flink-connector-redis支持select查询
EN
1 项目介绍
基于bahir-flink二次开发,相对bahir调整的内容有:
1.使用Lettuce替换Jedis,同步读写改为异步读写,大幅度提升了性能
2.增加了Table/SQL API,增加select/维表join查询支持
3.增加关联查询缓存(支持增量与全量)
4.增加支持整行保存功能,用于多字段的维表关联查询
5.增加限流功能,用于Flink SQL在线调试功能
6.增加支持Flink高版本(包括1.12,1.13,1.14+)
7.统一过期策略等
8.支持flink cdc删除及其它RowKind.DELETE
9.支持select查询
因bahir使用的flink接口版本较老,所以改动较大,开发过程中参考了腾讯云与阿里云两家产商的流计算产品,取两家之长,并增加了更丰富的功能。
注:redis不支持两段提交无法实现刚好一次语义。
2 使用方法:
2.1 工程直接引用
项目依赖Lettuce(6.2.1)及netty-transport-native-epoll(4.1.82.Final),如flink环境有这两个包,则使用flink-connector-redis-1.3.2.jar,
否则使用flink-connector-redis-1.4.1-jar-with-dependencies.jar。
<dependency><groupId>io.github.jeff-zou</groupId><artifactId>flink-connector-redis</artifactId><!-- 没有单独引入项目依赖Lettuce netty-transport-native-epoll依赖时 --><!-- <classifier>jar-with-dependencies</classifier>--><version>1.4.1</version>
</dependency>
2.2 自行打包
打包命令: mvn package -DskipTests,将生成的包放入flink lib中即可,无需其它设置。
2.3 使用示例
-- 创建redis表示例
create table redis_table (name varchar, age int) with ('connector'='redis', 'host'='10.11.69.176', 'port'='6379','password'='test123', 'redis-mode'='single','command'='set');
-- 写入 insert into redis_table select * from (values('test', 1));-- 查询 insert into redis_table select name,age + 1 from redis_table /*+ options('scan.key'='test') */create table gen_table (age int , level int, proctime as procTime()) with ('connector'='datagen','fields.age.kind' = 'sequence','fields.age.start' = '2','fields.age.end' = '2','fields.level.kind' = 'sequence','fields.level.start' = '10','fields.level.end' = '10'); -- 关联查询
insert into redis_table select 'test', j.age + 10 from gen_table s left join redis_table for system_time as of proctime as j
on j.name = 'test'3 参数说明:
3.1 主要参数:
| 字段 | 默认值 | 类型 | 说明 |
|---|---|---|---|
| connector | (none) | String | redis |
| host | (none) | String | Redis IP |
| port | 6379 | Integer | Redis 端口 |
| password | null | String | 如果没有设置,则为 null |
| database | 0 | Integer | 默认使用 db0 |
| timeout | 2000 | Integer | 连接超时时间,单位 ms,默认 1s |
| cluster-nodes | (none) | String | 集群ip与端口,当redis-mode为cluster时不为空,如:10.11.80.147:7000,10.11.80.147:7001,10.11.80.147:8000 |
| command | (none) | String | 对应上文中的redis命令 |
| redis-mode | (none) | Integer | mode类型: single cluster sentinel |
| lookup.cache.max-rows | -1 | Integer | 查询缓存大小,减少对redis重复key的查询 |
| lookup.cache.ttl | -1 | Integer | 查询缓存过期时间,单位为秒, 开启查询缓存条件是max-rows与ttl都不能为-1 |
| lookup.cache.load-all | false | Boolean | 开启全量缓存,当命令为hget时,将从redis map查询出所有元素并保存到cache中,用于解决缓存穿透问题 |
| max.retries | 1 | Integer | 写入失败重试次数 |
| value.data.structure | column | String | column: value值来自某一字段 (如, set: key值取自DDL定义的第一个字段, value值取自第二个字段) row: 将整行内容保存至value并以’\01’分割 |
| set.if.absent | false | Boolean | 在key不存在时才写入,只对set hset有效 |
| io.pool.size | (none) | Integer | Lettuce内netty的io线程池大小,默认情况下该值为当前JVM可用线程数,并且大于2 |
| event.pool.size | (none) | Integer | Lettuce内netty的event线程池大小 ,默认情况下该值为当前JVM可用线程数,并且大于2 |
| scan.key | (none) | String | 查询时redis key |
| scan.addition.key | (none) | String | 查询时限定redis key,如map结构时的hashfield |
| scan.range.start | (none) | Integer | 查询list结构时指定lrange start |
| scan.range.stop | (none) | Integer | 查询list结构时指定lrange start |
| scan.count | (none) | Integer | 查询set结构时指定srandmember count |
3.1.1 command值与redis命令对应关系:
| command值 | 写入 | 查询 | 维表关联 | 删除(Flink CDC等产生的RowKind.delete) |
|---|---|---|---|---|
| set | set | get | get | del |
| hset | hset | hget | hget | hdel |
| get | set | get | get | del |
| hset | hset | hget | hget | hdel |
| rpush | rpush | lrange | ||
| lpush | lpush | lrange | ||
| incrBy incrByFloat | incrBy incrByFloat | get | get | 写入相对值,如:incrby 2 -> incryby -2 |
| hincrBy hincryByFloat | hincrBy hincryByFloat | hget | hget | 写入相对值,如:hincrby 2 -> hincryby -2 |
| zincrby | zincrby | zscore | zscore | 写入相对值,如:zincrby 2 -> zincryby -2 |
| sadd | sadd | srandmember 10 | srem | |
| zadd | zadd | zscore | zscore | zrem |
| pfadd(hyperloglog) | pfadd(hyperloglog) | |||
| publish | publish | |||
| zrem | zrem | zscore | zscore | |
| srem | srem | srandmember 10 | ||
