吴恩达深度学习笔记:浅层神经网络(Shallow neural networks)3.1-3.5
目录
- 第一门课:神经网络和深度学习 (Neural Networks and Deep Learning)
- 第三周:浅层神经网络(Shallow neural networks)
- 3.1 神经网络概述(Neural Network Overview)
- 3.2 神经网络的表示(Neural Network Representation)
- 3.3 计算一个神经网络的输出(Computing a Neural Network's output)
- 3.4 多样本向量化(Vectorizing across multiple examples)
- 3.5 向 量 化 实 现 的 解 释 ( Justification for vectorized implementation)
第一门课:神经网络和深度学习 (Neural Networks and Deep Learning)
第三周:浅层神经网络(Shallow neural networks)
3.1 神经网络概述(Neural Network Overview)
本周你将学习如何实现一个神经网络。在我们深入学习具体技术之前,我希望快速的带你预览一下本周你将会学到的东西。如果这个视频中的某些细节你没有看懂你也不用担心,我们将在后面的几个视频中深入讨论技术细节。
现在我们开始快速浏览一下如何实现神经网络。上周我们讨论了逻辑回归,我们了解了这个模型(见图 3.1.1)如何与下面公式 3.1 建立联系。

接下来使用𝑧就可以计算出𝑎。我们将的符号换为表示输出𝑦^ ⟹ 𝑎 = 𝜎(𝑧),然后可以计算出 loss function 𝐿(𝑎, 𝑦)。
神经网络看起来是如下这个样子(图 3.1.2)。正如我之前已经提到过,你可以把许多sigmoid 单元堆叠起来形成一个神经网络。对于图 3.1.1 中的节点,它包含了之前讲的计算的两个步骤:首先通过公式 3.1 计算出值𝑧,然后通过𝜎(𝑧)计算值𝑎。
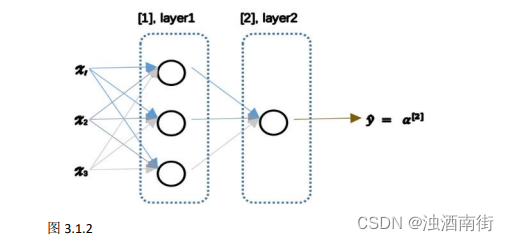
在这个神经网络(图 3.1.2)对应的 3 个节点,首先计算第一层网络中的各个节点相关的数 z [ 1 ] z^{[1]} z[1],接着计算 a [ 1 ] a^{[1]} a[1],在计算下一层网络同理; 我们会使用符号 [𝑚]表示第𝑚层网络中节点相关的数,这些节点的集合被称为第𝑚层网络。这样可以保证 [𝑚]不会和我们之前用来表示单个的训练样本的 (𝑖)(即我们使用表示第 i 个训练样本)混淆; 整个计算过程,公式如下: 公式 3.3:
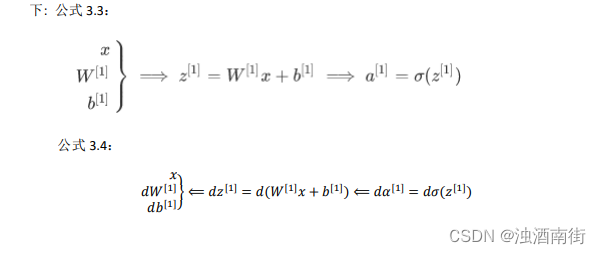
类似逻辑回归,在计算后需要使用计算,接下来你需要使用另外一个线性方程对应的参数计算 z [ 2 ] z^{[2]} z[2], 计算 a [ 2 ] a^{[2]} a[2],此时 a [ 2 ] a^{[2]} a[2]就是整个神经网络最终的输出,用 y ^ \hat{y} y^表示网络的输出。
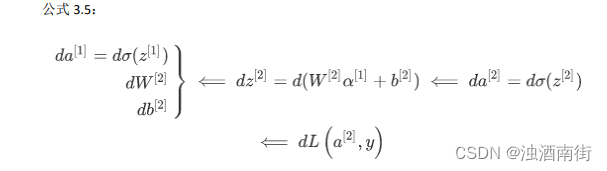
我知道这其中有很多细节,其中有一点非常难以理解,即在逻辑回归中,通过直接计算𝑧得到结果𝑎。而这个神经网络中,我们反复的计算𝑧和𝑎,计算𝑎和𝑧,最后得到了最终的输出 loss function。
你应该记得逻辑回归中,有一些从后向前的计算用来计算导数𝑑𝑎、𝑑𝑧。同样,在神经网络中我们也有从后向前的计算,看起来就像这样,最后会计算 d a [ 2 ] 、 d z [ 2 ] da^{[2]} 、dz^{[2]} da[2]、dz[2],计算出来之后,然后计算计算 d w [ 2 ] 、 d b [ 2 ] dw^{[2]}、db^{[2]} dw[2]、db[2] 等,按公式 3.4、3.5 箭头表示的那样,从右到左反向计算。
现在你大概了解了一下什么是神经网络,基于逻辑回归重复使用了两次该模型得到上述例子的神经网络。我清楚这里面多了很多新符号和细节,如果没有理解也不用担心,在接下来的视频中我们会仔细讨论具体细节。
那么,下一个视频讲述神经网络的表示。
3.2 神经网络的表示(Neural Network Representation)
先回顾一下我在上一个视频画几张神经网络的图片,在这次课中我们将讨论这些图片的具体含义,也就是我们画的这些神经网络到底代表什么。
我们首先关注一个例子,本例中的神经网络只包含一个隐藏层(图 3.2.1)。这是一张神经网络的图片,让我们给此图的不同部分取一些名字。
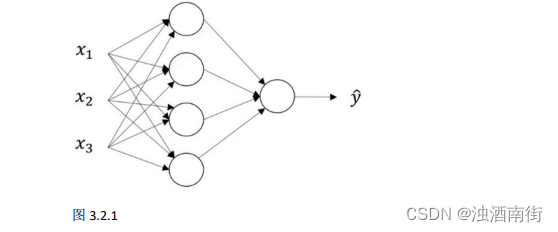
我们有输入特征 x 1 x_1 x1、 x 2 x_2 x2、 x 3 x_3 x3,它们被竖直地堆叠起来,这叫做神经网络的输入层。它包含了神经网络的输入;然后这里有另外一层我们称之为隐藏层(图 3.2.1 的四个结点)。待会儿我会回过头来讲解术语"隐藏"的意义;在本例中最后一层只由一个结点构成,而这个只有一个结点的层被称为输出层,它负责产生预测值。解释隐藏层的含义:在一个神经网络中,当你使用监督学习训练它的时候,训练集包含了输入𝑥也包含了目标输出𝑦,所以术语隐藏层的含义是在训练集中,这些中间结点的准确值我们是不知道到的,也就是说你看不见它们在训练集中应具有的值。你能看见输入的值,你也能看见输出的值,但是隐藏层中的东西,在训练集中你是无法看到的。所以这也解释了词语隐藏层,只是表示你无法在训练集中看到他们。
现在我们再引入几个符号,就像我们之前用向量𝑥表示输入特征。这里有个可代替的记号 a [ 0 ] a^{[0]} a[0]可以用来表示输入特征。𝑎表示激活的意思,它意味着网络中不同层的值会传递到它们后面的层中,输入层将𝑥传递给隐藏层,所以我们将输入层的激活值称为 a [ 0 ] a^{[0]} a[0];下一层即隐藏层也同样会产生一些激活值,那么我将其记作 a [ 1 ] a^{[1]} a[1],所以具体地,这里的第一个单元或结点我们将其表示为 a 1 [ 1 ] a_1^{[1]} a1[1],第二个结点的值我们记为 a 2 [ 1 ] a_2^{[1]} a2[1]以此类推。所以这里的是一个四维的向量如果写成 Python 代码,那么它是一个规模为 4x1 的矩阵或一个大小为 4 的列向量,如下公式,它是四维的,因为在本例中,我们有四个结点或者单元,或者称为四个隐藏层单元; 公式 3.7:
a [ 1 ] = [ a 1 [ 1 ] a 2 [ 1 ] a 3 [ 1 ] a 4 [ 1 ] ] a^{[1]} =\begin{bmatrix} a_1^{[1]}\\a_2^{[1]}\\a_3^{[1]}\\a_4^{[1]} \end{bmatrix} a[1]= a1[1]a2[1]a3[1]a4[1]
最后输出层将产生某个数值𝑎,它只是一个单独的实数,所以的 y ^ \hat{y} y^值将取为 a [ 2 ] a^{[2]} a[2]。这与逻辑回归很相似,在逻辑回归中,我们有 y ^ \hat{y} y^直接等于𝑎,在逻辑回归中我们只有一个输出层,所以我们没有用带方括号的上标。但是在神经网络中,我们将使用这种带上标的形式来明确地指出这些值来自于哪一层,有趣的是在约定俗成的符号传统中,在这里你所看到的这个例子,只能叫做一个两层的神经网络(图 3.2.2)。原因是当我们计算网络的层数时,输入层是不算入总层数内,所以隐藏层是第一层,输出层是第二层。第二个惯例是我们将输入层称为第零层,所以在技术上,这仍然是一个三层的神经网络,因为这里有输入层、隐藏层,还有输出层。但是在传统的符号使用中,如果你阅读研究论文或者在这门课中,你会看到人们将这个神经网络称为一个两层的神经网络,因为我们不将输入层看作一个标准的层。
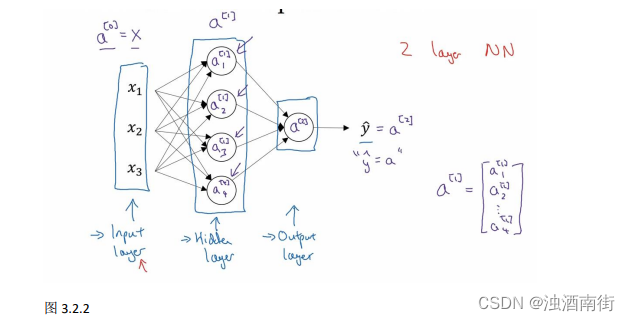
最后,我们要看到的隐藏层以及最后的输出层是带有参数的,这里的隐藏层将拥有两个参数W和b,我将给它们加上上标 [ 1 ] ( W [ 1 ] , b [ 1 ] ) ^{[1]}(W^{[1]} ,b^{[1]}) [1](W[1],b[1]),表示这些参数是和第一层这个隐藏层有关系的。之后在这个例子中我们会看到𝑊是一个 4x3 的矩阵,而𝑏是一个 4x1 的向量,第一个数字 4 源自于我们有四个结点或隐藏层单元,然后数字 3 源自于这里有三个输入特征,我们之后会更加详细地讨论这些矩阵的维数,到那时你可能就更加清楚了。相似的输出层也有一些与之关联的参数 W [ 2 ] W^{[2]} W[2]以及b^{[2]}。从维数上来看,它们的规模分别是 1x4 以及 1x1。1x4 是因为隐藏层有四个隐藏层单元而输出层只有一个单元,之后我们会对这些矩阵和向量的维度做出更加深入的解释,所以现在你已经知道一个两层的神经网络什么样的了,即它是一个只有一个隐藏层的神经网络。
在下一个视频中。我们将更深入地了解这个神经网络是如何进行计算的,也就是这个神经网络是怎么输入x,然后又是怎么得到 y ^ \hat{y} y^。
3.3 计算一个神经网络的输出(Computing a Neural Network’s output)
在上一节的视频中,我们介绍只有一个隐藏层的神经网络的结构与符号表示。在这节的视频中让我们了解神经网络的输出究竟是如何计算出来的。
首先,回顾下只有一个隐藏层的简单两层神经网络结构:
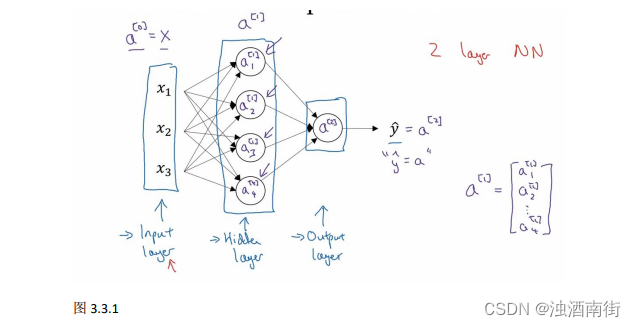
其中,𝑥表示输入特征,𝑎表示每个神经元的输出,𝑊表示特征的权重,上标表示神经网络的层数(隐藏层为 1),下标表示该层的第几个神经元。这是神经网络的符号惯例,下同。
神经网络的计算
关于神经网络是怎么计算的,从我们之前提及的逻辑回归开始,如下图所示。用圆圈表示神经网络的计算单元,逻辑回归的计算有两个步骤,首先你按步骤计算出𝑧,然后在第二步中你以 sigmoid 函数为激活函数计算𝑧(得出𝑎),一个神经网络只是这样子做了好多次重复计算。
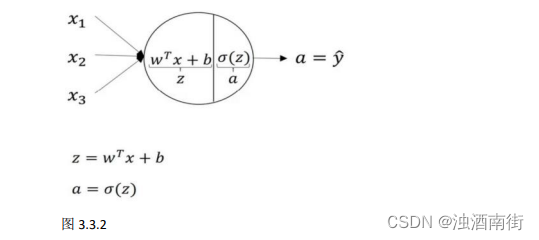
回到两层的神经网络,我们从隐藏层的第一个神经元开始计算,如上图第一个最上面的箭头所指。从上图可以看出,输入与逻辑回归相似,这个神经元的计算与逻辑回归一样分为两步,小圆圈代表了计算的两个步骤。
第一步,计算 z 1 [ 1 ] , z 1 [ 1 ] = w 1 [ 1 ] T x + b 1 [ 1 ] z_1^{[1]}, z_1^{[1]} = w_1^{[1]T}x+ b_1^{[1]} z1[1],z1[1]=w1[1]Tx+b1[1]。
第二步,通过激活函数计算 a 1 [ 1 ] , a 1 [ 1 ] = σ ( z 1 [ 1 ] ) a_1^{[1]}, a_1^{[1]} = σ(z_1^{[1]}) a1[1],a1[1]=σ(z1[1])。
隐藏层的第二个以及后面两个神经元的计算过程一样,只是注意符号表示不同,最终分别得到 a 2 [ 1 ] 、 a 3 [ 1 ] 、 a 4 [ 1 ] a_2^{[1]}、a_3^{[1]}、a_4^{[1]} a2[1]、a3[1]、a4[1],详细结果见下:
z 1 [ 1 ] = w 1 [ 1 ] T x + b 1 [ 1 ] , a 1 [ 1 ] = σ ( z 1 [ 1 ] ) z_1^{[1]} = w_1^{[1]T}x+ b_1^{[1]},a_1^{[1]} = σ(z_1^{[1]}) z1[1]=w1[1]Tx+b1[1],a1[1]=σ(z1[1])
z 2 [ 1 ] = w 2 [ 1 ] T x + b 2 [ 1 ] , a 2 [ 1 ] = σ ( z 2 [ 1 ] ) z_2^{[1]} = w_2^{[1]T}x+ b_2^{[1]},a_2^{[1]} = σ(z_2^{[1]}) z2[1]=w2[1]Tx+b2[1],a2[1]=σ(z2[1])
z 3 [ 1 ] = w 3 [ 1 ] T x + b 3 [ 1 ] , a 3 [ 1 ] = σ ( z 3 [ 1 ] ) z_3^{[1]} = w_3^{[1]T}x+ b_3^{[1]},a_3^{[1]} = σ(z_3^{[1]}) z3[1]=w3[1]Tx+b3[1],a3[1]=σ(z3[1])
z 4 [ 1 ] = w 4 [ 1 ] T x + b 4 [ 1 ] , a 4 [ 1 ] = σ ( z 4 [ 1 ] ) z_4^{[1]} = w_4^{[1]T}x+ b_4^{[1]},a_4^{[1]} = σ(z_4^{[1]}) z4[1]=w4[1]Tx+b4[1],a4[1]=σ(z4[1])
向量化计算
