常见数据库分类介绍及其适用场景
一、引言
数据库是指在计算机系统中,为了结构化地管理和存储数据而建立起来的一种数据管理系统。它以高效、安全和可靠的方式存储和管理用户所需的各种数据,并提供了强大的数据处理和查询功能。随着信息技术的不断发展,数据库已经成为现代计算机系统中必不可少的核心组件之一。
数据库作为一个数据管理系统,有着多方面的重要性。首先,数据库大大提高了数据的利用价值和共享性。数据库中存储的数据可以被多个应用程序共享和使用,节省了大量的数据存储空间和数据管理成本。其次,数据库提供了强大的数据处理和查询功能,可以高效地完成数据分析、挖掘和处理等任务,为企业和个人的发展和决策提供有力的支持。此外,数据库也具有对数据的安全保护、并发控制和备份恢复等方面的重要作用,确保了数据的完整性和安全性。
正因为数据库在现代计算机系统中的重要作用,如配置、备份、优化、查询、同步等各类问题逐渐增多,导致了多个不同类型和性质的数据库类型的出现。在选择和使用数据库时,应根据应用场景的不同,选择适合的数据库类型,并合理规划和设计数据库结构和数据存储方案,以提高数据库的效率和可靠性。
二、关系型数据库
1. 定义和特点
关系型数据库是指以表(table)为基本的数据组织结构的数据库。它的特点是数据以行列的形式存储在表中,并且表之间通过主键(primary key)和外键(foreign key)关联。通过 SQL(Structured Query Language)对数据库进行读取、更新、插入、删除等操作,能够保证数据的一致性和安全性。
关系型数据库的主要特点包括:
- 数据以表的形式存储,表之间通过主键和外键关联;
- 数据具有完整性约束,保证数据的一致性和安全性;
- 支持 SQL,操作简单,易于学习和使用;
- 可以支持 ACID(原子性、一致性、隔离性、持久性)事务。
2. 常见的关系型数据库
常见的关系型数据库包括:
- MySQL:开源关系型数据库,拥有极高的性能、可靠性和扩展性,适合于各种 Web 应用、企业应用等场景。
- Oracle:功能非常强大的商业关系型数据库,广泛应用于重要的企业级应用、大型数据仓库等高端市场。
- SQL Server:微软推出的商业关系型数据库,作为企业信息化的核心数据库,主要应用在企业级应用、数据仓库、BI 分析等领域。
- PostgreSQL:开源关系型数据库,特点是稳定性、可扩展性和兼容性,适合于大型系统中使用。
3. 适用场景和优缺点
关系型数据库在各种 Web 和企业级应用中得到广泛应用。由于关系型数据库具有良好的数据完整性约束、安全性较高、面向大众的 SQL 操作等特点,所以其主要适用于以下场景:
- 高并发读写:支持 ACID 的事务保证了数据的一致性和可靠性,能够应对高并发读写的需求;
- 大规模数据存储:通过表结构的方式存储数据,适合于大规模数据存储和管理;
- 复杂的查询操作:通过 SQL 操作对数据进行复杂的查询和操作;
- 数据安全性要求高:通过完整性约束、存储过程等方式保证数据的安全性。
关系型数据库的优点主要包括:
- 数据完整性约束,保证数据的一致性;
- SQL 操作简单,易于学习和使用;
- 支持 ACID 事务,保证数据的可靠性;
- 错误修复和恢复方便。
缺点主要包括:
- 处理大规模数据存储的性能较差;
- 对并行处理的支持不足,不能很好地处理高并发量的请求;
- 缺乏面向文档和其他非结构化数据的支持。
关系型数据库适用于支持高并发读写、大规模数据存储以及安全性要求较高的场景。其优点包括数据完整性、SQL 操作和事务管理,缺点主要包括处理大规模数据存储和并行处理能力较弱。
三、非关系型数据库
1. 定义和特点
非关系型数据库是以键值对(key-value)为基本存储结构的数据库,也被称为 NoSQL(Not Only SQL)。与关系型数据库不同,非关系型数据库具有高度的可扩展性,良好的性能和灵活的数据结构,能够有效地应对海量数据和高并发访问的需求。
非关系型数据库的主要特点包括:
- 数据以键值对的形式存储,没有固定的数据结构和数据模式;
- 支持多种数据类型,包括文档、键值对、图、列族等;
- 能够支持高水平的可扩展性和卓越的性能;
- 支持分布式部署,且支持数据的自动分片和负载均衡。
2. 常见的非关系型数据库
常见的非关系型数据库包括:
- MongoDB:文档型数据库,支持 Json 数据格式,拥有高度灵活的数据结构和丰富的查询语句,广泛应用于 Web 应用、大型数据分析等场景。
- Cassandra:列族型数据库,拥有高度的可扩展性和多节点支持,特别适合于互联网应用、物联网数据等海量存储场景。
- Redis:键值对型数据库,支持多种数据类型和高并发操作,具有高性能的缓存和消息队列等功能,广泛应用于 Web 应用、分布式缓存等场景。
- Memcached:键值对型数据库,特别适合于分布式缓存、会话管理等场景。
3. 适用场景和优缺点
非关系型数据库主要适用于以下场景:
- 高读写负载:具有卓越的性能和可扩展性,能够应对高并发的读写负载;
- 高度灵活的数据需求:支持多种数据类型和无模式的数据结构,适用于各种数据领域和处理方式;