| del | del | get | get | |
| hdel | hdel | hget | hget | |
| decrBy | decrBy | get | get |
注:为空表示不支持
3.1.2 value.data.structure = column(默认)
无需通过primary key来映射redis中的Key,直接由ddl中的字段顺序来决定Key,如:
create table sink_redis(username VARCHAR, passport VARCHAR) with ('command'='set')
其中username为key, passport为value.create table sink_redis(name VARCHAR, subject VARCHAR, score VARCHAR) with ('command'='hset')
其中name为map结构的key, subject为field, score为value.
3.1.3 value.data.structure = row
整行内容保存至value并以’\01’分割
create table sink_redis(username VARCHAR, passport VARCHAR) with ('command'='set')
其中username为key, username\01passport为value.create table sink_redis(name VARCHAR, subject VARCHAR, score VARCHAR) with ('command'='hset')
其中name为map结构的key, subject为field, name\01subject\01score为value.
3.2 sink时ttl相关参数
| Field | Default | Type | Description |
|---|---|---|---|
| ttl | (none) | Integer | key过期时间(秒),每次sink时会设置ttl |
| ttl.on.time | (none) | String | key的过期时间点,格式为LocalTime.toString(), eg: 10:00 12:12:01,当ttl未配置时才生效 |
| ttl.key.not.absent | false | boolean | 与ttl一起使用,当key不存在时才设置ttl |
3.3 在线调试SQL时,用于限制sink资源使用的参数:
| Field | Default | Type | Description |
|---|---|---|---|
| sink.limit | false | Boolean | 是否打开限制 |
| sink.limit.max-num | 10000 | Integer | taskmanager内每个slot可以写的最大数据量 |
| sink.limit.interval | 100 | String | taskmanager内每个slot写入数据间隔 milliseconds |
| sink.limit.max-online | 30 * 60 * 1000L | Long | taskmanager内每个slot最大在线时间, milliseconds |
3.4 集群类型为sentinel时额外连接参数:
| 字段 | 默认值 | 类型 | 说明 |
|---|---|---|---|
| master.name | (none) | String | 主名 |
| sentinels.info | (none) | String | 如:10.11.80.147:7000,10.11.80.147:7001,10.11.80.147:8000 |
| sentinels.password | (none) | String | sentinel进程密码 |
4 数据类型转换
| flink type | redis row converter |
|---|---|
| CHAR | String |
| VARCHAR | String |
| String | String |
| BOOLEAN | String String.valueOf(boolean val) boolean Boolean.valueOf(String str) |
| BINARY | String Base64.getEncoder().encodeToString byte[] Base64.getDecoder().decode(String str) |
| VARBINARY | String Base64.getEncoder().encodeToString byte[] Base64.getDecoder().decode(String str) |
| DECIMAL | String BigDecimal.toString DecimalData DecimalData.fromBigDecimal(new BigDecimal(String str),int precision, int scale) |
| TINYINT | String String.valueOf(byte val) byte Byte.valueOf(String str) |
| SMALLINT | String String.valueOf(short val) short Short.valueOf(String str) |
| INTEGER | String String.valueOf(int val) int Integer.valueOf(String str) |
| DATE | String the day from epoch as int date show as 2022-01-01 |
| TIME | String the millisecond from 0’clock as int time show as 04:04:01.023 |
| BIGINT | String String.valueOf(long val) long Long.valueOf(String str) |
| FLOAT | String String.valueOf(float val) float Float.valueOf(String str) |
| DOUBLE | String String.valueOf(double val) double Double.valueOf(String str) |
| TIMESTAMP | String the millisecond from epoch as long timestamp TimeStampData.fromEpochMillis(Long.valueOf(String str)) |
5 使用示例:
create table sink_redis(name varchar, level varchar, age varchar) with ( 'connector'='redis', 'host'='10.11.80.147','port'='7001', 'redis-mode'='single','password'='******','command'='hset');-- 先在redis中插入数据,相当于redis命令: hset 3 3 100 --
insert into sink_redis select * from (values ('3', '3', '100'));create table dim_table (name varchar, level varchar, age varchar) with ('connector'='redis', 'host'='10.11.80.147','port'='7001', 'redis-mode'='single', 'password'='*****','command'='hget', 'maxIdle'='2', 'minIdle'='1', 'lookup.cache.max-rows'='10', 'lookup.cache.ttl'='10', 'lookup.max-retries'='3');-- 随机生成10以内的数据作为数据源 --
-- 其中有一条数据会是: username = 3 level = 3, 会跟上面插入的数据关联 --
create table source_table (username varchar, level varchar, proctime as procTime()) with ('connector'='datagen', 'rows-per-second'='1', 'fields.username.kind'='sequence', 'fields.username.start'='1', 'fields.username.end'='10', 'fields.level.kind'='sequence', 'fields.level.start'='1', 'fields.level.end'='10');create table sink_table(username varchar, level varchar,age varchar) with ('connector'='print');insert intosink_table
