JavaSE day16笔记 - string
第十六天课堂笔记
- 学习任务

Comparable接口★★★★
-
接口 : 功能的封装 => 一组操作规范
- 一个抽象方法 -> 某一个功能的封装
- 多个抽象方法 -> 一组操作规范
-
接口与抽象类的区别
- 1本质不同
- 接口是功能的封装 , 具有什么功能 => 对象能干什么
- 抽象类是事物本质的抽象 => 对象是什么
- 2定义方式不同
- 抽象类 : abstract
- 接口 : interface
- 3内容不同
- 抽象类 => 普通类内容 + 抽象方法
- 接口 => 抽象方法 + 常量 + static方法 + default 方法
- 4使用方式不同
- 抽象类 -> 单继承
- 接口: 多继承 , 多实现
- 1本质不同
-
Comparable<T>接口 : 封装了 两个对象 比较大小的功能
-
<T> : 泛型 : 参数传递的数据类型

-
实现接口, 重写int compareTo(T o)方法
- this : 当前对象
- o : 表示待比较的对象
- 返回类型int : return 对象2.比较实例变量 - this.比较实例对象;
- this > o : return 正数
- this < o : return 负数
- this = o: return 0
-
通过 Arrays.sort(对象数组 , 0 , 对象个数); 调用进行排序 , 该方法内会调用重写了的compareTo方法
-
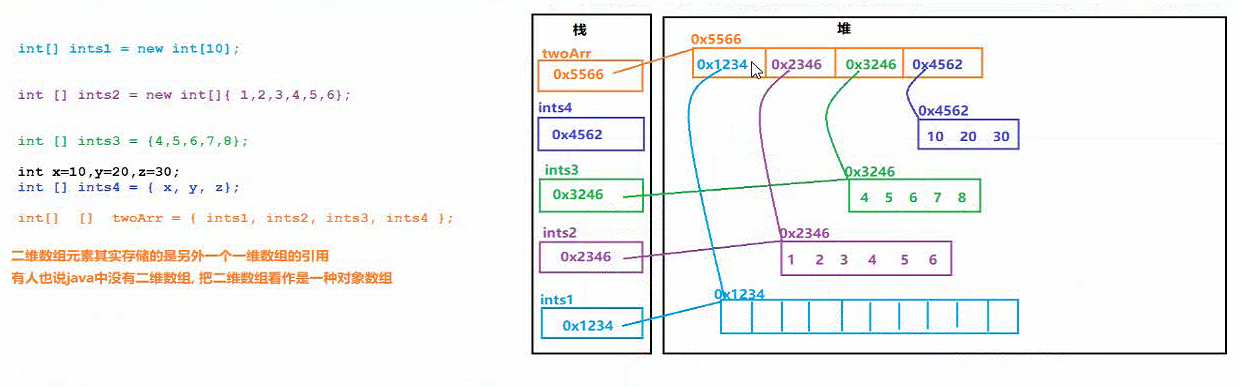
二维数组★
-
一维数组 : int[] arrs = {1,3,2} ; : 存储整数类型的数组
-
int[] [] 数组名 = {一维数组 , …}; : 存储一维数组类型的数组 => 数组的数组 => 二维数组的静态初始化形式
-
二位数组中的每个一维数组, 存储的是一维数组的引用值 => 将二维数组看作对象数组
-
-
二维数组的定义格式
- 动态初始化 :数据类型[] [] 数组名= new 数据类型[二维数组长度][一维数组长度];
- 当没给一维数组长度输入值 -> 那么系统不会给一维数组初始化, 即默认初始化为null -> 调用的话, 就会Null Pointer Exception
- 动态初始化 :数据类型[] [] 数组名= new 数据类型[二维数组长度][一维数组长度];
-
二维数组的遍历
- 两层for循环
- 两层foreach循环
Java常用类

String字符串★★★
-
创建String对象
-
赋值字符串创建 : String s = “fasfe”;
-
根据构造方法创建对象 :
-
根据字节数组创建
- String(byte[] bytes) 可以把bytes数组中所有字节以默认的字符编码解析为字符串
- String(byte[] bytes, int offset, int length)可以把bytes数组中从offset开始的length个字节以默认的字符编码解析为字符串
- String(byte[] bytes, String charsetName)可以把bytes数组中所有字节以指定的字符编码解析为字符串
- 用处: 从文件中读取若干字节保存到字节数组中 , 将字节数组 转换为 字符串 => 转换需要用到字符编码
- 字符编码就是字符与一串01二进制之间映射
- 常用的字符编码 : UTF-8 , UTF-16 , GBK/GB2312 , ASCII , ISO8859-1
- utf-8 : Unicode编码 ,
- 一个英文字符-> 1 byte字节的二进制 ,
- 一个汉字字符 -> 3 byte字节的二进制
- utf-16: Unicode编码 -> 2 byte字节的二进制 , => char类型数据默认编码
- GBK/GB 2312 : 中文编码 , GB 2312包含的字符数量多
- 一个英文字符-> 1 byte字节的二进制 ,
- 一个汉字字符 -> 2 byte字节的二进制
- ASCII : 美国信息交换码, 只有英文 -> 1 byte
- ISO8859-1 : 西欧编码,(Latin编码) 兼容ASCII => tomcat服务器默认编码
- utf-8 : Unicode编码 ,
- 常用的字符编码 : UTF-8 , UTF-16 , GBK/GB2312 , ASCII , ISO8859-1

