Python学习之-正则表达式
目录
- 前言:
- 1.re.serach
- 1.1例子:
- 2.re.match
- 2.1示例1:
- 2.2 示例2:
- 3.re.findall
- 3.1 示例
- 4.re.fullmatch
- 4.1 示例1:
- 4.2 示例2:
- 5.re.split
- 5.1 示例1:
- 5.2 示例2:
- 5.3 示例3:
- 6.re.sub
- 6.1 示例:
- 7.re.compile
- 7.1 示例:
- 8 总结
前言:
在python中使用的是re模块对正则表达式提供支持,下面我来讲解一些日常中比较常用的几种正则表达式的方法,希望对各位日常的工作中有帮助。
常见的正则表达式的操作:
\d
匹配任何十进制数字,相当于[0-9]。
示例:\d+ 匹配一个或多个连续的数字。
\D
匹配任何非数字字符,相当于[^0-9]。
\w
匹配任何字母数字字符,包括下划线,相当于[A-Za-z0-9_]。
示例:\w+ 匹配一个或多个字母数字字符或下划线。
\W
匹配任何非字母数字字符,不包括下划线,相当于[^A-Za-z0-9_]。
\s
匹配任何空白字符,包括空格、制表符、换页符等,相当于[ \t\n\r\f\v]。
\S
匹配任何非空白字符,相当于[^ \t\n\r\f\v]。
. (点)
匹配除换行符以外的任何单个字符。
[…]
匹配方括号内的任何单个字符。例如,[abc] 会匹配"a"、“b"或"c”。
[^…]
匹配不在方括号内的任何单个字符。例如,[^abc] 会匹配任何不是"a"、"b"或"c"的字符。
| (竖线)
A|B可以匹配A或B,所以(P|p)ython可以匹配"Python"或"python"。
^
匹配字符串的开始。在多行模式中,它还可以匹配每一行的开头。
$
匹配字符串的结尾。在多行模式中,它还可以匹配每一行的结尾。
*
匹配前面的子表达式零次或多次。例如,bo* 可以匹配 “b”、“bo” 或 “booo”。
+
匹配前面的子表达式一次或多次。例如,bo+ 可以匹配 “bo” 或 “booo”,但不会匹配 “b”。
?
匹配前面的子表达式零次或一次。例如,bo? 可以匹配 “b” 或 “bo”。
{n}
精确匹配 n 次前面的子表达式。例如,o{2} 不能匹配 “Bob” 中的 “o”,但能匹配 “food” 中的两个 o。
{n,}
匹配前面的子表达式至少 n 次。
{n,m}
匹配前面的子表达式至少 n 次,但不超过 m 次。
有需要详细了解的可以看re的官方文档:
re正则表达式操作
1.re.serach
该方法会根据传入的正则去扫描整个字符串,若能找到对应的子字符串,则返回该Match对象,否则返回None。这里返回的Match对象保存的是从左到右匹配到的第一个子字符串的信息。
re.search(pattern, string, flags=0)
1.1例子:
import re
result = re.search(r'\d+', 'abc123def')
if result:print(result.group()) # 输出: 123
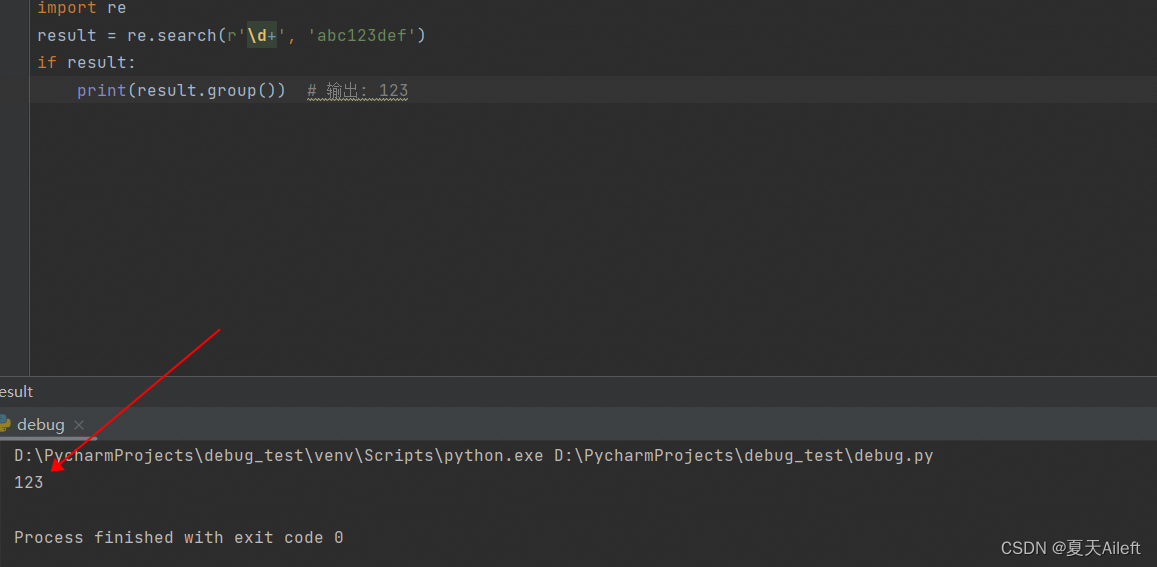
注意:下图显示 re.serach 这里他只会匹配从左到右第一个连续的数字,第二个不会匹配到
2.re.match
这个方法从字符串的开始处进行匹配,如果匹配成功,返回一个匹配对象;失败则返回None。
re.match(pattern, string, flags=0)
pattern 表示传进来的正则表达式
string 表示被匹配的字符串
flags 正则表达式匹配的模式
2.1示例1:
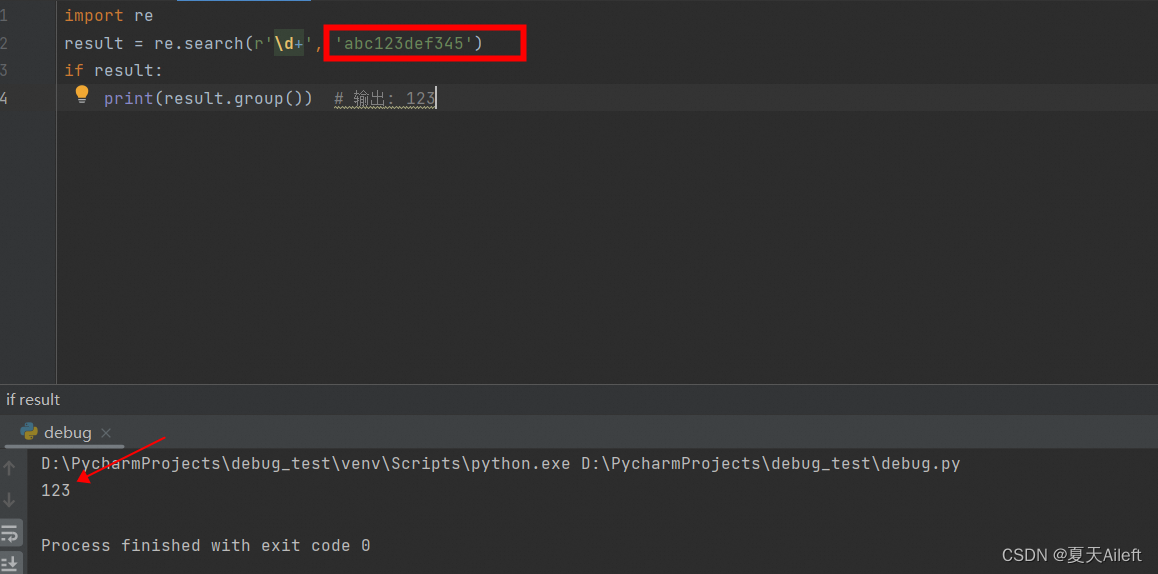
import re
result = re.match(r'\d+', '123abc')
if result:print(result.group()) # 输出: 123