selects.username,s.level,d.age
fromsource_table s
left join dim_table for system_time as of s.proctime as d ond.name = s.usernameand d.level = s.level;
-- username为3那一行会关联到redis内的值,输出为: 3,3,100
很多情况维表有多个字段,本实例展示如何利用’value.data.structure’='row’写多字段并关联查询。
-- 创建表
create table sink_redis(uid VARCHAR,score double,score2 double )
with ( 'connector' = 'redis','host' = '10.11.69.176','port' = '6379','redis-mode' = 'single','password' = '****','command' = 'SET','value.data.structure' = 'row'); -- 'value.data.structure'='row':整行内容保存至value并以'\01'分割
-- 写入测试数据,score、score2为需要被关联查询出的两个维度
insert into sink_redis select * from (values ('1', 10.3, 10.1));-- 在redis中,value的值为: "1\x0110.3\x0110.1" --
-- 写入结束 ---- create join table --
create table join_table with ('command'='get', 'value.data.structure'='row') like sink_redis-- create result table --
create table result_table(uid VARCHAR, username VARCHAR, score double, score2 double) with ('connector'='print')-- create source table --
create table source_table(uid VARCHAR, username VARCHAR, proc_time as procTime()) with ('connector'='datagen', 'fields.uid.kind'='sequence', 'fields.uid.start'='1', 'fields.uid.end'='2')-- 关联查询维表,获得维表的多个字段值 --
insertintoresult_table
selects.uid,s.username,j.score, -- 来自维表j.score2 -- 来自维表
fromsource_table as s
join join_table for system_time as of s.proc_time as j onj.uid = s.uidresult:
2> +I[2, 1e0fe885a2990edd7f13dd0b81f923713182d5c559b21eff6bda3960cba8df27c69a3c0f26466efaface8976a2e16d9f68b3, null, null]
1> +I[1, 30182e00eca2bff6e00a2d5331e8857a087792918c4379155b635a3cf42a53a1b8f3be7feb00b0c63c556641423be5537476, 10.3, 10.1]
-
5.3 DataStream查询方式
示例代码路径: src/test/java/org.apache.flink.streaming.connectors.redis.datastream.DataStreamTest.java
hset示例,相当于redis命令:hset tom math 150
Configuration configuration = new Configuration();configuration.setString(REDIS_MODE, REDIS_CLUSTER);configuration.setString(REDIS_COMMAND, RedisCommand.HSET.name());RedisSinkMapper redisMapper = (RedisSinkMapper)RedisHandlerServices.findRedisHandler(RedisMapperHandler.class, configuration.toMap()).createRedisMapper(configuration);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();GenericRowData genericRowData = new GenericRowData(3);genericRowData.setField(0, "tom");genericRowData.setField(1, "math");genericRowData.setField(2, "152");DataStream<GenericRowData> dataStream = env.fromElements(genericRowData, genericRowData);RedisSinkOptions redisSinkOptions =new RedisSinkOptions.Builder().setMaxRetryTimes(3).build();FlinkConfigBase conf =new FlinkSingleConfig.Builder().setHost(REDIS_HOST).setPort(REDIS_PORT).setPassword(REDIS_PASSWORD).build();RedisSinkFunction redisSinkFunction =new RedisSinkFunction<>(conf, redisMapper, redisSinkOptions, resolvedSchema);dataStream.addSink(redisSinkFunction).setParallelism(1);env.execute("RedisSinkTest");
-
5.4 redis-cluster写入示例
示例代码路径: src/test/java/org.apache.flink.streaming.connectors.redis.table.SQLInsertTest.java
set示例,相当于redis命令: set test test11
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings environmentSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, environmentSettings);String ddl = "create table sink_redis(username VARCHAR, passport VARCHAR) with ( 'connector'='redis', " +"'cluster-nodes'='10.11.80.147:7000,10.11.80.147:7001','redis- mode'='cluster','password'='******','command'='set')" ;tEnv.executeSql(ddl);
String sql = " insert into sink_redis select * from (values ('test', 'test11'))";
TableResult tableResult = tEnv.executeSql(sql);
tableResult.getJobClient().get()
.getJobExecutionResult()
.get();
6 解决问题联系我
https://github.com/jeff-zou/flink-connector-redis.git
7 开发与测试环境
ide: IntelliJ IDEA
code format: google-java-format + Save Actions
code check: CheckStyle
flink 1.12/1.13/1.14+
jdk1.8 Lettuce 6.2.1
8 如果需要flink 1.12版本支持,请切换到分支flink-1.12(注:1.12使用jedis)
<dependency><groupId>io.github.jeff-zou</groupId><artifactId>flink-connector-redis</artifactId><version>1.1.1-1.12</version>
</dependency>
相关文章:

flink-connector-redis支持select查询
EN 1 项目介绍 基于bahir-flink二次开发,相对bahir调整的内容有: 1.使用Lettuce替换Jedis,同步读写改为异步读写,大幅度提升了性能 2.增加了Table/SQL API,增加select/维表join查询支持 3.增加关联查询缓存(支持增量与全量) 4…...
[密码学] 密码学基础
目录 一 为什么要加密? 二 常见的密码算法 三 密钥 四 密码学常识 五 密码信息威胁 六 凯撒密码 一 为什么要加密? 在互联网的通信中,数据是通过很多计算机或者通信设备相互转发,才能够到达目的地,所以在这个转发的过程中,如果通信包…...
上海:6月1日起取消企业复工复产白名单制
财经新闻5月29日消息:上海市人民政府关于印发《上海市加快经济恢复振兴行动计划》的通知。 《方案》包括千方百计缓解各类市场主体困难,全面有序推进复工复产和市场复工复产,多措并举稳外资稳外贸,大力促进消费加速复苏࿰…...
SpringBoot扩展篇:循环依赖源码链路
SpringBoot扩展篇:循环依赖源码链路 1. 相关文章2. 一个简单的Demo3. 流程图3.1 BeanDefinition的注册3.2 开始创建Bean3.3 从三级缓存获取Bean3.4 创建Bean3.5 实例化Bean3.6 添加三级缓存3.7 属性初始化3.8 B的创建过程3.9 最终流程 1. 相关文章 SpringBoot 源码…...
服务消费微服务
文章目录 1.示意图2.环境搭建1.创建会员消费微服务模块2.删除不必要的两个文件3.检查父子模块的pom.xml文件1.子模块2.父模块 4.pom.xml 添加依赖(刷新)5.application.yml 配置监听端口和服务名6.com/sun/springcloud/MemberConsumerApplication.java 创…...
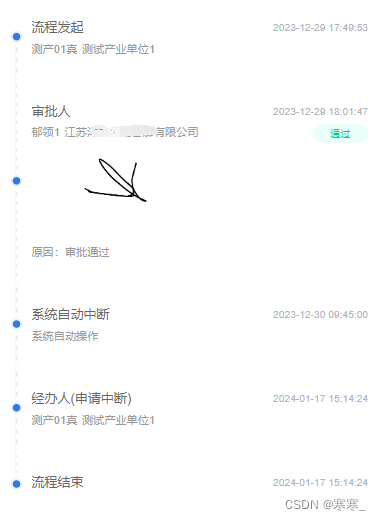
uni-app纵向步骤条
分享一下项目中自封装的步骤条,存个档~ 1. 话不多说,先看效果 2. 话还不多说,上代码 <template><!-- 获取一个数组,结构为[{nodeName:"流程发起"isAudit:falsetime:"2024-02-04 14:27:35"otherDat…...

