MySQL知识总结
一条 SQL 语句过来的流程是什么样的?
①当客户端连接到 MySQL 服务器时,服务器对其进行认证。可以通过用户名与密码认证,也可以通过 SSL 证书进行认证。登录认证后,服务器还会验证客户端是否有执行某个查询的操作权限。
②在正式查询之前,服务器会检查查询缓存,如果能找到对应的查询,则不必进行查询解析,优化,执行等过程,直接返回缓存中的结果集。
③MySQL 的解析器会根据查询语句,构造出一个解析树,主要用于根据语法规则来验证语句是否正确,比如 SQL 的关键字是否正确,关键字的顺序是否正确。而预处理器主要是进一步校验,比如表名,字段名是否正确等。
④查询优化器将解析树转化为查询计划,一般情况下,一条查询可以有很多种执行方式,最终返回相同的结果,优化器就是根据成本找到这其中最优的执行计划。
⑤执行计划调用查询执行引擎,而查询引擎通过一系列 API 接口查询到数据。
⑥得到数据之后,在返回给客户端的同时,会将数据存在查询缓存中。
查询缓存
我们先通过 show variables like '%query_cache%' 来看一下默认的数据库配置,此为本地数据库的配置。
概念
①have_query_cache:当前的 MySQL 版本是否支持“查询缓存”功能。
②query_cache_limit:MySQL 能够缓存的最大查询结果,查询结果大于该值时不会被缓存。默认值是 1048576(1MB)。
③query_cache_min_res_unit:查询缓存分配的最小块(字节)。默认值是 4096(4KB)。
当查询进行时,MySQL 把查询结果保存在 query cache,但是如果保存的结果比较大,超过了 query_cache_min_res_unit 的值,这时候 MySQL 将一边检索结果,一边进行保存结果。
他保存结果也是按默认大小先分配一块空间,如果不够,又要申请新的空间给他。
如果查询结果比较小,默认的 query_cache_min_res_unit 可能造成大量的内存碎片,如果查询结果比较大,默认的 query_cache_min_res_unit 又不够,导致一直分配块空间。
所以可以根据实际需求,调节 query_cache_min_res_unit 的大小。
注:如果上面说的内容有点弯弯绕,那举个现实生活中的例子,比如咱现在要给运动员送水,默认的是 500ml 的瓶子,如果过来的是少年运动员,可能 500ml 太大了,他们喝不完,造成了浪费。
那我们就可以选择 300ml 的瓶子,如果过来的是成年运动员,可能 500ml 不够,那他们一瓶喝完了,又开一瓶,直接不渴为止。那么那样开瓶子也要时间,我们就可以选择 1000ml 的瓶子。
④query_cache_size:为缓存查询结果分配的总内存。
⑤query_cache_type:默认为 on,可以缓存除了以 select sql_no_cache 开头的所有查询结果。
⑥query_cache_wlock_invalidate:如果该表被锁住,是否返回缓存中的数据,默认是关闭的。
原理
MySQL 的查询缓存实质上是缓存 SQL 的 Hash 值和该 SQL 的查询结果,如果运行相同的 SQL,服务器直接从缓存中去掉结果,而不再去解析,优化,寻找最低成本的执行计划等一系列操作,大大提升了查询速度。
但是万事有利也有弊:
第一个弊端就是如果表的数据有一条发生变化,那么缓存好的结果将全部不再有效。这对于频繁更新的表,查询缓存是不适合的。
比如一张表里面只有两个字段,分别是 id 和 name,数据有一条为 1,张三。
我使用 select * from 表名 where name=“张三”来进行查询,MySQL 发现查询缓存中没有此数据,会进行一系列的解析,优化等操作进行数据的查询。
查询结束之后将该 SQL 的 Hash 和查询结果缓存起来,并将查询结果返回给客户端。
但是这个时候我又新增了一条数据 2,张三。如果我还用相同的 SQL 来执行,他会根据该 SQL 的 Hash 值去查询缓存中,那么结果就错了。
所以 MySQL 对于数据有变化的表来说,会直接清空关于该表的所有缓存。这样其实效率是很差的。