-
根据字符数组创建
- String(char[] value) 把value数组中所有的字符连接为字符串.
- String(char[] value, int offset, int count) 把value数组中从offset开始的count个字符连接为字符串
-
-
-
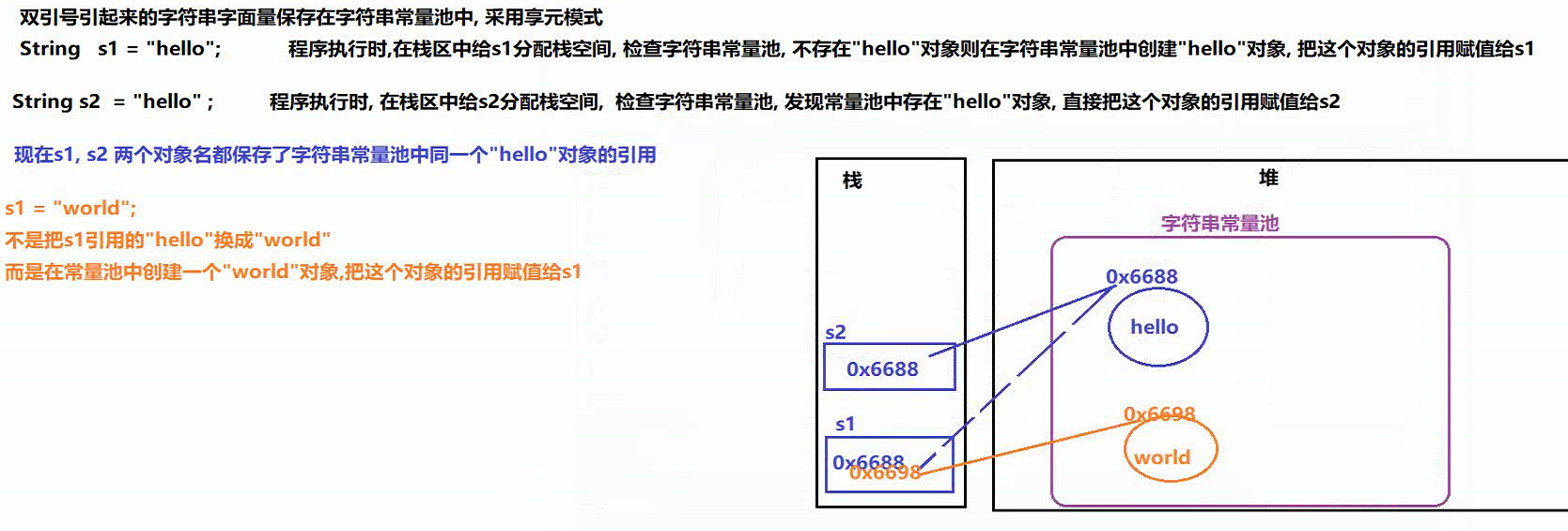
字符串数据存储 到 字符串常量池当中
-
字符串的字面值
- 字符串保存在字符串常量池中, 采用的是 享元模式
- 字符串对象声明赋值 : 先看 常量池是否有该数据 , 有则引用值, 无则创建
- 如果字符串重新赋值: 不是在常量池中覆盖替换 , 而是在常量池中重新创建一个字符串对象, 将对象引用赋值
-
==javac编译器会 在编译过程中 对字符串 常量的连接 进行优化 , 在.Java -> .class的这个过程中优化
-
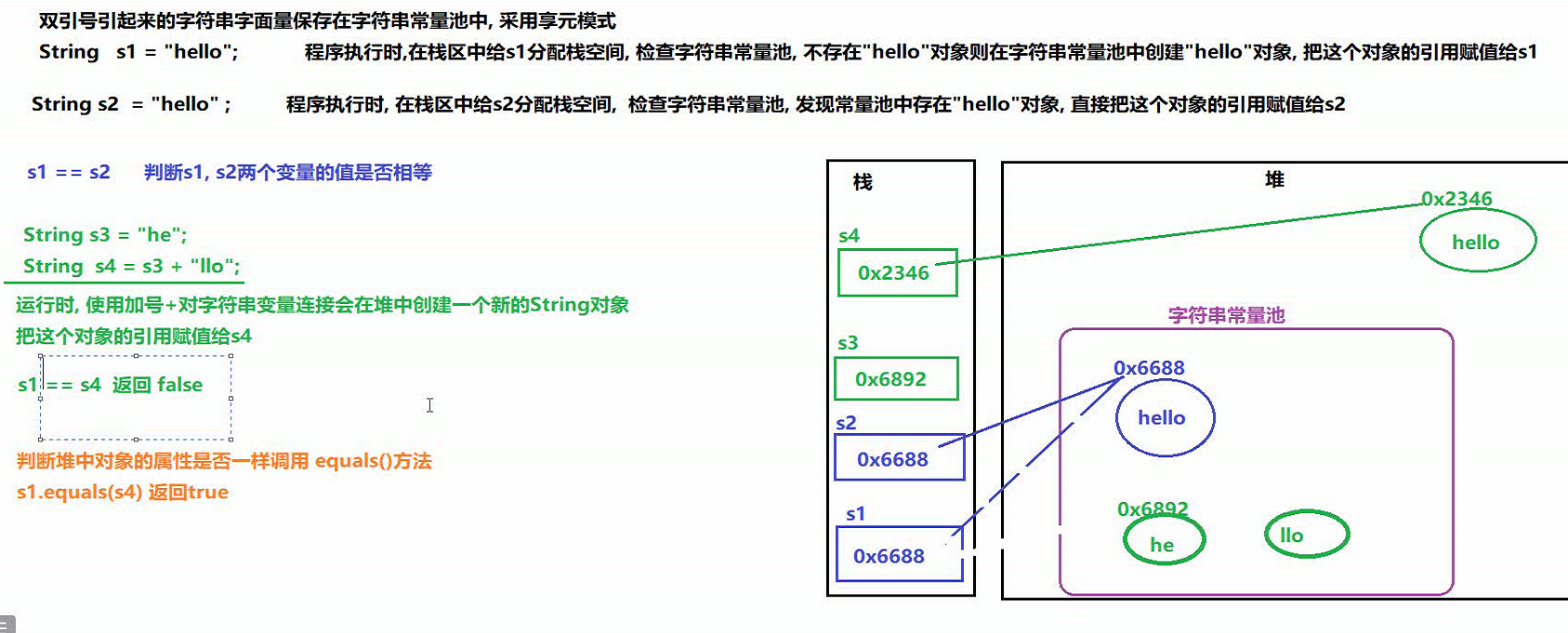
代码如下:
public static void main(String[] args) {// 定义两个字符串// "helloworld" 会存储到堆区中的常量池中,将索引值赋值给s1String s1 = "helloworld";// "helloworld"已经存在常量池中, 不会再重新创建, 将索引值给s2String s2 = "helloworld";System.out.println("s1 == s2 = " + (s1 == s2));System.out.println(s1 == s2); // 故判断结果为 true// 定义字符串String s3 = "hello"; //"hello"在常量池中不存在, 故重新创建, 并将索引值给s3String s4 = s3 + "world"; // s3是变量, 无法用到编译优化 , "world"不在常量池中,故需要创建 ,使用+号对string连接 , 会在 堆区 创建一个 新的字符串对象 , 故会是一个新的引用值 给 s4System.out.println(s1 == s4); // 故 s1 和 s4 的码值不同 falseString s5 = "hello" + "world"; // javac编译器会对字符串 常量的连接 进行优化 , 在.Java -> .class的这个过程中优化,故 s5 其实就是 s5 = "helloworld"System.out.println(s1 == s5); // trueSystem.out.println(s4 == s5); // false// final 常量final String s6 = "hello"; // "hello"在常量池中已经存在, 故直接引用值 赋给 s6String s7 = s6 + "world"; // "world"已经在常量池中, 不需要创建,只需要调用, 因为s6是个常量 , 故javac编译器会对字符串 进行优化 => 即 s6 + "world" == "helloworld" , 然后又发现"helloworld"在常量池中已经存在 , 故直接将 引用值 赋 给 s7System.out.println("s1 == s7 = " + (s1 == s7)); // true
-
面试题: 以下两个共创建了几个String字符串对象 ??
// 问题: 以下两个共创建了几个String字符串对象 ??String s8 = new String("girlfriend");String s9 = new String("girl" + "friend");/* 共三个首先 : "girlfriend" 在常量池中不存在, 故创建一个字符串对象其次 : new String("girlfriend") : 表示new 了一个字符串对象然而 : "girl" + "friend" 由于是两个常量使用+号拼接, 在javac编译时, 会自动进行调优, 使得"girl" + "friend" == "girlfriend" , 而"girlfriend" 在常量池中已经存在, 故只需要引用赋值, 不需要创建新的最后 : new String("girl" + "friend") : 表示new 了一个字符串对象综上所述 : 共创建了3个字符串对象*/
-
string对象的不可变性
- 创建string对象后, string字符串对象的字符序列,就无法修改了
- string提供的方法: toUppercase() , trim() , replace() 都是返回一个新的字符串对象, 原来的字符串不变
- string类底层使用private final byte[] value 字节数组 来保存字符串的每个字符 ,
- 该数组是private 私有的, 我们没有权限修改 value数组的元素
- string类 也没有相应的方法修改 value 数组元素
- 使用 + 进行字符串连接时 , 会创建新的string对象
-
问题 : 因为string字符串是不可变的 , 创建string字符串对象后 , 他的字符序列 就不能修改了 , 使用加号(+) 对string 变量进行连接时, 会创建新的string对象
- 当频繁使用字符串连接时 , 会出现多次创建string的情况 ,
- 故 频繁字符串操作 时建议使用 可变字符串来进行操作
stringBuilder&stringBuffer
-
可变字符串 => 字符序列可以修改
- stringBuffer : 是线程安全的
- stringBuilder : 是线程不安全的 , 但是执行效率更高
-
线程安全
- 多个线程 同时操作 一个共享数据 的时候, 可能会存在数据紊乱
-
创建对象常用构造方法
- new StringBuilder() 创建空字符串, 底层数组默认长度为16
- new StringBuilder( 1000000 ) 创建空字符串, 指定底层数组的大小, 避免数组频繁扩容
- StringBuilder(CharSequence seq) 根据其他字符串创建
-
常用操作
- StringBuilder append(String str) 在当前字符串后面连接str
- StringBuilder delete(int start, int end) 删除字符串中[start, end)范围内的字符
- StringBuilder insert(int offset , String str) : 在当前字符串的offset位置插入 str
- StringBuilder replace(int start, int end, String str) 把当前字符串[start, end)范围内的字符替换为str
- StringBuilder reverse() 把字符串中的字符序列逆序
- String toString()
- 因为字符串方法返回值类型都是字符串对象,故可以使用连缀操作
-
代码如下:
public static void main(String[] args) {// new一个可变字符串StringBuilder stringBuilder = new StringBuilder();// 空串, 底层数组长度为16StringBuilder stringBuilder1 = new StringBuilder(2000); // 空串, 底层数组长度为capacity : 2000StringBuffer stringBuffer = new StringBuffer(); // 'StringBuffer stringBuffer' may be declared as 'StringBuilder' : 都可以声明为StringBuilder// append() : 字符串的连接for (int i = 0; i < 10; i++) {stringBuffer.append(i);}System.out.println("stringBuffer = " + stringBuffer);// delete() : 删除stringBuffer.delete(3, 8); // 删除[3 , 8)范围内数字System.out.println("删完后stringBuffer = " + stringBuffer); //删完后stringBuffer = 01289// insert() : 插入stringBuffer.insert(3, "flower"); // 在索引为3的位置上插入个数,后面的数顺延System.out.println("插入后stringBuffer = " + stringBuffer); //插入后stringBuffer = 012flower89// replace() 替换stringBuffer.replace(0, 3, "double");System.out.println("替换后stringBuffer = " + stringBuffer); // 把[0 , 3)的值替换成str // 替换后stringBuffer = doubleflower89// reverse() : 反转stringBuffer.reverse();System.out.println("反转后stringBuffer = " + stringBuffer); //反转后stringBuffer = 98rewolfelbuod// 因为字符串方法返回值类型都是字符串对象,故可以使用连缀操作String string = stringBuffer.reverse().replace(0, 5, "hejiabei").toString();System.out.println("string = " + string); // string = hejiabeieflower89}
string常用的方法
-
char charAt(int index); : 返回字符串中 index 位置的字符
-
int length(); : 字符串中字符的数量
-
string字符串由若干字符组成,
-
jdk8之前 : 底层定义 private final char value[] 字符数组来保存字符串的每个字符
-
jdk9 开始 : 底层定义 private final byte[] value 字节数组来保存字符串的每个字符
- 目的 : 节省空间
- 在存储等操作时, 先判断字符编码,
- 如果是Latin编码则使用一个字节存储一个字符
- 如果是utf16编码 ,则使用2个字节存储一个字符
-
底层源码:
public int compareTo(String anotherString) {byte v1[] = value;byte v2[] = anotherString.value;byte coder = coder();if (coder == anotherString.coder()) {return coder == LATIN1 ? StringLatin1.compareTo(v1, v2): StringUTF16.compareTo(v1, v2);}return coder == LATIN1 ? StringLatin1.compareToUTF16(v1, v2): StringUTF16.compareToLatin1(v1, v2);}@IntrinsicCandidatepublic static int compareTo(byte[] value, byte[] other) {int len1 = value.length;int len2 = other.length;return compareTo(value, other, len1, len2);}public static int compareTo(byte[] value, byte[] other, int len1, int len2) {int lim = Math.min(len1, len2);for (int k = 0; k < lim; k++) {if (value[k] != other[k]) {return getChar(value, k) - getChar(other, k);}}return len1 - len2;}
-
-
-
代码如下:
// 定义一个字符串String s = "繁荣昌盛,国泰民安";// 获取字符串长度System.out.println("s.length() = " + s.length());for (int i = 0; i < s.length(); i++) {System.out.print(s.charAt(i) + " ");}System.out.println(); -
int compareTo(String anotherString) : 比较两个字符大小
-
string类型实现了comparable接口, 重写了comparaTo方法,
-
定义比较大小的规则: 区分大小写 , 逐个比较字符串的每个字符 , 遇到了第一个不一样的字符 字符相减 , 如果都一样 , 再比较字符串长度 .
-
底层代码:
public int compareTo(String anotherString) {byte v1[] = value;byte v2[] = anotherString.value;byte coder = coder();if (coder == anotherString.coder()) {return coder == LATIN1 ? StringLatin1.compareTo(v1, v2): StringUTF16.compareTo(v1, v2);}return coder == LATIN1 ? StringLatin1.compareToUTF16(v1, v2): StringUTF16.compareToLatin1(v1, v2);}private static int compareToUTF16Values(byte[] value, byte[] other, int len1, int len2) {int lim = Math.min(len1, len2);for (int k = 0; k < lim; k++) {char c1 = getChar(value, k);char c2 = StringUTF16.getChar(other, k);if (c1 != c2) {return c1 - c2;}}return len1 - len2;}
-
-
int compareToIgnoreCase(String str); 忽略大小写, 比较字符大小
- 代码如下:
// 比较两个字符串大小System.out.println("\"hello\".compareTo(\"hella\") = " + "hello".compareTo("hella"));System.out.println("\"hello\".compareTo(\"w\") = " + "hello".compareTo("w"));System.out.println("\"繁荣昌盛\".compareTo(s) = " + "繁荣昌盛".compareTo(s));System.out.println("\"hello\".compareTo(\"HELLO\") = " + "hello".compareTo("HELLO"));System.out.println("\"hello\".compareToIgnoreCase(\"HELLO\") = " + "hello".compareToIgnoreCase("HELLO")); -
boolean contains(CharSequence s) : 判断当前字符串是否包含s字符串
- CharSequence 是一个接口 ,
- 在调用方法时 , 方法实参为 CharSequence 接口的 实现类对象或者 匿名内部类对象
- CharSequence接口 的实现类有 : string , string builder , string buffer
- 代码如下:
// 包含System.out.println("s.contains(\"国\") = " + s.contains("国")); // trueSystem.out.println("s.contains(\"中\") = " + s.contains("中")); // fase - CharSequence 是一个接口 ,
-
boolean endsWith(String suffix) : 判断字符串是否以suffix结尾
-
boolean startsWith(String prefix) : 判断字符串是否以 prefix 开头
-
boolean equals(Object anjObject) : 判断两个字符串是否一样
-
boolean equalsIgnoreCase(String anotherString) : 忽略大小写, 判断是否一样
- 代码如下
// 判断字符System.out.println("s.startsWith(\"繁\") = " + s.startsWith("繁")); //trueSystem.out.println("s.endsWith(\"强\") = " + s.endsWith("强")); // falseSystem.out.println("s.equals(\"繁荣昌盛,国泰民安\") = " + s.equals("繁荣昌盛,国泰民安")); //s.equals("繁荣昌盛,国泰民安") = trueSystem.out.println("\"hello\".equalsIgnoreCase(\"HELLO\") = " + "hello".equalsIgnoreCase("HELLO")); //"hello".equalsIgnoreCase("HELLO") = true -
byte[] getBytes() : 返回当前字符串 在默认编码下 对应的字节数组 :
- utf-8编码中 , 一个英文字符对应一个byte字节, 一个汉字对应 3个 byte 字节
-
byte[] getBytes(String charsetName) : 返回当前字符串 在指定的编码 下对应的字节数组
- 报出异常 unhandled exception
- 代码如下:
// 返回 编码对应的字节数组byte[] bytes = s.getBytes();System.out.println("Arrays.toString(bytes) = " + Arrays.toString(bytes)); //Arrays.toString(bytes) = [-25, -71, -127, -24, -115, -93, -26, -104, -116, -25, -101, -101, 44, -27, -101, -67, -26, -77, -80, -26, -80, -111, -27, -82, -119]// 将字节数组 转为字符串: 通过创建string来实现String s1 = new String(bytes);System.out.println("s1 = " + s1); //s1 = 繁荣昌盛,国泰民安// 指定编码 返回对应的字节数组byte[] gbks = s.getBytes("GBK"); //Unhandled exception: java.io.UnsupportedEncodingExceptionSystem.out.println("Arrays.toString(gbks) = " + Arrays.toString(gbks)); //Arrays.toString(gbks) = [-73, -79, -56, -39, -78, -3, -54, -94, 44, -71, -6, -52, -87, -61, -15, -80, -78]// 将字节数组重新合成字符串String s2 = new String(gbks);System.out.println("s2 = " + s2); //s2 = ���ٲ�ʢ,��̩��String gbk = new String(gbks, "GBK");System.out.println("gbk = " + gbk); //gbk = 繁荣昌盛,国泰民安 -
int indexOf(String str) : 返回str在当前字符串中第一次出现的索引值
-
int lastIndexOf(String str) : 返回最后一次出现的索引值
-
String substring(int beginIndex) : 返回当前字符串 从 begin Index位置 开始的子串
-
String substring(int beginIndex, int endIndex) : 返回[beginIndex , endIndex ) 范围的子串
-
代码如下:
// 查字符String path = "E:\\course\\02Project\\javaSEProject\\day16\\src\\cn\\hejiabei\\string\\StringMethod.java";// 获取文件名 以及 文件类型int slash = path.lastIndexOf("\\"); // 获取最后一个小标int dot = path.lastIndexOf('.');// 获取字符串一段的值String fileName = path.substring(slash + 1, dot);System.out.println("fileName = " + fileName); // fileName = StringMethodString suffix = path.substring(dot);System.out.println("suffix = " + suffix); // suffix = .java -
String replace(CharSequence target, CharSequence replacement) : 将target 替换为 replacement, 返回一个新字符串 , 原字符串不变
-
代码如下:
// 字符替换replaceString s3 = "xiaoming666xiaohua666";String s4 = s3.replace('6', '*');System.out.println("原来是s3 = " + s3); //原来是s3 = xiaoming666xiaohua666System.out.println("替换后s4 = " + s4); //s4 = xiaoming***xiaohua*** -
String[] split(String regex) : 将字符串 通过regex 拆分成 数组
- regex = “”: 使用""空串 对字符串拆分 , => 即拆分成字符数组 ==> 相当于toCharArray方法
-
代码如下:
// 拆分String s5 = " 东临碣石,以观沧海,水何澹澹,山岛竦峙,树木丛生,百草丰茂,秋风萧瑟,洪波涌起,日月之行,若出其中,星汉灿烂,若出其里,幸甚至哉,歌以咏志";System.out.println(s5); // 东临碣石,以观沧海,水何澹澹,山岛竦峙,树木丛生,百草丰茂,秋风萧瑟,洪波涌起,日月之行,若出其中,星汉灿烂,若出其里,幸甚至哉,歌以咏志String[] split = s5.split(",");System.out.println("Arrays.toString(split) = " + Arrays.toString(split)); //Arrays.toString(split) = [ 东临碣石, 以观沧海, 水何澹澹, 山岛竦峙, 树木丛生, 百草丰茂, 秋风萧瑟, 洪波涌起, 日月之行, 若出其中, 星汉灿烂, 若出其里, 幸甚至哉, 歌以咏志]// 也可以使用""空字符进行拆分String[] split1 = s5.split("");System.out.println("Arrays.toString(split1) = " + Arrays.toString(split1)); //Arrays.toString(split1) = [ , 东, 临, 碣, 石, ,, 以, 观, 沧, 海, ,, 水, 何, 澹, 澹, ,, 山, 岛, 竦, 峙, ,, 树, 木, 丛, 生, ,, 百, 草, 丰, 茂, ,, 秋, 风, 萧, 瑟, ,, 洪, 波, 涌, 起, ,, 日, 月, 之, 行, ,, 若, 出, 其, 中, ,, 星, 汉, 灿, 烂, ,, 若, 出, 其, 里, ,, 幸, 甚, 至, 哉, ,, 歌, 以, 咏, 志] -
char[] toCharArray(); : 将字符串转成 字符数组
-
代码如下:
// 字符串 转换成 字符数组String s6 = "hello , world";char[] charArray = s6.toCharArray();System.out.println("Arrays.toString(charArray) = " + Arrays.toString(charArray)); //Arrays.toString(charArray) = [h, e, l, l, o, , ,, , w, o, r, l, d] -
String toLowerCase(); : 大写转小写
-
String toUpperCase(); : 小写转大写
-
代码如下:
// 大小写转化String s7 = "Good Good Study";String upperCase = s7.toUpperCase();System.out.println("upperCase = " + upperCase); //upperCase = GOOD GOOD STUDYString lowerCase = s7.toLowerCase();System.out.println("lowerCase = " + lowerCase); //lowerCase = good good study -
String trim(); : 去掉字符串前后空格符
-
代码如下:
// 去掉两边空白字符String s8 = " Good Good Study ";System.out.println("s8 = " + s8); //s8 = Good Good Study// 去掉两边空白String trim = s8.trim();System.out.println("trim = " + trim); //trim = Good Good Study -
static String valueOf(int i) : 把其他类型的数据转换为字符串
- 底层调用stu对象的toString()对象 , Student类没有重写toString()对象, 调用object类继承来的toString()方法 , 返回: 全限定类名 + “@” + 哈希码的十六进制
-
static String valueOf(Object obj) : 把对象转为字符串
-
代码如下:
// 将 数据类型 转换为 字符串 valueofint num = 2523;String s9 = String.valueOf(num);System.out.println("s9 = " + s9); // // s9 = 2523// object转换Student student = new Student("张三");String s10 = String.valueOf(student);System.out.println("s10 = " + s10); //s10 = cn.hejiabei.string.StringMethod$Studenfd0d5ae
调用object类继承来的toString()方法 , 返回: 全限定类名 + “@” + 哈希码的十六进制
-
static String valueOf(Object obj) : 把对象转为字符串
-
代码如下:
// 将 数据类型 转换为 字符串 valueofint num = 2523;String s9 = String.valueOf(num);System.out.println("s9 = " + s9); // // s9 = 2523// object转换Student student = new Student("张三");String s10 = String.valueOf(student);System.out.println("s10 = " + s10); //s10 = cn.hejiabei.string.StringMethod$Studenfd0d5ae
相关文章:
JavaSE day16笔记 - string
第十六天课堂笔记 学习任务 Comparable接口★★★★ 接口 : 功能的封装 > 一组操作规范 一个抽象方法 -> 某一个功能的封装多个抽象方法 -> 一组操作规范 接口与抽象类的区别 1本质不同 接口是功能的封装 , 具有什么功能 > 对象能干什么抽象类是事物本质的抽象 &…...
java将文件转成流文件返回给前端
环境:jdk1.8,springboot2.5.3,项目端口号:9100 1.待转换的文件 一、路径 二、文件内容 2.controller中代码 package com.example.pdf.controller;import com.example.pdf.service.GetFileStreamService; import org.springframework.web.b…...

