【SQL Server】2. 将数据导入导出到Excel表格当中
最开始,博主介绍一下自己的环境:SQL Sever 2008 R2
SQL Sever 大致都差不多
1. 通过自带软件的方式
首先找到下载SQL Sever中提供的导入导出工具


如果开始界面没有找到自己下载的路径
C:\Program Files\Microsoft SQL Server\100\DTS\Binn下的DTSWizard.exe文件

导出
1.1 打开界面
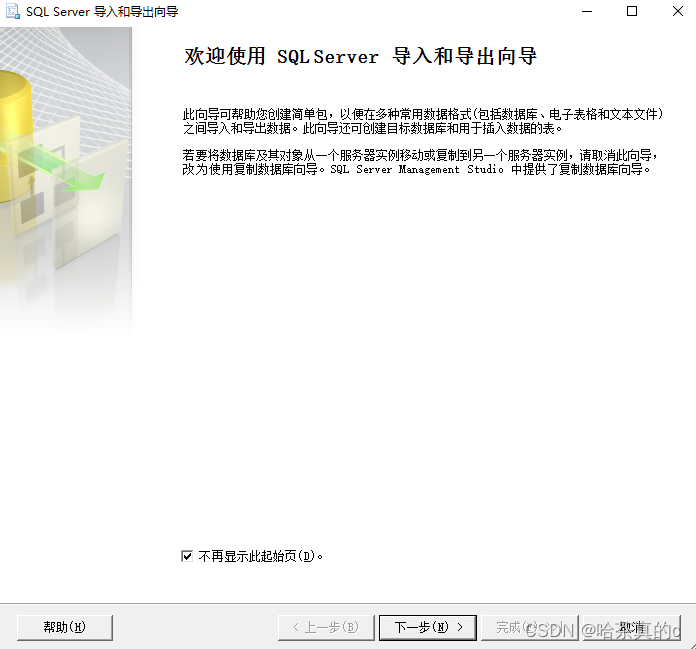
1.2 选择自己的数据源和数据库
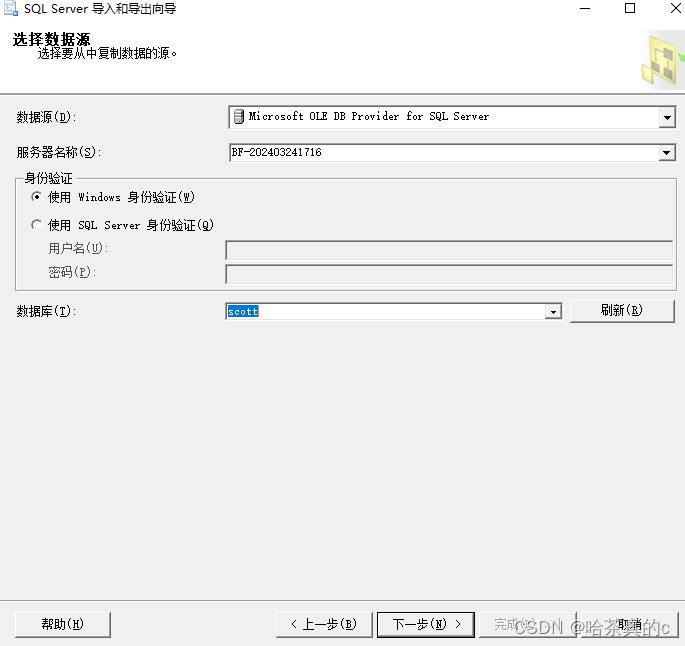