第二个弊端就是缓存机制是通过对 SQL 的 Hash,得出的值为 Key,查询结果为 Value 来存放的,那么就意味着 SQL 必须完完全全一模一样,否则就命不中缓存。
我们都知道 Hash 值的规则,就算很小的查询,哈希出来的结果差距是很多的,所以 select * from 表名 where name=“张三”和SELECT * FROM 表名 WHERE NAME=“张三”和select * from 表名 where name = “张三”,三个SQL 哈希出来的值是不一样的。
大小写和空格影响了他们,所以并不能命中缓存,但其实他们搜索结果是完全一样的。
生产如何设置 MySQL Query Cache
先来看线上参数:
我们发现将 query_cache_type 设置为 OFF,其实网上资料和各大云厂商提供的云服务器都是将这个功能关闭的,从上面的原理来看,在一般情况下,他的弊端大于优点。
索引
例子:创建一个名为 user 的表,其包括 id,name,age,sex 等字段信息。此外,id 为主键聚簇索引,idx_name 为非聚簇索引
CREATE TABLE `user` (
`id` varchar(10) NOT NULL DEFAULT '',
`name` varchar(10) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`sex` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
我们将其设置 10 条数据,便于下面的索引的理解:
INSERT INTO `user` VALUES ('1', 'andy', '20', '女');
INSERT INTO `user` VALUES ('10', 'baby', '12', '女');
INSERT INTO `user` VALUES ('2', 'kat', '12', '女');
INSERT INTO `user` VALUES ('3', 'lili', '20', '男');
INSERT INTO `user` VALUES ('4', 'lucy', '22', '女');
INSERT INTO `user` VALUES ('5', 'bill', '20', '男');
INSERT INTO `user` VALUES ('6', 'zoe', '20', '男');
INSERT INTO `user` VALUES ('7', 'hay', '20', '女');
INSERT INTO `user` VALUES ('8', 'tony', '20', '男');
INSERT INTO `user` VALUES ('9', 'rose', '21', '男');
聚簇索引(主键索引)
他包含两个特点:
-
使用记录主键值的大小来进行记录和页的排序。页内的记录是按照主键的大小顺序排成一个单项链表。各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。
-
叶子节点存储的是完整的用户记录。
注:聚簇索引不需要我们显示的创建,他是由 InnoDB 存储引擎自动为我们创建的。如果没有主键,其也会默认创建一个
非聚簇索引(二级索引)
上面的聚簇索引只能在搜索条件是主键时才能发挥作用,因为聚簇索引可以根据主键进行排序的。
如果搜索条件是 name,在刚才的聚簇索引上,我们可能遍历,挨个找到符合条件的记录,但是,这样真的是太蠢了,MySQL 不会这样做的。
如果我们想让搜索条件是 name 的时候,也能使用索引,那可以多创建一个基于 name 的二叉树,如下图:
他与聚簇索引的不同:
-
叶子节点内部使用 name 字段排序,叶子节点之间也是使用 name 字段排序。
-
叶子节点不再是完整的数据记录,而是 name 和主键值。
为什么不再是完整信息?MySQL 只让聚簇索引的叶子节点存放完整的记录信息,因为如果有好几个非聚簇索引,他们的叶子节点也存放完整的记录绩效,那就不浪费空间啦。
如果我搜索条件是基于 name,需要查询所有字段的信息,那查询过程是啥?
-
根据查询条件,采用 name 的非聚簇索引,先定位到该非聚簇索引某些记录行。
