【Python】学习率调整策略详解和示例
学习率调整得当将有助于算法快速收敛和获取全局最优,以获得更好的性能。本文对学习率调度器进行示例介绍。
- 学习率调整的意义
- 基础示例
- 无学习率调整方法
- 学习率调整方法一
- 多因子调度器
- 余弦调度器
- 结论
学习率调整的意义
首先,学习率的大小很重要。如果它太大,优化就会发散;如果它太小,训练就会需要过长时间,或者我们最终只能得到次优的结果(陷入局部最优)。我们之前看到问题的条件数很重要。直观地说,这是最不敏感与最敏感方向的变化量的比率。
其次,衰减速率同样很重要。如果学习率持续过高,我们可能最终会在最小值附近弹跳,从而无法达到最优解。 简而言之,我们希望速率衰减,但要比慢,这样能成为解决凸问题的不错选择。
另一个同样重要的方面是初始化。这既涉及参数最初的设置方式,又关系到它们最初的演变方式。这被戏称为预热(warmup),即我们最初开始向着解决方案迈进的速度有多快。一开始的大步可能没有好处,特别是因为最初的参数集是随机的。最初的更新方向可能也是毫无意义的。
鉴于管理学习率需要很多细节,因此大多数深度学习框架都有自动应对这个问题的工具。本文将梳理不同的调度策略对准确性的影响,并展示如何通过学习率调度器(learning rate scheduler)来有效管理。
基础示例
我们从一个简单的问题开始,这个问题可以轻松计算,但足以说明要义。 为此,我们选择了一个稍微现代化的LeNet版本(激活函数使用relu而不是sigmoid,汇聚层使用最大汇聚层而不是平均汇聚层),并应用于Fashion-MNIST数据集。 此外,我们混合网络以提高性能。
无学习率调整方法
import math
import torch
from torch import nn
from torch.optim import lr_scheduler, SGD
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import make_grid
import matplotlib.pyplot as pltdef load_data_fashion_mnist(batch_size):# 定义数据预处理transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))])# 加载训练集和测试集train_dataset = datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform)test_dataset = datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform)# 创建数据加载器train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)return train_loader, test_loader
def net_fn():model = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.ReLU(),nn.Linear(120, 84), nn.ReLU(),nn.Linear(84, 10))return modeldef train(net, train_loader, test_loader, num_epochs, loss, optimizer, device, scheduler=None):net.to(device)running_loss = 0.0train_losses = []test_losses = []test_accuracies = []for epoch in range(num_epochs):for i, (inputs, labels) in enumerate(train_loader):inputs, labels = inputs.to(device), labels.to(device)# Zero the parameter gradientsoptimizer.zero_grad()# Forward passoutputs = net(inputs)loss_value = loss(outputs, labels)# Backward and optimizeloss_value.backward()optimizer.step()# Print statisticsrunning_loss += loss_value.item()# if i % 200 == 199: # print every 200 mini-batches# print(f'[{epoch + 1}, {i + 1}] loss: {running_loss / 200}')# running_loss = 0.0train_losses.append(running_loss / len(train_loader))# Evaluate the model on the test datasettest_loss, test_acc = evaluate(net, test_loader, device)test_losses.append(test_loss)test_accuracies.append(test_acc)print(f'Epoch {epoch+1}, Train Loss: {train_losses[-1]:.4f}, Test Loss: {test_losses[-1]:.4f}, Test Acc: {test_accuracies[-1]:.2f}')if scheduler:if scheduler.__module__ == lr_scheduler.__name__:scheduler.step()else:for param_group in optimizer.param_groups:param_group['lr'] = scheduler(epoch)plt.figure(figsize=(10, 6))plt.plot(range(1, num_epochs + 1), train_losses, label='Training Loss')plt.plot(range(1, num_epochs + 1), test_losses, label='Test Loss')plt.plot(range(1, num_epochs + 1), test_accuracies, label='Test Accuracy')plt.title('Training, Test Losses and Test Accuracy')plt.xlabel('Epoch')plt.ylabel('Loss / Accuracy')plt.legend()plt.grid(True)plt.savefig("1.jpg")plt.show()def evaluate(model, data_loader, device):model.eval()test_loss = 0correct = 0with torch.no_grad():for inputs, labels in data_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)test_loss += nn.CrossEntropyLoss(reduction='sum')(outputs, labels).item()_, predicted = torch.max(outputs.data, 1)correct += (predicted == labels).sum().item()test_loss /= len(data_loader.dataset)accuracy = correct / len(data_loader.dataset)#accuracy = 100. * correct / len(data_loader.dataset)return test_loss, accuracy# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# Define the model
model = net_fn()# Define the loss function
loss = nn.CrossEntropyLoss()# Define the optimizer
lr=0.3
