Redis中的serverCron函数(一)
serverCron函数
Redis服务器中的serverCron函数默认每隔100毫秒执行一次,这个函数负责管理服务器的资源,并保持服务器自身的良好运转。
更新服务器时间缓存
Redis服务器中有不少功能需要获取系统的当前时间,而每次获取系统的当前时间都需要执行一次系统调用,为了减少系统调用的执行次数,服务器状态中的unixtime属性和mstime属性被用作当前时间的缓存:
struct redisServer {// ...// 保存了秒级精度的系统当前UNIX时间戳time_t unixtime;// 保存了毫秒级精度的系统当前UNIX时间戳long long mstime;// ....
};
因为serverCron函数默认会以每100毫秒一次的频率更新unixtime属性和mstime属性,所以这两个属性记录的时间的精确度并不高:
- 1.服务器只会在打印日志、更新服务器的LRU时钟、决定是否执行持久化任务、计算服务器上线时间(uptime)这类对事件精确度要求不高的功能上"使用unixtime属性和mstime属性"。
- 2.对于为键设置过期事件、添加慢查询日志这种需要高精确度时间的功能来说,服务器还是会再执行系统调用,从而获得最准确的系统当前时间
更新LRU时钟。
服务器状态中的lruclock属性保存了服务器的LRU时钟,这个属性和unixtime属性、mstime属性一样,都是服务器时间缓存的一种:
struct redisServer {// ...// 默认每10秒更新一次的时钟缓存// 用于计算键的空转(idle)时长unsigned lruclock:22;// ...
};
每个Redis对象都会有一个lru属性,这个lru属性保存了对象最后一次被命令访问的时间:
typedef struct redisObject {// ...unsigned lru:22;//...
} robj;
当服务器要计算一个数据库键的空转时间(也即是数据库键对应的值对象的空转时间),程序会用服务器的lruclock属性记录的时间减去对象的lru属性记录的时间,得出的计算结果就是这个对象的空转时间:
127.0.0.1:6379> SET msg "hello world"
OK
# 等待一小段时间
127.0.0.1:6379> OBJECT IDLETIME msg
(integer) 13
# 等待一阵子
127.0.0.1:6379> OBJECT IDLETIME msg
(integer) 19
# 访问msg键的值
127.0.0.1:6379> GET msg
"hello world"
# 键处于活跃状态,空转时长为2
127.0.0.1:6379> OBJECT IDLETIME msg
(integer) 2
serverCron函数默认会以每10秒一次的频率更新lruclock属性的值,因为这个时钟不是实时的,所以根据这个属性计算出来的LRU时间实际上只是一个模糊的估算值。lruclock时钟的当前值可以通过INFO server命令的
lru_clock域查看:
```c
127.0.0.1:6379> info server
# Server
redis_version:3.0.504
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:a4f7a6e86f2d60b3
redis_mode:standalone
os:Windows
arch_bits:64
multiplexing_api:WinSock_IOCP
process_id:5512
run_id:87544bbfd0b6ddf6c7168be02719f23b94c97a96
tcp_port:6379
uptime_in_seconds:95307
uptime_in_days:1
hz:10
lru_clock:581331
config_file:E:\redis\redis.windows-service.conf
更新服务器每秒执行命令次数
serverCron函数中的trackOperationPerSecond函数会以每100毫秒一次的频率执行,这个函数的功能是以抽样计算的方式,估算并记录服务器在最近一秒钟处理的命令请求数量,这个值可以通过INFO stats命令 的
instantaneous_ops_per_sec域查看:
127.0.0.1:6379> info stats
# Stats
total_connections_received:3
total_commands_processed:16
instantaneous_ops_per_sec:0
total_net_input_bytes:542
total_net_output_bytes:2417
instantaneous_input_kbps:0.00
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
evicted_keys:0
keyspace_hits:1
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:69502
migrate_cached_sockets:0
上面命令的结果显示中,在最近的一秒钟内,服务器没有处理命令。
trackOperationPerSecond函数和服务器状态中四个ops_sec开头的属性有关:
struct redisServer {// ...// 上一次进行抽样的时间long long ops_sec_last_sample_time;// 上一次抽样时,服务器已执行命令的数量long long ops_sec_last_sample_ops;// REDIS_OPS_SEC_SAMPLE 大小(默认值为16)的环形数组long long ops_sec_sample[REDIS_OPS_SEC_SAMPLES];// ops_sec_sample数组的索引值// 每次抽样后将值增一// 再值等于16时重置为0// 让ops_sec_samples数组构成一个唤醒数组int opts_sec_ids;// ...
