YARN集群 和 MapReduce 原理及应用
YARN集群模式
本文内容需要基于 Hadoop 集群搭建完成的基础上来实现
如果没有搭建,请先按上一篇:
<Linux 系统 CentOS7 上搭建 Hadoop HDFS集群详细步骤>
搭建:https://mp.weixin.qq.com/s/zPYsUexHKsdFax2XeyRdnA
配置hadoop安装目录下的 etc/hadoop/yarn-site.xml
配置hadoop安装目录下的 etc/hadoop/mapred-site.xml
例如:/opt/apps/hadoop-3.2.4/etc/hadoop/
配置 yarn-site.xml
vim etc/hadoop/yarn-site.xml添加内容如下:
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>node3</value></property>
</configuration>注意:上面node3 为自己规划的作为 resourcemanager 节点的主机名
配置 mapred-site.xml
[zhang@node3 hadoop]$ vi mapred-site.xml添加内容如下:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.2.4</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.2.4</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.2.4</value></property>
</configuration>注意:上面的 /opt/apps/hadoop-3.2.4 为自己 hadoop 的安装目录
同步配置
修改完成后,需要复制配置到其他所有节点
scp -r etc/ zhang@node1:/opt/apps/hadoop-3.2.4/
scp -r etc/ zhang@node1:/opt/apps/hadoop-3.2.4/
在 $HADOOP_HOME/etc/下
scp -r hadoop/yarn-site.xml zhang@node2:/opt/apps/hadoop-3.2.4/etc/hadoop/也可以通过 pwd来表示远程拷贝到和当前目录相同的目录下
scp -r hadoop node2:`pwd` # 注意:这里的pwd需要使用``(键盘右上角,不是单引号),表示当前目录启动 YARN 集群
# 在主服务器(ResourceManager所在节点)上hadoop1启动集群sbin/start-yarn.sh# jps查看进程,如下所⽰代表启动成功
==========node1===========
[zhang@node1 hadoop]$ jps
7026 DataNode
7794 Jps
6901 NameNode
7669 NodeManager==========node2===========
[zhang@node2 hadoop]$ jps
9171 NodeManager
8597 DataNode
8713 SecondaryNameNode
9294 Jps==========node3===========
[zhang@node3 etc]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[zhang@node3 etc]$ jps
11990 ResourceManager
12119 NodeManager
12472 Jps
11487 DataNode
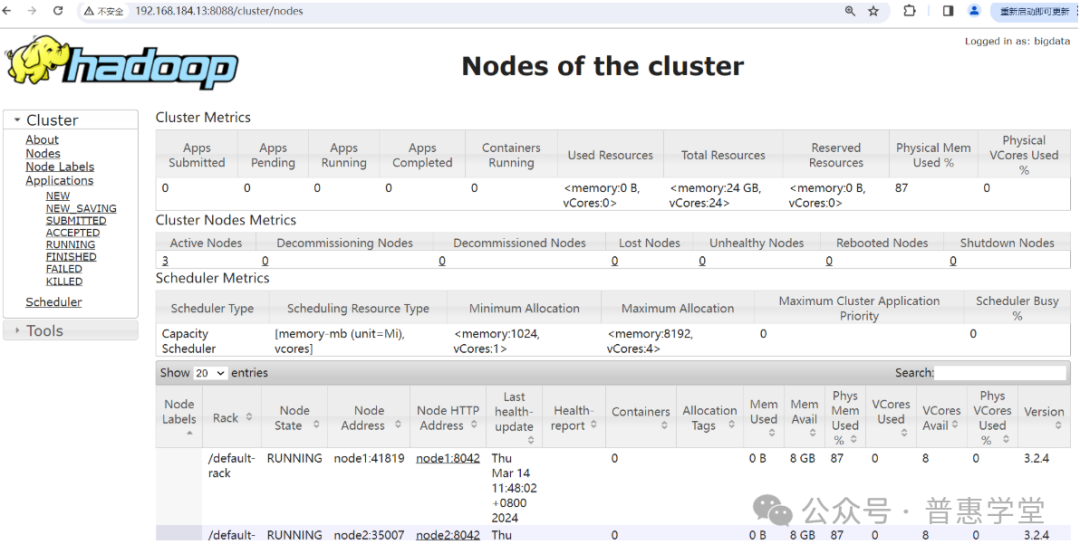
启动成功后,可以通过浏览器访问 ResourceManager 进程所在的节点 node3 来查询运行状态
截图如下:
MapReduce
简介和原理
MapReduce 是一种分布式编程模型,最初由 Google 提出并在学术论文中公开描述,后来被广泛应用于大规模数据处理,尤其是 Apache Hadoop 等开源项目中实现了这一模型。MapReduce 的核心思想是将复杂的大量数据处理任务分解成两个主要阶段:Map(映射)阶段和 Reduce(归约)阶段。
Map(映射)阶段:
-
将输入数据集划分为独立的块。
-
对每个数据块执行用户自定义的 map 函数,该函数将原始数据转换为一系列中间键值对。
-
输出的结果是中间形式的键值对集合,这些键值对会被排序并分区。
Shuffle(洗牌)和 Sort(排序)阶段:
-
在 map 阶段完成后,系统会对产生的中间键值对进行分发、排序和分区操作,确保具有相同键的值会被送到同一个 reduce 节点。
Reduce(归约)阶段:
-
每个 reduce 节点接收一组特定键的中间键值对,并执行用户自定义的 reduce 函数。
