MySQL 数据库的日志管理、备份与恢复
一. 数据库备份
1.数据备份的重要性
备份的主要目的是灾难恢复。
-
在生产环境中,数据的安全性至关重要。
-
任何数据的丢失都可能产生严重的后果。
-
造成数据丢失的原因:
程序错误人为,操作错误,运算错误,磁盘故障灾难(如火灾、地震)和盗窃.
容灾概念:
容灾(Disaster Recovery, DR)是指为了保障企业或组织的关键业务在遇到突发灾难性事件(如火灾、地震、洪水、恐怖袭击、网络攻击、硬件故障等)时,能够迅速恢复运营,保证数据安全和业务连续性的策略和技术手段。在信息技术(IT)领域中,容灾具体体现为一套完整的体系,包括预防、准备、响应和恢复四个阶段,旨在最大程度降低灾难对业务的影响,确保即使主数据中心失效,也能通过备用系统或远程站点迅速接管业务,维持服务的连续性和数据完整性。
容灾系统通常设计如下特点:
- 异地建设:在地理上远离主数据中心的位置设立备份站点,以防本地灾难波及。
- 功能冗余:备份站点拥有与主站点相同或相似的功能,可以无缝接管业务运行。
- 数据同步或复制:通过实时或近实时的数据复制技术,确保备份站点的数据与主站点保持一致或接近一致。
- 快速切换与恢复:在主站点出现故障时,能快速进行系统切换,确保业务中断时间(RTO: Recovery Time Objective)和数据损失量(RPO: Recovery Point Objective)达到可接受范围。
容灾方案可分为多种等级,如热容灾(Hot Site)、温容灾(Warm Site)和冷容灾(Cold Site),取决于备用站点的激活时间和数据恢复的程度。随着技术发展,还有基于云计算的容灾解决方案,提供了更为灵活和成本效益高的容灾选项。
2. 数据库备份的分类和备份的策略
2.1 数据库备份的分类
2.1.1 物理备份
物理备份:对数据库操作系统的物理文件(如数据文件、日志文件等)的备份。
物理备份方法:
- 冷备份(脱机备份) :是在关闭数据库的时候进行的
- 热备份(联机备份) :数据库处于运行状态,依赖于数据库的日志文件
- 温备份:数据库锁定表格(不可写入但可读)的状态下进行备份操作
2.1.2 逻辑备份
逻辑备份:对数据库逻辑组件(如:表等数据库对象)的备份。
- 即以sql语句的形式,把库、表结构、表数据保存下来。
2.2 数据库的备份策略
从数据库的备份策略角度,备份可分为
- 完全备份:每次对数据库进行完整的备份
- 差异备份:备份自从上次完全备份之后被修改过的文件
- 增量备份:只有在上次完全备份或者增量备份后被修改的文件才会被备份
解释:
2.2.1 完全备份

2.2.2 差异备份

2.2.3 增量备份
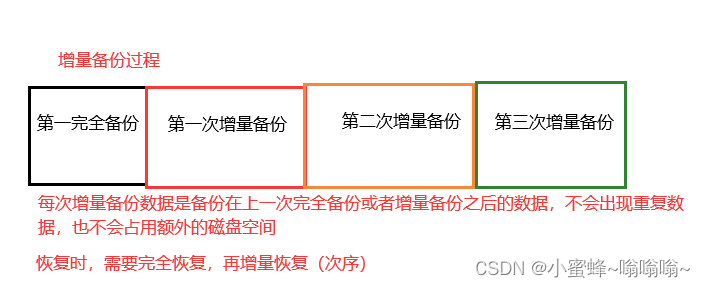
2.2.4 三种备份方式的比较
| 备份方式 | 完全备份 | 差异备份 | 增量备份 |
| 完全备份时的状态 | 1,2 | 1,2 | 1,2 |
| 第一次添加内容 | 创建3 | 创建3 | 创建3 |
| 备份内容 | 1,2,3 | 3 | 3 |
| 第二次添加内容 | 创建4 | 创建4 | 创建4 |
| 备份内容 | 1,2,3,4 | 3,4 | 4 |
2.2.5 如何选择逻辑备份策略
一周一次的全备,全备的时间需要在不提供业务的时间区间进行,PM 10点 AM 5点之间进行全备 凌晨1~5点
增量备份:3天/2天/1天一次增量备份
差异备份:选择特定的场景进行备份
2.3 常见的备份方法
- 物理冷备: (完全备份)
- 备份时数据库处于关闭状态,直接打包数据库文件
- 备份速度快,恢复时也是最简单的
- 专用备份工具 mydump 或 mysqlhotcopy (完全备份,逻辑备份)
- mysqldump 常用的逻辑备份工具 (导出为sql脚本)
- mysqlhotcopy 仅拥有备份 MyISAM 和 ARCHIVE 表
- 启用二进制日志进行增量备份 (增量备份)
- 进行增量备份,需要刷新二进制日志
- 第三方工具备份
- 免费的MySQL热备份软件Percona XtraBackup
- (阿里云的工具:dts,支持热迁移)
二. MySQL 完全备份
1. 完全备份介绍
- 完全备份是对整个数据库、数据库结构和文件结构的备份
- 保存的是备份完成时刻的数据库
- 是差异备份与增量备份的基础
2. 完全备份的优缺点
优点:
- 备份与恢复操作简单方便
缺点:
- 数据存在大量的重复
- 占用大量的备份空间
- 备份与恢复时间长
3. 完全备份的方法
-
物理冷备份与恢复
- 关闭MySQL数据库
- 使用 tar 命令直接打包数据库文件夹
- 直接替换现有MySQL目录即可
-
mysqldump备份与恢复
- MySQL自带的备份工具,可方便实现对MySQL的备份
- 可以将指定的库、表导出为SQL脚本
- 使用命令mysq|导入备份的数据
4. 完全备份与恢复的操作
4.1 物理冷备份与恢复
先关闭数据库

