深入探讨分布式ID生成方案

✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨
🎈🎈作者主页: 喔的嘛呀🎈🎈
✨✨ 帅哥美女们,我们共同加油!一起进步!✨✨
目录
引言
一. UUID(Universally Unique Identifier)
二、数据库自增ID
三. 基于Redis的方案
四. Twitter的snowflake算法
五、百度UidGenerator
结语
引言
在分布式系统中,生成唯一标识符(ID)是一个常见的需求。在这篇博客中,我们将介绍几种常见的分布式ID生成方案,包括UUID、Snowflake算法、基于数据库的方案和基于Redis的方案。我们将深入探讨每种方案的原理、优缺点,并提供相应的代码示例。
一. UUID(Universally Unique Identifier)
UUID(Universally Unique Identifier)是一种标准化的128位数字(16字节)格式,通常用32个十六进制数字表示。UUID的目的是让分布式系统中的多个节点生成的标识符在时间和空间上都是唯一的。
UUID通常由以下几部分组成:
- 时间戳:占据前32位,表示生成UUID的时间戳。
- 时钟序列号:占据接下来的16位,保证在同一时刻生成的UUID的唯一性。
- 全局唯一的节点标识符:占据最后的48位,通常是机器的MAC地址。
UUID的生成方法有多种,其中比较常见的是基于当前时间戳和随机数生成。Java中可以使用java.util.UUID类来生成UUID,示例如下:
import java.util.UUID;public class UUIDGenerator {public static void main(String[] args) {UUID uuid = UUID.randomUUID();System.out.println("Generated UUID: " + uuid.toString());}
}
这段代码将生成一个类似于550e8400-e29b-41d4-a716-446655440000的UUID。由于UUID的唯一性和随机性,通常用于分布式系统中的唯一标识符,例如作为数据库表的主键。
二、数据库自增ID
使用数据库的id自增策略,如 MySQL 的 auto_increment。并且可以使用两台数据库分别设置不同
步长,生成不重复ID的策略来实现高可用。
优点:数据库生成的ID绝对有序,高可用实现方式简单
缺点:需要独立部署数据库实例,成本高,有性能瓶颈
在许多关系型数据库中,自增ID是一种常见的用于唯一标识表中记录的方式。下面我将以MySQL为例,介绍如何在数据库中使用自增ID。
首先,我们需要创建一个带有自增ID的表。以下是一个简单的示例表的创建语句:
CREATE TABLE users (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(50) NOT NULL,email VARCHAR(100) NOT NULL
);
在这个例子中,id 列被定义为自增列,并且被指定为主键。每次向表中插入一条记录时,id 列都会自动递增,确保每个记录都有唯一的ID。
接下来,我们可以通过插入数据来演示自增ID的工作原理:
INSERT INTO users (name, email) VALUES ('Alice', 'alice@example.com');
INSERT INTO users (name, email) VALUES ('Bob', 'bob@example.com');
INSERT INTO users (name, email) VALUES ('Charlie', 'charlie@example.com');
查询表中的数据:
SELECT * FROM users;
输出应该类似于:
+----+---------+------------------+
| id | name | email |
+----+---------+------------------+
| 1 | Alice | alice@example.com|
| 2 | Bob | bob@example.com |
| 3 | Charlie | charlie@example.com|
+----+---------+------------------+
每次插入一条记录时,id 列都会自动递增。这就是自增ID的基本工作原理。
三. 基于Redis的方案
Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保
证生成的 ID 肯定是唯一有序的。
优点:不依赖于数据库,灵活方便,且性能优于数据库;数字ID天然排序,对分页或者需要排
序的结果很有帮助。
缺点:如果系统中没有Redis,还需要引入新的组件,增加系统复杂度;需要编码和配置的工作
量比较大。
考虑到单节点的性能瓶颈,可以使用 Redis 集群来获取更高的吞吐量。假如一个集群中有5台
Redis。可以初始化每台 Redis 的值分别是1, 2, 3, 4, 5,然后步长都是 5。
在 Redis 中生成自增 ID 通常可以通过使用 INCR 命令实现。INCR 命令会将存储在指定键中的数字递增 1,并返回递增后的值。你可以利用这个特性来实现一个简单的自增 ID 生成器。以下是一个基本的示例:
import redis.clients.jedis.Jedis;public class RedisIdGenerator {private Jedis jedis;public RedisIdGenerator() {this.jedis = new Jedis("localhost");}public long getNextId(String key) {return jedis.incr(key);}public static void main(String[] args) {RedisIdGenerator idGenerator = new RedisIdGenerator();String key = "my_id_counter";// 使用示例for (int i = 0; i < 5; i++) {long id = idGenerator.getNextId(key);System.out.println("Generated ID: " + id);}}
}
在这个示例中,我们首先创建了一个 RedisIdGenerator 类,该类包含一个 getNextId 方法,用于生成下一个自增 ID。在 main 方法中,我们创建了一个实例,并连续调用 getNextId 方法来生成 ID。
需要注意的是,这只是一个简单的示例。在实际应用中,你可能需要考虑并发访问时的线程安全性,以及如何处理 Redis 连接的创建和关闭等问题。
四. Twitter的snowflake算法
Twitter的Snowflake算法是一种用于生成分布式唯一ID的算法,它可以在分布式系统中生成全局唯一的ID。Snowflake算法的核心思想是将一个64位的long型的ID分成多个部分,包括时间戳、机器ID和序列号。具体来说,Snowflake算法的ID结构如下:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| unused | timestamp | worker ID | sequence
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- 位表示未使用的位,可根据需要保留或用于其他用途。
- 41位表示时间戳,可以表示的时间范围为2^41 / 1000 / 60 / 60 / 24 = 69年左右。
- 10位表示机器ID,可以用来区分不同的机器。
- 12位表示序列号,可以用来区分同一机器同一时间戳内生成的不同ID。
Snowflake算法生成ID的过程如下:
- 获取当前时间戳,单位是毫秒。
- 使用配置的机器ID。
- 如果当前时间戳与上一次生成ID的时间戳相同,则使用序列号加1;否则序列号重置为0。
- 将时间戳、机器ID和序列号合并生成最终的ID。
Snowflake算法的优点是生成的ID是递增的、趋势递增的,并且可以根据需要提取出生成ID的时间戳和机器ID。然而,Snowflake算法也有一些缺点,例如在高并发情况下可能会出现ID重复的情况,需要适当的措施来避免这种情况的发生。
Snowflake 算法是 Twitter 开源的一种分布式唯一 ID 生成算法,用于生成全局唯一的 ID。它的核心思想是将 ID 分为不同的部分,包括时间戳、机器 ID 和序列号。下面是一个详细的实现:
public class SnowflakeIdGenerator {private final long twepoch = 1288834974657L; // 起始时间戳,可以根据实际需求调整private final long workerIdBits = 5L; // 机器 ID 的位数private final long datacenterIdBits = 5L; // 数据中心 ID 的位数private final long maxWorkerId = -1L ^ (-1L << workerIdBits); // 最大机器 IDprivate final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); // 最大数据中心 IDprivate final long sequenceBits = 12L; // 序列号的位数private final long workerIdShift = sequenceBits; // 机器 ID 左移位数private final long datacenterIdShift = sequenceBits + workerIdBits; // 数据中心 ID 左移位数private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; // 时间戳左移位数private final long sequenceMask = -1L ^ (-1L << sequenceBits); // 序列号掩码private long workerId;private long datacenterId;private long sequence = 0L;private long lastTimestamp = -1L;public SnowflakeIdGenerator(long workerId, long datacenterId) {if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException("Worker ID 必须介于 0 和 " + maxWorkerId + " 之间");}if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException("Datacenter ID 必须介于 0 和 " + maxDatacenterId + " 之间");}this.workerId = workerId;this.datacenterId = datacenterId;}public synchronized long nextId() {long timestamp = timeGen();if (timestamp < lastTimestamp) {throw new RuntimeException("时钟回拨发生在 " + (lastTimestamp - timestamp) + " 毫秒内");}if (timestamp == lastTimestamp) {sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0L;}lastTimestamp = timestamp;return ((timestamp - twepoch) << timestampLeftShift)| (datacenterId << datacenterIdShift)| (workerId << workerIdShift)| sequence;}private long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}private long timeGen() {return System.currentTimeMillis();}public static void main(String[] args) {SnowflakeIdGenerator idGenerator = new SnowflakeIdGenerator(1, 1);// 使用示例for (int i = 0; i < 5; i++) {long id = idGenerator.nextId();System.out.println("Generated ID: " + id);}}
}
在这个实现中,我们首先定义了 Snowflake 算法中需要用到的各种参数和位移操作。然后,我们实现了一个 nextId 方法来生成下一个 ID。在 main 方法中,我们创建了一个 SnowflakeIdGenerator 实例,并连续调用 nextId 方法来生成 ID。
需要注意的是,Snowflake 算法中的时间戳部分可以根据实际需求进行调整,以确保生成的 ID 在不同时间内仍然是唯一的。
五、百度UidGenerator
百度的 UIDGenerator 是一个分布式唯一 ID 生成器,类似于 Twitter 的 Snowflake 算法,但在细节上有所不同。以下是一个简化的实现,展示了其基本原理:
import java.util.concurrent.atomic.AtomicLong;public class BaiduUidGenerator {private final long twepoch = 1288834974657L; // 起始时间戳,可以根据实际需求调整private final long workerIdBits = 10L; // 机器 ID 的位数private final long sequenceBits = 12L; // 序列号的位数private final long workerIdShift = sequenceBits; // 机器 ID 左移位数private final long timestampLeftShift = sequenceBits + workerIdBits; // 时间戳左移位数private final long sequenceMask = -1L ^ (-1L << sequenceBits); // 序列号掩码private final long workerId;private volatile long lastTimestamp = -1L;private volatile long sequence = 0L;public BaiduUidGenerator(long workerId) {if (workerId < 0 || workerId >= (1 << workerIdBits)) {throw new IllegalArgumentException("Worker ID 必须介于 0 和 " + ((1 << workerIdBits) - 1) + " 之间");}this.workerId = workerId;}public synchronized long nextId() {long timestamp = timeGen();if (timestamp < lastTimestamp) {throw new RuntimeException("时钟回拨发生在 " + (lastTimestamp - timestamp) + " 毫秒内");}if (timestamp == lastTimestamp) {sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0L;}lastTimestamp = timestamp;return ((timestamp - twepoch) << timestampLeftShift)| (workerId << workerIdShift)| sequence;}private long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}private long timeGen() {return System.currentTimeMillis();}public static void main(String[] args) {BaiduUidGenerator uidGenerator = new BaiduUidGenerator(1);// 使用示例for (int i = 0; i < 5; i++) {long id = uidGenerator.nextId();System.out.println("Generated ID: " + id);}}
}
在这个实现中,我们首先定义了 BaiduUidGenerator 类,其中包含了与 Snowflake 算法类似的参数和位移操作。然后,我们实现了一个 nextId 方法来生成下一个 ID。在 main 方法中,我们创建了一个 BaiduUidGenerator 实例,并连续调用 nextId 方法来生成 ID。
需要注意的是,这只是一个简化的实现,实际应用中可能需要根据具体需求进行调整和优化。
结语
以上是几种常见的分布式ID生成方案,每种方案都有其适用的场景,开发人员可以根据实际需求选择合适的方案。
相关文章:
深入探讨分布式ID生成方案
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨ 🎈🎈作者主页: 喔的嘛呀🎈🎈 ✨✨ 帅哥美女们,我们共同加油!一起进步&am…...

