InfluxDB 2 介绍与使用 flux查询 数据可视化
一、关键概念
相比V1 移除了database 和 RP,增加了bucket。
V2具有以下几个概念:
timestamp、field key、field value、field set、tag key、tag value、tag set、measurement、series、point、bucket、bucket schema、organization
新增的概念:
bucket:所有 InfluxDB 数据都存储在一个存储桶中。一个桶结合了数据库的概念和存储周期(时间每个数据点仍然存在持续时间)。一个桶属于一个组织
bucket schema:具有明确的schema-type的存储桶需要为每个度量指定显式架构。测量包含标签、字段和时间戳。显式模式限制了可以写入该度量的数据的形状。
organization:InfluxDB组织是一组用户的工作区。所有仪表板、任务、存储桶和用户都属于一个组织。
二、系统结构
数据模式:InfluxDB数据元素存储在时间结构合并树 (TSM)和时间序列索引 (TSI)文件中,以有效压缩存储的数据。
默认路径:
| Engine path | ~/.influxdbv2/engine/ | InfluxDB 存储时序数据的位置 |
|---|---|---|
| Bolt path | ~/.influxdbv2/influxd.bolt | 非时间序列数据的基于文件的键值存储 |
| Configs path | ~/.influxdbv2/configs | 配置文件(configs) 的文件路径 |
文件目录结构:
~/.influxdbv2/
- engine/
- data/
- TSM directories and files
- wal/
- WAL directories and files
- data/
- configs
- influxd.bolt
Influxdb分片和分片组
InfluxDB在将数据存储到磁盘时将时间序列数据组织成分片。分片被分组到分片组中
表示具有4d 保留期 和1d 分片组持续时间的存储桶:

分片删除:InfluxDB保留强制执行服务会例行检查早于其存储桶保留期的分片组。一旦分片组的开始时间超过存储桶的保留期,InfluxDB 将删除该分片组以及关联的分片和 TSM 文件(在具有无限保留期的存储桶中,分片无限期地保留在磁盘上)。
系统存储桶
_monitoring system bucket : 该_monitoring系统桶存储InfluxDB数据用于 监控数据并发送警报。数据保留:7天
_tasks system bucket: 该_tasks系统桶存储与数据InfluxDB任务的执行。数据保留:1天
标签和字段描述详见:https://docs.influxdata.com/influxdb/v2.0/reference/internals/system-buckets/
三、配置文件
当influxd启动时,它会在当前工作目录检查一个名为config.*的文件。
支持以下语法:
- YAML (.yaml, .yml)
- TOML (.toml)
- JSON (.json)
配置选项(日志、并发压缩…):https://docs.influxdata.com/influxdb/v2.0/reference/config-options/
四、Flux查询语句
Flux 是 InfluxData 的功能性数据脚本语言,设计用于查询、分析和处理数据,它是InfluxQL 和其他类似 SQL 的查询语言的替代品。
设计原则:受Javascript 启发,旨在设计出可用、可读、灵活、可组合、可测试、可贡献和可共享的语言。
示例查询:近一小时存储的数据,按cpu度量和cpu=cpu-total标签过滤,以 1 分钟为间隔对数据进行窗口化,并计算每个窗口的平均值
from(bucket:"example-bucket")
|> range(start:-1h)
|> filter(fn:(r) =>r._measurement == "cpu" andr.cpu == "cpu-total"
)
|> aggregateWindow(every: 1m, fn: mean)
1>关键概念
Pipe-forward operator (管道转发操作符" |> "):Flux广泛使用管道转发运算符 “|>” 将操作链接在一起。在每个函数或操作之后,Flux 返回一个包含数据的表或表的集合。管道转发运算符将这些表通过管道输送到下一个函数或操作中,在那里它们将被进一步处理或操作。
Tables :Flux 构造表格中的所有数据。当数据从数据源流式传输时,Flux 将其格式化为带注释的逗号分隔值 (CSV),表示表格。然后函数操作或处理它们并输出新表。
Group keys :每个表都有一个组键(Group keys),用于描述表的内容。它是一个列列表,表中的每一行都具有相同的值。每行中具有唯一值的列不是组键的一部分。
示例 group key
Group key: [_start, _stop, _field]_start:time _stop:time _field:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ------------------------------ ----------------------------
2019-04-25T17:33:55.196959000Z 2019-04-25T17:34:55.196959000Z used_percent 2019-04-25T17:33:56.000000000Z 65.55318832397461
2019-04-25T17:33:55.196959000Z 2019-04-25T17:34:55.196959000Z used_percent 2019-04-25T17:34:06.000000000Z 65.52391052246094
2019-04-25T17:33:55.196959000Z 2019-04-25T17:34:55.196959000Z used_percent 2019-04-25T17:34:36.000000000Z 65.536737442016
注意:_time和_value被排除在示例组键之外,它们对于每一行都是唯一的。
2>查询语法
https://docs.influxdata.com/influxdb/v2.0/query-data/get-started/query-influxdb/
指定数据源:from(bucket:"example-bucket")
指定时间范围:
使用管道转发运算符 ( |>) 将数据从数据源通过管道传输到range() 函数,该函数指定查询的时间范围。它接受两个参数:start和stop。范围可以是使用相对负持续时间 或使用绝对时间
// Relative time range with start only. Stop defaults to now.
from(bucket:"example-bucket")
|> range(start: -1h)// Relative time range with start and stop
from(bucket:"example-bucket")
|> range(start: -1h, stop: -10m)//使用绝对时间
from(bucket:"example-bucket")
|> range(start: 2018-11-05T23:30:00Z, stop: 2018-11-06T00:00:00Z)//过去十五分钟的数据
from(bucket:"example-bucket")
|> range(start: -15m)
3>数据过滤:
将范围数据传递到filter()函数中,以根据数据属性或列缩小结果范围。该filter()函数有一个参数 ,fn它需要一个匿名函数,该函数具有基于列或属性过滤数据的逻
// Pattern
(r) => (r.recordProperty comparisonOperator comparisonExpression)// Example with single filter
(r) => (r._measurement == "cpu")// Example with multiple filters
(r) => (r._measurement == "cpu") and (r._field != "usage_system" )//按cpu度量、usage_system字段和cpu-total标记值过滤
from(bucket:"example-bucket")
|> range(start: -15m)
|> filter(fn: (r) =>r._measurement == "cpu" andr._field == "usage_system" andr.cpu == "cpu-total"
)
4>生成指定查询数据
Flux 的yield()函数将过滤后的表作为查询结果输出。
Flux 会yield()在每个脚本的末尾自动假设一个函数,以便输出和可视化数据。yield()只有在同一个 Flux 查询中包含多个查询时,才需要显式调用。每组返回的数据都需要使用该yield()函数命
from(bucket:"example-bucket")
|> range(start: -15m)
|> filter(fn: (r) =>r._measurement == "cpu" andr._field == "usage_system" andr.cpu == "cpu-total"
)
|> yield()
5>数据转换
使用函数,将数据聚合为平均值、下采样数据等
//更新范围从最后一小时拉取数据
from(bucket:"example-bucket")
|> range(start: -1h)
|> filter(fn: (r) =>r._measurement == "cpu" andr._field == "usage_system" andr.cpu == "cpu-total"
)//以五分钟为间隔的窗口化数据
from(bucket:"example-bucket")
|> range(start: -1h)
|> filter(fn: (r) =>r._measurement == "cpu" andr._field == "usage_system" andr.cpu == "cpu-total"
)
|> window(every: 5m)//聚合窗口数据
from(bucket:"example-bucket")
|> range(start: -1h)
|> filter(fn: (r) =>r._measurement == "cpu" andr._field == "usage_system" andr.cpu == "cpu-total"
)
|> window(every: 5m)
|> mean()//添加时间列到聚合函数
from(bucket:"example-bucket")
|> range(start: -1h)
|> filter(fn: (r) =>r._measurement == "cpu" andr._field == "usage_system" andr.cpu == "cpu-total"
)
|> window(every: 5m)
|> mean()
|> duplicate(column: "_stop", as: "_time")//取消窗口聚合表,将所有点收集到一个无限的窗口中
from(bucket:"example-bucket")
|> range(start: -1h)
|> filter(fn: (r) =>r._measurement == "cpu" andr._field == "usage_system" andr.cpu == "cpu-total"
)
|> window(every: 5m)
|> mean()
|> duplicate(column: "_stop", as: "_time")
|> window(every: inf)//辅助函数(将聚合或选择器函数应用于固定的时间窗口,通过every指定窗口的持续时间)
from(bucket:"example-bucket")
|> range(start: -1h)
|> filter(fn: (r) =>r._measurement == "cpu" andr._field == "usage_system" andr.cpu == "cpu-total"
)
|> aggregateWindow(every: 5m, fn: mean)
6>语法基础与通量函数
语法基础:https://docs.influxdata.com/influxdb/v2.0/query-data/get-started/syntax-basics/
通量函数包:https://docs.influxdata.com/influxdb/v2.0/reference/flux/stdlib/
比如:mean()函数对每个时间窗口内的值求平均值(https://docs.influxdata.com/influxdb/v2.0/reference/flux/stdlib/built-in/transformations/aggregates/mean/)
五、可视化数据
https://docs.influxdata.com/influxdb/v2.0/visualize-data/visualization-types/
支持的可视化类型:
Band (乐队):显示随时间变化的数据组的上限和下限