4.1.1 方法一
备份:
[root@localhost mysql]#pwd
/usr/local/mysql
[root@localhost mysql]#tar zcvf data.tar.gz data/[root@localhost mysql]#mv data.tar.gz /opt

恢复:

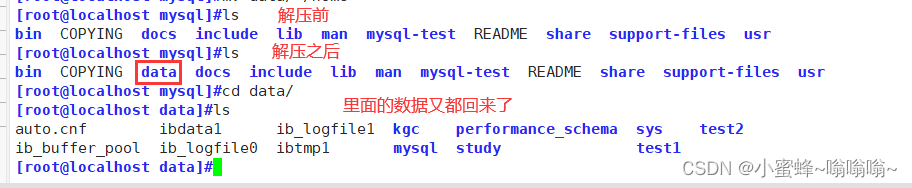
4.1.2 方法二
备份:


成功压缩备份

恢复:
[root@localhost mysql]#ls
[root@localhost mysql]#mkdir data
[root@localhost mysql]#ls
data
[root@localhost mysql]#pwd
/home/mysql
[root@localhost mysql]#tar Jxvf /opt/mysql_all_2024-03-25.tar.xz -C ./



4.2 mysqldump 备份与恢复
备份:
4.2.1 完全备份一个或多个完整的库(包括其中所有的表)
mysqldump -u root -p[密码] --databases 库名1 [库名2] ... > /备份路径/备份文件名.sql #导出的就是数据库脚本文件

4.2.2 完全备份MySQL服务器中所有的库
mysqldump -u root -p[密码] --all-databases > /备份路径/备份文件名.sql

4.2.3 完全备份指定库中的部份表
mysqldump -u root -p[密码] [-d] 库名 [表名1] [表名2] ... > /备份路径/备份文件名.sql#使用 -d 选项,说明只保存数据库的表结构
#不使用 -d 选项,说明表数据也进行备份

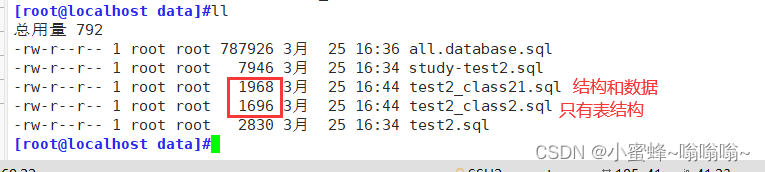
4.2.4 查看备份文件
先看里面的内容
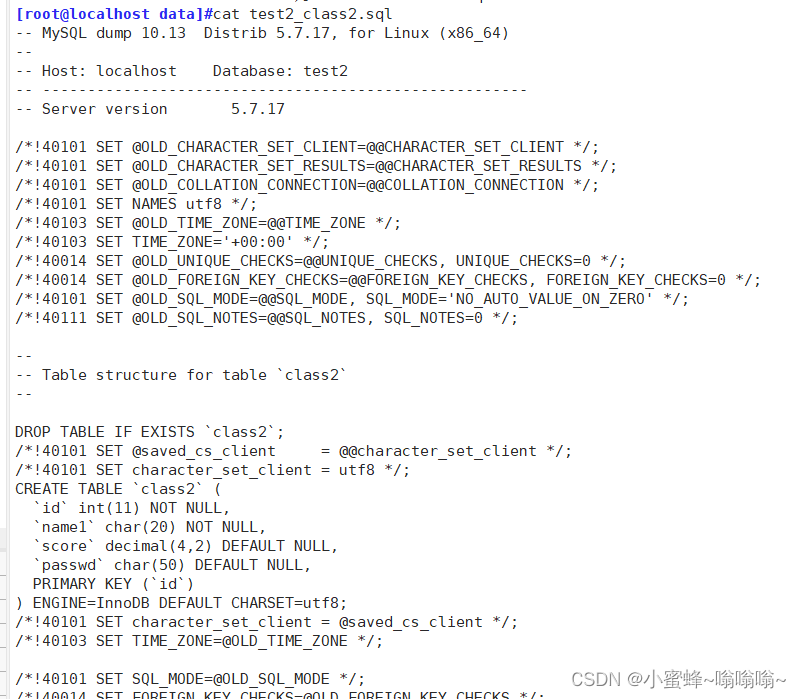
然后我们只用以下方法,过滤出备份文件信息
[root@localhost mysql]#grep -v '^--' /data/test2_class2.sql |grep -v '^/'|grep -v '^$'这条命令是用于Unix/Linux环境下的文本筛选,具体作用是对 /data/test2_class2.sql 文件内容进行多次筛选过滤:grep -v '^--': 过滤掉所有以双连字符(注释符号)开始的行。在SQL文件中,这样的行通常代表注释行。| grep -v '^/': 再次过滤,去除所有以正斜杠(/)开始的行。在某些情况下,这种行可能代表SQL脚本中的某些特殊指令或注释(例如在Oracle SQL中的一些PL/SQL块声明)。| grep -v '^$': 最后一步过滤,移除所有空行(即只有换行符,没有其他任何内容的行)。
恢复:
4.2.5 使用 source 命令恢复数据
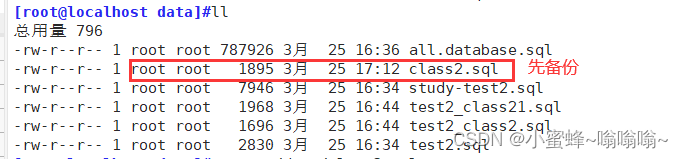


#恢复数据
mysql> source /data/class2.sql;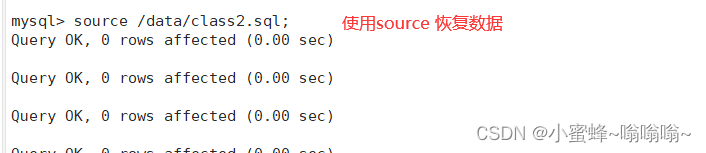

也可以直接在外面免交互查看:

4.2.6 重定向导入备份文件
#恢复
mysql -uroot -p123 test2 < /data/class2.sql #查看
mysql -uroot -p123 -e 'show tables from test2';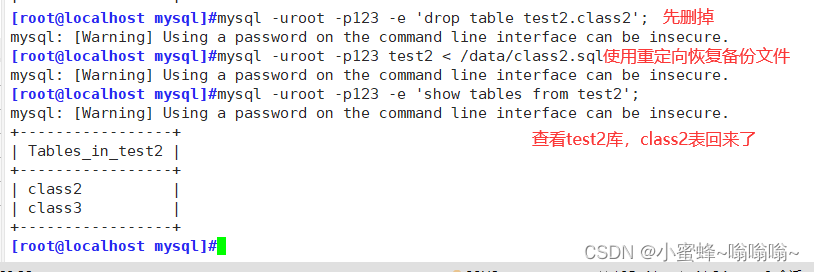
4.2.7 备份加与不加 --databases
mysqldump 严格来说属于温备份,会需要对表进行写入的锁定,在全量备份与恢复实验中:
① 当备份时加 --databases,表示针对 test2库

测试:
删除:

恢复:

查看:

② 当备份时不加 --databases,表示针对test2库下的所有表
![]()
恢复数据是会报错


恢复:

查看:

主要区别:
在于两种方式的备份(前者则全是针对表格进行操作,而后者会从 "create databases"开始)
5. 在生产环境中,可以使用Shell脚本自动实现定时备份(时间频率需要确认)
#!/bin/bash
# 定义变量
DATE=$(date +%Y%m%d_%H%M%S)
MYSQL_USER="username"
MYSQL_PASS="password"
DATABASE="database_name"
BACKUP_DIR="/path/to/backup/directory"# 执行mysqldump命令备份数据库
mysqldump -u$MYSQL_USER -p$MYSQL_PASS $DATABASE | gzip > $BACKUP_DIR/database_$DATE.sql.gz# 可选:删除超过一定天数的旧备份
find $BACKUP_DIR -name 'database_*.sql.gz' -type f -mtime +15 -exec rm {} \;# 输出备份成功信息
echo "Database backup successfully created at $BACKUP_DIR/database_$DATE.sql.gz"在上面的脚本中:mysqldump 命令用于导出MySQL数据库的内容。
-u$MYSQL_USER 和 -p$MYSQL_PASS 分别指定了数据库用户名和密码。
$DATABASE 是你要备份的数据库名称。
$BACKUP_DIR 是备份文件保存的目录。
备份文件名中包含日期时间戳,便于按时间排序和管理。
可选部分是通过find命令清理超过15天的旧备份。将脚本保存为可执行文件,例如:/usr/local/bin/mysql_backup.sh,然后赋予执行权限:chmod +x /usr/local/bin/mysql_backup.sh设置定时任务(Cron Job): 打开crontab编辑器(使用root或具有执行备份任务权限的用户身份):
crontab -e然后在文件末尾添加一条定时任务,比如每天凌晨1点执行备份
0 1 * * * /usr/local/bin/mysql_backup.sh保存并退出crontab编辑器,定时任务就会按照设定的时间自动执行MySQL数据库备份。三. MySQL 增量备份与恢复
1. 关于增量备份
1.1 增量备份产生的原因
- 使用 mysqldump 进行完全备份存在的问题
- 备份数据中有重复数据
- 备份时间与恢复时间过长
- 增量备份是什么:
- 是自上一次备份后增加/变化的文件或者内容
- 增量备份的特点
- 没有重复数据,备份量不大,时间短
- 恢复需要上次完全备份及完全备份之后所有的增量备份才 能恢复,而且要对所有增量备份进行逐个反推恢复
1.2 增量备份的过程
- MySQL没有提供直接的增量备份方法
- 可通过MySQL提供的二进制日志间接实现增量备份
- MySQL二进制日志对备份的意义
- 二进制日志保存了所有更新或者可能更新数据库的操作
- 二进制日志在启动MySQL服务器后开始记录,并在文件达到 max_binlog_size 所设置的大小或者接收到 flush logs 命令后重新创建新的日志文件
- 只需定时执行 flush logs 方法重新创建新的日志,生成二进制文件序列,并及时把这些日志保存到安全的地方就完成了一个时间段的增量备份
1.3 增量备份的方式
-
一般恢复
- 将所有备份的二进制日志内容全部恢复
-
基于位置恢复
- 数据库在某一时间点可能既有错误的操作也有正确的操作
- 可以基于精准的位置跳过错误的操作
-
基于时间点恢复
- 跳过某个发生错误的时间点实现数据恢复
2. MySQL 日志
配置文件:/etc/my.cnf
[mysqld] 模块下
错误日志,用来记录当MySQL启动、停止或运行时发生的错误信息,默认已开启
log-error=/usr/local/mysql/data/mysql_error.log
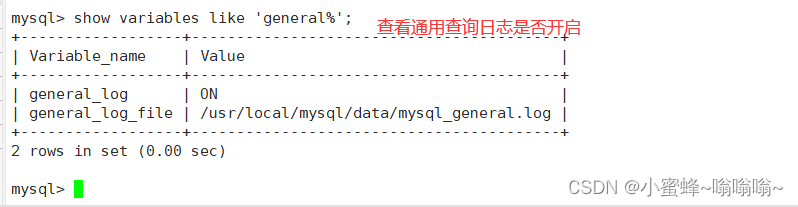
通用查询日志,用来记录MySQL的所有连接和语句,默认是关闭的
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
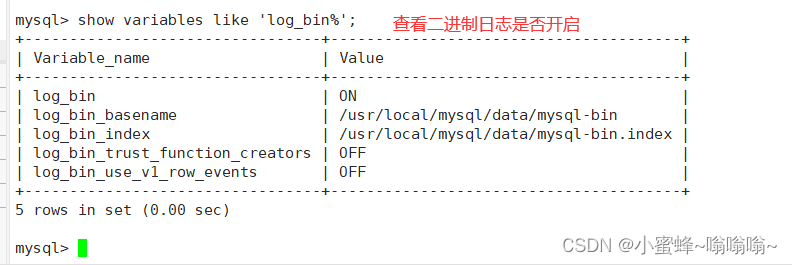
二进制日志(binlog),用来记录所有更新了数据或者已经潜在更新了数据的语句,记录了数据的更改,可用于数据恢复,默认已开启
log-bin=mysql-bin
或
log_bin=mysql-bin
中继日志
一般情况下它在Mysql主从同步(复制)、读写分离集群的从节点开启。主节点一般不需要这个日志
慢查询日志,用来记录所有执行时间超过long_query_time秒的语句,可以找到哪些查询语句执行时间长,以便提醒优化,默认是关闭的
s1ow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5 #设置超过5秒执行的语句被记录,缺省时为10秒
show variables like 'general%'; #查看通用查询日志是否开启
show variables like 'log_bin%'; #查看二进制日志是否开启
show variables like '%slow%'; #查看慢查询日功能是否开启
show variables like 'long_query_time'; #查看慢查询时间设置
set global slow_query_log=ON; #在数据库中设置开启慢查询的方法PS:variables 表示变量 like 表示模糊查询##复制段
log-error=/usr/local/mysql/data/mysql_error.log
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
log-bin=mysql-bin
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5二进制日志开启后,重启 mysql 会在目录中查看到二进制日志
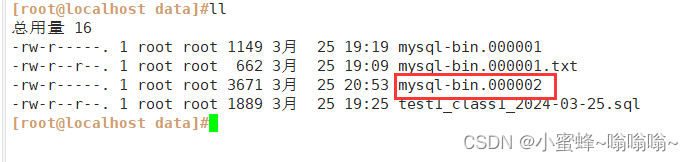
cd /usr/local/mysql/data
ls
mysql-bin.000001 #开启二进制日志时会产生一个索引文件及一个索引列表索引文件:记录更新语句
索引文件刷新方式:
1、重启mysql的时候会更新索引文件,用于记录新的更新语句
2、刷新二进制日志mysql-bin.index:
二进制日志文件的索引3. 增量备份操作
3.1 开启二进制日志功能
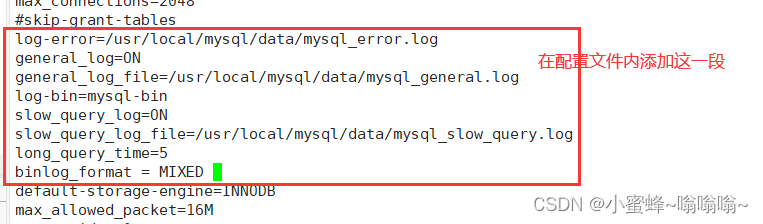

