【详细注释+流程讲解】基于深度学习的文本分类 TextCNN
前言
这篇文章用于记录阿里天池 NLP 入门赛,详细讲解了整个数据处理流程,以及如何从零构建一个模型,适合新手入门。
赛题以新闻数据为赛题数据,数据集报名后可见并可下载。赛题数据为新闻文本,并按照字符级别进行匿名处理。整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐的文本数据。实质上是一个 14 分类问题。
赛题数据由以下几个部分构成:训练集20w条样本,测试集A包括5w条样本,测试集B包括5w条样本。
比赛地址:零基础入门NLP - 新闻文本分类_学习赛_天池大赛-阿里云天池的赛制
数据可以通过上面的链接下载。
其中还用到了训练好的词向量文件。
词向量下载链接: 百度网盘 请输入提取码 提取码: qbpr
这篇文章中使用的模型主要是CNN + LSTM + Attention,主要学习的是数据处理的完整流程,以及模型构建的完整流程。虽然还没有使用 Bert 等方案,不过如果看完了这篇文章,理解了整个流程之后,即使你想要使用其他模型来处理,也能更快实现。
1. 为什么写篇文章
首先,这篇文章的代码全部都来源于 Datawhale 提供的开源代码,我添加了自己的笔记,帮助新手更好地理解这个代码。
1.1 Datawhale 提供的代码有哪些需要改进?
Datawhale 提供的代码里包含了数据处理,以及从 0 到 1模型建立的完整流程。但是和前面提供的 basesline 的都不太一样,它包含了非常多数据处理的细节,模型也是由 3 个部分构成,所以看起来难度陡然上升。
其次,代码里的注释非常少,也没有讲解整个数据处理和网络的整体流程。这些对于新手来说,增加了理解的门槛。 在数据竞赛方面,我也是一个新人,花了一天的时间,仔细研究数据在一种每一个步骤的转化,对于一些难以理解的代码,在群里询问之后,也得到了 Datawhale 成员的热心解答。最终才明白了全部的代码。
1.2 我做了什么改进?
所以,为了减少对于新手的阅读难度,我添加了一些内容。
-
首先,梳理了整个流程,包括两大部分:数据处理和模型。
因为代码不是从上到下顺序阅读的。因此,更容易让人理解的做法是:先从整体上给出宏观的数据转换流程图,其中要包括数据在每一步的 shape,以及包含的转换步骤,让读者心中有一个框架图,再带着这个框架图去看细节,会更加了然于胸。
-
其次,除了了解了整体流程,在真正的代码细节里,读者可能还是会看不懂某一段小逻辑。因此,我在原有代码的基础之上增添了许多注释,以降低代码的理解门槛。
2. 数据处理
2.1 数据拆分为 10 份
数据首先会经过all_data2fold函数,这个函数的作用是把原始的 DataFrame 数据,转换为一个list,有 10 个元素,表示交叉验证里的 10 份,每个元素是 dict,每个dict包括 label 和 text。
首先根据 label 来划分数据行所在 index, 生成 label2id。
label2id 是一个 dict,key 为 label,value 是一个 list,存储的是该类对应的 index。
然后根据`label2id`,把每一类别的数据,划分到 10 份数据中。最终得到的数据`fold_data`是一个`list`,有 10 个元素,每个元素是 `dict`,包括 `label` 和 `text`的列表:`[{labels:textx}, {labels:textx}. . .]`。
最后,把前 9 份数据作为训练集train_data,最后一份数据作为验证集dev_data,并读取测试集test_data。
2.2 定义并创建 Vacab
Vocab 的作用是:
-
创建 词 和
index对应的字典,这里包括 2 份字典,分别是:_id2word和_id2extword。 -
其中
_id2word是从新闻得到的, 把词频小于 5 的词替换为了UNK。对应到模型输入的batch_inputs1。 -
_id2extword是从word2vec.txt中得到的,有 5976 个词。对应到模型输入的batch_inputs2。 -
后面会有两个
embedding层,其中_id2word对应的embedding是可学习的,_id2extword对应的embedding是从文件中加载的,是固定的。 -
创建 label 和 index 对应的字典。
-
上面这些字典,都是基于
train_data创建的。
3. 模型
3.1 把文章分割为句子
上上一步得到的 3 个数据,都是一个list,list里的每个元素是 dict,每个 dict 包括 label 和 text。这 3 个数据会经过 get_examples函数。 get_examples函数里,会调用sentence_split函数,把每一篇文章分割成为句子。
然后,根据vocab,把 word 转换为对应的索引,这里使用了 2 个字典,转换为 2 份索引,分别是:word_ids和extword_ids。最后返回的数据是一个 list,每个元素是一个 tuple: (label, 句子数量,doc)。其中doc又是一个 list,每个 元素是一个 tuple: (句子长度,word_ids, extword_ids)。
在迭代训练时,调用data_iter函数,生成每一批的batch_data。在data_iter函数里,会调用batch_slice函数生成每一个batch。拿到batch_data后,每个数据的格式仍然是上图中所示的格式,下面,调用batch2tensor函数。