-
reduce 函数负责合并相同的键值对,并生成最终输出结果。
整个过程通过高度并行化的方式完成,非常适合处理 PB 级别的海量数据。由于其简单易懂的设计理念和强大的并行处理能力,MapReduce 成为了大数据处理领域的重要基石之一,尤其适用于批处理类型的分析任务,如网页索引构建、日志分析、机器学习算法实现等。
下面通过一张使用 MapReduce 进行单词数统计的过程图,来更直观的了解 MapReduce 工作过程和原理
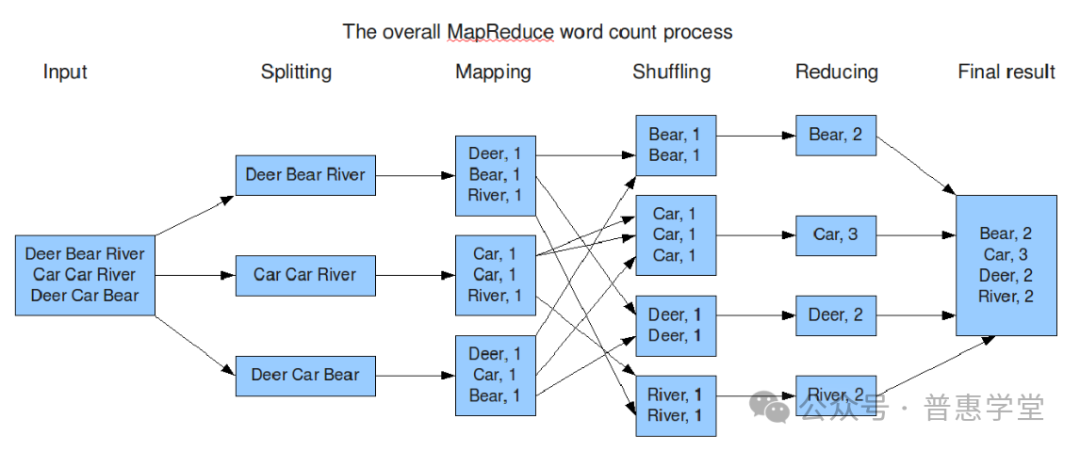
MapReduce 示例程序
在搭建好 YARN 集群后,就可以测试 MapReduce 的使用了,下面通过两个案例来验证使用 MapReduce
-
单词统计
-
pi 估算
在hadoop 安装目录下的 share/hadoop/mapreduce 目录下存放了一些示例程序 jar 包,
可以调用 hadoop jar 命令来调用示例程序
具体步骤如下:
PI 估算案例
先切换目录到 安装目录/share/hadoop/mapreduce/ 下
[zhang@node3 ~]$ cd /opt/apps/hadoop-3.2.4/share/hadoop/mapreduce/
[zhang@node3 mapreduce]$ ls
hadoop-mapreduce-client-app-3.2.4.jar hadoop-mapreduce-client-shuffle-3.2.4.jar
hadoop-mapreduce-client-common-3.2.4.jar hadoop-mapreduce-client-uploader-3.2.4.jar
hadoop-mapreduce-client-core-3.2.4.jar hadoop-mapreduce-examples-3.2.4.jar
hadoop-mapreduce-client-hs-3.2.4.jar jdiff
hadoop-mapreduce-client-hs-plugins-3.2.4.jar lib
hadoop-mapreduce-client-jobclient-3.2.4.jar lib-examples
hadoop-mapreduce-client-jobclient-3.2.4-tests.jar sources
hadoop-mapreduce-client-nativetask-3.2.4.jar
[zhang@node3 mapreduce]$
调用 jar 包执行
hadoop jar hadoop-mapreduce-examples-3.2.4.jar pi 3 4
[zhang@node3 mapreduce]$ hadoop jar hadoop-mapreduce-examples-3.2.4.jar pi 3 4
Number of Maps = 3 #
Samples per Map = 4
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Starting Job
2024-03-23 17:48:56,496 INFO client.RMProxy: Connecting to ResourceManager at node3/192.168.184.13:8032
2024-03-23 17:48:57,514 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for #............省略
2024-03-23 17:48:59,194 INFO mapreduce.Job: Running job: job_1711186711795_0001
2024-03-23 17:49:10,492 INFO mapreduce.Job: Job job_1711186711795_0001 running in uber mode : false
2024-03-23 17:49:10,494 INFO mapreduce.Job: map 0% reduce 0%
2024-03-23 17:49:34,363 INFO mapreduce.Job: map 100% reduce 0%
............Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format Counters Bytes Read=354File Output Format Counters Bytes Written=97
Job Finished in 53.854 seconds
Estimated value of Pi is 3.66666666666666666667 # 计算结果
命令的含义
这个命令的具体含义是:
hadoop jar: 命令用于执行 Hadoop 应用程序,这里的应用程序是指从 JAR 包hadoop-mapreduce-examples-3.2.4.jar中提取的 MapReduce 程序。
pi: 这是具体的示例程序名称,用于通过概率方法估算π值。
2: 这个数字代表实验的总样本数(也称为总投点数),意味着将会随机投掷2次点来估计π值。
4: 这个数字通常表示地图任务(map tasks)的数量,也就是说,计算过程将会被拆分为4个部分来并行执行。
单词统计案例
hadoop-mapreduce-examples-3.2.4.jar是 Apache Hadoop MapReduce 框架的一部分,其中包含了多个演示 MapReduce 概念和功能的例子程序,其中一个经典例子就是wordcount。
wordcount示例程序展示了如何使用 MapReduce 模型处理大规模文本数据,统计文本中每个单词出现的次数。当你在 Hadoop 环境中执行如下命令时:hadoop jar hadoop-mapreduce-examples-3.2.4.jar wordcount input_path output_path这里发生了以下过程:
input_path:指定输入数据的位置,通常是 HDFS 上的一个目录,该目录下的所有文件将作为输入数据源,被分割成各个映射任务(Mapper)处理。
Mapper:每个映射任务读取一段输入数据,并将其拆分成单词,然后为每个单词及其出现次数生成键值对
<word, 1>。Reducer:所有的映射任务完成后,Reducer 对由 Mapper 发出的中间键值对进行汇总,计算出每个单词的总出现次数,并将最终结果输出到 output_path 指定的 HDFS 目录下。
演示步骤如下:
新建文件
首先在 /opt/下新建目录 data 用来存放要统计的文件
新建 word.txt 文件并输入内容如下:
hello java
hello hadoop
java hello
hello zhang java具体命令如下:
[zhang@node3 opt]$ mkdir data
[zhang@node3 opt]$ cd data
[zhang@node3 data]$ ls
[zhang@node3 data]$ vim word.txt上传文件到hadoop
hdfs dfs 命令
新建 input 目录用来存放 word.txt 文件
[zhang@node3 data]$ hdfs dfs -mkdir /input # 新建目录
[zhang@node3 data]$ hdfs dfs -ls / # 查看目录
Found 1 items
drwxr-xr-x - zhang supergroup 0 2024-03-23 16:52 /input
[zhang@node3 data]$ hdfs dfs -put word.txt /input # 上传文件到目录
[zhang@node3 data]$ 统计单词
hadoop jar hadoop-mapreduce-examples-3.2.4.jar wordcount /input /outputx
hadoop jar 为命令
hadoop-mapreduce-examples-3.2.4.jar 为当前目录下存在jar文件
wordcount 为要调用的具体的程序
/input 为要统计单词的文件所在的目录,此目录为 hadoop 上的目录
/outputx 为输出统计结果存放的目录
注意:/outputx 目录不能先创建,只能是执行时自动创建,否则异常
[zhang@node3 mapreduce]$ hadoop jar hadoop-mapreduce-examples-3.2.4.jar wordcount /input /outputx
2024-03-23 18:11:55,438 INFO client.RMProxy: Connecting to ResourceManager at node3/192.168.184.13:8032
#............省略
2024-03-23 18:12:17,514 INFO mapreduce.Job: map 0% reduce 0%
2024-03-23 18:12:50,885 INFO mapreduce.Job: map 100% reduce 0%
2024-03-23 18:12:59,962 INFO mapreduce.Job: map 100% reduce 100%
2024-03-23 18:12:59,973 INFO mapreduce.Job: Job job_1711186711795_0003 completed successfully