二进制日志(binlog)有3种不同的记录格式:
STATEMENT (基于SQL语句)、ROW(基于行)、MIXED(混合模式),默认格式是STATEMENT
- ① STATEMENT(基于SQL语句)
每一条涉及到被修改的 sql 都会记录在 binlog 中
缺点:日志量过大,如 sleep()函数,last_insert_id()>,以及 user-defined fuctions(udf)、主从复制等架构记录日志时会出现问题
总结:增删改查通过sql语句来实现记录,如果用高并发可能会出错,可能时间差异或者延迟,可能不是我们想想的恢复可能你先删除或者在修改,可能会倒过来。准确率低
- ② ROW(基于行)
只记录变动的记录,不记录 sql 的上下文环境
缺点:如果遇到 update......set....where true 那么 binlog 的数据量会越来越大
总结:update、delete 以多行数据起作用,来用行记录下来,
只记录变动的记录,不记录 sql 的上下文环境,
比如 sql 语句记录一行,但是ROW就可能记录10行,但是准确性高,高并发的时候由于操作量,性能变低,比较大所以记录都记下来,
- ③ MIXED 推荐使用
一般的语句使用 statement,函数使用ROW方式存储。
mysql> show variables like 'general%';
mysql> show variables like 'log_bin%';
查看到日志存放位置

