机器学习_集成学习_梯度提升_回归_决策树_XGBoost相关概念
目录
1. 机器学习 使用监督吗?什么又是监督学习?
2. 与XGBoost 类似的机器学习方法有哪些?
3. 随机森林方法 和 梯度提升方法 有什么区别? 分别应用于什么场景?
4. 决策树回归方法 和 Gradient Boosting类回归方法 有什么区别和联系?
5. 什么是集成学习?
6. 多元线性回归方法 和 多项式回归方法 区别和联系?
7. 梯度提升回归方法 梯度下降回归方法 区别和联系? 各自应用场景?
8. 梯度提升回归方法(Gradient Boosting Regression 有哪些分类?
9. 梯度提升回归方法 有没有不是基于 梯度提升树 的方法
10. 什么是专家模型?
11. 多元线性回归方法 属于专家方法, 还是机器学习方法?
12.专家系统 和专家模型 区别联系?
13. 专家模型 和 机器学习模型 的区别和联系
14. 全局性和系统性的区别?
来自chatgpt
1. 机器学习 使用监督吗?什么又是监督学习?
是的,机器学习可以使用监督学习。监督学习是一种机器学习方法,其中模型从标记的数据中学习,也就是输入数据和相应的标签或目标值之间的映射关系。在监督学习中,训练数据集包含了模型需要学习的特征(输入)以及相应的标签(输出),模型通过学习这些特征和标签之间的关系来进行预测或分类。
监督学习可以分为两类主要任务:
-
回归:在回归问题中,目标是预测连续值的输出。例如,根据房屋的特征(如面积、卧室数量、位置等),预测房屋的价格。
-
分类:在分类问题中,目标是将输入数据分到不同的类别中。例如,根据肿瘤的特征(如大小、形状、密度等),将肿瘤分为良性和恶性两类。
监督学习的步骤通常包括:
-
数据准备:收集和清理数据,将数据集划分为训练集和测试集。
-
特征选择和提取:选择适当的特征并进行必要的数据预处理。
-
模型选择和训练:选择合适的监督学习模型,并使用训练数据来训练模型。
-
模型评估:使用测试数据集评估模型的性能和泛化能力。
监督学习是机器学习中最常用的方法之一,它在许多领域中都有广泛的应用,如图像识别、自然语言处理、医学诊断等。
2. 与XGBoost 类似的机器学习方法有哪些?
与XGBoost类似的机器学习方法包括:
-
LightGBM(Light Gradient Boosting Machine):由微软提出的一种梯度提升框架,专注于处理大规模数据集和高效的并行训练。
-
CatBoost:由Yandex开发的梯度提升算法,专注于处理类别型特征的梯度提升框架,能够自动处理类别特征的编码。
-
Gradient Boosting Machine(GBM):梯度提升的传统实现,是XGBoost和其他梯度提升方法的基础。
-
AdaBoost(Adaptive Boosting):另一种集成学习方法,也是使用迭代的方式训练一系列弱分类器,但它是通过调整实例的权重来提高模型性能。
-
Random Forest(随机森林):一种基于决策树的集成学习方法,通过随机选择特征和样本来构建多个决策树,并通过投票或平均的方式进行预测。
-
Extra Trees(极端随机树):与随机森林类似,但是在每个节点上随机选择特征,并且使用随机阈值来进行划分,从而提高了模型的多样性。
这些方法都是基于集成学习的思想,通过结合多个弱学习器来构建强大的模型,从而提高模型的性能和泛化能力。选择合适的方法取决于数据的特性、问题的复杂性以及任务的需求。
3. 随机森林方法 和 梯度提升方法 有什么区别? 分别应用于什么场景?
随机森林方法(Random Forest)和梯度提升方法(Gradient Boosting)是两种常见的集成学习技术,它们有着不同的特点和适用场景。
-
随机森林(Random Forest):
-
特点:
-
使用多个决策树进行集成,每个决策树都是一个弱学习器。
-
在构建每棵树时,随机选择样本和特征进行训练,以增加模型的多样性。
-
通过投票或平均的方式来进行预测。
-
-
适用场景:
-
对于分类和回归问题都适用。
-
处理高维度数据集和大规模数据集时表现良好。
-
对于需要快速建模和预测的场景,由于随机性的特性,随机森林通常比较快速。
-
-
-
梯度提升(Gradient Boosting):
-
特点:
-
通过迭代地训练多个弱学习器,每一轮都专注于修正前一轮的错误,从而逐步提高整体模型的性能。
-
每个新模型的建立是为了最小化损失函数的梯度。
-
通常采用决策树作为基学习器。
-
-
适用场景:
-
对于分类和回归问题都适用,尤其是回归问题。
-
处理各种类型的数据,包括高维度数据。
-
在需要更高预测准确率的任务中表现良好,例如 Kaggle 竞赛等。
-
-
总结:
-
随机森林适用于各种场景,特别是对于需要快速建模和预测的任务,以及大规模数据集。
-
梯度提升在需要更高预测准确率的任务中表现良好,但可能需要更多的调参和计算资源。
4. 决策树回归方法 和 Gradient Boosting类回归方法 有什么区别和联系?
决策树回归方法和Gradient Boosting类回归方法都是用于解决回归问题的机器学习算法,它们有一些区别和联系:
-
基本算法:
-
决策树回归方法:是一种基于决策树的算法,通过构建决策树来进行回归预测。它将特征空间划分为多个矩形区域,并在每个区域内拟合一个常数值,从而实现对目标变量的预测。
-
Gradient Boosting类回归方法:是一种集成学习算法,其主要思想是通过顺序地训练一系列弱学习器(通常是决策树),每个弱学习器都在之前弱学习器的残差上进行拟合,从而逐步改进预测性能。
-
-
训练方式:
-
决策树回归方法:通常是直接构建一个单独的决策树来拟合数据。
-
Gradient Boosting类回归方法:是一种迭代的训练过程,每一步都会添加一个新的模型(通常是决策树),并且会根据之前模型的残差来调整目标函数,以逐步提高模型性能。
-
-
模型复杂度:
-
决策树回归方法:每个决策树通常是相对简单的模型,不过可以通过集成多棵决策树来构建更复杂的模型。
-
Gradient Boosting类回归方法:由于是通过多个模型的组合来提高性能,因此往往可以构建更为复杂的模型。
-
-
鲁棒性和泛化能力:
-
决策树回归方法:由于每棵决策树只关注于局部特征,可能存在过拟合的问题,特别是在深度较大时。
-
Gradient Boosting类回归方法:由于是通过多个模型的组合来降低预测误差,因此往往具有较好的鲁棒性和泛化能力。
-
-
联系:
-
Gradient Boosting类回归方法中的每个基学习器通常可以选择决策树回归方法作为其基础模型,因此可以说Gradient Boosting是一种扩展了决策树回归方法的技术,通过集成多个决策树来提高性能。
-
总的来说,决策树回归方法和Gradient Boosting类回归方法在解决回归问题时有一些相似之处,但也存在一些显著的区别,主要体现在训练方式、模型复杂度和性能等方面。
在梯度提升决策树回归方法中, 弱学习器 和 决策树的区别和联系?
在梯度提升决策树回归方法中,"弱学习器"通常指的是基础的决策树模型,这些决策树模型通常是浅层的、限制了深度或叶子节点样本数量的决策树,因此被称为"弱"学习器。而"决策树"是一种具体的机器学习算法,用于构建以决策树结构表示的预测模型。
区别:
-
深度:弱学习器通常是浅层的决策树,具有较低的深度或限制了叶子节点的数量,以防止过拟合。而决策树可以是任意深度的,可以拟合更复杂的数据模式。
-
