【go从入门到精通】for和for range的区别
作者简介:
高科,先后在 IBM PlatformComputing从事网格计算,淘米网,网易从事游戏服务器开发,拥有丰富的C++,go等语言开发经验,mysql,mongo,redis等数据库,设计模式和网络库开发经验,对战棋类,回合制,moba类页游,手游有丰富的架构设计和开发经验。 (谢谢你的关注)
————————————————
for 和 for range有什么区别?
for可以遍历array和slice,遍历key为整型递增的map,遍历string
for range可以完成所有for可以做的事情,却能做到for不能做的,包括遍历key为string类型的map并同时获取key和value,遍历channel
所以除此之外还有其他区别吗?我们来用几个代码块说明他们的区别不仅仅是上面的这几点
测试代码
让我们用切片和数组对for range i、for range v 和for i循环进行一些测试:
package main_testimport "testing"var intsSlice = []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100}
var intsArray = [...]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100}func BenchmarkForRangeI_Slice(b *testing.B) {sum := 0for n := 0; n < b.N; n++ {for i := range intsSlice {sum += intsSlice[i]}}
}func BenchmarkForRangeV_Slice(b *testing.B) {sum := 0for n := 0; n < b.N; n++ {for _, v := range intsSlice {sum += v}}
}func BenchmarkForI_Slice(b *testing.B) {sum := 0for n := 0; n < b.N; n++ {for i := 0; i < len(intsSlice); i++ {sum += intsSlice[i]}}
}func BenchmarkForRangeI_Array(b *testing.B) {sum := 0for n := 0; n < b.N; n++ {for i := range intsArray {sum += intsArray[i]}}
}func BenchmarkForRangeV_Array(b *testing.B) {sum := 0for n := 0; n < b.N; n++ {for _, v := range intsArray {sum += v}}
}func BenchmarkForI_Array(b *testing.B) {sum := 0for n := 0; n < b.N; n++ {for i := 0; i < len(intsArray); i++ {sum += intsArray[i]}}
}运行结果如下:
go test -bench=. for_test.go -benchtime 100000000x
goos: windows
goarch: amd64
cpu: 11th Gen Intel(R) Core(TM) i5-11400H @ 2.70GHz
BenchmarkForRangeI_Slice-12 100000000 33.87 ns/op
BenchmarkForRangeV_Slice-12 100000000 33.91 ns/op
BenchmarkForI_Slice-12 100000000 40.68 ns/op
BenchmarkForRangeI_Array-12 100000000 28.47 ns/op
BenchmarkForRangeV_Array-12 100000000 28.57 ns/op
BenchmarkForI_Array-12 100000000 28.40 ns/op
PASS
ok command-line-arguments 19.439s
正如我们所看到的,对于切片来说, for i循环比for range 循环要慢一些,但对于数组来说没有区别……但是为什么呢?
首先让我们看一下github.com上的切片结构:
type slice struct {
array unsafe.Pointer // 数组数据位于 (slice + 0) 地址len int // 数组长度位于 (slice + 8) 地址cap int // 数组容量位于 (slice + 16) 地址
}反汇编
然后,让我们通过运行go tool objdump命令深入了解反汇编程序,并尝试找出 Go 编译器为我们做了什么:
for 循环遍历切片:
sum := 0
for i := 0; i < len(intsSlice); i++ {sum += intsSlice[i]
}反汇编:
0x48dd34 XORL AX, AX
0x48dd36 XORL CX, CX
0x48dd38 JMP 0x48dd48 # jump to the 5-th instruction of the loop
######################## loop start ##########################
0x48dd3a LEAQ 0x1(AX), BX # store AX (index counter) + 1 in BX
0x48dd3e MOVQ 0(DX)(AX*8), DX # store quadword (8 bytes) from DX (data pointer) + AX (index counter) * 8 address to DX
0x48dd42 ADDQ DX, CX # add DX value to CX (our sum accumulator)
0x48dd45 MOVQ BX, AX # set BX (previously incremented AX by 1) value to AX (index counter)
0x48dd48 MOVQ main.intsSlice(SB), DX # store slice data pointer in DX (from static address)
0x48dd4f CMPQ AX, main.intsSlice+8(SB) # compare to slice data size (static address)
0x48dd56 JG 0x48dd3a # jump back to start if slice size is greater than AX (index counter)
######################## loop end ##########################
for range循环遍历slice:
sum := 0
for i := range intsSlice { sum += intsSlice[i]
}以及反汇编:
0x48dd34 MOVQ main.intsSlice(SB), CX # store slice data pointer in CX (from static address)