guage(仪表盘):仪表视图中显示时间序列的单个值最新值
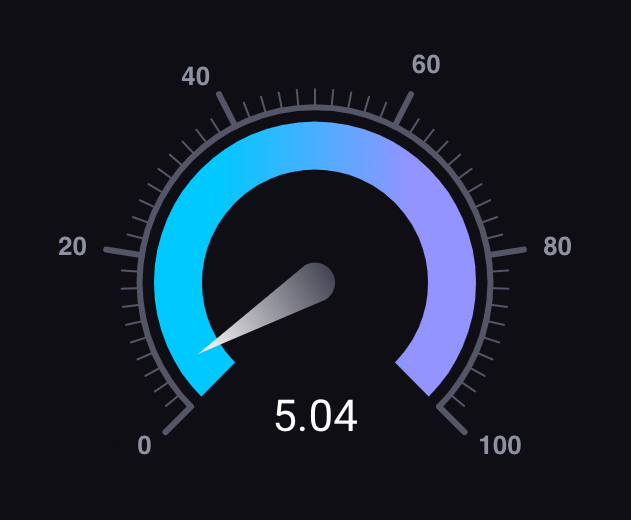
graph(图形):折线图

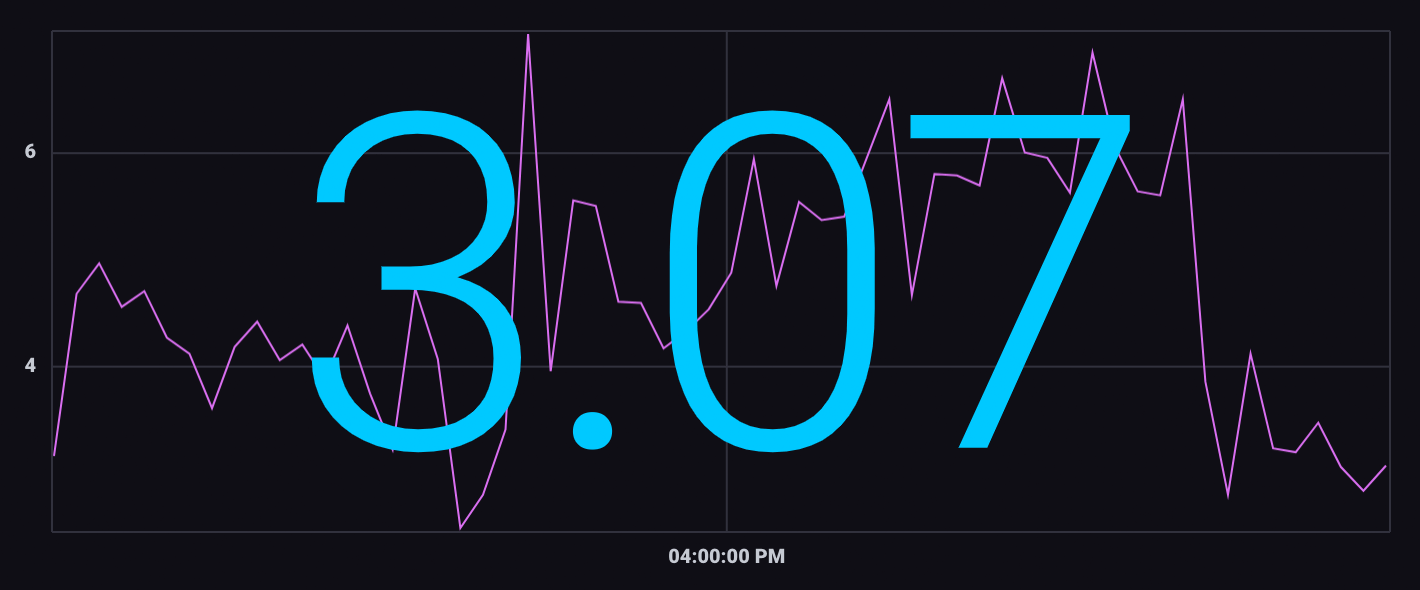
Graph + Single Stat(图表+单一统计):以折线图显示指定的时间序列,并将最近的单个值叠加为一个大数值
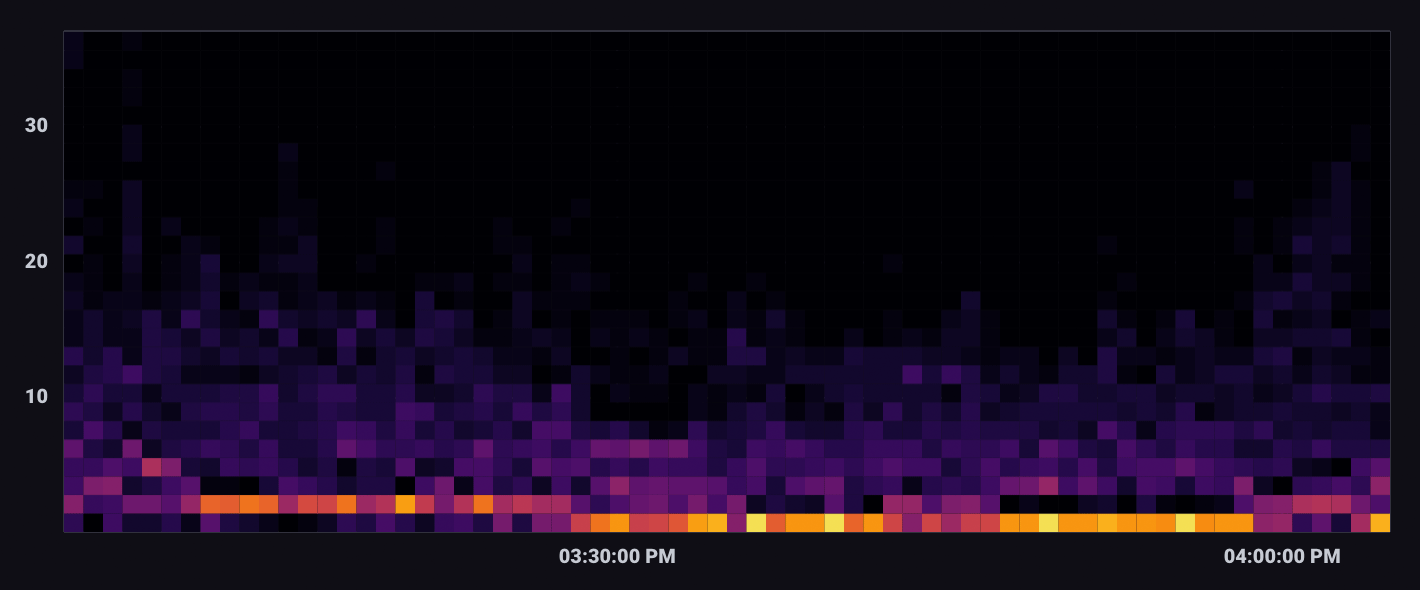
heatmap(热图):显示 x 和 y 轴上的数据分布,其中颜色代表不同的数据点浓度
histogram(直方图):一种查看数据分布的方法。y 轴专用于计数,x 轴分为 bin

mosaic(马赛克):化显示时间序列数据中的状态变化

scatter(散点图):视图使用散点图来显示时间序列数据
single stat(单项统计): 将指定时间序列的最新值显示为数值

table(表格视图):表格视图中显示查询结果

本地制造数据,通过图表数据展示案例:

grafana集成数据展示:

结论:
- influxdb控制台提供接入sdk源码,可直接在代码中使用,其他模块可直接在界面操作influxdb,使用体验较好
- influxdb可视化图表数量有限,如果图表无法满足需求,可以选择使用grafana展示数据,总体感觉grafana使用起来更舒适,数据显示更清晰
- flux刚开始不会写,通过控制台操作图表选择属性或函数,可以生成简单的flux语句
附录
官网地址:https://docs.influxdata.com/influxdb/v2.0/
相关文章:
InfluxDB 2 介绍与使用 flux查询 数据可视化
一、关键概念 相比V1 移除了database 和 RP,增加了bucket。 V2具有以下几个概念: timestamp、field key、field value、field set、tag key、tag value、tag set、measurement、series、point、bucket、bucket schema、organization 新增的概念&…...
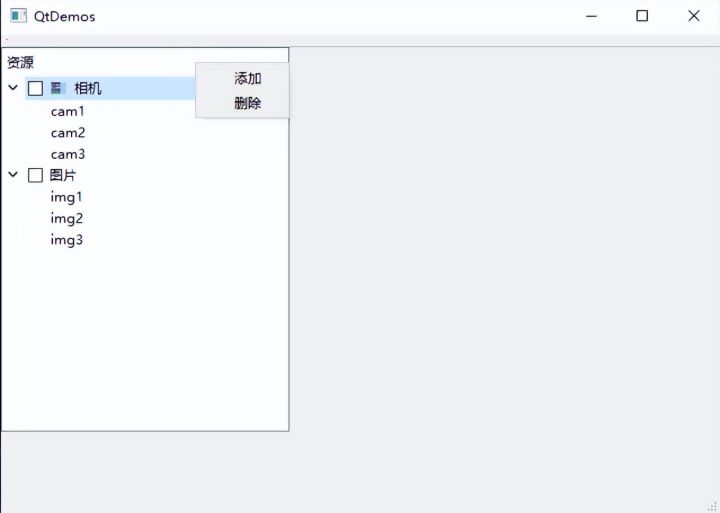
Qt QTreeView简单使用
QT-QTreeView使用方法 QTreeView: 用于显示树状结构数据,适用于树状结构数据的操作。 一、初始化 利用QStandardlternModel来初始化数据,标准的基于项数据的数据模型类, 每个项数据可以是任何数据类型。 // 初始化model QStandardItem…...
Wannacrypt蠕虫老树开花?又见Wannacrypt
Wannacrypt蠕虫是一个在2017年就出现的远古毒株,其利用永恒之蓝漏洞降维打击用户服务器,而后进行扩散勒索,曾经一度风靡全球,可谓是闻者伤心,听着落泪,因为这玩意解密是不可能 解密的。 而2023年的今天&am…...
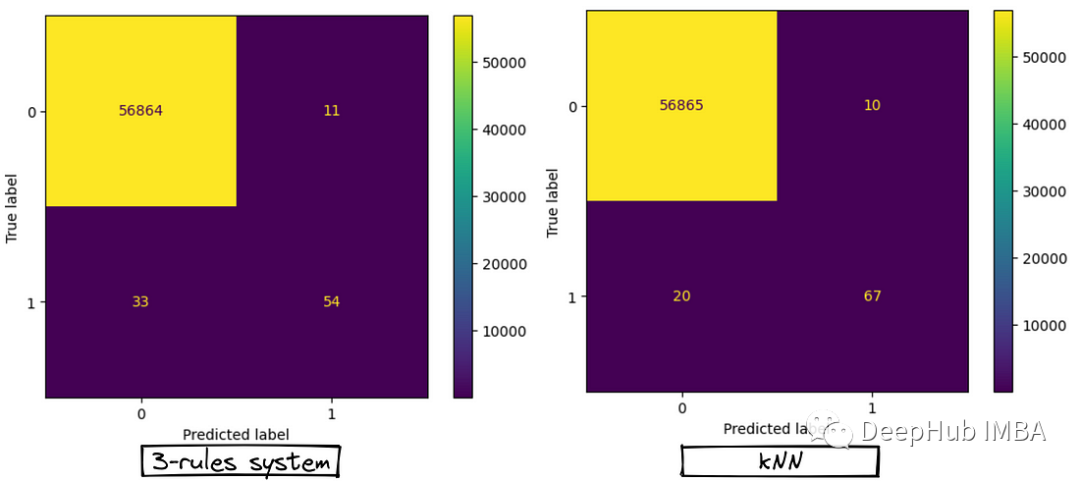
结合基于规则和机器学习的方法构建强大的混合系统
经过这些年的发展,我们都确信ML即使不能表现得更好,至少也可以在几乎所有地方与前ML时代的解决方案相匹配。比如说一些规则约束,我们都会想到能否把它们替换为基于树的ml模型。但是世界并不总是黑白分明的,虽然机器学习在解决问题…...
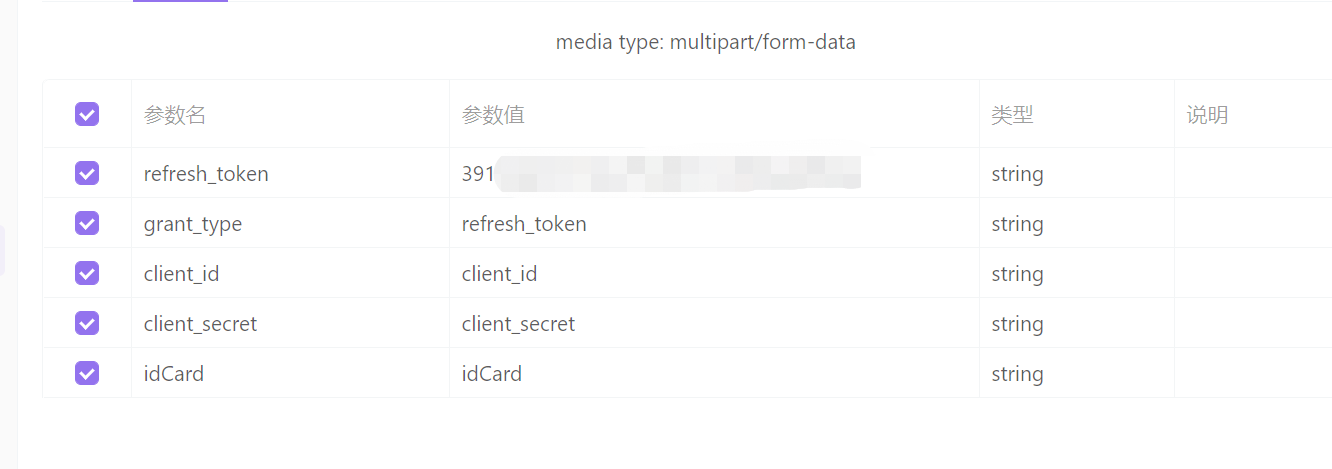
Spring Security OAuth2实现多用户类型认证、刷新Token
原本的OAuth2登录支持用户名密码登录,现在还想支持另外用id号码和密码登录。但是OAuth2默认提供的UserDetailsService只允许传入一个参数:想要实现多种用户登录,是不是可以考虑loadUserByUsername方法携带多个参数呢?接下来记录一…...

