Leetcode算法题笔记(2)
目录
- 图论
- 51. 岛屿数量
- 解法一
- 52. 腐烂的橘子
- 解法一
- 53. 课程表
- 解法一
- 54. 实现 Trie (前缀树)
- 解法一
- 回溯
- 55. 全排列
- 解法一
- 56. 子集
- 解法一
- 解法二
- 57. 电话号码的字母组合
- 解法一
- 58. 组合总和
- 解法一
- 解法二
- 59. 括号生成
- 解法一
- 解法二
- 60. 单词搜索
- 解法一
- 61. 分割回文串
- 解法一
- 二分查找
- 62. 搜索插入位置
- 解法一
- 63. 搜索二维矩阵
- 解法一
- 64. 在排序数组中查找元素的第一个和最后一个位置
- 解法一
- 65. 搜索旋转排序数组
- 解法一
图论
51. 岛屿数量
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。

解法一
深度优先搜索:对于矩阵中每一个‘1’点都将其看作三叉树(上下左右,其中一个为根生长方向,三个为子树方向)的节点,对每个为‘1’的节点进行深度优先搜索,搜索后就将其置为0,避免重复搜索。所寻找的岛屿则看作为一个全是‘1’的连通分量(连通树)。深度优先搜索了几次则代表有多少个岛屿。
class Solution {
private:void dfs(vector<vector<char>>& grid, int r, int c) {int nr = grid.size();int nc = grid[0].size();grid[r][c] = '0';if (r + 1 < nr && grid[r+1][c] == '1') dfs(grid, r + 1, c);if (r - 1 >= 0 && grid[r-1][c] == '1') dfs(grid, r - 1, c);if (c + 1 < nc && grid[r][c+1] == '1') dfs(grid, r, c + 1);if (c - 1 >= 0 && grid[r][c-1] == '1') dfs(grid, r, c - 1);}public:int numIslands(vector<vector<char>>& grid) {int nr = grid.size();if (!nr) return 0;int nc = grid[0].size();int num_islands = 0;for (int r = 0; r < nr; ++r) {for (int c = 0; c < nc; ++c) {if (grid[r][c] == '1') {++num_islands;dfs(grid, r, c);}}}return num_islands;}
};
52. 腐烂的橘子
在给定的 m x n 网格 grid 中,每个单元格可以有以下三个值之一:
值 0 代表空单元格;
值 1 代表新鲜橘子;
值 2 代表腐烂的橘子。
每分钟,腐烂的橘子 周围 4 个方向上相邻 的新鲜橘子都会腐烂。
返回 直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1 。

解法一
类似于上一题,以每个腐烂橘子为起点,进行广度优先搜索/深度优先搜索,确定每个橘子被腐蚀到的最短时间,之后再取全局最短时间即可。为了进行多个腐烂橘子一同开始向四周腐蚀,可采用一个队列按顺序将同一批次腐烂的橘子入队,这样就能保证全局最短时间一定是最后一个新鲜橘子被腐蚀的时间,例如全局最短时间如1111112222223333334444…。需注意,由于有的橘子可能永远不会被腐蚀,同时也需记录新鲜橘子剩余数量。
class Solution {int cnt;int dis[10][10];int dir_x[4]={0, 1, 0, -1};int dir_y[4]={1, 0, -1, 0};
public:int orangesRotting(vector<vector<int>>& grid) {queue<pair<int,int> >Q;memset(dis, -1, sizeof(dis));cnt = 0;int n=(int)grid.size(), m=(int)grid[0].size(), ans = 0;for (int i = 0; i < n; ++i){for (int j = 0; j < m; ++j){if (grid[i][j] == 2){Q.push(make_pair(i, j));dis[i][j] = 0;}else if (grid[i][j] == 1) cnt += 1;}}while (!Q.empty()){pair<int,int> x = Q.front();Q.pop();for (int i = 0; i < 4; ++i){int tx = x.first + dir_x[i];int ty = x.second + dir_y[i];if (tx < 0|| tx >= n || ty < 0|| ty >= m|| ~dis[tx][ty] || !grid[tx][ty]) continue;dis[tx][ty] = dis[x.first][x.second] + 1;Q.push(make_pair(tx, ty));if (grid[tx][ty] == 1){cnt -= 1;ans = dis[tx][ty];if (!cnt) break;}}}return cnt ? -1 : ans;}
};
53. 课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
例如,先修课程对 [0, 1] 表示:想要学习课程 0 ,你需要先完成课程 1 。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。

解法一
可以将问题转换为图论中寻找环的问题。其中两门课之间的依赖关系可以看作是图的有向边,每门课则为节点。可以通过深度优先搜索/广度优先搜索递归遍历节点,如果遍历过程中重新遍历到之前遍历过的节点,则表明存在环,无法完成课程;否则直至遍历完所有节点均未出现环,则表明可以完成课程。
class Solution {
private:vector<vector<int>> edges;vector<int> visited;bool valid = true;public:void dfs(int u) {visited[u] = 1;//表明当前节点已被遍历到for (int v: edges[u]) {if (visited[v] == 0) {dfs(v);if (!valid) {return;}}else if (visited[v] == 1) {valid = false;return;}}visited[u] = 2;//为了避免之前遍历过的地方在以另一个节点为起点时又重复遍历,浪费计算时间}bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {edges.resize(numCourses);visited.resize(numCourses);for (const auto& info: prerequisites) {edges[info[1]].push_back(info[0]);}//依次以每一个节点为起点进行深度优先搜索for (int i = 0; i < numCourses && valid; ++i) {if (!visited[i]) {//如果该起点未被dfs搜索过dfs(i);}}return valid;}
};
54. 实现 Trie (前缀树)
Trie(发音类似 “try”)或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
Trie() 初始化前缀树对象。
void insert(String word) 向前缀树中插入字符串 word 。
boolean search(String word) 如果字符串 word 在前缀树中,返回 true(即,在检索之前已经插入);否则,返回 false 。
boolean startsWith(String prefix) 如果之前已经插入的字符串 word 的前缀之一为 prefix ,返回 true ;否则,返回 false 。

