【论文阅读】DETR 论文逐段精读
【论文阅读】DETR 论文逐段精读
文章目录
- 【论文阅读】DETR 论文逐段精读
- 📖DETR 论文精读【论文精读】
- 🌐前言
- 📋摘要
- 📚引言
- 🧬相关工作
- 🔍方法
- 💡目标函数
- 📜模型结构
- ⚙️代码
- 📌实验
参考跟李沐学AI: 精读DETR
📖DETR 论文精读【论文精读】
🌐前言
目标检测领域:从目标检测开始火到 detr 都很少有端到端的方法,大部分方法最后至少需要后处理操作(NMS, non-maximum suppression 非极大值抑制)。有了 NMS,模型调参就会很复杂,而且即使训练好了一个模型,部署起来也非常困难(NMS 不是所有硬件都支持)。
📋摘要
贡献:把目标检测做成一个端到端的框架,把之前特别依赖人的先验知识的部分删掉了(NMS 部分、anchor)。
DETR提出:
- 新的目标函数,通过二分图匹配的方式,强制模型输出一组独一无二的预测(没有那么多冗余框,每个物体理想状态下就会生成一个框)
- 使用 encoder-decoder 的架构
两个小贡献:
- decoder 还有另外一个输入
learned object query,类似 anchor 的意思
(给定这些object query之后,detr就可以把learned object query和全局图像信息结合一起,通过不同的做注意力操作,从而让模型直接输出最后的一组预测框) - 想法&&实效性:并行比串行更合适
DETR 的好处:
- 简单性:想法上简单,不需要一个特殊的 library,只要硬件支持 transformer 或 CNN,就一定支持 detr
- 性能:在 coco 数据集上,detr 和一个训练非常好的 faster RCNN 基线网络取得了差不多的效果,模型内存和速度也和 faster RCNN 差不多
- 想法好,解决了目标检测领域很多痛点,写作好
- 别的任务:全景分割任务上 detr 效果很好,detr 能够非常简单拓展到其他任务上
📚引言
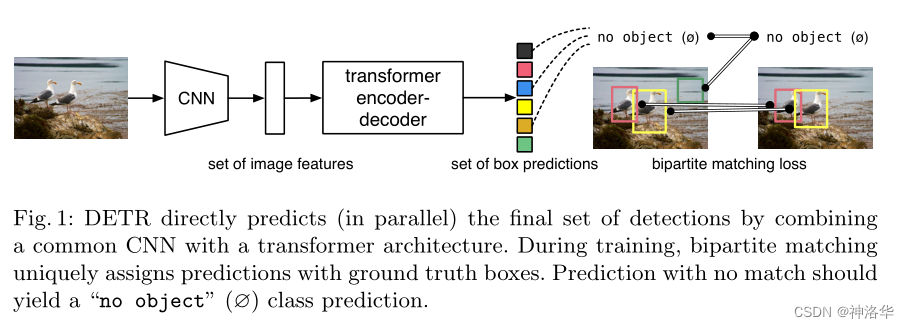
DETR 流程(训练):
- CNN 提特征
- 特征拉直,送到 encoder-decoder 中,encoder 作用:进一步学习全局信息,为近下来的 decoder,也就是最后出预测框做铺垫。
- decoder 生成框的输出,当你有了图像特征之后,还会有一个 object query(限定了你要出多少框),通过 query 和特征在 decoder 里进行自注意力操作,得到输出的框(文中是100,无论是什么图片都会预测100个框)
- loss :二分图匹配,计算100个预测框和2个 GT 框的 matching loss,决定100个预测框哪两个是独一无二对应到红黄色的 GT 框,匹配的框去算目标检测的 loss
推理:
1、2、3一致,第四步 loss 不需要,直接在最后的输出上用一个阈值卡一个输出的置信度,置信度比较大(>0.7的)保留,置信度小于0.7的当做背景物体。
🧬相关工作
让 DETR 成功主要原因:transformer
🔍方法
分两块:1、基于集合的目标函数怎么做,作者如何通过二分图匹配把预测的框和 GT 框连接在一起,算得目标函数 2、detr 具体模型架构
💡目标函数
DETR模型最后输出是一个固定集合,无论图片是什么,最后都会输出 n 个(本文 n=100)
问题:detr 每次都会出 100 个输出,但是实际上一个图片的 GT 的 bounding box 可能只有几个,如何匹配?如何计算 loss?怎么知道哪个预测框对应 GT 框?
匈牙利算法是解决该问题的一个知名且高效的算法,能够以较低的复杂度得到唯一的最优解。
在 scipy 库中,已经封装好了匈牙利算法,只需要将成本矩阵(cost matrix)输入进去就能够得到最优的排列。在 DETR 的官方代码中,也是调用的这个函数进行匹配(from scipy.optimize import linear_sum_assignment)。
从N个预测框中,选出与M个GT Box最匹配的预测框,也可以转化为二分图匹配问题,这里需要填入矩阵的“成本”,就是每个预测框和GT Box的损失。对于目标检测问题,损失就是分类损失和边框损失组成。
所以整个步骤就是:
- 遍历所有的预测框和 GT Box,计算其 loss。
- 将 loss 构建为 cost matrix,然后用 scipy 的
linear_sum_assignment(匈牙利算法)求出最优解,即找到每个 GT Box 最匹配的那个预测框。 - 计算最优的预测框和 GT Box 的损失。(分类+回归)
但是在 DETR 中,损失函数有两点小改动:
- 去掉分类损失中的 log
- 回归损失为 L1 loss+GIOU
📜模型结构