- 分布式的部署模式:能够方便地实现数据的分片和负载均衡,适用于云计算、大型分布式系统等场景;
- 海量数据存储:能够高效地存储并处理海量的数据,适用于物联网数据、大型数据分析等领域。
非关系型数据库的优点主要包括:
- 高度的可扩展性和灵活性,能够适应各种数据领域和处理方式;
- 卓越的性能,能够应对高并发和大量的数据访问;
- 分布式的部署模式和支持自动分片和负载均衡。
缺点主要包括:
- 数据库之间的数据互操作性不强,缺少通用性;
- 缺乏标准化的 SQL 语言,在处理复杂查询等方面不如关系型数据库。
非关系型数据库适用于海量数据存储和高并发读写等场景。其优点包括高度的可扩展性、灵活性和卓越的性能,缺点主要体现在缺少通用性和不如关系型数据库在处理复杂查询等方面的优势。
四、列存储数据库
1. 定义和特点
列存储数据库是一种建立在列的基础上存储数据的数据库,也被称为列式数据库。与关系型和非关系型数据库不同,列存储数据库以列(column)为基本的存储和组织单位,能够有效地解决大规模数据存储和处理过程中的瓶颈问题,具有高度的可扩展性和卓越的性能。
列存储数据库的主要特点包括:
- 数据以列的形式存储,相同列的数据在磁盘上存储在一起,提高了存储的效率;
- 通过类似 MapReduce 的方式对数据进行并行处理,能够应对海量数据存储和查询;
- 灵活的架构,能够支持多种操作,如全文搜索、复杂查询、数据分析等。
2. 常见的列存储数据库
常见的列存储数据库包括:
- HBase:开源的列式数据库,建立在 Apache Hadoop 上,主要应用于对大规模分布式数据集的读写操作;
- C-Store:由麻省理工大学开发的列式数据库,拥有高度的可扩展性和并行处理能力,具有较好的查询性能;
- Vertica:商业的列式数据库,拥有强大的查询优化技术和数据压缩技术,适合于大型企业数据仓库系统;
- InfoBright:通过数据压缩和并行处理能力,支持大规模数据的实时分析,适用于数据分析场景。
3. 适用场景和优缺点
列存储数据库主要适用于以下场景:
- 大规模数据存储和查询:能够支持海量数据的存储和查询,并具有极高的可扩展性和并行处理能力;
- 多种操作需求:能够实现全文搜索、复杂查询、数据分析等多种操作;
- 分布式环境:能够在分布式环境下部署和管理数据。
列存储数据库的优点主要包括:
- 灵活的数据架构和多种操作能力,能够满足多种复杂的数据存储和处理需求;
- 卓越的性能和可扩展性,能够应对大规模数据存储和查询的需求。
缺点主要包括:
- 较高的维护成本和学习成本;
- 在处理小规模数据时,性能可能不如传统关系型数据库。
列存储数据库适用于大规模数据存储和查询场景,具有灵活的架构和多种操作能力。其优点主要包括性能和可扩展性,缺点在于较高的维护成本和学习成本。
五、面向对象数据库
1. 定义和特点
面向对象数据库是指将面向对象技术应用于数据库系统中,建立在对象模型(Object Model)上的数据库。与传统数据库不同,面向对象数据库能够以对象的方式存储和处理数据,支持面向对象的语义和模型,具有更高的灵活性和更好的数据封装和隐藏能力。
面向对象数据库的主要特点包括:
- 数据被组织和封装为对象,具有面向对象编程的继承、聚合、多态等特性;
- 能够支持复杂的数据结构,如集合、数组、图等;
- 支持对象的持久化存储和加载,能够实现面向对象的程序和数据库的无缝集成。
2. 常见的面向对象数据库
常见的面向对象数据库包括:
- db4o:开源的面向对象数据库,特点是高速、无需 SQL 等操作;
- Versant:商业面向对象数据库,拥有强大的数据组织、存储能力和高度的可伸缩性,主要应用于数据驱动的应用和系统;
- Objectivity/DB:面向对象数据库的商业系统,拥有高度灵活的数据结构和对象关系管理能力。
3. 适用场景和优缺点
面向对象数据库主要适用于以下场景:
- 复杂的数据结构和操作:能够处理各种对象之间的复杂关系,并实现复杂的对象操作,适用于嵌入式系统、工程模型等领域;
- 对象模型的持久化:面向对象数据库能够将面向对象模型的程序和数据库进行无缝的集成;
- 高度灵活的数据模型:支持灵活的数据模型和面向对象的语义,便于开发人员进行编程。
面向对象数据库的优点主要包括:
- 能够以面向对象的方式处理和组织数据;
- 与面向对象程序语言的集成良好,能够方便地完成对象的持久化存储;
- 支持高度灵活的数据模型和面向对象的语义。
缺点主要包括:
- 学习和使用的门槛较高;
- 性能可能不如传统的关系型数据库。
面向对象数据库适用于处理复杂的数据结构和操作、对象模型的持久化等场景。其优点主要包括面向对象处理数据和集成的优势,缺点在于学习和使用门槛较高,性能不如传统关系型数据库。
六、图数据库
1. 定义和特点
图数据库是以图(Graph)为数据组织结构的数据库,它将数据存储为节点(Node)和边(Edge)组成的图形结构。与关系型和非关系型数据库不同,图数据库具有更好的图形结构处理能力,能够快速处理各种图形结构和数据关联。
图数据库的主要特点包括:
- 数据以节点和边的形式存储,拥有丰富的图形结构处理能力;