花钱的艺术:消费和投资如何分配
消费是钱花出去就回不来了。 消费分为可选消费和必需消费。 必需消费是必须花的钱,用一句老话,财米油盐酱醋茶,维持生活必需的支出。 可选消费,用来提升生活水平的支出,可花可不花,比如苹果手机…...

git 代码库查看方法
在Git中,你可以使用多种命令来查看代码库(repository)的内容。以下是一些常用的命令: 查看所有分支: git branch这个命令会列出本地仓库中的所有分支。当前活动的分支前面会有一个星号(*)。 查…...

MySql的下载与安装
window系统: 下载MySQL 8.0 访问MySQL官方网站: 打开浏览器,输入网址 https://dev.mysql.com/downloads/mysql/ 进入MySQL下载页面。 选择版本: 在网页中找到“MySQL Community Server”部分,这通常是最新的社区版&am…...

python学习17:python中的while循环
python中的while循环 1.循环的作用就是:重复运行某些代码 2.while循环: 1.while的条件必须是布尔类型的 True表示继续循环,False表示结束循环 2.必须设置循环结束条件,否则将会无限循环 ,如下的count<10 如果coun…...

Android中的导航navigation的使用
Android中的导航(Navigation)是一种应用程序设计模式,它通过使用统一的用户界面来管理应用程序中的各种界面和交互。在Android中,导航主要通过使用Navigation SDK来实现,该SDK提供了一组工具和组件,可以帮助…...

Clip算法解读
论文地址:https://arxiv.org/pdf/2103.00020.pdf 代码地址:https://github.com/OpenAI/CLIPz 中文clip代码:https://gitcode.com/OFA-Sys/Chinese-CLIP/overview 一、动机 主要解决的问题: 超大规模的文本集合训练出的 NLP 模…...
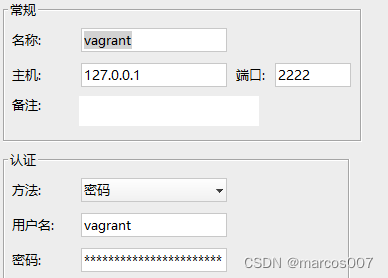
使用第三方远程连接工具ssh连接vagrant创建的虚拟机
vagrant默认密码都是vagrant 密码认证默认是关闭的,进入虚拟机,打开密码认证 1、使用命令vi /etc/ssh/sshd_config进入配置,注意要切换到root用户,这个配置root有权限 2、找到PasswordAuthentication默认为no,改为yes 3、重启虚…...
linux查找指定目录下包含指定字符串文件,包含子目录
linux查找指定目录下包含指定字符串的文件,包含子目录 linux查找指定目录下包含指定字符串的指定文件格式,包含子目录 指定目录 cd /home/www/linux查找指定目录下包含指定字符串的文件,包含子目录 grep -r "指定字符串"注释 gr…...
27. BI - PageRank 的那些相关算法 - PersonRank, TextRank, EdgeRank
本文为 「茶桁的 AI 秘籍 - BI 篇 第 27 篇」 Hi, 我是茶桁. 之前咱们用两节课的时间来讲了 PageRank, 包括它的起源, 公式以及工具. 并在一个希拉里邮件的案例中用networkx完成了练习. 在上一节课中, 咱们不仅做了案例, 并且说到了 PageRank 模型的影响力, 并且讲了其中一个…...

