ElasticSearch、java的四大内置函数式接口、Stream流、parallelStream背后的技术、Optional类
第四周笔记
一、ElasticSearch
1.安装
apt-get install lrzsz
adduser -m es
创建用户组:
useradd *-m* xiaoming(用户名) *PS:追加参数-m*
passwd xiaoming(用户名)
passwd xiaoming
输入新的 UNIX 密码:
重新输入新的 UNIX 密码:
passwd:已成功更新密码
最大文件描述符数(max file descriptors)太低,需要增加至少到65535。
ulimit -Hn 65536
ulimit -Hn
最大虚拟内存区域数(max virtual memory areas)过低,需要增加至少到262144。
-
使用root权限登录到Elasticsearch所在的服务器。
-
打开sysctl.conf文件,可以使用vim或者nano等文本编辑器打开:
复制代码sudo vim /etc/sysctl.conf -
在文件末尾添加以下内容:
复制代码vm.max_map_count=262144 -
保存并关闭文件。
-
执行以下命令使配置生效:
复制代码sudo sysctl -p -
重新启动Elasticsearch:
复制代码/path/to/elasticsearch/bin/elasticsearch
curl -O 路径下载文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
sudo yum install lrzsz
压缩:
tar -zcvf 文件名 压缩路径
解压:
tar -zxvf 文件名
sudo mkdir -p /root/es/elasticsearch-7.9.3/log
sudo yum install vim
sudo chown -R qingyue:qingyue /usr/local/es/elasticsearch-7.9.3/
[超详细的ElasticSearch安装使用教程视频_哔哩哔哩_bilibili
新增PUT
PUT新增索引,已存在会报错(幂等)
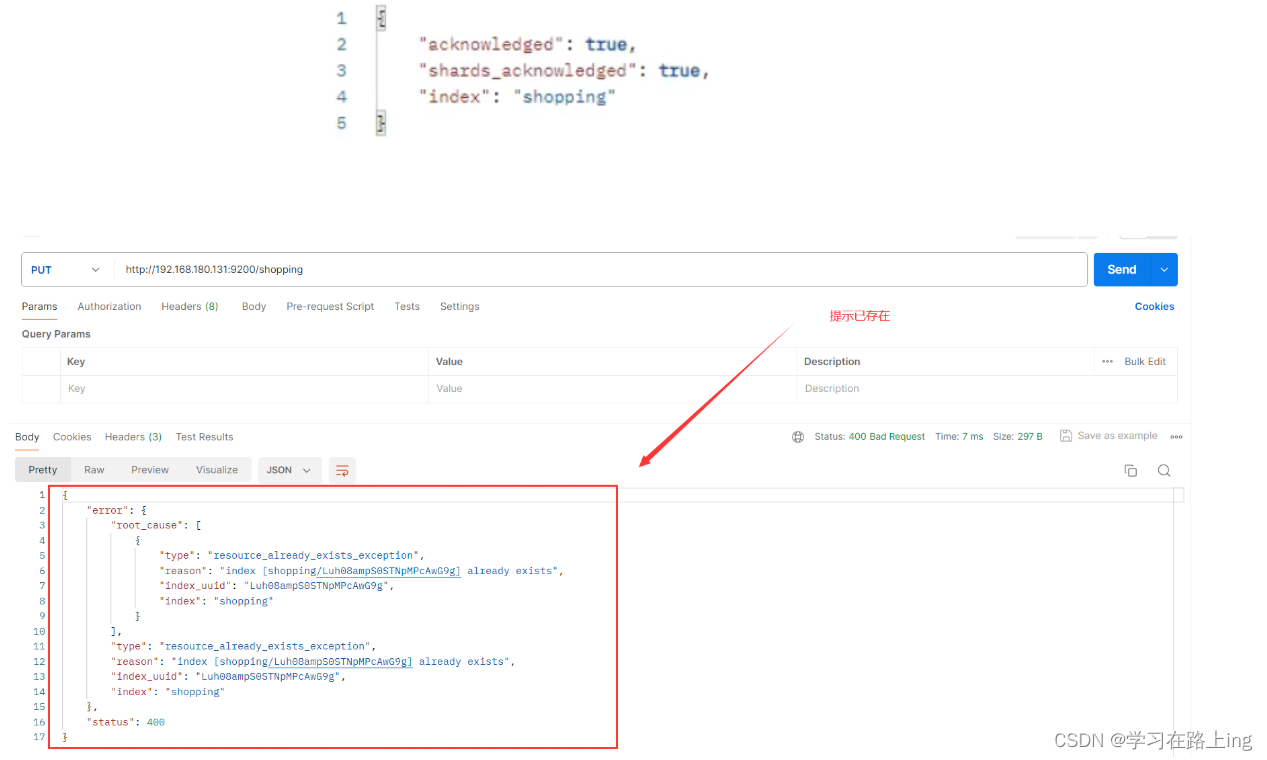
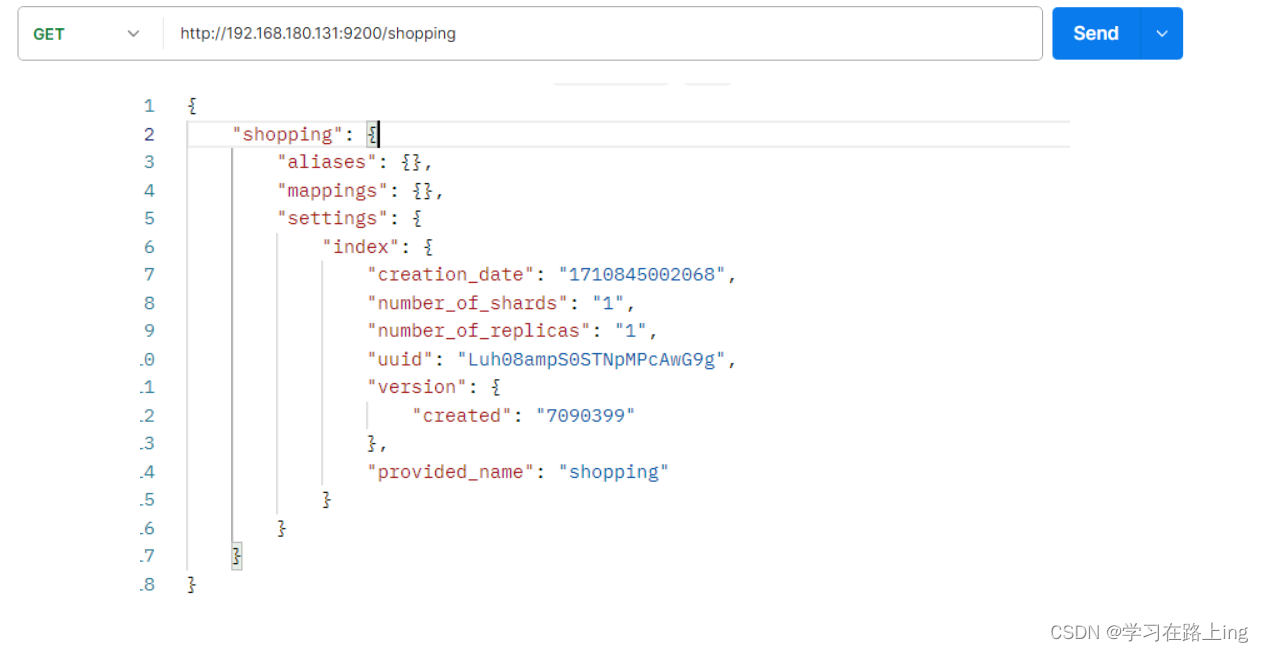
查询GET
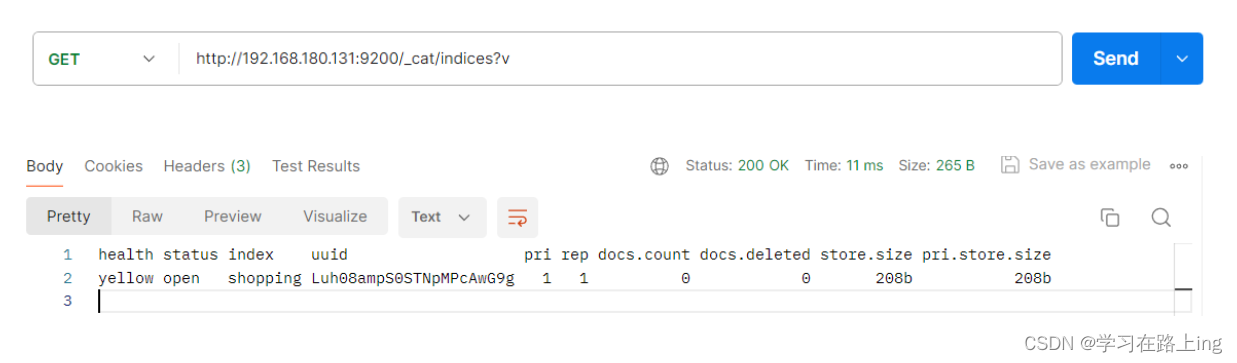
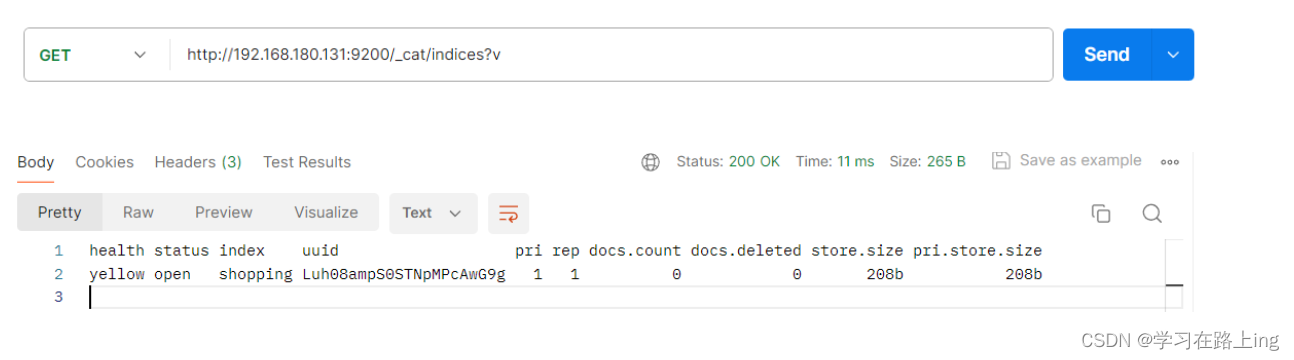
查询全部索引
POST
文档的创建
不指定id
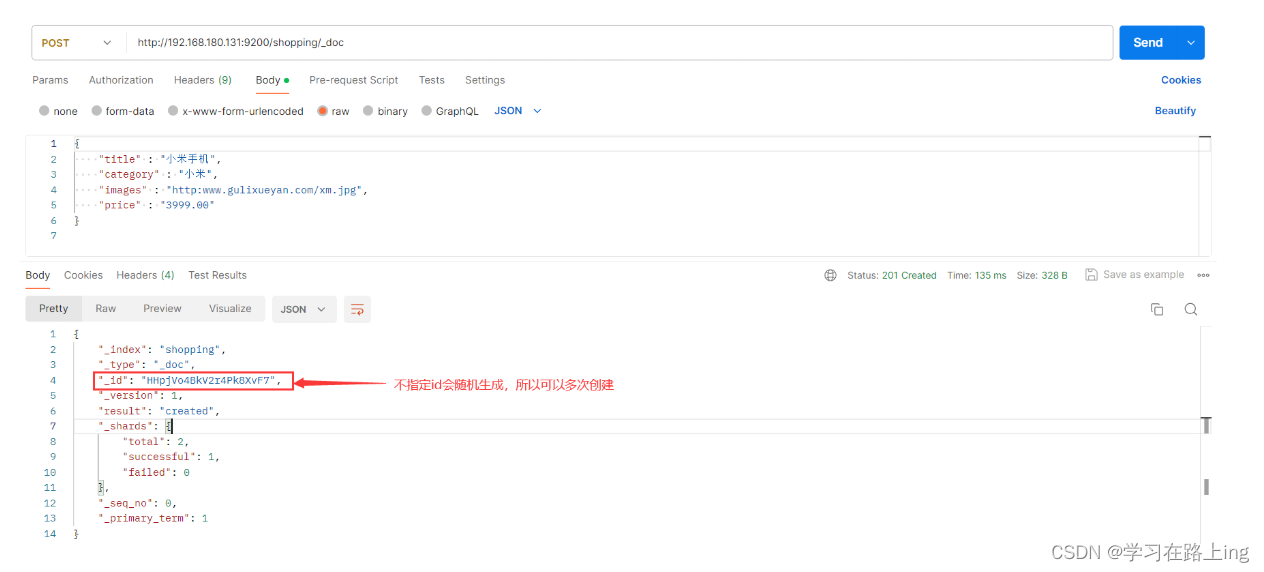
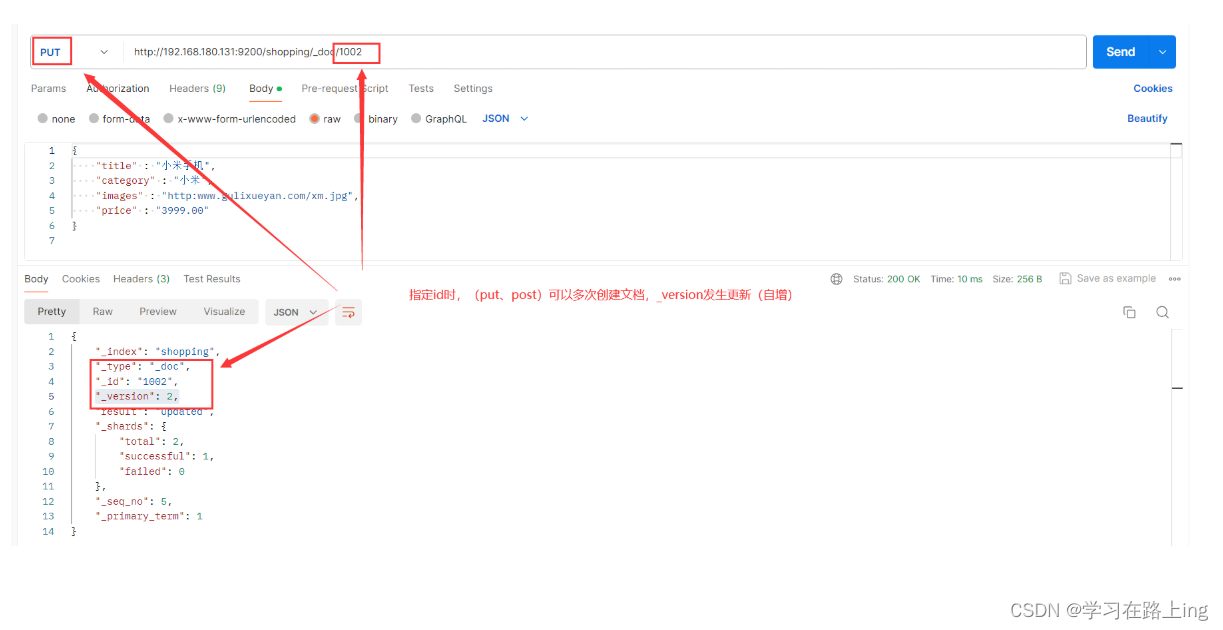
指定id