复杂度:弱学习器通常是简单的模型,具有较少的参数和规则。决策树可以是复杂的模型,可以包含更多的分裂节点和条件。
联系:
-
基础模型:弱学习器通常是梯度提升决策树中的基础模型,通过迭代地组合多个弱学习器来构建最终的预测模型。
-
决策树结构:弱学习器和决策树都是以决策树结构表示的模型,它们都通过一系列的特征划分来对输入数据进行预测。
-
集成学习:梯度提升决策树是一种集成学习方法,它通过组合多个弱学习器来提升整体模型的性能。因此,弱学习器在梯度提升决策树中扮演了重要的角色。
总的来说,弱学习器是梯度提升决策树中的基础模型,通常是浅层的、简单的决策树模型,而决策树是一种具体的机器学习算法,可以构建复杂的、深层的决策树模型。在梯度提升决策树中,通过组合多个弱学习器来构建更强大的集成模型,提高预测性能。
5. 什么是集成学习?
集成学习(Ensemble Learning)是一种机器学习方法,它通过组合多个模型来改善整体预测性能。它的核心思想是“众口铄金”,即通过组合多个模型的预测结果,以期望得到更好的结果,比单个模型的预测结果更可靠和准确。
集成学习的基本原理是结合多个弱学习器(Weak Learners),弱学习器通常是指在一定条件下预测结果略好于随机猜测的学习器。通过将多个弱学习器集成起来,可以产生一个强大的集成学习器(Strong Learner),其预测性能通常优于任何单个弱学习器。
集成学习方法通常可以分为两种类型:
-
平均方法(Averaging Methods):通过将多个模型的预测结果取平均来得到最终的预测结果。例如,Bagging 方法就是基于平均方法的一种典型代表,它通过对数据集进行有放回的随机抽样,训练出多个模型,然后将这些模型的预测结果取平均。
-
增强方法(Boosting Methods):通过迭代地训练多个模型,并重点关注之前模型预测错误的样本,以修正错误,从而逐步提高整体模型的性能。例如,梯度提升方法就是一种基于增强方法的典型代表,它通过训练多个弱学习器,每个弱学习器都专注于修正前一个弱学习器的错误。
集成学习方法在实践中被广泛应用,能够显著提高模型的性能和泛化能力,尤其在面对复杂任务和数据不平衡的情况下表现突出。
6. 多元线性回归方法 和 多项式回归方法 区别和联系?
多元线性回归和多项式回归是两种常见的回归分析方法,它们之间有一些区别和联系:
-
基本形式:
-
多元线性回归:多元线性回归是一种线性模型,用于建立自变量(特征)与因变量之间的线性关系。它的基本形式可以表示为 Y = β0 + β1X1 + β2X2 + ... + βnXn + ε,其中 Y 是因变量,X1、X2、...、Xn 是自变量,β0、β1、β2、...、βn 是回归系数,ε 是误差项。
-
多项式回归:多项式回归是一种非线性模型,它通过引入多项式的高次项来拟合数据。其基本形式可以表示为 Y = β0 + β1X + β2X^2 + ... + βnX^n + ε,其中 Y 是因变量,X 是自变量,β0、β1、β2、...、βn 是回归系数,ε 是误差项。多项式回归允许拟合出曲线关系,而不仅限于直线。
-
-
灵活性:
-
多元线性回归:多元线性回归假设因变量与自变量之间的关系是线性的,因此适用于那些因变量与自变量之间呈现线性关系的情况。
-
多项式回归:多项式回归对于因变量与自变量之间的关系没有线性的假设限制,可以拟合出更加灵活的曲线关系,因此在数据呈现非线性关系时更为适用。
-
-
模型复杂度:
-
多元线性回归:多元线性回归模型通常比较简单,只涉及到一阶的自变量。
-
多项式回归:多项式回归的模型复杂度取决于所选择的多项式的阶数,阶数越高,模型越复杂,可以更好地拟合复杂的数据。
-
-
过拟合风险:
-
多元线性回归:由于其线性假设,当数据之间的关系非线性时,可能导致拟合不足,但相对来说,过拟合的风险相对较低。
-
多项式回归:高阶多项式回归容易出现过拟合,特别是在使用高阶多项式时,对于噪声敏感,可能会过度拟合训练数据而泛化能力较差。
-
-
联系:
-
多元线性回归可以被视为多项式回归的特例,当多项式的阶数为1时,多项式回归退化为多元线性回归。
-
在实践中,多项式回归可以通过选择适当的多项式阶数来拟合非线性数据,而多元线性回归则更适用于线性数据的建模。
-
总的来说,多元线性回归和多项式回归都是回归分析中常用的方法,选择哪种方法取决于数据之间的关系及模型的需求。
7. 梯度提升回归方法 梯度下降回归方法 区别和联系? 各自应用场景?
梯度提升回归方法(Gradient Boosting Regression)和梯度下降回归方法(Gradient Descent Regression)虽然都涉及梯度,但它们是两种不同的机器学习算法,有着不同的原理、应用场景和方法。
-
梯度提升回归方法(Gradient Boosting Regression):
-
原理:梯度提升回归是一种集成学习方法,通过顺序地训练多个弱学习器(通常是决策树),每个模型都在前一个模型的残差上进行拟合,以逐步提升模型的性能。在每一轮迭代中,新的模型是通过梯度下降来最小化损失函数的残差。
-
应用场景:梯度提升回归适用于各种类型的回归问题,包括预测房价、股票价格、销售额等。它在数据集中存在复杂的非线性关系时尤其有效。
-
-
梯度下降回归方法(Gradient Descent Regression):
-
原理:梯度下降是一种优化算法,用于最小化一个目标函数(通常是损失函数)。在回归问题中,梯度下降被用来调整模型参数,使得损失函数最小化。通过计算目标函数的梯度,然后沿着梯度的反方向更新参数,以降低损失函数的值。
-
应用场景:梯度下降回归方法广泛应用于各种机器学习模型的训练中,包括线性回归、逻辑回归、神经网络等。它适用于大规模数据集和高维特征空间,并且在全局最优解相对容易求解时表现良好。
-
区别和联系:
-
梯度提升回归是一种集成学习方法,通过顺序地训练多个模型来提升整体性能;而梯度下降回归是一种优化算法,用于调整模型参数以最小化目标函数。
-
梯度提升回归主要用于构建预测性能较高的回归模型,而梯度下降可用于各种机器学习模型的参数优化。
-
在应用场景上,梯度提升回归通常用于解决复杂的非线性回归问题,而梯度下降则广泛用于机器学习模型的训练中。
总的来说,这两种方法在机器学习中扮演不同的角色,根据具体的问题和需求选择合适的方法。
8. 梯度提升回归方法(Gradient Boosting Regression 有哪些分类?
梯度提升回归方法(Gradient Boosting Regression)是一种集成学习技术,通过逐步优化基本的回归树模型来提升整体的预测性能。梯度提升回归方法可以分为以下几种分类:
-
梯度提升树(Gradient Boosting Trees):
-
梯度提升树是指以决策树为基础学习器,通过迭代地训练回归树模型并不断优化残差(负梯度),从而逐步提升整体模型的预测性能。
-
-
XGBoost (eXtreme Gradient Boosting):
-
XGBoost是梯度提升树的一种优化实现,通过提出正则化、并行计算和特征分桶等技术,显著提高了梯度提升树的性能和效率。
-
-
LightGBM (Light Gradient Boosting Machine):
-
LightGBM是另一种梯度提升树的优化实现,采用了基于直方图的决策树算法和梯度单边采样(Gradient-based One-Side Sampling,GOSS)等技术,提高了训练速度和内存利用效率。
-
-
CatBoost:
-
CatBoost是一种基于梯度提升树的开源机器学习库,专门针对类别特征的处理进行了优化,能够自动处理类别特征,并在处理数据时进行优化。