【JavaEE -- 文件操作IO有关面试题】
文件操作IO有关面试题 1.查找硬盘上的文件位置1.1 思路1.2 执行代码 2. 实现文件复制2.1 思路2.2 代码执行 3. 打印搜索的词的文件路径3.1 思路3.2 代码执行 1.查找硬盘上的文件位置 给定一个文件名,去指定的目录中进行搜索,找到文件名匹配的结果&#…...
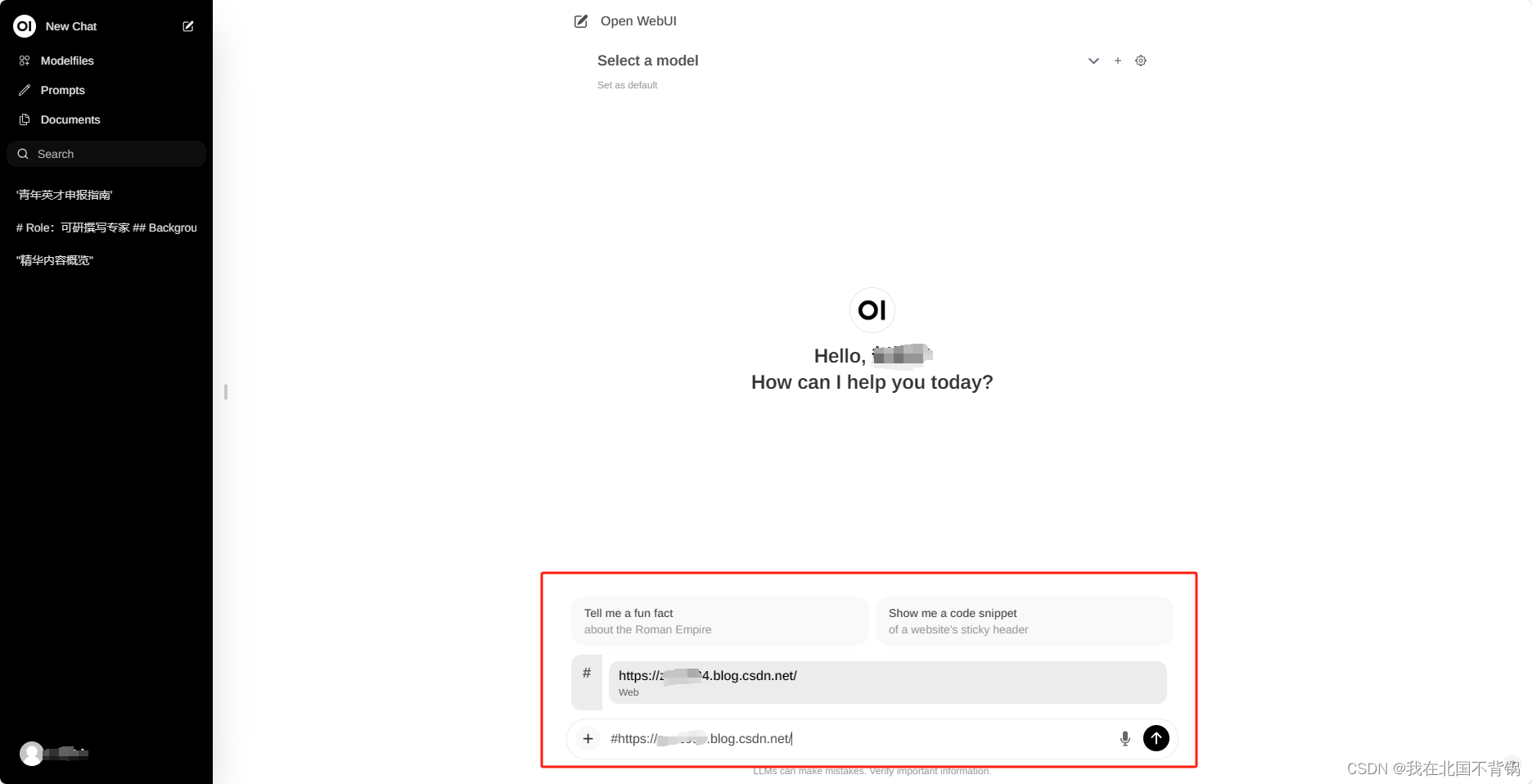
Open WebUI大模型对话平台-适配Ollama
什么是Open WebUI Open WebUI是一种可扩展、功能丰富、用户友好的大模型对话平台,旨在完全离线运行。它支持各种LLM运行程序,包括与Ollama和Openai兼容的API。 功能 直观的界面:我们的聊天界面灵感来自ChatGPT,确保了用户友好的体验。响应…...