解法一
根据前缀树的特点,每个节点可以看作为一个字母,从树的根节点向下遍历则得到的字母序列组为字符串。由于小写字母共26个,则每个节点有26种可能,可以用一个数组或者哈希表来进行映射下一个字母树节点在哪儿。此外,还需要一个变量来辅助判断从根节点到当前节点遍历字母组成的字符串是不是真正存储的字符串(有可能只是字符串的子串)。
class Trie {
private:vector<Trie*> children;bool isend;
public:Trie() : children(26),isend(false){}void insert(string word) {Trie* node = this;for(char si : word){si = si - 'a';if(node->children[si] == nullptr){node->children[si] = new Trie();}node = node->children[si];}node->isend = true;}bool search(string word) {Trie* node = this;for(char si : word){si = si-'a';if(node->children[si] == nullptr) return false;node = node->children[si];}if(node->isend == false) return false;else return true;}bool startsWith(string prefix) {Trie* node = this;for(char si : prefix){si = si-'a';if(node->children[si] == nullptr) return false;node = node->children[si];}return true;}
};/*** Your Trie object will be instantiated and called as such:* Trie* obj = new Trie();* obj->insert(word);* bool param_2 = obj->search(word);* bool param_3 = obj->startsWith(prefix);*/
回溯
55. 全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。

解法一
递归:由于数组长度不一,若想通过多层for循环依次列出所有解不现实。因此只能尝试递归。全排列相当于给n个格子里面填充元素。我们可以先确定第一个格子的值(共n种选择),之后再在剩余的n-1个值中选定第二个格子的值(共n-1中选择),依次如此直至n个格子填充满。我们可以将格子分成两个部分考虑,前一部分是已经确定的格子,后一部分是待排列的格子,因此后续我们只需要对后半部分再至执行全排列,依次递归。
class Solution {
public:vector<vector<int>> permute(vector<int>& nums) {vector<vector<int>> result;arrange(result,nums,0,nums.size());return result;}void arrange(vector<vector<int>> &result,vector<int> &nums,int first,int len){if(first == len){result.push_back(nums);return;}for(int i = first; i < len ; ++i){swap(nums[i],nums[first]);arrange(result,nums,first + 1,len);swap(nums[i],nums[first]);}}
};
56. 子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的
子集
(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集

解法一
按照数组顺序进行递归,每次递归选中一位数,再选下一位,下一位必须在第一位数的后面,这样就可以避免重复出现集合,例【1,2,3,4,5】,第一位选了2,则后续1,2就不可以选了,若第二位选了4,则后续1,2,3,4就不可以选了。由于每层递归可选的元素是多个,因此需要用一个循环考虑后续待选数的全部情况,并在递归返回时及时回溯。
class Solution {
public:vector<vector<int>> subsets(vector<int>& nums) {vector<vector<int>> result;vector<int> tmp;result.push_back({});subset(result,nums,tmp,0,nums.size());return result;}void subset(vector<vector<int>> &result,vector<int> &nums,vector<int> &tmp,int first,int len){if(first == len){return;}for(int i = first; i < len ; ++i){tmp.push_back(nums[i]);result.push_back(tmp);subset(result,nums,tmp,i+1,len);tmp.pop_back();}}
};
解法二
借用二进制数的思想,1表示选取该位数字,0表示不选取该位数字。这样n个元素的数组,每个元素位置上有两种可能,选与不选,即可表示所有情况。例如n=3,则子集的情况有000,001,010,011,100,101,110,111。采用递归的方法就是每层递归产生两次递归,一次选取该层索引的元素,一次为不选取该层索引的元素,直接跳到下一个索引处。
class Solution {
public:vector<int> t;vector<vector<int>> ans;void dfs(int cur, vector<int>& nums) {if (cur == nums.size()) {ans.push_back(t);return;}t.push_back(nums[cur]);dfs(cur + 1, nums);t.pop_back();dfs(cur + 1, nums);}vector<vector<int>> subsets(vector<int>& nums) {dfs(0, nums);return ans;}
};
57. 电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。