2.2 示例2:
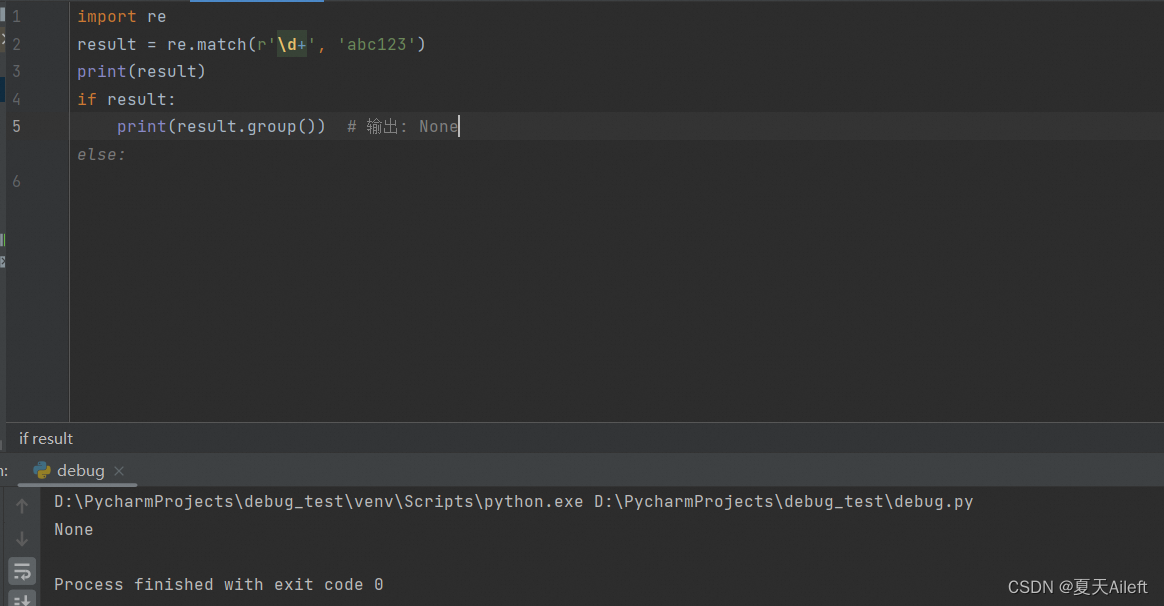
import re
result = re.match(r'\d+', 'abc123')
print(result)
if result:print(result.group()) # 输出: None
Match对象是一个包含关于搜索和结果的信息的特殊类型的对象。为了获取实际匹配的字符串,你需要调用Match对象的.group()方法。.group()方法返回模式匹配的子串。
Match对象的.group()方法可以接受一个或多个参数(称为group numbers)。如果没有提供参数,.group()方法默认返回第0组,即整个匹配的字符串。
示例:
import repattern = r"(\d+).(\d+)"
match = re.match(pattern, "123.456")if match:# 获取整个匹配的字符串print(match.group()) # 输出: "123.456"# 获取第一个括号内匹配的分组(组1)print(match.group(1)) # 输出: "123"# 获取第二个括号内匹配的分组(组2)print(match.group(2)) # 输出: "456"
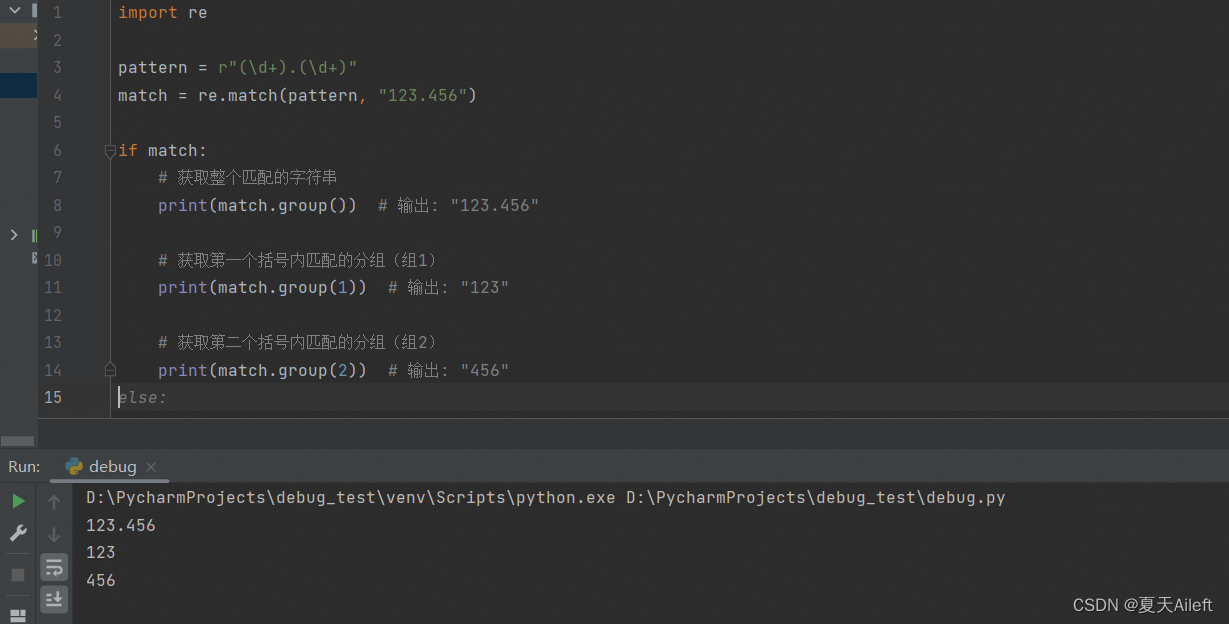
在上面的例子中,我们使用了两组括号来创建两个分组:
(\d+) 第一个分组匹配一个或多个数字。
(\d+) 第二个分组再次匹配一个或多个数字。
当我们调用.group()方法时:
.group() 或 .group(0) 返回整个匹配的字符串,即"123.456"。
.group(1) 返回第一个分组匹配的字符串,即"123"。
.group(2) 返回第二个分组匹配的字符串,即"456"。
3.re.findall
找到字符串中所有非重叠匹配的列表。意思就是
pattern 没有捕获组的话,该方法会返回所有匹配结果的list
pattern 包含一个或多个捕获组的话,list保存的结果是这些捕获组的匹配结果,且list里面的各项都是一个tuples
re.findall(pattern, string, flags=0)
3.1 示例
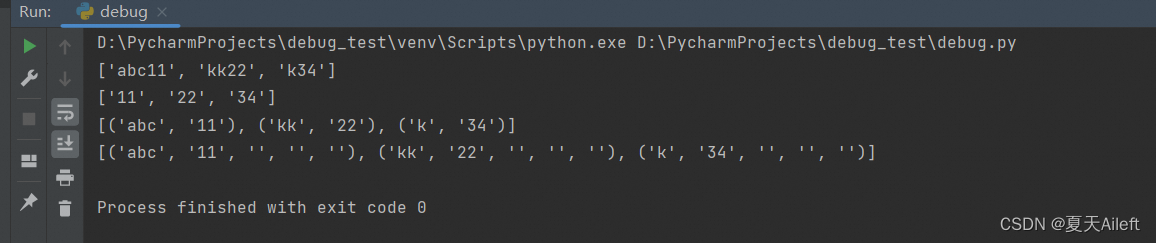
import re
result=re.findall(r"[a-z]+\d+","abc11kk22k34")
print(result)
# 匹配一个或多个小写字母 [a-z]+ 后面跟一个或多个数字 \d+。
# 输出: ['abc11', 'kk22', 'k34'] 因为它匹配了连续的字母和数字的组合。
result=re.findall(r"[a-z]+(\d+)","abc11kk22k34")
print(result)
#这个模式类似于第一个,但是这次数字部分被括号 (\d+) 包围,这意味着使用括号的分组功能。
# 在 findall 方法中,当模式包含分组时,只有分组内的内容会被返回。
# 输出: ['11', '22', '34'] 这是因为只有分组中的数字被返回。result=re.findall(r"([a-z]+)(\d+)","abc11kk22k34")
print(result)
