ElasticSearch 基础(五)之 映射
目录
- 前言
- 一、映射(Mapping)简介
- 二、动态映射(Dynamic mapping)
- 1、动态字段映射
- 1.1、日期检测
- 1.1.1、禁用日期检测
- 1.1.2、自定义检测到的日期格式
- 1.2、数值检测
- 2、动态模板
- 三、显示映射(Explicit mapping)
- 1、使用显式映射创建索引
- 2、添加新字段到现有映射
- 3、更新字段的映射
- 4、查看特定字段的映射
- 四、运行时字段(Runtime fields)
- 五、映射类型(Field data types)
- 六、元数据字段(Metadata fields)
- 七、映射参数(Mapping parameters)
- 八、映射限制设置(Mapping limit settings)
前言
本文主要内容转载于:ES Doc - mapping。
一、映射(Mapping)简介
映射(Mapping) 是定义文档及其包含的字段如何存储和索引的过程。
每个文档都是字段的集合,每个字段都有自己的数据类型。映射数据时,创建映射定义,其中包含与文档相关的字段列表,决定字段使用什么分词器解析,是否有子字段等。映射定义还包括元数据字段,如_source 字段,用于自定义如何处理文档的关联元数据。
| Elasticsearch 8.x | MySQL |
|---|---|
| Index(索引) | Table(数据表) |
| Dcoument(文档) | Row(行) |
| Fields(字段) | Column(列) |
在 ES 7.0.0之前,映射定义包含一个类型名。ES 7.0.0及更高版本不再接受默认映射。请参见 删除映射类型。
ES 使用 动态映射 和 显式映射 来定义数据。
动态映射(Dynamic mapping):可以根据写入文档的内容,来推断字段和数据类型,创建索引结构。显式映射(Explicit mapping):不希望使用默认值的字段,或获得对创建字段的更大控制,可以允许 ES 动态添加修改其他字段。
查看索引的映射:可以使用 获取映射 API 查看 现有索引。
语法:
GET /<index>/_mapping
测试:
//请求:
GET /test2/_mapping
//返回:
{"test2": {"mappings": {"properties": {"age": {"type": "long"},"email": {"type": "text"},"name": {"type": "keyword"}}}}
}
二、动态映射(Dynamic mapping)
自动检测和添加新字段称为 动态映射。可以自定义动态映射规则以适合您的情况 目的:
- 动态字段映射:管理动态字段检测的规则。
- 动态模板:用于配置动态添加字段映射的自定义规则。
1、动态字段映射
当 ES 检测到文档中的新字段时,默认情况下会将该字段动态添加到类型映射中。dynamic 参数控制此行为,通过将参数 dynamic 设置为 true 或 runtime,您可以明确指示 ES 根据传入的文档动态创建字段。
| dynamic 参数 | 意义 |
|---|---|
| true | 新字段被添加到映射中(默认)。 |
| runtime | 新字段作为运行时字段添加到映射中。这些字段未编入索引,而是查询时加载在 _source 中。 |
| false | 新字段被忽略。这些字段将不会被索引或搜索,但仍会出现在 _source 返回的匹配字段中。这些字段不会添加到映射中,必须显式添加新字段。 |
| strict | 如果检测到新字段,则会引发异常并拒绝文档。必须将新字段显式添加到映射中。 |
启用动态字段映射后,ES 使用下表中的规则来确定如何映射每个字段的数据类型,下表中的字段数据类型是 ES 动态检测的唯一字段数据类型,所有其他数据类型必须显式映射。
| JSON data type | “dynamic”:“true” | “dynamic”:“runtime” |
|---|---|---|
| null | 不添加字段映射 | 不添加字段映射 |
| true or false | boolean | boolean |
| double | float | double |
| long | long | long |
| object | object | No field added |
| array | 取决于数组中的第一个非值null | 取决于数组中的第一个非值null |
| 通过日期检测的字符串 | date | date |
| 通过数值检测的字符串 | float or long | double or long |
| 未通过日期检测或数值检测的字符串 | text with a .keyword sub-field | keyword |
1.1、日期检测
如果启用日期检测 date_detection(默认),则选中新字符串字段以查看其内容是否与 dynamic_date_formats 中指定的任何日期模式匹配。如果找到匹配项,则新的日期字段为 添加了相应的格式。
dynamic_date_formats 默认值为:
[ “strict_date_optional_time”,"yyyy/MM/dd HH:mm:ss Z||yyyy/MM/dd Z"]
strict_date_optional_time 是 date_optional_time 的严格级别,这个严格指的是年份、月份、天必须分别以4位、2位、2位表示,不足两位的话第一位需用0补齐。
1.1.1、禁用日期检测
可以通过设置为:date_detection:false。
PUT <index>
{"mappings": {"date_detection": false}
}
开始测试:
DELETE test2 # 删除之前的测试索引