2024-03-23 18:13:00,111 INFO mapreduce.Job: Counters: 54File System CountersFILE: Number of bytes read=188FILE: Number of bytes written=1190789FILE: Number of read operations=0#............省略HDFS: Number of write operations=2HDFS: Number of bytes read erasure-coded=0Job Counters Launched map tasks=4Launched reduce tasks=1Data-local map tasks=4Total time spent by all maps in occupied slots (ms)=125180#............省略Map-Reduce FrameworkMap input records=13Map output records=27Map output bytes=270Map output materialized bytes=206#............省略Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format Counters Bytes Read=163File Output Format Counters Bytes Written=51
[zhang@node3 mapreduce]$
查看统计结果
先查看输出目录下的结果文件名
在 hdfs dfs -cat 查看内容
[zhang@node3 mapreduce]$ hdfs dfs -ls /outputx # 查看输出目录下文件
Found 2 items
-rw-r--r-- 3 zhang supergroup 0 2024-03-23 18:12 /outputx/_SUCCESS
-rw-r--r-- 3 zhang supergroup 51 2024-03-23 18:12 /outputx/part-r-00000
[zhang@node3 mapreduce]$ hdfs dfs -cat /outputx/part-r-00000 # 查看内容
hadoop 3
hello 14
java 6
python 2
spring 1
zhang 1常见问题
错误1:
[2024-03-15 08:00:16.276]Container exited with a non-zero exit code 1. Error file: prelaunch.err. Last 4096 bytes of prelaunch.err : Last 4096 bytes of stderr : Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration: yarn.app.mapreduce.am.env HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}
解决办法:
根据上面提示修改 mapred-site.xml ,配置 HADOOP_MAPRED_HOME,指向 hadoop 安装目录 即可。
错误2:
运行 Java 程序,调用 Hadoop 时,抛出异常
2024-03-16 14:35:57,699 INFO ipc.Client: Retrying connect to server: node3/192.168.184.13:8032. Already tried 7 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)原因:
连接node3的 yarn 时,没有成功,说明没启动 start-yarn.sh
错误3:
node2: ERROR: JAVA_HOME is not set and could not be found.解决办法:
${HADOOP_HOME}/etc/hadoop/hadoop_en.sh 添加
JAVA_HOME=/opt/apps/opt/apps/jdk1.8.0_281
注意:不能使用 JAVA_HOME=${JAVA_HOME}
错误4:
[zhang@node3 hadoop]$ start-dfs.sh
ERROR: JAVA_HOME /opt/apps/jdk does not exist.解决办法:
修改 /hadoop/etc/hadoop/hadoop-env.sh 文件
添加 JAVA_HOME 配置
相关文章:
YARN集群 和 MapReduce 原理及应用
YARN集群模式 本文内容需要基于 Hadoop 集群搭建完成的基础上来实现 如果没有搭建,请先按上一篇: <Linux 系统 CentOS7 上搭建 Hadoop HDFS集群详细步骤> 搭建:https://mp.weixin.qq.com/s/zPYsUexHKsdFax2XeyRdnA 配置hadoop安装目录下的 etc…...