1.3 选择导出目标
这里博主导出到Excel文件当中
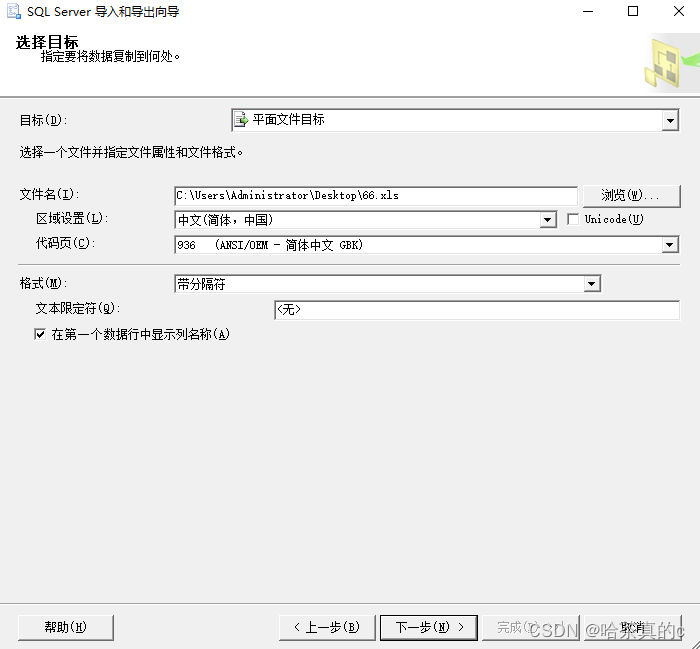
1.4 选择直接导出数据还是进行查询
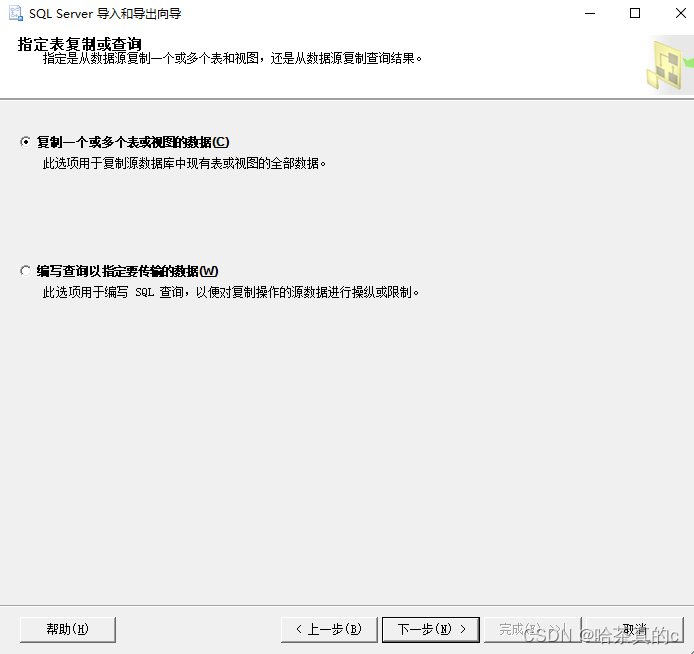
查询的话将自己在SSMS上编写的SQL语句直接复制到框中即可(确保SQL正确,可以进行测试!)
这里博主直接导出表中数据
1.5 选择表目标
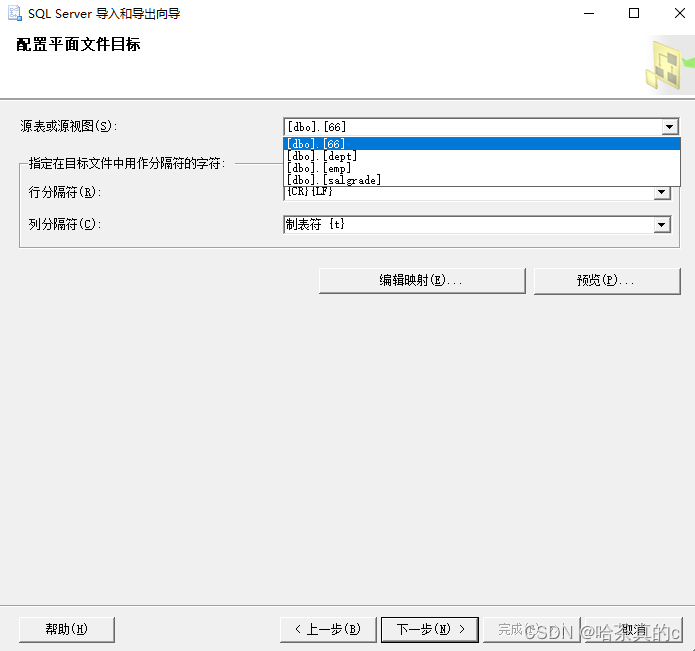
这里需要切记表的分隔符为:
行:{CR}{LF}
列:制表符
格式不对,可能导出的结构出错
(也就是不按照行列的方式导入到Excel当中!)
