Python学习从0到1 day18 Python可视化基础综合案例 1.折线图
我默记这段路的酸楚,等来年春暖花开之时再赏心阅读
—— 24.3.24
python基础综合案例
数据可视化 — 折线图可视化
一、折线图案例
1.json数据格式
2.pyecharts模块介绍
3.pyecharts快速入门
4.数据处理
5.创建折线图
1.json数据格式
1.什么是json
2.掌握如何使用json进行数据转化
1.什么是json
JSON是一种轻量级的数据交互格式,可以按照JSON指定的格式去组织和封装数据
JSON本质上是一个带有特定格式的字符串
主要功能:json就是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互,类似:
国际通用语言——英语
中国各民族各地区的通用语言——普通话
2.掌握如何使用json进行数据转化
①json格式的数据格式要求:(字典)
{“name”:"admin","age":18}
②也可以是:(字典列表)
[{"name":"admin","age":18},{"name":"root","age":16},{"name":"张三","age":20}]
JSON可以看作是把一个字典或者一个字典列表全部转换成字符串
正常定义为字典或字典列表导入包和方法后就可以进行自动转换
3.演示
''' 演示JSON数据和Python字典的相互转换 ''' import json# 准备列表,列表内每一个元素都是字典,将其转换为JSON data1 = [{"name":"张三","age":22},{"name":"李四","age":13},{"name":"王五","age":16}] json_str1 = json.dumps(data1,ensure_ascii=False) # 如果不写中文,则不需要参数ensure_ascii print(json_str1) print(type(json_str1))# 准备字典,将字典转换为JSON data2 = {"name":"JayZhou","addr":"台北"} json_str2 = json.dumps(data2,ensure_ascii=False) print(json_str2) print(type(json_str2))# 将JSON字符串转换为Python数据类型字典列表[{k:v,k:v},{k:v,k:v},{k:v,k:v}] str = '[{"name": "张三", "age": 22}, {"name": "李四", "age": 13}, {"name": "王五", "age": 16}]' json_str3 = json.loads(str) print(json_str3) print(type(json_str3))# 将JSON字符串转换为Python数据类型列表{k:v,k:v} str2 = '{"name":"JayZhou","addr":"台北"}' json_str4 = json.loads(str2) print(json_str4) print(type(json_str4))# 通过dumps和loads两个json包下的方法就可以将python中的字典或列表转换为json字符串通过dumps和loads两个json包下的方法就可以将python中的字典或列表转换为json字符串
总结
1.json:是一种轻量级的数据交互格式,采用完全独立于编程语言的格式来存储和表示数据(就是字符串)
python语言有很大的优势是因为JSON可以直接和Python的字典或者字典列表进行无缝转换
2.json格式数据转化
通过json.dumps(data)可以把python中的数据转化为json字符串
data = json.dumps(data)
如果其中有中文可以带上:ensure_ascii=False参数来确保中文正常转换
通过json.loads(data)方法把json数据转化为python中的列表或字典
data = json.loads(data)
2.pyecharts模块介绍
如果想要做出数据可视化效果图,可以借助pyecharts模块来完成