3.2 生成训练数据
batch2tensor函数最后返回的数据是:(batch_inputs1, batch_inputs2, batch_masks), batch_labels。形状都是(batch_size, doc_len, sent_len)。doc_len表示每篇新闻有几句话,sent_len表示每句话有多少个单词。
batch_masks在有单词的位置,值为1,其他地方为 0,用于后面计算 Attention,把那些没有单词的位置的 attention 改为 0。
batch_inputs1, batch_inputs2, batch_masks,形状是(batch_size, doc_len, sent_len),转换为(batch_size * doc_len, sent_len)。
3.3 网络部分
下面,终于来到网络部分。模型结构图如下:
3.3.1 WordCNNEncoder
WordCNNEncoder 网络结构示意图如下:
1. Embedding
batch_inputs1, batch_inputs2都输入到WordCNNEncoder。WordCNNEncoder包括两个embedding层,分别对应batch_inputs1,embedding 层是可学习的,得到word_embed;batch_inputs2,读取的是外部训练好的词向量,因此是不可学习的,得到extword_embed。所以会分别得到两个词向量,将 2 个词向量相加,得到最终的词向量batch_embed,形状是(batch_size * doc_len, sent_len, 100),然后添加一个维度,变为(batch_size * doc_len, 1, sent_len, 100),对应 Pytorch 里图像的(B, C, H, W)。
2. CNN
然后,分别定义 3 个卷积核,output channel 都是 100 维。
第一个卷积核大小为[2,100],得到的输出是(batch_size * doc_len, 100, sent_len-2+1, 1),定义一个池化层大小为[sent_len-2+1, 1],最终得到输出经过squeeze()的形状是(batch_size * doc_len, 100)。
同理,第 2 个卷积核大小为[3,100],第 3 个卷积核大小为[4,100]。卷积+池化得到的输出形状也是(batch_size * doc_len, 100)。
最后,将这 3 个向量在第 2 个维度上做拼接,得到输出的形状是(batch_size * doc_len, 300)。
3.3.2 shape 转换
把上一步得到的数据的形状,转换为(batch_size , doc_len, 300)名字是sent_reps。然后,对mask进行处理。
batch_masks的形状是(batch_size , doc_len, 300),表示单词的 mask,经过sent_masks = batch_masks.bool().any(2).float()得到句子的 mask。含义是:在最后一个维度,判断是否有单词,只要有 1 个单词,那么整句话的 mask 就是 1,sent_masks的维度是:(batch_size , doc_len)。
3.3.3 SentEncoder
SentEncoder 网络结构示意图如下:
SentEncoder包含了 2 层的双向 LSTM,输入数据sent_reps的形状是(batch_size , doc_len, 300),LSTM 的 hidden_size 为 256,由于是双向的,经过 LSTM 后的数据维度是(batch_size , doc_len, 512),然后和 mask 按位置相乘,把没有单词的句子的位置改为 0,最后输出的数据sent_hiddens,维度依然是(batch_size , doc_len, 512)。
3.3.4 Attention
接着,经过Attention。Attention的输入是sent_hiddens和sent_masks。在Attention里,sent_hiddens首先经过线性变化得到key,维度不变,依然是(batch_size , doc_len, 512)。
然后key和query相乘,得到outputs。query的维度是512,因此output的维度是(batch_size , doc_len),这个就是我们需要的attention,表示分配到每个句子的权重。下一步需要对这个attetion做softmax,并使用sent_masks,把没有单词的句子的权重置为-1e32,得到masked_attn_scores。
最后把masked_attn_scores和key相乘,得到batch_outputs,形状是(batch_size, 512)。
3.3.5 FC
最后经过FC层,得到分类概率的向量。
4. 完整代码+注释
4.1 数据处理
导入包
import random
import numpy as np
import torch
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)-15s %(levelname)s: %(message)s')
查看本文全部内容,欢迎访问天池技术圈官方地址:【详细注释+流程讲解】基于深度学习的文本分类 TextCNN_天池技术圈-阿里云天池
相关文章:

【详细注释+流程讲解】基于深度学习的文本分类 TextCNN
前言 这篇文章用于记录阿里天池 NLP 入门赛,详细讲解了整个数据处理流程,以及如何从零构建一个模型,适合新手入门。 赛题以新闻数据为赛题数据,数据集报名后可见并可下载。赛题数据为新闻文本,并按照字符级别进行匿名…...

Day.21
interface MyInterface{public final static int PI 3;void show();public default void printX(){System.out.println("接口默认方法");}public static void printY(){System.out.println("接口静态方法");}}class MyClass implements MyInterface{publi…...

Spring-IoC 基于注解
基于xml方法见:http://t.csdnimg.cn/dir8j 注解是代码中的一种特殊标记,可以在编译、类加载和运行时被读取,执行相应的处理,简化 Spring的 XML配置。 格式:注解(属性1"属性值1",...) 可以加在类上…...
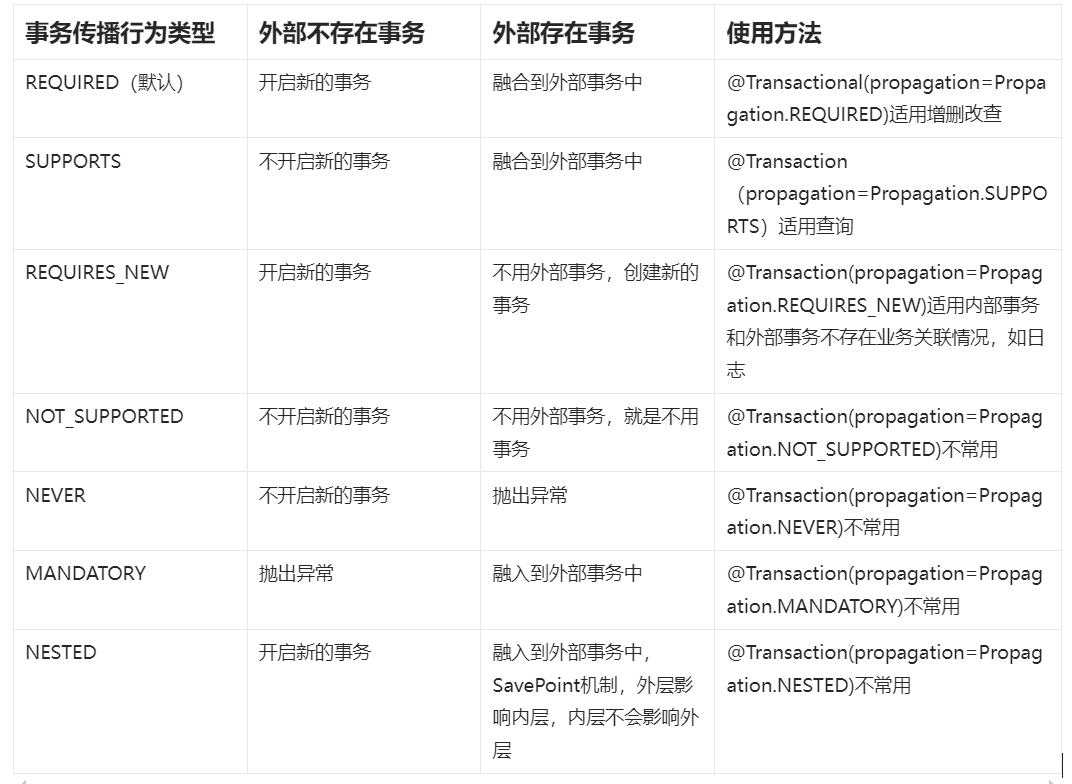
Spring声明式事务以及事务传播行为
Spring声明式事务以及事务传播行为 Spring声明式事务1.编程式事务2.使用AOP改造编程式事务3.Spring声明式事务 事务传播行为 如果对数据库事务不太熟悉,可以阅读上一篇博客简单回顾一下:MySQL事务以及并发访问隔离级别 Spring声明式事务 事务一般添加到…...