PUT test2 # 禁用日期检测
{"mappings": {"date_detection": false}
}
PUT /test2/_doc/1 # 索引文档{"time": "2020/10/01"
}//请求:
GET /test2/_mapping # 查看映射,time 类型变为 text 了
//返回
{"test2": {"mappings": {"date_detection": false,"properties": {"time": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}}}
}
1.1.2、自定义检测到的日期格式
或者,你可以设置 dynamic_date_formats 定制想要的 自己的日期格式:
PUT <index>
{"mappings": {"dynamic_date_formats": ["MM/dd/yyyy"]}
}
测试:
// 准备:
DELETE test2
PUT test2
{"mappings": {"dynamic_date_formats": ["yyyy-MM-dd"]}
}
PUT /test2/_doc/1
{"time": "2020-10-01"
}// 查看映射:
GET /test2/_mapping
{"test2": {"mappings": {"dynamic_date_formats": ["yyyy-MM-dd"],"properties": {"time": {"type": "date","format": "yyyy-MM-dd"}}}}
}
1.2、数值检测
虽然 JSON 支持本机浮点和整数数据类型,但一些 应用程序或语言有时可能会将数字呈现为字符串。通常 正确的解决方案是显式映射这些字段,但 数字检测默认情况下禁用,想要启用使用以下操作:
PUT <index>
{"mappings": {"numeric_detection": true}
}
测试:
// 准备
DELETE test2
PUT test2
{"mappings": {"numeric_detection": true}
}
PUT /test2/_doc/1
{"test_int": "100","test_float": "100.01"
}// 查看映射类型
GET /test2/_mapping
{"test2": {"mappings": {"numeric_detection": true,"properties": {"test_float": {"type": "float" # test_float 自动映射为 float 类型},"test_int": {"type": "long" # test_int 自动映射为 long 类型}}}}
}
2、动态模板
动态模板(Dynamic templates) 允许您更好地控制 ES 如何将数据映射到默认的动态字段映射规则之外,通过将参数 dynamic 设置为 true 或 runtime,可以启用动态映射。然后,您可以使用动态模板定义自定义映射,这些映射可以根据匹配条件应用于动态添加的字段。
注意:只有当字段包含具体值时,才会添加动态字段映射。当字段包含null或空数组时,ES 不会添加动态字段映射。如果在 dynamic_template 中使用了 null_value 选项,则只有在为字段指定了具体值的第一个文档编制索引后,才会应用该选项。
详细内容参考:动态模板示例。
三、显示映射(Explicit mapping)
您对自己的数据了解比 ES 所能猜到的还要多,因此,虽然 动态映射(Dynamic mapping) 对入门很有用,但在某些时候,您可能需要指定自己的 显式映射(Explicit mapping)。
创建索引并将字段添加到现有索引时,可以创建字段映射。
1、使用显式映射创建索引
您可以使用创建索引API创建具有显式映射的新索引。
当我们创建一份数据查看它的动态映射:
// 1、创建测试文档
POST /test2/_doc/1
{"name":"王五","age":1,"email": "11111@qq.com"
}// 2、查看动态映射
GET /test2/_mapping
{"test2": {"mappings": {"properties": {"age": {"type": "long"},"email": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"name": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}}}
}
动态映射结果:
age:默认long类型;但是我们并不需要这么大的长度,目前人类最大年龄是134岁,所以设置short就够了;name:默认text + keyword;这里的名称只要求 keyword 类型,不分词;email:默认text + keyword;邮箱强制只要求 text 类型,只分词;
text :会分词,先把对象进行分词处理,然后再再存入到es中。
keyword:不分词,没有把对象进行分词处理,而是存入了整个对象,这时候等值查询才能查到。
当我们新建一个索引时,我们可以先索引一个文档,去查看映射,复制下来再修改成我们想要的效果。
# 设置新索引映射:
//请求:
PUT /test2
{"mappings": {"properties": {"age": {"type": "long"},"email": {"type": "text"},"name": {"type": "keyword"}}}
}
//返回:
{"acknowledged": true,"shards_acknowledged": true,"index": "test2"
}# 查看映射
//请求:
GET /test2/_mapping