概况:
Echarts是个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可,而Python是门富有表达力的语言,很适合用于数据处理,当数据分析遇上数据可视化时pyecharts诞生了
pyecharts模块安装
使用在前面学过的pip命令即可快速安装PyEcharts模块
pip install pyecharts
总结
1.开发可视化图表使用的技术栈是:
Echarts框架的Python版本:PyEcharts包
2.如何安装PyEcharts包:
pip install pyecharts
3.如何查看官方示例:
打开官方画廊:
https://gallery.pyecharts.org/#/README
3.pyecharts快速入门
1.构建一个基础的折线图
2.使用全局配置项设置属性
1.构建一个基础的折线图
基础折线图
①导包,导入Line功能构建折线图对象
from pyecharts.charts import Line
②得到折线图对象
line = Line()
③添加x轴数
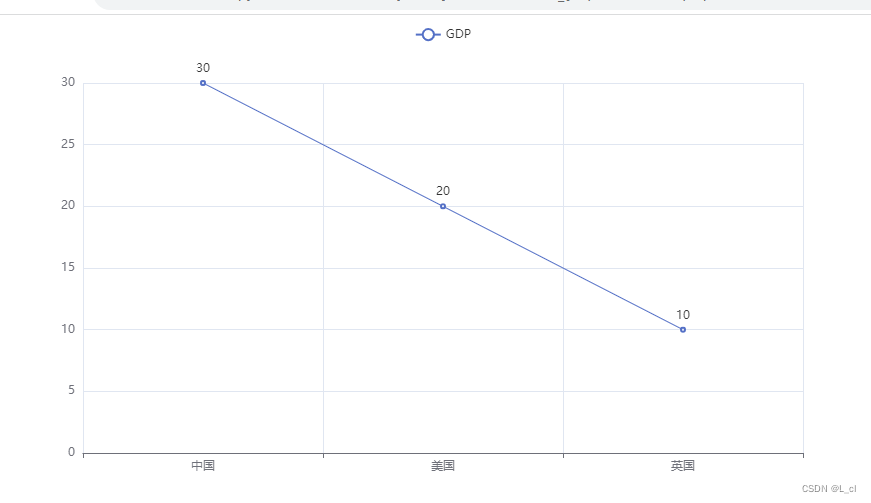
line.add_xaxis(["中国","美国","英国"])
⑤添加y轴数据
line.add_yaxis("GDP",[30,20,10])
⑥生成图表
line.render() # 生成图表后会在软件包内生成一个文件,运行这个文件就是生成的图表,可以运行文件也可以在文件右上角打开它
2.使用全局配置项设置属性
pyecharts有哪些配置选项
pyecharts模块中有很多的配置选项,常用到2个类别的选项
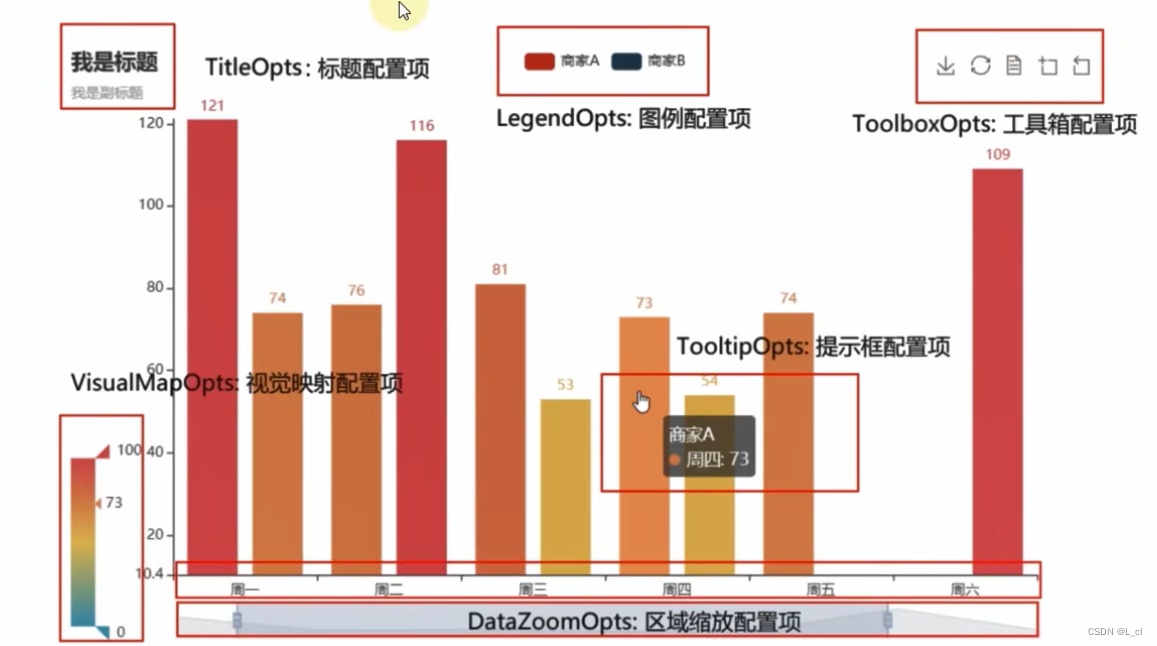
全局配置选项(表结构)
系列配置选项(数据)
全局配置选项 set_global_opts方法
这里全局配置选型可以通过set_global_opts方法来进行配置,相应的选项和选项的功能如下
3.示例
# ①导包,导入Line功能构建折线图对象 from pyecharts.charts import Line # 导包,导入控制标题的包 from pyecharts.options import TitleOpts,LegendOpts,ToolboxOpts,VisualMapOpts# 得到折线图对象,Line对象 line = Line()# ③给折线图对象添加x轴数 line.add_xaxis(["中国","美国","英国"])# ④给折线图对象添加y轴数据 line.add_yaxis("GDP",[30,20,10])# ⑤设置全局变量配置项set_global_opts来设置 line.set_global_opts(# ctrl+p 可以查看方法中传递的参数title_opts=TitleOpts(title = "GDP展示",pos_left="center",pos_bottom="1%"), # 控制标题及位置legend_opts=LegendOpts(is_show=True), # 是否显示图例(默认显示)toolbox_opts=ToolboxOpts(is_show=True), # 工具箱是否显示visualmap_opts=VisualMapOpts(is_show=True) # 视觉映射是否显示 )# ⑥通过render方法,将代码生成为图像 line.render()运行成功后,会自动在包里生成一个文件
总结
1.pyecharts模块中有很多的配置选项,常用到三个类别的选项:
全局配置选项
系列配置选项
2.全局配置项能做什么?
配置图表的标题
配置图例
配置鼠标移动效果
配置工具栏
等整体配置项
4.数据处理
1.能够通过json模块对数据进行处理
json可视化
根据json可视化掌握数据的层级关系
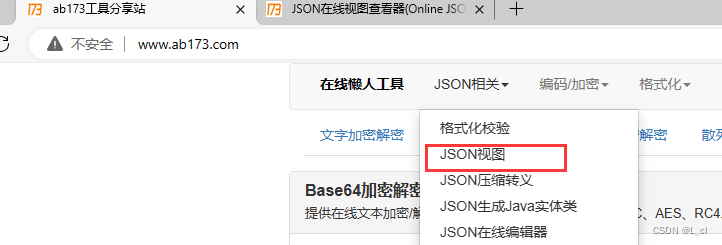
进入网站www.ab173.com
这是一个懒人软件,点击JSON相关、点击JSON视图