【C语言数据库】Sqlite3基础介绍
1. SQLite简介 SQLite is a C-language library that implements a small, fast, self-contained, high-reliability, full-featured, SQL database engine. SQLite is the most used database engine in the world. SQLite is built into all mobile phones and most computer…...
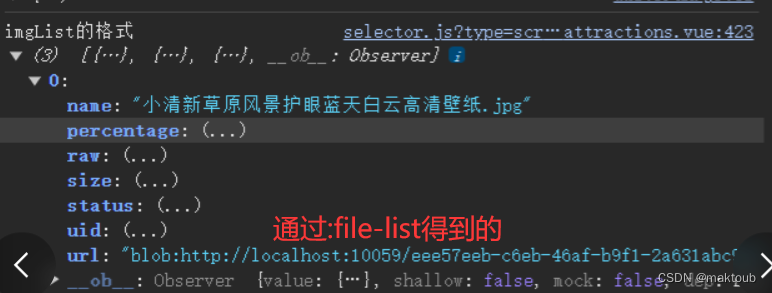
el-upload上传图片图片、el-load默认图片重新上传、el-upload初始化图片、el-upload编辑时回显图片
问题 我用el-upload上传图片,再上一篇文章已经解决了,el-upload上传图片给SpringBoot后端,但是又发现了新的问题,果然bug是一个个的冒出来的。新的问题是el-upload编辑时回显图片的保存。 问题描述:回显图片需要将默认的 file-lis…...
【拓扑空间】示例及详解1
例1 度量空间的任意两球形邻域的交集是若干球形邻域的并集 Proof: 任取空间的两个球形邻域、,令 任取,令 球形领域 例2 规定X的子集族,证明是X上的一个拓扑 Proof: 1. 2., (若干个球形邻域的并集都是的元素,元素…...