下面参考官网的一个 demo,以输入尺寸3×800×1066为例进行前向过程:
- CNN 提取特征(
[800,1066,3]→[25,34,256])
backbone 为 ResNet-50,最后一个 stage 输出特征图为 25×34×2048(32 倍下采样),然后用 1×1 的卷积将通道数降为 256; - Transformer encoder 计算自注意力(
[25,34,256]→[850,256])
将上一步的特征拉直为 850×256,并加上同样维度的位置编码(Transformer 本身没有位置信息),然后输入的 Transformer encoder 进行自注意力计算,最终输出维度还是 850×256; - Transformer decoder 解码,生成预测框
decoder 输入除了 encoder 部分最终输出的图像特征,还有前面提到的 learned object query,其维度为100×256。在解码时,learned object query 和全局图像特征不停地做 across attention,最终输出100×256的自注意力结果。
这里的 object query 即相当于之前的 anchor/proposal,是一个硬性条件,告诉模型最后只得到 100 个输出。然后用这 100 个输出接 FFN 得到分类损失和回归损失。 - 使用检测头输出预测框
检测头就是目标检测中常用的全连接层(FFN),输出 100 个预测框( h x c e n t e r , y c e n t e r , w , h h x_{center}, y_{center}, w, h hxcenter,ycenter,w,h )和对应的类别。 - 使用二分图匹配方式输出最终的预测框,然后计算预测框和真实框的损失,梯度回传,更新网络。
除此之外还有部分细节:
- Transformer-encode/decoder 都有 6层
- 除第一层外,每层 Transformer encoder 里都会先计算 object query 的 self-attention,主要是为了移除冗余框。这些 query 交互之后,大概就知道每个 query 会出哪种框,互相之间不会再重复(见实验)。
- decoder 加了 auxiliary loss,即每层 decoder 输出的 100×256 维的结果,都加了 FFN 得到输出,然后去计算 loss,这样模型收敛更快。(每层 FFN 共享参数)
⚙️代码
import torch
from torch import nn
from torchvision.models import resnet50class DETR(nn.Module):def __init__(self, num_classes, hidden_dim, nheads,num_encoder_layers, num_decoder_layers):super().__init__()# We take only convolutional layers from ResNet-50 modelself.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])self.conv = nn.Conv2d(2048, hidden_dim, 1) # 1×1卷积层将2048维特征降到256维self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers)self.linear_class = nn.Linear(hidden_dim, num_classes + 1) # 类别FFNself.linear_bbox = nn.Linear(hidden_dim, 4) # 回归FFNself.query_pos = nn.Parameter(torch.rand(100, hidden_dim)) # object query# 下面两个是位置编码self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))def forward(self, inputs):x = self.backbone(inputs)h = self.conv(x)H, W = h.shape[-2:]pos = torch.cat([self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),], dim=-1).flatten(0, 1).unsqueeze(1) # 位置编码h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),self.query_pos.unsqueeze(1))return self.linear_class(h), self.linear_bbox(h).sigmoid()detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)
📌实验
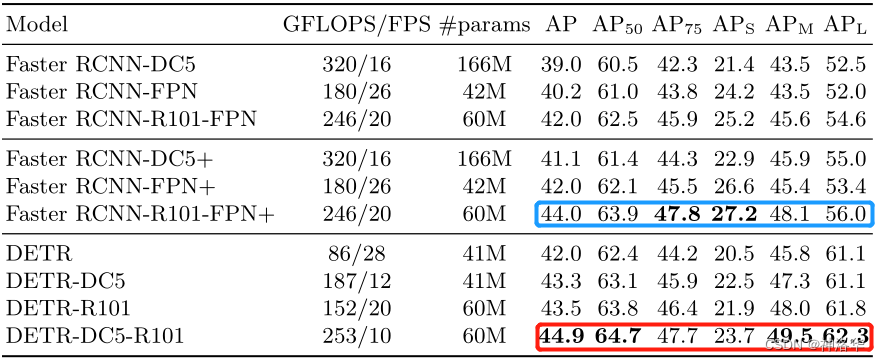
- 最上面一部分是 Detectron 2 实现的 Faster RCNN ,但是本文中作者使用了很多 trick
- 中间部分是作者使用了 GIoU loss、更强的数据增强策略、更长的训练时间来把上面三个模型重新训练了一次,这样更显公平。重新训练的模型以+表示,参数量等这些是一样的,但是普偏提了两个点
- 下面部分是 DETR 模型,可以看到参数量、GFLOPS 更小,但是推理更慢。模型比 Faster RCNN 精度高一点,主要是大物体检测提升 6 个点 AP,小物体相比降低了 4个点左右。
相关文章:
【论文阅读】DETR 论文逐段精读
【论文阅读】DETR 论文逐段精读 文章目录 【论文阅读】DETR 论文逐段精读📖DETR 论文精读【论文精读】🌐前言📋摘要📚引言🧬相关工作🔍方法💡目标函数📜模型结构⚙️代码 Ǵ…...