如果你执行神经网络的程序,用 for 循环来做这些看起来真的很低效。所以接下来我们要做的就是把这四个等式向量化。向量化的过程是将神经网络中的一层神经元参数纵向堆积起来,例如隐藏层中的𝑤纵向堆积起来变成一个(4,3)的矩阵,用符号𝑊[1]表示。另一个看待这个的方法是我们有四个逻辑回归单元,且每一个逻辑回归单元都有相对应的参数——向量𝑤,把这四个向量堆积在一起,你会得出这 4×3 的矩阵。因此,公式 3.8: z [ n ] = w [ n ] x + b [ n ] z^{[n]} =w^{[n]}x + b^{[n]} z[n]=w[n]x+b[n],公式 3.9: a [ n ] = σ ( z [ n ] ) a^{[n]} = σ(z^{[n])} a[n]=σ(z[n])
详细过程见下: 公式 3.10:
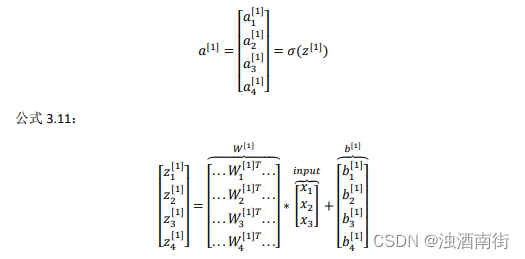
对于神经网络的第一层,给予一个输入𝑥,得到 a [ 1 ] a^{[1]} a[1],𝑥可以表示为 a [ 0 ] a^{[0]} a[0]。通过相似的衍生你会发现,后一层的表示同样可以写成类似的形式,得到 a [ 2 ] , y ^ = a [ 2 ] a^{[2]},\hat{y}= a^{[2]} a[2],y^=a[2],具体过程见公式 3.8、3.9。
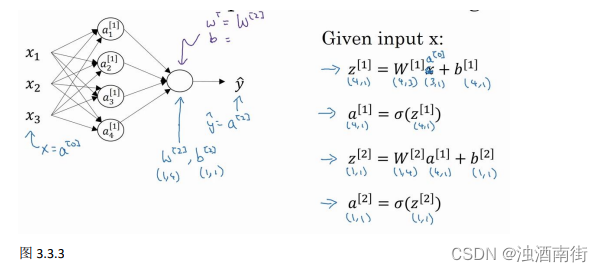
如上图左半部分所示为神经网络,把网络左边部分盖住先忽略,那么最后的输出单元就相当于一个逻辑回归的计算单元。当你有一个包含一层隐藏层的神经网络,你需要去实现以计算得到输出的是右边的四个等式,并且可以看成是一个向量化的计算过程,计算出隐藏层的四个逻辑回归单元和整个隐藏层的输出结果,如果编程实现需要的也只是这四行代码。
总结:通过本视频,你能够根据给出的一个单独的输入特征向量,运用四行代码计算出一个简单神经网络的输出。接下来你将了解的是如何一次能够计算出不止一个样本的神经网络输出,而是能一次性计算整个训练集的输出。
3.4 多样本向量化(Vectorizing across multiple examples)
在上一个视频,了解到如何针对于单一的训练样本,在神经网络上计算出预测值。
在这个视频,将会了解到如何向量化多个训练样本,并计算出结果。该过程与你在逻辑回归中所做类似。
逻辑回归是将各个训练样本组合成矩阵,对矩阵的各列进行计算。神经网络是通过对逻辑回归中的等式简单的变形,让神经网络计算出输出值。这种计算是所有的训练样本同时进行的,以下是实现它具体的步骤:
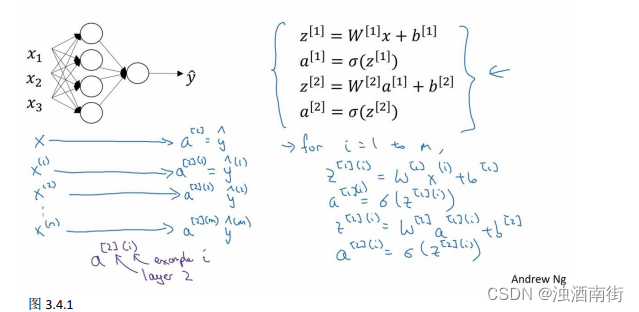
上一节视频中得到的四个等式。它们给出如何计算出 z [ 1 ] , a [ 1 ] , z [ 2 ] , a [ 2 ] z^{[1]},a^{[1]},z^{[2]},a^{[2]} z[1],a[1],z[2],a[2]。
对于一个给定的输入特征向量𝑋,这四个等式可以计算出 a [ 2 ] a^{[2]} a[2]等于 y ^ \hat{y} y^。这是针对于单一的训练样本。如果有𝑚个训练样本,那么就需要重复这个过程。
用第一个训练样本 x [ 1 ] x^{[1]} x[1]来计算出预测值 y ^ [ 1 ] \hat{y}^{[1]} y^[1],就是第一个训练样本上得出的结果。然后,用 x [ 2 ] x^{[2]} x[2]来计算出预测值 y ^ [ 2 ] \hat{y}^{[2]} y^[2],循环往复,直至用 x [ m ] x^{[m]} x[m]计算出 y ^ [ m ] \hat{y}^{[m]} y^[m]。用激活函数表示法,如上图左下所示,它写成 a [ 2 ] ( 1 ) 、 a [ 2 ] ( 2 ) a^{[2](1)}、a^{[2](2)} a[2](1)、a[2](2)和 a [ 2 ] ( m ) a^{[2](m)} a[2](m)。 【注】: a [ 2 ] ( i ) a^{[2](i)} a[2](i),(i)是指第i个训练样本而[2]是指第二层。
如果有一个非向量化形式的实现,而且要计算出它的预测值,对于所有训练样本,需要让i从 1 到m实现这四个等式:
z [ 1 ] ( i ) = w [ 1 ] ( i ) x ( i ) + b [ 1 ] ( i ) z^{[1](i)} =w^{[1](i)}x^{(i)} +b^{[1](i)} z[1](i)=w[1](i)x(i)+b[1](i)
a [ 1 ] ( i ) = σ ( z [ 1 ] ( i ) ) a^{[1](i)} = σ(z^{[1](i)} ) a[1](i)=σ(z[1](i))
z [ 2 ] ( i ) = w [ 2 ] ( i ) a [ 1 ] ( i ) + b [ 2 ] ( i ) z^{[2](i)} = w^{[2](i)}a^{[1](i)} +b^{[2](i)} z[2](i)=w[2](i)a[1](i)+b[2](i)
a [ 2 ] ( i ) = σ ( z [ 2 ] ( i ) ) a^{[2](i)} = σ(z^{[2](i)} ) a[2](i)=σ(z[2](i))
对于上面的这个方程中的 (𝑖),是所有依赖于训练样本的变量,即将(𝑖)添加到𝑥,𝑧和𝑎。如果想计算𝑚个训练样本上的所有输出,就应该向量化整个计算,以简化这列。
本课程需要使用很多线性代数的内容,重要的是能够正确地实现这一点,尤其是在深度学习的错误中。实际上本课程认真地选择了运算符号,这些符号只是针对于这个课程的,并且能使这些向量化容易一些。
所以,希望通过这个细节可以更快地正确实现这些算法。接下来讲讲如何向量化这些:
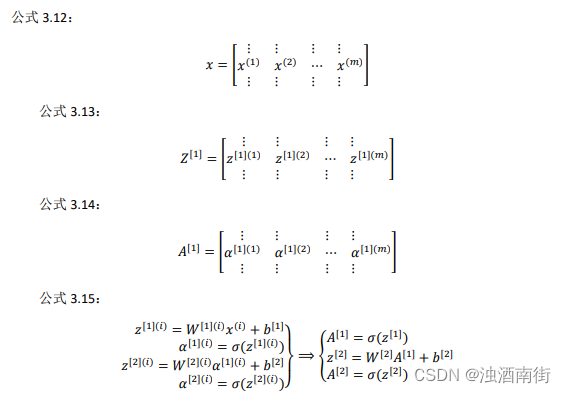
前一张幻灯片中的 for 循环是来遍历所有个训练样本。 定义矩阵𝑋等于训练样本,将它们组合成矩阵的各列,形成一个𝑛维或𝑛乘以𝑚维矩阵。接下来计算见公式 3.15:
以此类推,从小写的向量𝑥到这个大写的矩阵𝑋,只是通过组合𝑥向量在矩阵的各列中。同理, z [ 1 ] ( 1 ) , z [ 1 ] ( 2 ) z^{[1](1)},z^{[1](2)} z[1](1),z[1](2)等等都是 z [ 1 ] ( m ) z[1](m) z[1](m)的列向量,将所有𝑚都组合在各列中,就的到矩阵 Z [ 1 ] Z^{[1]} Z[1]。同理, a [ 1 ] ( 1 ) , z [ 1 ] ( 2 ) , … … , z [ 1 ] ( m ) a^{[1](1)},z^{[1](2)},……,z^{[1](m)} a[1](1),z[1](2),……,z[1](m)将其组合在矩阵各列中,如同从向量x到矩阵X,以及从向量z到矩阵Z一样,就能得到矩阵 A [ 1 ] A^{[1]} A[1]。同样的,对于 Z [ 2 ] Z^{[2]} Z[2]和 A [ 2 ] A^{[2]} A[2],也是这样得到。
这种符号其中一个作用就是,可以通过训练样本来进行索引。这就是水平索引对应于不同的训练样本的原因,这些训练样本是从左到右扫描训练集而得到的。
在垂直方向,这个垂直索引对应于神经网络中的不同节点。例如,这个节点,该值位于矩阵的最左上角对应于激活单元,它是位于第一个训练样本上的第一个隐藏单元。它的下一个值对应于第二个隐藏单元的激活值。它是位于第一个训练样本上的,以及第一个训练示例中第三个隐藏单元,等等。
当垂直扫描,是索引到隐藏单位的数字。当水平扫描,将从第一个训练示例中从第一个隐藏的单元到第二个训练样本,第三个训练样本……直到节点对应于第一个隐藏单元的激活值,且这个隐藏单元是位于这𝑚个训练样本中的最终训练样本。
从水平上看,矩阵𝐴代表了各个训练样本。从竖直上看,矩阵𝐴的不同的索引对应于不同的隐藏单元。
对于矩阵𝑍,𝑋情况也类似,水平方向上,对应于不同的训练样本;竖直方向上,对应不同的输入特征,而这就是神经网络输入层中各个节点。
神经网络上通过在多样本情况下的向量化来使用这些等式。在下一个视频中,将证明为什么这是一种正确向量化的实现。这种证明将会与逻辑回归中的证明类似。
3.5 向 量 化 实 现 的 解 释 ( Justification for vectorized implementation)
在上一个视频中,我们学习到如何将多个训练样本横向堆叠成一个矩阵𝑋,然后就可以推导出神经网络中前向传播(forward propagation)部分的向量化实现。
在这个视频中,我们将会继续了解到,为什么上一节中写下的公式就是将多个样本向量化的正确实现。
我们先手动对几个样本计算一下前向传播,看看有什么规律:
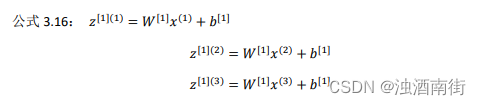
这里,为了描述的简便,我们先忽略掉 b [ 1 ] b^{[1]} b[1]后面你将会看到利用 Python 的广播机制,可以很容易的将 b [ 1 ] b^{[1]} b[1] 加进来。
现在 W [ 1 ] W^[1] W[1] 是一个矩阵, x ( 1 ) , x ( 2 ) , x ( 3 ) x^{(1)}, x^{(2)}, x^{(3)} x(1),x(2),x(3)都是列向量,矩阵乘以列向量得到列向量,下面将它们用图形直观的表示出来: 公式 3.17:
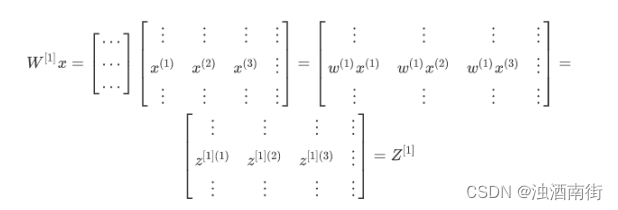
视频中,吴恩达老师很细心的用不同的颜色表示不同的样本向量,及其对应的输出。所以从图中可以看出,当加入更多样本时,只需向矩阵𝑋中加入更多列。
所以从这里我们也可以了解到,为什么之前我们对单个样本的计算要写成 z [ 1 ] ( i ) = W [ 1 ] x ( i ) + b [ 1 ] z[1](i) =W[1]x(i) + b[1] z[1](i)=W[1]x(i)+b[1]这种形式,因为当有不同的训练样本时,将它们堆到矩阵X的各列中,那么它们的输出也就会相应的堆叠到矩阵 Z [ 1 ] Z^{[1]} Z[1] 的各列中。现在我们就可以直接计算矩阵 Z [ 1 ] Z^{[1]} Z[1]加上 b [ 1 ] b^{[1]} b[1],因为列向量 b [ 1 ] b^{[1]} b[1] 和矩阵 Z [ 1 ] Z^{[1]} Z[1]的列向量有着相同的尺寸,而 Python 的广播机制对于这种矩阵与向量直接相加的处理方式是,将向量与矩阵的每一列相加。 所以这一节只是说明了为什么公式 Z [ 1 ] = W [ 1 ] X + b [ 1 ] Z^{[1]} = W^{[1]}X + b^{[1]} Z[1]=W[1]X+b[1]是前向传播的第一步计算的正确向量化实现,但事实证明,类似的分析可以发现,前向传播的其它步也可以使用非常相似的逻辑,即如果将输入按列向量横向堆叠进矩阵,那么通过公式计算之后,也能得到成列堆叠的输出。
最后,对这一段视频的内容做一个总结:
由公式 3.12、公式 3.13、公式 3.14、公式 3.15 可以看出,使用向量化的方法,可以不需要显示循环,而直接通过矩阵运算从𝑋就可以计算出 A [ 1 ] A^{[1]} A[1],实际上𝑋可以记为 A [ 0 ] A^{[0]} A[0],使用同样的方法就可以由神经网络中的每一层的输入 A [ i − 1 ] A^{[i−1]} A[i−1] 计算输出 A [ i ] A^{[i]} A[i]。其实这些方程有一定对称性,其中第一个方程也可以写成 Z [ 1 ] = W [ 1 ] A [ 0 ] + b [ 1 ] Z^{[1]}= W^{[1]}A^{[0]} + b^{[1]} Z[1]=W[1]A[0]+b[1],你看这对方程,还有这对方程形式其实很类似,只不过这里所有指标加了 1。所以这样就显示出神经网络的不同层次,你知道大概每一步做的都是一样的,或者只不过同样的计算不断重复而已。这里我们有一个双层神经网络,我们在下周视频里会讲深得多的神经网络,你看到随着网络的深度变大,基本上也还是重复这两步运算,只不过是比这里你看到的重复次数更多。在下周的视频中将会讲解更深层次的神经网络,随着层数的加深,基本上也还是重复同样的运算。
以上就是对神经网络向量化实现的正确性的解释,到目前为止,我们仅使用 sigmoid 函数作为激活函数,事实上这并非最好的选择,在下一个视频中,将会继续深入的讲解如何使用更多不同种类的激活函数。
相关文章:
吴恩达深度学习笔记:浅层神经网络(Shallow neural networks)3.1-3.5
目录 第一门课:神经网络和深度学习 (Neural Networks and Deep Learning)第三周:浅层神经网络(Shallow neural networks)3.1 神经网络概述(Neural Network Overview)3.2 神经网络的表示(Neural Network Representation…...