- 能够支持图形查询语言(如 Cypher),实现灵活的查询操作;
- 能够处理复杂的数据和数据关联结构,如社交网络、地理信息系统、网络拓扑等数据结构;
- 支持高度可扩展性和并行处理能力。
2. 常见的图数据库
常见的图数据库包括:
- Neo4j:开源的图数据库,采用类似 SQL 的查询语言 Cypher,能够支持高度灵活的图形结构操作和查询;
- FlockDB:Twitter 开源的图数据库,能够高效地处理社交网络中的关系数据;
- InfoGrid:开源的图数据库,可扩展支持复杂的数据结构和关联,具有高度的灵活性和性能;
- HypergraphDB:具有高度并发性和扩展性,支持复杂的数据结构和操作,适用于多种数据领域。
3. 适用场景和优缺点
图数据库主要适用于以下场景:
- 处理复杂的数据关联结构:由于图数据库能够高效地处理节点和边之间的关联关系,适用于处理复杂的社交网络、地理信息系统、网络拓扑等数据结构;
- 解决特定问题:能够通过数据和关联关系的图形结构快速定位和解决一些特定问题;
- 处理分布式数据:适用于分布式环境下的数据存储和处理。
图数据库的优点主要包括:
- 能够处理复杂的数据和数据关联结构;
- 支持高度灵活的图形查询语言(如 Cypher);
- 具有高度的可扩展性和并行处理能力。
缺点主要包括:
- 不适用于处理结构简单的无关系数据;
- 在处理大型数据和查询复合图结构时,性能可能会受到影响。
综上所述,图数据库适用于处理复杂的数据关联结构、解决特定问题和处理分布式数据场景。其优点包括高度的灵活性、表达并查询能力、可扩展性和并行处理能力,缺点主要在于不适用于处理结构简单的无关系数据,并且在处理大型数据和复合图结构时性能可能会受到影响。
七、总结
随着数据存储和处理技术的发展,数据库类型也变得越来越多样化。不同类型的数据库具有各自的优点和缺点,需要根据实际应用场景选择适合的数据库类型。以下是各种数据库类型的优缺点总结,供读者参考:
1. 关系型数据库
优点:
- 具有固定的数据结构和数据模式,处理关系型数据的效率较高;
- 支持强大的事务管理和数据一致性;
- 模型和 SQL 语言较为通用,易于学习和使用。
缺点:
- 不适用于存储非结构化或半结构化数据;
- 扩展性和性能受到限制,在高并发的环境下可能会遇到瓶颈。
2. 非关系型数据库
优点:
- 能够存储非结构化或半结构化数据;
- 具有高可扩展性和卓越的性能;
- 支持多种数据类型和数据结构;
- 在分布式环境下易于部署和管理。
缺点:
- 不支持 SQL 查询语言;
- 数据库之间的数据互操作性不强,缺少通用性。
3. 列存储数据库
优点:
- 具有高度的可扩展性和并行处理能力;
- 能够处理大规模数据存储和查询;
- 对于特定的查询非常高效。
缺点:
- 维护成本和学习成本较高。
4. 面向对象数据库
优点:
- 能够以面向对象的方式处理和组织数据;
- 与面向对象程序语言的集成良好,能够方便地完成对象的持久化存储;
- 支持高度灵活的数据模型和面向对象的语义。
缺点:
- 学习和使用的门槛较高;
- 性能可能不如传统关系型数据库。
5. 图数据库
优点:
- 能够处理复杂的数据和数据关联结构;
- 支持高度灵活的图形查询语言;
- 具有高度的可扩展性和并行处理能力。
缺点:
- 不适用于处理结构简单的无关系数据;
- 在处理大型数据和复合图结构时性能可能会受到影响。
选择适合的数据库类型需要根据实际应用场景和需求进行综合考虑。关系型数据库适用于处理关系型数据、强一致性和事务管理,适合于银行、金融、物流等领域;非关系型数据库适用于存储大量非结构化数据、高并发访问、分布式系统等领域;列存储数据库适用于大规模数据存储和查询、特定查询等领域;面向对象数据库适用于处理复杂对象数据、对象模型的持久化等领域;图数据库适用于处理复杂的数据关联结构、解决特定问题和处理分布式数据场景等领域。
八、参考资料
以下是本文参考的一些相关文献,供读者进一步深入学习:
1. 《MySQL 必知必会》(第4版),作者:Ben Forta,译者:齐波等,电子工业出版社,2016年。
2. 《MongoDB 实战》(第2版),作者:Kyle Banker等,译者:王峰等,机械工业出版社,2018年。
3. 《Hadoop 权威指南》(第4版),作者:Tom White,译者:李铁军等,人民邮电出版社,2016年。
4. 《Redis 实战》(第2版),作者:Josiah L. Carlson,译者:王磊等,人民邮电出版社,2019年。
5. 《Cassandra 权威指南》(第2版),作者:Jeff Carpenter等,译者:李凯,电子工业出版社,2019年。
6. 《图数据库》(第1版),作者:Emil Eifrem等,译者:李布斯,机械工业出版社,2016年。
7. 《面向对象数据库系统》(第2版),作者:C. S. R. Prabhu,清华大学出版社,2014年。
除此之外,一些相关的官方文档,如 MySQL 官方文档、Oracle 官方文档、MongoDB 官方文档等,也是学习数据库技术的重要资料。
相关文章:

常见数据库分类介绍及其适用场景
一、引言 数据库是指在计算机系统中,为了结构化地管理和存储数据而建立起来的一种数据管理系统。它以高效、安全和可靠的方式存储和管理用户所需的各种数据,并提供了强大的数据处理和查询功能。随着信息技术的不断发展,数据库已经成为现代计…...
)
周末总结(2024/03/30)
工作 接受破烂现状,改变状态 上周一周的工作都感觉是摸鱼状态,每天只有三个小时左右的时间聚焦在工作上,其他时间都在胡思乱想。但是我发现可以在工作中学习和下班相关的技术栈。我无意改变自己的工作状态,只想在5月底找好下家然后…...
爬楼梯)
(75)爬楼梯
文章目录 1. 每日一言2. 题目2.1 解题思路2.1.1 递归2.1.2 记忆化搜索2.1.3 动态规划2.1.4 动态规划空间优化 2.2 代码2.2.1 递归2.2.2 记忆化搜索2.2.3 动态规划2.2.4 动态规划空间优化 3. 结语 1. 每日一言 Happy life lies in a peaceful mind. 幸福的生活存在于心绪的宁静…...
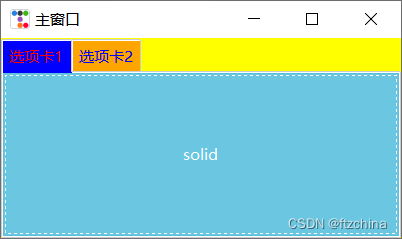
ttkbootstrap界面美化系列之Notebook(四)
在简单的界面设计中,Notebook也是常用的组件之一,Notebook组件的引入可以根据标签来切换不同的界面。使得界面更有层次感,不必都挤在一个界面上。在tkinter中就有Notebook组件,在ttkbootstrap中,同样也对Notebook进行了…...