3.2 查看二进制文件内容
[root@localhost data]#mysqlbinlog --no-defaults /data/mysql-bin.000001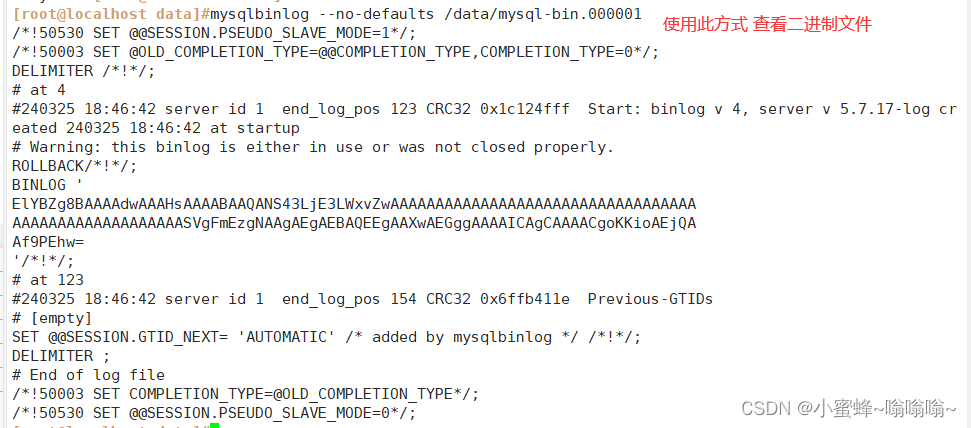
[root@localhost data]#mysqlbinlog --no-defaults --base64-output=decode-rows -v /data/mysql-bin.000001 #
-v: 显示详细内容
--no-defaults : 默认字符集(不加会报UTF-8的错误)PS: 可以将解码后的文件导出为txt格式,方便查阅
mysqlbinlog --no-defaults --base64-output=decode-rows -v /data/mysql-bin.000001 > /opt/mysql-bin.000001
[root@localhost data]#mysqlbinlog --no-defaults --base64-output=decode-rows -v /data/mysql-bin.000001 > /data/mysql-bin.000001.txt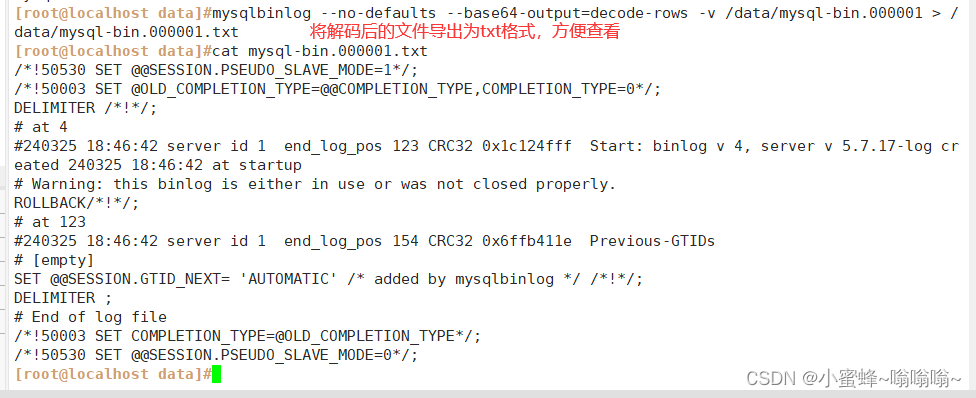
二进制日志中需要关注的部分

3.3 实际操作
3.3.1 准备工作




刷新后02的日志新生成的,里面是空的

先备份数据

3.3.2 一般恢复
恢复数据:
方式一:
先删除:

恢复数据
[root@localhost data]#mysql -uroot -p123 test1 < test1_class1_2024-03-25.sql 
查看

方式二:
得事先将库给删了。不然会报错,因为他前面重复了

[root@localhost data]#mysqlbinlog --no-defaults mysql-bin.000001 | mysql -uroot -p123

3.3.3 基于位置点恢复
先插入数据




测试:
将库删掉

查看数据

增量备份,先将之前的恢复

开始恢复

查看

我们的目的是恢复前三条数据,下面我们看02的过程


查看:

如果想跳过第4条,恢复第五条


查看

这是基于位置点恢复数据
基于位置点恢复
#仅恢复到操作 ID 为'1102'之前的数据,即恢复1 2的数据
mysqlbinlog --no-defaults --stop-position='1102' mysql-bin.000001|mysql -uroot -p123#恢复3数据 起始操作ID 为'2947',截止id为 '3237'
mysqlbinlog --no-defaults --start-position='2947' --stop-position='3237' mysql-bin.000002|mysql -uroot -p123#跳过第4条数据,恢复第5条数据,直接从第5条开始到最后
mysqlbinlog --no-defaults --start-position='3527' mysql-bin.000002|mysql -uroot -p1233.3.4 基于时间点恢复
mysqlbinlog [--no-defaults] --start-datetime='年-月-日 小时:分钟:秒' --stop-datetime='年-月-日小时:分钟:秒' 二进制日志 | mysql -u 用户名 -p 密码下面我们恢复第4条数据,用时间来恢复


查看:

如果恢复某条SQL语之前的所有数据,就stop在这个语句的位置节点或者时间点
如果恢复某条SQL语句以及之后的所有数据,就从这个语句的位置节点或者时间点start
总结:
① 物理冷备份
关闭 mysqld 服务,tar 命令打包 /usr/local/mysql 下的 data 目录 ,恢复就是直接解压 tar 包
② 逻辑备份
mysqldump -uxxx -pxxx --database 库1 库2 > xxx.sql
mysqldump -uxxx -pxxx --all-databases > xxx.sql
mysqldump -uxxx -pxxx 库1 表1 表2 > xxx.sql
完全恢复
mysql -uxxx -pxxx < xxx.sql 恢复库
mysql -uxxx -pxxx 库名 < xxx.sql
③ 增量备份
1 开启二级制日志,设置二进制日志格式MIXED
2 进行一次完全备份,可每周备份一次,通过crontab-e
3 使用mysqladmin -uroot -p
flush-logs刷新分割出二进制日志文件,由于刷新之前的数据都会记录在老的二进制日志里
4 可以通过mysqlbinlog --no-defaults --base64-output=decode-rows -v二进制日志文件名 查看日志内容
5 可以通过 mysqlbinlog --no-defaults 二进制日志文件名 mysql -uroo -t 恢复丢失的数据库
④ 位置恢复
start 开始(单独使用假设你要回复之后的数据可以使用start)
stop 结束(单独使用假设你要回复之前的数据可以使用stop)
⑤ 时间恢复
同上
相关文章:
MySQL 数据库的日志管理、备份与恢复
一. 数据库备份 1.数据备份的重要性 备份的主要目的是灾难恢复。 在生产环境中,数据的安全性至关重要。 任何数据的丢失都可能产生严重的后果。 造成数据丢失的原因: 程序错误人为,操作错误,运算错误,磁盘故障灾难(如火灾、地震࿰…...
一、Go开发环境搭建
文章目录 1、开发工具2、开发环境配置3、Hello World4、语法 1、开发工具 https://code.visualstudio.com/download 2、开发环境配置 类比Java的JDK,go的SDK下载:https://studygolang.com/dl 解压: 配置环境变量path,将命令&quo…...
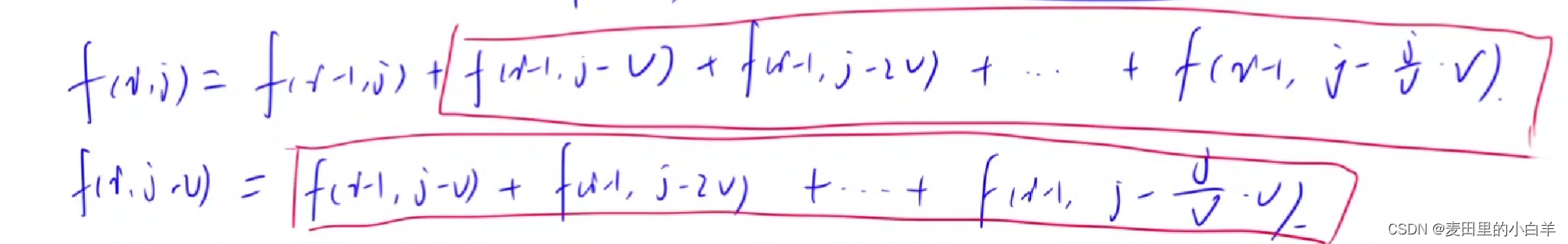
包子凑数(蓝桥杯,闫氏DP分析法)
题目描述: 小明几乎每天早晨都会在一家包子铺吃早餐。 他发现这家包子铺有 N 种蒸笼,其中第 i 种蒸笼恰好能放 Ai 个包子。 每种蒸笼都有非常多笼,可以认为是无限笼。 每当有顾客想买 X 个包子,卖包子的大叔就会迅速选出若干笼…...