Linux设备驱动开发 - 三色LED呼吸灯分析
By: fulinux E-mail: fulinux@sina.com Blog: https://blog.csdn.net/fulinus 喜欢的盆友欢迎点赞和订阅! 你的喜欢就是我写作的动力! 目录 展锐UIS7885呼吸灯介绍呼吸灯调试方法亮蓝灯亮红灯亮绿灯展锐UIS7885呼吸灯DTS配置ump9620 PMIC驱动ump9620中的LED呼吸灯驱动LED的tr…...
开发者的瑞士军刀:DevToys
DevToys: 一站式开发者工具箱,打造高效创意编程体验,让代码生活更加得心应手!—— 精选真开源,释放新价值。 概览 不知道大家是否在windows系统中使用过PowerToys?这是微软研发的一项免费实用的系统工具套…...
【vue3.0】实现导出的PDF文件内容是红头文件格式
效果图: 编写文件里面的主要内容 <main><div id"report-box"><p>线索描述</p><p class"label"><span>线索发现时间:</span> <span>{{ detailInfoVal?.problem.createdDate }}</span></p><…...
)
【CSP试题回顾】202012-2-期末预测之最佳阈值(优化)
CSP-202012-2-期末预测之最佳阈值 关键点 1.map的遍历方式 map<int, int>occ0Num, occ1Num; for (auto it thetaSet.begin(); it ! thetaSet.end(); it) {num num occ0Num[*it] - occ1Num[*it];auto nextIt next(it); // 获取下一个迭代器if (num > maxNum &a…...
docker学习笔记 三-----docker安装部署
我使用的部署环境是centos 7.9 1、安装依赖工具 yum install -y yum-utils device-mapper-persistent-data lvm2 安装完成如下图 2、添加docker的软件信息源 yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo url地址为如…...