负载均衡:实现高效稳定的网络服务
随着互联网技术的快速发展,网络应用服务的规模和复杂性日益增加。为了满足日益增长的用户需求,确保服务的高可用性和稳定性,负载均衡技术应运而生。本文将详细介绍负载均衡的概念、原理、分类以及应用场景,帮助读者深入了解这一关…...

2024最新软件测试【测试理论+ 抓包与网络协议】面试题(内附答案)
一、测试理论 3.1 你们原来项目的测试流程是怎么样的? 我们的测试流程主要有三个阶段:需求了解分析、测试准备、测试执行。 1、需求了解分析阶段 我们的 SE 会把需求文档给我们自己先去了解一到两天这样,之后我们会有一个需求澄清会议, …...

极简7照训练法,奇趣相机引领儿童AI摄影潮流
近日,奇趣未来推出一款专注于儿童AI摄影市场的微信小程序——奇趣相机,搭载了专为中国儿童精心研发的AIGC大模型,精准捕捉并贴合亚洲儿童人脸特征,让每一个孩子的笑容都能被完美定格。它不仅涵盖了从3岁至12岁各个年龄段的儿童摄影…...

Flink应用
1.免密登录 2.flink StandAlone模式 3.Flink Yarn 模式 (on per 模式,on session 模式) Flink概述 按照Apache官方的介绍,Flink是一个对有界和无界数据流进行状态计算的分布式处理引擎和框架。通俗地讲,Flink就是一个流计算框架,主要用来处…...

C# 委托与事件 终章
C# 委托与事件 浅尝 C# 委托与事件 深入 委托 委托有什么用? 将函数作为函数的参数传递声明事件并用来注册 强类型委托 Action<T1> Func<T1, TResult>事件 希望一个类的某些成员在发生变化时能被外界观测到 CollctionChangedTextChanged 标准.Ne…...

