快速上手Pytrch爬虫之爬取某应图片壁纸
一、前置知识
1 爬虫简介
网络爬虫(又被称作网络蜘蛛、网络机器人,在某些社区中也经常被称为网页追逐者)可以按照指定的规则(网络爬虫的算法)自动浏览或抓取网络中的信息。
1.1 Web网页存在方式
- 表层网页指的是不需要提交表单,使用静态的超链接就可以直接访问的静态页面。
- 深层网页指的是需要用户提交一些关键词才能获得的Wb页面。深层页面需要访问的信息数量是表层页面信息数量的几百倍,所以深层页面是主要的爬取对象。
1.2 网络爬虫的分类
1.2.1通用网络爬虫/全网爬虫
- 通用网络爬虫的爬行范围和数量巨大,对爬行速度和存储空间要求较高,通常采用并行工作方式,需要较长时间才可以刷新一次页面,所以存在着一定的缺陷。
- 主要应用于大型搜索引擎中,有非常高的应用价值。通用网络爬虫主要由初始URL(统一资源定位符)集合、UL队列、页面爬行模块,页面分析模块、页面数据库、链接过滤模块等构成。
1.2.2 聚焦网络爬虫/主题网络爬虫
- 主要指按照预先定义好的主题,有选择地进行相关网页爬取的一种网络爬虫,将爬取的目标网页定位在与主题相关的页面中,极大地节省了硬件和网络资源,保存的页面也由于数量少而更快了。
- 主要应用在对特定信息的爬取,为某一类特定的人群提供服务。
1.2.3 深层网络爬虫
深层网络爬虫主要通过六个基本功能的模块(爬行控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表、LVS表)等部分构成。其中,LVS表示标签、数值集合,用来表示填充表单的数据源。
1.3 爬虫的原理
①获取初始的网络地址,该地址是用户自己制定的初始爬取的网页。
②通过爬虫代码向网页服务器发送网络请求。
③实现网页中数据的解析,确认数据在网页代码中的位置。
④在服务器响应数据中,提取数据内容。
⑤实现数据的清洗,将无用数据筛选。
⑥将清洗后的数据保存至本地或数据库当中。

2 HTTP原理
2.1 URL
使用浏览器访问网页时,需要在浏览器地址栏处填写目标网页的URL地址,统一资源定位符。
2.2 HTTP协议
HTTP(hypertext transfer protocol),即超文本传输协议,是互联网上应用最为厂厂泛的一种网络),主要利用TCP(传输控制协议)在web服务器和客户端之间传输信息的协议。客户端使用器发起HTTP请求给Web服务器,Web服务器发送被请求的信息给客户端。
2.2.1 HTTP与Web服务器
当在浏览器输人URL地址后,浏览器会先请求DNS域名系统服务器,获得请求站点的P地址(根据URL地址www.aliyun.com获取其对应的P地址,如101.201.120.85),然后发送一个HTTP请求(request)给拥有该IP的主机(阿里云服务器),接着就会接收到服务器返回的HTTP响应(response),浏览器经过渲染后,以一种较好的效果呈现给用户。
2.2.2 Web服务器工作原理
①建立连接:客户端通过TCP/IP(传输控制协议、网际协议)协议建立到服务器的TCP连接。
②请求过程:客户端向服务器发送HTTP协议请求包,请求服务器里的资源文档。
③应答过程:服务器向客户端发送HTTP协议应答包,如果请求的资源包含动态语言的内容,那么服务器会调用动态语言的解释引擎处理动态语言部分,并将处理后得到的数据返回给客户端。由客户端HTML(超文本标记语言)文档,并在客户端屏幕上渲染图形结果。服务器返回给客户端的状态码可分为5种类型,由它们的第一位数字表示。