[数据集][目标检测]公共场所危险物品检测数据集VOC+YOLO格式1431张6类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1431 标注数量(xml文件个数):1431 标注数量(txt文件个数):1431 标注…...
)
创业项目开发(持续更新)
最近项目梳理: 一、业务目标 最重要的业务目标就是要能实现自己做事情赚钱。所以有两个维度,第一个维度就是最重要的就是自己做事情。第二个维度才是赚钱。 如果要自己做事情,需要什么样的事情,这个事情的目标是什么࿰…...

基于SpringBoot的“校园台球厅人员与设备管理系统”的设计与实现(源码+数据库+文档+PPT)
基于SpringBoot的“校园台球厅人员与设备管理系统”的设计与实现(源码数据库文档PPT) 开发语言:Java 数据库:MySQL 技术:SpringBoot 工具:IDEA/Ecilpse、Navicat、Maven 系统展示 系统功能结构图 系统首页界面图…...
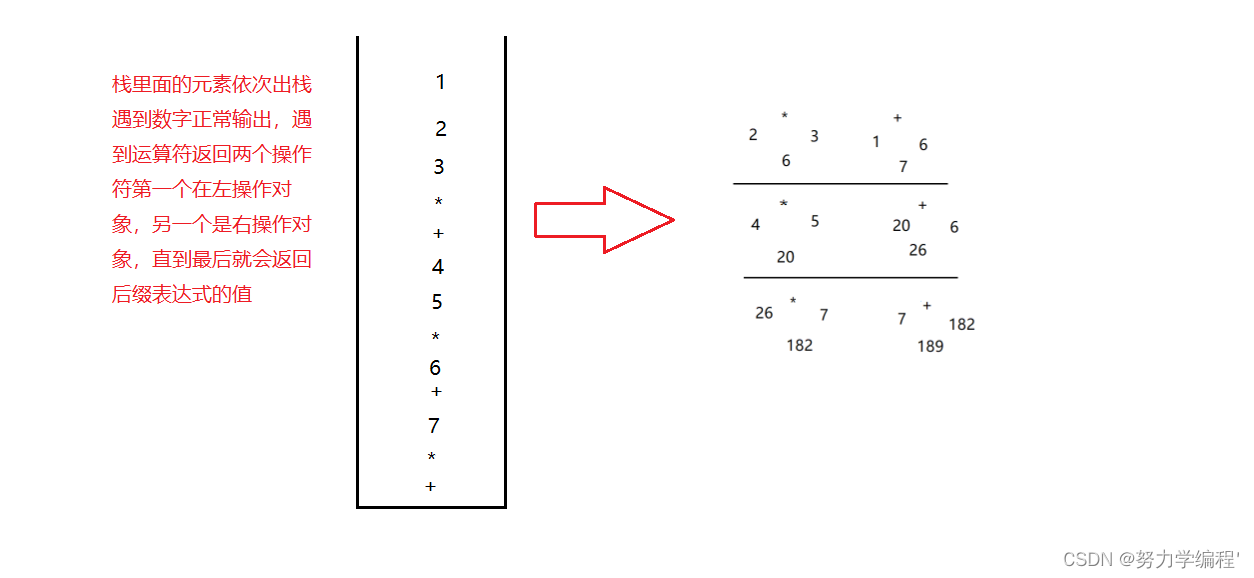
【Java数据结构】关于栈的操作出栈,压栈,中缀表达式,后缀表达式,逆波兰表达式详解
🔥个人主页:努力学编程’ 🔥内容管理:java数据结构 上一篇文章我们讲过了java数据结构的链表,对于链表我们使用了它的一些基本操作,完成了扑克牌小游戏的操作,如果你感兴趣的话,点…...
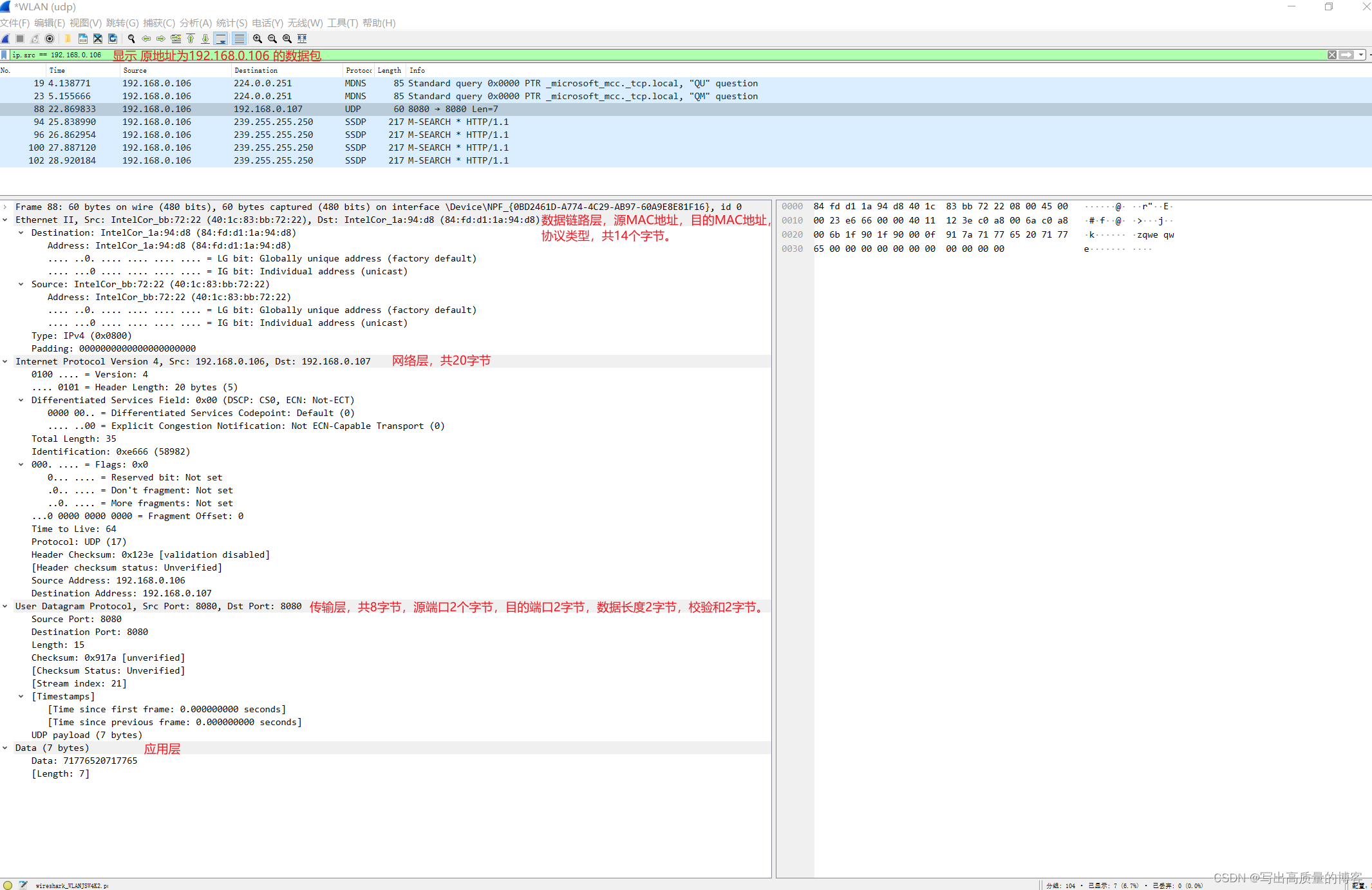
wireshark 使用
wireshark介绍 wireshak可以抓取经过主机网卡的所有数据包(包括虚拟机使用的虚拟网卡的数据包)。 环境安装 安装wireshark: https://blog.csdn.net/Eoning/article/details/132141665 安装网络助手工具:https://soft.3dmgame.com/down/213…...