# 这个模式有两个分组 ([a-z]+) 和 (\d+),分别匹配一系列字母和数字。
# 由于有两个分组,findall 会返回包含每个分组匹配的元组列表。
# 输出: [('abc', '11'), ('kk', '22'), ('k', '34')] 每对括号内的匹配分别作为元组的元素。result=re.findall(r"([a-z]+)(\d+)()()()","abc11kk22k34")
print(result)
# 这个模式现在包含两个有效的分组 ([a-z]+) 和 (\d+),以及三个空的分组 ()()()。
# 空的分组不会捕获任何内容,但它们仍然作为结果的一部分出现。
# 输出: [('abc', '11', '', '', ''), ('kk', '22', '', '', ''), ('k', '34', '', '', '')]
# 每个匹配现在都返回一个包含两个有效匹配和三个空字符串的元组。
4.re.fullmatch
该方法需要整个字符串跟正则完全匹配才会返回一个Match对象,否则返回None
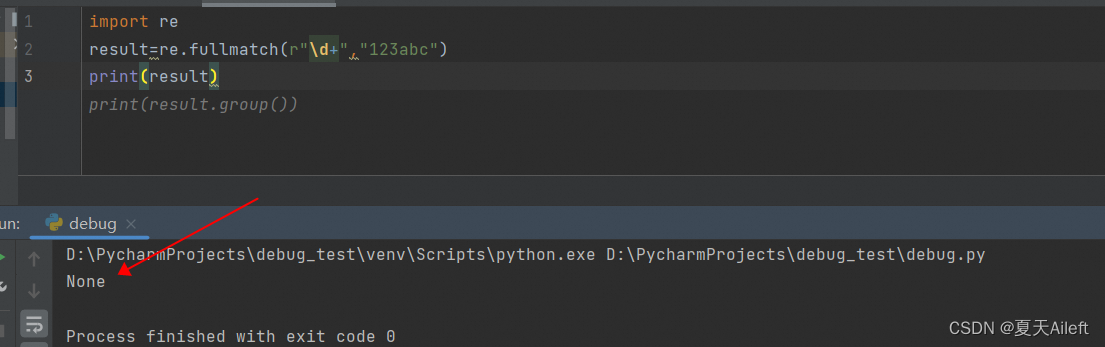
4.1 示例1:
这里需要完全匹配字符串是数字
import re
result=re.fullmatch(r"\d+","123abc")
print(result)
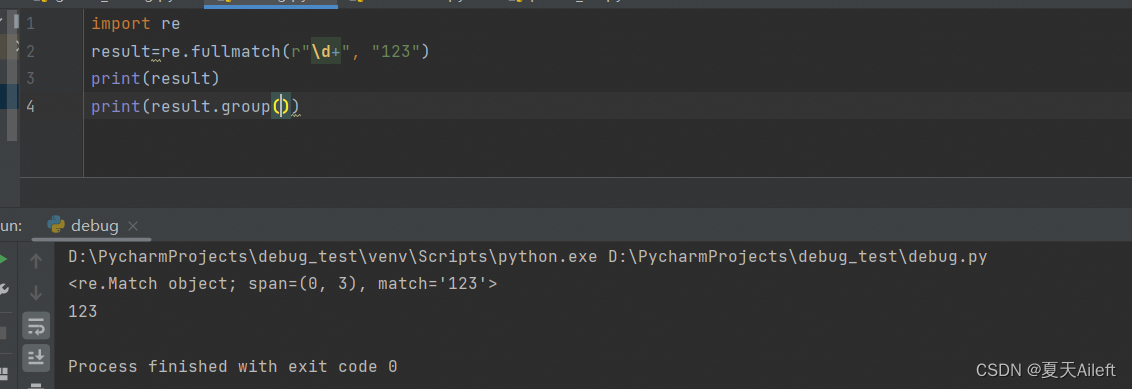
4.2 示例2:
import re
result=re.fullmatch(r"\d+", "123")
print(result)
print(result.group())
5.re.split
re.split(pattern, string, maxsplit=0, flags=0)
pattern: 这是用于分割字符串的正则表达式模式。字符串会在匹配这个模式的所有地方被分割。
string: 这是需要被分割的输入字符串。
maxsplit (可选): 这个参数指定了分割的最大次数。默认值为0,表示不限制分割次数,即分割可以在每次匹配到模式时发生。如果maxsplit被设置为一个正整数n,那么分割会在前n次匹配到模式之后停止,剩余的字符串会作为列表的最后一个元素返回。
flags (可选): 这个参数允许你指定正则表达式的一些额外选项,如忽略大小写(re.IGNORECASE)、多行模式(re.MULTILINE)等。默认值为0,表示没有特殊标志。
如果pattern没有捕获组的话,则按照正则分割后,返回一个list结果集;如果pattern里面包含捕获组的话,list结果集里面包含捕获组获取到的内容
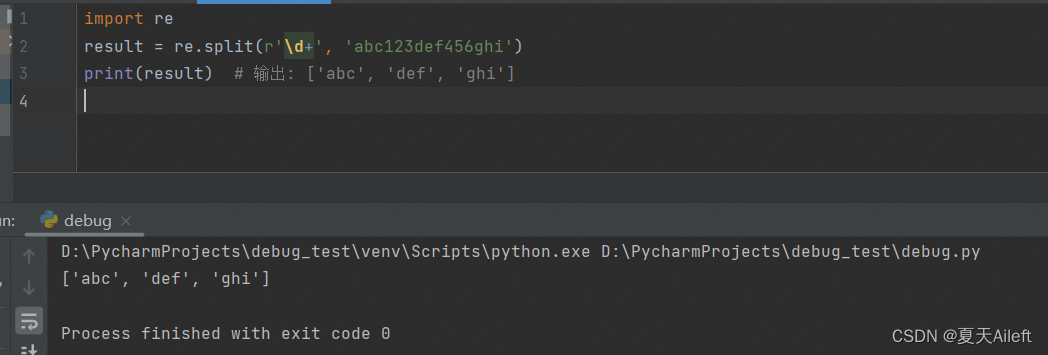
5.1 示例1:
import re
result = re.split(r'\d+', 'abc123def456ghi')
print(result) # 输出: ['abc', 'def', 'ghi']
5.2 示例2:
不带 maxsplit:
import reresult = re.split(r'\d+', 'one1two2three3four4')
print(result)
输出:

5.3 示例3:
带有 maxsplit:
import re
result = re.split(r’\d+', ‘one1two2three3four4’, maxsplit=2)
print(result)
输出:

在这个例子中,由于maxsplit被设置为2,所以分割只在前两次匹配到数字时发生,剩余的字符串(‘three3four4’)作为列表的最后一个元素返回。
6.re.sub
re.sub(pattern, repl, string, count=0, flags=0)
pattern: 一个字符串或者一个预编译的正则表达式对象(通过 re.compile 创建)。这是你想要在原始字符串中查找的正则表达式模式。
repl: 替换匹配项的字符串或者一个函数。如果是一个字符串,任何正则表达式中的分组引用(如 \1, \2 等)都会被匹配项中对应的分组替换。如果是一个函数,它应该接受一个匹配对象作为参数,并返回一个用来替换的字符串。
string: 要进行搜索和替换操作的原始字符串。
count (可选): 一个表示替换次数的整数,默认为0,表示替换所有匹配项。如果指定了这个参数,则最多替换 count 次匹配。
flags (可选): 正则表达式标志,例如 re.IGNORECASE、re.MULTILINE 等。这些标志用于修改正则表达式的行为。默认为0,表示没有标志被设置。
这个方法的作用是字符串替换,其中,rep1可以是字符串,也可以是一个方法。
6.1 示例:
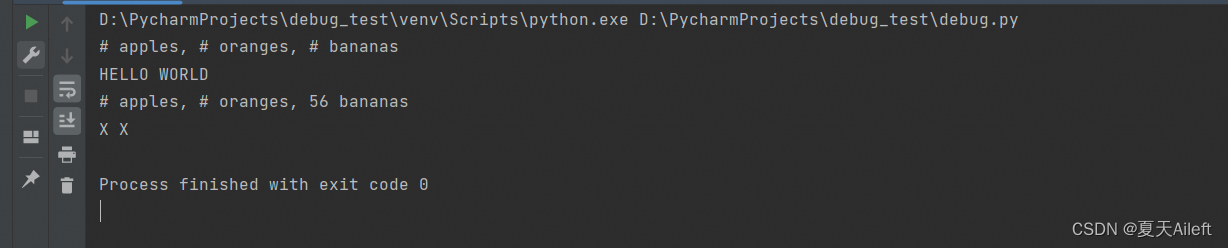
import re# 替换所有数字为 #
result = re.sub(r'\d+', '#', "12 apples, 34 oranges, 56 bananas")
print(result) # 输出: "# apples, # oranges, # bananas"# 使用函数来替换匹配项
def to_upper(match):return match.group().upper()result = re.sub(r'[a-z]+', to_upper, "hello world")
print(result) # 输出: "HELLO WORLD"# 替换前两个匹配项
result = re.sub(r'\d+', '#', "12 apples, 34 oranges, 56 bananas", count=2)
print(result) # 输出: "# apples, # oranges, 56 bananas"# 使用标志忽略大小写
result = re.sub(r'[a-z]+', 'X', "Hello World", flags=re.IGNORECASE)
print(result) # 输出: "X X"输出结果:
7.re.compile
编译正则,返回一个Pattern对象。 这样做的目的是可以重复使用该正则模式对象
pattern: 正则表达式字符串,即你希望编译的模式。
flags (可选): 正则表达式标志,可以改变正则表达式的行为。常见的标志包括:
re.IGNORECASE 或 re.I: 使匹配对大小写不敏感。
re.MULTILINE 或 re.M: 影响 ^ 和 $ 的行为。^ 匹配每一行的开始,$ 匹配每一行的结束,而不仅是整个字符串的开始和结束。
re.DOTALL 或 re.S: 使.(点)特殊字符匹配任何字符,包括换行符。
re.UNICODE 或 re.U: 根据Unicode字符属性数据库使 \w, \W, \b, \B, \d, \D, \s 和 \S 起作用。
re.ASCII 或 re.A: 使 \w, \W, \b, \B, \d, \D, \s 和 \S 只匹配ASCII字符。
re.LOCALE 或 re.L: 使 \w, \W, \b, \B, \s 和 \S 受当前区域设置的影响(不推荐使用,因为re.UNICODE通常是更好的选择)。
re.VERBOSE 或 re.X: 允许你通过忽略空白和添加注释来编写更易读的正则表达式。
7.1 示例:
import re# 编译一个正则表达式对象
pattern = re.compile(r'\d+', flags=re.IGNORECASE)# 使用编译后的对象进行匹配操作
match = pattern.match("123abc")if match:print(match.group()) # 输出: 123# 使用编译后的对象进行搜索操作
search = pattern.search("abc123def")if search:print(search.group()) # 输出: 123# 使用编译后的对象进行查找所有匹配项的操作
findall = pattern.findall("123abc456def")print(findall) # 输出: ['123', '456']
输出