解法一
主体思想就是解析字符串,然后从每个数字对应的字符串中依次取一个字符出来进行组合。可采用递归的方法动态构建n层递归,每层选出对应数字字符串中的一个字符。
unordered_map<char, string> phoneMap{{'2', "abc"},{'3', "def"},{'4', "ghi"},{'5', "jkl"},{'6', "mno"},{'7', "pqrs"},{'8', "tuv"},{'9', "wxyz"}};
class Solution {
public:vector<string> letterCombinations(string digits) {vector<string> result;if(digits.empty()) return result;string tmp;sarrange(result,digits,tmp,0);return result;}void sarrange(vector<string> &result,string &digits,string &tmp,int index){if(index == digits.length()){result.push_back(tmp);}else{string s = phoneMap[digits[index]];for(char c : s) {tmp.push_back(c);sarrange(result,digits,tmp,index+1);tmp.pop_back();}} }
};
58. 组合总和
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。

解法一
由于每个数可以重复使用,则每次递归有两条途径,一个是继续使用当前的数,另一个用下一个数,若重复使用当前数,记得回溯。继续使用当前数的前提是累加和小于target或者target剩余值大于零。对于整体来说,如果超出了target要求范围则返回,等于target则需保存组合,此外,若所有的数都用完了,没有下一个元素了则也需要返回。
class Solution {
public:void dfs(vector<int>& candidates, int target, vector<vector<int>>& ans, vector<int>& combine, int idx) {if (idx == candidates.size()) {return;}if (target == 0) {ans.emplace_back(combine);return;}// 直接跳过dfs(candidates, target, ans, combine, idx + 1);// 选择当前数if (target - candidates[idx] >= 0) {combine.emplace_back(candidates[idx]);dfs(candidates, target - candidates[idx], ans, combine, idx);combine.pop_back();}}vector<vector<int>> combinationSum(vector<int>& candidates, int target) {vector<vector<int>> ans;vector<int> combine;dfs(candidates, target, ans, combine, 0);return ans;}
};
解法二
方法二也是递归穷举,但是该方法效率更高。其思想为每层递归依次调用当前及其后面所有待选参数,也就把重复选值包含进去了。
class Solution {
public:vector<int> cur;void DFS(int begin,int sum,vector<int>& candidates,int target,vector<vector<int>> &res){if (sum==target){res.push_back(cur);return;}if (sum>target){return;}for (int i = begin; i < candidates.size(); i++){cur.push_back(candidates[i]);DFS(i,sum+candidates[i],candidates,target,res);cur.pop_back();}}vector<vector<int>> combinationSum(vector<int>& candidates, int target) {vector<vector<int>> res;DFS(0,0,candidates,target,res);return res;}
};
59. 括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。

解法一
暴力破解:递归列出所有可能情况。每层递归产生两种递归调用,一个是继续添加‘ ( ’,一个是继续添加‘ ) ’,递归终止条件为最终组合的字符串长度与2n相同。但是在终止条件中,需要判断该组合是否满足有效括号组合的要求,因此需要调用一个函数判断括号组合是否有效,即顺序遍历字符串时,正括号的数量必须时刻大于等于反括号的数量,但不能超过n,且最终两种括号总数相等,若不满足即返回false。
class Solution {
public:vector<string> generateParenthesis(int n) {vector<string> result;string s;dfs(result,s,n*2);return result;}void dfs(vector<string> &result,string &s,int n){if(n == 0){if(valid(s)){result.push_back(s);}return;}s.push_back('(');dfs(result,s,n-1);s.pop_back();s.push_back(')');dfs(result,s,n-1);s.pop_back();}bool valid(const string& str) {int balance = 0;for (char c : str) {if (c == '(') {++balance;} else {--balance;}if (balance < 0) {return false;}}return balance == 0;}
};
解法二
解法一中有很多无效的组合被递归生成,且还需要花费时间进行筛查。解法二采用在递归过程中避免无效组合生成(例如“)))(((”)。将括号组合有效的特性引入递归过程中,采用两个变量记录分别正括号与反括号的数量,保证当正括号数量小于n时,可以先调用递归继续存入正括号;当反括号数量小于正括号数量时,才能调用递归加入反括号。由于有的时候既可以加正括号,也可以加反括号,因此一层递归应该最多尝试调用两种递归,且需要回溯。递归终止条件即为最终括号组合的长度等于2n,才将
当前组合放入最终结果中。
class Solution {void backtrack(vector<string>& ans, string& cur, int open, int close, int n) {if (cur.size() == n * 2) {ans.push_back(cur);return;}if (open < n) {cur.push_back('(');backtrack(ans, cur, open + 1, close, n);cur.pop_back();}if (close < open) {cur.push_back(')');backtrack(ans, cur, open, close + 1, n);cur.pop_back();}}
public:vector<string> generateParenthesis(int n) {vector<string> result;string current;backtrack(result, current, 0, 0, n);return result;}
};
60. 单词搜索
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
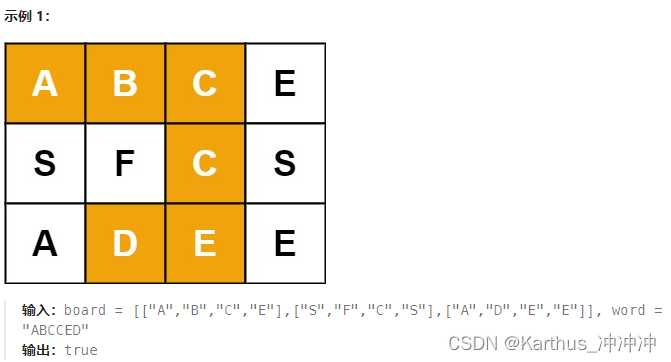
解法一
采用深度优先搜索的方法,以每个网格点为搜索起点,依次向上下左右开始搜索(注意边界)。此外,由于网格中的元素不能重复使用,因此还需要一个数组标记已经使用过的网格,当递归返回时,使用标记需要回溯。
class Solution {vector<vector<int>> copyboard;
public:bool exist(vector<vector<char>>& board, string word) {int row = board.size();int col = board[0].size();copyboard = vector<vector<int>>(row,vector<int>(col, 0));for(int i = 0; i < row; ++i){for(int j = 0; j < col; ++j){if(dfs(board,word,i,j,0)) return true;}}return false;}bool dfs(vector<vector<char>>& board, string &word, int row, int col, int index){// if(index == word.size()) return true;if(word[index] != board[row][col]) return false;if(index == word.size()-1) return true;int nr = board.size();int nc = board[0].size();bool res = false;copyboard[row][col] = 1;if(row + 1 < nr && !copyboard[row+1][col]) res = res || dfs(board,word,row+1,col,index+1);if(row - 1 >= 0 && !copyboard[row-1][col]) res = res || dfs(board,word,row-1,col,index+1);if(col + 1 < nc && !copyboard[row][col+1]) res = res || dfs(board,word,row,col+1,index+1);if(col - 1 >= 0 && !copyboard[row][col-1]) res = res || dfs(board,word,row,col-1,index+1);copyboard[row][col] = 0;return res;}
};
61. 分割回文串
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。