# 处理数据# 美国疫情数据
f_us = open("D:/2LFE/Desktop/Python/资料/可视化案例数据/折线图数据/美国.txt","r",encoding="utf-8")
us_data = f_us.read() # 美国的全部内容# 小日本疫情数据
f_jp = open("D:/2LFE/Desktop/Python/资料/可视化案例数据/折线图数据/日本.txt","r",encoding="utf-8")
jp_data = f_jp.read() # 日本的全部内容# 印度疫情数据
f_in = open("D:/2LFE/Desktop/Python/资料/可视化案例数据/折线图数据/日本.txt","r",encoding="utf-8")
in_data = f_in.read() # 印度的全部内容# 去掉不合JSON规范的开头,每个国家的数据不规范的内容不相同,需查看文档进行改变
us_data = us_data.replace("jsonp_1629344292311_69436(","")
jp_data = jp_data.replace("jsonp_1629350871167_29498(","")
in_data = in_data.replace("jsonp_1629350745930_63180(","")# 去掉不合JSON规范的结尾,结尾不规范数据相同,注意变量名的修改
us_data = us_data[:-2] # 序列的切片
jp_data = jp_data[:-2] # 序列的切片
in_data = in_data[:-2] # 序列的切片# JSON转Python字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)# 获取trend key
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']# 获取日期数据,用于x轴,取2020年(到314下标结束)
us_x_data = us_trend_data['updateDate'][:314]
jp_x_data = jp_trend_data['updateDate'][:314]
in_x_data = in_trend_data['updateDate'][:314]# 获取确诊数据,用于y轴,取2020年(到314下标结束)
us_y_data = us_trend_data['list'][0]['data'][:314]
jp_y_data = jp_trend_data['list'][0]['data'][:314]
in_y_data = in_trend_data['list'][0]['data'][:314]5.生成图表
# 生成图表
line = Line() # 构建折线图对象,Line()的图表对象# 添加x轴数据
line.add_xaxis(us_x_data) # x轴是三个国家公用的,所以一个国家的就好# 添加y轴数据,y轴数据不共用,label_opts功能:当前这个图表中标签属性是否显示
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) # 添加美国的y轴数据
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False)) # 添加日本的y轴数据
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False)) # 添加印度的y轴数据
6.设置全局选项
# 设置全局选项
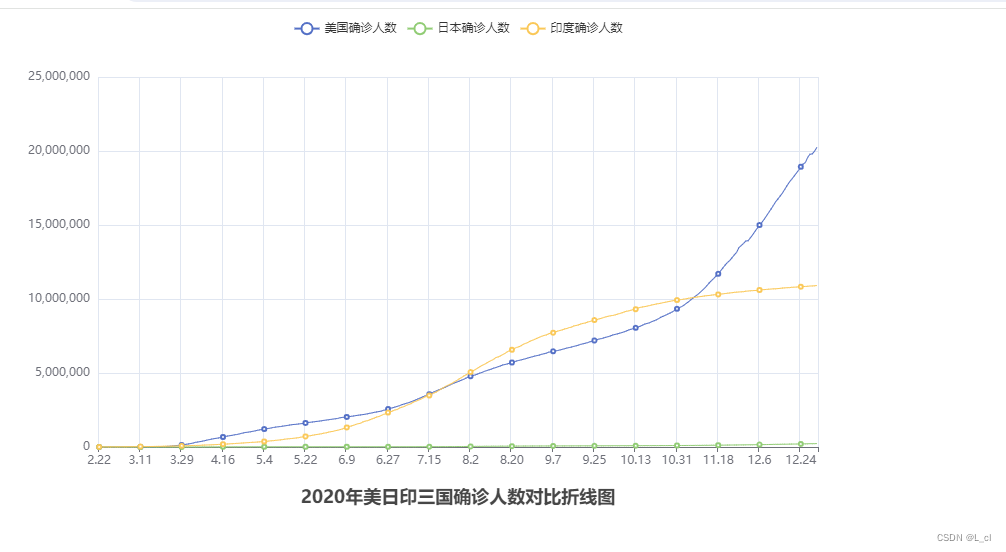
line.set_global_opts(# 标题设置title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%")
)7.整体代码
# 演示可视化需求1:折线图开发
# 导入包
import json # josn可视化包
from pyecharts.charts import Line # 读取文件的函数,导入line功能
