(持续更新)
CHAT(持续更新) 实现一个ChatGPT创建API设计页面布局业务操作技术架构 实现安装工具 其他 实现一个ChatGPT 创建API 最简单也最需要信息的一步 继续往下做的前提 此处省略,想要获取接口创建方式联系 设计 页面布局 按照官网布局 业务操作…...

linux系统------------Mysql数据库介绍、编译安装
目录 一、数据库基本概念 1.1数据(Data) 1.2表 1.3数据库 1.4数据库管理系统(DBMS) 数据库管理系统DBMS原理 1.5数据库系统(DBS) 二、数据库发展史 1、第一代数据库 2、第二代数据库 3、第三代数据库 三、关系型数据库 3.1关系型数据库应用 3.2主流的…...
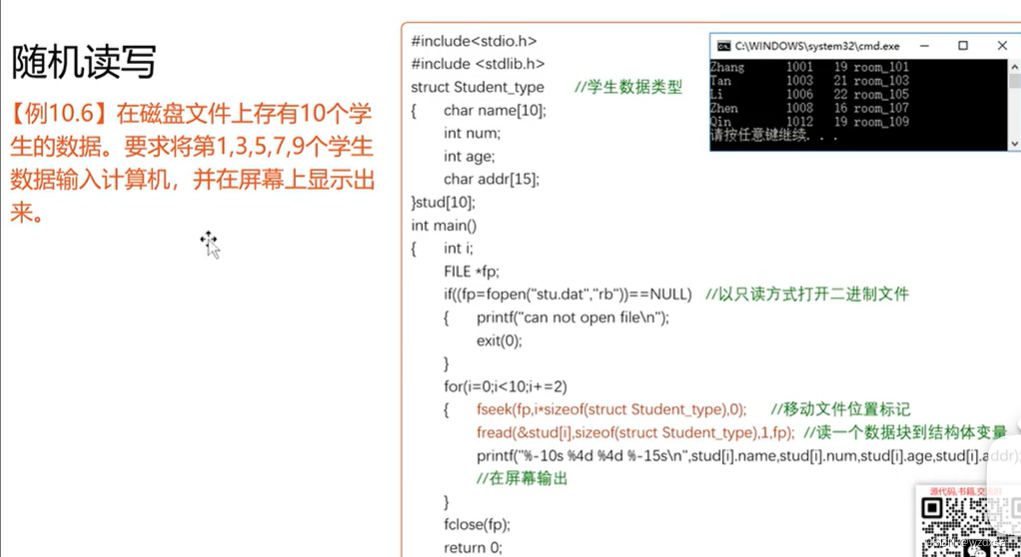
文件操作3
随机读写数据文件 一、随机读写原理 在我们写数据时,有一个光标不断的在随着新写入的数据往后移动; 而读数据时,也有一个看不见光标,随着已经读完的数据,往后移动 这里的文件读写位置标记——可以想象成图形界面里的…...

模型越强,Bug越隐?DeepSeek代码生成评测:12个真实项目踩坑案例,速查避雷清单
更多请点击: https://kaifayun.com 第一章:模型越强,Bug越隐?DeepSeek代码生成评测:12个真实项目踩坑案例,速查避雷清单 当大模型在代码补全、函数生成和单元测试编写中表现愈发惊艳,一个反直觉…...

亿万富翁不再相信比特币
亿万富翁首次公开称不再相信比特币的「数字黄金」叙事。对比特币而言,或许是一个重要转折点。5月22日,亿万富翁投资者马克库班表示, 在对比特币作为抵御法币疲软和地缘政治不稳定对冲工具的作用失去信心后, 他已经卖掉大部分比特币持仓。净资产约为100亿…...

如何永久保存微信聊天记录?WeChatMsg数据导出完整指南
如何永久保存微信聊天记录?WeChatMsg数据导出完整指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

别再手算公式了!用MathCAD Prime 5.0搞定工程计算,附保姆级安装与破解避坑指南
MathCAD Prime 5.0工程计算革命:从公式恐惧到高效验证的全流程实战 记得三年前我刚接手第一个桥梁应力分析项目时,整整两周都泡在Excel公式和手写计算稿里。某个深夜,当我发现第17次计算结果的单位换算出现致命错误时,崩溃得差点把…...

LinkSwift:九大网盘直链下载助手终极指南,告别限速烦恼
LinkSwift:九大网盘直链下载助手终极指南,告别限速烦恼 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动…...

Android 13 HTTPS抓包失效原因与Proxyman实战解决方案
1. 为什么Android 13上抓HTTPS包突然变难了?从Fiddler/Charles失效说起 你是不是也遇到过:上周还能用Fiddler在Android 12真机上稳稳抓到某电商App的登录接口,升级到Android 13后,所有HTTPS请求全变成“Connection refused”或直接…...

Tkinter Designer:从手动编码到可视化设计的Python GUI开发范式转变
Tkinter Designer:从手动编码到可视化设计的Python GUI开发范式转变 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer Python GUI开发长期面临…...

【开源】前端拖拽表单设计器 自定义表单
【开源】开源 VUE拖拽表单设计器 自定义表单 开源 tduck-platform: Tduck-填鸭收集器是一款开源的表单在线收集系统,后台基于SpringBootMybatisPlusMySqlRedis,前端基于Vue ElementUI开发,功能强大,界面美观。keywords࿱…...

Selenium自动化绕过反爬:彻底清除webdriver指纹的三层策略
1. 为什么“移除 webdriver 标志”成了自动化测试与爬虫绕过的第一道门槛 你有没有遇到过这样的情况:用 Selenium 写好了一套完整的电商比价脚本,本地跑得丝滑流畅,一上服务器或换台新机器就频繁触发验证码,甚至直接返回 403&…...

飞书文档批量导出终极解决方案:3分钟搞定700+文档迁移
飞书文档批量导出终极解决方案:3分钟搞定700文档迁移 【免费下载链接】feishu-doc-export 飞书文档导出服务 项目地址: https://gitcode.com/gh_mirrors/fe/feishu-doc-export 还在为飞书文档迁移而头疼吗?当企业需要从飞书切换到其他办公平台&am…...