使用Node.js常用命令提高开发效率
Node.js是一个基于Chrome V8引擎的JavaScript运行时环境,广泛用于构建服务器端应用程序和命令行工具。Node.js提供了丰富的命令和工具,可以帮助开发者更高效地开发应用程序。在日常开发中,除了Node.js本身的核心功能外,npm&#x…...

百度资源平台链接提交
百度资源平台是百度搜索引擎提供的一个重要工具,用于帮助网站主将自己的网站链接提交给百度搜索引擎,以便更快地被收录和展示在搜索结果中。以下将就百度资源平台链接提交的概念、操作方法以及其对网站收录和曝光的影响进行探讨: 什么是百度资…...

力扣爆刷第108天之CodeTop100五连刷26-30
力扣爆刷第108天之CodeTop100五连刷26-30 文章目录 力扣爆刷第108天之CodeTop100五连刷26-30一、15. 字符串相加二、300. 最长递增子序列三、42. 接雨水四、43. 重排链表五、142. 环形链表 II 一、15. 字符串相加 题目链接:https://leetcode.cn/problems/add-strin…...

Android裁剪图片为波浪形或者曲线形的ImageView
如果需要做一个自定义的波浪效果的进度条,裁剪图片,对ImageView的图片进行裁剪,比如下面2张图,如何实现? 先看下面的效果,看到其实只需要对第一张高亮的图片进行处理即可,灰色状态的作为背景图。…...

Linux课程____shell脚本应用
:一、认识shell 常用解释器 Bash , ksh , csh 登陆后默认使用shell,一般为/bin/bash,不同的指令,运行的环境也不同 二、 编写简单脚本并使用 # vim /frist.sh //编写脚本文件,简单内容 #!/bin/bash …...

设计模式12--组合模式
定义 案例一 案例二 优缺点...
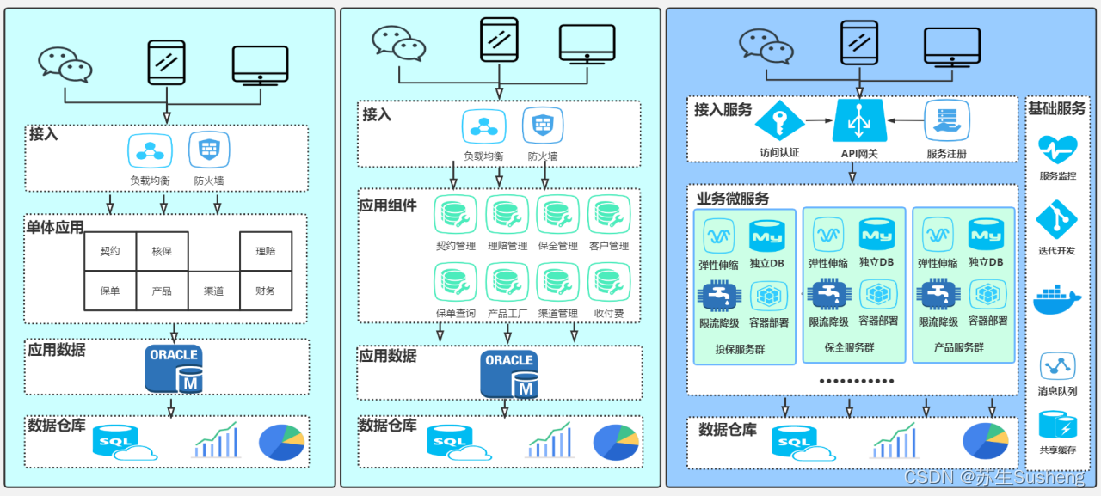
【微服务】软件架构的演变之路
目录 单体式架构的时代单体式架构(Monolithic)优点缺点适用场景单体式架构面临诸多问题1.宽带提速,网民增多2.Web2.0时代的特点问题描述优化方向 集群优点缺点适用场景搭建集群后面临诸多问题用户请求问题用户的登录信息数据查询 改进后的架构 垂直架构优点缺点 分布…...

安全算法 - 加密算法
加密算法是一种在信息安全领域中广泛应用的算法,能够将数据进行加密转换,以保证数据的保密性和安全性。 它具有保密性、对称加密和非对称加密、密钥管理、数据完整性和认证等重要特点和应用。 加密算法可以分为对称加密和非对称加密两种类型࿱…...

安全算法 - 国密算法
国密算法是中国自主研发的密码算法体系,包括对称加密算法、非对称加密算法和哈希算法。其中,国密算法采用SM4作为对称加密算法,SM2作为非对称加密算法,以及SM3作为哈希算法。国密算法在信息安全领域具有重要意义和广泛应用&#x…...