MySQL-linux安装-万能RPM法
一、MySQL的Linux版安装 1、 CentOS7下检查MySQL依赖 1. 检查/tmp临时目录权限(必不可少) 由于mysql安装过程中,会通过mysql用户在/tmp目录下新建tmp_db文件,所以请给/tmp较大的权限。执行 : chmod -R 777 /tmp2. …...

elment UI el-date-picker 月份组件选定后提交后台页面显示正常,提交后台字段变成时区格式
需求:要实现一个日期的月份选择<el-date-picker :typeformData.dateType :value-formatdateFormat v-modelformData.leaveFactoryDateplaceholder选择月份></el-date-picker>错误示例:将日期显示类型(type)dateType或将日期绑定值的格式(val…...

基于 NGINX 的 ngx_http_geoip2 模块 来禁止国外 IP 访问网站
基于 NGINX 的 ngx_http_geoip2 模块 来禁止国外 IP 访问网站 一、安装 geoip2 扩展依赖 [rootfxkj ~]# yum install libmaxminddb-devel -y二、下载 ngx_http_geoip2_module 模块 [rootfxkj tmp]# git clone https://github.com/leev/ngx_http_geoip2_module.git三、解压模…...
)
C++经典面试题目(二十)
1、请解释运算符重载的限制。 运算符重载必须至少有一个操作数是用户自定义类型。不能改变运算符的优先级和结合性。不能创建新的运算符。不能重载以下运算符:::, .*, .*, ?:, sizeof, typeid。 2、什么是友元函数?它有什么作用? 友元函数…...

vue3+uniapp 动态渲染组件,兼容h5、app端
1.setup写在js中,使用ref绑定数据,事件和数据都需要return出去。调用数据{数据名}.value。 如果你想要通过接口动态获取组件路径,并据此动态渲染组件,你可以使用异步组件和defineAsyncComponent函数。在Vue 3中,你可以…...

CSS层叠样式表学习(2)
(大家好,今天我们将继续来学习CSS(2)的相关知识,大家可以在评论区进行互动答疑哦~加油!💕) 目录 二、CSS基础选择器 2.1 CSS选择器的作用 2.2 选择器分类 2.3 标签选择器 2.…...

【MySQL】DML的表操作详解:添加数据&修改数据&删除数据(可cv例题语句)
前言 大家好吖,欢迎来到 YY 滴MySQL系列 ,热烈欢迎! 本章主要内容面向接触过C Linux的老铁 主要内容含: 欢迎订阅 YY滴C专栏!更多干货持续更新!以下是传送门! YY的《C》专栏YY的《C11》专栏YY的…...

Docker命令及部署Java项目
文章目录 简介Docker镜像镜像列表查找镜像拉取镜像删除镜像镜像标签 Docker容器容器启动容器查看容器停止和重启后台模式和进入强制停止容器清理停止的容器容器错误日志容器别名及操作 Docker部署Java项目 简介 Docker是一种容器化技术,可以帮助开发者轻松打包应用…...

深度学习入门:从理论到实践的全面指南
深度学习入门:从理论到实践的全面指南 引言第一部分:深度学习基础第二部分:数学基础第三部分:编程和工具第四部分:构建你的第一个模型第五部分:深入学习结语 引言 大家好,这里是程序猿代码之路。…...

后端前行Vue之路(二):模版语法之插值与指令
1.概述 Vue.js的模板语法是一种将Vue实例的数据绑定到HTML文档的方法。Vue的模板语法是一种基于HTML的扩展,允许开发者将Vue实例中的数据绑定到HTML元素,以及在HTML中使用一些简单的逻辑和指令。Vue.js 基于 HTML 的模板语法允许开发者声明式地将 DOM 绑…...

Kotlin 中的类和构造方法
Kotlin 中的类与接口和 Java 中的类与接口还是有区别的。例如,Koltin 中的接口可以包含属性声明,与 Java 不同的是。Kotlin 的声明默认是 final 和 public 的。此外,嵌套的类默认并不是内部类:它们并没有包含对其它外部类的隐式引…...
)
【2024最新】vue3的基本使用(超详细)
一、Vue 3 概述 1. 为什么要学习Vue 3 Vue 3是Vue.js的最新主要版本,它带来了许多改进和新特性,包括但不限于: 性能提升:Vue 3提供了更快的渲染速度和更低的内存使用率。Composition API:引入了一个新的API…...
【xinference】(8):在autodl上,使用xinference部署qwen1.5大模型,速度特别快,同时还支持函数调用,测试成功!
1,关于xinference Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,您可以使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用。 Xor…...
YARN集群 和 MapReduce 原理及应用
YARN集群模式 本文内容需要基于 Hadoop 集群搭建完成的基础上来实现 如果没有搭建,请先按上一篇: <Linux 系统 CentOS7 上搭建 Hadoop HDFS集群详细步骤> 搭建:https://mp.weixin.qq.com/s/zPYsUexHKsdFax2XeyRdnA 配置hadoop安装目录下的 etc…...