}
trackOperationsPerSecond函数
每次运行,都回根据ops_sec_last_sample_time记录的上一次抽样时间和服务器的当前时间,以及ops_sec_last_sample_ops记录的上一次抽样的已执行命令数量和服务器当前的已执行命令数量,计算出两次trackOperationsPerSecond调用之间,服务器平均每一毫秒处理了多少个命令请求,然后将这个平均值
乘以1000,这就得到了服务器在一秒钟内处理多少个命令请求的估计值,这个估计值会被作为一个新的数组项被放进ops_sec_samples唤醒数组里面。当客户端执行INFO命令时,服务器就会调用getOperationsPerSecond函数,根据ops_sec_samples唤醒数组中的抽样结果,计算出instantaneous_ops_per_sec属性的值,
getOperationsPerSecond函数
以下是getOperationsPerSecond函数的实现代码:
long long getOperationsPerSecond(void) {int j;long long sum = 0;// 计算所有取样值综合for (j = 0; j < REDIS_OPS_SEC_SAMPLES; j++) {sum += server.ops_sec_samples[j];}// 计算取样的平均值return sum / REDIS_OPS_SEC_SAMPLES;
}
根据getOperationsPerSeoncd函数的定义可以看出,instantaneous_ops_per_sec
属性的值是通过计算最近REDIS_OPS_SEC_SAMPLES次取样的平均值来计算得出的,它只是一个估算值。
相关文章:
)
Redis中的serverCron函数(一)
serverCron函数 Redis服务器中的serverCron函数默认每隔100毫秒执行一次,这个函数负责管理服务器的资源,并保持服务器自身的良好运转。 更新服务器时间缓存 Redis服务器中有不少功能需要获取系统的当前时间,而每次获取系统的当前时间都需要…...
)
python保存中间变量(学习笔记)
python保存中间变量 原因: 最近在部署dust3r算法,虽然在本地部署了,也能测试出一定的结果,但是发现无法跑很多图片,为了能够测试多张图片跑出来的模型,于是就在打算在autodl上部署算法,但是由…...

CTF wed安全(攻防世界)练习题
一、Training-WWW-Robots 进入网站如图: 翻译:在这个小小的挑战训练中,你将学习Robots exclusion standard。网络爬虫使用robots.txt文件来检查它们是否被允许抓取和索引您的网站或只是其中的一部分。 有时这些文件会暴露目录结构,…...

计算机网络链路层
数据链路 链路是从一个节点到相邻节点之间的物理线路(有线或无线) 数据链路是指把实现协议的软件和硬件加到对应链路上。帧是点对点信道的数据链路层的协议数据单元。 点对点信道 通信的主要步骤: 节点a的数据链路层将网络层交下来的包添…...

VUE3——reactive对比ref
从定义数据角度对比: 。ref用来定义:基本类型数据 。reactive用来定义:对象(或数组)类型数据。 。备注:ref也可以用来定义对象(或数组)类型数据,它内部会自动通过 reactive 转为代理对象。 从原理角度对比: 。ref通过 object.defineProperty()的 get 与set 来实现响应式(数据劫…...

广场舞团系统的设计与实现|Springboot+ Mysql+Java+ B/S结构(可运行源码+数据库+设计文档)
本项目包含可运行源码数据库LW,文末可获取本项目的所有资料。 推荐阅读100套最新项目持续更新中..... 2024年计算机毕业论文(设计)学生选题参考合集推荐收藏(包含Springboot、jsp、ssmvue等技术项目合集) 目录 1. 系…...
经典永不过时 Wordpress模板主题
经得住时间考验的模板,才是经典模板,带得来客户的网站,才叫NB网站。 https://www.jianzhanpress.com/?p2484...