linux安装jdk8
上传到某个目录,例如:/usr/local/ tar -xvf jdk-8u144-linux-x64.tar.gz配置环境变量: export JAVA_HOME/usr/local/java export PATH$PATH:$JAVA_HOME/bin设置环境变量: source /etc/profile...
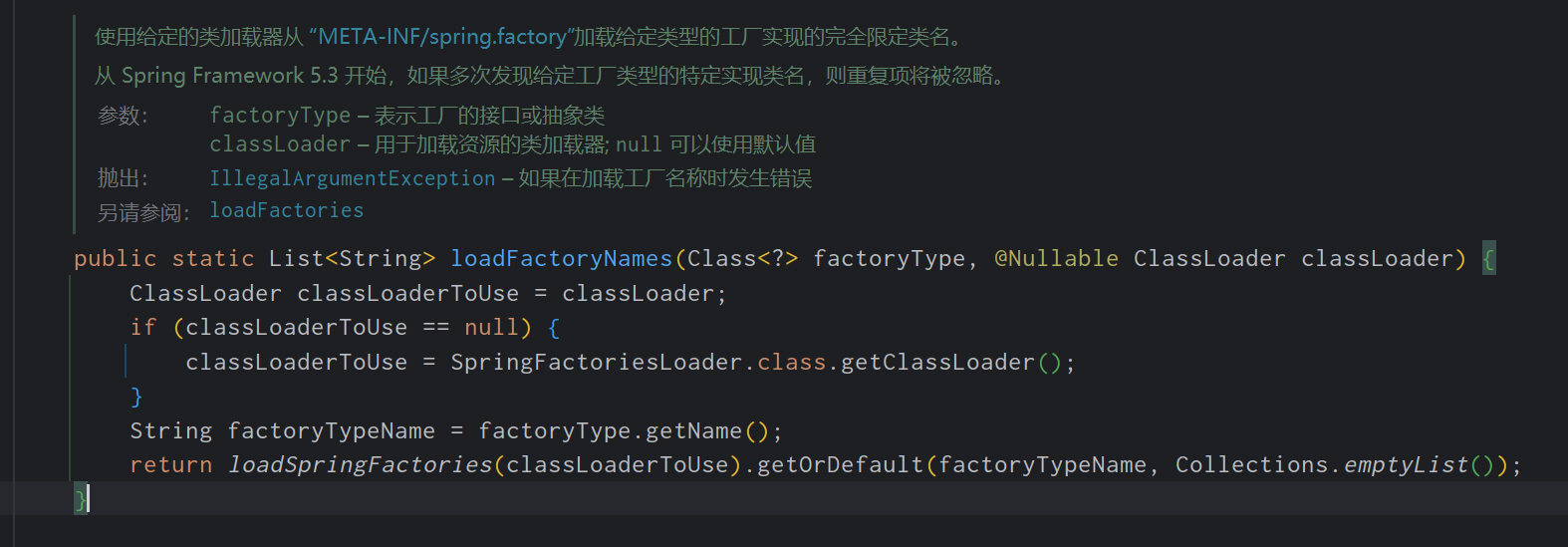
Spring重点知识(个人整理笔记)
目录 1. 为什么要使用 spring? 2. 解释一下什么是 Aop? 3. AOP有哪些实现方式? 4. Spring AOP的实现原理 5. JDK动态代理和CGLIB动态代理的区别? 6. 解释一下什么是 ioc? 7. spring 有哪些主要模块?…...

HTML基础知识详解(上)(如何想知道html的全部基础知识点,那么只看这一篇就足够了!)
前言:在学习前端基础时,必不可少的就是三大件(html、css、javascript ),而HTML(超文本标记语言——HyperText Markup Language)是构成 Web 世界的一砖一瓦,它定义了网页内容的含义和…...

如何借助Idea创建多模块的SpringBoot项目
目录 1.1、前言1.2、开发环境1.3、项目多模块结构1.4、新建父工程1.5、创建子模块1.6、编辑父工程的pom.xml文件 1.1、前言 springmvc项目,一般会把项目分成多个包:controler、service、dao、utl等,但是随着项目的复杂性提高,想复用其他一个模…...

爬虫 新闻网站 并存储到CSV文件 以红网为例 V1.0
爬虫:红网网站, 获取当月指定关键词新闻,并存储到CSV文件 V1.0 目标网站:红网 爬取目的:为了获取某一地区更全面的在红网已发布的宣传新闻稿,同时也让自己的工作更便捷 环境:Pycharm2021&#…...