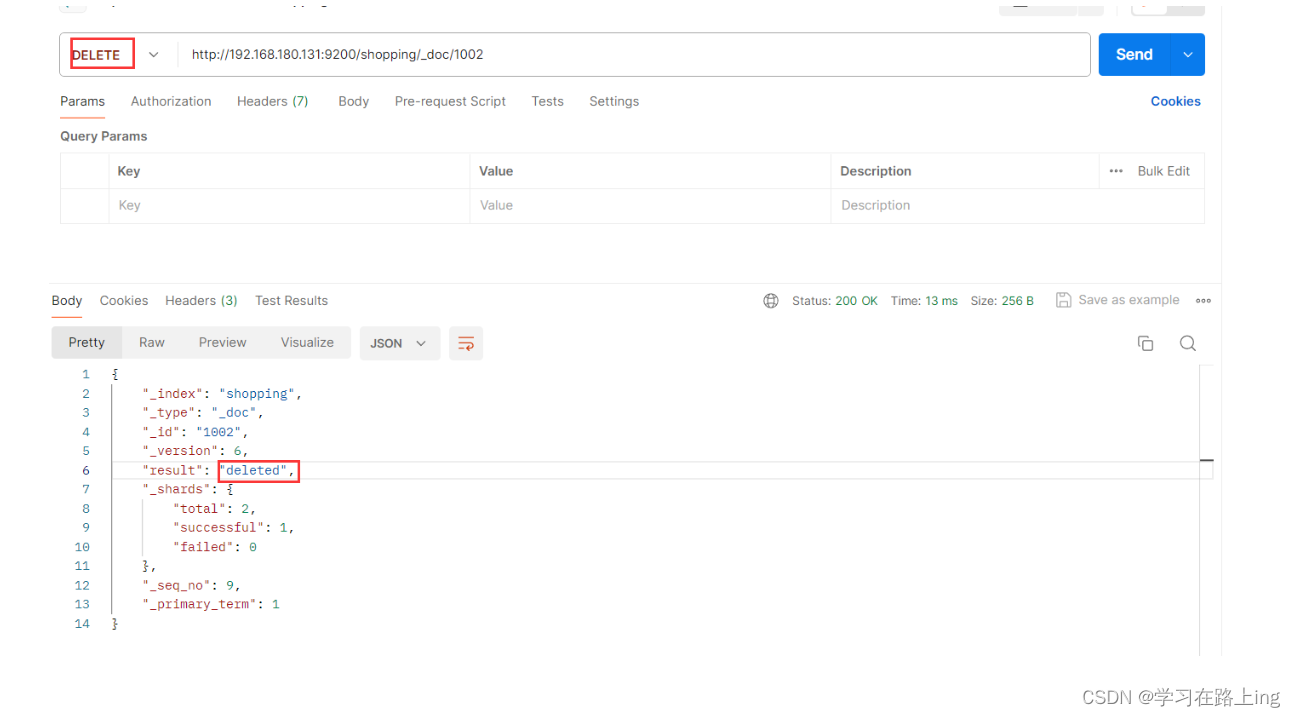
删除
二、java的四大内置函数式接口
1、Supplier(生产型接口)
Supplier:这是一个不接受任何参数并产生一个结果的函数。泛型类型 T 是返回结果的类型。例如,你可以使用 Supplier 接口来生成一个随机数:
1.1、get()方法
1.1.1示例:
package supplierTest;import java.util.function.Supplier;/*常用的函数式接口java.util.fuction.Supplier<T>接口仅包含一个无参的方法:T get();用来获取一个泛型参数指定类型的对象数据Supplier<T>接口被称之为生产型接口,泛型执行String,get方法就会返回一个String*/
public class SupplierTest {// 定义一个方法,方法的参数传毒Supplier<T>接口,泛型执行String,get方法就会返回一个String;public static String getString(Supplier<String> supplier) {return supplier.get();}public static void main(String[] args) {// 调用getString方法,方法的参数Supplier是一个函数式接口,所以可以传递Lambda表达式;String str1 = getString(() -> {return "hello";});System.out.println(str1);// 优化Lambda表达式(只有一条语句,可以省略{},又是return语句,可以省略return)String str = getString(() -> "Hello");System.out.println(str);}
}1.1.2练习
package supplierTest;import java.util.function.Supplier;public class SupplierTest2 {public static Integer getMax(Supplier<Integer> supplier) {return supplier.get();}public static void main(String[] args) {int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};int max = getMax(() -> {int maxNum = arr[1];for (int i = 0; i < arr.length; i++) {if (arr[i] > maxNum) {maxNum = arr[i];}}return maxNum;});System.out.println(max);}
}2、Consumer(消费型接口)
这是一个接受一个参数并返回 void 的函数。泛型类型 T 是输入参数的类型。例如,你可以使用 Consumer 接口来打印一个字符串:
1.1、appect()方法
package ConsumerTest;import java.util.function.Consumer;/*java.util.functional.Consumer<T> 接口则正好与Supplier接口相反,它是不是生产一个数据,而是消费一个数据,其数据类型有泛型决定Consumer接口中包含抽象发放void accept(T t),意为消费一个指定泛型的数据。Consumer接口是一个消费型接口,泛型执行什么类型,就可以使用accept方法消费什么类型的数据,治愈具体则呢么消费(使用),需要自定义(输出,计算......)*/
public class ConsumerTest1 {/** 定义一个方法* 方法的参数传递一个字符串的姓名* 方法的参数传递Consumer接口,泛型使用String* 可以使用Consumer接口消费字符串的姓名** */public static void method(String name, Consumer<String> consumer) {consumer.accept(name);}public static void main(String[] args) {method("hahah", (String name) -> {System.out.println(name);});method("hahah", (String name) -> {// 调用StringBuffer的reverse方法,将字符串反转String reName = new StringBuffer(name).reverse().toString();System.out.println(reName);});}}1.2 andThen方法示例
package ConsumerTest;import java.util.function.Consumer;/** Consumer接口的默认方法andThen()* 作用:需要两个Consumer接口,可以把连个Consumer接口组合到一起,再对数据解析消费* 例如:* Consumer<String> consumer1;* Consumer<String> consumer2;* String s = "hello world";* consumer1.accpet(s);* consumer2.accpet(s);** consumer.andThen(consumer2).accept(s);谁在前谁先消费* */
public class AndThenTest {// 定义一个方法,方法的参数传递一个字符串和两个Consumer接口,Consumer接口的泛型使用字符串public static void method(String s, Consumer<String> con1, Consumer<String> con2) {
// con1.accept(s);
// con2.accept(s);// 使用adnThen()方法,把两个Consumer接口组合到一起,再对数据解析消费con1.andThen(con2).accept(s);}public static void main(String[] args) {// 调用method方法,传递一个字符串,两个Lamnbda表达式method("hello",(t) -> {System.out.println(t.toUpperCase());},(t) -> {System.out.println(t.toLowerCase());});}}
1.3 andThen方法练习
package ConsumerTest;import java.util.function.Consumer;public class AndThenTest2 {// 定义一个方法,参数传递String类型的数组和两个Consumer接口,泛型用Stringpublic static void printInfo(String[] arr, Consumer<String> consumer1, Consumer<String> consumer2) {for (String s : arr) {consumer1.andThen(consumer2).accept(s);}}public static void main(String[] args) {String[] arr = {"迪丽热巴,女", "古力娜扎,女", "马尔扎哈,男"};printInfo(arr, (message) -> {String name = message.split(",")[0];System.out.println("姓名:"+ name);}, (message) -> {String sex = message.split(",")[1];System.out.println("性别:"+sex);});}
}
3、Predicate(断言型接口)
这是一个接受一个参数并返回一个布尔值的函数。泛型类型 T 是输入参数的类型。例如,你可以使用 Predicate 接口来检查一个字符串是否为空:
1.1、test() 方法
package PreicateTest;import java.util.function.Predicate;/** java.util.fuction.Predicate<T>接口 判断性接口* 作用:对某种数据类型的数据进行判断,结果返回一个Boolean类型** Predicate接口中包含一个抽象发放:* boolean test(T t):用来指定数据类型进行判断的方法* 结果:* 符合条件返回true,否则返回false** */
public class PredicateTest {/** 定义一个方法* 参数传一个String类型的字符串* 传递与一个Predicate接口,泛型使用String* 使用Predicate中的方法test对字符串进行判断,并返回判断的结果返回* */public static Boolean chekString(String s, Predicate<String> predicate) {return predicate.test(s);}public static void main(String[] args) {String s = "hello";Boolean a = chekString(s, (message) -> message.length() > 5);System.out.println(a);}
}1.2、and() 方法
package PreicateTest;import java.util.function.Predicate;/** 逻辑表达式:可以连接多个判断的条件* && : 与* || : 或* ! : 非(取反)** Predicate方法中的默认方法and,表示并且关系,可以用于连接两个判断条件** */
public class PredicateAndTest {/* 需求:判断一个字符串,有两个判断条件* 1.判断字符串的长度是否大于5* 2.判断字符串中是否包含a* 两个条件必须同时满足* */public static Boolean chekPredicateString(String s, Predicate<String> predicate, Predicate<String> predicate2) {
// return predicate.test(s) && predicate2.test(s);return predicate.and(predicate2).test(s);}public static void main(String[] args) {String s = "hello";boolean a = chekPredicateString(s, (message) -> message.length() > 5,(message) -> message.contains("a"));System.out.println(a);}}
1.3 or() 方法
package PreicateTest;import java.util.function.Predicate;/* 需求:判断一个字符串,有两个判断条件* 1.判断字符串的长度是否大于5* 2.判断字符串中是否包含a* 两个条件有一个满足** Predicate方法中的默认方法or,表示或关系,可以用于连接两个判断条件* */
public class PredicateOrTest {public static Boolean chekStringOr(String s, Predicate<String> predicate, Predicate<String> predicate2) {
// return predicate.test(s) || predicate2.test(s);return predicate.or(predicate2).test(s);}public static void main(String[] args) {String s = "hello";boolean a = chekStringOr(s, (message) -> message.length() > 5, (message) -> message.contains("o"));System.out.println(a);}
}1.4 negate() 方法
package PreicateTest;import java.util.function.Predicate;public class PredicateNegateTest {/* 需求:判断一个字符串的长度是否大于5如果字符串的长度大于5,那么返回false,反之Predicate方法中的默认方法negate,表示取反关系,* */public static Boolean chekStingNegate(String s, Predicate<String> predicate, Predicate<String> predicate2) {
// return !(predicate.and(predicate2).test(s));return predicate.and(predicate2).negate().test(s);}public static void main(String[] args) {String s = "hello";boolean a = chekStingNegate(s, (message) -> message.length() > 5,(message) -> message.contains("e"));System.out.println(a);}
}
3、Function<T, R>(函数型接口)
这是一个接受一个参数并产生一个结果的函数。泛型类型 T 是输入参数的类型,而 R 是返回结果的类型。例如,你可以使用 Function 接口将一个字符串转换为大写:
1.1、apply() 方法
package FunctionTest;import java.util.function.Function;/** java.util.fuction.Function<T,R>接口 用来根据一个类型的数据得到另一个类型的数据,* 前者称为前置条件,后者称为后置条件* Function接口中最主要的抽象方法为:R apply(T t) 根据类型T的参数获取类型R的结果* 使用场景如:将String类型转换为Integer类型* */
public class FunctionTest {/** 定义一个方法* 方法的参数传递一个字符串类型的整数* 方法的参数传递一个Function接口,泛型使用<String, Integer>* 使用Function接口中的方法apply,把字符串类型的整数,转换为Integer类型的整数* */public static Integer change(String s, Function<String, Integer> fun) {
// Integer i = fun.apply(s);int i = fun.apply(s); // 自动拆箱System.out.println(i);return i;}public static void main(String[] args) {String s = "123456";
// change(s, (message) -> Integer.parseInt(message));change(s, Integer::parseInt);}}1.2、andThen() 方法
package FunctionTest;import java.util.function.Function;/** Function接口中的默认方法andThen:用来进行组合操作* */