0x48dd3b MOVQ main.intsSlice+8(SB), DX # store slice data size in DX (from static address)
0x48dd42 XORL AX, AX
0x48dd44 XORL BX, BX
0x48dd46 JMP 0x48dd56 # jump to the 5-th instruction of the loop
######################## loop start ##########################
0x48dd48 LEAQ 0x1(AX), SI # store AX (index counter) + 1 in SI
0x48dd4c MOVQ 0(CX)(AX*8), DI # store quadword (8 bytes) from CX (data pointer) + AX (index counter) * 8 address to DI
0x48dd50 ADDQ DI, BX # add DI value to BX (our sum accumulator)
0x48dd53 MOVQ SI, AX # move SI (previously incremented AX by 1) value to AX (index counter)
0x48dd56 CMPQ DX, AX # compare DX (slice data size) to AX (index counter)
0x48dd59 JL 0x48dd48 # jump back to start if AX (index counter) is less than DX (slice size)
######################## loop end ##########################
因此,这里的主要区别在于,在for 循环的情况下,我们通过切片结构的静态地址访问切片数据指针,并在每次迭代时将其存储在某个通用寄存器中。比较指令被调用为切片数据大小值,我们也是通过切片结构静态地址访问该值。
但在for range循环的情况下,切片数据指针和大小都预先存储在通用寄存器中。所以这里我们每个周期丢失了一条指令。另外,我们不需要每次迭代时从 RAM 或 CPU 缓存中读取切片数据大小。
所以for range循环肯定比for i in slices更快,而且更“安全”。因为如果 slice 在循环迭代期间改变其大小和数据地址(例如来自另一个 goroutine),我们仍然会访问旧的“有效”数据。但当然我们不应该依赖这种行为并消除代码中的任何竞争条件;)
如果当查看for 循环数组:
sum := 0
for i := 0; i < len(intsArray); i++ {sum += intsArray[i]
}以及反汇编:
0x48dd34 XORL AX, AX
0x48dd36 XORL CX, CX
0x48dd38 JMP 0x48dd4f
######################## loop start ##########################
0x48dd3a LEAQ 0x1(AX), DX
0x48dd3e LEAQ main.intsArray(SB), BX # store the address of array in BX
0x48dd45 MOVQ 0(BX)(AX*8), SI
0x48dd49 ADDQ SI, CX
0x48dd4c MOVQ DX, AX
0x48dd4f CMPQ $0x64, AX # here the array size is pre determined at compile time
0x48dd53 JL 0x48dd3a
######################## loop end ##########################
for range循环遍历数组:
sum := 0
for i := range intsArray {sum += intsArray[i]
}以及反汇编:
0x48dd34 XORL AX, AX
0x48dd36 XORL CX, CX
0x48dd38 JMP 0x48dd4f
######################## loop start ##########################
0x48dd3a LEAQ 0x1(AX), DX
0x48dd3e LEAQ main.intsArray(SB), BX
0x48dd45 MOVQ 0(BX)(AX*8), SI
0x48dd49 ADDQ SI, CX
0x48dd4c MOVQ DX, AX
0x48dd4f CMPQ $0x64, AX
0x48dd53 JL 0x48dd3a
######################## loop end ##########################
我们会发现它们是完全相同的。在这两种情况下,我们每次迭代都会从内存中读取数组的地址并将其存储在 BX 寄存器中。但看起来效率不太高。
但这个怎么样:
sum := 0
for _, v := range intsArray { sum += v
}反汇编之后:
0x48dd49 LEAQ 0x28(SP), DI # 0x28(SP) is the address where our array will be located on the stack
0x48dd4e LEAQ main.intsArray(SB), SI
0x48dd55 NOPW 0(AX)(AX*1)
0x48dd5e NOPW
0x48dd60 MOVQ BP, -0x10(SP)
0x48dd65 LEAQ -0x10(SP), BP
0x48dd6a CALL 0x45e8a4 # runtime.duffcopy call
0x48dd6f MOVQ 0(BP), BP
0x48dd73 XORL AX, AX
0x48dd75 XORL CX, CX
0x48dd77 JMP 0x48dd84
######################## loop start ##########################
0x48dd79 MOVQ 0x28(SP)(AX*8), DX # so now we are accessing our data copy on the stack
0x48dd7e INCQ AX
0x48dd81 ADDQ DX, CX
0x48dd84 CMPQ $0x64, AX
0x48dd88 JL 0x48dd79
######################## loop end ##########################
由于某种原因,Go 决定将数组复制到堆栈......真的吗?这是作弊。
我尝试将数组大小增加到 1000,但该死的事情仍然认为将所有内容复制到堆栈会更好:)
0x48dd51 LEAQ 0x28(SP), DI # 0x28(SP) is the address where our array will be located on the stack