C++纯虚函数的使用
纯虚函数是一种在C中定义抽象基类的方法,它是一个在基类中声明但没有实现的虚函数。 纯虚函数需要在派生类中进行实现,否则派生类也会成为抽象类,无法直接实例化对象。 下面是关于纯虚函数的讲解和代码示例: 纯虚函数的定义&#…...
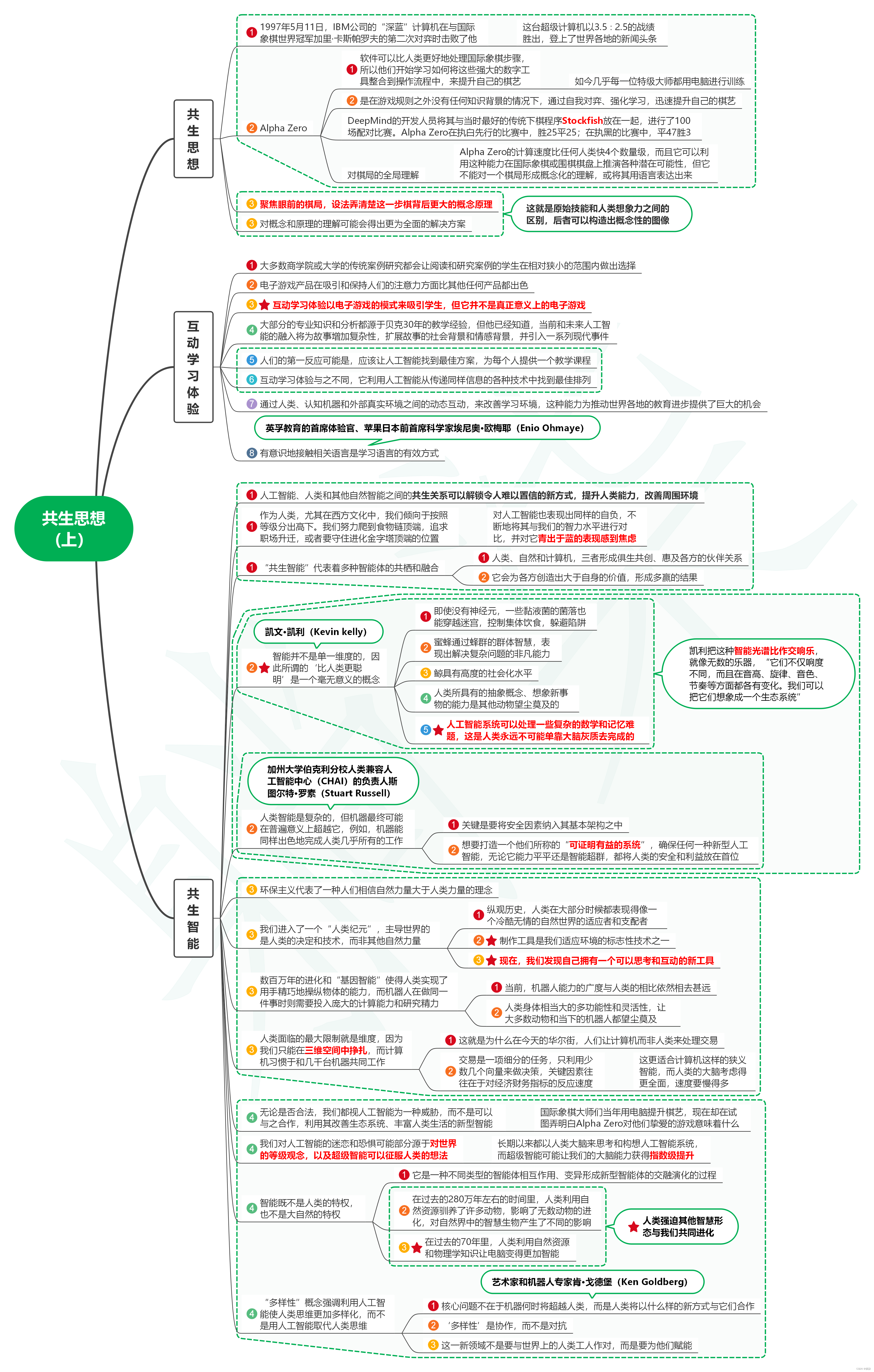
读所罗门的密码笔记06_共生思想(上)
1. 共生思想 1.1. 1997年5月11日,IBM公司的“深蓝”计算机在与国际象棋世界冠军加里卡斯帕罗夫的第二次对弈时击败了他 1.1.1. 