from pyecharts.options import TitleOpts, LabelOpts # 标题设置Title包,系列属性LabelOpts包# 处理数据# 美国疫情数据
f_us = open("E:\python.learning\折线图数据\美国.txt","r",encoding="utf-8")
us_data = f_us.read() # 美国的全部内容# 小日本疫情数据
f_jp = open("E:\python.learning\折线图数据\日本.txt","r",encoding="utf-8")
jp_data = f_jp.read() # 日本的全部内容# 印度疫情数据
f_in = open("E:\python.learning\折线图数据\印度.txt","r",encoding="utf-8")
in_data = f_in.read() # 印度的全部内容# 去掉不合JSON规范的开头,每个国家的数据不规范的内容不相同,需查看文档进行改变
us_data = us_data.replace("jsonp_1629344292311_69436(","")
jp_data = jp_data.replace("jsonp_1629350871167_29498(","")
in_data = in_data.replace("jsonp_1629350745930_63180(","")# 去掉不合JSON规范的结尾,结尾不规范数据相同,注意变量名的修改
us_data = us_data[:-2] # 序列的切片
jp_data = jp_data[:-2] # 序列的切片
in_data = in_data[:-2] # 序列的切片# JSON转Python字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)# 获取trend key
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']# 获取日期数据,用于x轴,取2020年(到314下标结束)
us_x_data = us_trend_data['updateDate'][:314]
jp_x_data = jp_trend_data['updateDate'][:314]
in_x_data = in_trend_data['updateDate'][:314]# 获取确诊数据,用于y轴,取2020年(到314下标结束)
us_y_data = us_trend_data['list'][0]['data'][:314]
jp_y_data = jp_trend_data['list'][0]['data'][:314]
in_y_data = in_trend_data['list'][0]['data'][:314]# 生成图表
line = Line() # 构建折线图对象,Line()的图表对象# 添加x轴数据
line.add_xaxis(us_x_data) # x轴是三个国家公用的,所以一个国家的就好# 添加y轴数据,y轴数据不共用,label_opts功能:当前这个图表中标签属性是否显示
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) # 添加美国的y轴数据
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False)) # 添加日本的y轴数据
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False)) # 添加印度的y轴数据# 设置全局选项
line.set_global_opts(# 标题设置title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%")
)# 调用render方法,生成图表
line.render() # 折线图对象.render方法# 关闭文件对象
f_us.close()
f_in.close()
f_jp.close()运行结果:

相关文章:
Python学习从0到1 day18 Python可视化基础综合案例 1.折线图
我默记这段路的酸楚,等来年春暖花开之时再赏心阅读 —— 24.3.24 python基础综合案例 数据可视化 — 折线图可视化 一、折线图案例 1.json数据格式 2.pyecharts模块介绍 3.pyecharts快速入门 4.数据处理 5.创建折线图 1.json数据格式 1.什么是json 2.掌握如何使用js…...

HTML网站的概念
目录 前言: 1.什么是网页: 2.什么是网站: 示例: 3.服务器: 总结: 前言: HTML也称Hyper Text Markup Language,意思是超文本标记语言,同时HTML也是前端的基础&…...

【微服务】Nacos(配置中心)
文章目录 1.AP和CP1.基本介绍2.说明 2.Nacos配置中心实例1.架构图2.在Nacos Server加入配置1.配置列表,加号2.加入配置3.点击发布,然后返回4.还可以编辑 3. 创建 Nacos 配置客户端模块获取配置中心信息1.创建子模块 e-commerce-nacos-config-client50002…...

比较AI编程工具Copilot、Tabnine、Codeium和CodeWhisperer
主流的几个AI智能编程代码助手包括Github Copilot、Codeium、Tabnine、Replit Ghostwriter和Amazon CodeWhisperer。 你可能已经尝试过其中的一些,也可能还在不断寻找最适合自己或公司使用的编程助手。但是,这些产品都会使用精选代码示例来实现自我宣传…...

顺应互联网发展大潮流,红河农资招商火爆开启
顺应互联网发展大潮流,红河农资招商火爆开启 进入新世纪,生态农业建设成为了影响和改变农村、农业工作的重要领域。尤其是在互联网的快速发展之下,实现农业结构调整,推动互联网模式的发展,成为了当前生态农业发展的主流…...

网络七层模型之传输层:理解网络通信的架构(四)
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

微信小程序实现图片懒加载的4种方案
实现图片懒加载的意义 实现图片懒加载可以提高小程序的性能和用户体验,是微信小程序开发中非常重要的一项优化手段。微信小程序实现图片懒加载的目的主要有以下几点: 提高页面加载速度:图片通常是页面中最耗时的资源,如果一次性…...

各大pdf转word软件都用的哪家的ocr引擎?
国内一般的PDF软件一般都调用某国际PDF原厂的OCR接口,但这家公司是主要做PDF,在OCR方面并不专注,一些不是很复杂的场景还能应付得过来,复杂一点的效果就强差人意了,推荐用金鸣表格文字识别系统,它主要有以下…...

学习没有速成可言
那些声称几天就能让你精通软件的书籍,往往是夸大其词的宣传。学习软件需要时间和实践,没有什么快速的捷径可以让你在短时间内成为专家。 对于速成软件书,我个人持保留态度。它们可能提供一些基础知识和技巧,可以给初学者一个入门…...

快速上手Pytrch爬虫之爬取某应图片壁纸
一、前置知识 1 爬虫简介 网络爬虫(又被称作网络蜘蛛、网络机器人,在某些社区中也经常被称为网页追逐者)可以按照指定的规则(网络爬虫的算法)自动浏览或抓取网络中的信息。 1.1 Web网页存在方式 表层网页指的是不需要提交表单&…...