-
-
HistGradientBoosting:
-
HistGradientBoosting是scikit-learn中引入的一种梯度提升树算法,采用了直方图加速技术,能够在大规模数据集上实现更高的性能。
-
这些分类都是基于梯度提升回归方法的不同优化实现或特性,它们在不同的应用场景下可能表现出不同的性能和效果。选择合适的梯度提升回归方法需要考虑到数据特征、数据规模、训练时间和预测性能等因素。
9. 梯度提升回归方法 有没有不是基于 梯度提升树 的方法
梯度提升回归方法通常与梯度提升树(Gradient Boosting Trees)紧密相关,因为梯度提升回归是一种通过迭代地训练回归树模型并不断优化残差的技术。然而,除了基于梯度提升树的方法之外,还有其他类型的梯度提升回归方法,例如基于线性模型的梯度提升方法。
一种不基于梯度提升树的方法是基于线性模型的梯度提升方法,它将梯度提升技术应用于线性回归或广义线性模型。在这种方法中,每一轮迭代会拟合一个线性模型,并通过梯度下降来更新模型参数以最小化损失函数。这种方法的优势在于模型具有更好的可解释性,更容易理解和解释模型中各个特征对预测结果的影响。
虽然基于线性模型的梯度提升方法在某些情况下可能比基于树模型的方法具有一定优势,但通常情况下,基于树模型的梯度提升方法更为流行和广泛应用,因为它们通常能够更好地处理非线性关系和复杂的数据结构,同时在性能上也更为出色。
10. 什么是专家模型?
专家模型通常指的是一种基于专家知识和经验构建的模型。这些模型依赖于领域专家的见解和规则,而不是从数据中自动学习模式。专家模型在一些领域中仍然非常有用,特别是在数据稀缺或者需要透明且可解释性较高的情况下。
专家模型的特点包括:
-
基于规则的决策:专家模型通常由一系列规则组成,这些规则基于领域专家的经验和知识而不是从数据中学习得到的。
-
透明性和解释性:与一些黑盒机器学习模型相比,专家模型通常更容易解释和理解,因为它们的决策过程可以追溯到明确的规则和原理。
-
数据需求较少:专家模型不需要大量的数据来训练,因为它们的决策基于先验知识和规则,而不是数据驱动的学习过程。
-
易于调整和更新:由于专家模型的规则是明确的,因此可以相对容易地进行调整和更新,以反映新的知识或情境变化。
专家模型在一些领域中仍然被广泛应用,例如医学诊断、金融风险评估、工业控制等。然而,随着机器学习和深度学习等技术的发展,专家模型在某些情况下已经被更灵活和精确的数据驱动模型所取代。
11. 多元线性回归方法 属于专家方法, 还是机器学习方法?
多元线性回归方法通常被归类为机器学习方法,而不是专家方法。
在多元线性回归中,我们试图通过一组特征变量(自变量)来预测一个或多个目标变量(因变量)。该方法使用统计技术来建立自变量与因变量之间的线性关系。在训练阶段,模型通过观察数据集中的特征和目标值来学习这种关系,并找到最佳的系数,以便在给定新的特征值时进行预测。
虽然多元线性回归方法可能依赖于领域专家来选择和解释特征变量,但它的核心是基于数据的建模和预测。因此,它更符合机器学习方法的定义,即从数据中学习模型,并利用这些模型进行预测或决策。
专家方法通常更侧重于基于领域专家的规则、经验和知识来解决问题,而不是依赖于数据驱动的模型。典型的专家系统可能会使用专家的知识库和推理引擎来进行决策推断。因此,多元线性回归通常被归类为机器学习方法,而不是专家方法。
12.专家系统 和专家模型 区别联系?
专家系统和专家模型都是基于专家知识构建的工具,但它们在概念和应用上有一些不同之处。
-
专家系统:
-
专家系统是一种计算机程序,它模拟了领域专家的知识和推理过程,以解决特定领域的问题。
-
专家系统通常包括知识库、推理引擎和用户接口等组件,它们可以接收用户提供的信息并根据事先定义好的规则和知识来做出推断和决策。
-
专家系统的设计目标是通过模拟人类专家的思维过程来解决复杂问题,它们通常用于诊断、决策支持等领域。
-
-
专家模型:
-
专家模型是一种基于专家知识构建的数学模型或规则系统,用于解决特定问题或预测特定事件。
-
专家模型可以是简单的规则集合,也可以是基于经验和专家见解的数学方程或模型。
-
专家模型的目标是使用专家领域知识来帮助理解和解决问题,通常不涉及推理引擎或用户交互界面,而是直接应用于特定的预测或决策任务中。
-
因此,专家系统更侧重于模拟人类专家的推理过程,提供类似人类专家的决策支持功能,而专家模型更侧重于将专家知识转化为可计算的形式,通常用于预测或解决特定问题。在某些情况下,专家系统可以使用专家模型来支持其推理过程。
13. 专家模型 和 机器学习模型 的区别和联系
专家模型和机器学习模型是两种不同的建模方法,它们在概念、应用和工作原理上有所不同,但也有一些联系点。
区别:
-
基础原理:
-
专家模型依赖于领域专家的知识、经验和规则,这些规则通常以人工方式定义,而不是从数据中自动学习得来。
-
机器学习模型则通过从数据中学习模式和关系来进行预测或决策,而不需要人工明确规定的规则。
-
-
训练方式:
-
专家模型通常是通过人工定义和调整规则来构建的,不需要大量的数据进行训练。
-
机器学习模型则需要大量的数据用于训练,并通过优化算法自动调整模型参数以最大程度地拟合数据并提高性能。
-
-
可解释性:
-
专家模型通常具有较高的可解释性,因为它们的决策基于明确的规则和经验知识。
-
机器学习模型的可解释性通常较低,特别是对于复杂的模型(例如深度学习模型),因为它们的决策过程可能是黑盒的,难以理解。
-
-
灵活性和泛化能力:
-
机器学习模型通常更灵活,能够从数据中学习到复杂的模式和关系,具有较强的泛化能力,可以适应新的数据和情境。
-
专家模型可能在特定领域或问题上表现良好,但在面对未知情况或者需要适应新数据时,其泛化能力可能较差。
-
联系:
-
应用领域:
-
专家模型和机器学习模型都可以用于解决各种问题,例如分类、回归、聚类等。
-
选择使用哪种模型通常取决于问题的性质、可用的数据和问题的复杂程度。
-
-
相互影响:
-
在某些情况下,专家知识可以与机器学习相结合,用于指导模型的构建、特征选择或者结果解释。
-
机器学习模型的预测结果也可以被用来验证或者辅助专家模型的决策。
-
综上所述,专家模型和机器学习模型在建模方法、训练方式、可解释性和应用范围等方面存在明显的区别,但在某些情况下它们也可以相互影响和结合使用。
14. 全局性和系统性的区别?
"全局性"和"系统性"是两个不同但相关的概念,它们在描述问题或者解决方案时具有不同的侧重点。
-
全局性:
-
全局性指的是关注范围广泛,考虑整体的、综合的情况或者影响。
-
在问题分析或解决方案设计中,全局性意味着考虑到所有相关的因素、变量或者影响因素,并在整体上进行评估和处理。
-
全局性的思维更侧重于从整体角度看待问题,而不是局限于特定的部分或细节。
-
-
系统性:
-
系统性指的是以系统为单位,关注各个组成部分之间的相互作用、关联和影响。
-
在问题分析或解决方案设计中,系统性意味着将问题或者方案视为一个整体系统,考虑到其中各个部分之间的相互关系和互动。
-
系统性的思维更侧重于理解系统的结构、功能和相互作用,以便更好地理解和解决问题。
-
区别:
-
全局性关注的是问题或方案的整体范围和综合情况,而系统性关注的是问题或方案的内部结构和组成部分之间的关系。
-
全局性思维更强调从整体角度来看待问题,而系统性思维更强调对系统内部结构和功能的理解。
-
全局性和系统性思维通常是相辅相成的,一个有效的解决方案往往需要同时考虑到全局性和系统性的因素。
相关文章:

机器学习_集成学习_梯度提升_回归_决策树_XGBoost相关概念
目录 1. 机器学习 使用监督吗?什么又是监督学习? 2. 与XGBoost 类似的机器学习方法有哪些? 3. 随机森林方法 和 梯度提升方法 有什么区别? 分别应用于什么场景? 4. 决策树回归方法 和 Gradient Boosting类回归方法…...
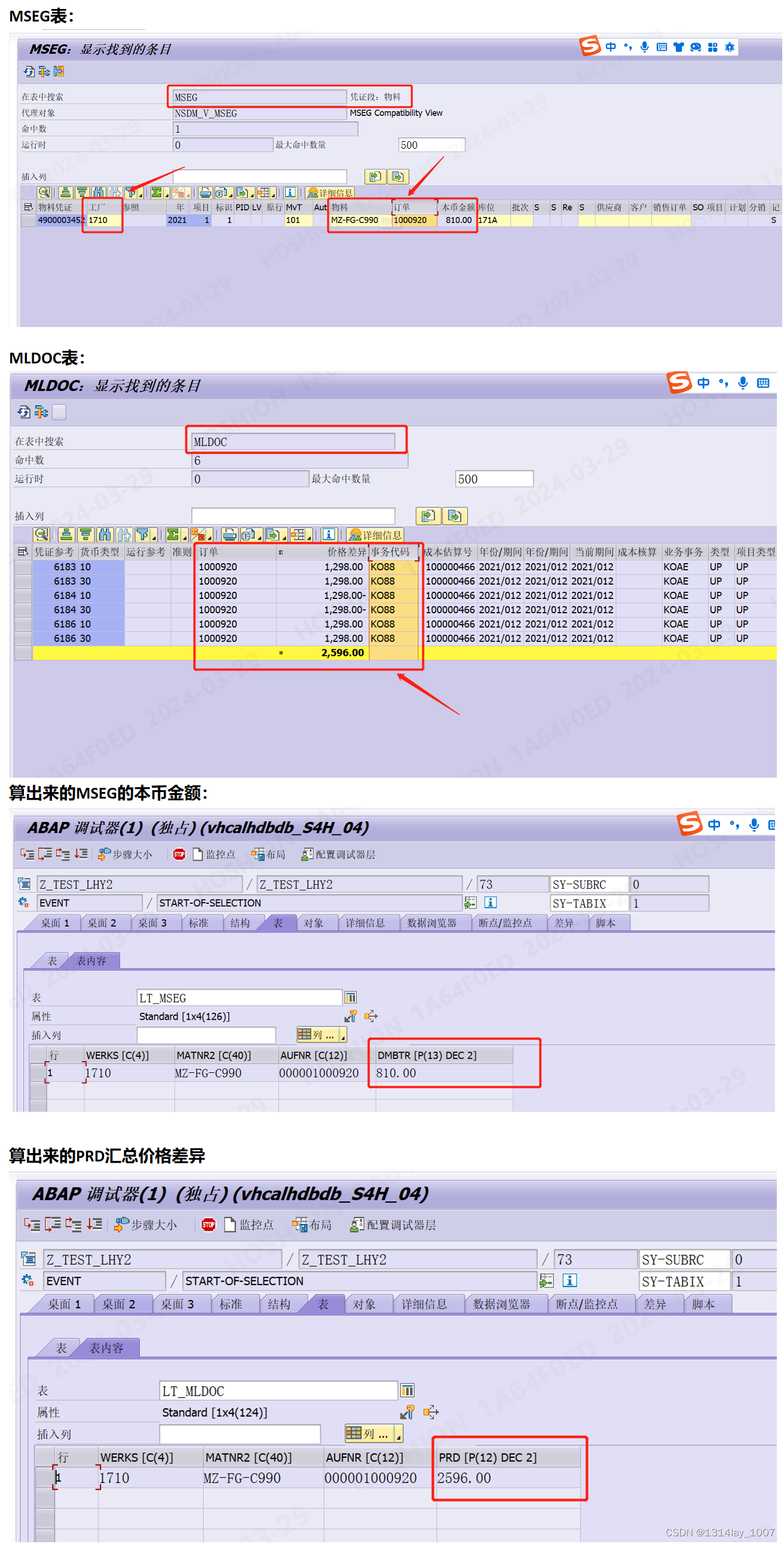
ABAP 字段类型不一样导致相加之后金额错误
文章目录 ABAP 字段类型不一样导致相加之后金额错误写在前面的总结示例程序1汇总MSEG表和MLDOC表 ABAP 字段类型不一样导致相加之后金额错误 写在前面的总结 如果需要不同底表的字段相加的值,那么最好是根据条件去分别算出那些值放在临时内表里面,再去…...

