python、execl数据分析(数据描述)
一 python
1.各函数
1.1python库的安装与导入
#pip install os#pip install matplotlib#pip install seaborn#pip install scikit-learn#pip install scipy#修 改 工 作 目 录import osos.getcwd () # 查看当前工作环境os.chdir( 'F :\my course\database ') # 修改工作环境os.getcwd ()#模 块 价 值import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns #统 计 绘 图from sklearn.preprocessing import StandardScalerfrom scipy.stats import normfrom scipy import stats #统 计from sklearn.impute import Simple Imputer #导 入 模 块1.2python读入和检查数据
# 读 入 分 析 数 据
2 df= pd.read_csv("customer1997 .csv")
3
4 # 检 查 数 据、 行 数、 列 数、 列 属 性 和 类 型
5 df.shape # 行 数 和 列 出
6 df.info () # 每 个 属 性 的 行 数 和 类 型
7 df.columns # 属 性 列 名 称
8 # 查 看 数 据 集 前5 行
9 df.head (5)1.3数据属性的描述性分析
1 # 分 别 查 看RFM 的 描 述 统 计 量
2 # 方 法1 使 用describe() 输 出 数 值 属 性 的 行 数、 均 值、 标 准 差、 最 小 值、 Q1 ,Q2 ,Q3 ,最 大 值 3 df.describe ()
4 # 方 法2 使 用describe() 输 出 数 值 属 性 的 行 数、 均 值、 标 准 差、 最 小 值、 Q1 ,Q2 ,Q3 ,最 大 值 5 df[ 'Rec en cy '].describe () # 注 意 大 小 写 是 敏 感 的
6 # 方 法3 使 用 函 数 对 某 列 进 行 描 述 统 计
7 print( '对 客 户 的 到 店 次 数 进 行 描 述 统 计 ')
8 print( '最 小 值 是 ' , df[ 'Frequency '].min ())
9 print( '均 值 是 ' , df[ 'Frequency '].mean ())
10 print( ' 中 位 数 是 ' , df[ 'Frequency '].median ())
11 print( '第25 百 分 位 数 ' , df[ 'Frequency '].quantile(q=0.25))
12 print( '第75 百 分 位 数 ' , df[ 'Frequency '].quantile(q=0.75))
13 print( '最 大 值 是 ' , df[ 'Frequency '].max ())
14 print( '极 差 是 ' , df[ 'Frequency '].max ()-df[ 'Frequency '].min ())
15 print( '方 差 和 标 准 差 ' , df[ 'Frequency '].var(),df[ 'Frequency '].std())
16 print( '变 异 系 数 ' , df[ 'Frequency '].std()/df[ 'Frequency '].mean ())
17 print( '偏 度 和 峰 度 ' , df[ 'Frequency '].skew (),df[ 'Frequency '].kurt os is ())
18
19 # 数 值 型 属 性 统 计 分 布 图
20 # 绘 制 分 布 图 确 保 import seaborn as sns 被 执 行
21 df[ 'Monetary ']
22 sns.distplot(df[ 'Monetary '])
23 # 绘 制 盒 型 图
24 sns.boxplot(df[ 'Monetary '])
25 # 绘 制 核 密 度 图
26 sns.kdeplot(df[ 'Monetary '], shade=True , bw=.5, color="olive")1.4分类属性的描述性分析
1 # 分 类 数 据 的 频 数 统 计
2 # 按 会 员 卡 等 级 统 计 人 数、 RFM 的 均 值、 描 述 统 计 量
3 # 设 置 数 据 对 象 的 分 组 属性 ,并 创 建 新 的 数 据 对 象
4 member card_summary=df.groupby( 'member_card ')
5 member card_summary [ 'customer_id '].count ()
6 member card_summary [ 'Rec en cy '].mean ()
7 member card_summary .mean ()
8 member card_summary [ 'Frequency '].describe ()
9 member card_summary [ 'Monetary '].describe ()1.5两个分类属性的交叉统计分析
1 # 两 个 个 分 类 属 性 的 交 叉 统 计 分 析
2 # 按 会 员 卡 和 性 别 的 输 出 交 叉 表
3 pd.crosstab(df[ 'member_card '], df[ 'gender '])
4 #对 交 叉 结 果 进 行 归 一 化
5 pd.crosstab(df[ 'member_card '], df[ 'gender '],normalize=True)
6 #在 最 右 边 增 加 一 个 汇 总 列
7 pd.crosstab(df[ 'member_card '], df[ 'gender '],normalize=True ,margins=True)
8 # 对 每 列 进 行 归 一 化
9 pd.crosstab(df[ 'member_card '], df[ 'gender '],normalize= 'columns ')
10 # 绘 制 频 数 图/条 形 图
11 # 对 比 每 个 会 员 等 级 的 不 同 性 别 的 客 户 数 量
12 sns.countplot(y="member_card" ,hue= 'gender ' ,data=df)
13 # 两 个 分 类 属 性 增 加1个 数 值 属 性 的 盒 形 图
14 sns.boxplot(x="member_card" ,y="Frequency" ,hue="gender" ,data=df)1.6两个数值属性的相关分析
# 两 个 数 值 属 性
2 # 绘 制 相 关 矩 阵 和 热 力 图
3 # 输 出 数 值 型 属 性 的 两 两 相 关 系 数 表
4 df.corr ()
5 #绘 制 热 力 图
6 corr=df.corr ()
7 corr=(corr)
8 sns.heatmap(corr , xticklabels=corr.columns.values , yticklabels=corr.columns.values) 9 #绘 制2个 变 量 散 点 图 (scatterplot)
10 sns.scatterplot(x="Frequency" , y="Monetary" , data=df)
11 #绘 制 带 回 归 线 的 散 点 图 (lmplot)
12 sns.lmplot(x="Frequency" , y="Monetary" , data=df)
13 #在 散 点 图 上 增 加 一 个 分 类 属 性
14 sns.lmplot(x="Frequency" , y="Monetary" ,hue="gender" , data=df)
15 # 集 群 散 点 图(swarmplot)
16 sns.swarmplot(x=df[ 'gender '], y=df[ 'Monetary '])
17 sns.swarmplot(x=df[ 'gender '], y=df[ 'Frequency '])
18
19
20 #简 单 散 点 图 的 绘 图 语 法: sns .scatterplot( x=X对 应 变量 , y=Y对 应 变 量)
21 #分 组 散 点 图 的 绘 图 语 法: sns .scatterplot( x=X对 应 变量 , y=Y对 应 变量 , hue=分 组 依 据 的 类 别 变 量) 22 # 带 回 归 线 的 散 点 图 的 绘 图 语 法: sns .regplot( x=X对 应 变量 , y=Y对 应 变 量)
23 # 带 回 归 线 的 分 组 散 点 图 的 绘 图 语 法: sns .lmplot(x=X变 量 列名 , y=Y变 量 列名 , hue=分 组 依 据 的 类 别 变 量 列 名 , data=数 据 表)
24 #集 群 散 点 图(swarmplot) 的 绘 图 语 法: sns .swarmplot( x=X对 应 的 类 别 变量 , y=Y对 应 变 量)1.7分类属性和数值属性的方差分析
1 # 1个 分 类 属 性 和1个 数 值 属 性
2 # 绘 制 盒 型 图
3 sns.boxplot(x=df[ 'member_card '],y=df[ 'Monetary '],data=df)
4 sns.boxplot(x=df[ 'gender '],y=df[ 'Monetary '],data=df)
5 # 单 因 素 方 差 分 析: 比 较 均 值 的 差 异 性
6 from scipy import stats
7 from statsmodels.formula.api import ol s
8 from statsmodels.stats.anova import anova_lm
9 from statsmodels.stats.multi comp import pairwise_tukeyhsd
10
11 df2=pd.con cat ([df[ 'gender '],df[ 'Monetary ']],axis=1)
12 anova_monetary= anova_lm(ol s( 'Monetary~C (gender) ' ,data=df2[[ 'gender ' , 'Monetary ']]).fit()) 13 print(anova_monetary)
14 ## 在0.05 的 显 著 水 平 下, 不 同 性 别 客 户 的 消 费 金 额 是 有 差 异 的
15 # 绘 制 不 同 组 的 核 密 度 图
16 # 使 用loc()取 出 不 同 组 的 数 据
17 p1=sns.kdeplot(df.loc[(df[ 'gender ']== 'M '), 'Rec en cy '], shade=True , color="r" ,label= 'M ') 18 p2=sns.kdeplot(df.loc[(df[ 'gender ']== 'F '), 'Rec en cy '], shade=True , color="b" ,label= 'F ') 19 plt.show ()
20 ##绘 制 叠 加 图 时 多 行 一 起 执 行1.8时间序列数据
1 # 带 有 时 间 属 性
2 # 读 入 分 析 数 据
3 import numpy a s np
4 import pandas a s pd
5 from datetime import datetime
6 import matplotlib.pylab a s plt
7 # 读 取 数 据, pd .read_csv 默 认 生 成DataFrame对 象, 需 将 其 转 换 成Series对 象
8 df = pd.read_csv( 'daily sales1997 .csv ' , encoding= 'utf-8 ' , index_col= 'date ')
9 df.info ()
10 df.index
11 df.index = pd.to_datetime(df.index) # 将 字 符 串 索 引 转 换 成 时 间 索 引
12 ts = df[ 'sales '] # 生 成pd .Series对 象
13 # 查 看 数 据 格 式
14 ts.head ()
15 ts.head ().index
16 #查 看 某 日 的 值 既 可 以 使 用 字 符 串 作 为 索 引, 又 可 以 直 接 使 用 时 间 对 象 作 为 索 引
17 ts[ '1997-01-05 ']
18 ts[datetime (1997 ,10 ,1)]
19 #切 片 操 作
20 ts[ '1997-5 ' : '1997-6 ']
21 #绘 制 时 间 序 列 图
22 ts.plot(fig size=(12 ,8))2.例子
(1)
hotel.csv