云计算介绍,让你更了解云计算
同学们好! 第一次接触IT行业吗?没关系,看完这篇文章肯定会让你不再陌生。给自己几分钟时间,认真看完哦! 1、不知道什么是云计算? 网络计算云计算 官方定义是:通过网络提供可伸缩的分布式计算…...

阿里大佬翻遍全网Java面试文章,总结出这份1658页文档,GitHub收获25K+点赞
就目前大环境来看,跳槽成功的难度比往年高很多。一个明显的感受:今年的面试,无论一面还是二面,都很考验Java程序员的技术功底。这不又到了面试跳槽的黄金段,成功升职加薪,不成功饱受打击。当然也要注意&…...

【JDK1.8 新特性】Lambda表达式
1. 什么是Lambda表达式? Lambda 是一个匿名函数,我们可以把 Lambda 表达式理解为是一段可以传递的代码(将代码像数据一样进行传递)。使用它可以写出更简洁、更灵活的代码。作为一种更紧凑的代码风格,使Java的语言表达…...

【Vue.js】Vuex核心概念
文章目录全局状态管理模式Vuexvuex是什么?什么是“状态管理模式”?vuex的应用场景Vuex安装开始核心概念一、State1、单一状态树2、在 Vue 组件中获得 Vuex 状态3、mapState辅助函数二、Getter三、Mutation1、提交载荷(Payload)2、…...

react router零基础使用教程
安装既然学习 react router 就免不了运行 react安装 reactnpx create-react-app my-appcd my-appnpm start安装 react routernpm install react-router-dom如果一切正常,就让我们打开 index.js 文件。配置路由引入 react-router-dom 的 RouterProviderimport {Route…...