0x48dd56 LEAQ main.intsArray(SB), SI # store slice data pointer in SI (from static address)
0x48dd5d MOVL $0x3e8, CX # store slice data size (1000) in CX
0x48dd62 REP; MOVSQ DS:0(SI), ES:0(DI) # Move quadword from SI to DI, repeat CX times
0x48dd65 XORL AX, AX
0x48dd67 XORL CX, CX
0x48dd69 JMP 0x48dd76
######################## loop start ##########################
0x48dd6b MOVQ 0x28(SP)(AX*8), DX
0x48dd70 INCQ AX
0x48dd73 ADDQ DX, CX
0x48dd76 CMPQ $0x3e8, AX
0x48dd7c JL 0x48dd6b
######################## loop end ##########################
主要是使用场景不同
for可以遍历array和slice,遍历key为整型递增的map,遍历string
for range可以完成所有for可以做的事情,却能做到for不能做的,包括
遍历key为string类型的map并同时获取key和value,遍历channel.
我最好的猜测是,由于 Go 多线程特性,编译器决定预先将所有数据(因为我们无论如何都会复制每个值)复制到堆栈中,以在整个for range循环期间保持其完整性并获得一些性能。因此,只有基准测试才能完全反映我们算法性能的真相;)
好的,但是边界检查在哪里呢?panic 在哪里?正如我们所看到的,没有,因为 Go 足够聪明,可以区分根本不存在越界的情况。顺便说一句,它被称为边界检查消除(BCE)
所以对代码做一个小改动:
sum := 0
for i := 0; i < len(intsSlice)-1; i++ {sum += intsSlice[i+1]
}现在我们有了:
0x48dd38 XORL AX, AX
0x48dd3a XORL CX, CX
0x48dd3c JMP 0x48dd49
######################## loop start ##########################
0x48dd3e MOVQ 0x8(BX)(AX*8), DX
0x48dd43 ADDQ DX, CX
0x48dd46 MOVQ SI, AX
0x48dd49 MOVQ main.intsSlice+8(SB), DX # store slice data size in DX
0x48dd50 MOVQ main.intsSlice(SB), BX
0x48dd57 LEAQ -0x1(DX), SI
0x48dd5b NOPL 0(AX)(AX*1)
0x48dd60 CMPQ SI, AX
0x48dd63 JGE 0x48dd70 # jump out of the loop if finished
0x48dd65 LEAQ 0x1(AX), SI # SI will get AX (index counter) plus one
0x48dd69 CMPQ SI, DX # out of bounds checking
0x48dd6c JA 0x48dd3e # jump back to loop start if no out of bounds detected
######################## loop end ##########################
0x48dd6e JMP 0x48ddc1 # jump to the panic procedure call
...
0x48ddc1 MOVQ SI, AX
0x48ddc4 MOVQ DX, CX
0x48ddc7 CALL runtime.panicIndex(SB)
最后与 C gcc 编译器进行比较:
int64_t sum = 0;
for (int i = 0; i < sizeof(intsArray) / sizeof(intsArray[0]); i++)
{sum += intsArray[i];
}gcc -o main.exe -O3 main.c
objdump -S main.exe > main-c-for-i.asm100401689: lea 0x990(%rip),%rax # 100402020 <intsArray>; store intsArray address in rax
100401690: pxor %xmm0,%xmm0
100401694: lea 0x320(%rax),%rdx # store rax + 800 (array size is 100 * 8 bytes) in rdx (intsArray after end address)
10040169b: nopl 0x0(%rax,%rax,1)
######################## loop start ##########################
1004016a0: paddq (%rax),%xmm0 # adds 2 qwords from rax to xmm0 (128-bit register)
1004016a4: add $0x10,%rax # increments rax (current intsArray address) by 16 bytes
1004016a8: cmp %rax,%rdx # compare rax (current intsArray address) to (intsArray after end address)
1004016ab: jne 1004016a0 <main+0x20> # jump if current intsArray address not equals to intsArray after end address
######################## loop end ##########################
1004016ad: movdqa %xmm0,%xmm1 # copy accumulated 2 qwords to xmm1
1004016b1: psrldq $0x8,%xmm1 # shift xmm1 by 8 bytes right, so the 1-st qword will be at 2-nd qword place
1004016b6: paddq %xmm1,%xmm0 # add shifted 1-st qword from xmm1 to 2-nd qword of xmm0
1004016ba: movq %xmm0,%rax # copy final 2-nd qword to 64 bit rax, so here will be the final result
我们可以看到,循环中只有 4 条指令,并且累加执行速度快了 2 倍,因为使用了paddq指令(将第一个操作数中的2 个打包qword添加到第二个操作数中对应的 2 个打包qword)。
相关文章:

【go从入门到精通】for和for range的区别
作者简介: 高科,先后在 IBM PlatformComputing从事网格计算,淘米网,网易从事游戏服务器开发,拥有丰富的C,go等语言开发经验,mysql,mongo,redis等数据库,设计模…...

【C语言】【Leetcode】88. 合并两个有序数组
文章目录 一、题目二、思路再思考 一、题目 链接: link 二、思路 这题属于简单题,比较粗暴的做法就是直接比较两个数组,先把第二个数组加到第一个的后面,如何冒泡排序,这种方法简单粗暴但有效,可是不适用于这题&…...
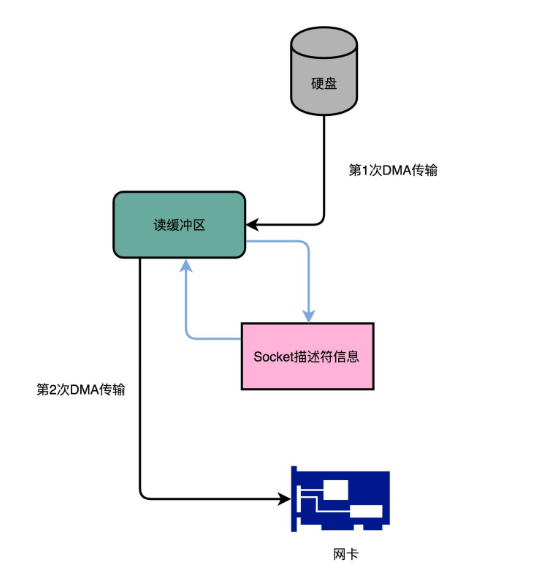
DMA控制器
前言 大家好,我是jiantaoyab,这是我作为学习笔记的25篇,本篇文章给大家介绍DMA。 无论 I/O 速度如何提升,比起 CPU,总还是太慢。如果我们对于 I/O 的操作,都是由 CPU 发出对应的指令,然后等待…...