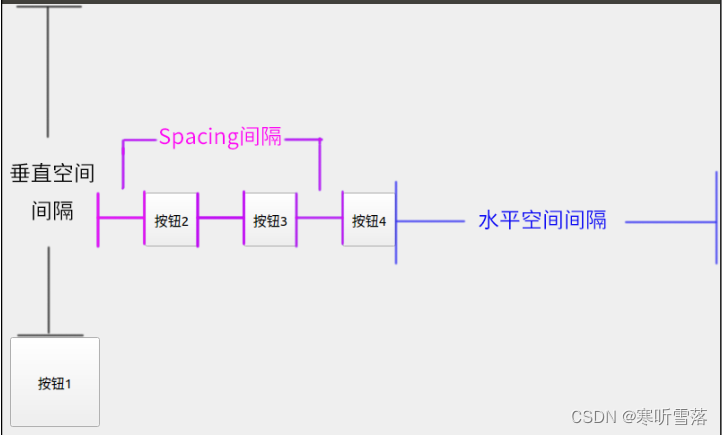
QT布局管理和空间提升为和空间间隔
QHBoxLayout:按照水平方向从左到右布局; QVBoxLayout:按照竖直方向从上到下布局; QGridLayout:在一个网格中进行布局,类似于HTML的table; 基本布局管理类包括:QBoxLayout、QGridL…...
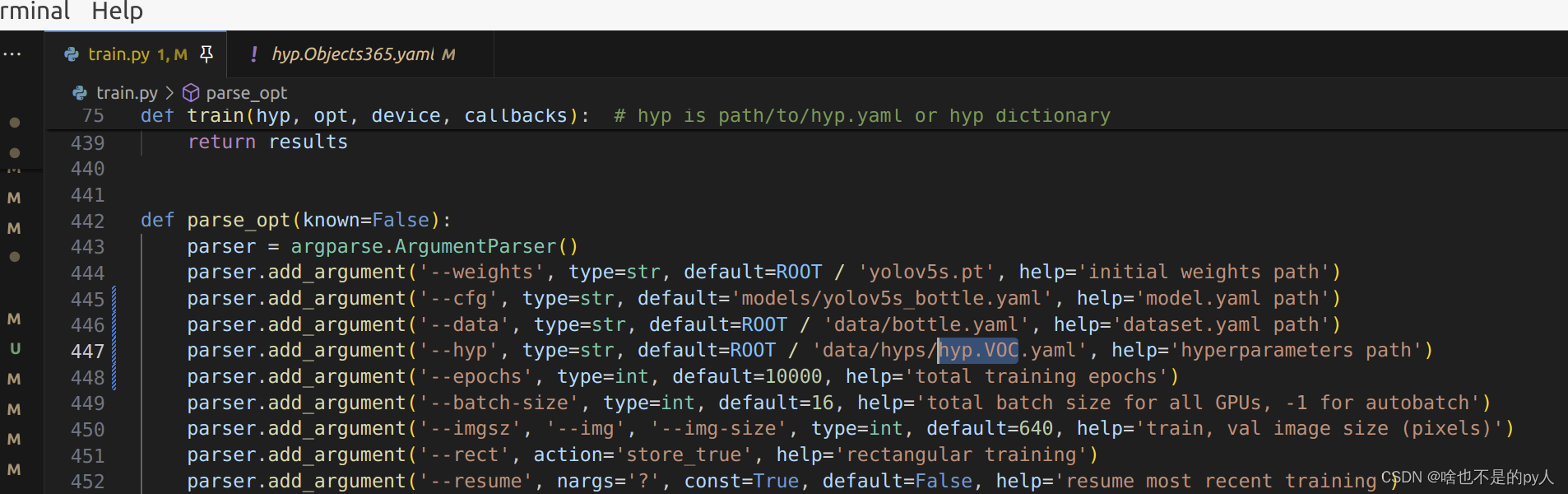
Yolo 自制数据集dect训练改进
上一文请看 Yolo自制detect训练-CSDN博客 简介 如下图: 首先看一下每个图的含义 loss loss分为cls_loss, box_loss, obj_loss三部分。 cls_loss用于监督类别分类,计算锚框与对应的标定分类是否正确。 box_loss用于监督检测框的回归,预测框…...

vlan间单臂路由
【项目实践4】 --vlan间单臂路由 一、实验背景 实验的目的是在一个有限的网络环境中实现VLAN间的通信。网络环境包括两个交换机和一个路由器,交换机之间通过Trunk链路相连,路由器则连接到这两个交换机的Trunk端口上。 二、案例分析 在网络工程中&#…...

day4 linux上部署第一个nest项目(java转ts全栈/3R教室)
背景:上一篇吧nest-vben-admin项目,再开发环境上跑通了,并且build出来了dist文件,接下来再部署到linux试试吧 dist文件夹是干嘛的? 一个pnpn install 直接生成了两个dist文件夹,前端admin项目一个…...