这台超级计算机以3.5∶2.5的战绩胜出,登上了世界各地的新闻头条 1.2. Alpha Zero 1.2.…...
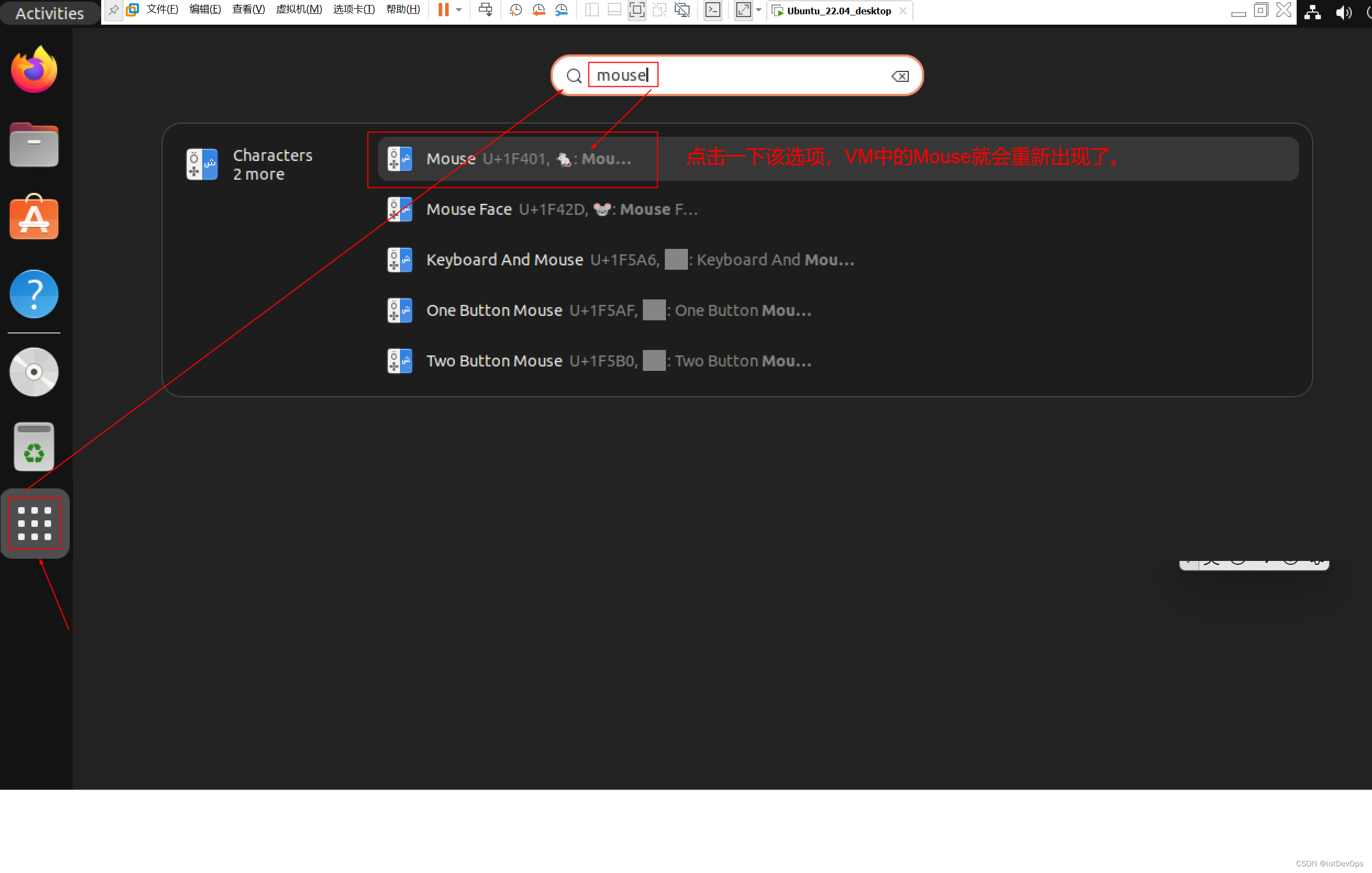
QA:ubuntu22.04.4桌面版虚拟机鼠标丢失的解决方法
前言 在Windows11中的VMWare Workstation17.5.1 Pro上安装了Ubuntu22.04.4,在使用过程中发现,VM虚拟机的鼠标的光标会突然消失,但鼠标其他正常,就是光标不见了,下面是解决办法。 内容 如下图,输入mouse&a…...