如何在Apache Arrow中定位与解决问题
如何在apache Arrow定位与解决问题 最近在执行sql时做了一些batch变更,出现了一个 crash问题,底层使用了apache arrow来实现。本节将会从0开始讲解如何调试STL源码crash问题,在这篇文章中以实际工作中resize导致crash为例,引出如何…...
[ Linux ] git工具的基本使用(仓库的构建,提交)
1.安装git yum install -y git 2.打开Gitee,创建你的远程仓库,根据提示初始化本地仓库(这里以我的仓库为例) 新建好仓库之后跟着网页的提示初始化便可以了 3.add、commit、push三板斧 git add . //add仓库新增(变…...
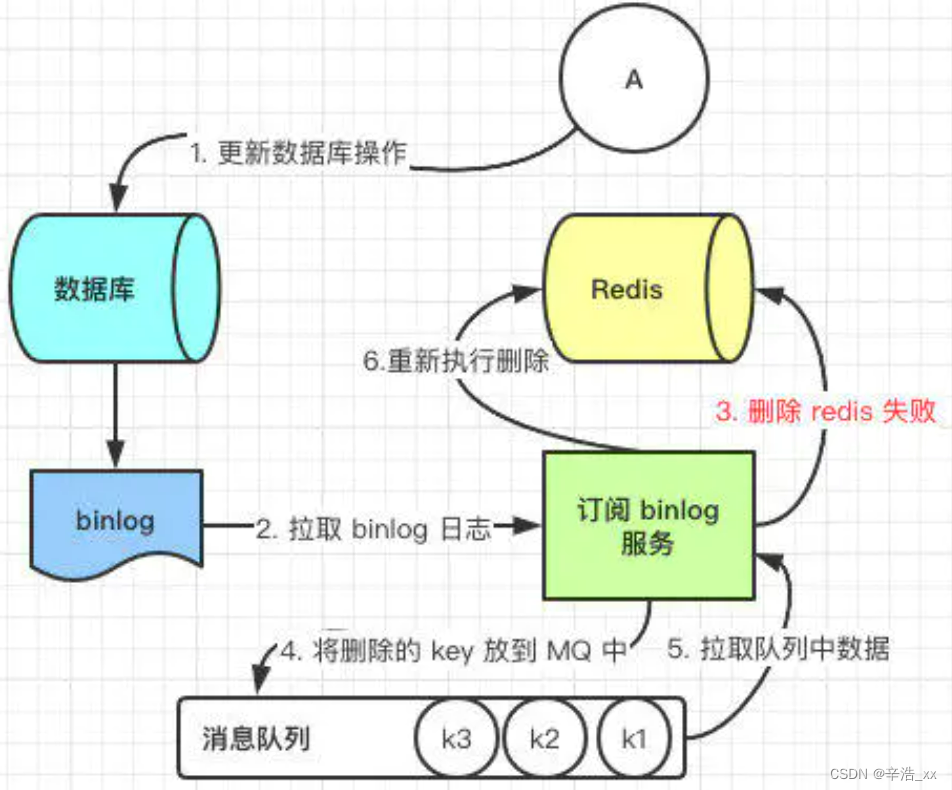
怎样去保证 Redis 缓存与数据库双写一致性?
解决方案 那么我们这里列出来所有策略,并且讨论他们优劣性。 先更新数据库,后更新缓存先更新数据库,后删除缓存先更新缓存,后更新数据库先删除缓存,后更新数据库 先更新数据库,后更新缓存 这种方法是不推…...
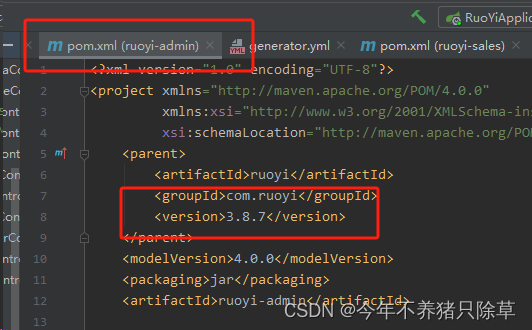
RuoYi-Vue若依框架-新增子模块启动后,前端页面报接口404
如何新建子模块可以参考RuoYi-Vue若依框架-如何新增子模块 我在新增依赖的时候提过版本号的问题,如果不是按照我的博客走的,然后接口报了404,可以选择添加父版本号,官方的参考文档是没写的,但添加了确实能解决这个问题…...