//返回:
{"test2": {"mappings": {"properties": {"age": {"type": "long"},"email": {"type": "text"},"name": {"type": "keyword"}}}}
}
2、添加新字段到现有映射
可以使用 更新映射 API 添加一个或多个新的字段到现有索引。
测试:为新字段 addres 添加映射。
//请求:
PUT /test2/_mapping
{"properties": {"address": {"type": "keyword"}}
}
//返回:
{"acknowledged": true
}//请求:
GET /test2/_mapping
//返回:
{"test2": {"mappings": {"properties": {"address": {"type": "keyword"},"age": {"type": "long"},"email": {"type": "text"},"name": {"type": "keyword"}}}}
}
3、更新字段的映射
除了支持的 映射参数 外,您不能更改现有字段的映射或字段类型。更改现有字段可能会使已编入索引的数据失效。 如果需要更改数据流备份索引中字段的映射,请参阅 更改数据流的映射和设置。
如果需要更改其他索引中字段的映射,请使用正确的映射创建一个新索引,然后将数据 reindex 到该索引中。
重命名字段将使已在旧字段名称下索引的数据无效。相反,添加 alias 字段以创建备用字段名。
4、查看特定字段的映射
如果只想查看一个或多个特定字段的映射,则可以使用 获取字段映射 API。如果您不需要索引的完整映射,或者索引包含大量字段,这将非常有用。
语法:
GET /<index>/_mapping/field/<field>
测试:
//请求:
GET /test2/_mapping/field/email
//返回:
{"test2": {"mappings": {"email": {"full_name": "email","mapping": {"email": {"type": "text"}}}}}
}
四、运行时字段(Runtime fields)
我们知道, 从历史上看,ES 依靠 写时模式(Schema on write) 的模式来快速搜索数据。如果一个索引,在一开始是没有定义映射的,那么当我们写入第一个数据时,ES 会根据自己的猜测来给写入的文档的字段定义类型。现在,我们向 ES 添加了 Schema on read 模式,以便用户可以灵活地在读取后更改文档的 schema,还可以生成仅作为搜索查询一部分存在的字段。这个字段只存在于 read 的时候,也就是在查询的时候。Schema on read 和 Schema on write 一起为用户提供了选择,可以根据他们的需求来平衡性能和灵活性。
写时模式(Schema on write):在写入文档的同时,如果该字段从来没有被创建过,ES 会自动帮我们生产相应的字段 content。
读时模式(Schema on read): 当对数据运行查询时,可以即时创建其他字段。 你不需要提前对数据有深入的了解,也不必预测数据最终可能被查询的所有可能方式。 你可以随时更改数据结构,即使在文档已被索引之后 —— 读时模式的巨大好处。
Runtime fields 的使用,让 Schema on read 模式成为可能。
如果我们想根据日志总结我们的服务投放了多少广告,我们需要先提取这些日志消息相关信息以便进行聚合。
最简单的方法是使用运行时字段(runtime fields)。 此功能允许你在文档中定义其他字段,即使它们不存在于你发送到 Elasticsearch 的原始值中。
Runtime field 也被称为运行时字段。运行时字段是在查询时评估的字段。 运行时字段使你能够:
- 在不重新索引数据的情况下向现有文档添加字段;
- 在不了解数据结构的情况下开始处理数据;
- 在查询时覆盖从索引字段返回的值;
- 为特定用途定义字段而不修改底层 mapping;
运行时字段的好处: 因为运行时字段没有索引,所以添加运行时字段不会增加索引大小。 你直接在索引映射中定义运行时字段,从而节省存储成本并提高摄取速度。 当你定义一个运行时字段时,你可以立即在搜索请求、聚合、过滤和排序中使用它,而无需额外重新索引你的数据。
运行时字段的缺点: 每次你对运行时字段运行搜索时,Elasticsearch 都必须再次评估该字段的值,因为它不是你文档中被索引的真实字段。 如果此字段是你打算在将来经常查询的字段,那么你应该考虑将其提取为摄取管道的一部分。
更多参考:
ES Doc - runtime
Elasticsearch:Runtime fields 及其应用(一)
Elasticsearch:Runtime fields 及其应用(二)
五、映射类型(Field data types)
下一篇文章会讲映射类型及相关测试。
六、元数据字段(Metadata fields)
更新详细内容可参考:
Elasticsearch:Metadata fields - 元数据字段介绍
Elastic Docs › Elasticsearch Guide [8.6] › Mapping › Metadata fields
_id:文档的 ID。_index:文档所属的索引。
文档源元数据字段_source:表示文档正文的原始 JSON。_size:_source 字段的大小(以字节为单位),由 mapper-size 插件提供。_doc_count:当文档表示预聚合(pre-aggregation)数据时,用于存储文档计数的自定义字段。_field_names:档中包含非空值的所有字段。_ignored:由于 ignore_malformed 而在索引时被忽略的文档中的所有字段。_routing: 将文档路由到特定分片的自定义路由值。_meta:应用程序特定的元数据,参考 Elasticsearch:添加 metadata 到 mapping 中。_tier:文档所属索引的当前数据层首选项。