idea从零开发Android 安卓 (超详细)
首先把所有的要准备的说明一下 idea 2023.1 什么版本也都可以操作都是差不多的 gradle 8.7 什么版本也都可以操作都是差不多的 Android SDK 34KPI 下载地址: AndroidDevTools - Android开发工具 Android SDK下载 Android Studio下载 Gradle下载 SDK Tools下载 …...
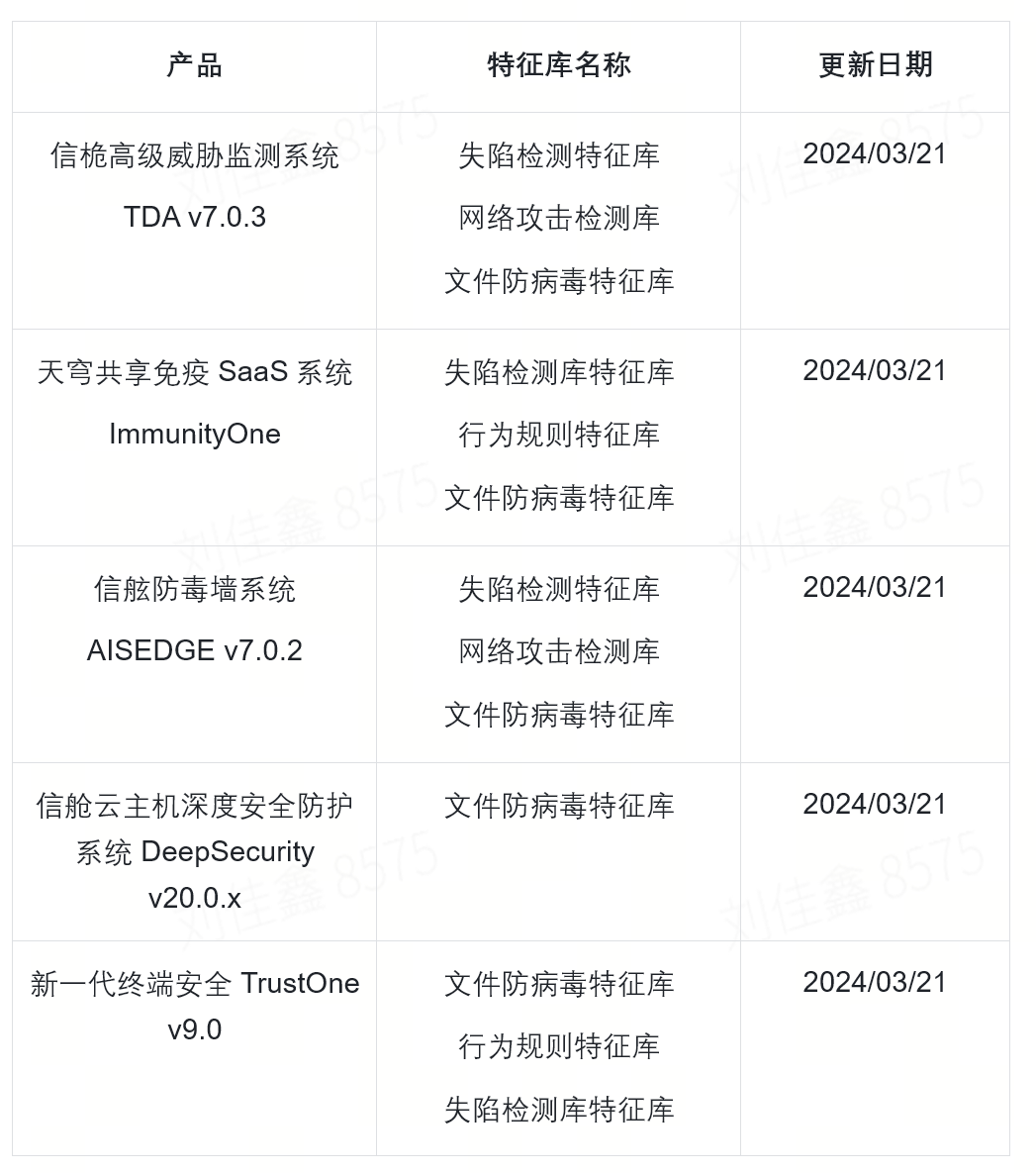
1.5T数据惨遭Lockbit3.0窃取,亚信安全发布《勒索家族和勒索事件监控报告》
本周态势快速感知 本周全球共监测到勒索事件93起,近三周攻击数量呈现持平状态。 本周Lockbit3.0是影响最严重的勒索家族,Blacksuit和Ransomhub恶意家族紧随其后,从整体上看Lockbit3.0依旧是影响最严重的勒索家族,需要注意防范。 …...