optimizer = SGD(model.parameters(), lr=lr)# Load the dataset
batch_size=128
train_loader, test_loader=load_data_fashion_mnist(batch_size)
num_epochs=30
train(model, train_loader, test_loader, num_epochs, loss, optimizer, device)
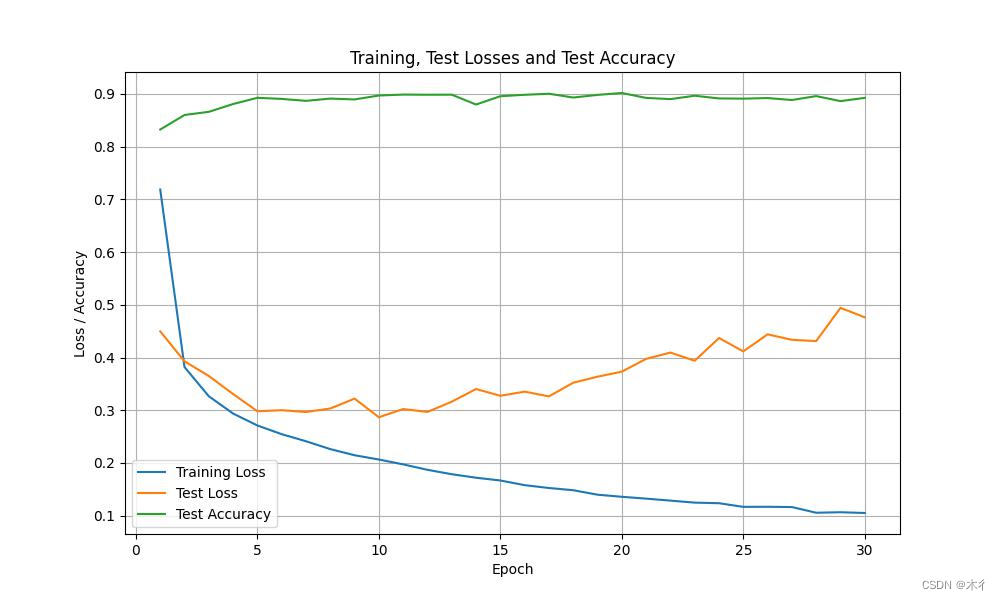
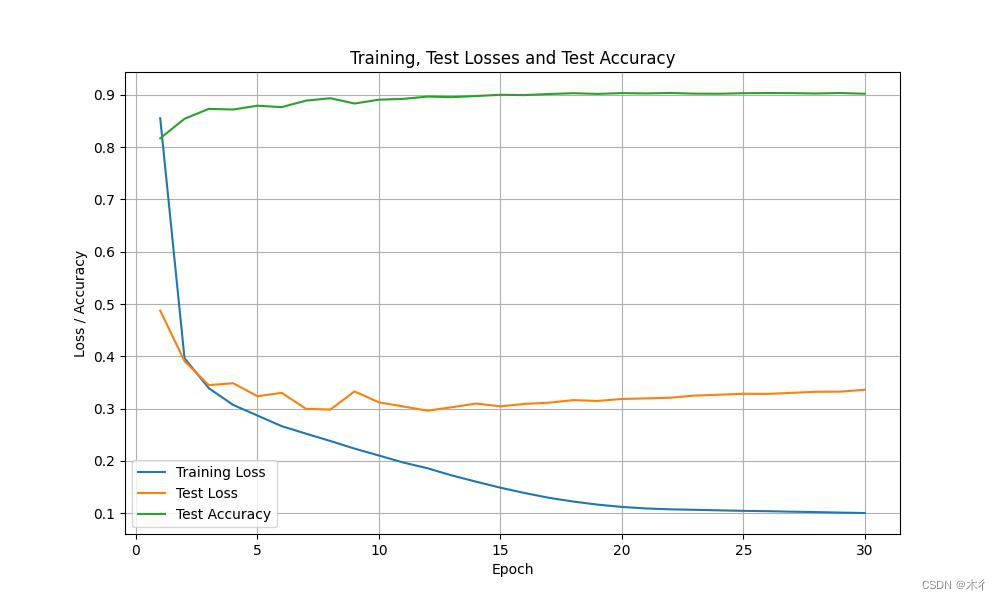
这里没有使用学习率调整策略。训练过程和结果如下图所示:
.
.
.
.
Epoch 23, Train Loss: 0.1247, Test Loss: 0.3939, Test Acc: 0.90
Epoch 24, Train Loss: 0.1236, Test Loss: 0.4370, Test Acc: 0.89
Epoch 25, Train Loss: 0.1167, Test Loss: 0.4117, Test Acc: 0.89
Epoch 26, Train Loss: 0.1169, Test Loss: 0.4440, Test Acc: 0.89
Epoch 27, Train Loss: 0.1163, Test Loss: 0.4336, Test Acc: 0.89
Epoch 28, Train Loss: 0.1055, Test Loss: 0.4312, Test Acc: 0.90
Epoch 29, Train Loss: 0.1065, Test Loss: 0.4942, Test Acc: 0.89
Epoch 30, Train Loss: 0.1051, Test Loss: 0.4763, Test Acc: 0.89
学习率调整方法一
设置在每个迭代轮数(甚至在每个小批量)之后向下调整学习率。 例如,以动态的方式来响应优化的进展情况。
在代码最后添加SquareRootScheduler类,并更新train()函数参数,其它内容不变。
class SquareRootScheduler:def __init__(self, lr=0.1):self.lr = lrdef __call__(self, num_update):return self.lr * pow(num_update + 1.0, -0.5)scheduler = SquareRootScheduler(lr=0.1)
train(model, train_loader, test_loader, num_epochs, loss, optimizer, device,scheduler)
运行代码,可得相应参数值和变化过程,如下所示。
Epoch 23, Train Loss: 0.1823, Test Loss: 0.2811, Test Acc: 0.90
Epoch 24, Train Loss: 0.1801, Test Loss: 0.2800, Test Acc: 0.90
Epoch 25, Train Loss: 0.1767, Test Loss: 0.2819, Test Acc: 0.90
Epoch 26, Train Loss: 0.1747, Test Loss: 0.2800, Test Acc: 0.91
Epoch 27, Train Loss: 0.1720, Test Loss: 0.2818, Test Acc: 0.90
Epoch 28, Train Loss: 0.1689, Test Loss: 0.2856, Test Acc: 0.90
Epoch 29, Train Loss: 0.1669, Test Loss: 0.2907, Test Acc: 0.90
Epoch 30, Train Loss: 0.1641, Test Loss: 0.2813, Test Acc: 0.90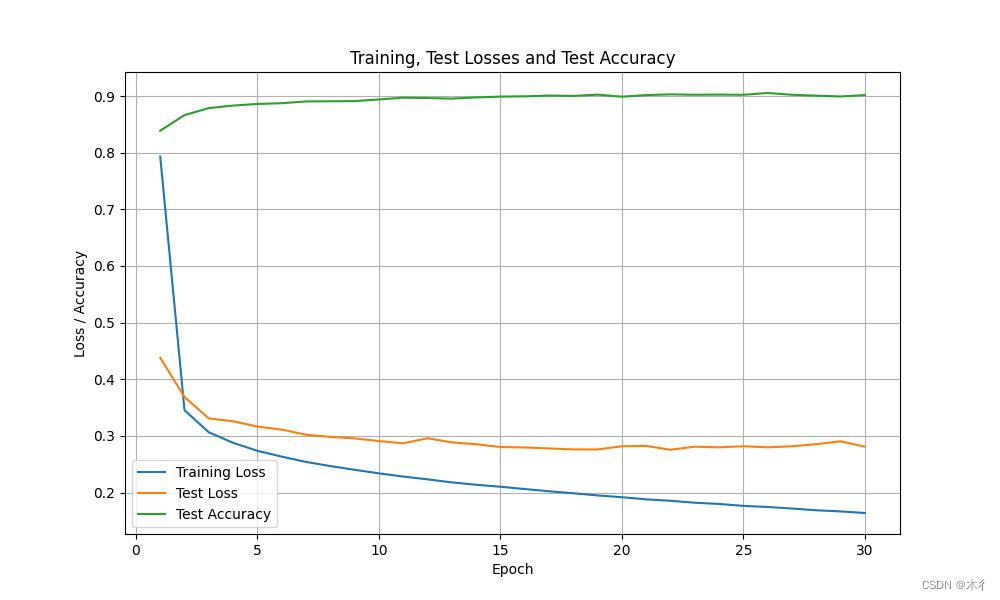
我们可以看出曲线比没有策略时平滑了很多,效果有所提升。
多因子调度器
多因子调度器。