FastAPI+React全栈开发02 什么是FARM技术栈
Chapter01 Web Development and the FARM Stack 02 What is the FARM stack and how does it fit together? FastAPIReact全栈开发02 什么是FARM技术栈 It is important to understand that stacks aren’t really special, they are just sets of technologies that cover…...

C#程序结构详解
目录 背景: 一、C#程序的基本组成部分 二、C# Hello World示例 三、程序结构解析 四、编译与执行C#程序 五、总结 背景: 在学习C#编程语言的过程中,了解程序的基本结构是非常重要的。C#程序由多个组成部分构成,每个部分都有其特定的功能和作用。下面…...

linux 清理空间
1. 根目录下执行命令,查看每个目录下文件大小总和 rootvm10-88-88-3 /]# du -h --max-depth1 79M ./tmp 123M ./etc 4.0K ./media 4.0K ./srv 104M ./boot 5.3G ./var 0 ./sys 8.6M ./dev 196G ./usr 4.0K ./mnt 285M ./opt…...
C语言:给结构体取别名的4种方法
0 前言 在进行嵌入式开发的过程中,我们经常会见到typedef这个关键字,这个关键字的作用是给现有的类型取别名,在实际使用过程中往往是将一个复杂的类型名取一个简单的名字,便于我们的使用。就像我们给很熟的人取外号一样ÿ…...