解法一
回溯+记忆搜索:找的组合是每个元素均为回文串,通过递归,依次搜索所有可能的字符串。当s前一部分已经被分割为若干个回文串后,后续则只需要搜寻如何把后部分的字符串分割为若干个子回文串,是一个明显的递归过程。递归过程主要为一步一步的切割子串,切割出一个回文串后,下次就从这个回文串之后的部分再切割一个回文串出来,循环往复。每次选定一个切割点,切割点以前的字符串为已经分割好的无需再次考虑,之后需递归尝试切割后半部分每个可能的切割点,所以一层递归中可能需要尝试生成多个递归。例如“aacdef”,若“aa”已被切割除去了,则下层递归则需要尝试先切割出“c”,或“cd”,或“cde”,或“cdef”,判断每种切割的子串是不是回文串,如果不是则继续尝试下一种切割。由于后三种情况均不满足回文串,则下一层递归表明“aa” “c”已经被切割出去,现在要递归考虑“def”怎么切,依次类推。注意一层递归中某种切割方式成功后一定要回溯,因为要尝试下一种切割方法。
由于每次都需要判断s(i,j)是不是回文串,可能会有多次重复计算。因此采用一个n*n的数组,记录每个s(i,j)是不是回文串(例如“abcba”),如果s(i+1,j-1)是回文串(“bcb”),则再只需判断s[i]与s[j]是否相等。
class Solution {
private:vector<vector<int>> f;vector<vector<string>> ret;vector<string> ans;int n;public:void dfs(const string& s, int i) {if (i == n) {ret.push_back(ans);return;}for (int j = i; j < n; ++j) {if (isPalindrome(s, i, j) == 1) {ans.push_back(s.substr(i, j - i + 1));dfs(s, j + 1);ans.pop_back();}}}// 记忆化搜索中,f[i][j] = 0 表示未搜索,1 表示是回文串,-1 表示不是回文串int isPalindrome(const string& s, int i, int j) {if (f[i][j]) {return f[i][j];}if (i >= j) {//当i=8,j=9,则后面return下次调用i=9,j=8,i比j大的情况为回文串搜索过头了,需要及时终止return f[i][j] = 1;}return f[i][j] = (s[i] == s[j] ? isPalindrome(s, i + 1, j - 1) : -1);}vector<vector<string>> partition(string s) {n = s.size();f.assign(n, vector<int>(n));dfs(s, 0);return ret;}
};二分查找
62. 搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。

解法一
由于数组有序且需要时间复杂度为 O(log n) ,可以采用二分查找算法。
class Solution {
public:int searchInsert(vector<int>& nums, int target) {int top = nums.size()-1,low = 0;int mid;while(low <= top){mid = ((top - low) >> 1) + low ;// mid = (top + low) / 2;if(nums[mid] < target){low = mid + 1;}else{top = mid - 1;} }return low;}
};
63. 搜索二维矩阵
给你一个满足下述两条属性的 m x n 整数矩阵:
每行中的整数从左到右按非严格递增顺序排列。
每行的第一个整数大于前一行的最后一个整数。
给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则,返回 false 。

解法一
将二维数组想象成一个长一些的一维数组,依然使用上一题的二分查找法,只不过在比较中间元素值需要索引二维数组的值,直接将mid数值转换为第i行第j列的元素。
class Solution {
public:bool searchMatrix(vector<vector<int>>& matrix, int target) {int m = matrix.size();int n = matrix[0].size();int top = m*n - 1,low = 0;int mid;int j = 0,i = 0;while(low <= top){mid = ((top - low) >> 1) + low ;// mid = (top + low) / 2;i = mid / n;j = mid % n;if(matrix[i][j] == target) return true;if(matrix[i][j] < target){low = mid + 1;}else{top = mid - 1;} }return false;}
};
64. 在排序数组中查找元素的第一个和最后一个位置
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。