[2021]Zookeeper getAcl命令未授权访问漏洞概述与解决
今天在漏洞扫描的时候蹦出来一个zookeeper的漏洞问题,即使是非zookeeper的节点,或者是非集群内部节点,也可以通过nc扫描2181端口,获取极多的zk信息。关于漏洞的详细描述参考apache zookeeper官方概述:CVE-2018-8012: A…...
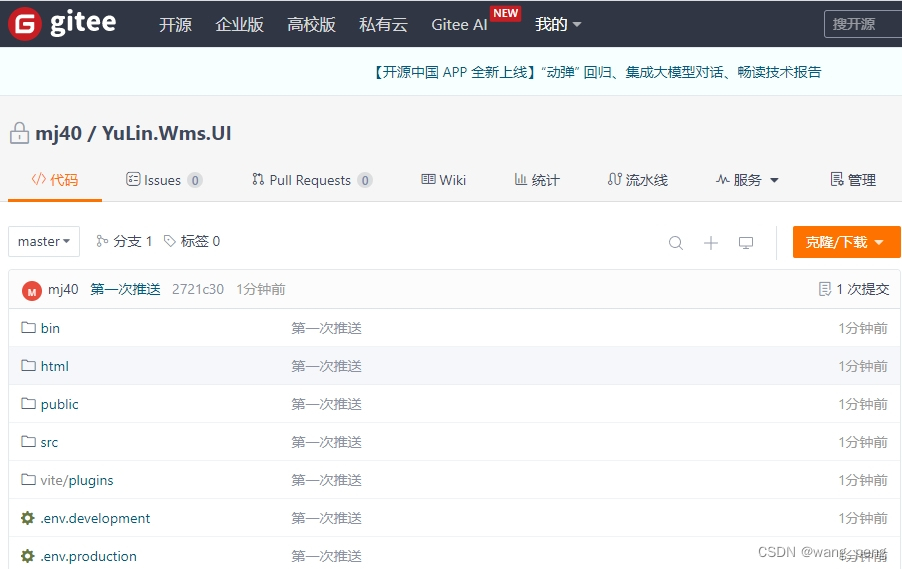
vscode添加gitee
1.创建仓库 2.Git 全局设置 3.初始化仓库 2.1 打开vscode打开需要上传到给git的代码文件 2.2.点击左边菜单第三个的源代码管理->初始化仓库 4.点击加号暂存所有更改 5.添加远程仓库 5.1 添加地址,回车 5.2 填写库名,回车 6.提交和推送 6.1 点击✔提交…...