CentOS 使用 Cronie 实现定时任务
CentOS 使用 Cronie 实现定时任务 文章目录 CentOS 使用 Cronie 实现定时任务一、简介二、基本使用1、常用命令2、使用示例第一步:创建脚本/home/create.sh第二步:添加定时任务第三步:重启 cronie 服务额外:查看 cronie 运行状态定…...
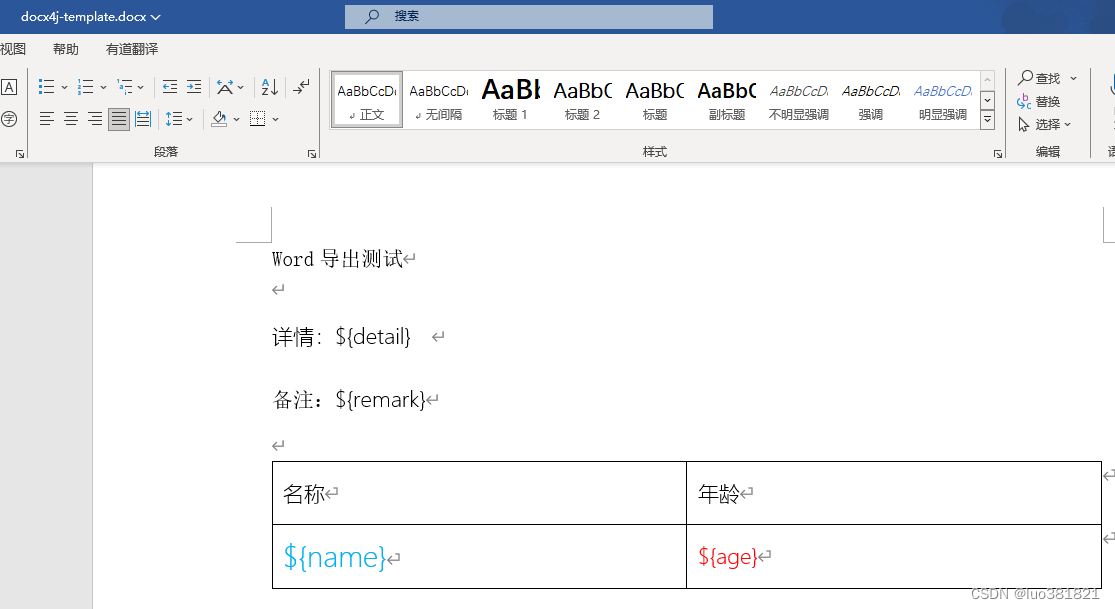
java生成word
两种方案 一、poi-tl生成word <dependency><groupId>com.deepoove</groupId><artifactId>poi-tl</artifactId><version>1.12.1</version> </dependency> public static void main(String[] args) throws Exception {String…...

C语言中的结构体:揭秘数据的魔法盒
前言 在C语言的广阔天地中,结构体无疑是一颗璀璨的明珠。它就像是一个魔法盒,能够容纳各种不同类型的数据,并按我们的意愿进行组合和排列。那么,这个魔法盒究竟有何神奇之处呢?让我们一探究竟。 一、结构体的诞生&…...

Listener
文章目录 ListenerServletContextListenerServletContextAttributeListenerHttpSessionListenerHttpSessionAttributeListenerServletRequestListenerServletRequestAttributeListenerHttpSessionBindingListenerHttpSessionActivationListener Listener Listener 监听器它是 J…...

单细胞RNA测序(scRNA-seq)SRA数据下载及fastq-dumq数据拆分
单细胞RNA测序(scRNA-seq)入门可查看以下文章: 单细胞RNA测序(scRNA-seq)工作流程入门 单细胞RNA测序(scRNA-seq)细胞分离与扩增 1. NCBI查询scRNA-seq SRA数据 NCBI地址: https…...

金蝶Apusic应用服务器 未授权目录遍历漏洞复现
0x01 产品简介 金蝶Apusic应用服务器(Apusic Application Server,AAS)是一款标准、安全、高效、集成并具丰富功能的企业级应用服务器软件,全面支持JakartaEE8/9的技术规范,提供满足该规范的Web容器、EJB容器以及WebService容器等,支持Websocket1.1、Servlet4.0、HTTP2.0…...

成都百洲文化传媒有限公司电商服务的新领军者
在当今数字化时代,电商行业正以前所未有的速度蓬勃发展。在这个大背景下,成都百洲文化传媒有限公司凭借其深厚的行业经验和精湛的专业技能,正迅速崛起为电商服务领域的新领军者。 一、专业引领,成就卓越 作为一家专注于电商服务的…...