node.js 常见命令
1. npm init: 初始化一个新的Node.js项目,创建一个package.json文件。 2. npm install: 安装项目所需的所有依赖项。 3. npm run: 运行在package.json文件中定义的脚本。 4. node index.js: 运行一个Node.js文件。 5. node -v: 查看当前安装的Node.js版本号。 6. np…...
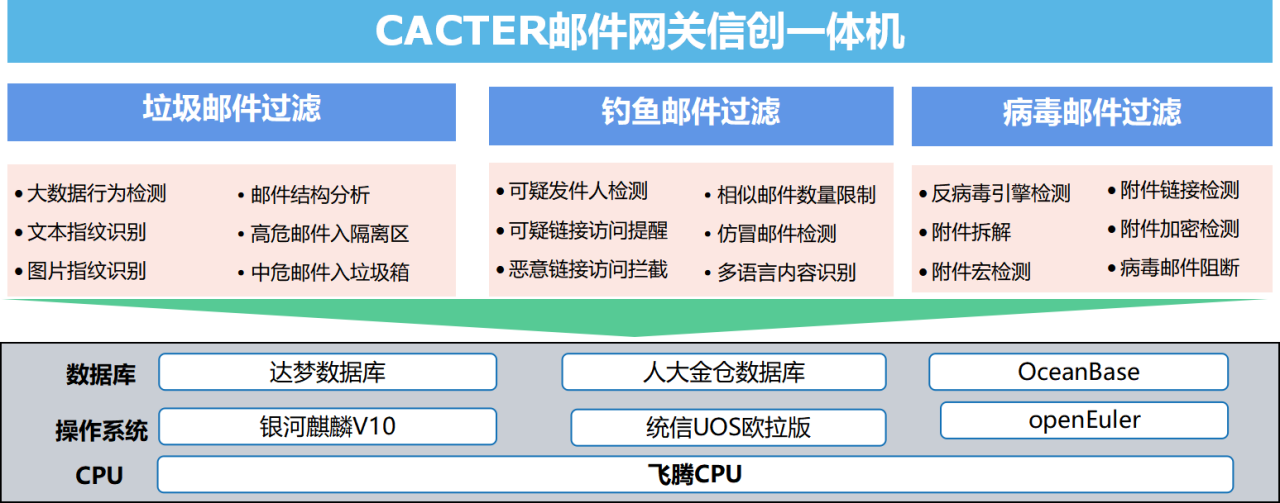
教育信创,重磅发布!Coremail联合飞腾发布全场景教育信创白皮书
3月28日,Coremail参与编制的《教育行业数字化自主创新 飞腾生态解决方案白皮书》正式发布。白皮书历时一年,由25所代表院校、66位专家,119家生态伙伴共同编写。 本次白皮书围绕教育数字化转型和信创人才培养两大领域,聚焦办公、教…...
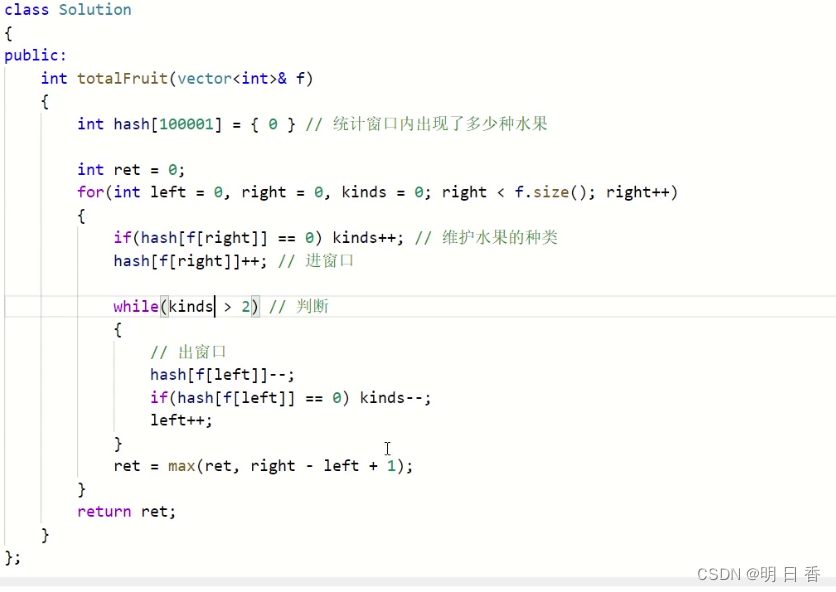
滑动窗口_水果成篮_C++
题目: 题目解析: fruits[i]表示第i棵树,这个fruits[i]所表示的数字是果树的种类例如示例1中的[1,2,1],表示第一棵树 的种类是 1,第二个树的种类是2 第三个树的种类是1随后每一个篮子只能装一种类型的水果,我…...
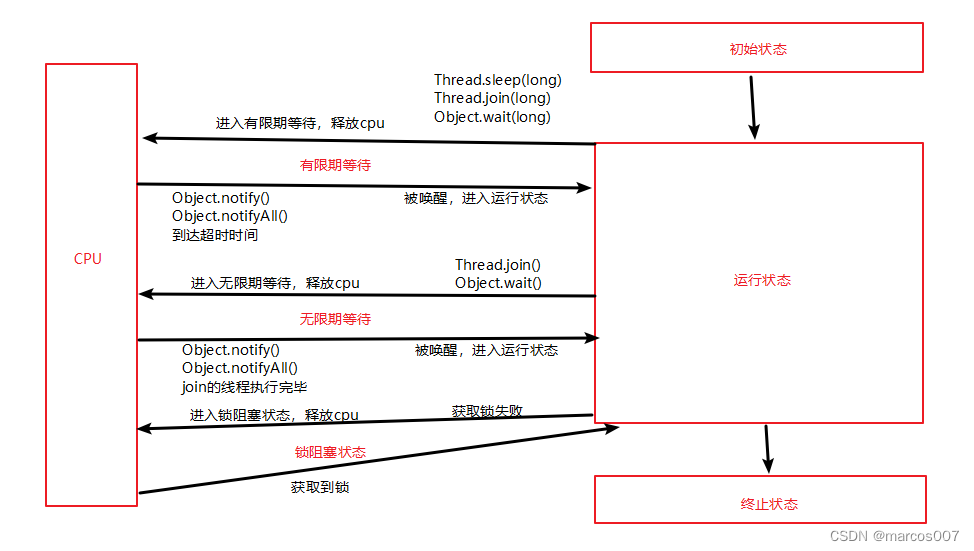
线程的状态:操作系统层面和JVM层面
在操作系统层面,线程有五种状态 初始状态:线程被创建,操作系统为其分配资源。 可运行状态(就绪状态):线程被创建完成,进入就绪队列,参与CPU执行权的争夺。或因为一些原因,从阻塞状态唤醒的线程…...