文字识别OCR 在线工具 vs OCR API 接口平台:普通用户和开发者该怎么选?
随着 AI 发展,OCR 已经成了办公、学习、开发必备工具。 但现在市面上的 OCR 工具大致分两类: 在线 OCR 网站(网页直接用) OCR API 接口平台(系统对接用) 很多人不知道该怎么选,我从【普通用…...

突破性分子动力学自由能计算工具:gmx_MMPBSA技术深度解析与实战指南
突破性分子动力学自由能计算工具:gmx_MMPBSA技术深度解析与实战指南 【免费下载链接】gmx_MMPBSA gmx_MMPBSA is a new tool based on AMBERs MMPBSA.py aiming to perform end-state free energy calculations with GROMACS files. 项目地址: https://gitcode.co…...

基于九轴传感器 + K-means 聚类的振动异常检测实战教程
(嵌入式 / 工业监测场景:设备振动、电机故障、结构松动、碰撞异常实时检测)一、前言(你能学到什么)这篇文章不讲虚的,直接带你做一个工业级轻量异常检测系统:用 LSM6DS3TR-C(6 轴&am…...

嘎嘎降AI和去AIGC哪个更适合文科论文?深度对比评测
嘎嘎降AI和去AIGC哪个更适合文科论文?深度对比评测 选降AI工具看三点:达标率、价格、处理后文本质量。 按这标准我花了一周研究主流工具。结论先说:嘎嘎降AI(www.aigcleaner.com)最适合大多数人——4.8元一篇&#x…...

如何通过GDScript游戏开发入门成为独立游戏开发者
如何通过GDScript游戏开发入门成为独立游戏开发者 【免费下载链接】learn-gdscript Learn Godots GDScript programming language from zero, right in your browser, for free. 项目地址: https://gitcode.com/gh_mirrors/le/learn-gdscript 对于许多游戏爱好者来说&am…...

echarts环形饼图自定义边框、标题及图例
目录 1、官网找示例 2、初步改造有个雏形 3、细节改造和优化 4、全部代码 5、原始效果和最终效果对比 看下效果图,和普通的饼图很明显的区别就是: 1有明显的白色边框线 2圆环中心自定义内容标题 3需要设置图例位置与内容 我通常的实现思路就是官网找例子再一步一步改…...

AA-PEG-C12/C16/C18,乙酸聚乙二醇月桂/棕榈/硬脂酸酯,一类结合了乙酸、聚乙二醇和长链烷基的化合物
一.名称英文名称:AA-PEG-C12/C16/C18,Acetic Acid-PEG-C12/C16/C18中文名称:乙酸聚乙二醇月桂/棕榈/硬脂酸酯,乙酸-PEG-月桂/棕榈/硬脂酸酯分子量:1k,2k,3.4k,5k,10k&…...

考研408计算机学科专业基础——计算机组成原理复习
考研408计算机学科专业基础——计算机组成原理复习 核心说明:本笔记聚焦考研408计算机组成原理(计组)高频考点、必背知识点,贴合命题规律(选择大题),剔除冗余内容,突出重难点&#x…...

mysql备份工具选择_mysqldump对InnoDB与MyISAM支持
mysqldump默认对MyISAM用表级锁、InnoDB不启用事务快照,混合引擎必须用--lock-all-tables保证一致性,且需确保REPEATABLE READ隔离级别和ROW/MIXED binlog格式。mysqldump 默认行为对 InnoDB 和 MyISAM 完全不同默认不加任何参数时,mysqldump…...

Jetson Orin Nano环境搭建避坑实录:从JetPack到PyQt5,我踩过的那些‘坑’都帮你填平了
Jetson Orin Nano环境搭建避坑实录:从JetPack到PyQt5的实战指南 第一次拿到Jetson Orin Nano这块开发板时,我天真地以为按照官方文档就能轻松搞定所有环境配置。结果从JetPack安装到PyQt5编译,几乎每一步都遇到了意想不到的问题。这篇文章不会…...