| 分类 | 字段 |
|---|---|
| 身份元数据字段 | _id、_index |
| 文档源元数据字段 | _source、_size |
| 文档计数元数据字段 | _doc_count |
| 索引元数据字段 | _field_names、_ignored |
| 路由元数据字段 | _routing |
| 其它元数据字段 | _meta、_tier |
七、映射参数(Mapping parameters)
详细内容请参考:Elastic Docs › Elasticsearch Guide [8.6] › Mapping › Mapping parameters
以下映射参数是某些或所有字段数据类型的通用参数:
-
index:控制是否对字段值建立索引。接受 true 或 false 值,默认 true 值;未索引的字段不能通过检索查询到数据。 -
store:标记字段是否需要被 额外的 单独的 存储在和 index 不同的 fragment 中。接受 yes/no 和 true/false 值,默认为 no/false 值,即不单独存储。- 默认情况下,文档添加到索引后是不需要再单独储存的,因为 _source 默认已经存储了整个原始文档,而默认情况下,提取出来的字段值也是从 _source 中解析出来的。
- 字段开启独立存储时,需要占用额外的磁盘空间,独立的字段越多,索引就越大,但在单独获取一个被独立 store 的字段值时,要比从 _source 中解析要快。
- 提取数据时,每一个被 store 独立存储的字段,都需要一次单独的 IO 从对应的存储块中获取;而未被 store 标记的其他的字段,则只需要一次 IO 即可从 _source 中全部获取。
- 文档被添加到索引后可被查询检索,文档被指定到存储后可被返回显示,因而,常规情况下,需要返回原始值的字段至少保证 store 或 _source 中有存储。
-
analyzer:用于指定text文本字段在创建文档索引或查询检索文档时使用的文本分析器;仅支持text字段使用,除非被 search_analyzer 参数覆盖,否则将同时应用于索引和搜索。 -
search_analyzer:指定查询搜索文档时对查询条件使用的分析器。默认情况下,查询条件将使用被查询字段 analyzer 参数定义的索引分析器,但是可以通过此参数设置覆盖。 -
boost:在索引期间指定字段在查询时的相关性得分(不推荐);也可以直接在查询时指定。 -
format:自定义日期的解析格式。在JSON文档中,日期表示为字符串,在ES中预配置了一组格式来识别这些字符串并将其解析为一个long类型的毫秒数。 -
fields:为不同的目的以不同的方式对同一字段建立索引,这就是多字段的目的。多字段不会更改原始 _source 字段。 -
null_value:一个空的值不能被索引或搜索,参数用于将显式的空(null)值替换为指定的值。 -
meta:附加到字段的元数据。只对在相同索引上工作的多个应用程序有用,以共享关于字段(如单位)的元信息;可以通过提交映射更新进行更新。
八、映射限制设置(Mapping limit settings)
使用以下设置限制字段映射的数量(手动或动态创建),并防止文档导致映射爆炸:
-
index.mapping.total_fields.limit:索引中的最大字段数。字段和对象映射以及字段别名都属于此限制。映射的运行时字段也计算到此限制。默认值为1000。该限制已到位,以防止映射和搜索变得太大。较高的值可能会导致性能下降和内存问题,特别是在负载高或资源少的集群中。
如果增加此设置,我们建议您也增加 indices.query.bool.max_clause_count 设置,该设置限制查询中子句的最大数量。
如果字段映射包含一组大的任意键,请考虑使用 扁平数据类型。 -
index.mapping.depth.limit:字段的最大深度,以内部对象的数量度量。例如,如果所有字段都在根对象级别定义,则深度为1。如果有一个对象映射,则深度为2等。默认值为20。 -
index.mapping.nested_fields.limit:索引中不同嵌套映射的最大数量。嵌套类型只能在特殊情况下使用,当需要独立查询对象数组时。为了防止设计不良的映射,此设置限制了每个索引的唯一嵌套类型的数量。默认值为50。 -
index.mapping.nested_objects.limit:单个文档在所有嵌套类型中可以包含的最大嵌套JSON对象数。当文档包含太多嵌套对象时,此限制有助于防止内存不足错误。默认值为 10000。 -
index.mapping.field_name_length.limit:字段名称的最大长度设置。这个设置并不能解决映射爆炸的问题,但如果您想限制字段长度,它可能仍然有用。通常不需要设置此设置。默认值是可以的,除非用户开始添加大量具有真正长名称的字段。默认值为Long.MAX_VALUE(无限制)。 -
index.mapping.dimension_fields.limit:[预览]此功能处于技术预览中,可能会在将来的版本中更改或删除。Elastic将尽最大努力解决任何问题,但技术预览中的功能不受正式GA功能支持SLA的约束。(dynamic,integer)索引的最大 时间序列维度数。默认值为16。
相关文章:
之 映射)
ElasticSearch 基础(五)之 映射
目录前言一、映射(Mapping)简介二、动态映射(Dynamic mapping)1、动态字段映射1.1、日期检测1.1.1、禁用日期检测1.1.2、自定义检测到的日期格式1.2、数值检测2、动态模板三、显示映射(Explicit mapping)1、…...