public class FunctionAndThenTest {/* 需求:* 把String类型的"123",转换为Integer类型,把转换后的结果加10* 把增加之后的Integer类型的数据,转换为String类型* 分析:* 转换了两次* */public static void chek(String s, Function<String, Integer> function, Function<Integer, String> function2) {String a = function.andThen(function2).apply(s);System.out.println(a);}public static void main(String[] args) {String s = "123456";chek(s, (message) -> Integer.parseInt(message) + 10, (message) ->Integer.toString(message) // 只能是int或者Integer类型
// return String.valueOf(message); // 所有类型都可以);}
}1.3 andThen()方法练习
package FunctionTest;import java.util.function.Consumer;
import java.util.function.Function;public class FunctionTestDemo {public static Integer change(String s, Function<String, String> function1, Function<String, Integer> function2, Function<Integer, Integer> function3) {return function1.andThen(function2).andThen(function3).apply(s);}public static void main(String[] args) {String s = "清月,20";Integer a = change(s, (message) -> message.split(",")[1],(String1) -> Integer.parseInt(String1),(Integer1) -> Integer1 + 100);System.out.println(a);}
}三、Stream流
1、Stream的两种获取方式
(1)通过Collection接口中的默认方法Stream stream()
(2)通过Stream接口中的静态of方法
package StreamAPI;import java.util.*;
import java.util.stream.Stream;public class StreamTest02 {public static void main(String[] args) {// 方法一: 根据Collection获取流// Collection接口中有一个默认的方法:default Stream<E> streamArrayList<String> list = new ArrayList<>();Stream<String> stream1 = list.stream();HashSet<String> set = new HashSet<>();Stream<String> stream2 = set.stream();HashMap<String, String> map = new HashMap<>();Stream<String> stream3 = map.keySet().stream();Stream<String> stream4 = map.values().stream();Stream<Map.Entry<String, String>> stream5 = map.entrySet().stream();// 方式二:Stream中的静态方法of获取流// static<t> Stream<T> of(T... values)Stream<String> stream6 = Stream.of("aa", "bb", "cc");String[] strings = {"aa", "bb", "cc"};Stream<String> stream7 = Stream.of(strings);// 基本数据类型的数组不行,会将整个数组看做一个元素进行操作int[] arr = {11, 22, 33};Stream<int[]> stream8 = Stream.of(arr);}
}
2、Stream的注意事项和常用方法
1、注意事项
1.Stream只能操作一次
2.Stream方法返回的是新的流
3.Stream不调用终结方法,中间的操作不会执行
package StreamAPI;import java.util.stream.Stream;public class StreamTest03 {public static void main(String[] args) {Stream<String> stream1 = Stream.of("aa", "bb", "cc");// 1.Stream只能操作一次
// long count = stream1.count();
// long count2 = stream1.count();// 2.Stream方法返回的是新的流
// Stream<String> stream2 = stream1.limit(1);
// System.out.println(stream1);
// System.out.println(stream2);// 3.Stream不调用终结方法,中间的操作不会执行stream1.filter((s) -> {System.out.println(s);return true;}).count();}
}
2、常用方法
(1)终结方法:返回值类型不再是Stream类型的方法,不再支持链式调用。
(2)非终结方法:反之
| 方法名 | 方法作用 | 返回值类型 | 方法种类 |
|---|---|---|---|
| count | 统计个数 | long | 终结 |
| forEach | 逐一处理 | void | 终结 |
| filter | 过滤 | Stream | 函数拼接 |
| limit | 取用前几个 | Stream | 函数拼接 |
| skip | 跳过前几个 | Stream | 函数拼接 |
| map | 映射 | Stream | 函数拼接 |
| concat | 组合 | Stream | 函数拼接 |
1、forEach方法(遍历)
@Testvoid StreamForEach() {List<String> list = new ArrayList<>();Collections.addAll(list, "欧阳无敌", "鱿鱼卷", "苏大娣", "老子", "庄子", "孙子");list.stream().forEach(System.out::println);}
2、count方法(求个数)
@Testvoid StreamCount() {List<String> list = new ArrayList<>();Collections.addAll(list, "欧阳无敌", "鱿鱼卷", "苏大娣", "老子", "庄子", "孙子");Long a = list.stream().count();System.out.println(a);}
3、filter方法(过滤)
@Testvoid StreamFilter() {List<String> list = new ArrayList<>();Collections.addAll(list, "欧阳无敌", "鱿鱼卷", "苏大娣", "老子", "庄子", "孙子");list.stream().filter(message -> message.length() == 3).forEach(System.out::println);}
4、limit方法(只取前几个)
@Testvoid StreamLimit() {List<String> list = new ArrayList<>();Collections.addAll(list, "欧阳无敌", "鱿鱼卷", "苏大娣", "老子", "庄子", "孙子");list.stream().limit(3).forEach(System.out::println);}
5、skip方法(跳过前几个)
@Testvoid StreamSkip() {List<String> list = new ArrayList<>();Collections.addAll(list, "欧阳无敌", "鱿鱼卷", "苏大娣", "老子", "庄子", "孙子");list.stream().skip(3).forEach(System.out::println);}
6、map方法(映射)
@Testvoid StreamMap() {List<String> list = new ArrayList<>();Collections.addAll(list, "11", "22", "33", "44", "66", "55");list.stream().map(Integer::parseInt).forEach(System.out::println);}
7、sorted方法(按元素的自然顺序排列)
@Testvoid StreamSorted() {List<String> list = new ArrayList<>();Collections.addAll(list, "11", "22", "33", "44", "66", "55");list.stream().sorted().forEach(System.out::println);System.out.println("-----------------------------");Stream<Integer> integerStream = Stream.of(11, 22, 33, 44, 66, 55);
// integerStream.sorted().forEach(System.out::println); // 正序//通过Comparator构造自定义比较器,integerStream.sorted((o1, o2) -> o2 - o1).forEach(System.out::println);// 反序}
8、distinct方法(去重)
@Testvoid StreamDistinct() {Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);stream.distinct().forEach(System.out::println);System.out.println("-----------------------------");Stream<String> stream1 = Stream.of("aa", "bb", "cc", "cc", "dd", "aa");stream1.distinct().forEach(System.out::println);}
9、distinct方法自定义对象(去重)
@Testvoid StreamDistinct1() {Stream<Student> stream = Stream.of(new Student("西施", 18),new Student("貂蝉", 19),new Student("貂蝉", 19),new Student("杨玉环", 19),new Student("王昭君", 20));stream.distinct().forEach(System.out::println);}
10、allMatch方法(判断所有元素是否满足)
@Testvoid StreamAllMatch() {Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);boolean a = stream.allMatch(message -> message > 7);System.out.println(a);}
11、anyMatch方法(判断任意元素是否满足)
@Testvoid StreamAnyMatch() {Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);boolean a = stream.anyMatch(message -> message > 44);System.out.println(a);}
12、noneMatch方法(判断所有元素均不满足)
@Testvoid StreamNoneMatch() {Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);boolean a = stream.noneMatch(message -> message > 44);System.out.println(a);}
13、findFirst 和 findAny 方法(查找第一个元素)
@Testvoid StreamFindFirst() {Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);Optional<Integer> a = stream.findFirst();System.out.println(a.get());System.out.println("---------------------");Stream<Integer> stream1 = Stream.of(11, 22, 33, 33, 66, 55);Optional<Integer> b = stream1.findAny();System.out.println(b.get());}
14、max方法(比较最大值,取排列后的最后一个元素)
@Testvoid StreamMax() {Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);Optional<Integer> a = stream.max((o1, o2) -> o1 - o2);System.out.println(a.get());}
15、min方法(比较最小值,取排列后的第一个元素)
@Testvoid StreamMin() {Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);Optional<Integer> a = stream.min((o1, o2) -> o1 - o2);System.out.println(a.get());}16、reduce方法() (各种类型的累积计算操作,例如求和、求积、字符串连接等)
@Testvoid StreamReduce() {Stream<Integer> stream = Stream.of(4, 5, 3, 9);
// Integer a = stream.reduce(0,(x,y) -> x+y );Optional<Integer> a = stream.reduce((x, y) -> x + y);System.out.println(a.get());}
17、mapToInt方法 (将Stream中的Integer类型数据转换成int类型)
// 同理还有mapLong、mapToDouble@Testvoid StreamMapToInt() {// Stream<Integer>.filter 自动拆箱进行比较Stream<Integer> stream = Stream.of(4, 5, 3, 9).filter(s -> s > 3);stream.forEach(System.out::println);// 转换成IntStream 减少自动装箱和拆箱IntStream intStream = Stream.of(4, 5, 3, 9).mapToInt(Integer::intValue);intStream.filter(s1 -> s1 > 3).forEach(System.out::println);}
18、collect方法(将流中的数据收集到集合中)