-
根据记录行找到相应的 id,再根据 id 到聚簇索引中找到相关记录。这个过程叫做回表。
联合索引
图就不画了,简单来说,如果 name 和 age 组成一个联合索引,那么先按 name 排序,如果 name 一样,就按 age 排序。
一些原则
①最左前缀原则。一个联合索引(a,b,c),如果有一个查询条件有 a,有 b,那么他则走索引,如果有一个查询条件没有 a,那么他则不走索引。
②使用唯一索引。具有多个重复值的列,其索引效果最差。例如,存放姓名的列具有不同值,很容易区分每行。
而用来记录性别的列,只含有“男”,“女”,不管搜索哪个值,都会得出大约一半的行,这样的索引对性能的提升不够高。
③不要过度索引。每个额外的索引都要占用额外的磁盘空间,并降低写操作的性能。
在修改表的内容时,索引必须进行更新,有时可能需要重构,因此,索引越多,所花的时间越长。
④索引列不能参与计算,保持列“干净”,比如 from_unixtime(create_time) = ’2014-05-29’就不能使用到索引。
原因很简单,B+ 树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。
所以语句应该写成:
create_time = unix_timestamp(’2014-05-29’);
⑤一定要设置一个主键。前面聚簇索引说到如果不指定主键,InnoDB 会自动为其指定主键,这个我们是看不见的。
反正都要生成一个主键的,还不如我们设置,以后在某些搜索条件时还能用到主键的聚簇索引。
⑥主键推荐用自增 id,而不是 uuid。上面的聚簇索引说到每页数据都是排序的,并且页之间也是排序的,如果是 uuid,那么其肯定是随机的,其可能从中间插入,导致页的分裂,产生很多表碎片。
如果是自增的,那么其有从小到大自增的,有顺序,那么在插入的时候就添加到当前索引的后续位置。当一页写满,就会自动开辟一个新的页。
注:如果自增 id 用完了,那将字段类型改为 bigint,就算每秒 1 万条数据,跑 100 年,也没达到 bigint 的最大值。
万年面试题(为什么索引用 B+ 树)
①B+ 树的磁盘读写代价更低:B+ 树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对 B 树更小。
如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对 IO 读写次数就降低了。
②由于 B+ 树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可。
但是 B 树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以 B+ 树更加适合在区间查询的情况,所以通常 B+ 树用于数据库索引。
优化器
在开篇的图里面,我们知道了 SQL 语句从客户端经由网络协议到查询缓存,如果没有命中缓存,再经过解析工作,得到准确的 SQL,现在就来到了我们这模块说的优化器。
首先,我们知道每一条 SQL 都有不同的执行方法,要不通过索引,要不通过全表扫描的方式。
那么问题就来了,MySQL 是如何选择时间最短,占用内存最小的执行方法呢?
什么是成本?
-
I/O 成本。数据存储在硬盘上,我们想要进行某个操作需要将其加载到内存中,这个过程的时间被称为 I/O 成本。默认是 1。
-
CPU 成本。在内存对结果集进行排序的时间被称为 CPU 成本。默认是 0.2。
单表查询的成本
先来建一个用户表 dev_user,里面包括主键 id,用户名 username,密码 password,外键 user_info_id,状态 status,外键 main_station_id,是否外网访问 visit,这七个字段。
索引有两个,一个是主键的聚簇索引,另一个是显式添加的以 username 为字段的唯一索引 uname_unique。
如果搜索条件是 select * from dev_user where username='XXX',那么 MySQL 是如何选择相关索引呢?
①使用所有可能用到的索引