蓝桥杯2014年第十三届省赛真题-武功秘籍
一、题目 武功秘籍 小明到X山洞探险,捡到一本有破损的武功秘籍(2000多页!当然是伪造的)。他注意到:书的第10页和第11页在同一张纸上,但第11页和第12页不在同一张纸上。 小明只想练习该书的第81页到第92页的…...
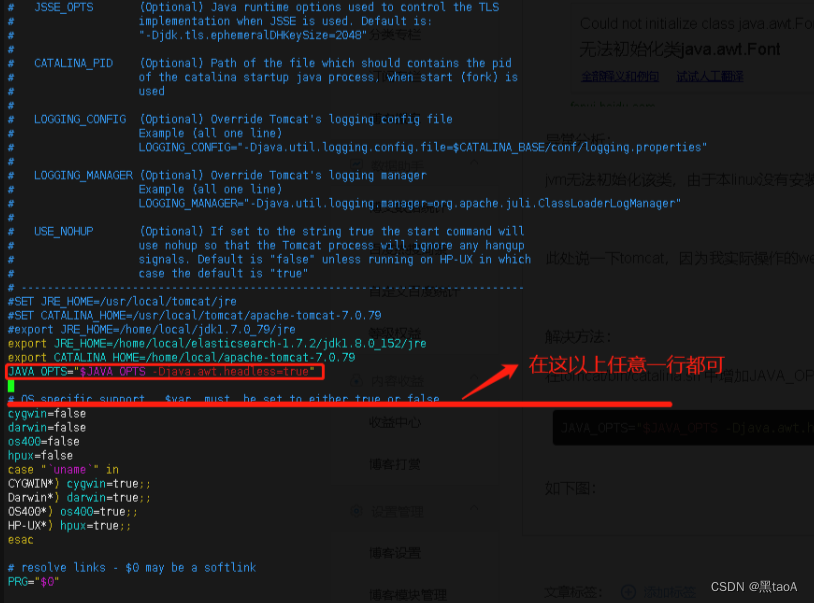
Could not initialize class java.awt.Font
项目场景: 项目场景:java项目在web端导出Excel、Word、PDF等文档 问题描述 在Windows系统中开发以及运行文件导出正常,单机部署到Linux中或者使用docker部署后,导出报错。 异常: eleasing transactional SqlSession…...
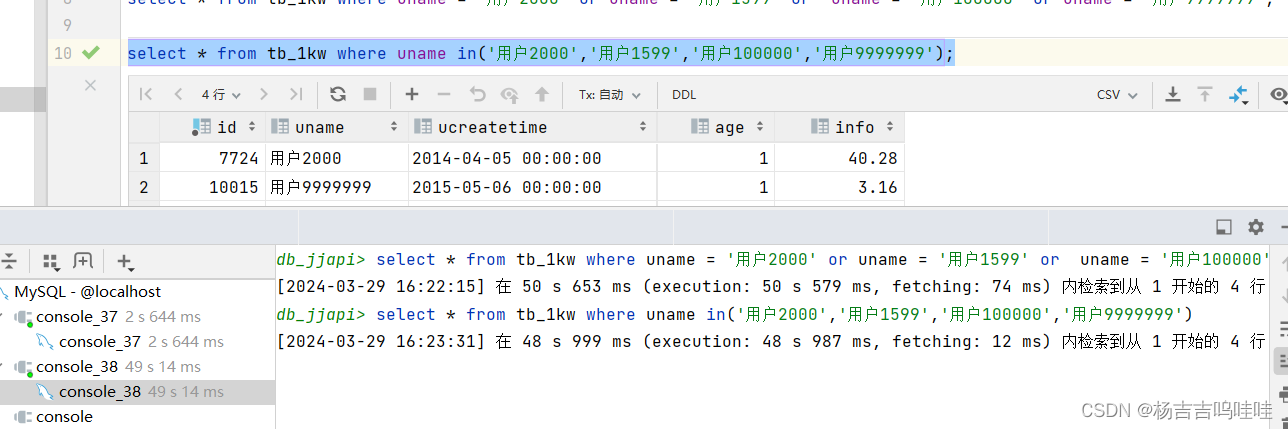
Mysql or与in的区别
创建一个表格 内涵一千万条数据 这张表中,只有id有建立索引,且其余都没有 测试1:使用or的情况下,根据主键进行查询 可以看到根据主键id进行or查询 花费了30-114毫秒,后面30多毫秒可能是因为Mysql的Buffer Pool缓冲池的…...

STM32——USART
一、通信 1.1通信是什么; 通信是将一个设备的数据发送到另一个设备中,从而实现硬件的扩展; 1.2通信的目的是什么; 实现硬件的扩展-在STM32中集成了很多功能,例如PWM输出,AD采集,定时器等&am…...
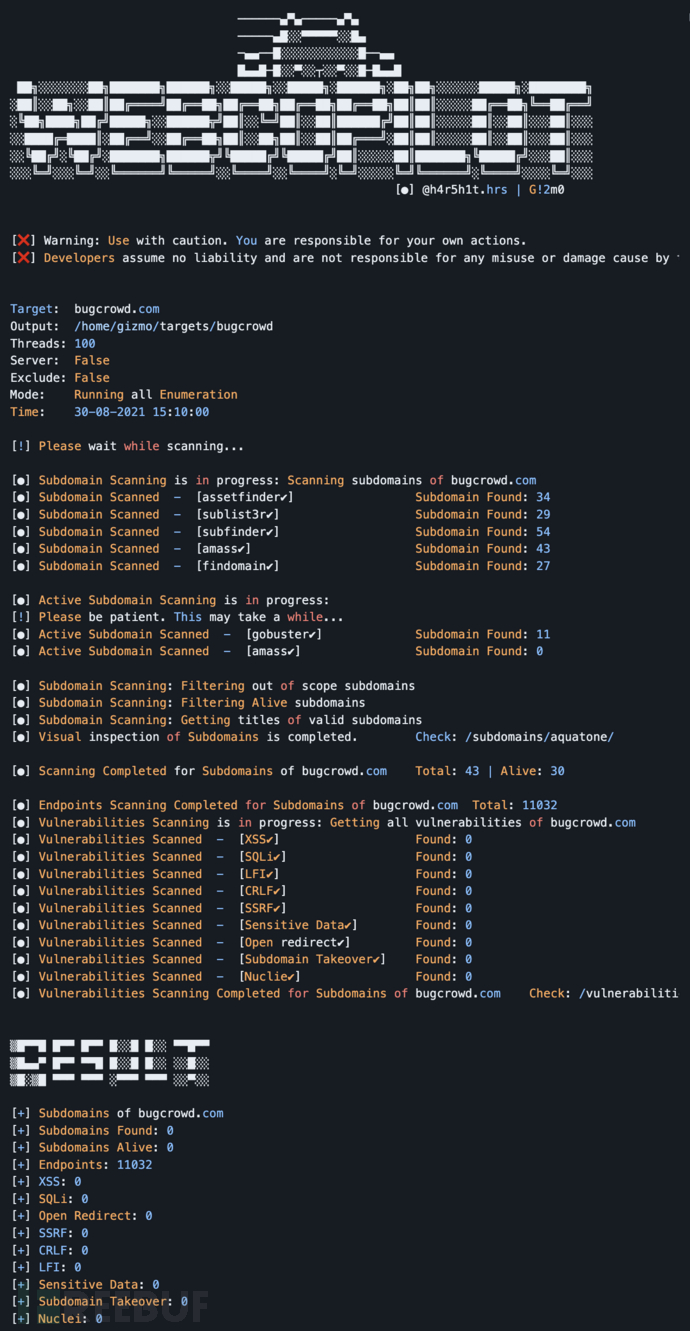
WebCopilot:一款功能强大的子域名枚举和安全漏洞扫描工具
关于WebCopilot WebCopilot是一款功能强大的子域名枚举和安全漏洞扫描工具,该工具能够枚举目标域名下的子域名,并使用不同的开源工具检测目标存在的安全漏洞。 工具运行机制 WebCopilot首先会使用assetsfinder、submaster、subfinder、accumt、finddom…...
HarmonyOS实战开发-如何实现一个支持加减乘除混合运算的计算器。
介绍 本篇Codelab基于基础组件、容器组件,实现一个支持加减乘除混合运算的计算器。 说明: 由于数字都是双精度浮点数,在计算机中是二进制存储数据的,因此小数和非安全整数(超过整数的安全范围[-Math.pow(2, 53)&#…...