@Testvoid StreamCollect() {Stream<String> stream1 = Stream.of("张三", "李四", "王五", "张三");// 收集到List集合中
// List<String> collect = stream1.collect(Collectors.toList());
// System.out.println(collect);// 收集到Set集合中
// Set<String> collect = stream1.collect(Collectors.toSet());
// System.out.println(collect);// 收集到指定的集合中AyyayList
// ArrayList<String> collect = stream1.collect(Collectors.toCollection(ArrayList::new));
// System.out.println(collect);// 收集到指定的集合中AyyayListHashSet<String> collect = stream1.collect(Collectors.toCollection(HashSet::new));System.out.println(collect);}
19、toArray()方法(将流中的数据和收集到数组中)
@Testvoid StreamToArray() {Stream<String> stream1 = Stream.of("张三", "李四", "王五总", "张三");// 转成Object数组不方便
// Object[] array = stream1.toArray();
// for (Object o : array) {
// System.out.println(o);
// }String[] array = stream1.toArray(String[]::new);for (String s : array) {System.out.println(s.length() + s);}}
20、其他收集流中数据的方式(相当于数据库中的聚合函数)
@Testpublic void StreamToOther() {Stream<Student> studentStream = Stream.of(new Student("赵丽颖", 58, 95),new Student("杨颖", 56, 88),new Student("迪丽热巴", 56, 99),new Student("柳岩", 52, 77));// 获取最大值// Optional<Student> max = studentStream.collect(Collectors.maxBy((s1, s2) -> s1.getSocre() - s2.getSocre()));// System.out.println("最大值: " + max.get());// 获取最小值// Optional<Student> min = studentStream.collect(Collectors.minBy((s1, s2) -> s1.getSocre() - s2.getSocre()));// System.out.println("最小值: " + min.get());// 求总和// Integer sum = studentStream.collect(Collectors.summingInt(s -> s.getAge()));// System.out.println("总和: " + sum);// 平均值// Double avg = studentStream.collect(Collectors.averagingInt(s -> s.getSocre()));// Double avg = studentStream.collect(Collectors.averagingInt(Student::getSocre));// System.out.println("平均值: " + avg);// 统计数量Long count = studentStream.collect(Collectors.counting());System.out.println("统计数量: " + count);}
21、groupingBy方法(分组)
// @Testpublic void StreamGroup() {Stream<Student> studentStream = Stream.of(new Student("赵丽颖", 52, 95),new Student("杨颖", 56, 88),new Student("迪丽热巴", 56, 55),new Student("柳岩", 52, 33));// Map<Integer, List<Student>> map = studentStream.collect(Collectors.groupingBy(Student::getAge));// 将分数大于60的分为一组,小于60分成另一组Map<String, List<Student>> map = studentStream.collect(Collectors.groupingBy((s) -> {if (s.getScoure() > 60) {return "及格";} else {return "不及格";}}));map.forEach((k, v) -> {System.out.println(k + "::" + v);});}
22、groupingBy方法(多级分组)
@Testpublic void StreamCustomGroup() {Stream<Student> studentStream = Stream.of(new Student("赵丽颖", 52, 95),new Student("杨颖", 56, 88),new Student("迪丽热巴", 56, 55),new Student("柳岩", 52, 33));// 先根据年龄分组,每组中在根据成绩分组// groupingBy(Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream)Map<Integer, Map<String, List<Student>>> map = studentStream.collect(Collectors.groupingBy(Student::getAge, Collectors.groupingBy((s) -> {if (s.getScoure() > 60) {return "及格";} else {return "不及格";}})));// 遍历map.forEach((k, v) -> {System.out.println(k);// v还是一个map,再次遍历v.forEach((k2, v2) -> {System.out.println("\t" + k2 + " == " + v2);});});}
18、joining方法(拼接)
// @Testpublic void StreamJoining() {Stream<Student> studentStream = Stream.of(new Student("赵丽颖", 52, 95),new Student("杨颖", 56, 88),new Student("迪丽热巴", 56, 99),new Student("柳岩", 52, 77));// 根据一个字符串拼接: 赵丽颖__杨颖__迪丽热巴__柳岩// String names = studentStream.map(Student::getName).collect(Collectors.joining("__"));// 根据三个字符串拼接String names = studentStream.map(Student::getName).collect(Collectors.joining("__", "^_^", "V_V"));System.out.println("names = " + names);}
3、Map和reduce的组合使用
package StreamAPI;
import org.junit.jupiter.api.Test;
import java.util.stream.Stream;public class StreamMapAndReduceTest {// 所有人的年龄总和@Testvoid mapAndReduce() {Integer allTotalAge = Stream.of(new Student("西施", 18),new Student("貂蝉", 19),new Student("杨玉环", 19),new Student("王昭君", 20)).map(Student::getAge).reduce(0, Integer::sum);System.out.println(allTotalAge);}// 找出最大的年龄@Testvoid test1() {Integer allTotalAge = Stream.of(new Student("西施", 18),new Student("貂蝉", 19),new Student("杨玉环", 19),new Student("王昭君", 20)).map(Student::getAge).reduce(0, Math::max); // Integer.max->Math.maxSystem.out.println(allTotalAge);}//统计a的出现次数@Testvoid test2() {
// long number = Stream.of("a","b","c","a","b","a","d").filter((s)->{
// return s.equals("a");
// }).count();long number = Stream.of("a", "b", "c", "a", "b", "a", "d").map(s -> {if (s.equals("a")) {return 1;} else {return 0;}}).reduce(0, Integer::sum);System.out.println(number);}
}
3.串行Stream流的获取方式
1、streamParallel方法(直接获取并行的Stream流)
@Testvoid Stream_StreamParallel() {ArrayList<String> list = new ArrayList<>();Stream<String> stream = list.parallelStream();}
2、parallel方法(将串行流转换成并行流)
@Testvoid StreamParallel() {long count = Stream.of(4, 5, 3, 9, 1, 2, 6).parallel() // 转成并行流.filter(s -> {System.out.println(Thread.currentThread() + "::" + s);return s > 3;}).count();System.out.println(count);}
3、解决parallelStream线程安全问题的三个方案
package StreamAPI;import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Vector;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
import java.util.stream.LongStream;public class StreamParallelTest {private static final int times = 500000000;long start;@BeforeEachpublic void init() {start = System.currentTimeMillis();}@AfterEachpublic void destory() {long end = System.currentTimeMillis();System.out.println("消耗时间:" + (end - start));}// 并行的Stream : 消耗时间:137@Testpublic void testParallelStream() {LongStream.rangeClosed(0, times).parallel().reduce(0, Long::sum);}// 串行的Stream : 消耗时间:343@Testpublic void testStream() {// 得到5亿个数字,并求和LongStream.rangeClosed(0, times).reduce(0, Long::sum);}// 使用for循环 : 消耗时间:235@Testpublic void testFor() {int sum = 0;for (int i = 0; i < times; i++) {sum += i;}}// parallelStream线程安全问题@Testvoid test1() {ArrayList<Integer> list = new ArrayList<>();IntStream.rangeClosed(1, 1000).parallel().forEach(i -> {list.add(i);});System.out.println("list = " + list.size()); // list.size < 1000}// 解决parallelStream线程安全问题方案一: 使用同步代码块@Testpublic void test2() {ArrayList<Integer> list = new ArrayList<>();Object obj = new Object();IntStream.rangeClosed(1, 1000).parallel().forEach(i -> {synchronized (obj) {list.add(i);}});}// 解决parallelStream线程安全问题方案二: 使用线程安全的集合@Testpublic void test3() {ArrayList<Integer> list = new ArrayList<>();Vector<Integer> v = new Vector();List<Integer> synchronizedList = Collections.synchronizedList(list);IntStream.rangeClosed(1, 1000).parallel().forEach(i -> {synchronizedList.add(i);});System.out.println("list = " + synchronizedList.size());}// 解决parallelStream线程安全问题方案三: 调用Stream流的collect/toArray@Testpublic void test4() {ArrayList<Integer> list = new ArrayList<>();List<Integer> collect = IntStream.rangeClosed(1, 1000).parallel().boxed().collect(Collectors.toList());System.out.println("collect.size = "+collect.size());}
}
四、parallelStream背后的技术
1、Fork/Join框架介绍
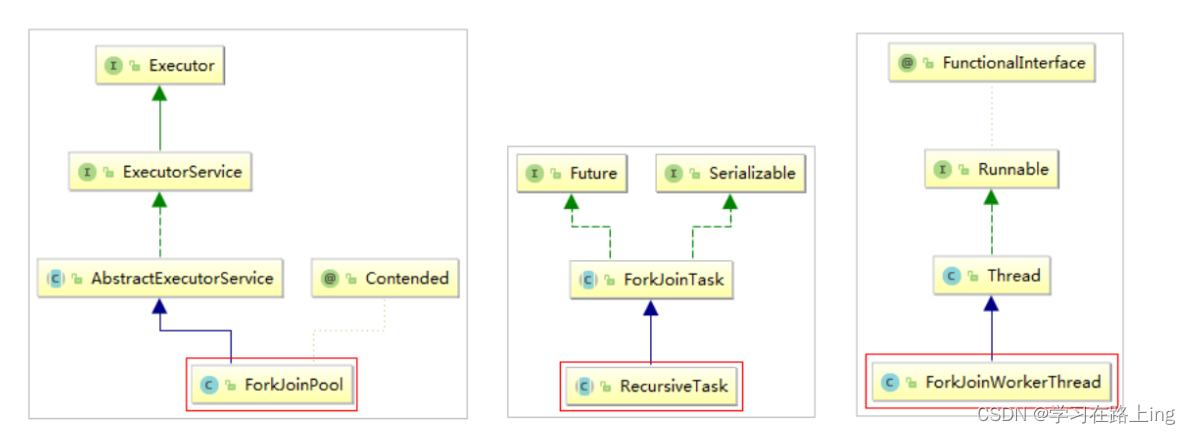
parallelStream使用的是Fork/Join框架。Fork/Join框架自JDK 7引入。Fork/Join框架可以将一个大任务拆分为很多小 任务来异步执行。 Fork/Join框架主要包含三个模块:
- 线程池:ForkJoinPool
- 任务对象:ForkJoinTask
- 执行任务的线程:ForkJoinWorkerThread
2、Fork/Join原理-分治法
把大任务拆成小任务