④关闭连接:客户端与服务器断开连接。
2.2.3 浏览器中的请求与响应

3 urllib模块
3.1 urllib模块简介
Python3中将urib与urllib2模块的功能组合,并且命名为urllib。Python3中的urllib模块中包含多个功能的子模块,具体内容如下。
- urllib.request:用于实现基本HTTP请求的模块。
- urlb.error:异常处理模块,如果在发送网络请求时出现了错误,可以捕获的有效处理。
- urllib.parse:用于解析URL的模块。
- urllib.robotparser:用于解析robots.txt文件,判断网站是否可以爬取信息。
3.2 发送网络请求urllib.request.urlopen()
3.2.1 urllib.request.urlopen()函数简介
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)- url:需要访问网站的URL完整地址
- data:该参数默认为None,通过该参数确认请求方式,如果是None,表示请求方式为GET,否则请求方式为POST。在发送POST请求时,参数daa需要以字典形式的数据作为参数值,并且需要将字典类型的参数值转换为字节类型的数据才可以实现POST请求。
- timeout:设置网站访问超时时间,以秒为单位。
- cafile:指定包含CA证书的单个文件,
- capah:指定证书文件的目录。
- cadefault:CA证书默认值
- context:描述SSL选项的实例。
3.2.2 发送GET请求
import urllib.request
response = urllib.request.urlopen("https://www.baidu.com/")
print("response:",response)
# 输出: response: <http.client.HTTPResponse object at 0x000001AD2793C850>3.2.3 获取状态码、响应头、获取HTMl代码
import urllib.request
url = "https://www.baidu.com/"
response = urllib.request.urlopen(url=url)
print("响应状态码:",response.status)
# 输出: 响应状态码: 200
print("响应头信息:",response.getheaders())
# 响应头信息: [('Accept-Ranges', 'bytes'), ('Cache-Control', 'no-cache'), ('Content-Length', '227'), ('Content-Type', 'text/html'), ('Date', 'Wed, 09 Mar 2022 10:45:04 GMT'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('Pragma', 'no-cache'), ('Server', 'BWS/1.1'), ('Set-Cookie', 'BD_NOT_HTTPS=1; path=/; Max-Age=300'), ('Set-Cookie', 'BIDUPSID=5C4759402F5A8C38E347A1E6FB8788EF; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'PSTM=1646822704; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'BAIDUID=5C4759402F5A8C384F12C0C34D5D3B36:FG=1; max-age=31536000; expires=Thu, 09-Mar-23 10:45:04 GMT; domain=.baidu.com; path=/; version=1; comment=bd'), ('Strict-Transport-Security', 'max-age=0'), ('Traceid', '1646822704264784359414774964437731406767'), ('X-Frame-Options', 'sameorigin'), ('X-Ua-Compatible', 'IE=Edge,chrome=1'), ('Connection', 'close')]
print("响应头指定信息:",response.getheader('Accept-Ranges'))
# 响应头指定信息: bytes
print("目标页面的Html代码 \n ",response.read().decode('utf-8'))
# 即为Html文件的内容3.2.4 发送POST请求
urlopen()方法在默认的情况下发送的是GET请求,如果需要发送POST请求,可以为其设置data参数、该参数是byte类型,需要使用bytes()方法将参数值进行数据类型转换
import urllib.request
import urllib.parseurl = "https://www.baidu.com/"
data = bytes(urllib.parse.urlencode({'hello':'python'}),encoding='utf-8') # 将表单转化为bytes类型,并且设置编码
response = urllib.request.urlopen(url=url,data=data,timeout=0.1) # 发送网络请求 设置超时时间0.1s
print(response.read().decode('utf-8')) # 读取Html代码进行编码3.2.5 处理网络超市异常
如果遇到了超时异常,爬虫程序将在此处停止。所以在实际开发中开发者可以将超时异常捕获,然后处理下面的爬虫任务。以上述发送网络请求为例,将超时参数imeout设置为0.1s,然后使用try...excpt 捕获异常并判断如果是超时异常就模拟自动执行下一个任务。
import urllib.request
import urllib.error
import socketurl = "https://www.baidu.com/"try:response = urllib.request.urlopen(url=url,timeout=0.1)print(response.read().decode('utf-8'))
except urllib.error.URLError as error :if isinstance(error.reason,socket.timeout):print("当前任务已经超时,即将执行下一任务")4 设置请求头
4.1 urllib.request.Request()
urlopen()方法可以实现最基本的请求的发起,但如果要加入Headers等信息,就可以利用Request类来构造请求。
4.1.1 函数原型
使用方法为:
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)4.1.2 参数解析
- url:要请求的URL地址
- data :必须是bytes(字节流)类型,如果是字典,可以用urllib.parse模块里的urlencode()编码
- headers:是一个字典类型,是请求头。①在构造请求时通过headers参数直接构造,也可以通过调用请求实例的add_header()方法添加。②通过请求头伪装浏览器,默认User-Agent是Python-urllib。要伪装火狐浏览器,可以设置User-Agent为Mozilla/5.0 (x11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11
- origin_req_host:指定请求方的host名称或者ip地址
- unverifiable:设置网页是否需要验证,默认是False,这个参数一般也不用设置。
- method :字符串,用来指定请求使用的方法,比如GET,POST和PUT等。
4.1.3 设置请求头的作用
请求头参数是为了模拟浏览器向网页后台发送网络请求,这样可以避免服务器的反爬措施。使用urlopen()方法发送网络请求时,其本身并没有设置请求头参数,所以向测试地址发送请求时,返回的信息中headers将显示默认值。
所以在设置请求头信息前,需要在浏览器中找到一个有效的请求头信息。以谷歌浏览器为例2
4.1.4 手动寻找请求头
F12打开开发工具,选择 Network 选项,接着任意打开一个网页,在请求列表中找到Headers选项中找到请求头。