Java八股文(JVM)
Java八股文のJVM JVM JVM 什么是Java虚拟机(JVM)? Java虚拟机是一个运行Java字节码的虚拟机。 它负责将Java程序翻译成机器代码并执行。 JVM的主要组成部分是什么? JVM包括以下组件: ● 类加载器(ClassLoa…...

云硬盘扩容后将空间增加到原有分区的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
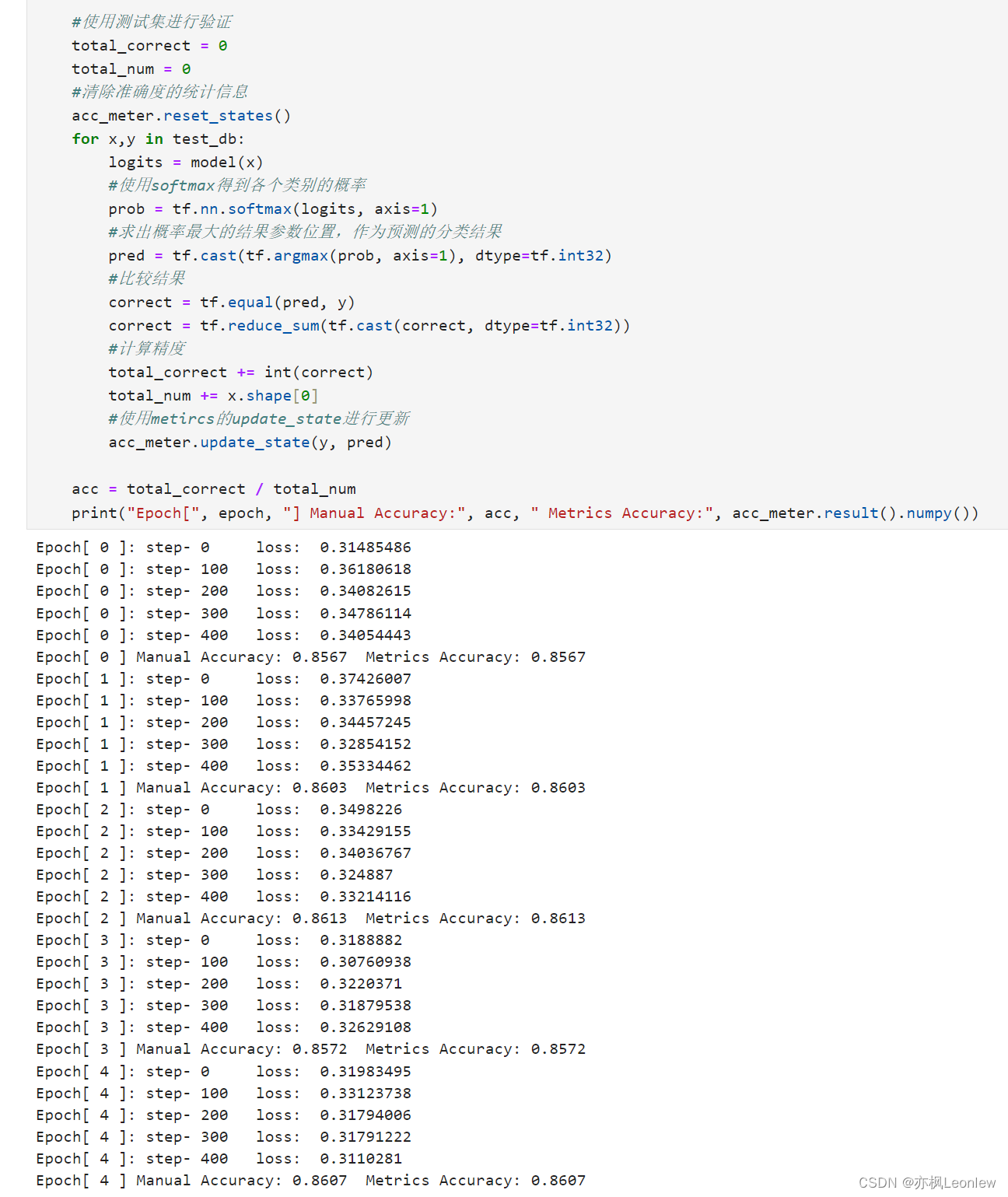
Tensorflow2.0笔记 - metrics做损失和准确度信息度量
本笔记主要记录metrics相关的内容,详细内容请参考代码注释,代码本身只使用了Accuracy和Mean。本节的代码基于上篇笔记FashionMnist的代码经过简单修改而来,上篇笔记链接如下: Tensorflow2.0笔记 - FashionMnist数据集训练-CSDN博…...