1.6 完成导出
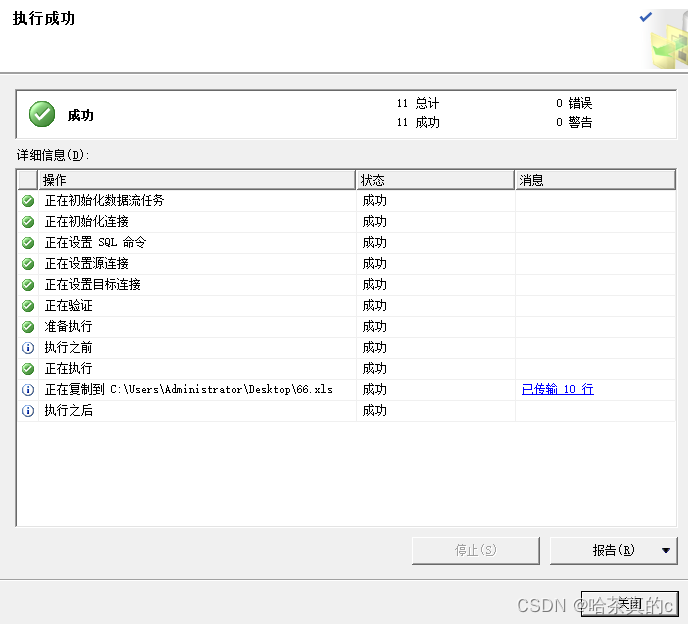
1.7 检查是否导出成功
可以看到Excel表格中出现新数据!
导入
1.1 打开界面
1.2 选择数据源
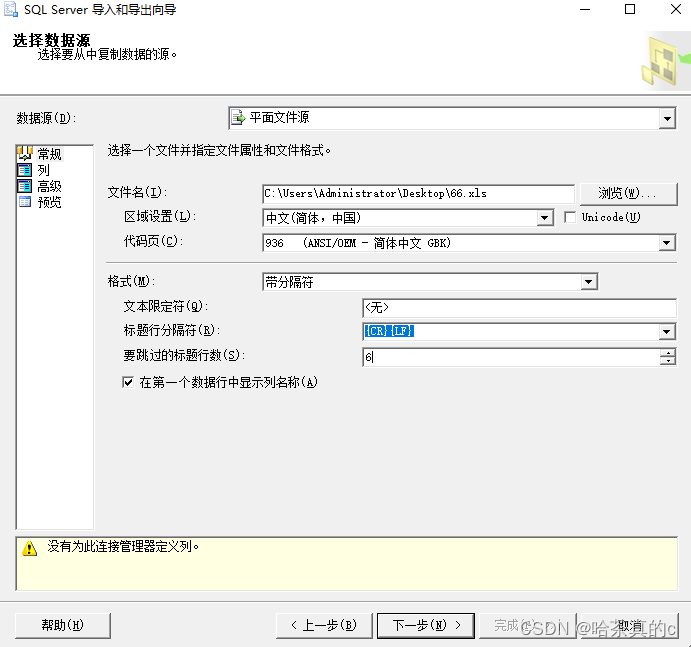
这里博主选择的是Excel表格
这里的标题分隔符选{CR}{LF}
这里博主前面有6行垃圾数据(所以选择跳过6行)