IOC三种依赖注入的方式,以及区别
目录构造方法注入(constructor injection)setter 方法注入(setter injection)接口注入(interface injection)三种方式比较构造方法注入(constructor injection) 构造方法中声明依赖…...
Ubuntu18安装新版本PCL-1.13,并和ROS自带PCL-1.8共存
文章目录1.安装新版本PCL-1.132.在工程中使用新版本的PCL-1.133.pcl-1.13误装到/usr/local/下如何卸载1.安装新版本PCL-1.13 下载PCL-1.13代码: 修改CMakeLists.txt文件,不编译vtk相关的代码:vtk的问题比较难解决,但是一般我们安…...
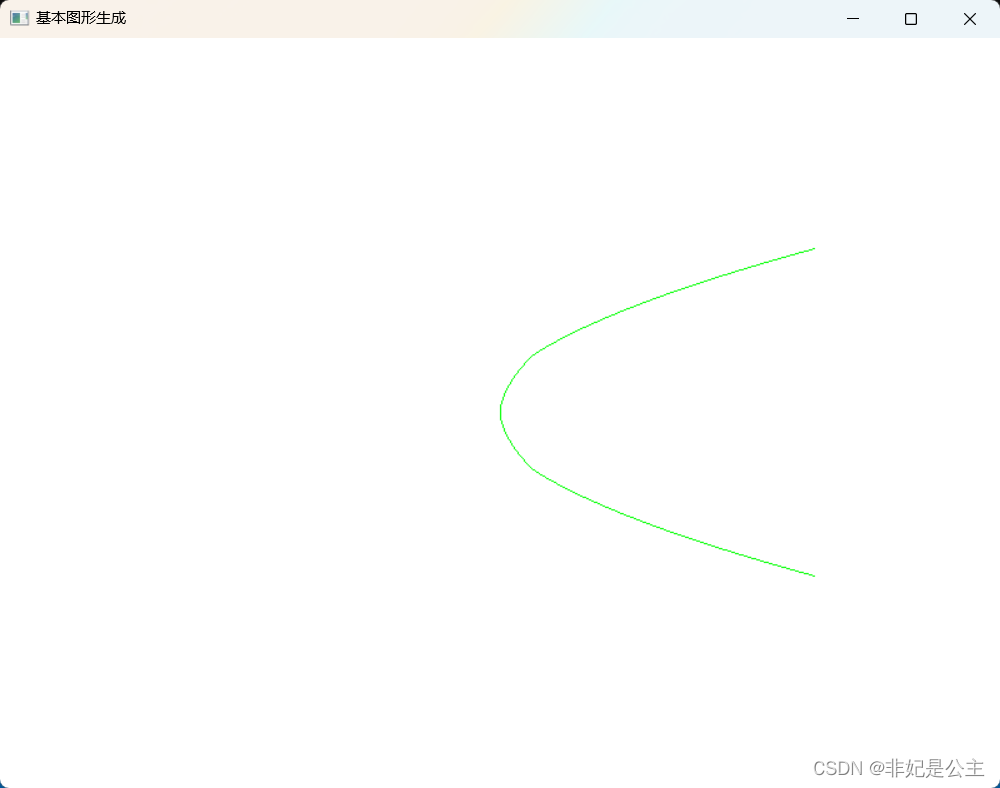
计算机图形学08:中点BH算法绘制抛物线(100x = y^2)
作者:非妃是公主 专栏:《计算机图形学》 博客地址:https://blog.csdn.net/myf_666 个性签:顺境不惰,逆境不馁,以心制境,万事可成。——曾国藩 文章目录专栏推荐专栏系列文章序一、算法原理二、…...