我们可以看到搜索条件 username,所以可能走 uname_unique 索引。也可以做聚簇索引,也就是全表扫描。
②计算全表扫描代价
我们通过 show table status like ‘dev_user’命令知道 rows 和 data_length 字段,如下图:
rows:表示表中的记录条数,但是这个数据不准确,是个估计值。
data_length:表示表占用的存储空间字节数。data_length=聚簇索引的页面数量 X 每个页面的大小。
反推出页面数量=1589248÷16÷1024=97:
-
I/O 成本:97X1=97
-
CPU 成本:6141X0.2=1228
-
总成本:97+1228=1325
③计算使用不同索引执行查询的代价
因为要查询出满足条件的所有字段信息,所以要考虑回表成本:
-
I/O 成本=1+1X1=2(范围区间的数量+预计二级记录索引条数)
-
CPU 成本=1X0.2+1X0.2=0.4(读取二级索引的成本+回表聚簇索引的成本)
-
总成本= I/O 成本+CPU 成本=2.4
④对比各种执行方案的代价,找出成本最低的那个
上面两个数字一对比,成本是采用 uname_unique 索引成本最低。
多表查询的成本
对于两表连接查询来说,他的查询成本由下面两个部分构成:
-
单次查询驱动表的成本
-
多次查询被驱动表的成本(具体查询多次取决于对驱动表查询的结果集有多少个记录)
index dive
如果前面的搜索条件不是等值,而是区间,如 select * from dev_user where username>'admin' and username<'test' 这个时候我们是无法看出需要回表的数量。
步骤 1:先根据 username>'admin' 这个条件找到第一条记录,称为区间最左记录。
步骤 2:再根据 username<'test' 这个条件找到最后一条记录,称为区间最右记录。
步骤 3:如果区间最左记录和区间最右记录相差不是很远,可以准确统计出需要回表的数量。
如果相差很远,就先计算 10 页有多少条记录,再乘以页面数量,最终模糊统计出来。
Explain
产品来索命:
-
产品:为什么这个页面出来这么慢?
-
开发:因为你查的数据多呗,他就是这么慢
-
产品:我不管,我要这个页面快点,你这样,客户怎么用啊
-
开发:......你行你来
哈哈哈哈,不瞎 BB 啦,如果有些 SQL 贼慢,我们需要知道他有没有走索引,走了哪个索引,这个时候我就需要通过 explain 关键字来深入了解 MySQL 内部是如何执行的。
id:一般来说一个 select 一个唯一 id,如果是子查询,就有两个 select,id 是不一样的,但是凡事有例外,有些子查询的,他们 id 是一样的。
这是为什么呢?那是因为 MySQL 在进行优化的时候已经将子查询改成了连接查询,而连接查询的 id 是一样的。
select_type:
-
simple:不包括 union 和子查询的查询都算 simple 类型。
-
primary:包括 union,union all,其中最左边的查询即为 primary。
-
union:包括 union,union all,除了最左边的查询,其他的查询类型都为 union。
table:显示这一行是关于哪张表的。
type 访问方法:
-
ref:普通二级索引与常量进行等值匹配
-
ref_or_null:普通二级索引与常量进行等值匹配,该索引可能是 null
-
const:主键或唯一二级索引列与常量进行等值匹配
-
range:范围区间的查询
-
all:全表扫描
possible_keys:对某表进行单表查询时可能用到的索引。
key:经过查询优化器计算不同索引的成本,最终选择成本最低的索引。
rows:
-
如果使用全表扫描,那么 rows 就代表需要扫描的行数
-
如果使用索引,那么 rows 就代表预计扫描的行数
filtered:
-
如果全表扫描,那么 filtered 就代表满足搜索条件的记录的满分比
-
如果是索引,那么 filtered 就代表除去索引对应的搜索,其他搜索条件的百分比
结语
本次写的稍微杂,但是都是mysql可能遇到的一些问题,主要是讲优化器。
相关文章:

MySQL知识总结
一条 SQL 语句过来的流程是什么样的? ①当客户端连接到 MySQL 服务器时,服务器对其进行认证。可以通过用户名与密码认证,也可以通过 SSL 证书进行认证。登录认证后,服务器还会验证客户端是否有执行某个查询的操作权限。 ②在正式…...

Go-Gin-Example 第八部分 优化配置接口+图片上传功能
文章目录 前情提要本节目标 优化配置结构讲解落实修改配置文件优化配置读取及设置初始化顺序第一步 验证 抽离file 实现上传图片接口图片名加密封装image的处理逻辑编写上传图片的业务逻辑增加图片上传的路由 验证实现前端访问 http.FileServerr.StaticFS修改文章接口新增、更新…...

阿里云国际DDoS高防的定制场景策略
DDoS高防的定制场景策略允许您在特定的业务突增时段(例如新业务上线、双11大促销等)选择应用独立于通用防护策略的定制防护策略模板,保证适应业务需求的防护效果。您可以根据需要设置定制场景策略。 背景信息 定制场景策略提供基于业务场景…...
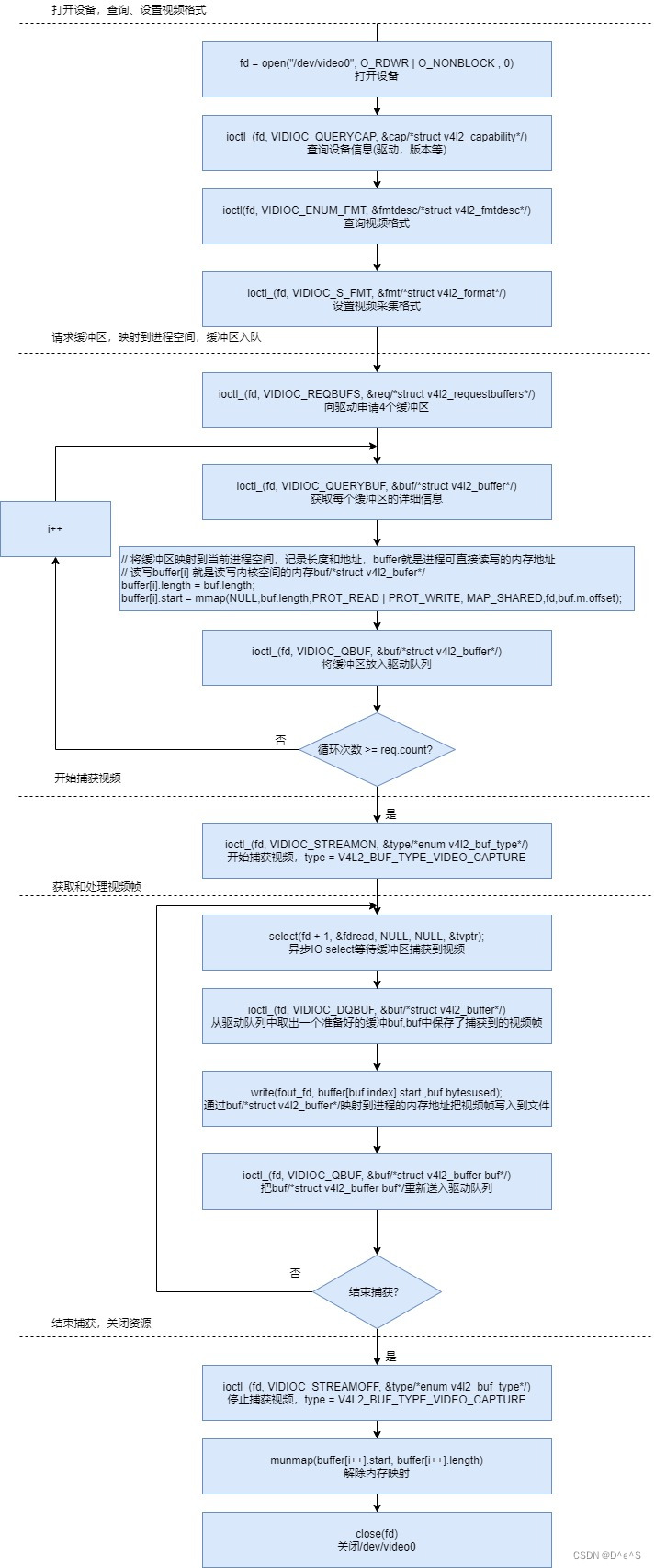
v4l2采集视频
Video4Linux2(v4l2)是用于Linux系统的视频设备驱动框架,它允许用户空间应用程序直接与视频设备(如摄像头、视频采集卡等)进行交互。 linux系统下一切皆文件,对视频设备的操作就像对文件的操作一样ÿ…...