【C语言督学训练营 第二天】C语言中的数据类型及标准输入输出
文章目录一、前言二、数据类型1.基本数据类型①.整形②.浮点型③.字符型2.高级数据类型3.数据分类①.常量②.变量三、标准输入输出1.scanf2.printf四、进制转换1.进制转换简介2.十进制转其他进制3.其他进制转换五、OJ网站的使用一、前言 王道2024考研408C语言督学营第二天&…...

重资产模式和物流网络将推动京东第四季度利润率增长
来源:猛兽财经 作者:猛兽财经 强劲的2022年第三季度财务业绩 2022年11月18日,京东(JD)公布了2022年第三季度财务业绩,净收入为2435亿元人民币,增长了11.4%。净服务收入为465亿元人民币…...
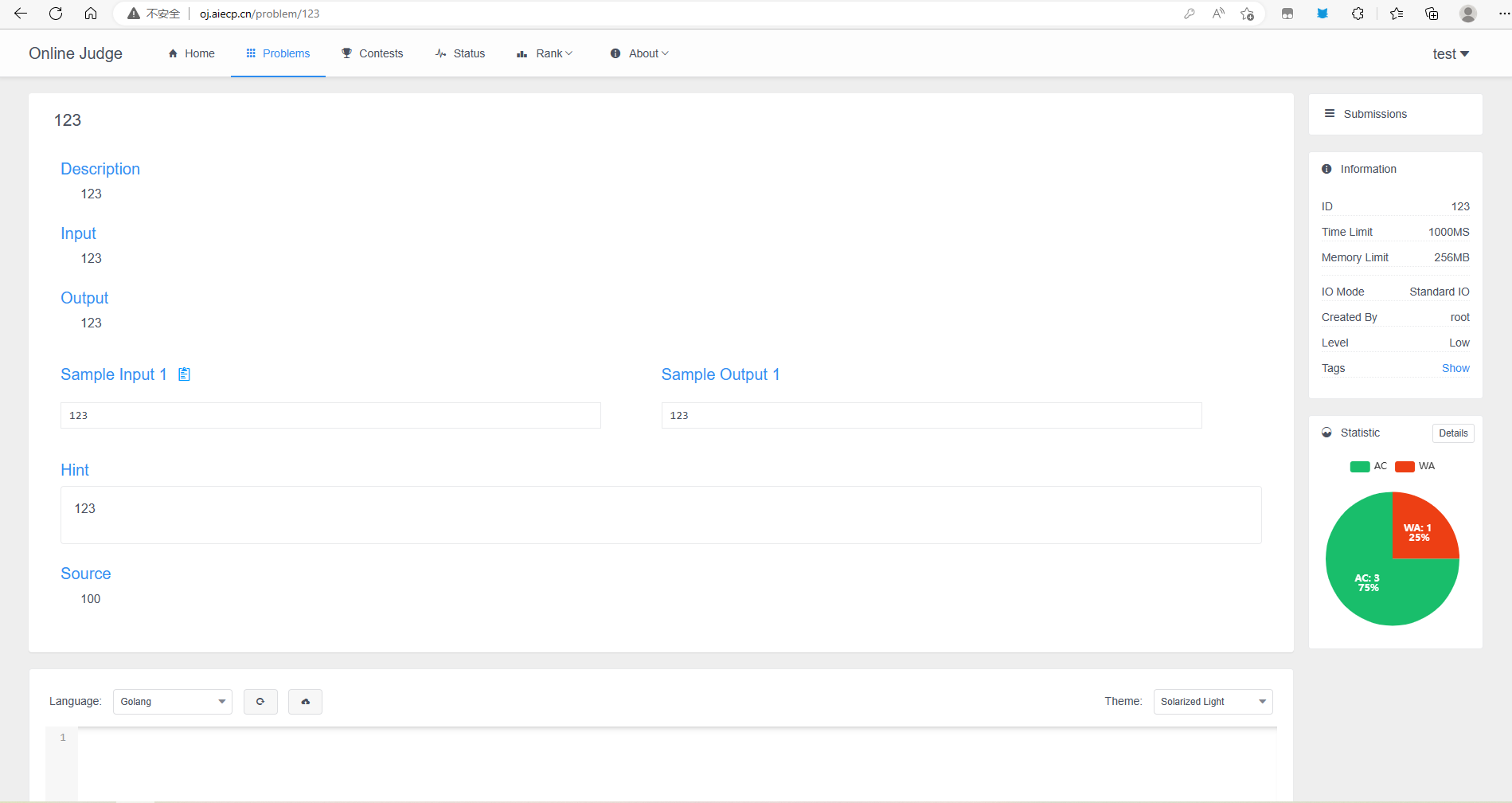
【新】EOS至MES的假捻报工数据导入-V2.0版本
假捻自动线的数据和MES没有进行对接,直接入库至EOS。 因此可信平台上缺少这部分的报工数据,需要把EOS的入库数据导出,整理成报工数据,导入到MES,然后通过定时任务集成到可信平台。 MES这边的报工数据整理,主要是添加订单明细ID,和完工单号。 订单明细ID(根据批次号和…...