SQLiteC/C++接口详细介绍sqlite3_stmt类(十)
返回:SQLite—系列文章目录 上一篇:SQLiteC/C接口详细介绍sqlite3_stmt类(九) 下一篇: SQLiteC/C接口详细介绍sqlite3_stmt类(十一) 38、sqlite3_column_value sqlite3_column_valu…...

Android 生成Excel文件保存到本地
本文用来记录在安卓中生成Excel文件并保存到本地操作,在网上找了好久,终于找到一个可以用的,虽然代码已经很老的,但亲测可用! 项目地址:https://github.com/wanganan/AndroidExcel 可以下载下来修改直接用…...

Hive-技术补充-ANTLR语法编写
一、导读 我们学习一门语言,或外语或编程语言,是不是都是要先学语法,想想这些语言有哪些相同点 1、中文、英语、日语......是不是都有 主谓宾 的规则 2、c、java、python、js......是不是都有 数据类型 、循环 等语法或数据结构 虽然人们在…...
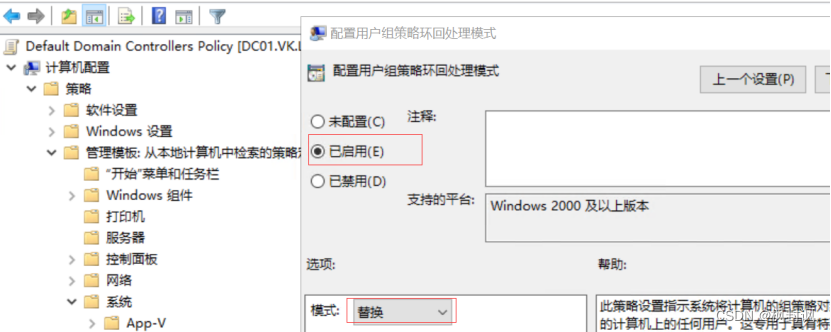
6.使用个人用户登录域控的成员服务器,如何防止个人用户账号的用户策略生效?
(1)需求: (2)实战配置步骤 第一步:创建新的策略-并编辑策略 第二步:将策略应用到服务器处在OU 第三步:测试 (1)需求: 比如域控,或者加入域的…...

模拟算法
例题一 算法思路: 纯模拟。从前往后遍历整个字符串,找到问号之后,就⽤ a ~ z 的每⼀个字符去尝试替换即 可。 例题二 解法(模拟 分情况讨论): 算法思路: 模拟 分情况讨论。 计算相邻两个…...
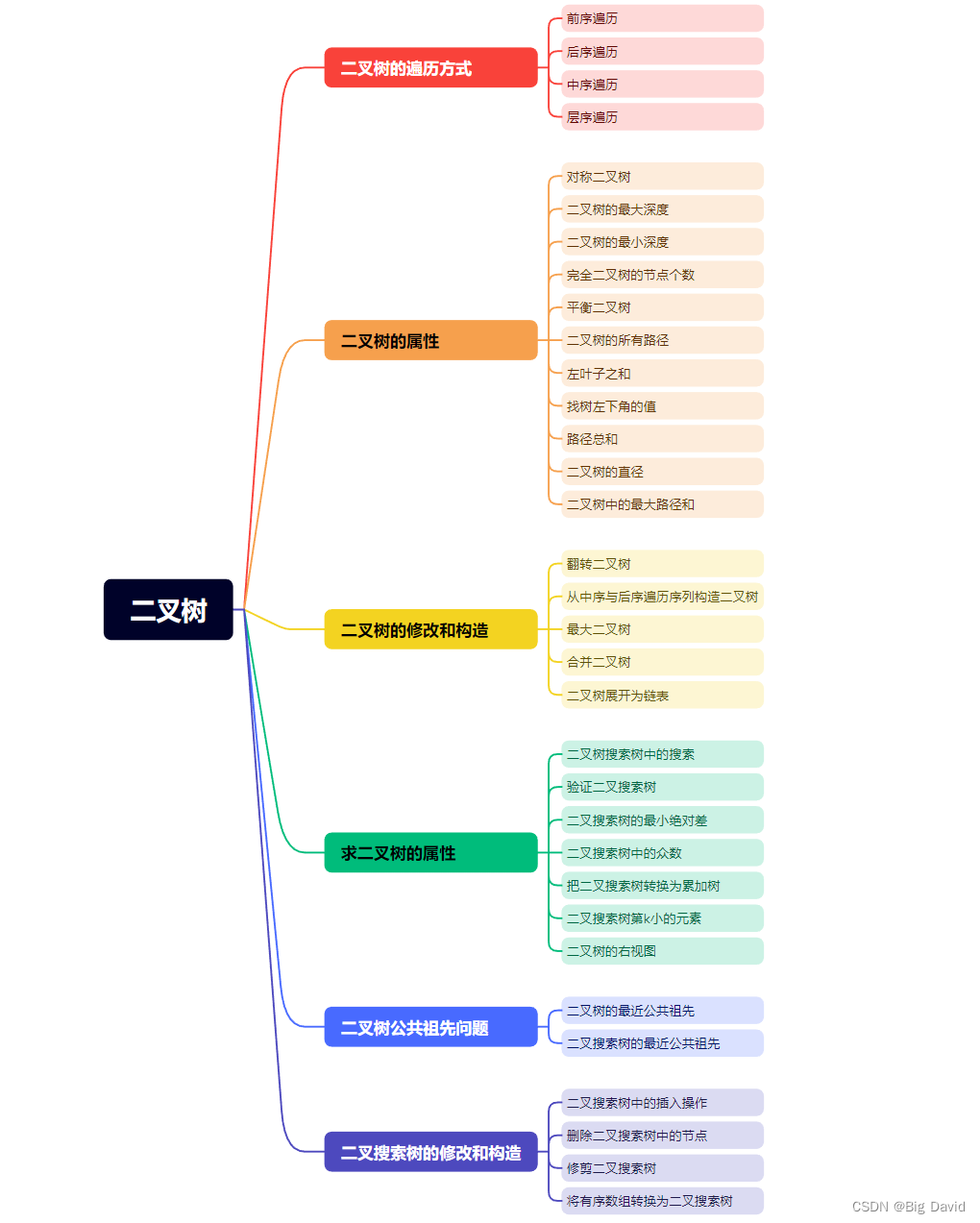
【数据结构刷题专题】—— 二叉树
二叉树 二叉树刷题框架 二叉树的定义: struct TreeNode {int val;TreeNode* left;TreeNode* right;TreeNode(int x) : val(x), left(NULL), right(NULL); };1 二叉树的遍历方式 【1】前序遍历 class Solution { public:void traversal(TreeNode* node, vector&…...