【L1距离和L2距离】Manhattan Distance Euclidean Distance 解释和计算公式
距离度量 特征空间中两个实例点的距离可以反映出两个实力点之间的相似性程度,使用的距离可以是欧式距离,也可以是其他距离。 欧氏距离(L2距离):最常见的两点之间或多点之间的距离表示法,又称之为欧几里得度量,它定义于…...
自动发卡平台源码优化版,支持个人免签支付
源码下载地址:自动发卡平台源码优化版.zip 环境要求: php 8.0 v1.2.6◂ 1.修复店铺共享连接时异常问题 2024-03-13 23:54:20 v1.2.5 1.[新增]用户界面硬币增款扣款操作 2.[新增]前台对接库存信息显示 3.[新增]文件缓存工具类[FileCache] 4.[新增]库存同…...

如何使用固定公网地址远程连接Python编译器并将运行结果返回到Pycharm
文章目录 一、前期准备1. 检查IDE版本是否支持2. 服务器需要开通SSH服务 二、Pycharm本地链接服务器测试1. 配置服务器python解释器 三、使用内网穿透实现异地链接服务器开发1. 服务器安装Cpolar2. 创建远程连接公网地址 四、使用固定TCP地址远程开发 本文主要介绍如何使用Pych…...
Java设计模式—备忘录模式(快照模式)
定义 备忘录模式提供了一种状态恢复的实现机制,使得用户可以方便地回到一个特定的历史步骤,当新的状态无效或者存在问题时,可以使用暂时存储起来的备忘录将状态复原,很多软件都提供了撤销(Undo)操作&#…...
没学数模电可以玩单片机吗?
我们首先来看一下数电模电在单片机中的应用。数电知识在单片机中主要解决各种数字信号的处理、运算,如数制转换、数据运算等。模电知识在单片机中主要解决各种模拟信号的处理问题,如采集光照强度、声音的分贝、温度等模拟信号。而数电、模电的相互转换就…...