LeetCode 面试经典150题 290.单词规律
题目: 给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。 这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 s 中的每个非空单词之间存在着双向连接的对应规律。 思路:一一映射需要用到…...
)
【CASS精品教程】CASS中计算四参数和七参数(以RTK数据为例)
文章目录 一、四参数介绍二、四参数计算三、七参数介绍四、四参数、七参数的区别一、四参数介绍 两个不同的二维平面直角坐标系之间转换通常使用四参数模型,四参数适合小范围测区的空间坐标转换,相对于七参数转换的优势在于只需要2个公共已知点就能进行转换,操作简单。 在…...

什么是RISC-V?开源 ISA 如何重塑未来的处理器设计
RISC-V代表了处理器架构的范式转变,特点是其开源模型简化了设计理念并促进了全球community-driven的开发。RISC-V导致了处理器技术发展前进方式的重大转变,提供了一个不受传统复杂性阻碍的全新视角。 RISC-V起源于加州大学伯克利分校的学术起点ÿ…...

展馆设计中展示有哪些要求
1、展示产品特点和功能 产品展示应突出产品的特点、功能和优势。通过使用适当的展示方式和展示环境,使观众能够直观地了解产品的外观、结构、性能等方面。可以使用实物展示、模型、原型、图表、动画等方式,以多种角度和视角展示产品的特点和功能。 2、提…...
python实战之PyQt5桌面软件
一. 演示效果 二. 准备工作 1. 使用pip 下载所需包 pyqt5 2. 下载可视化UI工具 QT Designer 链接:https://pan.baidu.com/s/1ic4S3ocEF90Y4L1GqYHPPA?pwdywct 提取码:ywct 3. 可视化UI工具汉化 把上面的链接打开, 里面有安装和汉化包, 前面的路径还要看…...
Switch 和 PS1 模拟器:3000+ 游戏随心玩 | 开源日报 No.174
Ryujinx/Ryujinx Stars: 26.1k License: MIT Ryujinx 是用 C# 编写的实验性任天堂 Switch 模拟器。 该项目旨在提供出色的准确性和性能、用户友好的界面以及稳定的构建。它已经通过了大约 4050 个测试,其中超过 4000 个可以启动并进入游戏,其中大约 340…...
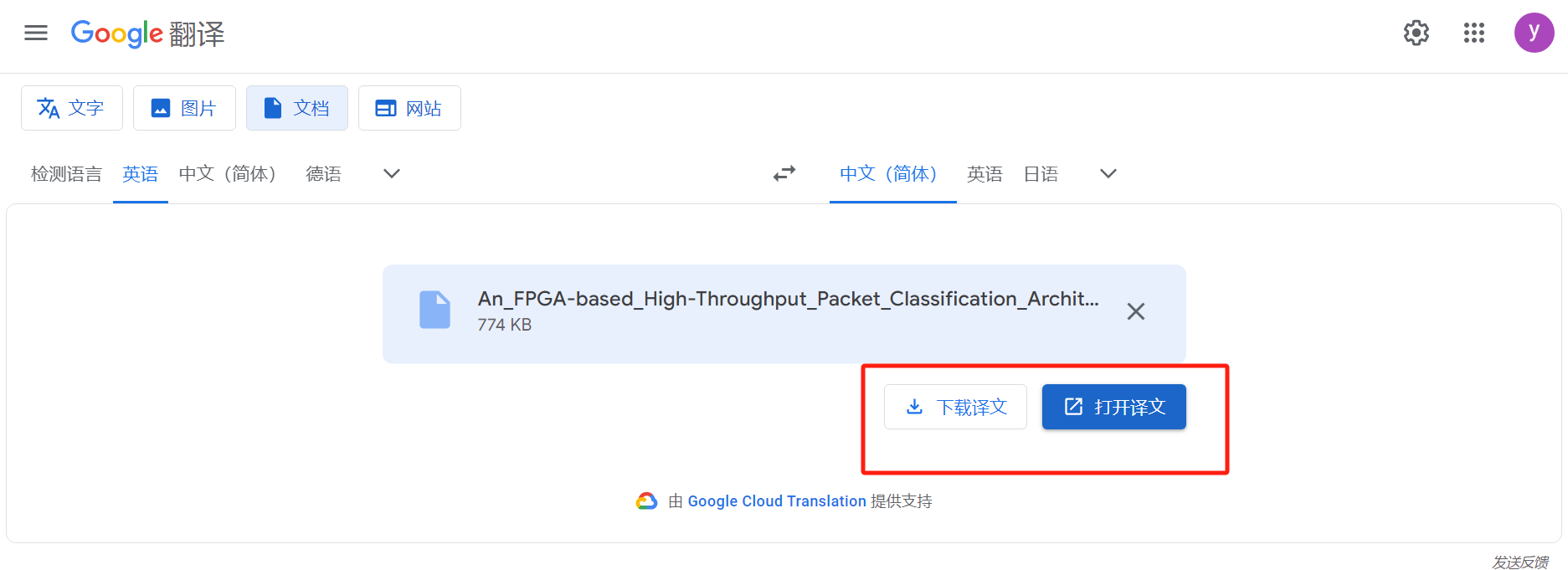
免费翻译pdf格式论文
进入谷歌翻译网址https://translate.google.com/?slauto&tlzh-CN&opdocs 将需要全文翻译的pdf放进去 选择英文到中文,然后点击翻译 可以选择打开译文或者下载译文,下载译文会下载到电脑上,打开译文会在浏览器打开。...

3D产品可视化SaaS
“我们正在走向衰退吗?” “我们已经陷入衰退了吗?” “我们正在步入衰退。” 过去几个月占据头条的问题和陈述引发了关于市场对每个行业影响的讨论和激烈辩论。 特别是对于科技行业来说,过去几周一直很动荡,围绕费用、增长和裁…...