4.2 设置请求头
import urllib.request
import urllib.parse
url = "https://www.baidu.com/" # 设置请求地址
#设置请求头信息
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
# data转化为bytes类型,并设置编码方式
data = bytes(urllib.parse.urlencode({'hello':'python'}),encoding='utf-8')
# 创建Request类型对象
url_post = urllib.request.Request(url=url,data=data,headers=headers,method='POST')
# 发送网络请求
response = urllib.request.urlopen(url_post)
# 读取HTMl代码并进行UTF-8编码
print(response.read().decode('utf-8'))5 Cookie
Cookie是服务器向客户端返回响应数据时所留下的标记,当客户端再次访问服务器时将携带这个标记。一般在实现登录一个页面时,登录成功后,会在浏览器的Cookie中保留一些信息,当浏览器再次访问时会携带Cook中的信息,经过服务器核对后便可以确认当前用户已经登录过,此时可以直接将登录后的数据返回。
在使用网络爬虫获取网页登录后的数据时,除了使用模拟登录以外,还可以获取登录后的Cookie,然后利用这个Cookie再次发送请求时,就能以登录用户的身份获取数据。
5.1 模拟登陆
5.1.1 登陆前准备
目标地址:site2.rjkflm.com:666
账号:test01test
密码:123456
5.1.2 查看登陆目标地址
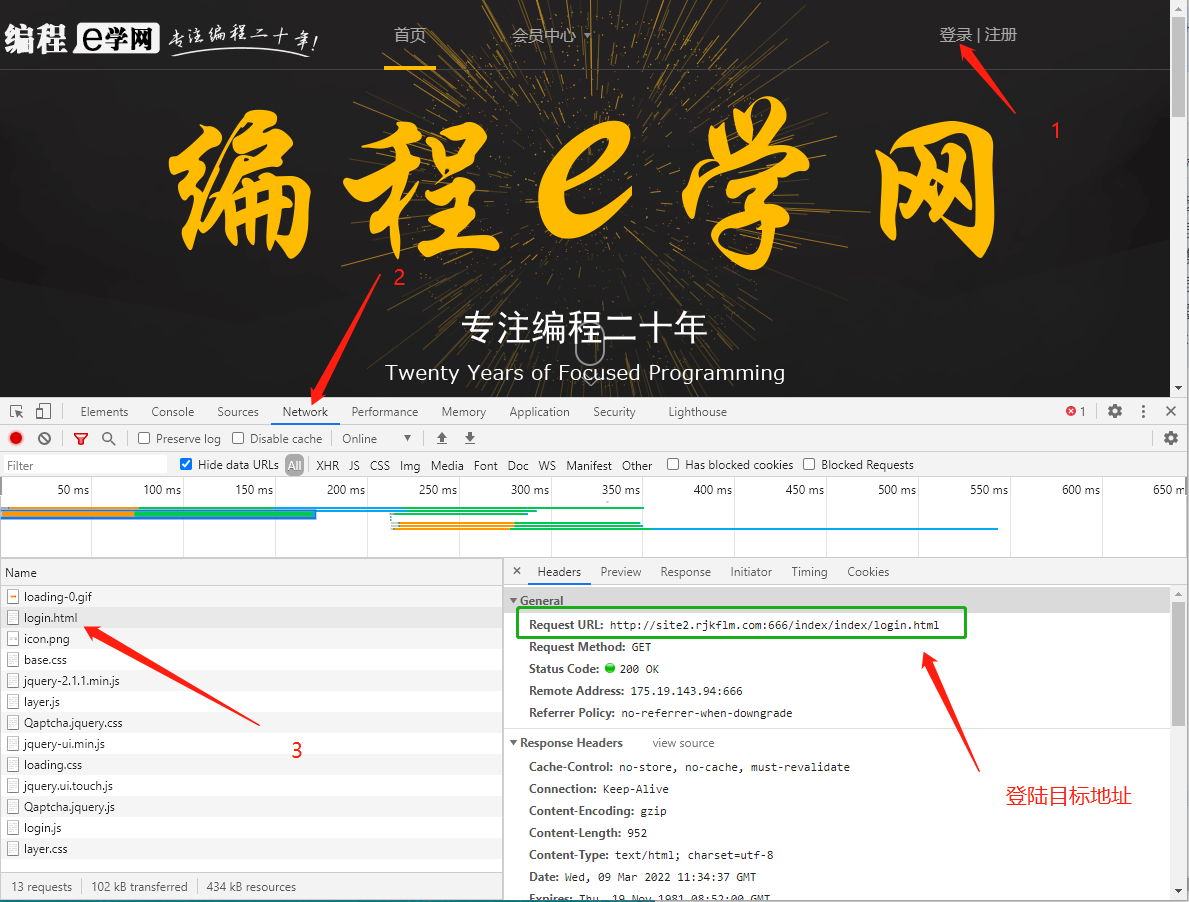
得到以下信息
Request URL:http://site2.rjkflm.com:666/index/index/login.html
5.1.2 实现模拟登陆
import urllib.request
import urllib.parseurl = "http://site2.rjkflm.com:666/index/index/chklogin.html"
# 设置表单
data = bytes(urllib.parse.urlencode({'username':'test01test','password':'123456'}),encoding='utf-8')
# 将bytes转化,并且设置编码
r = urllib.request.Request(url=url,data=data,method='POST')
response = urllib.request.urlopen(r) # 发送请求
print(response.read().decode('utf-8'))
# 返回:{"status":true,"msg":"登录成功!"}5.1.3 获取Cookies
import urllib.request
import urllib.parse
import http.cookiejar
import jsonurl = "http://site2.rjkflm.com:666/index/index/chklogin.html"
# 设置表单
data = bytes(urllib.parse.urlencode({'username':'test01test','password':'123456'}),encoding='utf-8')cookie_file = 'cookie.txt'
cookie = http.cookiejar.LWPCookieJar(cookie_file) # 创建LWPCookieJar对象
# 生成 Cookie处理器
cookie_processor = urllib.request.HTTPCookieProcessor(cookie)
# 创建opener对象
opener = urllib.request.build_opener(cookie_processor)
response = opener.open(url,data=data) # 发送网络请求
response = json.loads(response.read().decode('utf-8'))['msg']
if response == '登陆成功':cookie.save(ignore_discard=True,ignore_expires=True) # 保存Cookie文件5.1.4 载入Cookies
import urllib.request
import http.cookiesimport urllib.request # 导入urllib.request模块
import http.cookiejar # 导入http.cookiejar子模块
# 登录后页面的请求地址
url = 'http://site2.rjkflm.com:666/index/index/index.html'