FlinkSQL之Flink SQL Join二三事
Flink SQL支持对动态表进行复杂而灵活的连接操作。 为了处理不同的场景,需要多种查询语义,因此有几种不同类型的 Join。默认情况下,joins 的顺序是没有优化的。表的 join 顺序是在 FROM 从句指定的。可以通过把更新频率最低的表放在第一个…...

某某消消乐增加步数漏洞分析
一、漏洞简介 1) 漏洞所属游戏名及基本介绍:某某消消乐,三消游戏,类似爱消除。 2) 漏洞对应游戏版本及平台:某某消消乐Android 1.22.22。 3) 漏洞功能:增加游戏步数。 4…...
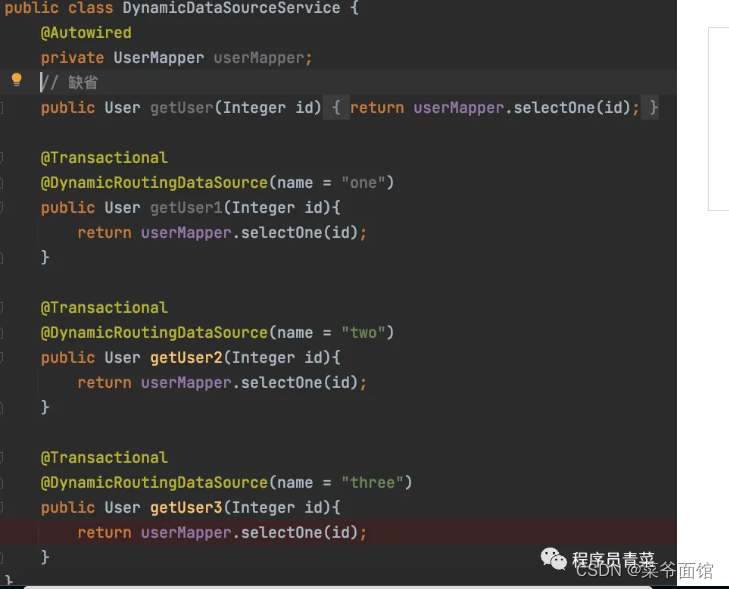
SpringBoot动态数据源实现
一、背景 一个应用难免需要连接多个数据库,像我们系统起码连接了5个以上数据库,AWS RDS主库,ECS自搭MySQL从库,工厂系统三个SQLServer数据库,在线网站MySQL数据库,记得很早以前是用SessionFactory配置&…...