今天聊聊Docker
在数字化时代,软件应用的开发和部署变得越来越复杂。环境配置、依赖管理、版本控制等问题给开发者带来了不小的挑战。而Docker作为一种容器化技术,正以其独特的优势成为解决这些问题的利器。本文将介绍Docker的基本概念、优势以及应用场景,帮…...

【C语言】结构体
个人主页点这里~ 结构体 一、结构体类型的声明1、结构的声明2、结构体变量的创建和初始化3、声明时的特殊情况4、自引用 二、结构体内存对齐1、对齐规则2、存在内存对齐的原因3、修改默认对齐数 三、结构体传参四、结构体实现位段 一、结构体类型的声明 我们在指针终篇中提到过…...
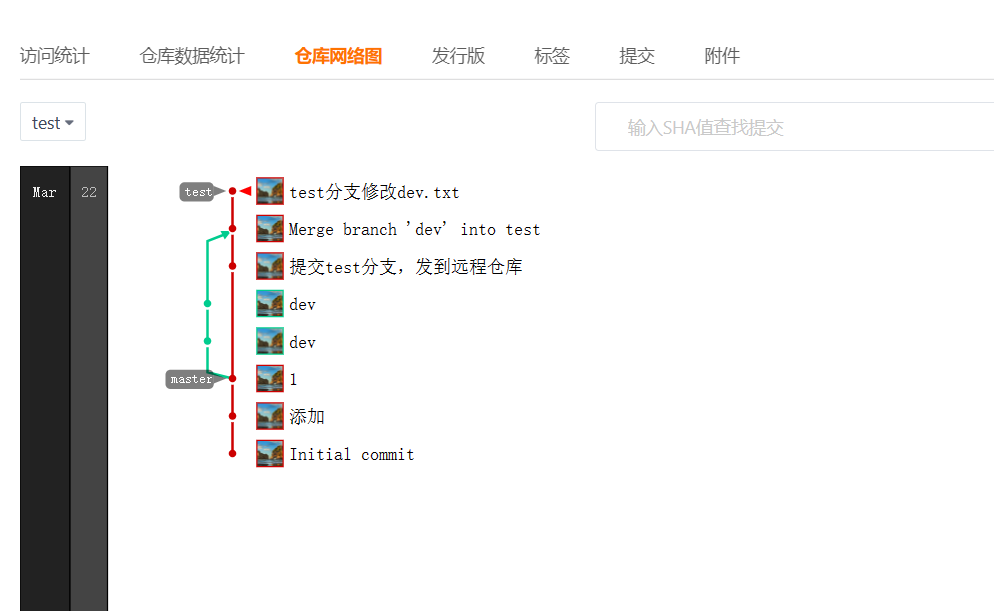
Git基础(24):分支回退
文章目录 前言放弃已修改的内容分支回退到指定commit 前言 将分支回退到之前的某个版本 开发中,可能开发某个功能不需要了,或者想要回退到之前历史的某个commit, 放弃后来修改的内容。 放弃已修改的内容 如果未提交,直接使用 …...