Fork/Join案例:
需求:使用Fork/Join计算1-10000的和,当一个任务的计算数量大于3000时拆分任务,数量小于3000时计算。
package study;import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;public class ForkJoinTest {public static void main(String[] args) {Long startTime = System.currentTimeMillis();ForkJoinPool pool = new ForkJoinPool();SumRecursiveTask sumRecursiveTask = new SumRecursiveTask(1, 999999999);Long result = pool.invoke(sumRecursiveTask);System.out.println("result = " + result);Long endTime = System.currentTimeMillis();System.out.println("消耗时间 = " + (endTime - startTime));}}// 创建一个求和的任务
// RecursiveTask:一个任务
class SumRecursiveTask extends RecursiveTask<Long> {// 是否要拆分的临界值private static final long THRESHOLD = 3000L;// 起始值private final long start;// 结束值private final long end;SumRecursiveTask(long start, long end) {this.start = start;this.end = end;}@Overrideprotected Long compute() {long lenth = end - start;if (lenth < THRESHOLD){// 小于拆分临界值long sum = 0;for (long i = start; i < end; i++) {sum += i;}return sum;} else {// 拆分long middle = (start + end) / 2;SumRecursiveTask left = new SumRecursiveTask(start, middle);left.fork();SumRecursiveTask right = new SumRecursiveTask(middle + 1, end);right.fork();return left.join() + right.join();}}
}3、Fork/Join原理-工作窃取算法
Fork/Join最核心的地方就是利用了现代硬件设备多核,在一个操作时候会有空闲的cpu,那么如何利用好这个空闲的 cpu就成了提高性能的关键,而这里我们要提到的工作窃取(work-stealing)算法就是整个Fork/Join框架的核心理念 Fork/Join工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
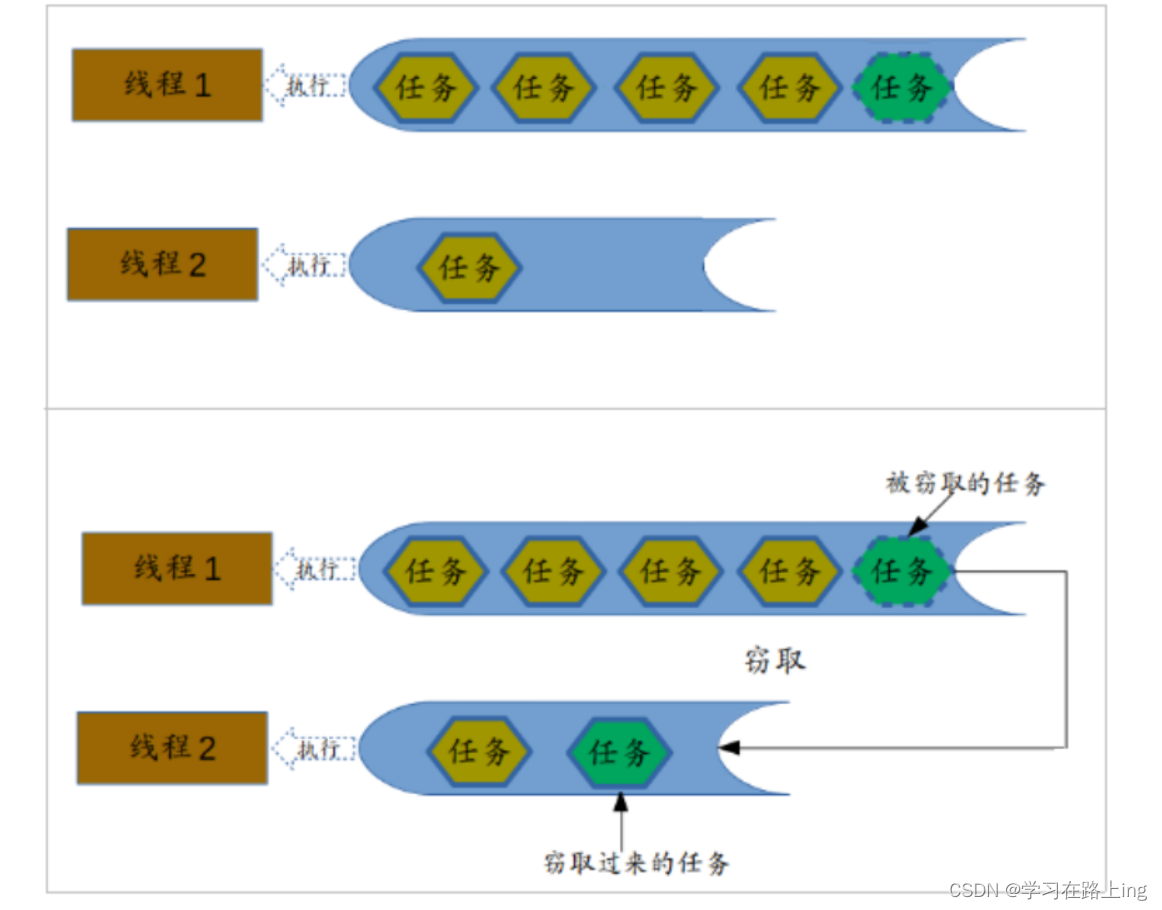
4、小结和注意事项
- parallelStream是线程不安全的
- parallelStream适用的场景是CPU密集型的,只是做到别浪费CPU,假如本身电脑CPU的负载很大,那还到处用 并行流,那并不能起到作用
- I/O密集型 磁盘I/O、网络I/O都属于I/O操作,这部分操作是较少消耗CPU资源,一般并行流中不适用于I/O密集 型的操作,就比如使用并流行进行大批量的消息推送,涉及到了大量I/O,使用并行流反而慢了很多
- 在使用并行流的时候是无法保证元素的顺序的,也就是即使你用了同步集合也只能保证元素都正确但无法保证 其中的顺序
五、Optional类
1、Optional类介绍
Optional是一个没有子类的工具类,Optional是一个可以为null的容器对象。它的作用主要就是为了解决避免Null检 查,防止NullPointerException。
2、Optional的常用方法基本使用
| 方法名 | 作用 |
|---|---|
| empty() | 静态方法,返回一个空的Optional实例。 |
| of(T value) | 静态方法,返回一个包含指定值的Optional实例,如果指定值为null,则抛出NullPointerException。 |
| ofNullable(T value) | 静态方法,返回一个Optional实例,若传入值为null,则返回一个空的Optional实例。 |
| filter(Predicate<? super T> predicate) | 如果值存在并且满足提供的谓词,返回表示该值的Optional;否则返回一个空的Optional。 |
| isPresent() | 如果值存在,返回true;否则返回false。 |
| ifPresent(Consumer<? super T> consumer) | 如果值存在,执行指定的操作。 |
| orElse(T other) | 如果值存在,返回该值;否则返回指定的其他值。 |
| orElseGet(Supplier<? extends T> other) | 如果值存在,返回该值;否则使用指定的Supplier函数生成一个值返回。 |
| orElseThrow(Supplier<? extends X> exceptionSupplier) | 如果值存在,返回该值;否则抛出由Supplier函数生成的异常。 |
package study;import java.util.Optional;public class study {public static void main(String[] args) {test();test1();test2();test3();test4();}// 静态of方法(具体值)public static void test() {Optional<String> op1 = Optional.of("凤姐");
// Optional<String> op2 = Optional.of(null); // NullPointerException}// ofNullable(具体值/空)public static void test1() {Optional<Object> op3 = Optional.ofNullable("如花");Optional<Object> op4 = Optional.ofNullable(null);}// empty(只能传入空)public static void test2() {Optional<Object> op3 = Optional.empty();}// 判断Optional是否有具体值// 1.isPresent()public static void test3() {Optional<Object> op3 = Optional.ofNullable("如花");System.out.println(op3.isPresent()); // trueOptional<Object> op4 = Optional.ofNullable(null);System.out.println(op4.isPresent()); // false}// 1.isPresent()public static void test4() {Optional<Object> op3 = Optional.ofNullable("如花");System.out.println(op3.get()); // 如花Optional<Object> op4 = Optional.ofNullable(null);System.out.println(op4.get()); // NoSuchElementException}}|
| orElseGet(Supplier<? extends T> other) | 如果值存在,返回该值;否则使用指定的Supplier函数生成一个值返回。 |
| orElseThrow(Supplier<? extends X> exceptionSupplier) | 如果值存在,返回该值;否则抛出由Supplier函数生成的异常。 |
package study;import java.util.Optional;public class study {public static void main(String[] args) {test();test1();test2();test3();test4();}// 静态of方法(具体值)public static void test() {Optional<String> op1 = Optional.of("凤姐");
// Optional<String> op2 = Optional.of(null); // NullPointerException}// ofNullable(具体值/空)public static void test1() {Optional<Object> op3 = Optional.ofNullable("如花");Optional<Object> op4 = Optional.ofNullable(null);}// empty(只能传入空)public static void test2() {Optional<Object> op3 = Optional.empty();}// 判断Optional是否有具体值// 1.isPresent()public static void test3() {Optional<Object> op3 = Optional.ofNullable("如花");System.out.println(op3.isPresent()); // trueOptional<Object> op4 = Optional.ofNullable(null);System.out.println(op4.isPresent()); // false}// 1.isPresent()public static void test4() {Optional<Object> op3 = Optional.ofNullable("如花");System.out.println(op3.get()); // 如花Optional<Object> op4 = Optional.ofNullable(null);System.out.println(op4.get()); // NoSuchElementException}}相关文章:
ElasticSearch、java的四大内置函数式接口、Stream流、parallelStream背后的技术、Optional类
第四周笔记 一、ElasticSearch 1.安装 apt-get install lrzsz adduser -m es 创建用户组: useradd *-m* xiaoming(用户名) *PS:追加参数-m* passwd xiaoming(用户名) passwd xiaoming 输入新的 UNIX 密码: 重新输入新的 UNIX 密码&…...