解法一
该题目明显是考察当有多个重复元素出现时,二分查找法如何探测重复元素的边界。由二分查找的原理可知,如果target元素存在,那么必有至少依次mid所指元素等于target。后续待求解的问题则是,mid == target后,low和top应该怎么移动。当循环条件为low <= top时,合法区间为闭区间【low,top】。
当mid == target时,如果top向左移动,那么后续mid肯定也会向左移动,此时就是在尝试探测重复元素的左边界。由于 mid最终可能会移动到比target小的元素上,且该过程一定是top向左移才导致mid也向左移至小元素上,则我们当mid == target时需保存一下上次mid所指的位置,当不满足条件的时候保存的上次mid的地方就是第一个target元素出现在最左侧的位置。
同理, 当mid == target时,如果low向右移动,那么后续mid肯定也会向右移动,此时就是在尝试探测重复元素的右边界。由于 mid最终可能会移动到比target大的元素上,且该过程一定是top向左移才导致mid也向右移至大元素上,则我们当mid == target时需保存一下上次mid所指的位置,当不满足条件的时候保存的上次mid的地方就是第一个target元素出现在最左右侧的位置。
但是由于上述两种情况,保存mid结果时出现的条件不一致,因此造成代码无法有效复用。通过找寻规律方法,可以发现无非就是当mid == target时,保存结果的代码是写在“low = mid + 1”旁边还是“top = mid - 1”旁边。这个可以通过nums[mid] > target还是nums[mid] >= target来调控。由于代码是固定的,如果将结果保存总是写在“top = mid - 1”的旁边,当条件为nums[mid] > target时,找到target后mid会右移(low = mid + 1),直到移到大于target的元素上(此时,low = mid = top,下一次top-1就退出循环了),则执行一次ans = mid,ans每次指向的为最右边的第一个重复元素的下一个元素位置。当条件为nums[mid] >= target时,如果将结果保存还是写在“top = mid - 1”的旁边,找到target后mid会左移,直到移到小于target的元素上(此时,low=mid=top,下一次执行low-1就要退出了),则上一次top = mid - 1后保存的ans = mid为最左边第一个重复元素的位置。
class Solution {
public:int binarySearch(vector<int>& nums, int target, bool lower) {int left = 0, right = (int)nums.size() - 1, ans = (int)nums.size();while (left <= right) {int mid = (left + right) / 2;if (nums[mid] > target || (lower && nums[mid] >= target)) {//通过lower来控制最终执行为大于还是大于等于right = mid - 1;ans = mid;} else {left = mid + 1;}}return ans;}vector<int> searchRange(vector<int>& nums, int target) {int leftIdx = binarySearch(nums, target, true);//后续执行大于等于条件,ans返回为最左边第一个target重复元素int rightIdx = binarySearch(nums, target, false) - 1;//执行大于条件,ans返回为最右边第一个target重复元素下一个元素位置if (leftIdx <= rightIdx && nums[leftIdx] == target && nums[rightIdx] == target) {//leftIdx <= rightIdx是为了保证当搜索数组为[]时,leftIdx为0,rightIdx为-1,索引无效return vector<int>{leftIdx, rightIdx};} return vector<int>{-1, -1};}
};
65. 搜索旋转排序数组
整数数组 nums 按升序排列,数组中的值 互不相同 。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], …, nums[n-1], nums[0], nums[1], …, nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题。

解法一
虽然数组不是完全有序,但是是前一部分有序和后一部分有序,且后一部分永远小于前一部分,可以利用这些特点修改二分查找法进行查找。
当mid 小于 nums[0]时,此时mid处于后半部分有序数组中。若target < nums[mid],则target掉入范围【nums[0],nums[mid-1]】,则top = mid-1;若target > nums[mid],则搜索范围有两个区间【nums[0],nums[mid-1]】和【nums[mid+1],nums[n-1]】,其一是当target <= nums[n-1]时,则low=mid+1,其二时当target>nums[n-1]时,则top=mid-1 ;
当mid大于等于nums[0]时,此时mid处于前半部分有序数组中,与上同理推导。
class Solution {
public:int search(vector<int>& nums, int target) {int n = nums.size();int top = n - 1,low = 0;while(low <= top){int mid = ((top - low) >> 1) + low ;// mid = (top + low) / 2;if(nums[0] <= nums[mid]){if(target < nums[mid] && target >= nums[0]){top = mid - 1;}else{low = mid + 1;}}else{if(target > nums[mid] && target <= nums[n - 1]){low = mid + 1;}else{top = mid - 1;}}if (nums[mid] == target) return mid;}return -1;}
};
相关文章:
Leetcode算法题笔记(2)
目录 图论51. 岛屿数量解法一 52. 腐烂的橘子解法一 53. 课程表解法一 54. 实现 Trie (前缀树)解法一 回溯55. 全排列解法一 56. 子集解法一解法二 57. 电话号码的字母组合解法一 58. 组合总和解法一解法二 59. 括号生成解法一解法二 60. 单词搜索解法一 61. 分割回文串解法一 …...
二手车交易网站|基于JSP技术+ Mysql+Java+ B/S结构的二手车交易网站设计与实现(可运行源码+数据库+设计文档)
推荐阅读100套最新项目 最新ssmjava项目文档视频演示可运行源码分享 最新jspjava项目文档视频演示可运行源码分享 最新Spring Boot项目文档视频演示可运行源码分享 2024年56套包含java,ssm,springboot的平台设计与实现项目系统开发资源(可…...

lora-scripts 训练IP形象
CodeWithGPU | 能复现才是好算法CodeWithGPU | GitHub AI算法复现社区,能复现才是好算法https://www.codewithgpu.com/i/Akegarasu/lora-scripts/lora-trainstable-diffusion打造自己的lora模型(使用lora-scripts)-CSDN博客文章浏览阅读1.1k次…...