在Isaac-sim中弧度转四元数以及四元数转弧度的问题
问题: 在Isaac-sim中如果采用set_world_pose()和get_world_pose()得到的都是四元数,如何将弧度转四元数,或者将四元数转为弧度是需要解决的一个问题, 这里的弧度是以x轴为0度,y轴为90度,逆时针方向逐渐增大…...

【计算机网络】高级IO模型
高级IO模型 一、 理解 IO二、认识五种高级 IO 模型1. 阻塞 IO2. 非阻塞IO3. 信号驱动 IO4. IO 多路转接5. 异步 IO 三、高级 IO 重要概念1. 阻塞和非阻塞2. 同步通信和异步通信 四、非阻塞 IOfcntl 一、 理解 IO 当我们调用系统接口 write、read 的时候,本质是把数…...
)
滑动窗口(数组)
作用滑动窗口:求连续满足条件的最短子数组代码模板int left 0; int right;//外层循环扩展右边界,内层循环扩展左边界 for (right 0; right < n; right) {//获取当前考虑的元素while (left < right && check()) {//区间[left,right]不符合…...

Sveltos:多集群Kubernetes应用分发与配置管理的核心利器
1. 项目概述:Sveltos,一个被低估的集群应用管理利器如果你和我一样,长期在多集群的Kubernetes环境中摸爬滚打,那你一定对“应用分发”这件事的复杂性深有体会。想象一下,你手头有几十甚至上百个集群,有的在…...

PyTorch深度学习资源大全:如何快速找到最佳教程和项目库的终极指南
PyTorch深度学习资源大全:如何快速找到最佳教程和项目库的终极指南 【免费下载链接】the-incredible-pytorch The Incredible PyTorch: a curated list of tutorials, papers, projects, communities and more relating to PyTorch. 项目地址: https://gitcode.c…...

抖音去水印免费版哪个好用?2026实测推荐与软件对比
抖音去水印免费版哪个好用?2026实测推荐与软件对比 刷到一条有意思的视频想保存下来发给朋友,下载后却发现左上角顶着一串"用户名"水印;好不容易找到一段适合做素材的内容,画面边缘那行字怎么裁都裁不干净。这几乎是每个…...

强力解密RPG Maker加密文件:新手快速上手指南
强力解密RPG Maker加密文件:新手快速上手指南 【免费下载链接】RPGMakerDecrypter Tool for decrypting and extracting RPG Maker XP, VX and VX Ace encrypted archives and MV and MZ encrypted files. 项目地址: https://gitcode.com/gh_mirrors/rp/RPGMakerD…...

2026最权威的降重复率神器解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 降低人工智能部署以及应用阶段的优化,需要从算力调度、算法剪枝以及参数压缩这三…...

从丰田SUA事件看安全关键系统软件可靠性:设计原则与工程实践
1. 项目概述:当软件缺陷成为致命威胁我干了十多年嵌入式开发,从单片机玩到复杂的汽车域控制器,经手的代码行数自己都数不清了。但每次看到“软件缺陷导致车辆突然加速”这类新闻,后背还是会发凉。这行干久了,你会对代码…...

GPT-4 Turbo访问权、优先响应、高级数据分析——ChatGPT Plus五大隐藏权益深度拆解,92%用户根本没用全
更多请点击: https://intelliparadigm.com 第一章:ChatGPT Plus订阅值不值得买 ChatGPT Plus 提供每月 $20 的固定订阅服务,主打 GPT-4 模型访问、优先响应队列、文件上传解析(PDF/CSV/TXT 等)及自定义 GPTs 功能。是…...

Windows 11本地部署最新大模型深度方案
一、方案概述 随着大语言模型的快速发展,本地部署已成为保护数据隐私、降低API成本的重要选择。本方案将详细介绍在Windows 11系统上部署最新大模型的完整流程,包括硬件配置、环境搭建、模型选择和性能优化。 二、硬件配置要求 2.1 最低配置 GPU: NVIDIA…...

ChatGPT开发者实战指南:从API集成到应用部署的完整资源导航
1. 项目概述:一份面向开发者的ChatGPT资源导航 如果你是一名开发者、产品经理,或者任何对AI应用构建感兴趣的技术爱好者,最近几个月肯定被ChatGPT和GPT-3相关的新闻、工具和项目刷屏了。信息爆炸带来的一个直接问题是:好东西太多…...