基于AWS云服务构建智能家居系统的最佳实践
在当今智能家居时代,构建一个安全、高性能、可扩展和灵活的智能家居系统已经成为许多公司的目标。亚马逊网络服务(AWS)提供了一系列云服务,可以帮助企业轻松构建和管理智能家居系统。本文将探讨如何利用AWS云服务构建一个智能家居系统,并分享相关的最佳实践。 系统架构概述 该…...

Java零基础-集合:Set接口
哈喽,各位小伙伴们,你们好呀,我是喵手。 今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一个人虽可以走的更快,但一群人可以走的更远。 我是一名后…...

数据结构与算法-排序算法
1.顺序查找 def linear_search(iters, val):for i, v in enumerate(iters):if v val:return ireturn 2.二分查找 # 升序的二分查找 def binary_search(iters, val):left 0right len(iters)-1while left < right:mid (left right) // 2if iters[mid] val:return mid…...
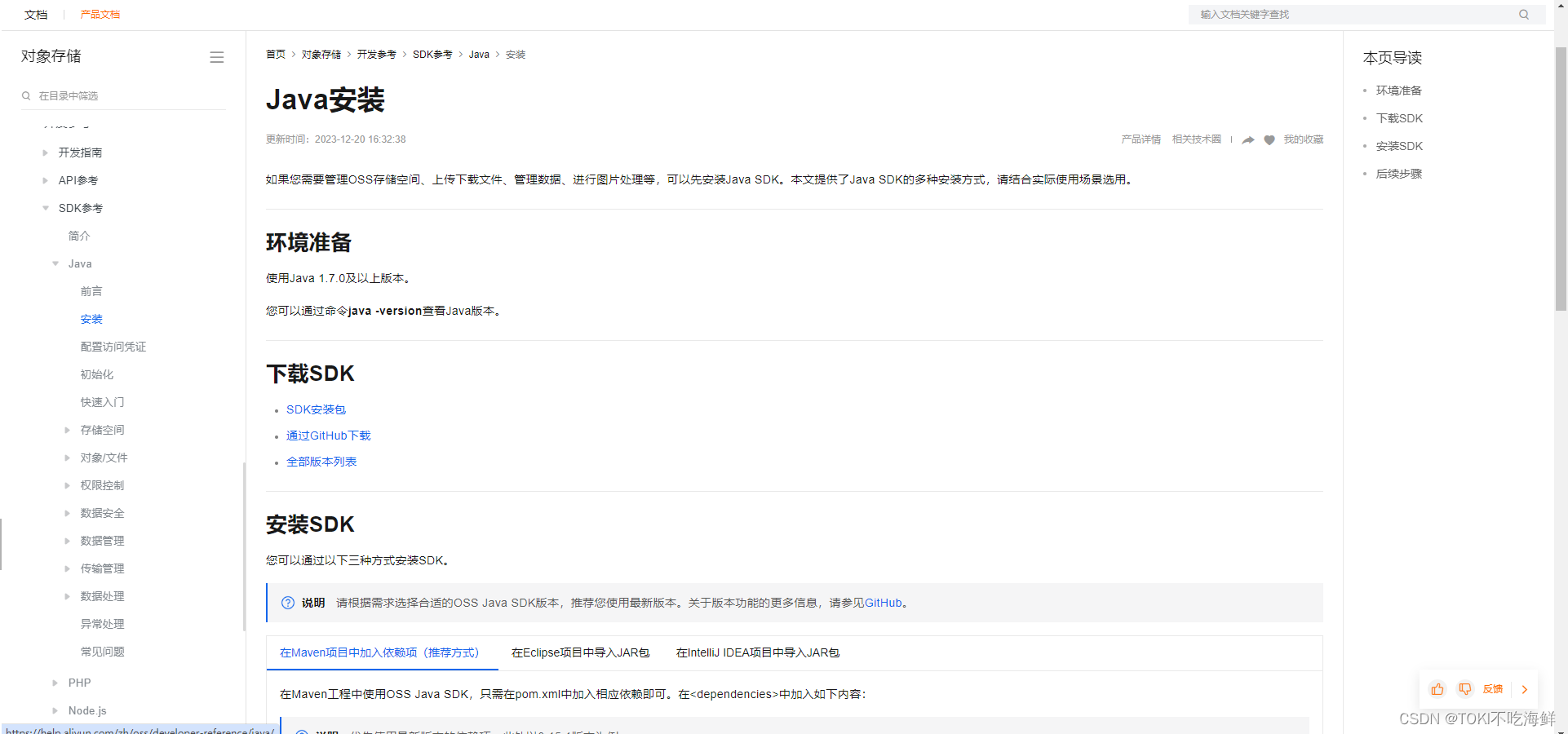
SpringBoot 文件上传(三)
之前讲解了如何接收文件以及如何保存到服务端的本地磁盘中: SpringBoot 文件上传(一)-CSDN博客 SpringBoot 文件上传(二)-CSDN博客 这节讲解如何利用阿里云提供的OSS(Object Storage Service)对象存储服务保存文件。…...