cookie_file = 'cookie.txt' # cookie文件cookie = http.cookiejar.LWPCookieJar() # 创建LWPCookieJar对象
# 读取cookie文件内容
cookie.load(cookie_file,ignore_expires=True,ignore_discard=True)
# 生成cookie处理器
handler = urllib.request.HTTPCookieProcessor(cookie)
# 创建opener对象
opener = urllib.request.build_opener(handler)
response = opener.open(url) # 发送网络请求
print(response.read().decode('utf-8')) # 打印登录后页面的html代码二、项目简介
必应是微软推出的搜索引擎,相比于百度具有广告少的显著优点,比较良心。以下为必应的网址:必应
经常使用必应应该可以发现,其主页每天都会更新一张图片,博主发现这些图片非常符合博主的审美,希望每天能够下载收藏每张图片。幸运的是已经有人完成了这项工作,具体请看这个网站:必应每日高清壁纸(必应每日高清壁纸 - 精彩,从这里开始)。
这个网站收录了必应每天的主页图片,并且提供直接下载(管理猿太良心了,祝愿少掉一些头发,少写一些bug )。但是博主发现这个网站缺少一个一键全部下载功能,只能一张一张图片手动下载,如果要把所有图片都下载下来,非常麻烦,因此用python写了一个下载网站上所有图片的小爬虫,分享给大家。
三、使用的环境
- python3.8.1(较新版本都可)
- requests库(需要使用pip工具下载该库)
- re库(python自带,不用下载,直接导入就行)
- bs4库(需要使用pip工具下载该库)
1 分析页面
1.1 分析网址
https://bing.ioliu.cn/?p=11.2 元素寻找页面
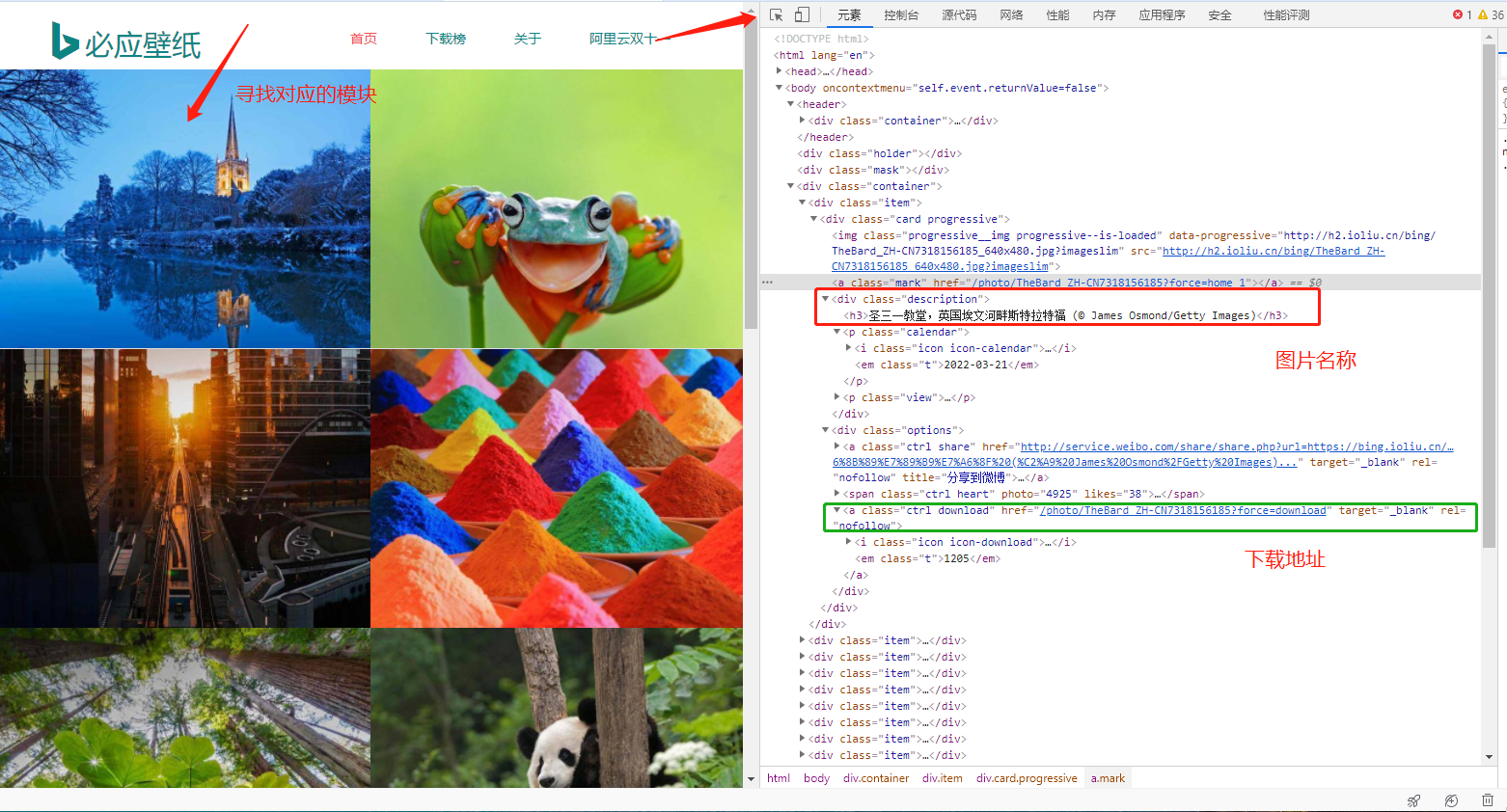
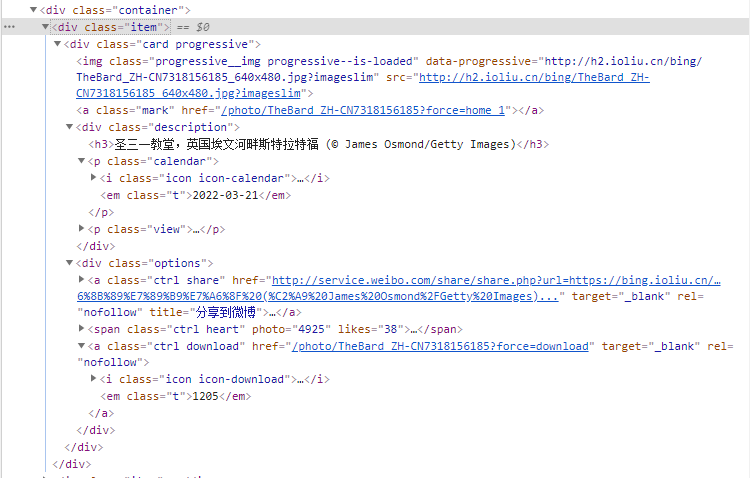
2 代码编写
import urllib3
import re
import oshttp = urllib3.PoolManager() # 创建连接池管理对象
# 定义火狐浏览器请求头信息
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0'}# 通过网络请求,获得该页面的信息
def send_request(url,headers):response = http.request('GET',url,headers=headers)if response.status == 200:html_str = response.data.decode('utf-8')return html_str# 解析地址并下载壁纸
def download_pictures(html_str):# 提取壁纸名称pic_names = re.findall('<div class="description"><h3>(.*?)</h3>',html_str) print("未处理的壁纸名称:",pic_names)# 提取壁纸的下载地址pic_urls = re.findall('<a class="ctrl download" href="(.*?)" ',html_str)print("未处理的下载地址:", pic_urls)for name,url in zip(pic_names,pic_urls): # 遍历壁纸的名称与地址pic_name = name.replace('/',' ') # 把图片名称中的/换成空格pic_url = 'https://bing.ioliu.cn'+url # 组合一个完整的urlpic_response = http.request('GET',pic_url,headers=headers) # 发送网络请求,准备下载图片if not os.path.exists('pic'): # 判断pic文件夹是否存在os.mkdir('pic') # 创建pic文件夹with open('pic/'+pic_name+'.jpg','wb') as f:f.write(pic_response.data) # 写入二进制数据,下载图片print('图片:',pic_name,'下载完成了!')if __name__ == '__main__':for i in range(1, 2):url = 'https://bing.ioliu.cn/p={}'.format(i)print(url)html_str = send_request(url=url, headers=headers) # 调用发送网络请求的方法download_pictures(html_str=html_str) # 调用解析数据并下载壁纸的方法3 效果展示