Acwing 503. 借教室
Problem: 503. 借教室 文章目录 思路解题方法复杂度Code 思路 这是一个二分查找问题。我们需要找到最大的借教室数量,使得每个教室的借用时间不超过其可用时间。我们可以通过二分查找来找到这个最大的借教室数量。 解题方法 我们首先对所有的借教室请求按照结束时间…...
吴恩达深度学习笔记:浅层神经网络(Shallow neural networks)3.1-3.5
目录 第一门课:神经网络和深度学习 (Neural Networks and Deep Learning)第三周:浅层神经网络(Shallow neural networks)3.1 神经网络概述(Neural Network Overview)3.2 神经网络的表示(Neural Network Representation…...

Linux设备驱动开发 - 三色LED呼吸灯分析
By: fulinux E-mail: fulinux@sina.com Blog: https://blog.csdn.net/fulinus 喜欢的盆友欢迎点赞和订阅! 你的喜欢就是我写作的动力! 目录 展锐UIS7885呼吸灯介绍呼吸灯调试方法亮蓝灯亮红灯亮绿灯展锐UIS7885呼吸灯DTS配置ump9620 PMIC驱动ump9620中的LED呼吸灯驱动LED的tr…...
开发者的瑞士军刀:DevToys
DevToys: 一站式开发者工具箱,打造高效创意编程体验,让代码生活更加得心应手!—— 精选真开源,释放新价值。 概览 不知道大家是否在windows系统中使用过PowerToys?这是微软研发的一项免费实用的系统工具套…...
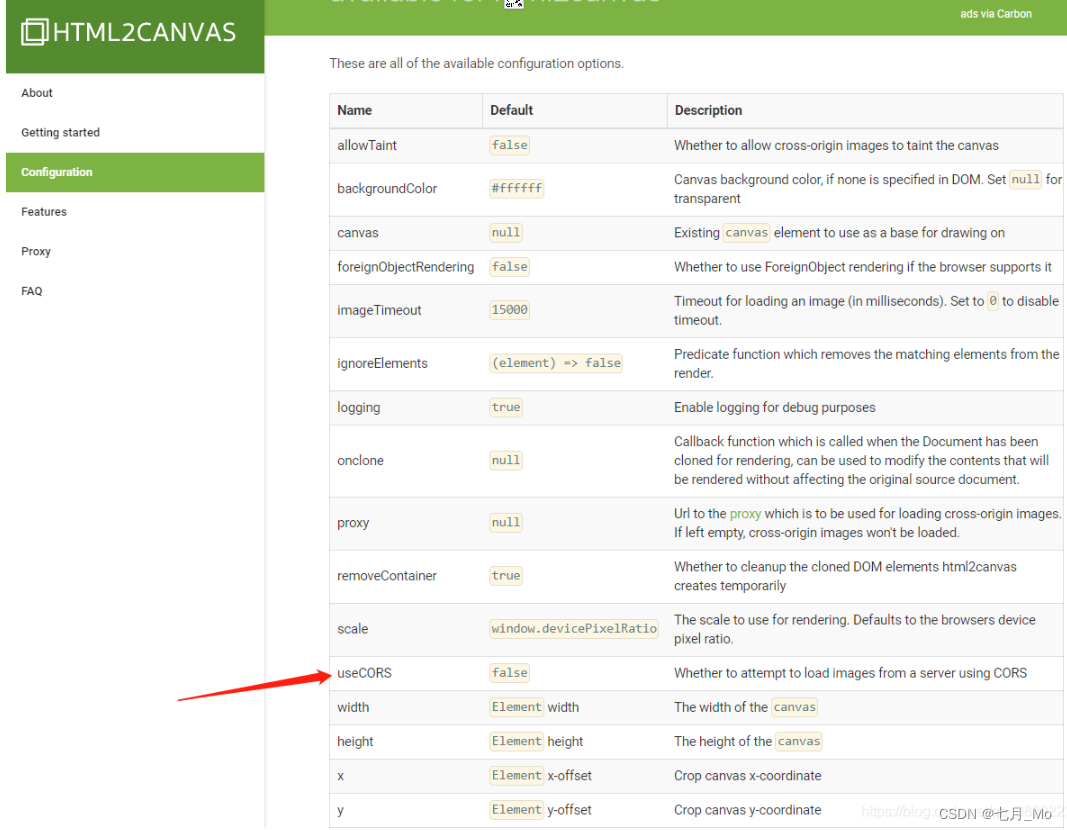
【vue3.0】实现导出的PDF文件内容是红头文件格式
效果图: 编写文件里面的主要内容 <main><div id"report-box"><p>线索描述</p><p class"label"><span>线索发现时间:</span> <span>{{ detailInfoVal?.problem.createdDate }}</span></p><…...
)
【CSP试题回顾】202012-2-期末预测之最佳阈值(优化)
CSP-202012-2-期末预测之最佳阈值 关键点 1.map的遍历方式 map<int, int>occ0Num, occ1Num; for (auto it thetaSet.begin(); it ! thetaSet.end(); it) {num num occ0Num[*it] - occ1Num[*it];auto nextIt next(it); // 获取下一个迭代器if (num > maxNum &a…...
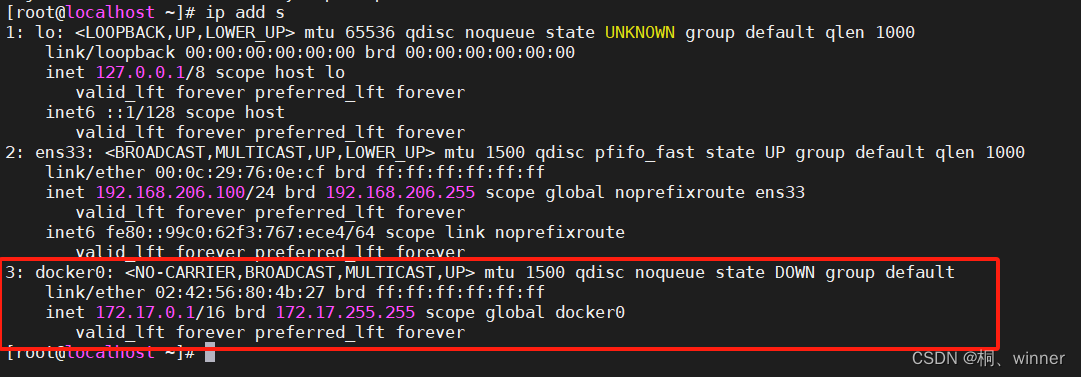
docker学习笔记 三-----docker安装部署
我使用的部署环境是centos 7.9 1、安装依赖工具 yum install -y yum-utils device-mapper-persistent-data lvm2 安装完成如下图 2、添加docker的软件信息源 yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo url地址为如…...