web渗透测试漏洞流程:红队目标信息收集之资产搜索引擎收集
web渗透测试漏洞流程 渗透测试信息收集---域名信息收集1.域名信息的科普1.1 域名的概念1.2 后缀分类1.3 多重域名的关系1.4 域名收集的作用1.5 DNS解析原理1.6 域名解析记录2. 域名信息的收集的方法2.1 基础方法-搜索引擎语法2.1.1 Google搜索引擎2.1.1.1 Google语法的基本使用…...

UI自动化_id 元素定位
## 导包selenium from selenium import webdriver import time1、创建浏览器驱动对象 driver webdriver.Chrome() 2、打开测试网站 driver.get("你公司的平台地址") 3、使浏览器窗口最大化 driver.maximize_window() 4、在用户名输入框中输入admin driver.find_ele…...

华为OD技术面算法题整理
LeetCode原题 简单 题目编号频次409. 最长回文串 - 力扣(LeetCode)3...

vmware虚拟机下ubuntu扩大磁盘容量
1、扩容: 可以直接在ubuntu setting界面里直接扩容,也可通过vmware命令,如下: vmware提供一个命令行工具,vmware-vdiskmanager.exe,位于vmware的安装目录下,比如 C:/Program Files/VMware/VMwar…...
秋招打卡算法题第一天
一年多没有刷过算法题了,已经不打算找计算机类工作了,但是思来想去,还是继续找吧。 1. 字符串最后一个单词的长度 public static void main(String[] args) {Scanner in new Scanner(System.in);while(in.hasNextInt()){String itemin.nextL…...