深入MNN:开源深度学习框架的介绍、安装与编译指南
引言 在人工智能的世界里,深度学习框架的选择对于研究和应用的进展至关重要。MNN,作为一个轻量级、高效率的深度学习框架,近年来受到了众多开发者和研究人员的青睐。它由阿里巴巴集团开源,专为移动端设备设计,支持跨平…...

[LeetCode][400]第 N 位数字
题目 400. 第 N 位数字 给你一个整数 n ,请你在无限的整数序列 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, …] 中找出并返回第 n 位上的数字。 示例 1: 输入:n 3 输出:3 示例 2: 输入:n 11 输出:…...

clickhouse 查询group 分组最大值的一行数据。
按照 sql_finger_md5 分组取query_time_ms 最大的一行数据。 使用any函数可以去匹配到的第一行数据,所以可以先让数据按照query_time_ms 排序,然后再使用group by 和any结合取第一行数据,就是最大值的那一行数据。 selectany (time) as time…...

Python装饰器与生成器:从原理到实践
一、引言 Python 是一种功能强大且易于学习的编程语言,其丰富的特性使得开发者能够高效地完成各种任务。在 Python 中,装饰器和生成器是两个非常重要的概念,它们能够极大地增强代码的可读性和可维护性。本文将详细介绍如何学习 Python 装饰器…...