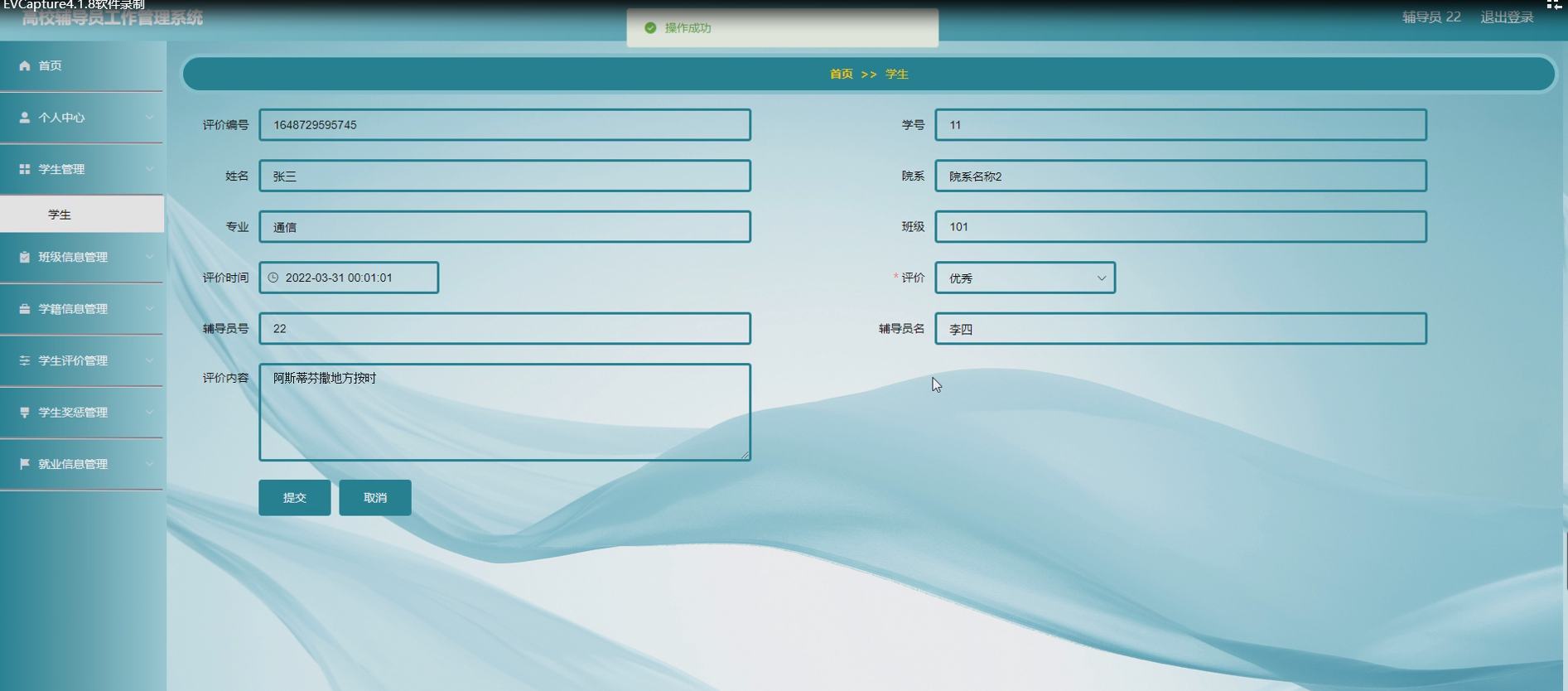
基于java的高校辅导员工作管理系统
摘 要网络技术的快速发展给各行各业带来了很大的突破,也给各行各业提供了一种新的管理模块,对于高校辅导员工作管理将是又一个传统管理到智能化信息管理的改革,设计高校辅导员工作管理系统的目的就是借助计算机让复杂的班级信息、学籍信息等管…...
字节3次都没裁掉的7年老测试。掌握设计业务与技术方案,打开上升通道!
前言职场中的那些魔幻操作,研发最烦的是哪个?“面对业务需求的时候,可能都听过这样一句话:这个很简单,直接开发,三天内上线;”朋友说:“产品听了流泪,测试见了崩溃&#…...
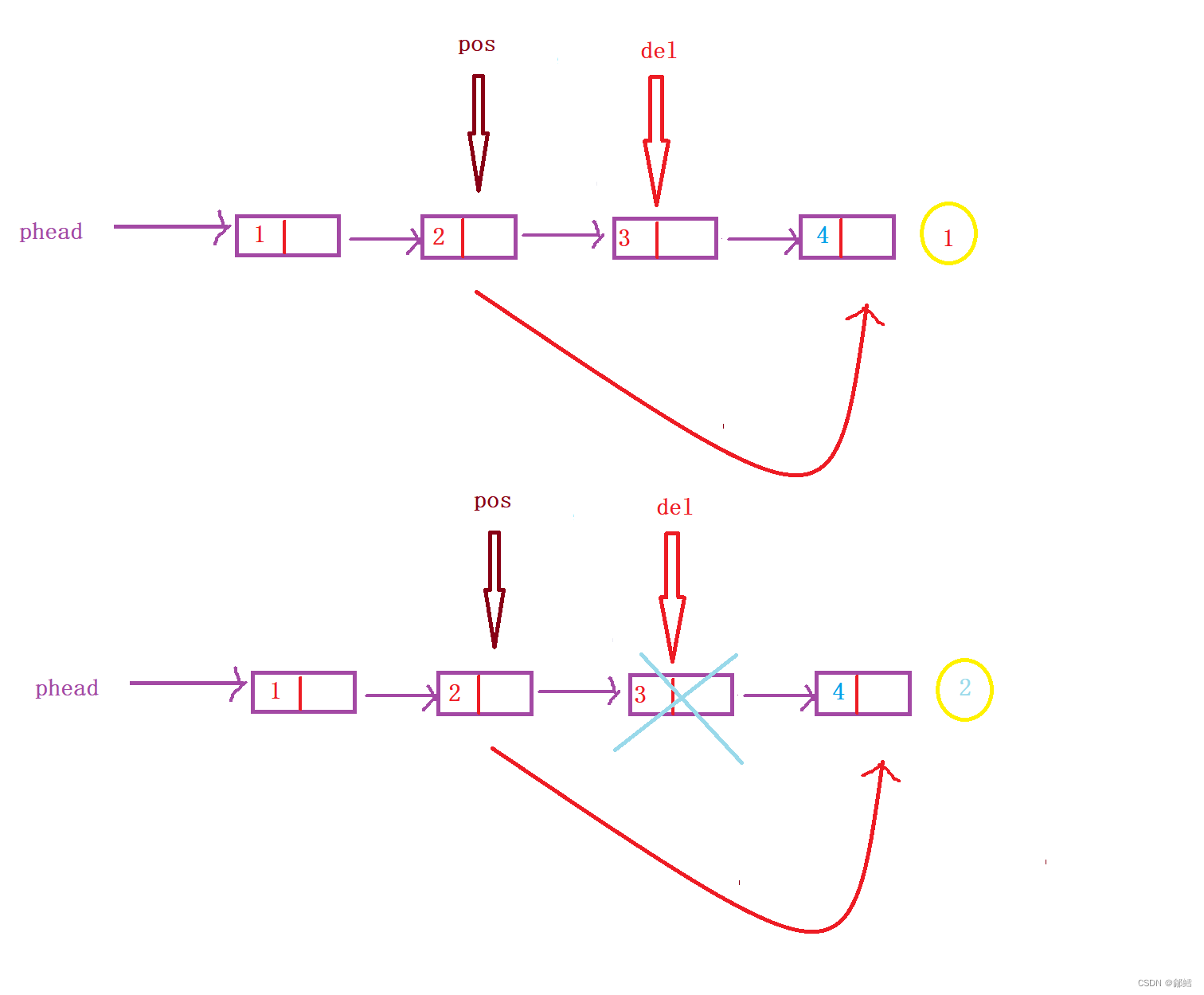
详细介绍关于链表【数据结构】
文章目录链表单链表尾插头插尾删第一种方式删除第二种头删查找pos之前插入pos位置删除pos后面插入pos位置后面删除链表 顺序表缺点: 空间不够了 需要扩容,但是扩容是有消耗的头部或中间位置需要插入或删除,需要挪动 ,但是挪动是…...