相关文章:
快速上手Pytrch爬虫之爬取某应图片壁纸
一、前置知识 1 爬虫简介 网络爬虫(又被称作网络蜘蛛、网络机器人,在某些社区中也经常被称为网页追逐者)可以按照指定的规则(网络爬虫的算法)自动浏览或抓取网络中的信息。 1.1 Web网页存在方式 表层网页指的是不需要提交表单&…...

如何在Apache Arrow中定位与解决问题
如何在apache Arrow定位与解决问题 最近在执行sql时做了一些batch变更,出现了一个 crash问题,底层使用了apache arrow来实现。本节将会从0开始讲解如何调试STL源码crash问题,在这篇文章中以实际工作中resize导致crash为例,引出如何…...
[ Linux ] git工具的基本使用(仓库的构建,提交)
1.安装git yum install -y git 2.打开Gitee,创建你的远程仓库,根据提示初始化本地仓库(这里以我的仓库为例) 新建好仓库之后跟着网页的提示初始化便可以了 3.add、commit、push三板斧 git add . //add仓库新增(变…...
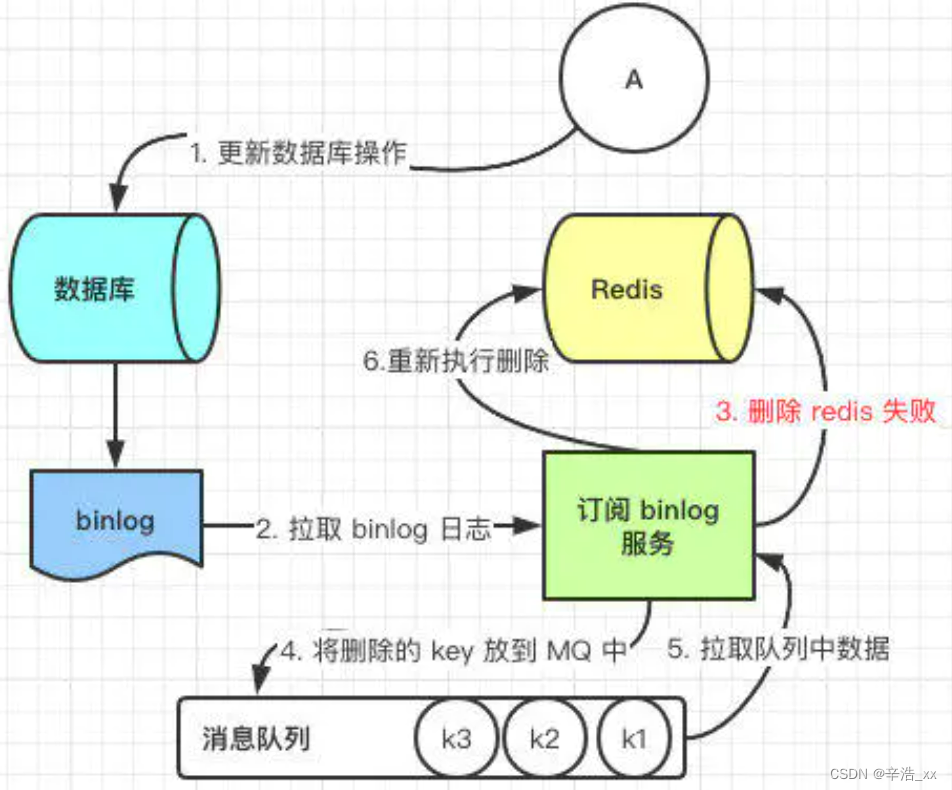
怎样去保证 Redis 缓存与数据库双写一致性?
解决方案 那么我们这里列出来所有策略,并且讨论他们优劣性。 先更新数据库,后更新缓存先更新数据库,后删除缓存先更新缓存,后更新数据库先删除缓存,后更新数据库 先更新数据库,后更新缓存 这种方法是不推…...
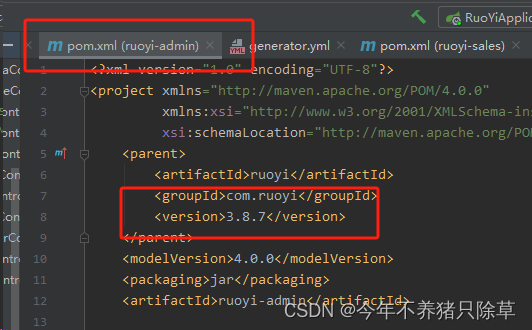
RuoYi-Vue若依框架-新增子模块启动后,前端页面报接口404
如何新建子模块可以参考RuoYi-Vue若依框架-如何新增子模块 我在新增依赖的时候提过版本号的问题,如果不是按照我的博客走的,然后接口报了404,可以选择添加父版本号,官方的参考文档是没写的,但添加了确实能解决这个问题…...