BC98 序列中删除指定数字
题目 描述 有一个整数序列(可能有重复的整数),现删除指定的某一个整数,输出删除指定数字之后的序列,序列中未被删除数字的前后位置没有发生改变。 数据范围:序列长度和序列中的值都满足 1≤�≤…...
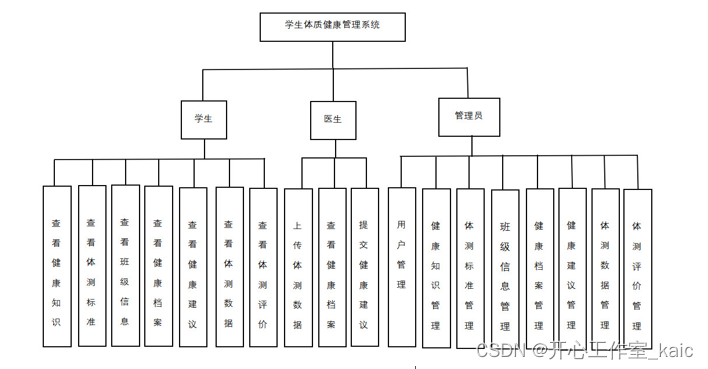
基于Java的学生体质健康管理系统的设计与实现(论文+源码)_kaic
摘 要 随着时代的进步,信息化也在逐渐深入融进我们生活的方方面面。其中也给健康管理带来了新的发展方向。通过对学生体质健康管理的研究与分析发现当下的管理系统还不够全面,系统的性能达不到使用者的要求。因此,本文结合Java的优势和流行性…...

阴阳师智能自动化脚本:5个步骤实现游戏任务全托管
阴阳师智能自动化脚本:5个步骤实现游戏任务全托管 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 还在为阴阳师中重复的日常任务感到厌倦吗?每天花费数小…...

【Sora 2视频后期处理黄金法则】:20年AI影像专家亲授5大不可绕过的帧级调优技巧
更多请点击: https://codechina.net 第一章:Sora 2视频后期处理的底层逻辑与帧级思维重构 Sora 2并非传统时间轴驱动的剪辑工具,其视频后期处理建立在扩散模型与隐空间帧序列联合优化的基础之上。每一帧不再作为孤立图像存在,而是…...

《彻底搞懂RAG技术:解决大模型幻觉,落地企业AI应用的核心方案》
随着大模型技术快速普及,众多企业纷纷入局AI落地,但绝大多数通用大模型在实际业务场景中都会面临两大致命难题:知识滞后与幻觉问题。通用大模型的训练数据存在固定时间截止点,无法获取最新行业数据、企业私有业务数据,…...

今天不用就过期:Gemini深度研究模式2024Q3权限变更预警——3类高价值功能即将对免费用户关闭
更多请点击: https://intelliparadigm.com 第一章:Gemini深度研究模式的核心价值与权限变更全景 Gemini深度研究模式(Deep Research Mode)是Google面向专业研究者与开发者推出的增强型推理能力范式,其核心价值在于将多…...

如何用NightX Client打造终极Minecraft 1.8.9体验?完整功能解析+新手教程 [特殊字符]
如何用NightX Client打造终极Minecraft 1.8.9体验?完整功能解析新手教程 🚀 【免费下载链接】NightX-Client Minecraft Forge 1.8.9 hacked client, Based on LiquidBounce 项目地址: https://gitcode.com/gh_mirrors/ni/NightX-Client NightX Cl…...

高级内核模式硬件信息欺骗工具:深度解析Windows驱动级设备指纹伪装技术
高级内核模式硬件信息欺骗工具:深度解析Windows驱动级设备指纹伪装技术 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER EASY-HWID-SPOOFER是一款基于内核模式的硬件信息…...

2026告别水印烦恼!免费图片去水印保姆级教程,从微信小程序到手机App一看就会
你是不是也遇到过这种抓狂的时刻?好不容易在小红书、抖音上看到一张绝美的壁纸、一个笑到岔气的表情包,兴致勃勃地保存下来,结果发现画面正中间或角落上,总趴着一个破坏美感的水印。想用来做PPT配图,水印太显眼&#x…...

【数据分析】基于matlab智慧城市温度与湿度分析系统【含Matlab源码 15555期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

基于离散阻抗与线性回归的嵌入式电池健康状态在线估计方法
1. 项目概述:当电池健康遇上“轻量级”机器学习在电动汽车、储能电站乃至消费电子领域,锂离子电池的健康状态(State of Health, SoH)都是一个绕不开的核心指标。它直接决定了设备的续航能力、安全边界乃至剩余价值。传统的BMS&…...
)
跟着 MDN 学CSS day_12 :(值与单位的技能测试与深入理解)
在学习 CSS 的过程中,值与单位是决定样式精确性和灵活性的关键知识。颜色值怎么写、字体大小用 px 还是 em、背景图怎么定位,这些看似基础的问题,实际上直接影响到页面的可维护性、响应式表现和视觉效果。MDN 的"Test your skills: Valu…...