2.3 二分搜索技术
二分搜索算法是运用分治策略的典型例子。给定己排好府的 n个元素a10:n-1],现要在这n个元素中找出一特定元素3。首先较容易想到的是用顺序搜索方法,逐个比较a10:1-1]中元素,直至找出元素,或搜索遍整个数组后确定,不在其…...
RWEQ模型的土壤风蚀模数估算、其变化归因分析
土壤风蚀是一个全球性的环境问题。中国是世界上受土壤风蚀危害最严重的国家之一,土壤风蚀是中国干旱、半干旱及部分湿润地区土地荒漠化的首要过程。中国风蚀荒漠化面积达160.74104km2,占国土总面积的16.7%,严重影响这些地区的资源开发和社会经…...
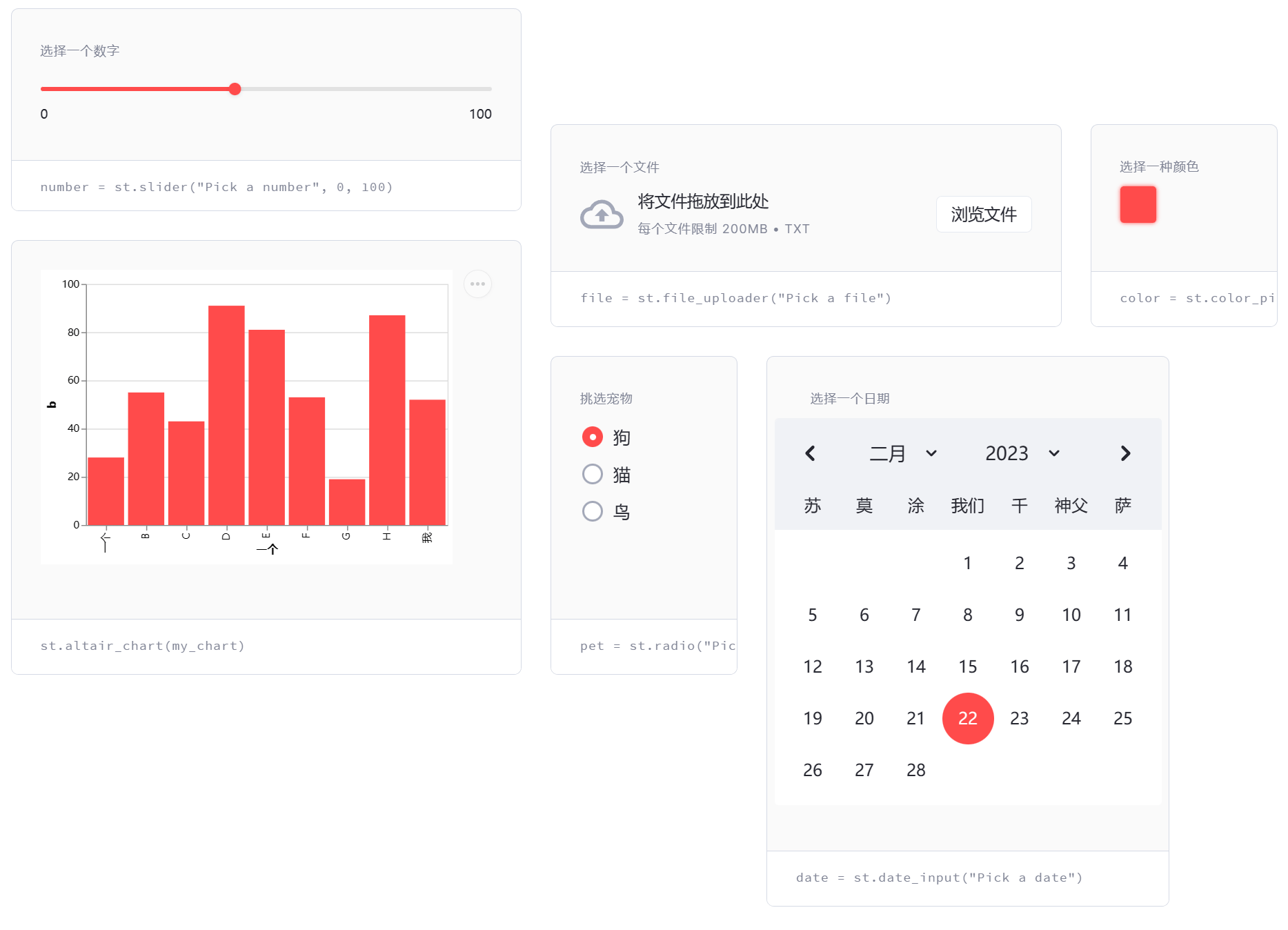
学习streamlit-1
Streamlit A faster way to build and share data apps streamlit在几分钟内就可以将数据脚本转换为可共享的web应用程序,并且是纯python编程,无需前端经验。 快速开始 streamlit非常容易上手,运行demo只需2行代码: pip install…...