浙大版《C语言程序设计(第4版)》题目集-习题3-5 三角形判断
给定平面上任意三个点的坐标(x1,y1)、(x2,y2)、(x3,y3),检验它们能否构成三角形。 输入格式: 输入在一行中顺序给出六个[−100,100]范围内的数字,即三个点的坐标x1、y1、x2、y2、x3、y3。 输出格式: 若这3个点不能构成三角形,则在一行中输…...

Java封装、继承、多态和抽象深度解析
在软件工程的世界里,面向对象编程(OOP)是一种编程范式,它使用“对象”来设计软件。对象可以封装数据和方法,以提高代码的复用性、可维护性和可扩展性。Java作为一门面向对象的编程语言,提供了四个基本的面向…...
深度学习每周学习总结P3(天气识别)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 数据链接 提取码:o3ix 目录 0. 总结1. 数据导入部分数据导入部分代码详解:a. 数据读取部分a.1 提问:关…...

通过iOS网络抓包工具实现移动应用数据安全监控
摘要 本文将深入探讨iOS平台上常用的网络抓包工具,包括Charles、克魔助手、Thor和Http Catcher,以及通过SSH连接进行抓包的方法。此外,还介绍了克魔开发助手作为iOS应用开发的辅助工具,提供的全方面性能监控和调试功能。 在iOS应…...

Stable Diffusion WebUI 生成参数:脚本(Script)——提示词矩阵、从文本框或文件载入提示词、X/Y/Z图表
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里,订阅后可阅读专栏内所有文章。 大家好,我是水滴~~ 在本篇文章中,我们将深入探讨 Stable Diffusion WebUI 的另一个引人注目的生成参数——脚本(Script)。我们将逐一细说提示词矩阵、从文本框或文件导入提示词,…...

synchronized和volatile的原理及应用
文章目录 synchronized的实现原理及应用升级锁代码示例volatile原理及应用代码示例线程不安全类 synchronized的实现原理及应用 synchronized 是Java中用于实现线程同步的关键字,可以应用于方法或代码块,确保在多线程环境下对共享资源的安全访问。下面是…...

springboot-vue基于web框架的高校教材征订管理系统的设计与实现
目录技术选型与架构设计核心功能模块划分数据库设计要点开发阶段规划关键技术实现方案部署与运维方案项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术选型与架构设计 后端技术栈 采用Spring Boot作为核心框架,整…...

计算机毕设 java 基于 BS 架构的实验室开放管理系统 java 基于 B/S 架构的实验室预约管理系统 java 基于 B/S 架构的智能实验室管理系统
计算机毕设 java 基于 BS 架构的实验室开放管理系统 t780o9(配套有源码 程序 mysql 数据库 论文)本套源码可以先看具体功能演示视频领取,文末有联 xi 可分享当今社会已步入科技进步与经济快速发展的新时期,计算机技术对各领域的影…...

三步解决Windows系统Cursor试用限制:go-cursor-help技术工具重置方案
三步解决Windows系统Cursor试用限制:go-cursor-help技术工具重置方案 【免费下载链接】go-cursor-help 解决Cursor在免费订阅期间出现以下提示的问题: Youve reached your trial request limit. / Too many free trial accounts used on this machine. Please upgra…...

银河麒麟V10 SP1安全基线配置踩坑记:为什么pam_wheel.so的group=wheel参数会失效?
银河麒麟V10 SP1安全基线配置深度解析:从pam_wheel.so失效看系统级安全加固实战 第一次在银河麒麟V10 SP1上配置安全基线时,我盯着终端屏幕足足愣了三分钟。按照多年Linux系统管理经验,我在/etc/pam.d/su中加入了标准的groupwheel参数&#x…...

如何永久保存微信聊天记录:WeChatExporter完整解决方案
如何永久保存微信聊天记录:WeChatExporter完整解决方案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因手机丢失、系统升级或误操作而丢失珍贵的微…...
实战:从多模态数据构建到节点特征提取)
超图神经网络(HGNN)实战:从多模态数据构建到节点特征提取
超图神经网络实战:多模态数据融合与节点特征提取全流程解析 在电商推荐系统中,我们常常需要同时处理用户行为日志、商品图像和评论文本——这三种异构数据如何统一建模?传统图神经网络(GNN)在处理这类多模态关联时往往…...

OpenClaw技能扩展:用GLM-4.7-Flash实现Markdown文档自动整理
OpenClaw技能扩展:用GLM-4.7-Flash实现Markdown文档自动整理 1. 为什么需要文档自动化整理 作为一个长期使用Markdown写作的技术博主,我的文档库已经积累了超过2000篇笔记和草稿。曾经有整整三个月,我每周都要花3-4小时手动整理这些文档——…...

Swin2SR进阶使用:通过HTTP链接实现远程增强
Swin2SR进阶使用:通过HTTP链接实现远程增强 1. 引言:从本地工具到远程服务 如果你用过Swin2SR这个AI图像超分工具,一定会被它“化腐朽为神奇”的能力震撼——一张模糊的小图,经过AI的“脑补”,瞬间变成细节丰富的高清…...

【唠嗑第二嗑-代码里面的无为思想,空空如也的接口】
文章目录接口怎么是空的你当然知道为什么1.定义类型体系,而非行为契约2.为差异化行为预留空间3.真正的实现在子接口中为什么我会惊讶圣人不妄为最近拜读了老子的《道德经》。很多时候觉得读懂了,可转念一想又不是那么回事!不知道是老子他老人…...

requests - 简单好用的HTTP请求库
一、什么是requests? requests 是一个用于发送HTTP请求的 Python 库。 它可以帮助你: 轻松发送GET、POST、PUT、DELETE等请求处理Cookie、会话等复杂性自动解压缩内容处理国际化域名和URL 二、应用场景 requests 广泛应用于以下实际场景:…...