数据库底层原理
本文将介绍数据库在储存和通讯时的原理 数据库储存 首先,数据库的作用持久化存储数据,数据库的存储形式就是文件,每一张表就是一个文件,其他数据也是文件形式,比如索引文件。 比如像mysql数据库,其中的数…...

JVM虚拟机-实战篇
专属小彩蛋:前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站(前言 - 床长人工智能教程) 目录 一、内存溢出和内存泄漏 什么是内存泄漏? 二、解决内存泄漏 解决内存泄漏的思路 top命令 发现问题 VisualVM 发现问…...

上岸跨考生的备考经验,送给零基础跨考计算机的你!
九个月的时间绝对是够用的,就算是跨考也够用! 一般来说,专业课要复习三轮,九个月的时间,复习三轮完全够用 复习资料:王道四本书王道真题 打基础阶段:3-6月: 学习目标:…...

js改变图片曝光度(高亮度)
方法一: 原理: 使用canvas进行滤镜操作,通过改变图片数据每个像素点的RGB值来提高图片亮度。 缺点 当前项目使用的是svg,而不是canvas 调整出来的效果不是很好,图片不是高亮,而是有些发白 效果 代码 …...

【NLP笔记】大模型prompt推理(提问)技巧
文章目录 prompt概述推理(提问)技巧基础prompt构造技巧进阶优化技巧prompt自动优化 参考链接: Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing预训练、提示和预测:NL…...

【目标检测】西红柿成熟度数据集三类标签原始数据集280张
文末有分享链接 标签名称names: - unripe - semi-ripe - fully-ripe D00399-西红柿成熟度数据集三类标签原始数据集280张...
)
Java File类(文件操作类)
背景: 在Java编程语言中,操作文件和目录是一项常见的任务。而File类,则是java.io包中的重要类,它是唯一代表磁盘文件本身的对象。通过File类提供的方法,我们可以轻松地创建、删除、重命名文件和目录等操作。 构造方法&…...

正则表达式 vs. 字符串处理:解析优势与劣势
title: 正则表达式 vs. 字符串处理:解析优势与劣势 date: 2024/3/27 15:58:40 updated: 2024/3/27 15:58:40 tags: 正则起源正则原理模式匹配优劣分析文本处理性能比较编程应用 1. 正则表达式起源与演变 正则表达式(Regular Expression)最早…...
1、goreplay流量回放
目的 在实际项目中,会有大量的回归测试工作,通常会使用自动化代码的手段来实现回归,但是对于一个庞大的系统来说,通过自动化脚本的方式来实现回归测试,又显得很费时费力。并且如果有定期将线上数据同步到测试环境的需求…...
Transformer的前世今生 day06(Self-Attention和RNN、LSTM的区别)
Self-Attention和RNN、LSTM的区别 RNN的缺点:无法做长序列,当输入很长时,最后面的输出很难参考前面的输入,即长序列会缺失上文信息,如下: 可能一段话超过50个字,输出效果就会很差了 LSTM通过忘…...