MySQL8存储过程整合springboot
注意:调用使用mybatis-plus3形式调用,可能会有些区别 1. 创建存储过程 -- -- 生成员工工号的存储过程 DELIMITER $$ CREATE PROCEDURE generate_employee_number(OUT employeeNumber VARCHAR(20)) -- 解释 out 一个返回值 BEGINDECLARE prefix VARCHAR…...

Acwing 1238.日志统计 双指针
小明维护着一个程序员论坛。现在他收集了一份”点赞”日志,日志共有 N� 行。 其中每一行的格式是: ts id 表示在 ts 时刻编号 id 的帖子收到一个”赞”。 现在小明想统计有哪些帖子曾经是”热帖”。 如果一个帖子曾在任意一个长度为 D 的…...

Matlab-R2022b-安装文件分享
一、MATLAB主要特点和功能 MATLAB是一款强大的科学计算软件,专门用于算法开发、数据分析、数值计算以及科学数据可视化。 以下是一些MATLAB的主要特点和功能: 1.矩阵运算: MATLAB的名字来源于"Matrix Laboratory"(矩阵实验室&…...

Flutter开发之objectbox
Flutter开发之objectbox 在之前进行iOS开发的时候使用WCDB去进行管理数据库很方便,它支持ORM(Object-Relational Mapping,对象关系映射),用于实现面向对象编程语言里不同类型系统的数据之间的转换。 那么在Flutter开发…...
)
AI Drug Discovery Design(学习路线)
AIDD,即AI Drug Discovery & Design,是近年来非常火热的技术应用,已经介入到新药设计到研发的大部分环节当中,为新药发现与开发带来了极大的助力。其学习路线涉及多个学科和领域的知识。以下是一个可能的AIDD学习路线…...

【软考】设计模式之状态模式
目录 1. 说明2. 应用场景3. 结构图4. 构成5. 优缺点5.1 优点5.2 缺点 6. java示例6.1 非状态模式6.1.1 问题分析6.1.2 接口类6.1.2 实现类6.1.3 客户端6.1.4 结果截图 6.2 状态模式6.2.1 抽象状态类6.2.2 状态类6.2.3 上下文类6.2.4 上下文类 1. 说明 1.允许一个对象在其内部状…...