Spring Cloud 八:微服务架构中的数据管理
Spring Cloud 一:Spring Cloud 简介 Spring Cloud 二:核心组件解析 Spring Cloud 三:API网关深入探索与实战应用 Spring Cloud 四:微服务治理与安全 Spring Cloud 五:Spring Cloud与持续集成/持续部署(CI/C…...
Chrome/Edge 使用 Markdown Viewer 查看 Markdown 格式文件
Chrome/Edge 使用 Markdown Viewer 查看 Markdown 格式文件 0. 引言1. 安装 Markdown Viewer 插件2. 使用 Markdown Viewer 阅读 Markdown 格式文件 0. 引言 大部分程序员都喜欢 Markdown 格式的文件,这时给一些没有在电脑上安装 Markdown 编辑器的同事分享资料时&…...

flutter 弹窗之系列一
自定义不受Navigator影响的弹窗 class MyHomePage extends StatefulWidget {const MyHomePage({super.key, required this.title});final String title;overrideState<MyHomePage> createState() > _MyHomePageState(); }class _MyHomePageState extends State<MyH…...

【Flink实战】Flink hint更灵活、更细粒度的设置Flink sql行为与简化hive连接器参数设置
文章目录 一. create table hints1. 语法2. 示例3. 注意 二. 实战:简化hive连接器参数设置三. select hints(ing) SQL 提示(SQL Hints)是和 SQL 语句一起使用来改变执行计划的。本章介绍如何使用 SQL 提示来实现各种干预。 SQL 提示一般可以…...

【python从入门到精通】-- 第二战:注释和有关量的解释
🌈 个人主页:白子寰 🔥 分类专栏:python从入门到精通,魔法指针,进阶C,C语言,C语言题集,C语言实现游戏👈 希望得到您的订阅和支持~ 💡 坚持创作博文…...

【手写AI代码目录】准备发布的教程
文章目录 1. tensorboard2. F.cross_entropy(input_tensor, target) F.log_softmax() F.nll_loss() 1. tensorboard from torch.utils.tensorboard import SummaryWriter# TensorBoard writer SummaryWriter(runs/mnist_experiment_1) ...if i % 100 99: # 每 100 个 b…...

2024.3.9|第十五届蓝桥杯模拟赛(第三期)
2024.3.9|十五届蓝桥杯模拟赛(第三期) 第一题 第二题 第三题 第四题 第五题 第六题 第七题 第八题 第九题 第十题 心有猛虎,细嗅蔷薇。你好朋友,这里是锅巴的C\C学习笔记,常言道,不积跬步无以至千里&…...
搭建PHP本地开发环境:看这一篇就够了
什么是PHP本地开发环境 PHP本地开发环境是指在个人计算机上模拟的服务器环境,这使得开发者能够在没有网络连接的情况下也能开发、测试和调试PHP应用程序。就像在你的电脑里装个小“服务器”,即使没网也能搞定PHP程序的开发和修修补补。这就是PHP本地开发…...