IDEA全局替换不够用?试试这个Java脚本,精准处理多模块项目文件内容替换
IDEA全局替换不够用?试试这个Java脚本,精准处理多模块项目文件内容替换 在大型Java项目中,我们经常需要批量修改代码中的某些字符串或配置。虽然IntelliJ IDEA提供了"Replace in Path"功能,但在实际企业级开发中&#…...

PySpur工作流追踪终极指南:实时监控AI代理执行过程的10个技巧
PySpur工作流追踪终极指南:实时监控AI代理执行过程的10个技巧 【免费下载链接】pyspur Minimalist AI Agent Graph UI 项目地址: https://gitcode.com/gh_mirrors/py/pyspur PySpur是一个极简主义的AI代理图形化界面工具,专为构建和监控复杂AI工作…...
Pixel Dimension Fissioner 镜像深度配置:环境变量与启动参数详解
Pixel Dimension Fissioner 镜像深度配置:环境变量与启动参数详解 1. 为什么需要深度配置? 当你第一次部署Pixel Dimension Fissioner镜像时,默认设置可能已经能满足基本需求。但随着使用场景的复杂化,你会发现很多情况下需要根…...

解锁Audacity:5个零成本音频处理功能彻底改变你的创作流程
解锁Audacity:5个零成本音频处理功能彻底改变你的创作流程 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity 价值定位:为什么Audacity是音频创作者的必备工具 在音频编辑领域,专…...

从零开始构建你的渗透测试字典库:账号密码大字典与设备默认口令全解析
从零开始构建你的渗透测试字典库:账号密码大字典与设备默认口令全解析 在安全测试领域,一个高质量的字典库往往能决定渗透测试的效率上限。想象一下,当你面对一个需要爆破的系统时,手头拥有精准覆盖目标特征的字典,就…...
)
模型安全实践:实时手机检测-通用输入图像异常检测(模糊/过曝/裁剪)
模型安全实践:实时手机检测-通用输入图像异常检测(模糊/过曝/裁剪) 1. 项目简介与核心价值 在日常的手机检测应用中,我们经常会遇到各种图像质量问题:图片模糊看不清手机细节、光线过曝导致手机轮廓丢失、或者图片被…...

如何用d2s-editor高效管理暗黑破坏神2存档:终极可视化编辑指南
如何用d2s-editor高效管理暗黑破坏神2存档:终极可视化编辑指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor d2s-editor是一款免费开源的Web版暗黑破坏神2存档编辑器,它将复杂的二进制存档文件转化为直…...
Uncertainty-Aware Pixel-Level Contrastive Learning for Enhanced Semi-Supervised Medical Image Segmen
1. 医学图像分割的挑战与半监督学习机遇 医学图像分割一直是计算机视觉领域的重要研究方向,它能够帮助医生快速定位病灶区域,提高诊断效率。但在实际应用中,我们常常面临标注数据稀缺的问题——专业医生标注一张CT或MRI图像可能需要数小时&am…...

避坑指南:从Paraformer到SenseVoice,语音模型训练数据准备的5个常见错误
避坑指南:从Paraformer到SenseVoice,语音模型训练数据准备的5个常见错误 语音识别和多模态语音模型正在重塑人机交互的边界。当Paraformer凭借其简洁的音频-文本配对要求成为ASR领域的新宠时,SenseVoice却以情感识别、事件标记等多维度分析能…...

Phi-3-vision-128k-instruct 代码理解能力展示:解析截图中的复杂算法伪代码
Phi-3-vision-128k-instruct 代码理解能力展示:解析截图中的复杂算法伪代码 1. 引言 最近在GitHub上看到一个有趣的项目,测试了Phi-3-vision-128k-instruct模型对编程相关图像的理解能力。作为一个经常需要阅读算法伪代码的程序员,我对这个…...