C++算法——滑动窗口
一、长度最小的子数组 1.链接 209. 长度最小的子数组 - 力扣(LeetCode) 2.描述 3.思路 本题从暴力求解的方式去切入,逐步优化成“滑动窗口”,首先,暴力枚举出各种组合的话,我们先让一个指针指向第一个&…...

Rust---有关介绍
目录 Rust---有关介绍变量的操作Rust 数值库:num某些基础数据类型序列(Range)字符类型单元类型 发散函数表达式(! 语句) Rust—有关介绍 得益于各种零开销抽象、深入到底层的优化潜力、优质的标准库和第三方库实现,Ru…...

vue项目双击from表单限制重复提交 添加全局注册自定义函数
第一步: 找到utils文件夹添加directive.js文件 import Vue from vue //全局防抖函数 // 在vue上挂载一个指量 preventReClick const preventReClick Vue.directive(preventReClick, {inserted: function (el, binding) {console.log(el.disabled)el.addEventListener(click,…...

WebPack的使用及属性配、打包资源
WebPack(静态模块打包工具)(webpack默认只识别js和json内容) WebPack的作用 把静态模块内容压缩、整合、转译等(前端工程化) 1️⃣把less/sass转成css代码 2️⃣把ES6降级成ES5 3️⃣支持多种模块文件类型,多种模块标准语法 export、export…...
机器学习实战17-高斯朴素贝叶斯(GaussianNB)模型的实际应用,结合生活中的生动例子帮助大家理解
大家好,我是微学AI,今天给大家介绍一下机器学习实战17-高斯朴素贝叶斯(GaussianNB)模型的实际应用,结合生活中的生动例子帮助大家理解。GaussianNB,即高斯朴素贝叶斯模型,是一种基于概率论的分类算法,广泛应…...

数据处理库Pandas数据结构DataFrame
Dataframe是一种二维数据结构,数据以表格形式(与Excel类似)存储,有对应的行和列,如图3-3所示。它的每列可以是不同的值类型(不像 ndarray 只能有一个 dtype)。基本上可以把 DataFrame 看成是共享…...

中国发展新能源的核心驱动力是什么?其原理是如何运作的?
中国发展新能源的核心驱动力是推进能源消费方式变革、构建多元清洁能源供应体系、实施创新驱动发展战略、深化能源体制改革和持续推进国际合作。 新能源的发展背后有多重经济、政策及环境因素的推动: 经济发展需求:随着中国经济的快速发展,…...
skywalking
部署: docker部署方式 docker-compose.yaml version: 3 services:elasticsearch:build:context: elasticsearchrestart: alwaysnetworks:- skywalking_netcontainer_name: elasticsearchimage: elasticsearch:7.17.6environment:- "discovery.typesingle-no…...
 060108》第二次过程性考核作业参考答案)
江苏开放大学2024年春《大学英语(D) 060108》第二次过程性考核作业参考答案
答案:更多答案,请关注【电大搜题】微信公众号 答案:更多答案,请关注【电大搜题】微信公众号 答案:更多答案,请关注【电大搜题】微信公众号 单选题 1从选项中选出翻译最为准确的一项。 We cannot help …...

dockerfile制作-pytoch+深度学习环境版
你好你好! 以下内容仅为当前认识,可能有不足之处,欢迎讨论! 文章目录 文档内容docker相关术语docker常用命令容器常用命令根据dockerfile创建容器dokerfile文件内容 docker问题:可能的原因和解决方法示例修改修改后的D…...