MNN介绍、安装与编译:移动端深度学习推理引擎
MNN介绍、安装与编译:移动端深度学习推理引擎 引言第一部分:MNN简介第二部分:MNN的安装第三部分:MNN的编译结语 引言 大家好,这里是程序猿代码之路。在移动设备上实现高效的深度学习模型推理一直是人工智能领域的一个挑…...
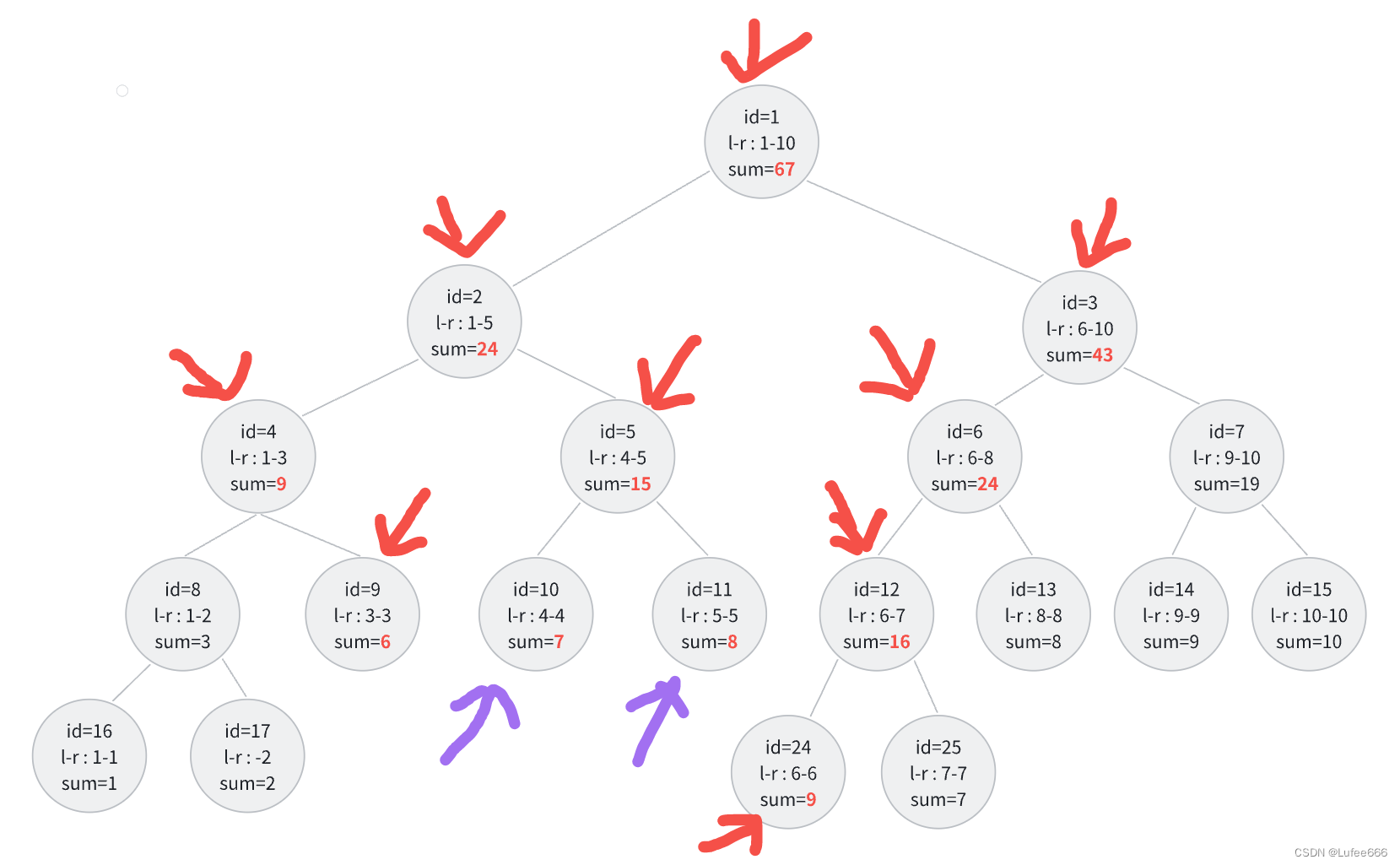
A Simple Problem with Integers(线段树)
目录 描述 输入 输出 样例输入 样例输出 思路 建树 第一次错误解法(正确解法在下面,可跳过这一步) 正确解法 code 描述 You have N integers, A1, A2, ... , AN. You need to deal with two kinds of operations. One type of …...
用例简介)
单元测试(UT)用例简介
单元测试(Unit Testing, UT)用例是一系列预先设计好的、针对软件最小可测试单元的测试场景。每一个单元测试用例都是为了验证一个独立代码单元(如函数、方法、类)的行为是否符合预期。这些用例通常包含以下几个关键组成部分&#…...

Java通过反射机制获取类对象下的属性值
目录 以类USER为例: 使用Java的反射机制获取Column的name为“user_name”的类属性值 以类USER为例: import lombok.Data; import javax.persistence.*; import java.io.Serializable;Data Table(name "user_info") public class User imple…...