8 总结
re.search, re.match, 和 re.findall 是Python中用于正则表达式匹配的三个不同的函数,它们有着不同的用途和行为。下面是每个函数的作用、相似之处和不同之处:
re.search(pattern, string, flags=0)
作用: 在字符串中查找第一个匹配正则表达式pattern的位置。
返回: 如果找到匹配,返回一个Match对象;如果没有找到匹配,则返回None。
行为: re.search会扫描整个字符串,直到找到一个匹配项。
re.match(pattern, string, flags=0)
作用: 从字符串的开始处检查是否有匹配正则表达式pattern的内容。
返回: 如果字符串开始的字符匹配正则表达式,返回一个Match对象;如果不匹配或匹配不是在字符串的开始处,返回None。
行为: re.match仅在字符串的开始处进行匹配检查。
re.findall(pattern, string, flags=0)
作用: 查找字符串中所有匹配正则表达式pattern的非重叠匹配项。
返回: 返回一个列表,包含所有匹配项的字符串。如果正则表达式中包含了一个或多个捕获组,将返回一个元组列表。
行为: re.findall会扫描整个字符串,并返回所有匹配的完整列表。
相同点
它们都是re模块提供的函数,用于执行正则表达式匹配。
它们都可以接受flags参数,该参数可以改变正则表达式的行为(如忽略大小写等)。
它们都从左到右扫描字符串进行匹配。
不同点
re.match只在字符串的起始处检查匹配,而re.search在整个字符串中搜索第一个匹配项。
re.findall返回的是一个列表,包含所有的匹配项,而re.match和re.search返回的是Match对象。
如果正则表达式包含捕获组,re.match和re.search返回的Match对象可以通过.group()方法访问各个捕获组,而re.findall将直接返回一个包含捕获组内容的元组列表。
相关文章:
Python学习之-正则表达式
目录 前言:1.re.serach1.1例子: 2.re.match2.1示例1:2.2 示例2: 3.re.findall3.1 示例 4.re.fullmatch4.1 示例1:4.2 示例2: 5.re.split5.1 示例1:5.2 示例2:5.3 示例3: 6.re.sub6.1 示例&#…...
Godot.NET C# 工程化开发(1):通用Nuget 导入+ 模板文件导出,包含随机数生成,日志管理,数据库连接等功能
文章目录 前言Github项目地址,包含模板文件后期思考补充项目设置编写失误环境visual studio 配置详细的配置看我这篇文章 Nuget 推荐NewtonSoft 成功Bogus 成功Github文档地址随机生成构造器生成构造器接口(推荐) 文件夹设置Nlog 成功!Nlog.configNlogHe…...