YOLOv8结合SCI低光照图像增强算法!让夜晚目标无处遁形!【含端到端推理脚本】
这里的"SCI"代表的并不是论文等级,而是论文采用的方法 — “自校准光照学习” ~ 左侧为SCI模型增强后图片的检测效果,右侧为原始v8n检测效果 这篇文章的主要内容是通过使用SCI模型和YOLOv8进行算法联调,最终实现了如上所示的效果:在增强图像可见度的同时,对图像…...
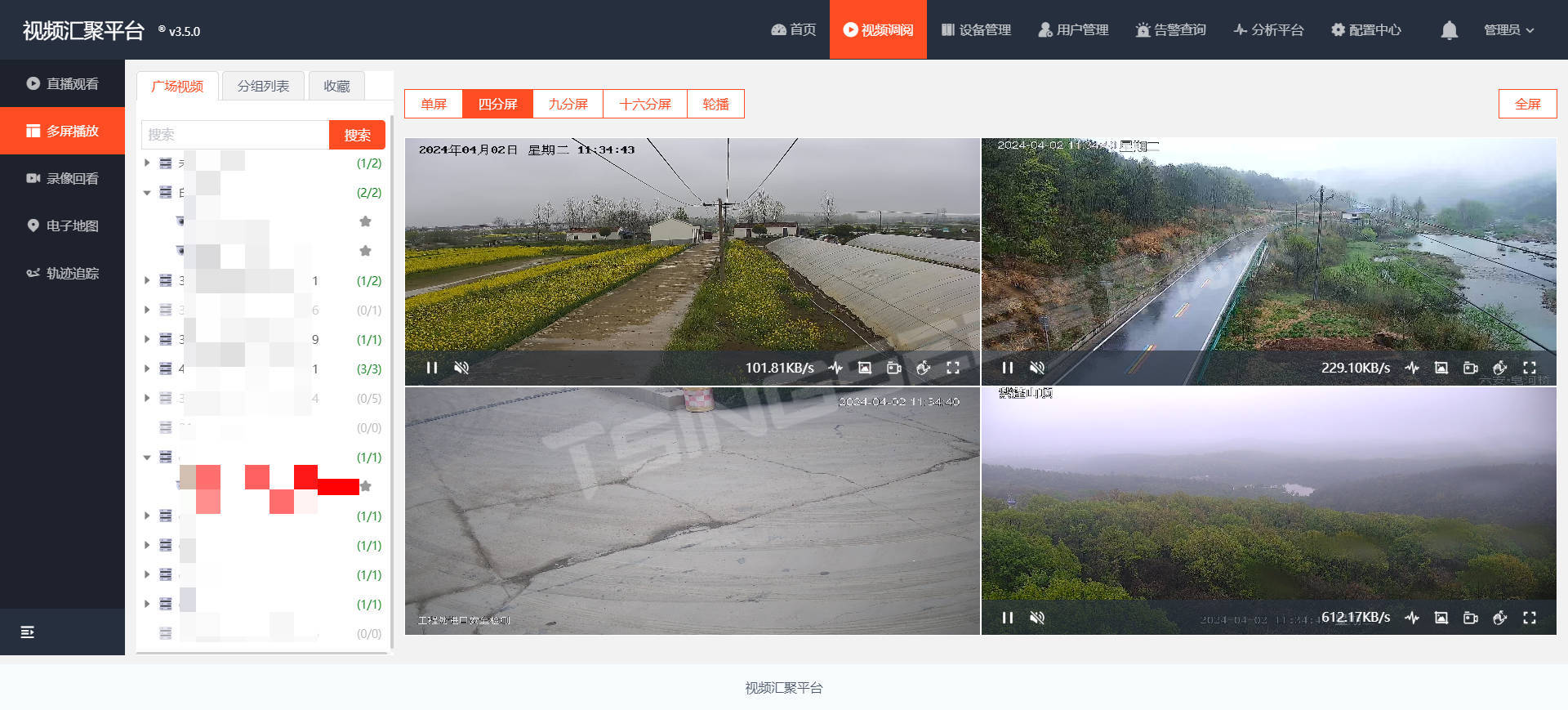
视频监控/云存储/AI智能分析平台EasyCVR集成时调用接口报跨域错误的原因
EasyCVR视频融合平台基于云边端架构,可支持海量视频汇聚管理,能提供视频监控直播、云端录像、云存储、录像检索与回看、智能告警、平台级联、智能分析等视频服务。平台兼容性强,支持多协议、多类型设备接入,包括:国标G…...

VuePress基于 Vite 和 Vue 构建优秀框架
VitePress 是一个静态站点生成器 (SSG),专为构建快速、以内容为中心的站点而设计。简而言之,VitePress 获取用 Markdown 编写的内容,对其应用主题,并生成可以轻松部署到任何地方的静态 HTML 页面。 VitePress 附带一个用于技术文档…...
)
冒泡排序,选择排序,插入排序,希尔排序,基数排序,堆排序代码分析(归并排序和快速排序后续更新)
所有的算法都是这样,算法思想最重要,其次是实现过程,最后才是实现的代码 上战伐谋,我们只要明确了其算法思想和实现过程,所有算法都是纸老虎,所有算法题都是纸老虎 笔者才疏学浅,也算是刚刚接…...

从入门到精通:NTP卫星时钟服务器技术指南
从入门到精通:NTP卫星时钟服务器技术指南 从入门到精通:NTP卫星时钟服务器技术指南 一、 产品功能 卫星时钟服务器是一款采用GPS或北斗卫星提供高精度网络时间服务的产品。卫星天线安装简便(根据天线所放位置提示实时卫星颗数)&a…...

OpenResty基于来源IP和QPS来限流
Nginx 经典限流法 ngx_http_limit_req_module 和 ngx_http_limit_conn_module,可以在代理层面对服务进行限流和熔断。 http {# 请求限流定义1:# - $binary_remote_addr:限制对象(客户端)# - zone:定义限制(策略)名称# - 10m:用十…...