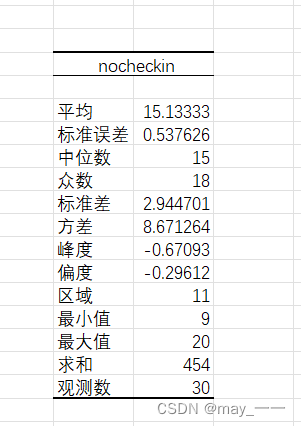
def hotel_data():df = pd.read_csv('hotel.csv')# print(df)return dfdef get_shape(): # 获取行列值shape = hotel_data().shapeprint(shape)def get_info():info = hotel_data().infoprint(info)def get_column():column = hotel_data().columnsprint(column)def get_describe(): # 描述数据:数量,均值,最小值,最大值,25%,50%,75%describe = hotel_data().describe()print(describe)def get_box(): # 盒型图data = hotel_data()sns.boxplot(data)# sns.boxplot(data['nocheckin'], vert=False, showfliers=True)plt.show()def get_dis(): # 柱形图data = hotel_data()sns.displot(data)plt.show()def get_kdef(): # 分布图data = hotel_data()# sns.kdeplot(data, shade=True, bw=.5, color="olive")sns.kdeplot(data, fill=True, bw_method=.5, color="olive")plt.show()hotel_data()结果:
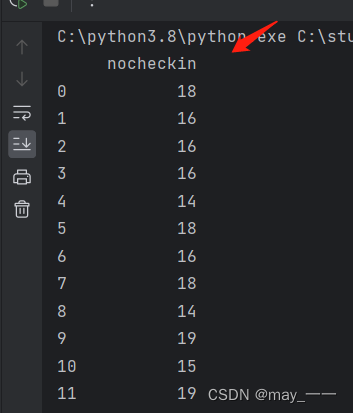
get_describe()结果:
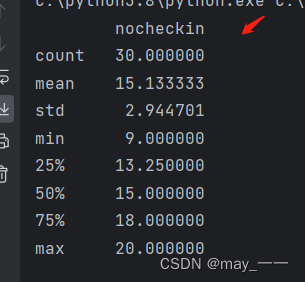
get_column()结果:
get_box()结果:
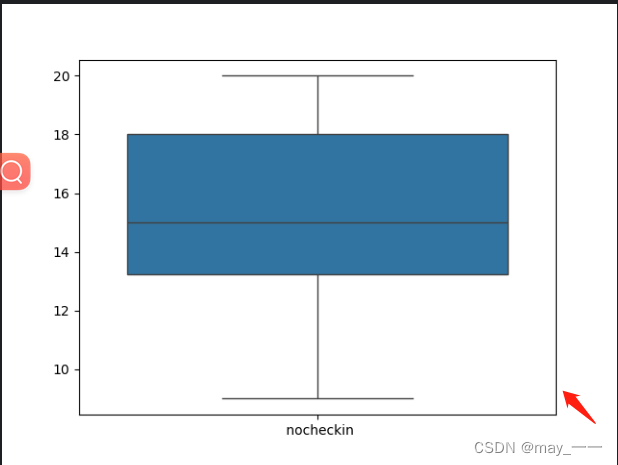
get_dis()结果:

get_kdef()结果:
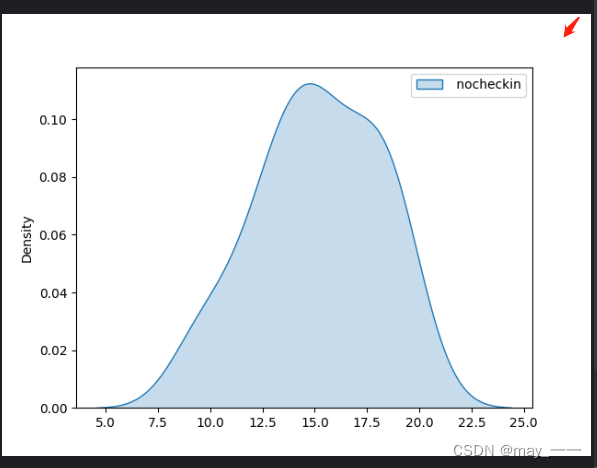
(2)
customer1997.csv
def get_summary(): # 分组频数统计data = customer_data()member_summary = data.groupby('member_card')data1 = data.groupby('member_card').count()print(data1)data2 = member_summary['customer_id'].count() # 单个变量 每类会员卡人数print(data2)data3 = member_summary['Monetary'].mean() # 双变量 会员卡 消费金额 每类会员卡平均print(data3)data4 = member_summary['Monetary'].describe()print(data4)结果