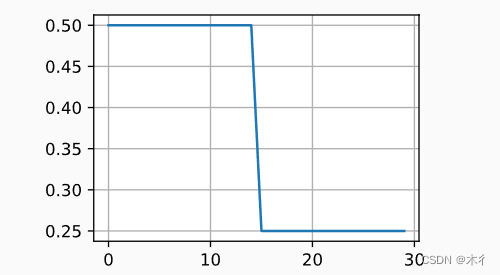
代码部分修改:
scheduler =lr_scheduler.MultiStepLR(optimizer, milestones=[15, 30], gamma=0.5)
运行结果为:
可见效果不理想,出现过拟合现象。
余弦调度器
余弦调度器是 (Loshchilov and Hutter, 2016)提出的一种启发式算法。 它所依据的观点是:我们可能不想在一开始就太大地降低学习率,而且可能希望最终能用非常小的学习率来“改进”解决方案。 这产生了一个类似于余弦的调度,函数形式如下所示,学习率的值在
之间。

代码中添加CosineScheduler类和修改scheduler。
class CosineScheduler:def __init__(self, max_update, base_lr=0.01, final_lr=0,warmup_steps=0, warmup_begin_lr=0):self.base_lr_orig = base_lrself.max_update = max_updateself.final_lr = final_lrself.warmup_steps = warmup_stepsself.warmup_begin_lr = warmup_begin_lrself.max_steps = self.max_update - self.warmup_stepsdef get_warmup_lr(self, epoch):increase = (self.base_lr_orig - self.warmup_begin_lr) \* float(epoch) / float(self.warmup_steps)return self.warmup_begin_lr + increasedef __call__(self, epoch):if epoch < self.warmup_steps:return self.get_warmup_lr(epoch)if epoch <= self.max_update:self.base_lr = self.final_lr + (self.base_lr_orig - self.final_lr) * (1 + math.cos(math.pi * (epoch - self.warmup_steps) / self.max_steps)) / 2return self.base_lr#scheduler = SquareRootScheduler(lr=0.1)
#scheduler =lr_scheduler.MultiStepLR(optimizer, milestones=[15, 30], gamma=0.5)
scheduler = CosineScheduler(max_update=20, base_lr=0.3, final_lr=0.01)
train(model, train_loader, test_loader, num_epochs, loss, optimizer, device,scheduler)
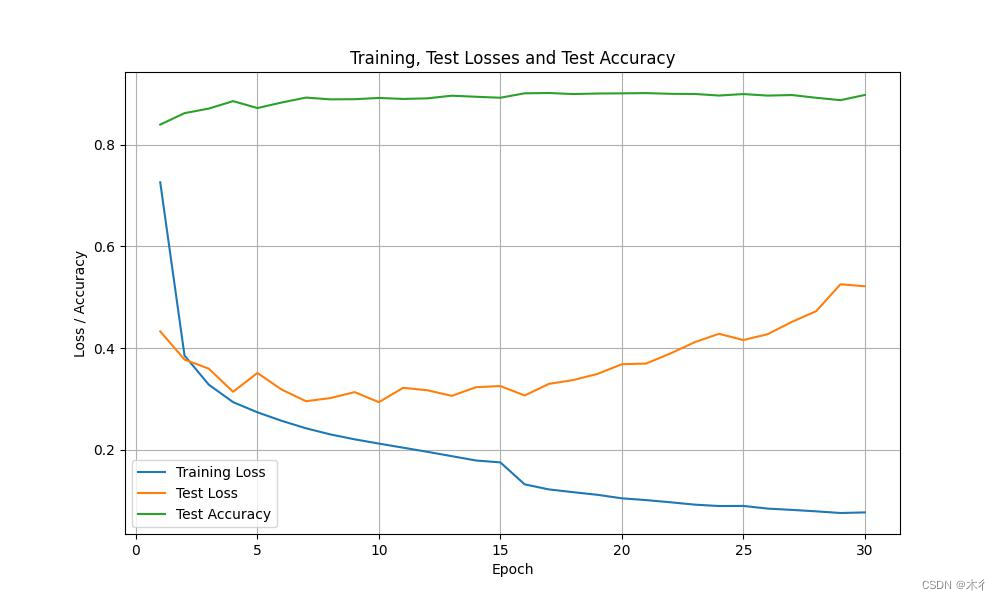
运行结果如下:
过拟合现象消失,效果提升。
结论
在开发时应根据自己需要,选择合适的学习率调整策略。优化在深度学习中有多种用途。对于同样的训练误差而言,选择不同的优化算法和学习率调度,除了最大限度地减少训练时间,可以导致测试集上不同的泛化和过拟合量。
注:部分内容摘选子书籍《动手学深度学习》
相关文章:
【Python】学习率调整策略详解和示例
学习率调整得当将有助于算法快速收敛和获取全局最优,以获得更好的性能。本文对学习率调度器进行示例介绍。 学习率调整的意义基础示例无学习率调整方法学习率调整方法一多因子调度器余弦调度器 结论 学习率调整的意义 首先,学习率的大小很重要。如果它…...