node.js 常见命令
1. npm init: 初始化一个新的Node.js项目,创建一个package.json文件。 2. npm install: 安装项目所需的所有依赖项。 3. npm run: 运行在package.json文件中定义的脚本。 4. node index.js: 运行一个Node.js文件。 5. node -v: 查看当前安装的Node.js版本号。 6. np…...
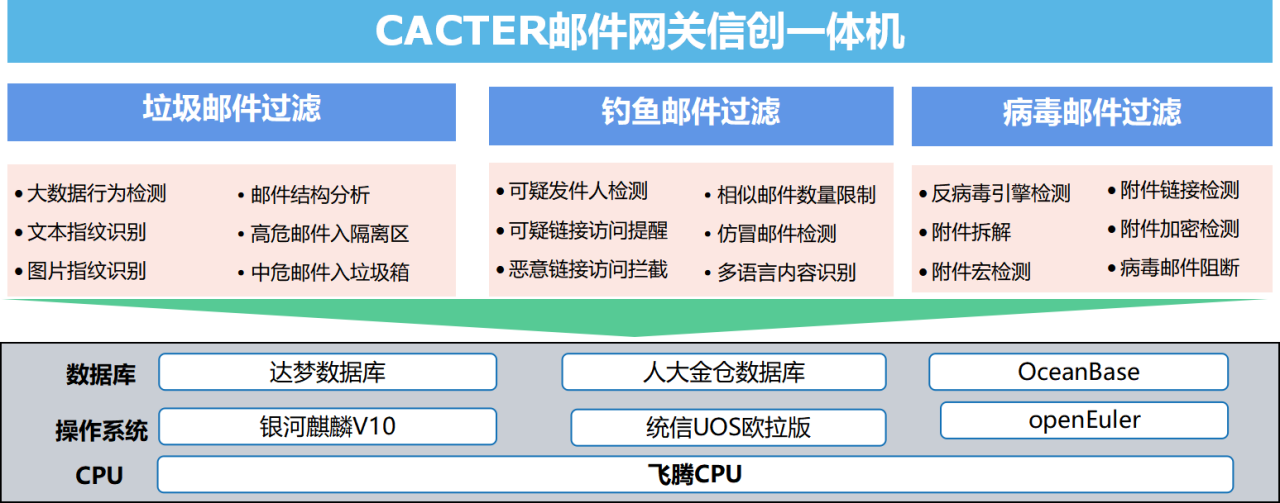
教育信创,重磅发布!Coremail联合飞腾发布全场景教育信创白皮书
3月28日,Coremail参与编制的《教育行业数字化自主创新 飞腾生态解决方案白皮书》正式发布。白皮书历时一年,由25所代表院校、66位专家,119家生态伙伴共同编写。 本次白皮书围绕教育数字化转型和信创人才培养两大领域,聚焦办公、教…...
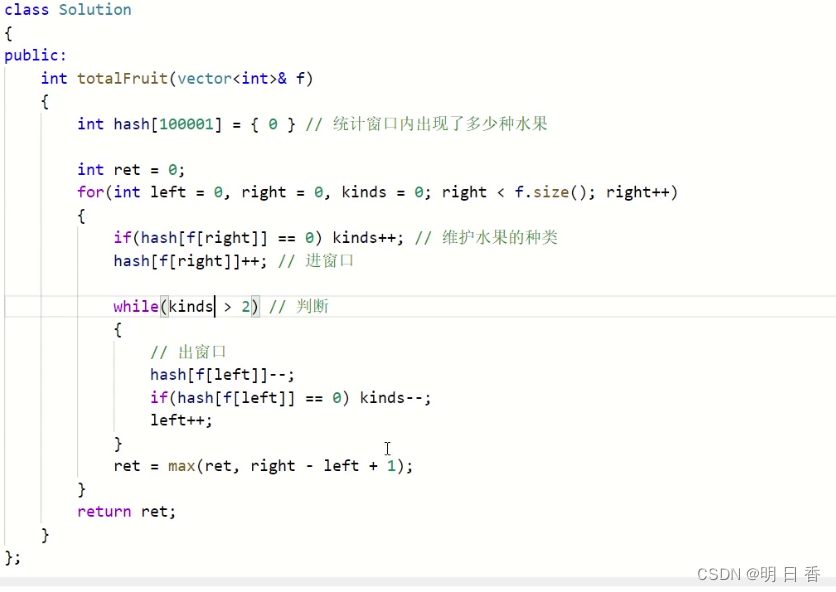
滑动窗口_水果成篮_C++
题目: 题目解析: fruits[i]表示第i棵树,这个fruits[i]所表示的数字是果树的种类例如示例1中的[1,2,1],表示第一棵树 的种类是 1,第二个树的种类是2 第三个树的种类是1随后每一个篮子只能装一种类型的水果,我…...
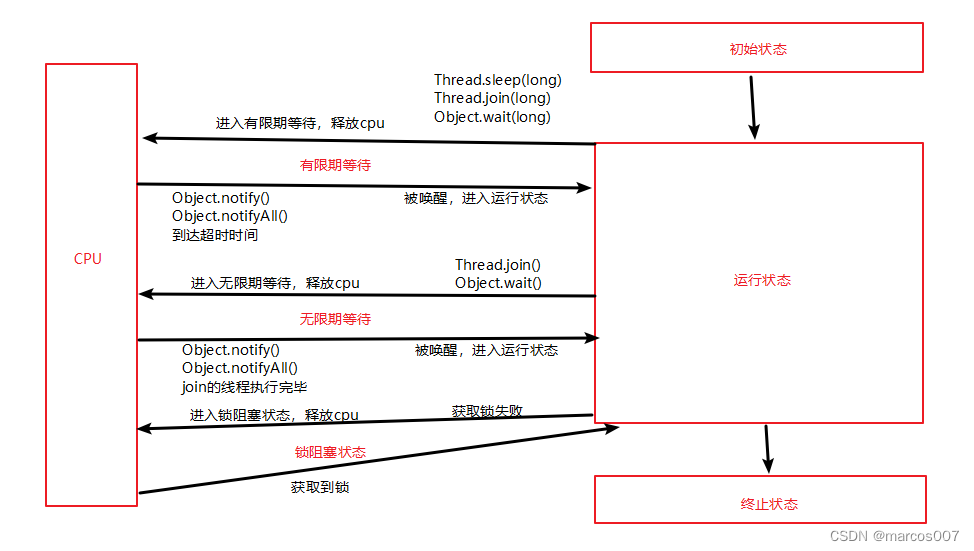
线程的状态:操作系统层面和JVM层面
在操作系统层面,线程有五种状态 初始状态:线程被创建,操作系统为其分配资源。 可运行状态(就绪状态):线程被创建完成,进入就绪队列,参与CPU执行权的争夺。或因为一些原因,从阻塞状态唤醒的线程…...

在Isaac-sim中弧度转四元数以及四元数转弧度的问题
问题: 在Isaac-sim中如果采用set_world_pose()和get_world_pose()得到的都是四元数,如何将弧度转四元数,或者将四元数转为弧度是需要解决的一个问题, 这里的弧度是以x轴为0度,y轴为90度,逆时针方向逐渐增大…...

【计算机网络】高级IO模型
高级IO模型 一、 理解 IO二、认识五种高级 IO 模型1. 阻塞 IO2. 非阻塞IO3. 信号驱动 IO4. IO 多路转接5. 异步 IO 三、高级 IO 重要概念1. 阻塞和非阻塞2. 同步通信和异步通信 四、非阻塞 IOfcntl 一、 理解 IO 当我们调用系统接口 write、read 的时候,本质是把数…...