python甜橙歌曲音乐网站平台源码
wx供重浩:创享日记 对话框发送:python音乐 获取完整源码源文件说明文档配置教程等 在虚拟环境下输入命令“python manage.py runserver”启动项目,启动成功后,访问“http://127.0.0.1:5000”进入甜橙音乐网首页,如图1所…...

docker imageID计算
Image ID是在本地由Docker根据镜像的描述文件计算的,并用于imagedb的目录名称 docker镜像id都保存在/var/lib/docker/image/overlay2/imagedb/content/sha256下面,都是一些以sha256sum计算文件内容得出的哈希值的文件。 #ls /var/lib/docker/image/ove…...
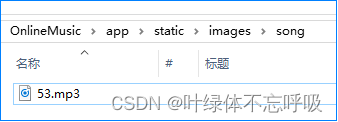
借助媛如意让ROS机器人turtlesim画出美丽的曲线-云课版本
首先安装并打开猿如意其次打开蓝桥云课ROS并加入课程在猿如意输入问题得到答案在蓝桥云课ROS验证如何通过turtlesim入门ROS机器人您可以通过以下步骤入门ROS机器人:安装ROS:您需要安装ROS,可以在ROS官网上找到安装指南。安装turtlesim&#x…...

小区业主入户安检小程序开发
小区业主入户安检小程序开发 可针对不同行业自定义安检项目,线下安检,线上留存(安检拍照/录像),提高安检人员安检效率 功能特性,为你介绍小区入户安检系统的功能特性。 小区管理;后台可添加需要安检的小区…...
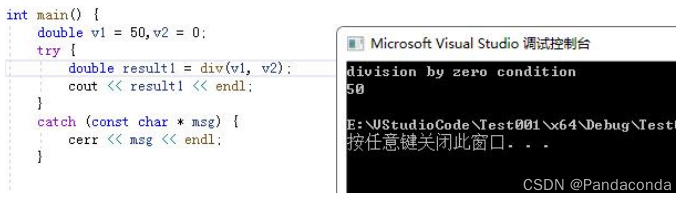
【C++知识点】异常处理
✍个人博客:https://blog.csdn.net/Newin2020?spm1011.2415.3001.5343 📚专栏地址:C/C知识点 📣专栏定位:整理一下 C 相关的知识点,供大家学习参考~ ❤️如果有收获的话,欢迎点赞👍…...

【FATE联邦学习debug】 No module named ‘federatedml‘
直接pip install federatedml是无法找得到这个库的。 这个的原因是环境变量的事情,因为在部署文档中,本身提示我们要更新一些环境变量,如果不export那些变量,下面的fate_test其实也是无法测试成功的。 打开bin/init_env.sh&#x…...
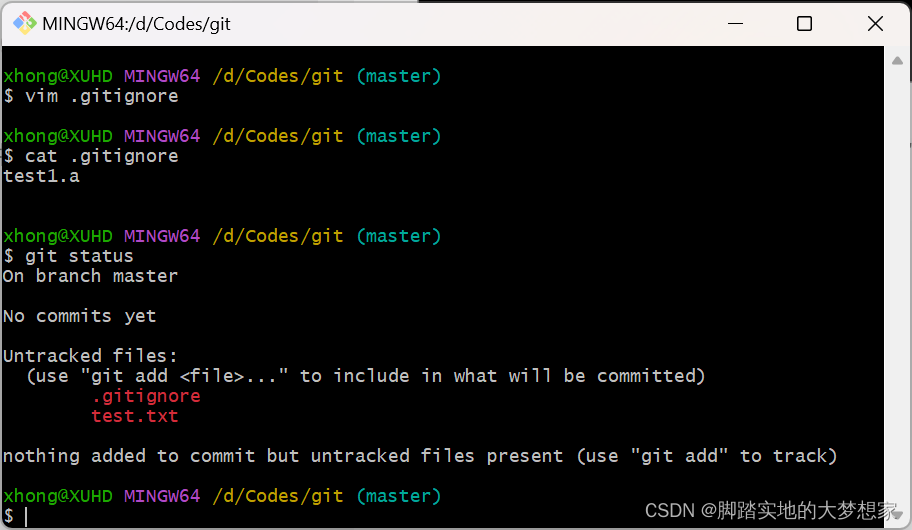
【Git】P1 Git 基础
Git 基础Git 基本概念集中式版本控制工具 与 分布式版本控制工具Git 下载与安装Bash 初始设置创建本地仓库Git 三区概念一个简单的提交流程更改文件后再次提交git 实现版本切换查看提交日志设置 git 快捷键版本切换(一)版本切换(二࿰…...