数据仓库——雪花模式以及层次递归
层次结构 钻取 向下钻取:对某些代表事实的报表中添加维度细节 向上钻取:从某些代表事实的报表中去除维度细节 属性层次 提供了一种自然方法,用于顺序地在不断深入的层次上组织事实。许多维度可以被理解为包含连续主从关系的属性层次。此类…...
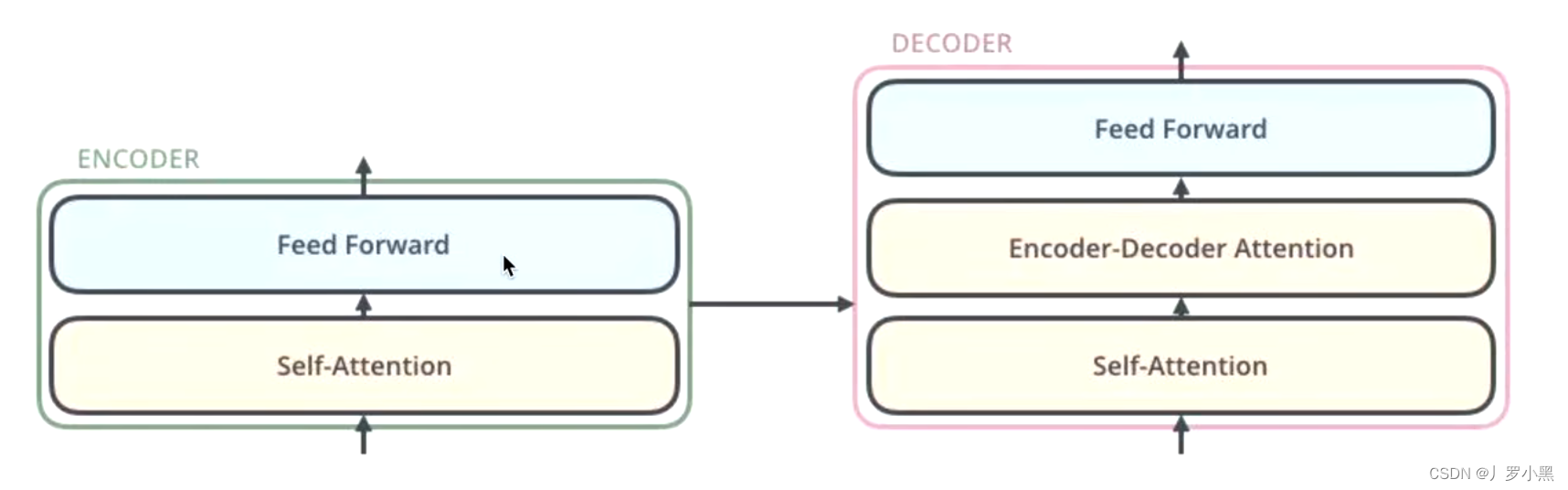
Transformer的前世今生 day09(Transformer的框架概述)
前情提要 编码器-解码器结构 如果将一个模型分为两块:编码器和解码器那么编码器-解码器结构为:编码器负责处理输入,解码器负责生成输出流程:我们先将输入送入编码器层,得到一个中间状态state,并送入解码器…...
Qt 压缩/解压文件
前面讲了很多Qt的文件操作,文件操作自然就包括压缩与解压缩文件了,正好最近项目里要用到压缩以及解压缩文件,所以就研究了一下Qt如何压缩与解压缩文件。 QZipReader/QZipWriter QZipReader 和 QZipWriter 类提供了用于读取和写入 ZIP 格式文…...
——位运算+数学+一维动态规划+多维动态规划)
【leetcode刷题之路】面试经典150题(8)——位运算+数学+一维动态规划+多维动态规划
文章目录 20 位运算20.1 【位运算】二进制求和20.2 【位运算】颠倒二进制位20.3 【位运算】位1的个数20.4 【位运算】只出现一次的数字20.5 【哈希表】【位运算】只出现一次的数字 II20.6 【位运算】数字范围按位与 21 数学21.1 【双指针】回文数21.2 【数学】加一21.3 【数学】…...
JetBrains全家桶激活,分享 WebStorm 2024 激活的方案
大家好,欢迎来到金榜探云手! WebStorm公司简介 JetBrains 是一家专注于开发工具的软件公司,总部位于捷克。他们以提供强大的集成开发环境(IDE)而闻名,如 IntelliJ IDEA、PyCharm、和 WebStorm等。这些工具…...
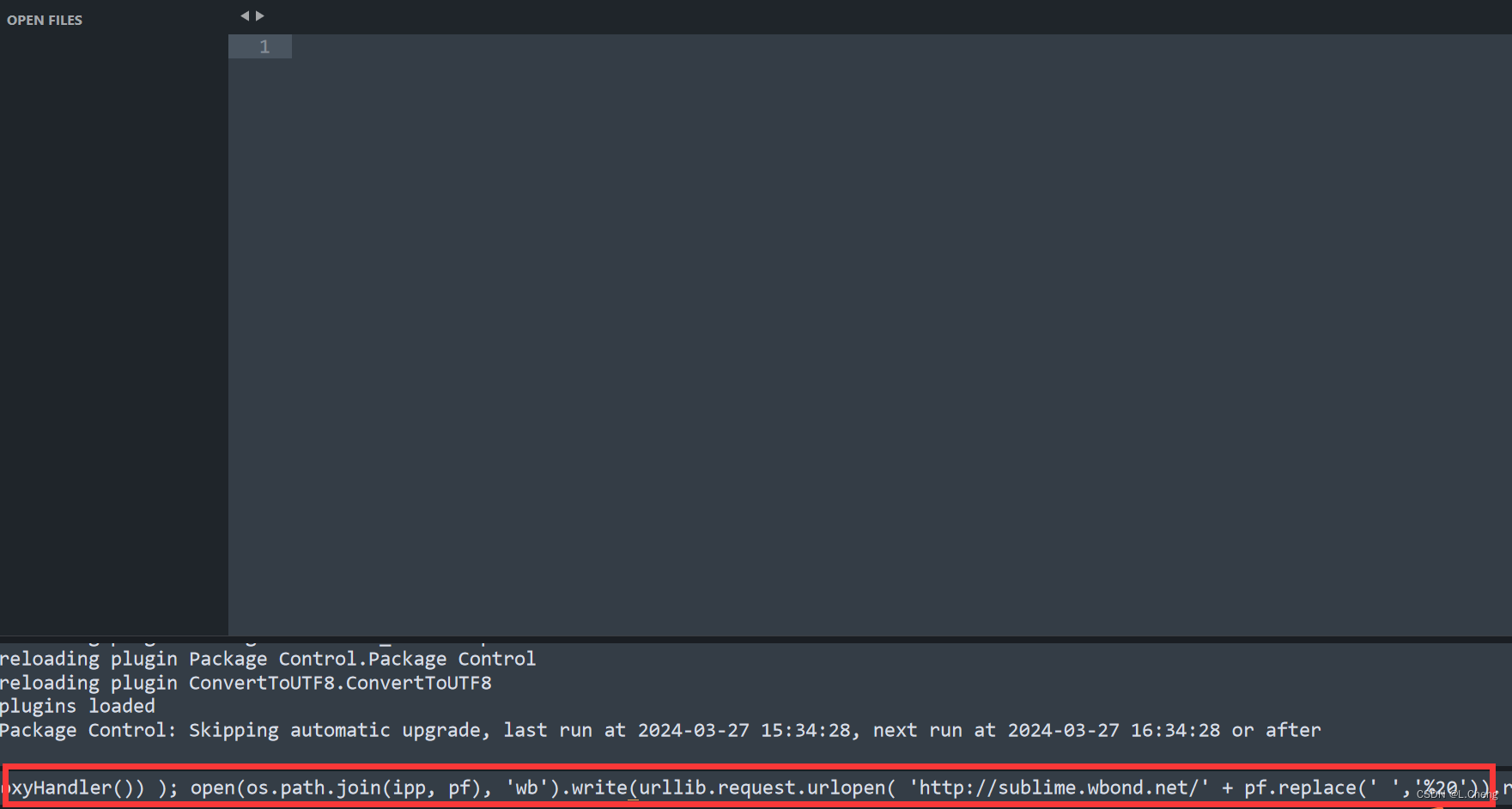
Sublime 彻底解决中文乱码
1. 按ctrl,打开Console,输入如下代码: import urllib.request,os; pf Package Control.sublime-package; ipp sublime.installed_packages_path(); urllib.request.install_opener( urllib.request.build_opener( urllib.request.ProxyHand…...