IDEA插件开发-File -> New->Project中添加一个myOptions
写一个IDEA插件,在IDEA的File -> New -> Project 中添加一个选项myOptions ,点击myOptions 后弹出一个提示对话框:被点击了 为了在IntelliJ IDEA中创建一个插件,您需要遵循一系列的步骤来开发和集成您的功能。下面是一个简化的指南&am…...
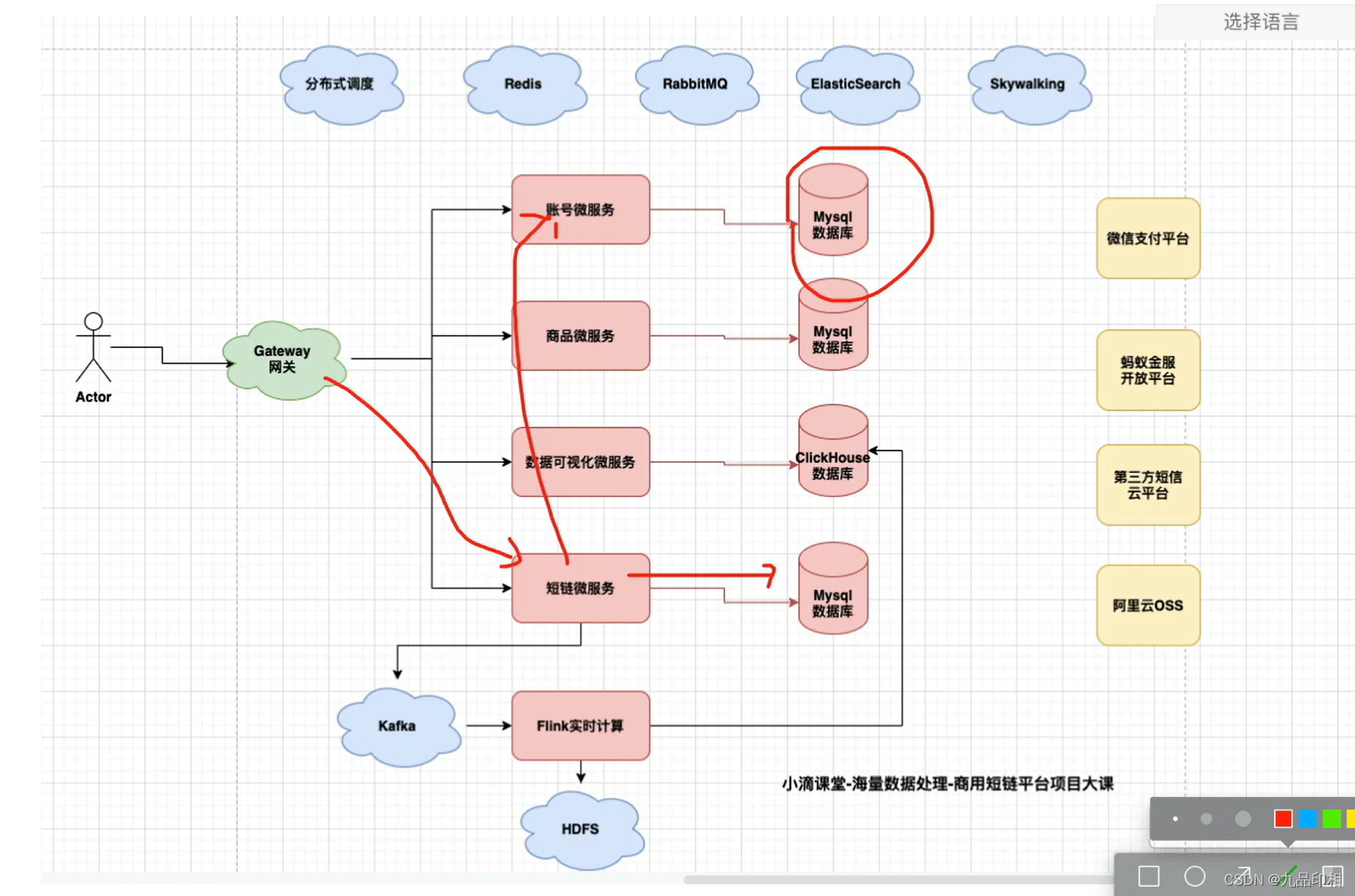
海量数据处理项目-账号微服务和流量包数据库表+索引规范(下)
海量数据处理项目-账号微服务和流量包数据库表索引规范(下) 第2集 账号微服务和流量包数据库表索引规范讲解《下》 简介:账号微服务和流量包数据库表索引规范讲解 账号和流量包的关系:一对多traffic流量包表思考点 海量数据下每…...
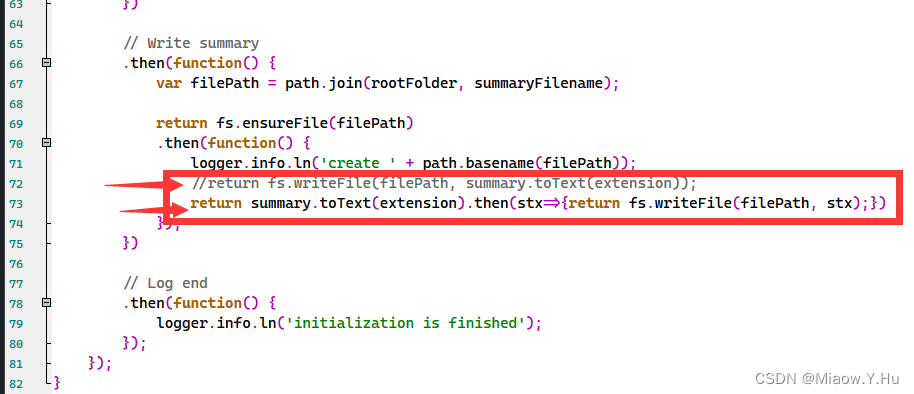
Nodejs 16与 gitbook搭建属于你自己的书本网站-第一篇
最近想重新搭建一个网站来存放自己的相关知识点,并向网络公开,有个hexo博客其实也不错的,但是总感觉hexo很多花里胡哨的玩意,导致挂载的博客异常卡,这样反而不利于我自己回顾博客了,于是我就开始钻研这个鬼…...