智能交通数据集Rope3D(仅限科研使用)
Rope3D Dataset 官网:https://thudair.baai.ac.cn/index !!!如想要使用Rope3D数据集进行2D检测,最后有我们处理完的数据集链接。 !!! 介绍: DAIR-V2X数据集是首个用于…...

Java虚拟机JVM-面试题
1、Java 虚拟机是如何捕获异常的? 答: 在编译生成的字节码中,每个方法都附带一个异常表。异常表中的每一个条目代表一个异常处理器,并且由 from 指针、to 指针、target 指针以及所捕获的异常类型构成。这些指针的值是字节码索引…...

详细的说说Redis的数据类型
Redis是一个开源的内存数据库,它可以用作缓存、消息代理、实时数据处理和许多其他用途。Redis是一个key-value存储系统,其中数据存储在内存中,并通过网络进行访问。与传统的关系型数据库不同,Redis支持多种数据结构,包…...

798.差分矩阵
输入一个 n行 m列的整数矩阵,再输入 q个操作,每个操作包含五个整数 x1,y1,x2,y2,c,其中 (x1,y1)和 (x2,y2) 表示一个子矩阵的左上角坐标和右下角坐标。每个操作都要将选中的子矩阵中的每个元素的值加上 c。 请你将进行完所有操作后的矩阵输出…...

InfluxDB 2 介绍与使用 flux查询 数据可视化
一、关键概念 相比V1 移除了database 和 RP,增加了bucket。 V2具有以下几个概念: timestamp、field key、field value、field set、tag key、tag value、tag set、measurement、series、point、bucket、bucket schema、organization 新增的概念&…...
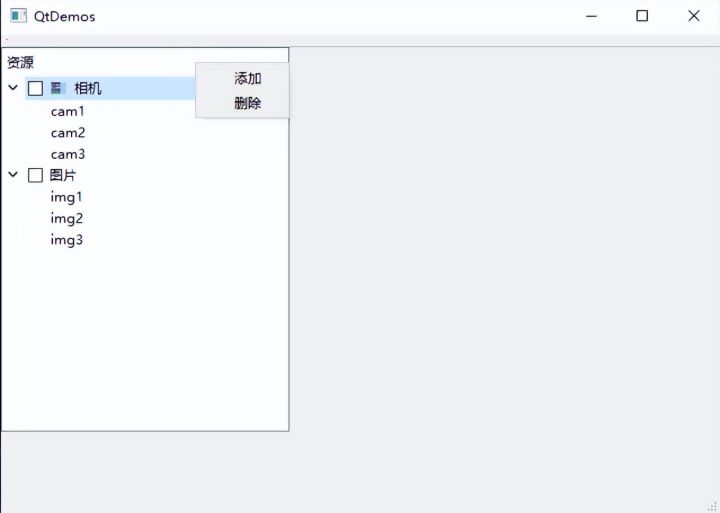
Qt QTreeView简单使用
QT-QTreeView使用方法 QTreeView: 用于显示树状结构数据,适用于树状结构数据的操作。 一、初始化 利用QStandardlternModel来初始化数据,标准的基于项数据的数据模型类, 每个项数据可以是任何数据类型。 // 初始化model QStandardItem…...
Wannacrypt蠕虫老树开花?又见Wannacrypt
Wannacrypt蠕虫是一个在2017年就出现的远古毒株,其利用永恒之蓝漏洞降维打击用户服务器,而后进行扩散勒索,曾经一度风靡全球,可谓是闻者伤心,听着落泪,因为这玩意解密是不可能 解密的。 而2023年的今天&am…...