复旦大学EMBA校友出席两会建言献策助力中国发展
阳春三月,备受瞩目的全国两会如期召开。期间,复旦大学EMBA多位校友作为第十四届全国人民代表大会代表、第十四届全国政协委员与全国各地代表共商国是。 无论是作为大型央企负责人,还是作为科创企业的中坚力量,复旦大学EM…...
virtualbox导入vdi
新建虚拟机 点击新建 输入新建属性 配置cpu和内存 虚拟硬盘 这里选择已有的vdi文件 摘要 这里点击完成 虚拟机添加成功 点击启动,启动虚拟机 注意 这个时候的ip,还是以前镜像的ip,如果两个镜像一起启动,则需要修 改ip地…...

【信号处理】基于DGGAN的单通道脑电信号增强和情绪检测(tensorflow)
关于 情绪检测,是脑科学研究中的一个常见和热门的方向。在进行情绪检测的分类中,真实数据不足,经常导致情绪检测模型的性能不佳。因此,对数据进行增强,成为了一个提升下游任务的重要的手段。本项目通过DCGAN模型实现脑…...

使用 Docker Compose 部署 Spring Boot 应用
使用 Docker Compose 部署 Spring Boot 应用 第一步:创建 Spring Boot 应用的 Dockerfile 在您的 Spring Boot 项目根目录中创建一个 Dockerfile。 编辑 Dockerfile,添加以下内容: # 基础镜像使用 OpenJDK FROM openjdk:11-jdk-slim# 维护者…...

nginx 正向代理 https
问题背景 因为网络环境受限,应用服务器无法直接访问外网,需要前置机上中转一下,这种情况可在应用服务器修改/etc/hosts文件指向前置机,在前置机上的nginx设置四层代理,从而出站。 方案 根据How to Use NGINX as an …...

vue3从其他页面跳转页面头部组件菜单el-menu菜单高亮
主要代码 import { ref, onMounted, watch } from vue; const activeIndex ref("/"); const route useRoute();onMounted(() > {updateActiveMenu(); });watch(() > route.path, updateActiveMenu);function updateActiveMenu() {// 根据路由更新activeMenu…...

python 条件循环语句
python 条件循环语句 一、条件控制语句1. Python3 条件控制2. if 语句3. if 嵌套4. match...case5. 注意: 二、循环控制语句1. Python3 循环语句2. while 循环3. 无限循环4. while 循环使用 else 语句5. 简单语句组6. for 语句7. for...else8. break 和 continue 语…...
CIM搭建实现发送消息的效果
目录 背景过程1、下载代码2、进行配置3、直接启动项目4、打开管理界面5、启动web客户端实例项目6、发送消息 项目使用总结 背景 公司项目有许多需要发送即时消息的场景,之前一直采用的是传统的websocket连接,它会存在掉线严重,不可重连&…...
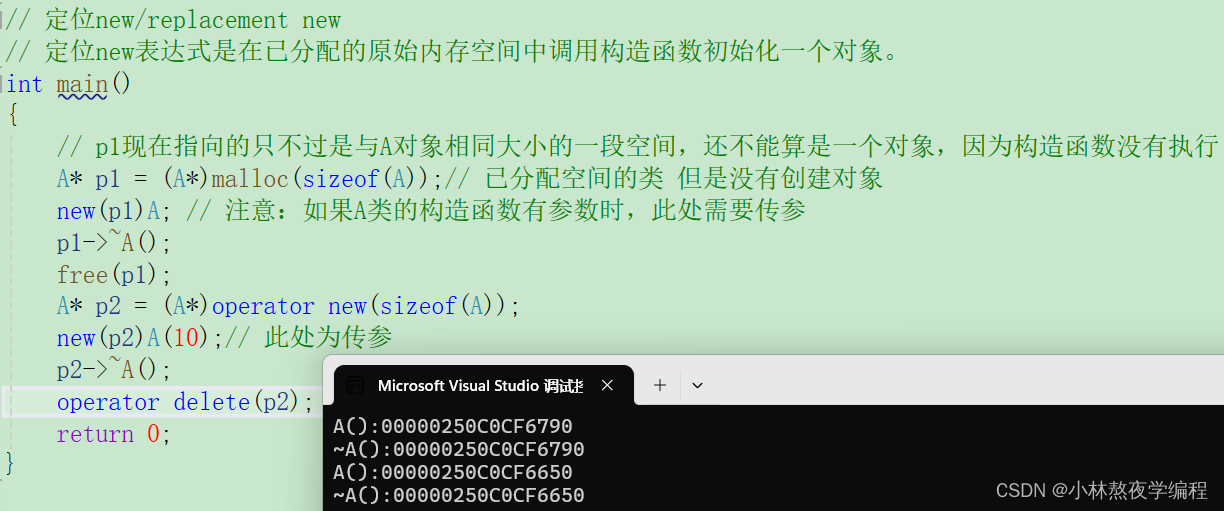
C++第十三弹---内存管理(下)
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】【C详解】 目录 1、operator new与operator delete函数 1.1、operator new与operator delete函数 2、new和delete的实现原理 2.1、内置类型 2.2、自定义类型 …...
Python爬虫学习完整版
一、什么是爬虫 网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本。由于互联网数据的多样性和资源的有限性,根据用户需求定向抓取相关网页并分析也成为如今主流的爬取策略。 1 爬虫可以做什么 你可以爬取网络上的的图片&#…...
JavaScript中的继承方式详解
Question JavaScript实现继承的方式? 包含原型链继承、构造函数继承、组合继承、原型式继承、寄生式继承、寄生组合式继承和ES6 类继承 JavaScript实现继承的方式 在JavaScript中,实现继承的方式多种多样,每种方式都有其优势和适用场景。以下…...
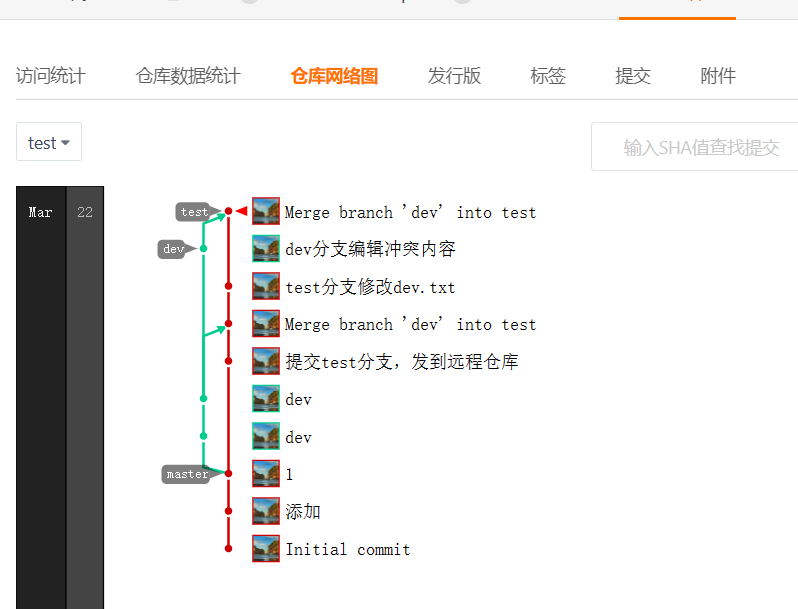
Git基础(23):Git分支合并实战保姆式流程
文章目录 前言准备正常分支合并1. 创建两个不冲突分支2. 将dev合并到test 冲突分支合并1. 制造分支冲突2. 冲突合并 前言 Git分支合并操作 准备 这里先在Gitee创建了一个空仓库,方便远程查看内容。 正常分支合并 1. 创建两个不冲突分支 (1…...