二 execl
1.调出“数据分析”按钮
文件--选项--加载项--转到--分析工具库
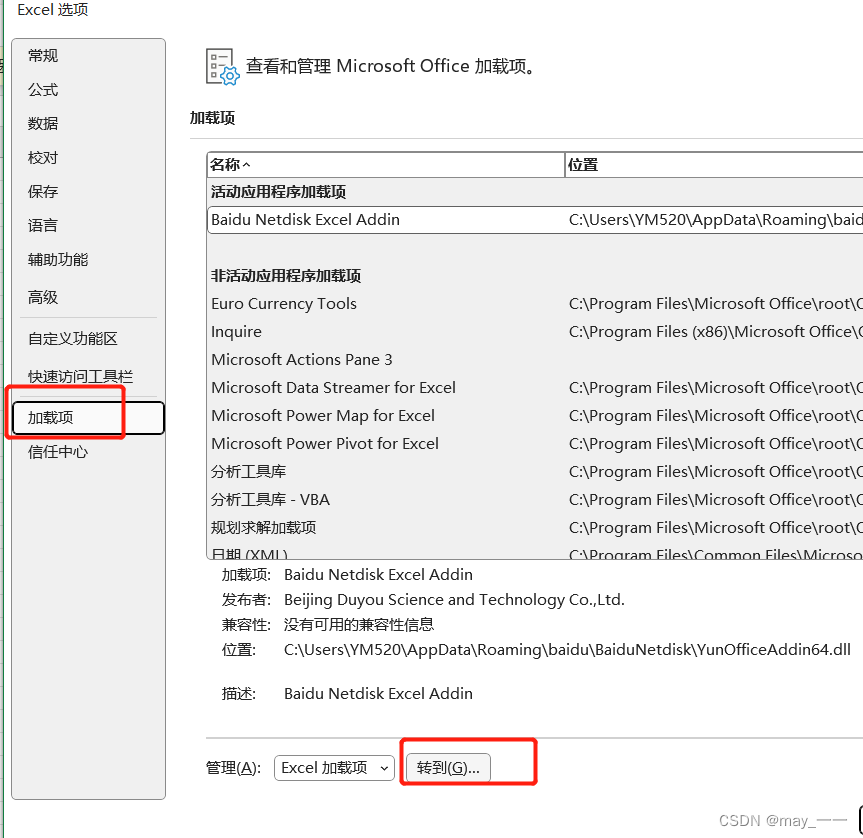
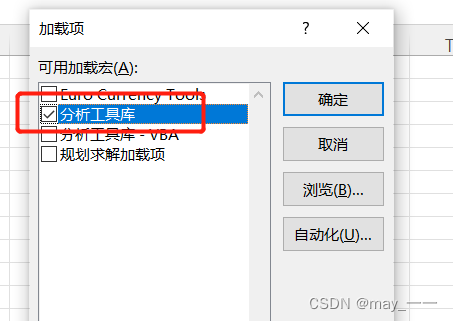
查看
 2.数据分析使用
2.数据分析使用
选中数据,点击“数据分析”,选中“描述分析”