【Linux实践室】Linux用户管理实战指南:用户密码管理操作详解
🌈个人主页:聆风吟_ 🔥系列专栏:Linux实践室、网络奇遇记 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 一. ⛳️任务描述二. ⛳️相关知识2.1 🔔用户密码存放地及方式2.2 🔔使用…...

UE5学习日记——蓝图节点前缀关键字整理
一、起因 节点如海,中英文翻译的时候还是有差别的,比如: 同一个中文,可能在英文里完全不同,连出现位置可能都不一样 附加 Attach Actor To Component(将Actor附加到组件)Append Array…...

浅析机器学习的常用方法
引言: 机器学习(Machine Learning,ML)是一种以计算机程序为基础,在不需要明确编程的情况下,对数据进行分析和处理的人工智能技术。与传统的计算机编程相比,机器学习的区别在于它通过数据建立模…...

大数据开发(日志离线分析项目)
大数据开发(日志离线分析项目) 一、项目需求1、使用jqueryecharts的方式调用程序后台提供的rest api接口,获取json数据,然后通过jquerycss的方式进行数据展示。工作流程如下:2、七大角度1、用户基本信息分析模块2、浏览…...
PostgreSQL技术大讲堂 - 第48讲:PG高可用实现keepalived
PostgreSQL从小白到专家,是从入门逐渐能力提升的一个系列教程,内容包括对PG基础的认知、包括安装使用、包括角色权限、包括维护管理、、等内容,希望对热爱PG、学习PG的同学们有帮助,欢迎持续关注CUUG PG技术大讲堂。 第48讲&#…...