服务器被CC攻击之后怎么办?
1.取消域名绑定取消域名绑定后Web服务器的CPU能够马上恢复正常状态,通过IP进行访问连接一切正常。但是不足之处也很明显,取消或者更改域名对于别人的访问带来了不变,另外,对于针对IP的CC攻击它是无效的,就算更换域名攻…...

pygame通过重心坐标 用纹理填充三角形
texture_x int(alpha * texture_image.get_width()) texture_y int(beta * texture_image.get_height())为什么没有gama 2024/3/30 15:45:52 在使用重心坐标进行纹理映射时,通常是通过计算 alpha 和 beta 来确定纹理图片上的对应位置,而 gamma 通常是…...

Leetcode 611. 有效三角形的个数
给定一个包含非负整数的数组 nums ,返回其中可以组成三角形三条边的三元组个数。 示例 1: 输入: nums [2,2,3,4] 输出: 3 解释:有效的组合是: 2,3,4 (使用第一个 2) 2,3,4 (使用第二个 2) 2,2,3 示例 2: 输入: nums [4,2,3,4] 输出: 4 提示: 1 < nums.len…...

Zotero中文文献管理终极指南:三步彻底解决知网PDF元数据抓取难题
Zotero中文文献管理终极指南:三步彻底解决知网PDF元数据抓取难题 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 你是…...

3步掌握NBTExplorer:从Minecraft数据恐惧到编辑专家的完整指南
3步掌握NBTExplorer:从Minecraft数据恐惧到编辑专家的完整指南 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft的level.dat文件…...

LocalChat:零门槛本地部署开源大语言模型,实现隐私安全的离线AI对话
1. 项目概述与核心价值如果你和我一样,对ChatGPT这类大语言模型的能力感到兴奋,但又对数据隐私、服务依赖和网络延迟心存顾虑,那么LocalChat这个项目可能就是为你量身打造的。简单来说,LocalChat是一个让你能在自己电脑上…...

Flutter for OpenHarmony学习资料搜索与PDF阅读器技术文章
Flutter for OpenHarmony学习资料搜索与PDF阅读器技术文章 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 🚀 Flutter for OpenHarmony 学习资料搜索与 PDF 阅读器开发实战 大家好!今天带大家从零开始打造一款专…...

3分钟极速攻略:ctfileGet如何一键破解城通网盘下载限速
3分钟极速攻略:ctfileGet如何一键破解城通网盘下载限速 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否曾因城通网盘的低速下载而焦虑?面对大文件的漫长等待和频繁验证码&…...

Ctool架构深度解析:模块化开发工具集的高效实现方案
Ctool架构深度解析:模块化开发工具集的高效实现方案 【免费下载链接】Ctool 程序开发常用工具 chrome / edge / firefox / utools / windows / linux / mac 项目地址: https://gitcode.com/gh_mirrors/ct/Ctool 在程序开发过程中,开发者经常需要在…...

RISC-V汽车电子开发:功能安全认证工具链的挑战与实践
1. 项目概述:RISC-V在汽车领域的破局与挑战最近和几个在主机厂和Tier 1做嵌入式开发的老朋友聊天,话题总绕不开芯片选型和开发工具。大家普遍的感觉是,传统的Arm架构虽然生态成熟,但在追求极致能效比和定制化的今天,成…...

NVIDIA显卡终极调校指南:用Profile Inspector释放游戏潜能的简单方法
NVIDIA显卡终极调校指南:用Profile Inspector释放游戏潜能的简单方法 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 还在为游戏卡顿、画面撕裂而烦恼吗?NVIDIA Profile Inspect…...

你的密码正在裸奔!一张RTX 5090,1小时破解60%的MD5密码
网络安全文章 文章目录 网络安全文章前言一、卡巴斯基到底做了什么?1.1 测试环境1.2 测试结果 二、为什么MD5这么脆弱?2.1 MD5设计初衷就不是用来存密码的2.2 MD5 vs bcrypt vs Argon2 对比 三、真实案例:算力平台租卡破解有多便宜࿱…...

windows系统安装wsl安装opencode教程
使用 AI 助手(OpenCode)在 WSL2 中高效安全工作教程 背景 在 AI 极大发展的现在,AI 可以帮助我们完成很多工作。那么怎么让 AI 帮我们高效、安全地工作呢?以下是教程。 同时,大模型在 Windows 里面直接执行脚本时错…...