python-函数引入模块面向对象编程创建类继承
远离复读机行为 def calculate_BMI(weight,height):BMI weight / height**2if BMI < 18.5:category "偏瘦"elif BMI < 25:category "正常"elif BMI < 30:category "偏胖"else:category "肥胖"print(f"您的BMI分类…...
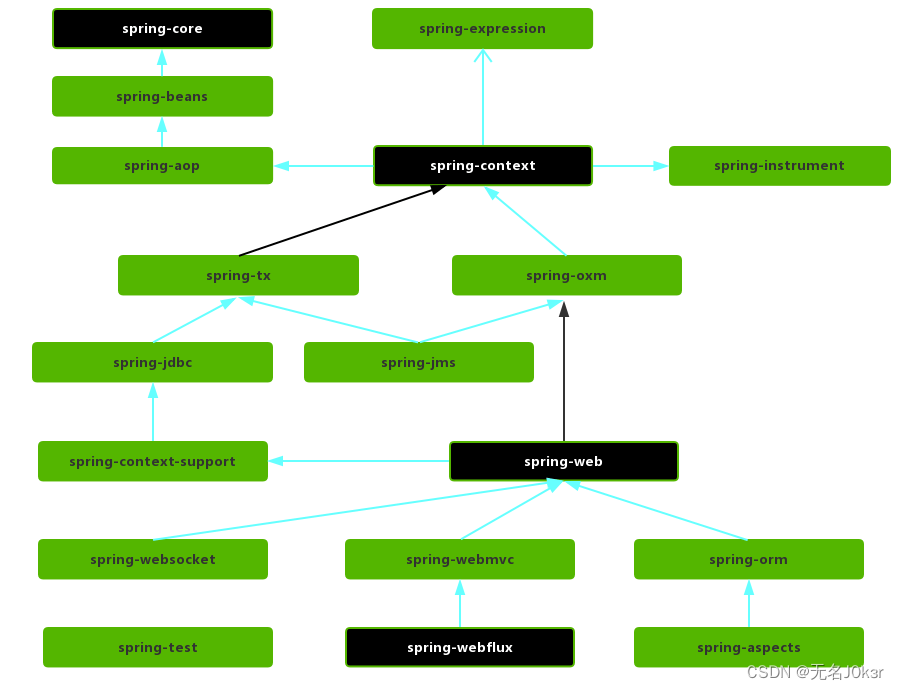
Spring:面试八股
文章目录 参考Spring模块CoreContainerAOP 参考 JavaGuide Spring模块 CoreContainer Spring框架的核心模块,主要提供IoC依赖注入功能的支持。内含四个子模块: Core:基本的核心工具类。Beans:提供对bean的创建、配置、管理功能…...

Flask Python:请求上下文和应用上下文
请求上下文和应用上下文详解 一、背景二、什么是上下文2.1、请求上下文2.2、应用上下文2.3、两种上下文的底层逻辑 三、写在最后 一、背景 在如何实现异步发送邮件的时候,遇到过这样一个报错 RuntimeError: Working outside of request context.This typically me…...
哔哩哔哩直播姬有线投屏教程
1 打开哔哩哔哩直播姬客户端并登录(按下图进行操作) 2 手机用usb数据线连接电脑(若跳出安装驱动的弹窗点击确定或允许),usb的连接方式为仅充电(手机差异要求为仅充电),不同品牌手机要求可能不一样,根据实际的来 3 在投屏过程中不要更改usb的连接方式(不然电脑会死机需要重启) …...

您现在可以在家训练 70b 语言模型
原文:Answer.AI - You can now train a 70b language model at home 我们正在发布一个基于 FSDP 和 QLoRA 的开源系统,可以在两个 24GB GPU 上训练 70b 模型。 已发表 2024 年 3 月 6 日 概括 今天,我们发布了 Answer.AI 的第一个项目&#…...
算法题剪格子使我重视起了编程命名习惯
剪格子是一道dfs入门题。 我先写了个dfs寻找路径的模板,没有按题上要求输出。当我确定我的思路没错时,一直运行不出正确结果。然后我挨个和以前写的代码对比,查了两个小时才发现,是命名风格的问题。 我今天写的代码如下ÿ…...

P19:注释
注释是什么? 在java的源程序中,对java代码的解释说明注释内容不会被编译到.class字节码文件中一个的开发习惯应该多写注释,增加程序的可读性 java中注释的方式: 单行注释:注释内容只占一行 // 注释内容多行注释&…...
)
python习题小练习(挑战全对)
1. (单选题)Python 3.0版本正式发布的时间? A. 1991B. 2000C. 2008D. 1989 2. (单选题)以下关于Python语言中“缩进”说法正确的是: A. 缩进在程序中长度统一且强制使用B. 缩进是非强制的,仅为了提高代码可读性C. 缩进可以用在任何语句之后…...

大数据学习-2024/3/30-MySQL基本语法使用介绍实例
学生信息表 create table studend(stu_id int primary key auto_increment comment 学生学号,stu_name varchar(20) not null comment 学生名字,mobile char(11) unique comment 手机号码,stu_sex char(3) default 男 comment 学生性别,birth date comment 出生日期,stu_time …...

C#_事件_多线程(基础)
文章目录 事件通过事件使用委托 多线程(基础)进程:线程: 多线程线程生命周期主线程Thread 类中的属性和方法创建线程管理线程销毁线程 事件 事件(Event)本质上来讲是一种特殊的多播委托,只能从声明它的类中进行调用,基本上说是一个用户操作&…...

vue 通过插槽来分配内容
通过插槽来分配内容 一些情况下我们会希望能和 HTML 元素一样向组件中传递内容: <AlertBox>Something bad happened. </AlertBox> 这可以通过 Vue 的自定义 <slot> 元素来实现: <template><div class"alert-box&quo…...

YOLO图像前处理及格式转换
import cv2 import numpy as np import os import glob# 数据增强函数 def augment_data(img):rows,cols,_ img.shape# 水平翻转图像if np.random.random() > 0.5:img cv2.flip(img, 1)img_name os.path.splitext(save_path)[0] "_flip.png"cv2.imwrite(img_n…...
ES6 学习(二)-- 字符串/数组/对象/函数扩展
文章目录 1. 模板字符串1.1 ${} 使用1.2 字符串扩展(1) ! includes() / startsWith() / endsWith()(2) repeat() 2. 数值扩展2.1 二进制 八进制写法2.2 ! Number.isFinite() / Number.isNaN()2.3 inInteger()2.4 ! 极小常量值Number.EPSILON2.5 Math.trunc()2.6 Math.sign() 3.…...
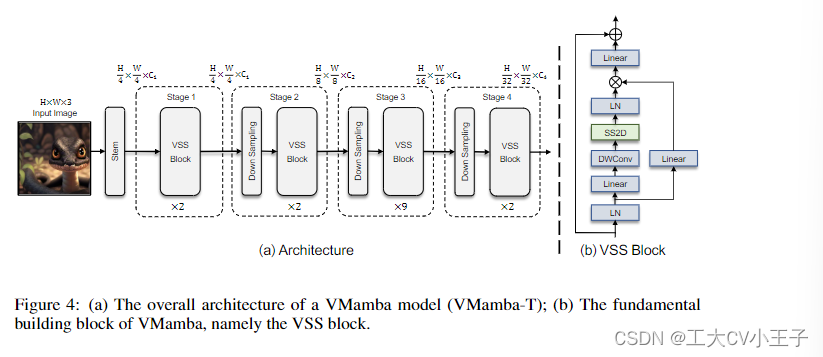
《VMamba》论文笔记
原文链接: [2401.10166] VMamba: Visual State Space Model (arxiv.org) 原文笔记: What: VMamba: Visual State Space Model Why: 多年以来CNN和VIT作为视觉特征提取的主流框架 CNN具有模型简单,共享权重&…...

手机真机连接USB调试adb不识别不显示和TCPIP连接问题
手机真机连接USB调试adb devices不显示设备和TCPIP连接 本文手机型号为NOVA 7 ,其他型号手机在开发人员模式打开等方式可能略有不同,需根据自己的手机型号修改。 文章目录 1. 打开和关闭开发者模式2. 真机USB连接调试adb不显示设备问题的若干解决方法3…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

echarts中heatmap鼠标滚动禁用缩放,向下滚动
配置如下效果如下...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...