FastAPI+React全栈开发02 什么是FARM技术栈
Chapter01 Web Development and the FARM Stack 02 What is the FARM stack and how does it fit together? FastAPIReact全栈开发02 什么是FARM技术栈 It is important to understand that stacks aren’t really special, they are just sets of technologies that cover…...

C#程序结构详解
目录 背景: 一、C#程序的基本组成部分 二、C# Hello World示例 三、程序结构解析 四、编译与执行C#程序 五、总结 背景: 在学习C#编程语言的过程中,了解程序的基本结构是非常重要的。C#程序由多个组成部分构成,每个部分都有其特定的功能和作用。下面…...

linux 清理空间
1. 根目录下执行命令,查看每个目录下文件大小总和 rootvm10-88-88-3 /]# du -h --max-depth1 79M ./tmp 123M ./etc 4.0K ./media 4.0K ./srv 104M ./boot 5.3G ./var 0 ./sys 8.6M ./dev 196G ./usr 4.0K ./mnt 285M ./opt…...
C语言:给结构体取别名的4种方法
0 前言 在进行嵌入式开发的过程中,我们经常会见到typedef这个关键字,这个关键字的作用是给现有的类型取别名,在实际使用过程中往往是将一个复杂的类型名取一个简单的名字,便于我们的使用。就像我们给很熟的人取外号一样ÿ…...

今天聊聊Docker
在数字化时代,软件应用的开发和部署变得越来越复杂。环境配置、依赖管理、版本控制等问题给开发者带来了不小的挑战。而Docker作为一种容器化技术,正以其独特的优势成为解决这些问题的利器。本文将介绍Docker的基本概念、优势以及应用场景,帮…...

【C语言】结构体
个人主页点这里~ 结构体 一、结构体类型的声明1、结构的声明2、结构体变量的创建和初始化3、声明时的特殊情况4、自引用 二、结构体内存对齐1、对齐规则2、存在内存对齐的原因3、修改默认对齐数 三、结构体传参四、结构体实现位段 一、结构体类型的声明 我们在指针终篇中提到过…...
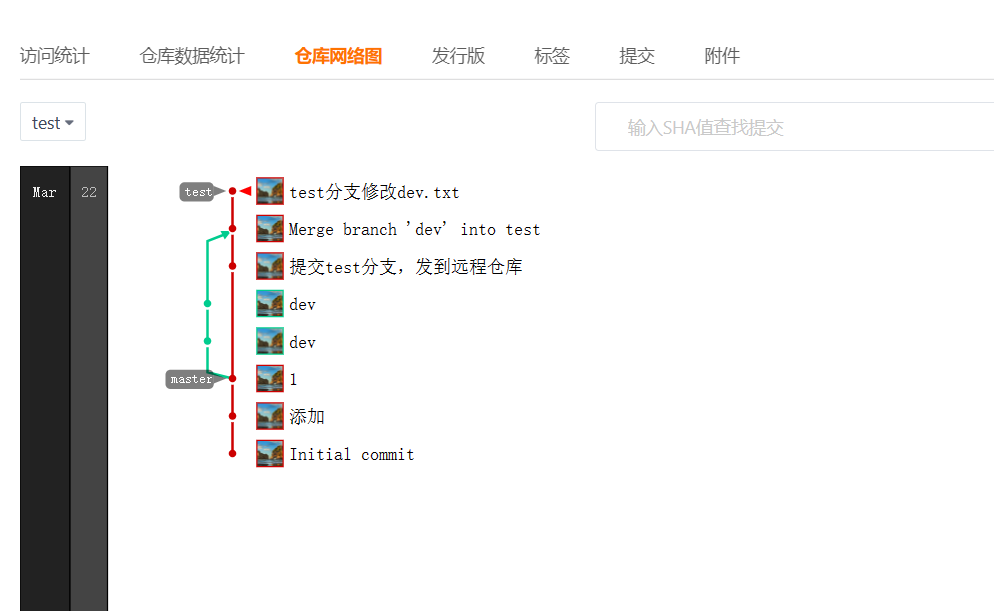
Git基础(24):分支回退
文章目录 前言放弃已修改的内容分支回退到指定commit 前言 将分支回退到之前的某个版本 开发中,可能开发某个功能不需要了,或者想要回退到之前历史的某个commit, 放弃后来修改的内容。 放弃已修改的内容 如果未提交,直接使用 …...