结果如下:
相关文章:
python、execl数据分析(数据描述)
一 python 1.各函数 1.1python库的安装与导入 #pip install os#pip install matplotlib#pip install seaborn#pip install scikit-learn#pip install scipy#修 改 工 作 目 录import osos.getcwd () # 查看当前工作环境os.chdir( F :\my course\database ) # 修改工作环境o…...
——页面布局方法)
前端理论总结(css3)——页面布局方法
瀑布流 优点:节省空间,外表美观,更有艺术性 对于触屏设备非常友好,通过向上滑动浏览 用户浏览时的观赏和思维不容易被打断,留存更容易 缺点:用户…...

06|Java集合框架初学者指南:List、Set与Map的实战训练
Java集合框架是Java语言的核心部分,它提供了丰富的类和接口,用来高效地管理和操作大量数据。这个强大的工具箱包括多种集合类型,其中最为常用的是List、Set和Map。 1.List - 有序且可重复的数据清单 概念: List就像一个购物清单,你可以按照加入顺序存放和检索项目,而且同…...
压测过程中的注意事项)
Jmeter基础篇(18)压测过程中的注意事项
一、测试计划设计: 1、场景设计:需要基于实际业务需求设计合理的并发用户模型、事务和思考时间,模拟真实用户的操作行为。 2、目标明确:定义明确的性能指标(如响应时间、吞吐量、并发用户数、错误率等)和性…...
‘npm‘ 不是内部或外部命令,也不是可运行的程序
npm认识三年了,今天才知道这是node.js的命令 也就是说,想要在cmd里面运行 npm 命令,但就的安装node.js 1. node.js安装 没有安装包的先下载安装包:下载 | Node.js 中文网 (nodejs.cn) 下载之后双击打开,一路安装确…...

使el-table通过操控鼠标滚轮横向滚动
1.创建directive文件夹,里面创建directive.js文件 import Vue from vue;Vue.directive(scroll-x,{inserted:function(el){let domClass el.getAttribute(class)if(domClass.indexOf(el-table)<0){return false}const scrollDiv el;if(scrollDivnull){return fa…...

神经网络深度学习梯度下降算法优化
【神经网络与深度学习】以最通俗易懂的角度解读[梯度下降法及其优化算法],这一篇就足够(很全很详细)_梯度下降在神经网络中的作用及概念-CSDN博客 https://blog.51cto.com/u_15162069/2761936 梯度下降数学原理...

向开发板上移植ip工具:将ip工具移植到开发板系统中
一. 简介 前面一篇文章对 ip工具源码进行了交叉编译,生成了ip工具。文章如下: 向开发板上移植ip工具:交叉编译 ip工具-CSDN博客 本文对生成的 ip工具进行移植,即移植到开发板系统中,并确定是否可用。 二. 向开发板…...