[蓝桥杯 2015]机器人数目
机器人数目 题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 少年宫新近邮购了小机器人配件,共有3类。 A 类含有:8个轮子,1个传感器; B 类含有: 6个轮子࿰…...
)
Codeforces Round 935 (Div. 3)
A. Setting up Camp(模拟) #include<iostream> #include<algorithm> using namespace std; const int N 2e5 10;int main(){int t, n;scanf("%d", &t);int a, b, c;while(t--){scanf("%d%d%d", &a, &b, …...
自然语言处理下载nltk模块库
nltk安装 目录 nltk安装 1.官方下载 2.离线下载 2.1 下载nltk资料包 2.2 解压下载的资料包重命名 2.2.1 将解压后的packages文件夹重命名为nltk_data 2.2.2 查看将重命名的文件夹放在那个位置 2.2.3 将上述nltk_data 文件夹放在 2.2.2 打印的位置处 3.验证是否下载成…...
)
题解:CF1937B(Binary Path)
题解:CF1937B(Binary Path) 一、 理解题意 1. 题目链接 CodeForces; 洛谷。 2. 题目翻译 给定一个 由 0 0 0 和 1 1 1 组成的 2 2 2 行 n n n 列的网格上寻找一条路径,使得这条路径上所有的数串联起来形成的0…...

JS——9大陷阱
一、警惕A>X>B写法 3>2>1 返回值为false(原因:3>2为true,会默认转成数字1,1>1为false) 1<4<3 返回值为true(原因:1<4为true,会默认转成数字1ÿ…...

USB - 通过configfs配置Linux USB Gadget
Linux USB gadget configured through configfs Overview USB Linux 小工具是一种具有 UDC(USB 设备控制器)的设备,可连接到 USB 主机,以扩展其附加功能,如串行端口或大容量存储功能。 A USB Linux Gadget is a device…...
)
迷宫与陷阱(蓝桥杯)
文章目录 迷宫与陷阱问题描述bfs解题思路代码 迷宫与陷阱 问题描述 小明在玩一款迷宫游戏,在游戏中他要控制自己的角色离开一间由 N x N 个格子组成的2D迷宫。 小明的起始位置在左上角,他需要到达右下角的格子才能离开迷宫,每一步…...
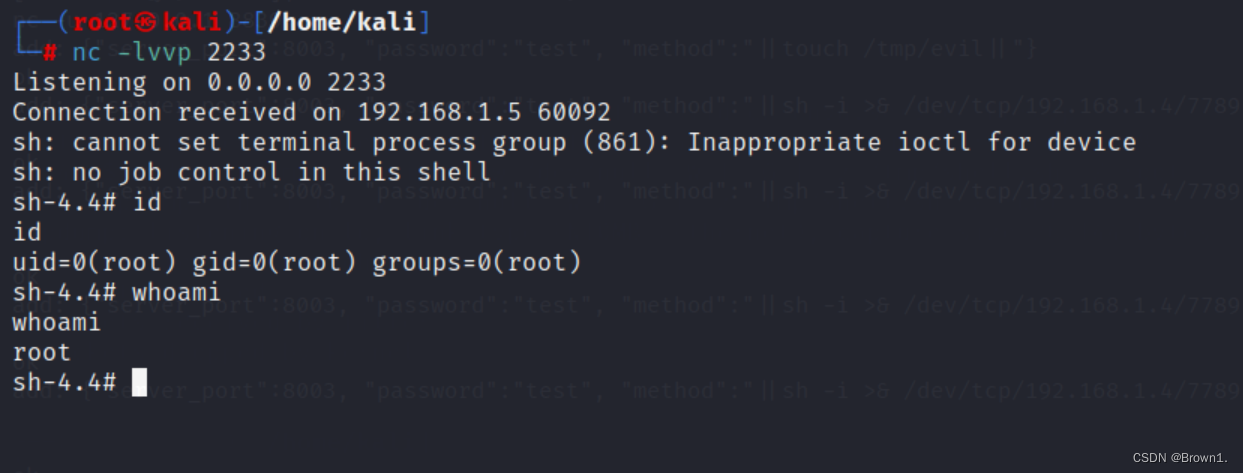
Temple of Doom靶场nodejs获取shellss-manager漏洞tcpdump提权
下载链接: Temple of Doom: 1 ~ VulnHub 下载完成后直接在vxbox中导入即可,网络链接模式根据自身情况而定(我采用的桥接模式) 正文: 先用nmap进行扫描靶机ip nmap -sn 192.168.1.1/24 对192.168.1.5进行端口探测&a…...