学会这几点,是搭建产品知识库的关键
现如今,企业都特别看重产品知识库,因为有了它,企业就能更好地管理产品信息,提升客户服务水平,还能帮企业做决策。但是,搭建一个好用、高效的产品知识库,也难倒了不少人。下面,我们一…...

MySql 常用的聚合函数总结
MySQL 中的聚合函数用于对一组数据进行计算,并返回单个值作为结果。以下是常用的 MySQL 聚合函数的总结及其功能描述: 1. COUNT() 功能:用于计算指定列或表中的行数。 语法: COUNT(*) COUNT(expression) 示例: SELECT …...

Charles for Mac 强大的网络调试工具
Charles for Mac是一款功能强大的网络调试工具,可以帮助开发人员和测试人员更轻松地进行网络通信测试和调试。以下是一些Charles for Mac的主要特点: 软件下载:Charles for Mac 4.6.6注册激活版 流量截获:Charles可以截获和分析通…...
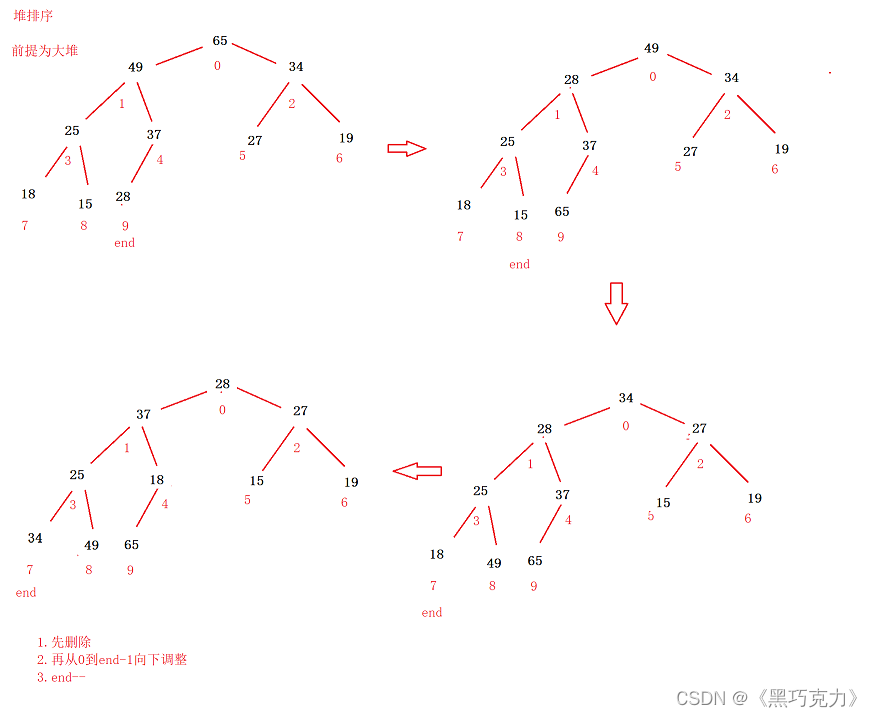
【数据结构】优先级队列——堆
🧧🧧🧧🧧🧧个人主页🎈🎈🎈🎈🎈 🧧🧧🧧🧧🧧数据结构专栏🎈🎈🎈&…...

【力扣】45.跳跃游戏Ⅱ
45.跳跃游戏Ⅱ 给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处: 0 < j < nums[i]i j < n 返回到达 n…...

containerd使用了解
containerd使用了解 yum安装 [rootvm ~]# curl -o /etc/yum.repos.d/docker.repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo [rootvm ~]# yum list | grep containerd containerd.io.x86_64 1.6.28-3.1.el7 doc…...

gateway 分发时若两个服务的路由地址一样,怎么指定访问想要的服务下的地址
1.思路 在使用Spring Cloud Gateway时,如果两个服务的路由地址相同,可以通过Predicate(断言)和Filter(过滤器)的组合来实现根据请求的不同条件将请求分发到不同的服务下的地址。 使用Predicate进行路由条件…...

【LeetCode】三月题解
文章目录 [2369. 检查数组是否存在有效划分](https://leetcode.cn/problems/check-if-there-is-a-valid-partition-for-the-array/)思路:代码: [1976. 到达目的地的方案数](https://leetcode.cn/problems/number-of-ways-to-arrive-at-destination/) 思路…...