复试专业前沿问题问答合集1
复试专业前沿问题问答合集1 人工智能基础知识问答 Q1: 什么是人工智能(AI)? A1: 人工智能(AI)是计算机科学的一个分支,它涉及创建能够执行通常需要人类智能的任务的机器和软件。这些任务包括学习(获取信息并根据信息对其进行规则化以达到结论)、推理(使用规则达到近…...

C++标准库中提供的用于处理正则表达式的类std::regex
std 是 C 标准库的命名空间,包含了大量标准的 C 类、函数和对象。这些类和函数提供了广泛的功能,包括输入输出、容器、算法、字符串处理等。 通常,为了使用标准库中的对象和函数,需在代码中包含相应的头文件,比如 #in…...
.NET Core 服务实现监控可观测性最佳实践
前言 本次实践主要是介绍 .Net Core 服务通过无侵入的方式接入观测云进行全面的可观测。 环境信息 系统环境:Kubernetes编程语言:.NET Core ≥ 2.1日志框架:Serilog探针类型:ddtrace 接入方案 准备工作 DataKit 部署 DataK…...
AI基础知识扫盲
AI基础知识扫盲 AIGCLangchain--LangGraph | 新手入门RAG(Retrieval-Augmented Generation)检索增强生成fastGPT AIGC AIGC是一种新的人工智能技术,它的全称是Artificial Intelligence Generative Content,即人工智能生成内容。 …...
分布式系统面试全集通第一篇(dubbo+redis+zookeeper----分布式+CAP+BASE+分布式事务+分布式锁)
目录 分布式系统面试全集通第一篇什么是分布式?和微服务的区别什么是分布式分布式与微服务的区别 什么是CAP?为什么不能三者同时拥有分区容错性一致性可用性 Base理论了解吗基本可用软状态最终一致性 什么是分布式事务分布式事务有哪些常见的实现方案?2PC(Two Ph…...
Prompt-RAG:在特定领域中应用的革新性无需向量嵌入的RAG技术
论文地址:https://arxiv.org/ftp/arxiv/papers/2401/2401.11246.pdf 原文地址:https://cobusgreyling.medium.com/prompt-rag-98288fb38190 2024 年 3 月 21 日 虽然 Prompt-RAG 确实有其局限性,但在特定情况下它可以有效地替代传统向量嵌入 …...

线性代数 - 应该学啥 以及哪些可以交给计算机
AI很热,所以小伙伴们不免要温故知新旧时噩梦 - 线代。 (十几年前,还有一个逼着大家梦回课堂的风口,图形学。) 这个真的不是什么美好的回忆,且不说老师的口音,也不说教材的云山雾绕,单…...

QrazyBox终极指南:专业二维码修复工具拯救你的损坏二维码
QrazyBox终极指南:专业二维码修复工具拯救你的损坏二维码 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾因打印模糊、水渍污染或屏幕划痕导致的重要二维码无法扫描而焦急…...

【限时解锁】Gemini深度研究模式私有化部署方案:仅3家头部科研机构掌握的本地化推理链配置
更多请点击: https://codechina.net 第一章:Gemini深度研究模式的核心原理与能力边界 Gemini深度研究模式并非简单增强上下文长度的推理机制,而是一种面向复杂知识密集型任务的分层式认知架构。其核心原理在于动态构建“问题-证据-推理”三元…...

通过curl命令快速测试Taotoken不同模型的响应速度与效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken不同模型的响应速度与效果 对于习惯使用命令行工具的技术人员来说,curl是一个直接且高效…...

零基础玩转AI斗地主:DouZero_For_HappyDouDiZhu快速上手实战指南
零基础玩转AI斗地主:DouZero_For_HappyDouDiZhu快速上手实战指南 【免费下载链接】DouZero_For_HappyDouDiZhu 基于DouZero定制AI实战欢乐斗地主 项目地址: https://gitcode.com/gh_mirrors/do/DouZero_For_HappyDouDiZhu 想要在欢乐斗地主中体验AI智能辅助的…...

Taotoken 用量看板如何帮助个人开发者管理月度成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 用量看板如何帮助个人开发者管理月度成本 对于独立开发者而言,在项目开发中调用多个大模型 API 时࿰…...

高效拦截微信撤回消息:WeChatIntercept一站式解决方案
高效拦截微信撤回消息:WeChatIntercept一站式解决方案 【免费下载链接】WeChatIntercept 微信防撤回插件,一键安装,仅MAC可用,支持v3.7.0微信 项目地址: https://gitcode.com/gh_mirrors/we/WeChatIntercept 还在为微信聊天…...

3分钟快速解锁:如何让你的索尼相机显示中文菜单?
3分钟快速解锁:如何让你的索尼相机显示中文菜单? 【免费下载链接】OpenMemories-Tweak Unlock your Sony cameras settings 项目地址: https://gitcode.com/gh_mirrors/op/OpenMemories-Tweak 还在为索尼相机只能显示英文或日文菜单而烦恼吗&…...

独立开发者如何借助 Taotoken 一站式管理多个项目的 AI 调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助 Taotoken 一站式管理多个项目的 AI 调用 对于独立开发者而言,同时维护多个项目是常态。每个项目可…...

高效突破小红书反爬:7个实用User-Agent伪装技巧与实战指南
高效突破小红书反爬:7个实用User-Agent伪装技巧与实战指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接…...

新手快速上手使用 Python 调用 Taotoken 聚合大模型 API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手快速上手使用 Python 调用 Taotoken 聚合大模型 API 对于刚接触 Taotoken 的 Python 开发者而言,最直接的需求就是…...