计算机网络常见题(持续更新中~)
1 描述一下HTTP和HTTPS的区别 2 Cookie和Session有什么区别 3 如果没有Cookie,Session还能进行身份验证吗? 4 BOI,NIO,AIO分别是什么 5 Netty的线程模型是怎么样的 6 Netty是什么?和Tomcat有什么区别,特点是什么? 7 TCP的三次…...

富格林:可信招数揭发防备暗箱陷阱
富格林悉知,在风云变幻的金融市场中,炒贵金属是一项具有高收益潜力的投资方式。但投资是风险与收益共存的,因此我们在做单投资过程中需总结可信招数揭发暗箱陷阱,防备受害亏损。以下总结几点可信的投资技巧,希望能够帮…...
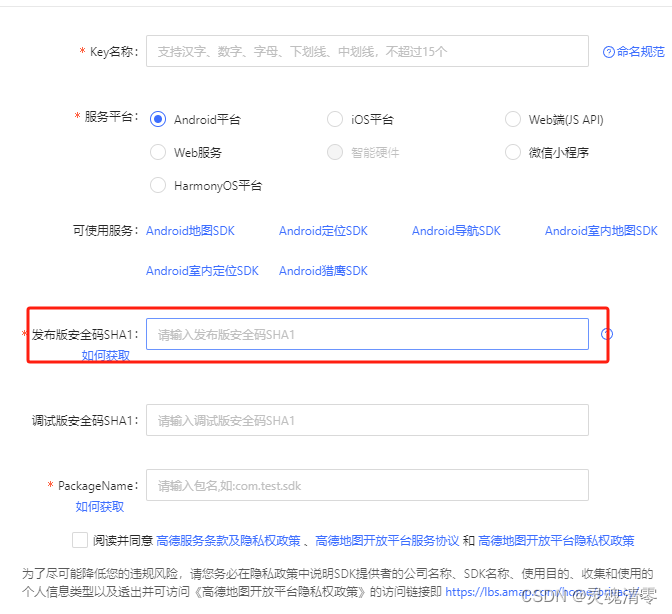
获取高德安全码SHA1
高德开发者平台上给的三种方法 获取安全码SHA1,这里我自己使用的是第三种方法。 1、通过Eclipse编译器获取SHA1 使用 adt 22 以上版本,可以在 eclipse 中直接查看。 Windows:依次在 eclipse 中打开 Window -> Preferances -> Androi…...
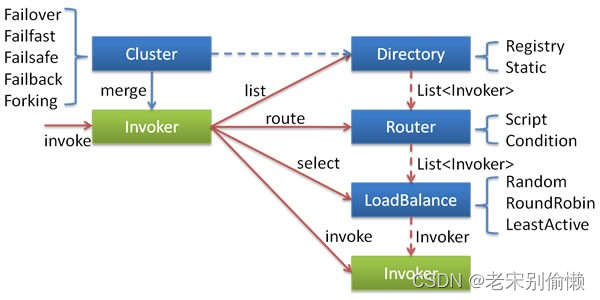
关于RPC
初识RPC RPC VS REST HTTP Dubbo Dubbo 特性: 基于接口动态代理的远程方法调用 Dubbo对开发者屏蔽了底层的调用细节,在实际代码中调用远程服务就像调用一个本地接口类一样方便。这个功能和Fegin很类似,但是Dubbo用起来比Fegin还要简单很多&a…...

pulsar: kafka on pulsar之把pulsar当kafka用
一、下载协议包(要和pulsar版本比较一致) https://github.com/streamnative/kop/releases?q2.8.0&expandedtrue二、在pulsar的根目录创建一个protocols目录,将上述包放到这个目录里 三、编辑broker.conf(如果是集群)或者standalone.con…...

七月论文审稿GPT第4版:通过paper-review数据集微调Mixtral-8x7b
模型训练 Mixtral-8x7b地址:魔搭社区 GitHub: hiyouga/LLaMA-Factory: Unify Efficient Fine-tuning of 100 LLMs (github.com) 环境配置 git clone https://github.com/hiyouga/LLaMA-Factory.git conda create -n llama_factory python3.10 conda activate lla…...
基于 YOLO V8 Fine-Tuning 训练自定义的目标检测模型
一、YOLO V8 YOLO V8 是由 2023 年 ultralytics 公司开源的发布,是结合了前几代 YOLO 的融合改进版。YOLO V8 支持全方位的视觉 AI 任务,包括检测、分割、姿态估计、跟踪和分类。并且在速度和准确性方面具有无与伦比的性能。能够应用在各种对速度和精度…...