LabVIEW电动汽车直流充电桩监控系统
LabVIEW电动汽车直流充电桩监控系统 随着电动汽车的普及,充电桩的安全运行成为重要议题。通过集成传感器监测、单片机技术与LabVIEW开发平台,设计了一套电动汽车直流充电桩监控系统,能实时监测充电桩的温度、电压和电流,并进行数…...
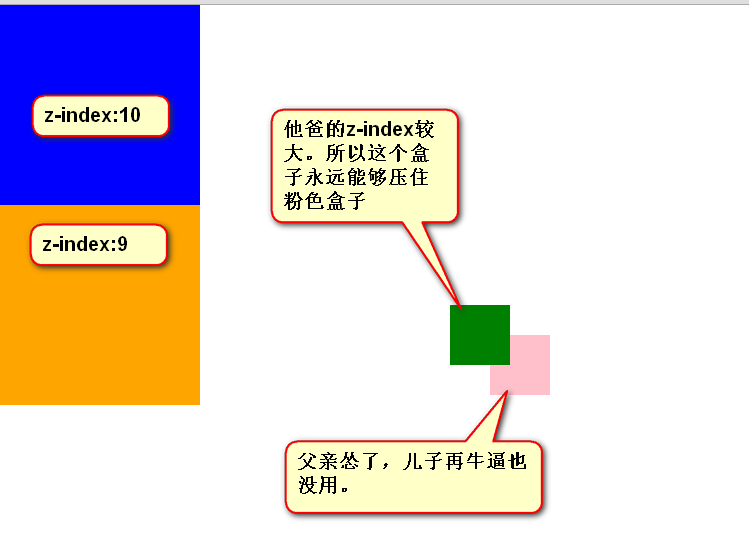
前端学习<二>CSS基础——08-CSS属性:定位属性
CSS的定位属性有三种,分别是绝对定位、相对定位、固定定位。 position: absolute; <!-- 绝对定位 -->position: relative; <!-- 相对定位 -->position: fixed; <!-- 固定定位 --> 下面逐一介绍。 相对定位 相对定位:让…...
)
88. 合并两个有序数组(javascript)
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。 注意:最终,合并后数组…...

机器学习_集成学习_梯度提升_回归_决策树_XGBoost相关概念
目录 1. 机器学习 使用监督吗?什么又是监督学习? 2. 与XGBoost 类似的机器学习方法有哪些? 3. 随机森林方法 和 梯度提升方法 有什么区别? 分别应用于什么场景? 4. 决策树回归方法 和 Gradient Boosting类回归方法…...
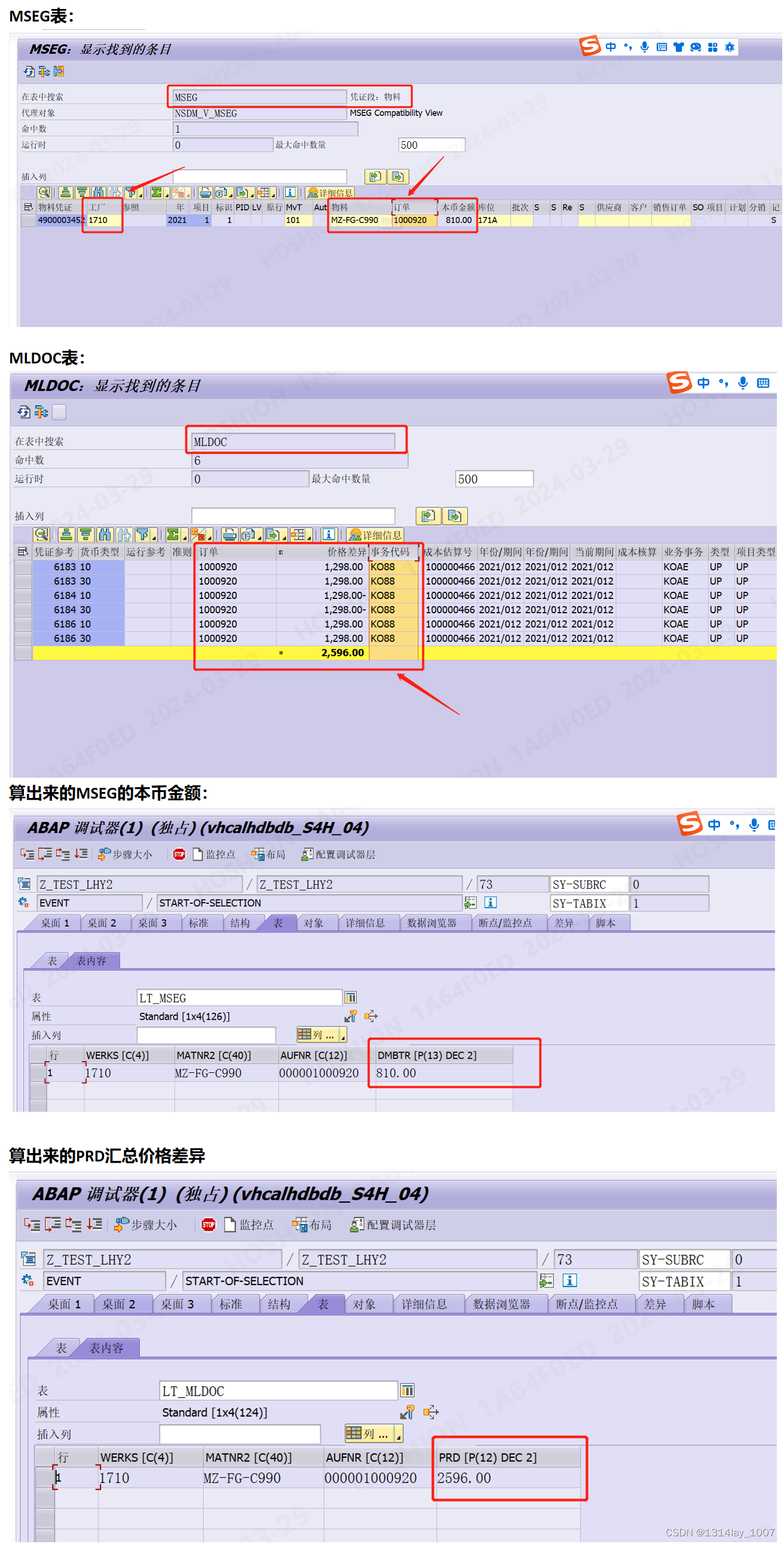
ABAP 字段类型不一样导致相加之后金额错误
文章目录 ABAP 字段类型不一样导致相加之后金额错误写在前面的总结示例程序1汇总MSEG表和MLDOC表 ABAP 字段类型不一样导致相加之后金额错误 写在前面的总结 如果需要不同底表的字段相加的值,那么最好是根据条件去分别算出那些值放在临时内表里面,再去…...