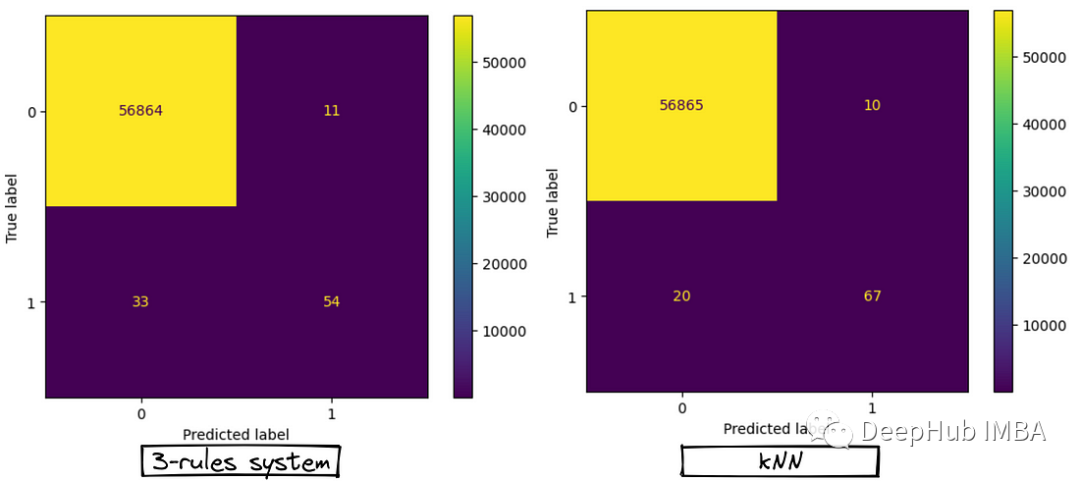
结合基于规则和机器学习的方法构建强大的混合系统
经过这些年的发展,我们都确信ML即使不能表现得更好,至少也可以在几乎所有地方与前ML时代的解决方案相匹配。比如说一些规则约束,我们都会想到能否把它们替换为基于树的ml模型。但是世界并不总是黑白分明的,虽然机器学习在解决问题…...
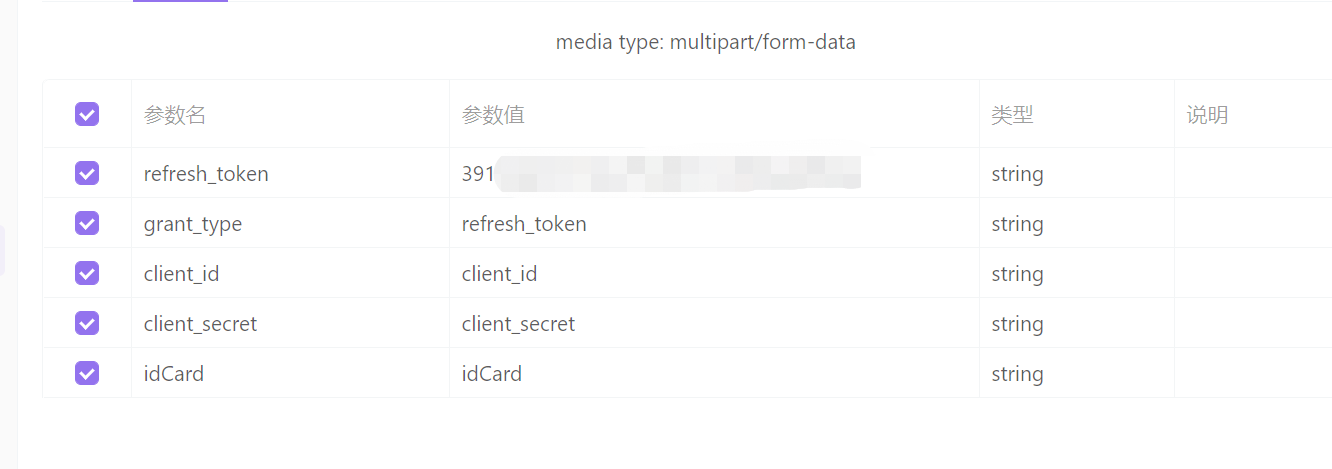
Spring Security OAuth2实现多用户类型认证、刷新Token
原本的OAuth2登录支持用户名密码登录,现在还想支持另外用id号码和密码登录。但是OAuth2默认提供的UserDetailsService只允许传入一个参数:想要实现多种用户登录,是不是可以考虑loadUserByUsername方法携带多个参数呢?接下来记录一…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...

ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题
ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...

Stitches API完全指南:从基础配置到自定义扩展
Stitches API完全指南:从基础配置到自定义扩展 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一款强大的HTML5 Sprite Sheet Generator,它提供了直观的API接口&…...

量子计算中Loschmidt回声相位测量的创新方法
1. 量子计算中的Loschmidt回声相位测量方法概述Loschmidt回声是量子动力学中一个重要的概念,它描述了量子系统在时间反演演化后与初始状态的相似程度。在量子计算领域,精确测量Loschmidt回声的相位信息对于理解量子系统的非平衡态行为、计算能量本征值以…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...