面对AI技术创业的挑战以及提供给潜在创业者的一些建议
面对AI创业的挑战 AI技术创业虽然机遇众多,但也面临不少挑战,理解这些挑战并寻找应对策略是创业成功的关键。 技术挑战 AI技术的快速发展意味着创业者需要持续学习和更新知识库,以保持技术竞争力。同时,AI项目往往需要处理大量数…...

`require`与`import`的区别
require与import的区别主要体现在以下几个方面: 1.加载时间不同。require是在运行时加载模块,这意味着模块的加载和执行可以在代码的任何地方进行,也可以在运行时根据条件动态地加载不同的模块;import是在编译时加载模块…...

中介者模式:优雅解耦的利器
在软件设计中,随着系统功能的不断扩展,对象之间的依赖关系往往会变得错综复杂,导致系统难以维护和扩展。为了降低对象之间的耦合度,提高系统的可维护性和可扩展性,设计模式应运而生。中介者模式(Mediator P…...

ksail:本地Kubernetes开发环境一键搭建与云原生实践
1. 项目概述:当Kubernetes遇上本地开发如果你是一名后端或云原生方向的开发者,大概率经历过这样的场景:为了调试一个微服务,你需要在本地启动一整套依赖——数据库、消息队列、缓存,可能还有另外两三个兄弟服务。你手忙…...

轻量级代码同步工具codesyncer:P2P架构实现跨设备实时同步
1. 项目概述:一个被低估的代码同步利器如果你和我一样,经常需要在多台开发机、服务器甚至不同的云环境之间同步代码片段、配置文件或者小型项目,那你一定对那种“这台机器上有,那台机器上没有”的混乱感同身受。手动复制粘贴&…...

PCB高级工艺如何降本:盲孔、微孔与HDI设计的成本优化实战
1. 项目概述:当高级PCB技术成为降本利器在硬件研发圈子里待久了,总有一个根深蒂固的印象:但凡沾上“高级”、“高密度”这些词的技术,比如盲孔、埋孔和微孔,那成本肯定是蹭蹭往上涨。我刚开始接触HDI板设计时也是这么想…...

小熊猫Dev-C++:5个理由让你爱上这款轻量级C++开发工具
小熊猫Dev-C:5个理由让你爱上这款轻量级C开发工具 【免费下载链接】Dev-CPP A greatly improved Dev-Cpp 项目地址: https://gitcode.com/gh_mirrors/dev/Dev-CPP 在C编程的世界里,寻找一个既功能强大又简单易用的开发环境常常让初学者望而却步。…...

Android启动镜像深度解析:MagiskBoot技术实现与架构设计
Android启动镜像深度解析:MagiskBoot技术实现与架构设计 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk MagiskBoot作为Magisk项目的核心组件,专为Android启动镜像处理而生&#…...
)
从机器学习转做DFT计算?手把手教你用Python ASE库搞定VASP输入文件(含VC++14安装避坑)
从机器学习转做DFT计算?用Python ASE库高效构建VASP输入文件全指南 当机器学习背景的研究者首次接触第一性原理计算时,往往会被VASP等传统软件的复杂输入文件格式所困扰。POSCAR、INCAR、KPOINTS这些文件的手动编写不仅耗时,还容易出错。本文…...

深入u-boot目录结构:以全志V3s的LicheePi Zero为例,理解每个文件夹的作用
深入解析u-boot目录结构:全志V3s平台下的LicheePi Zero实践指南 当你第一次打开u-boot源码仓库时,面对密密麻麻的目录结构可能会感到无从下手。作为嵌入式系统开发中至关重要的启动加载程序,u-boot的架构设计既体现了通用性又兼顾了平台特异…...

B站视频转文字终极指南:3分钟学会用开源工具提取视频内容
B站视频转文字终极指南:3分钟学会用开源工具提取视频内容 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为手动记录B站视频内容而烦恼吗&…...

三步彻底解决Zotero中文文献管理的三大难题:茉莉花插件完整指南
三步彻底解决Zotero中文文献管理的三大难题:茉莉花插件完整指南 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 你是否…...

如何免费获取B站8K高清视频:哔哩下载姬完整使用教程
如何免费获取B站8K高清视频:哔哩下载姬完整使用教程 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等…...