GPS定位知识介绍
GPS定位和网络定位 GPS定位需要卫星参与,设备借助搜到的卫星讯号,计算出设备的位置。网络定位是指利用基站、WIFI MAC,获取一个粗略的位置。3D定位和2D 定位 3D一般是指使用至少4颗以上卫星完成的定位。2D一般使用3颗卫星完成的定位过程。...

怎样高效管理微信社交网络:5个微信工具箱实用技巧完整指南
怎样高效管理微信社交网络:5个微信工具箱实用技巧完整指南 【免费下载链接】wechat-toolbox WeChat toolbox(微信工具箱) 项目地址: https://gitcode.com/gh_mirrors/we/wechat-toolbox 微信工具箱(wechat-toolbox…...
)
AI原生图计算应用落地全景图(SITS 2026权威白皮书核心精要)
更多请点击: https://intelliparadigm.com 第一章:AI原生图计算应用:SITS 2026图神经网络工程化方案 SITS 2026 是面向大规模动态图场景的AI原生图计算框架,深度融合GNN训练、图拓扑实时更新与边缘-云协同推理能力。其核心设计摒…...

AzurLaneAutoScript:如何用智能自动化脚本彻底解放你的碧蓝航线时间?
AzurLaneAutoScript:如何用智能自动化脚本彻底解放你的碧蓝航线时间? 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLane…...

18.地下室的服务器
六月第一个周末的深夜,暴雨如注。陈远坐在书桌前,屏幕上是花花绿绿的监控图表,代表着他那台二手服务器资源使用率的曲线,正像垂死病人的心电图一样剧烈地上下跳动。CPU占用率长时间维持在90%以上,内存也逼近红线。这已…...

AI工作流框架实战:从脚本到自动化流程的架构设计与应用
1. 项目概述:当AI遇上工作流最近在折腾自动化工具链,发现一个挺有意思的项目叫ai-flow。这名字听起来就挺直白,AI 工作流。简单来说,它就是一个用代码来编排和自动化AI任务(比如调用大语言模型、处理数据、执行特定操…...

从仿真到PCB:基于74LS系列芯片的十字路口交通灯系统实战设计
1. 项目背景与设计目标 十字路口交通灯控制系统是数字电路课程的经典实践项目。记得我第一次接触这个课题时,既兴奋又忐忑——兴奋的是终于能把课本上的与非门、触发器应用到真实场景,忐忑的是从仿真到实物可能存在的各种"坑"。这个基于74LS系…...

终极指南:Flair如何引领NLP技术未来发展趋势
终极指南:Flair如何引领NLP技术未来发展趋势 【免费下载链接】flair A very simple framework for state-of-the-art Natural Language Processing (NLP) 项目地址: https://gitcode.com/gh_mirrors/fl/flair Flair是一个由柏林洪堡大学开发的简单而强大的自…...
)
用STM32的TIM1和GPIO中断,手把手教你实现带霍尔BLDC的平稳启动与调速(附PID代码)
STM32实战:基于霍尔传感器的BLDC电机六步换相与PID调速全解析 在工业自动化、无人机和机器人等领域,无刷直流电机(BLDC)凭借其高效率、长寿命和低噪音特性成为首选驱动方案。本文将深入探讨如何利用STM32的TIM1高级定时器和GPIO中断实现带霍尔传感器的BL…...

加州DMV十年自动驾驶报告深度解析:从测试数据看行业格局与技术演进
1. 项目概述:一份数据,十年自动驾驶风云如果你关注自动驾驶,那你一定听说过加州车管局(DMV)的年度测试报告。这玩意儿,可以说是全球自动驾驶行业的“晴雨表”和“成绩单”。从2015年开始,加州就…...

告别IDEA编译警告:深入解析JDK版本过时问题与多维度解决方案
1. 当IDEA开始"抱怨":那些烦人的编译警告从哪来? 每次打开老项目,总能看到那个熟悉的黄色警告:"Warning:java: 源值1.5已过时,将在未来所有发行版中删除"。这个提示就像个唠叨的老朋友,…...