复试专业前沿问题问答合集1
复试专业前沿问题问答合集1 人工智能基础知识问答 Q1: 什么是人工智能(AI)? A1: 人工智能(AI)是计算机科学的一个分支,它涉及创建能够执行通常需要人类智能的任务的机器和软件。这些任务包括学习(获取信息并根据信息对其进行规则化以达到结论)、推理(使用规则达到近…...

C++标准库中提供的用于处理正则表达式的类std::regex
std 是 C 标准库的命名空间,包含了大量标准的 C 类、函数和对象。这些类和函数提供了广泛的功能,包括输入输出、容器、算法、字符串处理等。 通常,为了使用标准库中的对象和函数,需在代码中包含相应的头文件,比如 #in…...
.NET Core 服务实现监控可观测性最佳实践
前言 本次实践主要是介绍 .Net Core 服务通过无侵入的方式接入观测云进行全面的可观测。 环境信息 系统环境:Kubernetes编程语言:.NET Core ≥ 2.1日志框架:Serilog探针类型:ddtrace 接入方案 准备工作 DataKit 部署 DataK…...

高斯过程回归与离散变分原理:数据驱动的物理结构发现
1. 项目概述:当高斯过程回归遇见离散变分原理在物理信息机器学习这个交叉领域,我们常常面临一个核心挑战:如何从有限的、可能带有噪声的观测数据中,不仅还原出物理系统的动态,还能揭示其背后深刻的数学结构?…...

Gofile极速下载器:3倍下载速度的完整指南
Gofile极速下载器:3倍下载速度的完整指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在数字时代,文件分享已成为日常工作的一部分,但…...

使用Taotoken稳定调用大模型API提升智能客服响应效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken稳定调用大模型API提升智能客服响应效率 构建一个稳定、高效的智能客服系统,是许多技术团队面临的核心挑战…...

AIGC工作流自动化平台技术选型与架构设计:从LLM到编排引擎的全链路拆解
系列导读 你现在看到的是《从0到1构建AIGC工作流自动化平台:架构、实践与运维全指南》的第 1/10 篇,当前这篇会重点解决:用架构决策树帮助读者在众多框架中快速定位最适合自己项目的技术栈,避免选型踩坑。 上一篇回顾:这是系列首篇,我们先把整体背景和问题边界搭起来。…...

DeepSeek API调用成本失控?揭秘Token计费陷阱及4步精准降本法
更多请点击: https://codechina.net 第一章:DeepSeek API调用成本失控?揭秘Token计费陷阱及4步精准降本法 DeepSeek API 采用严格的 token 精确计费机制,但开发者常因忽略输入/输出双计费、系统提示词隐式消耗、以及未压缩上下文…...

长期使用Taotoken Token Plan套餐的成本节约体感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐的成本节约体感 在管理一个中型项目的AI模型调用成本时,我们经历了从按次、按量付费到…...

具身智能的发展趋势对就业市场的影响的时间线是怎样的?
一、时间线为什么是 2026–2027 / 2028–2029 / 2030?1)2026–2027:阵痛期(工业 / 物流先替代)核心依据:量产节奏 成本拐点 机构一致判断出货量预测:多家机构(IFR、高盛、麦肯锡&a…...

使用taotoken后github actions自动化任务中的api调用稳定性观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用taotoken后github actions自动化任务中的api调用稳定性观察 1. 背景与迁移动机 在持续集成与自动化开发流程中,Gi…...

【紧急预警】ChatGPT默认图表存在3类隐性误导风险!金融/医疗行业已发生2起决策偏差事故
更多请点击: https://intelliparadigm.com 第一章:ChatGPT数据可视化建议 在利用ChatGPT辅助数据分析与可视化时,需特别注意输入提示(prompt)的结构化设计,以引导模型生成可执行、可复现的可视化代码。Cha…...

韭菜盒子:在VSCode中打造你的专属投资工作台,让代码与行情无缝融合
韭菜盒子:在VSCode中打造你的专属投资工作台,让代码与行情无缝融合 【免费下载链接】leek-fund :chart_with_upwards_trend: 韭菜盒子VSCode插件,可以看股票、基金、期货等实时数据。 LeekFund turns your VS Code and Cursor into a real-ti…...