数据关联_3.7
目标 利用匈牙利算法对目标框和检测框进行关联 在这里我们对检测框和跟踪框进行匹配,整个流程是遍历检测框和跟踪框,并进行匹配,匹配成功的将其保留,未成功的将其删除。 def associate_detections_to_trackers(detections, track…...
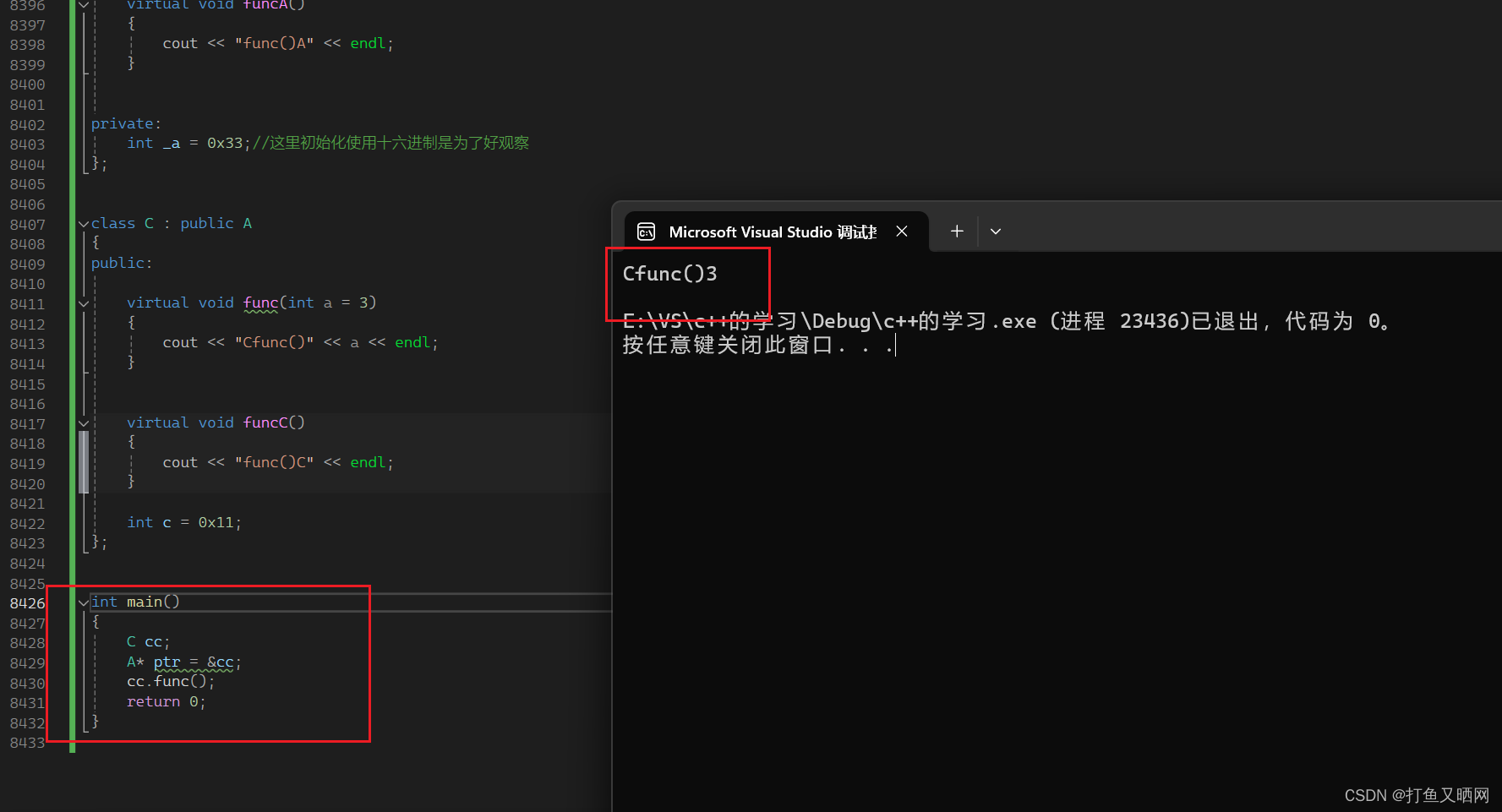
总结虚函数表机制——c++多态底层原理
前言: 前几天学了多态。 然后过去几天一直在测试多态的底层与机制。今天将多态的机制以及它的本质分享给受多态性质困扰的友友们。 本节内容只涉及多态的原理, 也就是那张虚表的规则,有点偏向底层。 本节不谈语法!不谈语法&#x…...

Contos7 安装 Maven
Contos7 安装 Maven 前言 Maven是一个用于构建和管理Java项目的强大工具。它提供了一种简单且一致的方式来构建、测试和部署项目,同时管理项目依赖关系。Maven基于项目对象模型(Project Object Model,POM),使用XML…...

对适配器模式的理解
目录 一、适配器模式是什么?二、示例【[来源](https://refactoringguru.cn/design-patterns/adapter)】1 第三方依赖 (接口A 数据A)2 客户端3 方钉转圆钉的适配器(数据B) 三、适配器(xxxAdapter࿰…...

纯前端调用本机原生Office实现Web在线编辑Word/Excel/PPT,支持私有化部署
在日常协同办公过程中,一份文件可能需要多次重复修改才能确定,如果你发送给多个人修改后再汇总,这样既效率低又容易出错,这就用到网页版协同办公软件了,不仅方便文件流转还保证不会出错。 但是目前一些在线协同Office…...