【若依 SpringBoot 前后端分离版】修改加密传输后密码错误的解决方法(附排错过程)
目录 排错过程 报错信息 SysLoginController SysLoginService(问题核心) 太长不看版:解决方法 文章传送门:若依(RuoYi)SpringBoot框架密码加密传输(前后分离板)_若依密码加密方式-CSDN博客文章浏览阅读1.5w次,点赞…...
发送请求- header配置
请求头里是客户端的要求,把你的诉求告诉服务端,服务端按照你的要求返回数据 , 请求header需要严格全配置,把请求header全部传入,不能频繁访问,让后端知道它是正常请求 一般只配置User-Agent和Content Typ…...

C语言重难知识点
C语言重难知识点 if(a=1) 为真函数指针的调用(int)2.9 = 2逗号运算符,最右边表达式值作为整个逗号表达式的值。文件操作if(a=1) 为真 int a=0,b=0,c=0; if(a...

jMeter学习
一. JMeter介绍 1. 什么是JMeter? Apache JMeter™ 应用程序是开源软件,一个 100% 纯 Java 应用程序,旨在加载测试功能行为和测量性能 。它最初是为测试 Web 应用程序而设计的,但后来扩展到其他测试功能。 2. JMeter能做啥&#x…...

Nodejs运行vue项目时,报错:Error: error:0308010C:digital envelope routines::unsupported
前端项目使用( npm run dev ) 运行vue项目时,出现错误:Error: error:0308010C:digital envelope routines::unsupported 经过探索,发现问题所在,主要是nodeJs V17版本发布了OpenSSL3.0对算法和秘钥大小增加了更为严格的限制&#…...

华为汽车图谱
极狐 极狐(ARCFOX)是由北汽、华为、戴姆勒、麦格纳等联合打造。总部位于北京蓝谷。 问界 华为与赛力斯(东风小康)合作的成果。 阿维塔 阿维塔(AVATR)是由长安汽车、华为、宁德时代三方联合打造。公司总部位…...

鸿蒙操作系统-初识
HarmonyOS-初识 简述安装配置hello world1.创建项目2.目录解释3.构建页面4.真机运行 应用程序包共享包HARHSP 快速修复包 官方文档请参考:HarmonyOS 简述 1.定义:HarmonyOS是分布式操作系统,它旨在为不同类型的智能设备提供统一的操作系统&a…...
)
【ZZULIOJ】1003: 两个整数的四则运算(Java)
题目描述 输入两个整数num1和num2,请你设计一个程序,计算并输出它们的和、差、积、整数商及余数。 输入 输入只有两个正整数num1、num2。 输出 输出占一行,包括两个数的和、差、积、商及余数,数据之间用一个空格隔开。 样例…...

聊聊芯片原厂
芯片原厂是芯片的生产商,他们制造和设计芯片,并拥有产品的所有权原厂这个词是为了区分芯片代理商(厂)而创造的。 每一家芯片制造商都会通过自己忠诚的芯片代理商(厂)来销售自己的芯片,代理商(厂)也会打着芯片制造商的旗号来销售芯片,因此有时候为了强调自己的正统地…...
百人一岗,Android开发者的困境。。。。。
前言 在当前的Android开发领域,竞争的激烈程度已经达到了前所未有的水平,几乎到了100个开发者竞争1个岗位的地步。 这种“内卷”现象的背后,是技术的快速发展和市场对Android开发者技能要求的不断提升。随着移动应用的普及和多样化…...

若依分离版 —引入echart连接Springboot后端
1. vue引入echart (1)首先安装ECharts库。可以通过npm npm install echarts --save (2)在vue页面中添加一个容器元素来显示图表 <el-card class"mt20"><div id"ha" ref"main"><…...

Halcon深度学习项目实战
Halcon在机器视觉中的价值主要体现在提供高效、可扩展、灵活的机器视觉解决方案,帮助用户解决各种复杂的机器视觉问题,提高生产效率和产品质量。 缩短产品上市时间 Halcon的灵活架构使其能够快速开发出任何类型的机器视觉应用。其全球通用的集成开发环…...