从无到有开始创建动态顺序表——C语言实现
顺序表的概念 顺序表的底层结构是数组,对数组的封装,实现了常用的增删改查等接口。在物理结构和逻辑结构都是连续的,物理结构是指顺序表在计算机内存的存储方式,逻辑结构是我们思考的形式,顺序表和数组是类似的&#x…...
)
从漏极、栅极到源极开关:手把手教你选对单端电荷泵拓扑(基于噪声与速度权衡)
从漏极、栅极到源极开关:单端电荷泵拓扑的噪声与速度权衡实战指南 在锁相环(PLL)设计中,电荷泵的性能往往成为整个系统相位噪声和杂散特性的瓶颈。特别是当设计目标同时包含低带内相位噪声和高开关速度时,单端电荷泵的拓扑选择就变得尤为关键…...

【限时公开】20年农业AI工程师压箱底的17条精度校验铁律:从田间采集到模型上线零容错实践手册
第一章:农业图像识别精度校验的底层逻辑与行业特殊性农业图像识别并非通用计算机视觉任务的简单迁移,其精度校验需直面田间场景固有的复杂性:光照剧烈波动、作物生长阶段连续变化、病斑形态高度异质、背景杂草与土壤纹理干扰显著。这些因素共…...

Vue 3 Fragments:打破枷锁的组件化革命
Vue 3 Fragments:打破枷锁的组件化革命 在前端框架的演进史上,每一次对底层限制的突破,往往都伴随着开发体验的质的飞跃。Vue 3 中引入的 Fragments(片段) 特性,正是这样一场迟来的“解绑”革命。它彻底粉碎…...

OpenClaw+Qwen3-32B低成本方案:RTX4090D镜像长任务稳定性实测
OpenClawQwen3-32B低成本方案:RTX4090D镜像长任务稳定性实测 1. 为什么需要测试长任务稳定性? 上周我遇到一个头疼的问题:用OpenClaw整理3年积累的摄影素材时,任务执行到2小时突然中断。检查日志发现是显存溢出导致模型服务崩溃…...

Node.js 轻量级数据库 NeDB 实战指南:从入门到精通
1. 为什么你需要了解NeDB 如果你正在寻找一个轻量级的Node.js数据库解决方案,NeDB绝对值得你花时间研究。作为一个嵌入式数据库,它不需要单独运行数据库服务,数据可以直接存储在内存或磁盘文件中。我在多个小型项目中使用过NeDB,最…...

The Leather Archive应用案例:从赛博都市到极简主义的皮衣穿搭
The Leather Archive应用案例:从赛博都市到极简主义的皮衣穿搭 1. 项目概述 「The Leather Archive」是一个基于AI技术的高端皮衣穿搭生成系统,它巧妙融合了Anything V5基础模型与Stable Yogi皮衣系列LoRA的专业能力。与传统AI工具不同,该项…...

5分钟掌握League Akari:英雄联盟玩家的智能助手终极指南
5分钟掌握League Akari:英雄联盟玩家的智能助手终极指南 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari…...

十大经典排序算法解析与实现
## 1. 十大经典排序算法技术解析### 1.1 算法分类体系 排序算法可分为两大技术类别:**比较类排序**: - 通过元素间比较确定相对次序 - 时间复杂度下限为O(nlogn) - 典型代表:快速排序、堆排序、归并排序**非比较类排序**: - 不依赖…...

南北阁 4.1-3B 开源镜像实战:Streamlit轻量化UI+CoT折叠展示一文详解
南北阁 4.1-3B 开源镜像实战:Streamlit轻量化UICoT折叠展示一文详解 想快速体验一个能在本地流畅运行、还能“看见”模型思考过程的智能对话工具吗?今天要介绍的,就是基于南北阁(Nanbeige)4.1-3B模型打造的轻量化流式…...

LiuJuan Z-Image Generator参数详解:CFG Scale=2.0与12步生成高质量人像
LiuJuan Z-Image Generator参数详解:CFG Scale2.0与12步生成高质量人像 想用AI生成一张惊艳的人像照片,却发现要么细节模糊,要么风格怪异,怎么调参数都达不到理想效果?如果你也遇到过类似问题,那今天这篇文…...