云手机:实现便携与安全的双赢
随着5G时代的到来,云手机在各大游戏、直播和新媒体营销中扮演越来越重要的角色。它不仅节约了成本,提高了效率,而且在边缘计算和云技术逐渐成熟的背景下,展现出了更大的发展机遇。 云手机的便携性如何? 云手机的便携性…...

利用示波器直方图功能低成本测量信号抖动的方法与实践
1. 项目概述:用直方图低成本测量抖动在嵌入式系统、高速数字接口乃至电机控制的设计与调试中,信号抖动(Jitter)的测量和分析是一个绕不开的坎。无论是为了确保通信链路的误码率,还是为了验证时钟信号的纯净度ÿ…...
)
Nature论文检索正在失效,Perplexity底层检索逻辑重构预警(仅限科研骨干内部流通的3条技术简报)
更多请点击: https://intelliparadigm.com 第一章:Nature论文检索正在失效,Perplexity底层检索逻辑重构预警(仅限科研骨干内部流通的3条技术简报) 检索信号衰减的实证观测 近期对Nature、Science主站及PubMed Centra…...

Maya-glTF插件深度解析:现代3D工作流中的glTF 2.0导出技术内幕
Maya-glTF插件深度解析:现代3D工作流中的glTF 2.0导出技术内幕 【免费下载链接】maya-glTF glTF 2.0 exporter for Autodesk Maya 项目地址: https://gitcode.com/gh_mirrors/ma/maya-glTF 在当今3D内容创作领域,Maya作为行业标准工具,…...

Python 爬虫数据处理:特殊格式文档爬虫解析处理
前言 在 Python 爬虫规模化采集业务中,除常规 HTML 网页与 JSON 接口数据外,经常会遇到各类非网页型特殊格式文档资源,常见包含 PDF、Word、Excel、CSV、TXT、压缩包内嵌文档、Base64 加密文档、富文本混合格式文档等。这类文档无法通过常规…...

企业采购AI升级:需求驱动的智能供应商匹配实战
工业数字化与 AI 技术深度融合的当下,传统采购招标模式的短板愈发凸显。众多 Java 架构的企业采购系统仍停留在人工化、经验化运营阶段,供应商管理效率低、匹配精准度不足、人力成本居高不下。依托JBoltAI企业级 Java AI 应用开发框架所倡导的 AIGS 人工…...

ClickHouse性能优化:OLAP数据库实战,让查询飞起来
**作者:洛水石** | **更新日期:2026-05-11** | **标签:ClickHouse | OLAP | 数据库优化 | 大数据**前言上个月,运营同学找我抱怨:每天凌晨的报表查询要等5分钟才能出来,数据量大的时候直接超时。作为DBA&am…...

三维动画课程期末复盘:从零搭建我的马卡龙童话游乐场✨
当我按下 3ds Max 的渲染按钮,看着浅蓝的摩天轮缓缓转动、粉白的旋转木马跟着节奏起舞、淡紫色热气球轻轻飘动时,我才真正意识到:为期一学期的三维动画课程,就这样在我的指尖落下了帷幕。从刚打开软件连工具栏都认不全的 “小白”…...

C++ 特殊成员函数详解:构造、析构、拷贝与移动
C 特殊成员函数详解:构造、析构、拷贝与移动 目录 概述基础成员函数 默认构造函数虚析构函数 拷贝操作 拷贝构造函数拷贝赋值运算符 移动操作(C11) 移动构造函数移动赋值运算符 常见问题解析 为什么拷贝参数是 const T&?为什…...

C# 从零开发 MCP 工具基础教程
在C#编程领域,MCP(Managed Code Programming,托管代码编程)工具能极大提升开发效率与代码管理能力。无论是代码分析、自动化构建,还是调试辅助,一款实用的MCP工具都能成为开发者的得力助手。本教程将带你从…...

应用间自动化网关:构建私有化、可编程的跨平台工作流中枢
1. 项目概述与核心价值最近在折腾一些跨平台、跨设备的自动化流程,发现一个痛点:不同应用、不同服务之间的数据流转,经常需要手动“搭桥”。比如,想把手机上的一个链接快速推送到电脑上处理,或者把某个文档从A服务同步…...