【L1距离和L2距离】Manhattan Distance Euclidean Distance 解释和计算公式
距离度量 特征空间中两个实例点的距离可以反映出两个实力点之间的相似性程度,使用的距离可以是欧式距离,也可以是其他距离。 欧氏距离(L2距离):最常见的两点之间或多点之间的距离表示法,又称之为欧几里得度量,它定义于…...
自动发卡平台源码优化版,支持个人免签支付
源码下载地址:自动发卡平台源码优化版.zip 环境要求: php 8.0 v1.2.6◂ 1.修复店铺共享连接时异常问题 2024-03-13 23:54:20 v1.2.5 1.[新增]用户界面硬币增款扣款操作 2.[新增]前台对接库存信息显示 3.[新增]文件缓存工具类[FileCache] 4.[新增]库存同…...

如何使用固定公网地址远程连接Python编译器并将运行结果返回到Pycharm
文章目录 一、前期准备1. 检查IDE版本是否支持2. 服务器需要开通SSH服务 二、Pycharm本地链接服务器测试1. 配置服务器python解释器 三、使用内网穿透实现异地链接服务器开发1. 服务器安装Cpolar2. 创建远程连接公网地址 四、使用固定TCP地址远程开发 本文主要介绍如何使用Pych…...
Java设计模式—备忘录模式(快照模式)
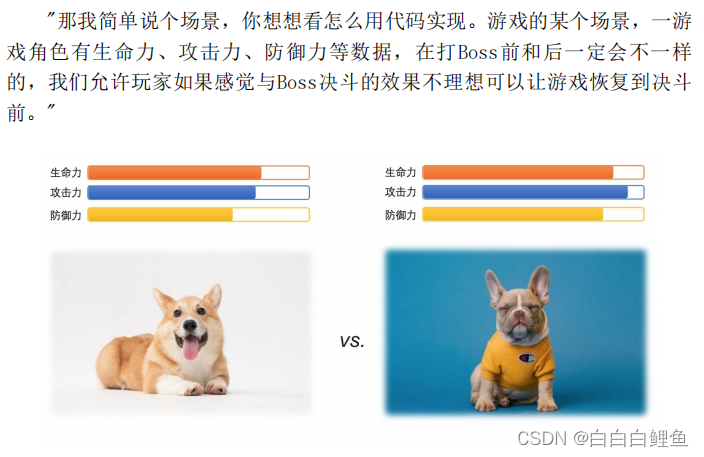
定义 备忘录模式提供了一种状态恢复的实现机制,使得用户可以方便地回到一个特定的历史步骤,当新的状态无效或者存在问题时,可以使用暂时存储起来的备忘录将状态复原,很多软件都提供了撤销(Undo)操作&#…...

基于Next.js+MUI+Tailwind的Materio管理后台模板实战指南
1. 项目概述:Materio - 一个为开发者而生的免费管理后台模板如果你是一名前端或全栈开发者,正在为下一个企业级应用、SaaS平台或者内部管理系统寻找一个既专业又省心的起点,那么你很可能已经厌倦了从零开始搭建UI组件、设计布局和配置路由的繁…...

实测Taotoken多模型聚合服务的响应延迟与稳定性观感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken多模型聚合服务的响应延迟与稳定性观感 1. 引言 在将大模型能力集成到实际应用的过程中,开发者除了关注模…...

【紧急通告】DeepSeek-R1毒性分类器存在语境盲区?3小时内验证并热修复的4种API级补丁
更多请点击: https://intelliparadigm.com 第一章:【紧急通告】DeepSeek-R1毒性分类器存在语境盲区?3小时内验证并热修复的4种API级补丁 近期社区报告指出,DeepSeek-R1毒性分类器在处理嵌套反讽、多轮对话上下文拼接及跨语言混合…...

2026最权威的降重复率神器解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 降低人工智能部署以及应用阶段的优化,需要从算力调度、算法剪枝以及参数压缩这三…...
2026.5.13最新版免费下载 转存后自动更新 (看到请立即转存 资源随时失效)pc手机版通用)
冬日狂想曲(赠去马赛克补丁)2026.5.13最新版免费下载 转存后自动更新 (看到请立即转存 资源随时失效)pc手机版通用
下载链接 冬日狂想曲》(Winter Memories)作为《夏日狂想曲》的正统续作,在独立游戏圈、尤其是像素风生活模拟(Life Sim)领域有着极高的讨论度。 针对你提到的内容,我需要先说明:作为一个人工智…...

Z轴传感技术在大屏触控中的应用与优化
1. Z轴传感技术:重新定义大屏触控的物理维度十年前我第一次接触银行ATM的触控屏时,那种生硬的点击反馈让人总想多戳几下确认操作是否成功。如今站在商场里观察用户操作自助点餐机,类似的迟疑依然普遍存在——这正是传统二维触控的体验天花板。…...

Bun用Claude自己“换心手术“?AI重构软件的新纪元来了
五月中旬的编程界上演了一出荒诞又魔幻的戏码——Bun,这个曾以 Zig 语言为傲的 JavaScript 运行时,在短短六天时间里,由被它拖累的 Claude AI 亲手把自己从 Zig 重写成 Rust 语言。事情得从两年前说起。2024年,Bun 创始人 Jarred …...

ARM PMSWINC寄存器解析与性能监控实践
1. ARM PMSWINC寄存器深度解析与性能监控实战在ARM架构的性能监控领域,PMSWINC(Performance Monitors Software Increment)寄存器是一个关键但常被忽视的组件。作为一位长期从事ARM平台性能调优的工程师,我将在本文中分享这个寄存…...

SK海力士晶圆代工战略:特色工艺如何重塑半导体产业格局
1. 韩国半导体雄心:从存储巨头到晶圆代工的野望最近几年,全球半导体产业的新闻头条几乎被台积电、英特尔和三星的千亿美元级投资计划所占据。然而,在2021年5月,一则来自韩国的消息,虽然声量相对较小,却揭示…...

青海黑独山|人间极致灰度,藏着西北水墨秘境
沿着青海省海西蒙古族藏族自治州冷湖镇西南方向行驶,一片被灰黑色山体包裹的荒原逐渐展开在视野中。这便是黑独山,一处以极简色彩和奇特地形著称的自然景观。不同于常见丹霞地貌的绚烂或雅丹地貌的雄浑,黑独山的主体由灰黑色砂石、岩层与少量…...