双指针的详细教程
双指针算法是一种常用的算法技巧,它通常用于在数组或字符串中进行快速查找、匹配、排序或移动操作。 双指针并非真的用指针实现,一般用两个变量来表示下标(在后面都用指针来表示) 双指针算法使用两个指针在数据结构上进行迭代&a…...
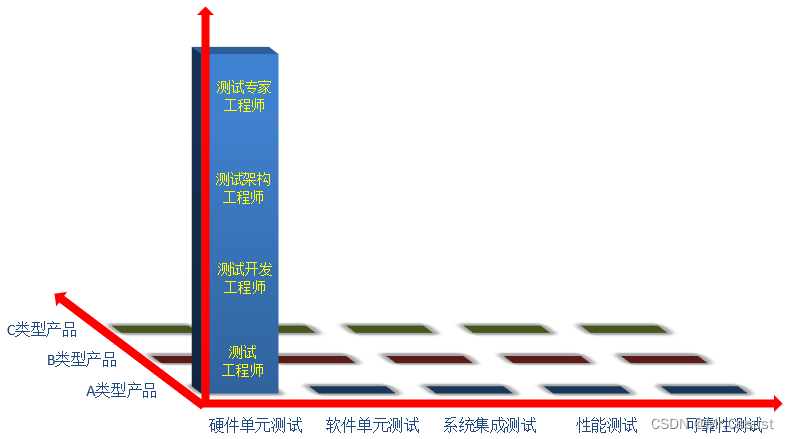
【Review+预测】测试架构演进的曲折之路
文章目录 前言 一、“原始”阶段 二、“小打小闹”阶段 三、“小米加步枪”阶段 四、“摩托化部队”阶段 五、“骑兵连”阶段 六、“海军陆战队”阶段 七、“社区型组织”阶段 前言 近期公司的测试团队需要重新组织安排,本着谦虚谨慎的态度,我从…...

2015年认证杯SPSSPRO杯数学建模D题(第二阶段)城市公共自行车全过程文档及程序
2015年认证杯SPSSPRO杯数学建模 D题 城市公共自行车 原题再现: 城市交通问题直接影响市民的生活和工作。在地形平坦的城市,公共自行车出行系统是一种很好的辅助手段。一般来说,公共自行车出行系统由数据中心、驻车站点、驻车桩、自行车&…...
视频汇聚平台EasyCVR启用图形验证码之后调用login接口的操作方法
视频综合管理平台EasyCVR视频监控系统支持多协议接入、兼容多类型设备,平台可以将区域内所有部署的监控设备进行统一接入与集中汇聚管理,实现对监控区域的实时高清视频监控、录像与存储、设备管理、云台控制、语音对讲、级联共享等,在监控中心…...
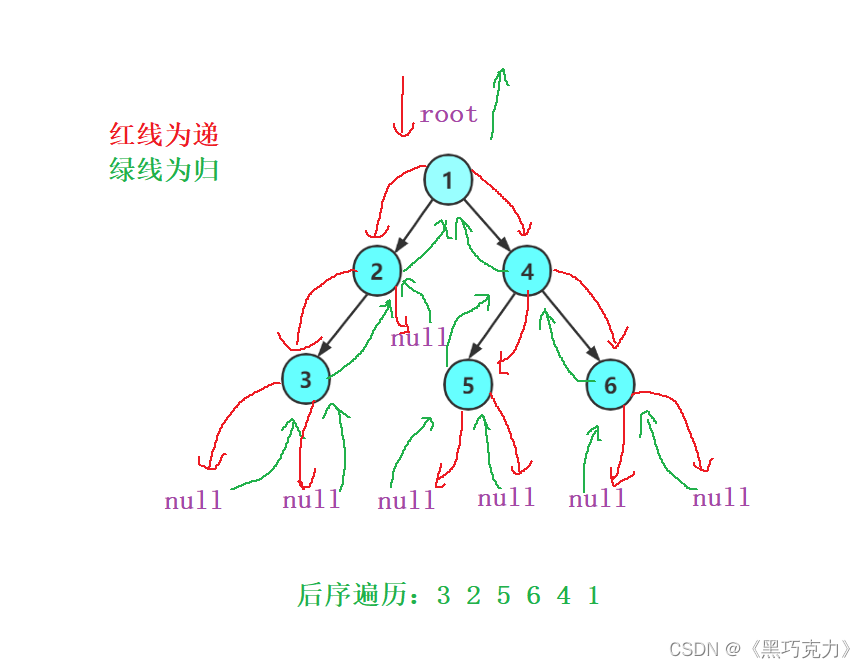
【数据结构】非线性结构——二叉树
文章目录 前言1.树型结构1.1树的概念1.2树的特性1.3树的一些性质1.4树的一些表示形式1.5树的应用2.二叉树 2.1 概念2.2 两种特殊的二叉树2.3 二叉树的性质2.4 二叉树的存储2.5 二叉树的基本操作 前言 前面我们都是学的线性结构的数据结构,接下来我们就需要来学习非…...
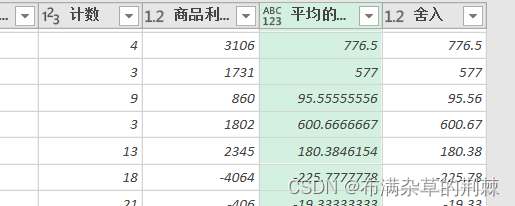
数据分析POWER BI之power query
1.导入数据 ctrla全选--数据--获取数据--其他来源--来自表格/区域 导入数据,进入编辑模式 2.整理与清除 清除:删除所选列的非打印字符 转换--格式--清除 修整:删除前面和后面的空格 转换---格式---修整(修整后前面后面的空格没有了…...