子类中的方法去调用父类中的方法有几种形式?原生django如何向响应头写入数据
1 子类中的方法去调用父类中的方法有几种形式 2 原生django如何向响应头写入数据 1 子类中的方法去调用父类中的方法有几种形式? class Animal:def eat(self):print(self.name, 在吃饭)class Dog(Animal):def __init__(self, name):self.name namedef test(self):#…...

数据安全治理框架构建
一、引言 在数字化时代,数据已成为企业和社会发展的重要驱动力。然而,随着数据量的激增和数据应用场景的扩展,数据安全风险也日益凸显。数据安全治理作为确保数据安全、合规使用的关键手段,受到了广泛的关注。本文旨在探讨数据安…...

PC版微信小程序抓包实战:WinHTTP+Proxifier+Burp精准拦截方案
1. 为什么PC版微信小程序抓包非得绕开模拟器?很多人一提“抓PC微信小程序的包”,第一反应就是开个安卓模拟器,装个微信PC版的APK,再配个Fiddler或者Charles——这路子没错,但实操起来全是坑。我去年帮三个客户做小程序…...
)
手把手教你用N32G435的DMA‘传输过半中断’实现软件双缓冲(附2.5M波特率测试代码)
N32G435 DMA传输过半中断实现高负载串口通信的工程实践 在嵌入式系统开发中,高效处理高速串口数据流一直是工程师面临的挑战。当数据速率达到兆波特级别时,传统的中断驱动方式往往会导致CPU资源耗尽,系统响应迟缓。本文将深入探讨如何利用N32…...

别再为Tesseract中文识别报错发愁了!手把手教你搞定chi_sim语言包和环境变量配置
Tesseract中文识别实战:从报错排查到精准配置的全流程指南 当你在终端兴奋地输入第一行Tesseract命令,却看到刺眼的Failed loading language chi_sim报错时,那种挫败感我深有体会。这个看似简单的错误背后,往往隐藏着路径配置、文…...

昇腾CANN asc-devkit:开发者工具包的核心能力和工程化实践
asc-devkit 是 CANN 开发者工具包的入口——它是一个命令行工具,也是一套 IDE 插件,还打包了所有开发所需的脚本和模板。定位类似于 NVIDIA 的 nsys(性能分析) nvcc(编译器封装) 项目脚手架工具,…...

山东甲亢专治医院哪个好
近年来,甲状腺疾病发病率呈上升趋势,甲亢因其症状多样、影响广泛,成为困扰许多人的健康问题。面对这一状况,如何在山东地区选择一家专业、可靠的医院进行诊治,是众多患者及家属关心的核心问题。专业的诊疗不仅关乎症状…...

浙大联合腾讯让AI“看懂“三维世界
这项由浙江大学、腾讯混元大模型团队、香港科技大学及深圳湾区研究院联合完成的研究,以预印本形式发布于2026年5月,论文编号为arXiv:2605.15876,有兴趣深入了解的读者可通过该编号查询完整论文。当你拿起手机拍下一张客厅照片,现在…...

HALAR® ECTFE光滑内壁:脱硫塔里,石膏垢为什么不贴它
苏福(深圳)科技有限公司 世索科HALAR ECTFE官方代理商一、脱硫塔结垢这事,运行维护的人最头疼湿法烟气脱硫(WFGD)系统里,脱硫塔内壁、除雾器、浆液循环管道,天天泡在含硫酸钙、亚硫酸钙的浆液里…...

Node.js 服务端应用无缝集成 Taotoken API 的实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 服务端应用无缝集成 Taotoken API 的实践 对于 Node.js 后端开发者而言,将大模型能力集成到服务中已成为提升应…...

在Nodejs后端服务中集成稳定可靠的大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成稳定可靠的大模型能力 应用场景类,针对需要构建智能对话或内容生成功能的后端工程师࿰…...

【入门+总结】万字复盘黑马点评|从业务到 Redis 实战,面试直接背
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...