每日OJ题_子序列dp⑥_力扣873. 最长的斐波那契子序列的长度
目录 力扣873. 最长的斐波那契子序列的长度 解析代码 力扣873. 最长的斐波那契子序列的长度 873. 最长的斐波那契子序列的长度 难度 中等 如果序列 X_1, X_2, ..., X_n 满足下列条件,就说它是 斐波那契式 的: n > 3对于所有 i 2 < n&#x…...

病毒循环Viral Loop是什么?为何能实现指数增长
一、什么是病毒循环(Viral Loop)? 病毒循环(Viral Loop)是一种机制,它推动连续的推荐以实现持续增长。 它会促使你现有的客户推荐其他人,去认识你的品牌,然后让这些新客户进一步告诉…...
下载huggingface中数据集/模型(保存到本地指定路径)
一. snapshot_download # 1.安装huggingface_hub # pip install huggingface_hubimport osfrom huggingface_hub import snapshot_downloadprint(downloading entire files...) # 注意,这种方式仍然保存在cache_dir中 snapshot_download(repo_id"ibrahimhamam…...
)
Landsat 9 数据预处理第一步:在ENVI里正确加载影像的保姆级指南(含MTL文件处理)
Landsat 9数据预处理全流程:从ENVI加载到分析就绪的完整指南 当第一次拿到Landsat 9数据时,很多遥感新手会卡在最基础的数据加载环节。这就像拿到一把高级门锁的钥匙,却因为不知道正确的插入角度而无法开启后续分析的大门。本文将带你系统掌…...

基于Go + gin+gorm+ rag+千问大模型 + pgvector 构建市场监管智能问答智能体
基于Go 千问大模型 pgvector构建市场监管智能问答智能体 一、项目背景 随着"放管服"改革的深入推进,市场监管领域政策法规不断更新,企业和公众对政策咨询的需求日益增长。传统的政策咨询模式存在响应慢、效率低、准确性差等问题,…...

安路PH1A180 FPGA实战:用米联客FDMA IP搞定DDR视频缓存,附源码调试心得
安路PH1A180 FPGA实战:FDMA IP与DDR视频缓存深度优化指南 在视频处理系统中,FPGADDR架构已成为实时高清视频流处理的标准方案。安路PH1A180凭借其高性能特性,配合米联客FDMA IP核,能够构建稳定高效的视频缓存系统。但在实际工程落…...

探索ROCm:从基础到实践的完整路径
探索ROCm:从基础到实践的完整路径 【免费下载链接】ROCm AMD ROCm™ Software - GitHub Home 项目地址: https://gitcode.com/GitHub_Trending/ro/ROCm ROCm(Radeon Open Compute)是AMD推出的开源GPU计算平台,为高性能计算…...

深入理解Fritzing电路仿真:5个专业级电子设计验证技巧
深入理解Fritzing电路仿真:5个专业级电子设计验证技巧 【免费下载链接】fritzing-app Fritzing desktop application 项目地址: https://gitcode.com/gh_mirrors/fr/fritzing-app Fritzing是一款开源的电子设计自动化(EDA)软件&#x…...

新手避坑指南:安捷伦/是德示波器探头选1MΩ还是50Ω?实测对比告诉你差别有多大
示波器探头阻抗选择实战手册:1MΩ与50Ω的黄金法则 第一次接触示波器时,我犯了个低级错误——用1MΩ探头直接测量射频电路,结果不仅波形畸变成锯齿状,还差点烧毁前端放大器。这个价值3000元的教训让我深刻认识到:探头…...

Joy-Con Toolkit:突破官方限制的任天堂手柄全能控制工具
Joy-Con Toolkit:突破官方限制的任天堂手柄全能控制工具 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 重新定义手柄控制:从消费级到开发级的跨越 Joy-Con控制器作为任天堂Switch的核心…...
)
SD卡 vs SD NAND:SPI模式下性能对比与选型建议(含实测数据)
SD卡 vs SD NAND:SPI模式下性能对比与选型建议(含实测数据) 在智能硬件和消费电子产品的开发过程中,存储方案的选择往往成为硬件工程师面临的关键决策之一。面对市场上琳琅满目的存储器件,如何在性能、成本和可靠性之…...

【AI黑话日日新】什么是大语言模型驱动的代码生成技术?
摘要 生成式人工智能的快速普及,重塑了传统软件开发的全链路流程。大语言模型(LLM)凭借海量语料预训练与深度语义理解能力,成为智能代码生成的核心底座。这项技术打通了自然语言与编程语言的语义壁垒,能够实现代码续写、需求转源码、自动化测试、系统重构等多元化能力,帮…...

为什么最终选 TQUIC:T-Box QUIC 库选型的约束过滤与源码验证
"为什么选 TQUIC?XQUIC 是阿里的,也有 MPQUIC 和 FEC,而且是 C 实现,不是更容易集成吗?"架构师的这个问题,比"为什么不用 quiche"更难回答。quiche 没有 MPQUIC,一句话就能…...