终极分布式编程框架全攻略:从零掌握Awesome BigData核心技术
终极分布式编程框架全攻略:从零掌握Awesome BigData核心技术 【免费下载链接】awesome-bigdata A curated list of awesome big data frameworks, ressources and other awesomeness. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-bigdata 在数据爆…...

从“意大利面”到整洁代码:我是如何用SonarQube重构遗留项目的
从“意大利面”到整洁代码:我是如何用SonarQube重构遗留项目的 接手一个结构混乱的遗留项目,就像面对一盘煮过头的意大利面——各种逻辑纠缠不清,随便动一处就可能引发连锁反应。去年我遇到这样一个Java项目:12万行代码࿰…...

为AI智能体构建持久化记忆系统:基于RAG与向量检索的实践
1. 项目概述:为AI智能体构建持久化记忆系统在AI智能体(AI Agent)的开发浪潮中,一个核心的痛点日益凸显:如何让智能体拥有持续、可靠的记忆能力?无论是基于Claude API、GPTs还是其他大语言模型构建的对话机器…...

AI抠图的几种方法:从传统到智能,一文掌握所有工具和技巧
最近被问得最多的问题就是:"怎么快速给图片换个背景?"、"证件照怎么自己换底色?"、"商品图去背景用什么工具?"。说实话,随着AI技术的发展,抠图这件事已经从"需要Photos…...

ksail:本地Kubernetes开发环境一键搭建与云原生实践
1. 项目概述:当Kubernetes遇上本地开发如果你是一名后端或云原生方向的开发者,大概率经历过这样的场景:为了调试一个微服务,你需要在本地启动一整套依赖——数据库、消息队列、缓存,可能还有另外两三个兄弟服务。你手忙…...

Chrome QRCode:浏览器原生二维码生成与解析的极简技术方案
Chrome QRCode:浏览器原生二维码生成与解析的极简技术方案 【免费下载链接】chrome-qrcode :zap: A Chrome plugin to Genrate QRCode of URL / Text, or Decode the QRcode in website. 一个Chrome浏览器插件,用于生成当前URL或者选中内容的二维码&…...

现代React Native开发:从Expo生态到Redux状态管理的工程实践
1. 项目概述:一个为现代React Native开发量身定制的生产力引擎 如果你和我一样,在过去几年里用React Native做过几个项目,那你一定对项目初始化时那种重复、繁琐的“体力活”深有体会。每次新建一个项目,都要重新安装一堆依赖库&…...

Unitree Go2 ROS2 SDK架构设计指南:实现企业级机器人性能优化的5大策略
Unitree Go2 ROS2 SDK架构设计指南:实现企业级机器人性能优化的5大策略 【免费下载链接】go2_ros2_sdk Unofficial ROS2 SDK support for Unitree GO2 AIR/PRO/EDU 项目地址: https://gitcode.com/gh_mirrors/go/go2_ros2_sdk Unitree Go2 ROS2 SDK是一个为宇…...

如何彻底解决Minecraft离线启动限制:PrismLauncher-Cracked完全指南
如何彻底解决Minecraft离线启动限制:PrismLauncher-Cracked完全指南 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a functional O…...
)
别再死记硬背了!用一块74283芯片搞定所有BCD码转换(附实战练习题)
用74283芯片玩转BCD码转换:从原理到实战的终极指南 在数字电路设计与计算机组成原理的学习中,BCD码转换一直是让许多学生头疼的"拦路虎"。传统的死记硬背方法不仅效率低下,更无法应对考试中千变万化的题型。本文将彻底改变这一现状…...