Linux 服务器安装 CC Switch GUI 工具 + VNC 远程桌面完整教程
Linux 服务器安装 CC Switch GUI 工具 VNC 远程桌面完整教程 前言 CC Switch 是一款 All-in-One 的 AI 助手启动器,集成了 Claude Code、Codex 和 Gemini CLI 等工具。但它是 GTK 图形界面程序,在无桌面环境的 Linux 服务器上直接运行会报错ÿ…...

Taotoken多模型路由在单一服务故障时的体验保障
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken多模型路由在单一服务故障时的体验保障 1. 引言 在构建依赖大模型能力的应用时,服务的稳定性是开发者必须面对…...

免费AI搜索工具怎么选?2026年实测TOP8工具性能、响应速度与隐私合规性深度评测
更多请点击: https://codechina.net 第一章:免费AI搜索工具推荐2026 2026年,开源与社区驱动的AI搜索工具生态迎来爆发式增长。得益于大语言模型轻量化部署、RAG(检索增强生成)架构普及以及WebAssembly在浏览器端的成熟…...

Boss-Key终极指南:一键隐藏窗口保护办公隐私的完整解决方案
Boss-Key终极指南:一键隐藏窗口保护办公隐私的完整解决方案 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 你是否曾在办公室里…...

边缘AI落地实战:模型轻量化、硬件加速与端侧部署全链路解析
1. 项目概述:为什么“把AI带到边缘设备”不是一句口号,而是正在发生的产业迁移 “Bringing AI To Edge Devices”——这个标题乍看像科技发布会的PPT副标题,但在我过去十年跑遍深圳华强北模组厂、杭州海康产线、苏州工业视觉集成商和北京智能…...

Meteor-Ionic 模态框和弹出层:创建优雅的用户交互体验
Meteor-Ionic 模态框和弹出层:创建优雅的用户交互体验 【免费下载链接】meteor-ionic Ionic components for Meteor. No Angular! 项目地址: https://gitcode.com/gh_mirrors/me/meteor-ionic Meteor-Ionic 是一个专为 Meteor 框架设计的 Ionic 组件库&#…...

12点标定
12点标定九点标定和十二点标定转换本质是两个平面二维空间的转换两个平面的二维空间的转换公式X物理 X图像200 k * 2 k缩放系数 k2/2000.01剪切图像是一个标准的二维平面空间物理世界,某个固定高度的平面物理空间 高度为5的,板子的所在的物理平面空间…...

GDScriptDecomp:让Godot游戏逆向工程变得触手可及
GDScriptDecomp:让Godot游戏逆向工程变得触手可及 【免费下载链接】gdsdecomp Godot reverse engineering tools 项目地址: https://gitcode.com/GitHub_Trending/gd/gdsdecomp 你是否曾遇到过这样的情况:手头有一个Godot引擎开发的游戏ÿ…...

5个步骤在Windows Hyper-V上完美运行macOS虚拟机
5个步骤在Windows Hyper-V上完美运行macOS虚拟机 【免费下载链接】OSX-Hyper-V OpenCore configuration for running macOS on Windows Hyper-V. 项目地址: https://gitcode.com/gh_mirrors/os/OSX-Hyper-V 你是否想在Windows电脑上体验macOS的流畅操作?OSX-…...

用一块老芯片玩转计数器:手把手教你用74390与非门搭一个24小时制时钟电路
用一块老芯片玩转计数器:手把手教你用74390与非门搭一个24小时制时钟电路 记得大学时第一次在实验室看到LED数字管跳动的那种兴奋感吗?那种从抽象理论到具象显示的魔法时刻,正是电子设计的魅力所在。今天我们就用上世纪70年代诞生的74390这块…...