【c语言】详解操作符(上)
1. 操作符的分类 2. 原码、反码、补码 整数的2进制表示方法有三种,即原码、反码、补码 有符号整数的三种表示方法均有符号位和数值位两部分,2进制序列中,最高位的1位是被当做符号位其余都是数值位。 符号位都是用0表示“正”,用…...

Unity InputField组件保姆级配置指南:从登录框到聊天框,一次搞定所有输入场景
Unity InputField组件实战配置指南:从登录验证到聊天系统的深度优化在游戏开发中,用户输入交互是连接玩家与游戏世界的重要桥梁。Unity的InputField组件作为最常用的输入控件之一,其配置灵活性直接影响用户体验的流畅度。本文将深入探讨如何针…...

避坑指南:在openEuler 22.03上配置vsftpd虚拟用户,解决PAM认证和SELinux权限问题
深度实战:openEuler 22.03中vsftpd虚拟用户配置全流程与疑难解析 在服务器运维领域,FTP服务作为经典的文件传输方案,其安全配置一直是系统管理员的核心技能。本文将聚焦openEuler 22.03操作系统环境,深入剖析vsftpd虚拟用户模式的…...

第一次的博客
我是???计划考研由于是跨考,计划从0开始,先打c语言基础,再学习数据结构每天二~三小时暂无...

避坑指南:处理NOAA海温数据时,关于陆地掩膜、时间解析和面积加权的三个常见错误
NOAA海温数据处理实战:避开陆地掩膜、时间解析与面积加权的三大陷阱当分析NOAA OISST海温数据时,许多研究者会不自觉地掉进几个技术陷阱——这些错误看似微小,却足以让整个分析结果偏离真实。我曾亲眼见过一位同行因为忽略纬度权重校正&#…...

【STM32 C 语言入门】什么是强制类型转换?小白也能秒懂!
一、什么是强制类型转换?一句话讲透 强制类型转换,就是“强行把一种数据类型,变成另一种数据类型”。 打个比方: 你手里拿着一个苹果(int类型)但函数只收橙子(枚举类型)强制类型转换…...

量子机器学习模型安全:反向工程威胁与防御策略解析
1. 量子机器学习模型的反向工程:安全威胁与防御策略量子计算与机器学习的结合,正以前所未有的方式重塑我们处理复杂问题的能力。作为一名长期关注量子算法与信息安全交叉领域的研究者,我亲眼见证了量子机器学习从理论构想走向实际应用的飞速发…...

Taotoken用量看板如何帮助团队分析并优化大模型API支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队分析并优化大模型API支出 对于团队技术负责人或项目经理而言,管理大模型API支出并非易事…...

3步搞定专业显示管理:ColorControl让色彩控制变得如此简单
3步搞定专业显示管理:ColorControl让色彩控制变得如此简单 【免费下载链接】ColorControl Easily change NVIDIA display settings and/or control LG TVs 项目地址: https://gitcode.com/gh_mirrors/co/ColorControl 你是否曾经遇到过这样的烦恼?…...
)
ssm出租车投诉管理系统(10092)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

AI搜索将如何重构信息获取链路:3大底层范式迁移、4类已验证商业落地路径及2025关键拐点预警
更多请点击: https://intelliparadigm.com 第一章:AI搜索将如何重构信息获取链路:3大底层范式迁移、4类已验证商业落地路径及2025关键拐点预警 从关键词匹配到语义意图理解 传统搜索引擎依赖倒排索引与TF-IDF加权,而AI搜索以多模…...