PS 图片模糊修复教程:4 种方法,一键变高清
在日常设计、摄影后期、电商运营等场景中,模糊图片往往会严重影响观感与使用效果——无论是拍摄时的对焦失误、低分辨率素材的压缩失真,还是老照片的模糊褪色,都需要快速恢复清晰度。本文整理4种超实用的图片清晰化方法,涵盖PS原生…...

Agent 一接 MCP 大结果集就开始失忆:从 Result Summarization 到 Cursor Paging 的工程实战
一、MCP 一接大结果集,Agent 最先坏掉的不是推理,而是记忆 🧠 很多团队把 MCP 当成 Agent 的万能扩展层:只要把数据库、工单、代码检索、指标平台都挂进去,模型就能“边查边做”。真正上线后最先暴露的问题却很一致&am…...
第1小节:光学物镜核心原理)
0601光刻机 第六篇:EUV超精密光学系统(S级 长期死磕突破)第1小节:光学物镜核心原理
第六篇:EUV超精密光学系统(S级 长期死磕突破) 第1小节:光学物镜核心原理(硬核无水分,从物理本质到工程实现) 前置硬核声明 EUV物镜是光刻机的“原子级眼睛”,13.5nm波长决定透射方案…...

2026年数字孪生升级版:三维重构透明建筑实时重构跟踪定位
2026数字孪生升级:三维重构透明建筑实时重构跟踪定位结合2026年数字孪生技术前沿迭代趋势,围绕实景三维重构、建筑透明可视化、场景实时重构、全域跟踪定位四大核心能力,完成新一代数字孪生体系技术升级。彻底解决传统数字孪生静态滞后、建筑…...

番茄小说下载器终极指南:三步打造你的私人数字图书馆
番茄小说下载器终极指南:三步打造你的私人数字图书馆 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在深夜追更小说时突然断网?或者想在地铁上继续阅读却发…...

创业公司如何借助 Taotoken 的多模型聚合能力快速验证产品 AI 功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业公司如何借助 Taotoken 的多模型聚合能力快速验证产品 AI 功能 对于资源有限的创业团队而言,在产品早期快速验证核…...

CANN 模型转换与适配:从 PyTorch 到 Ascend OM 的完整指南
模型转换是昇腾落地的第一道坎。不管你用 PyTorch、TensorFlow 还是 MindSpore,最终都要变成 Ascend 的 .om 模型才能在 NPU 上跑。 这篇文章讲清楚:模型转换的完整流程、常见问题和优化技巧。 为什么需要模型转换? 昇腾 NPU 不能直接运行 Py…...

SSH密钥不能直接访问phpMyAdmin:正确使用隧道方案
1. 这个标题里藏着三个根本性误解,先说清楚再动手 “如何安全的使用ssh秘钥访问phpmyadmin”——这句话本身就是一个典型的认知错位组合。我第一次在客户现场看到这个需求时,花了一整个下午才把技术逻辑理顺。 phpMyAdmin 本质上是一个运行在 Web 服务器…...

Prism Launcher:重新定义你的Minecraft启动体验
Prism Launcher:重新定义你的Minecraft启动体验 【免费下载链接】PrismLauncher A custom launcher for Minecraft that allows you to easily manage multiple installations of Minecraft at once (Fork of MultiMC) 项目地址: https://gitcode.com/gh_mirrors/…...

从鸟群到AI:Parisi的复本对称破缺,如何成为理解复杂世界的通用钥匙?
无序中的秩序:复本对称破缺如何重塑复杂系统认知 1. 从自旋玻璃到普适范式 1975年的一个寒冷冬日,物理学家Giorgio Parisi在罗马大学的办公室里凝视着杂乱的计算手稿。他当时可能并未意识到,自己即将揭开复杂系统科学最深刻的奥秘之一——复本…...