快手,得物,蓝月亮,蓝禾,奇安信,三七互娱,顺丰,康冠科技,金证科技24春招内推
快手,得物,蓝月亮,蓝禾,奇安信,三七互娱,顺丰,康冠科技,金证科技24春招内推 ①得物 【岗位】技术,设计,供应链,风控,产品,…...
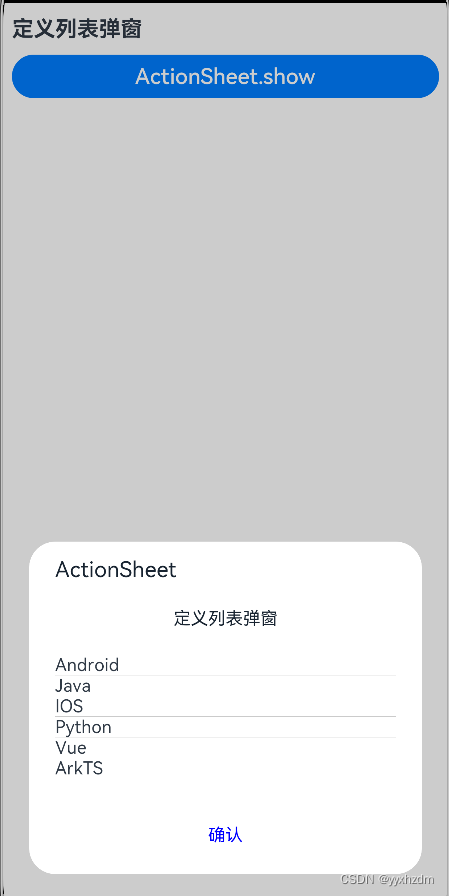
全局UI方法-弹窗二-列表选择弹窗(ActionSheet)
1、描述 定义列表弹窗 2、接口 ActionSheet.show(value:{ title: string | Resource, message: string | Resource, autoCancel?: boolean, confrim?: {value: string | Resource, action: () > void }, cancel?: () > void, alignment?: DialogAlignment, …...
Memcached分布式内存对象数据库
一 Memcached 概念 Memcached 是一个高性能的分布式内存对象缓存系统,用于动态 Web 应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。 二 在架构中的位置 Memcached 处于前端或中间件后…...

PaDiM实战:从理论到代码的异常检测全流程拆解
1. PaDiM异常检测模型入门指南 第一次接触PaDiM时,我也被那些数学公式吓到了。但真正用起来才发现,这个基于预训练CNN的异常检测框架其实很友好。简单来说,它就像个"找不同"的高手 - 先记住正常样本长什么样(训练阶段&a…...

Relic项目:用纯文本文件为AI工具打造可移植的持久记忆系统
1. 项目概述:为你的AI伙伴打造一个持久、可移植的“灵魂芯片”如果你和我一样,深度依赖各种AI工具来辅助工作、学习和创作,那你一定遇到过这个令人头疼的问题:每次切换工具,都像是在和一个“失忆”的新朋友重新建立关系…...

【RT-DETR实战】030、注意力机制改进:引入SimAM,EMA等无参注意力
从一次深夜调试说起 上周三凌晨两点,我在部署RT-DETR到边缘设备时遇到了性能瓶颈。模型在Jetson Orin上跑起来比预期慢了23%,显存占用也超出了预算。 用perf工具分析发现,注意力模块的计算开销占了近40%——这让我不得不重新审视那些“标配”的注意力机制。 我们习惯性地…...

LINE Messaging API集成实战:基于Node.js开源库的即时通讯解决方案
1. 项目概述:一个被低估的即时通讯集成利器 如果你正在开发一个需要集成即时通讯功能的应用,比如一个电商后台需要向管理员推送订单提醒,或者一个内部系统需要将告警信息发送到团队聊天群,你可能会第一时间想到微信、钉钉或者Tel…...

OpenCrow:自托管多智能体AI平台的架构解析与实战部署指南
1. 项目概述:一个能自我进化的多智能体AI平台如果你和我一样,对AI智能体的潜力感到兴奋,但又对市面上那些要么功能单一、要么部署复杂的平台感到头疼,那么OpenCrow的出现,可能就是我们一直在等的那个“瑞士军刀”。这不…...

别再傻傻分不清!一张图看懂PMOS、NMOS、CMOS在电路设计中的关键区别与选型
电子工程师必读:PMOS、NMOS与CMOS的实战选型指南 在电路设计的世界里,MOS管就像乐高积木中的基础模块,而PMOS、NMOS和CMOS则是三种最常用的"积木类型"。许多初学者在面对原理图上那些看似相似的符号时,常常感到困惑&…...

OneDark.nvim测试与质量保证:自动化测试套件与持续集成
OneDark.nvim测试与质量保证:自动化测试套件与持续集成 【免费下载链接】onedark.nvim One dark and light colorscheme for neovim > 0.5.0 written in lua based on Atoms One Dark and Light theme. Additionally, it comes with 5 color variant styles 项…...

Grav CMS 组合拳漏洞| CVE-2026-42613CVE-2026-42607复现研究
0x0 背景介绍 Grav是一个基于文件的Web平台。 在2.0.0-beta.2之前版本中,存在两个高危漏洞可导致组合利用权限提升漏洞->CVE-2026-42613 Grav的Login插件在处理用户注册请求时,未对请求数据中的groups/access字段进行服务端校验。当管理员在插件配置中…...

基于Next.js urborepo的企业级电商全栈架构实战解析
1. 项目概述与核心价值最近在梳理企业级电商项目的技术选型与架构方案,发现了一个非常值得深入研究的开源项目——Blazity/enterprise-commerce。这不仅仅是一个简单的电商模板,而是一个基于Next.js 14、TypeScript和Turborepo构建的现代化、全栈式企业级…...
常见问题)
使用S32 Design Studio(S32DS)常见问题
S32DS常见问题如下:1. 编译器找不到ld文件工程路径不能有中文字符2. 编译器找不到make文件鼠标右键点击工程,在弹出菜单中点击 “Properties” 按钮,弹出属性对话框,点击 Tool Settings 选项卡,在左侧树状框中点击 C/C…...