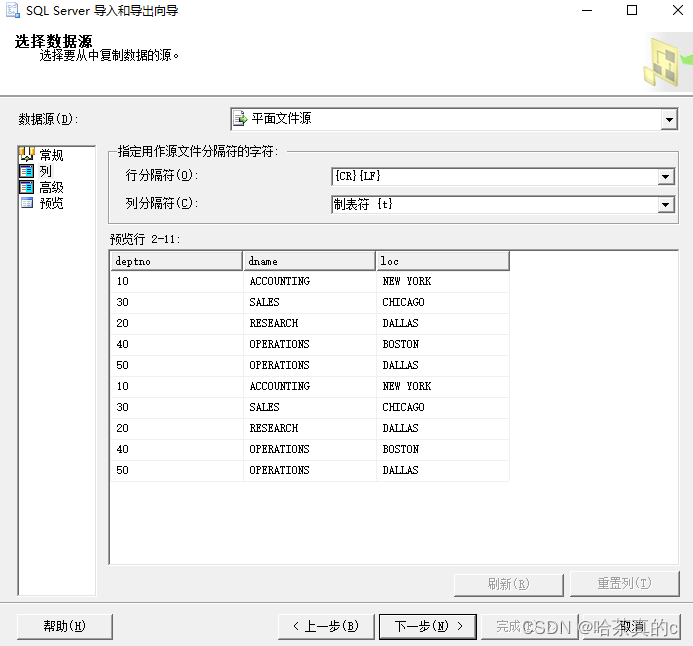
行分隔符{CR}{LF}
列分隔符制表符
1.3 选择导入目标数据库
选择自己的服务器和数据库
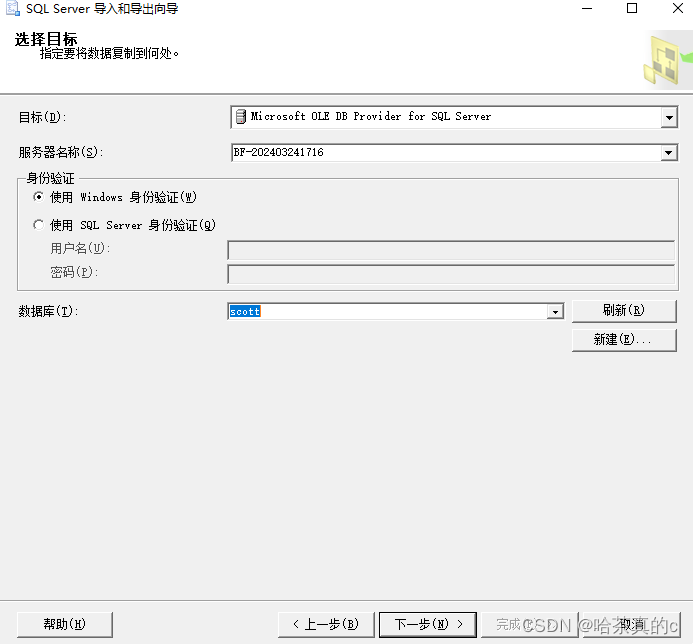
1.4 选择表
导入的目标表
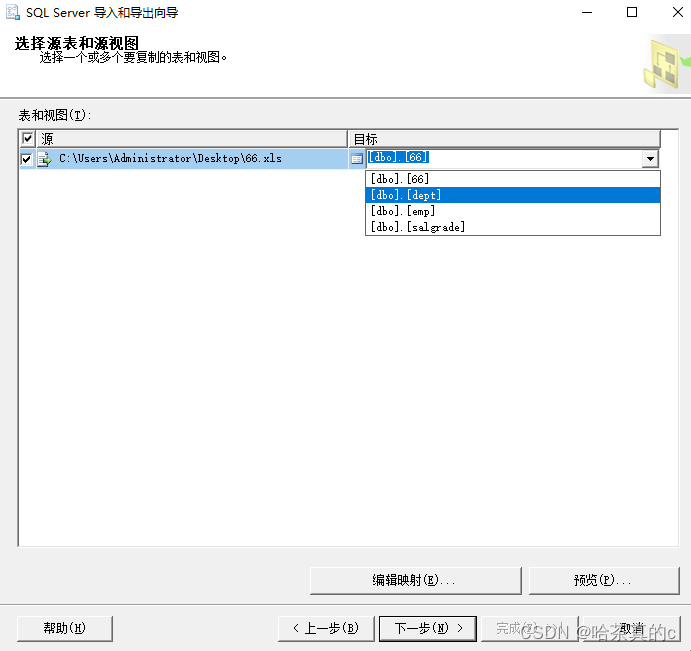
1.5 选择数据类型映射
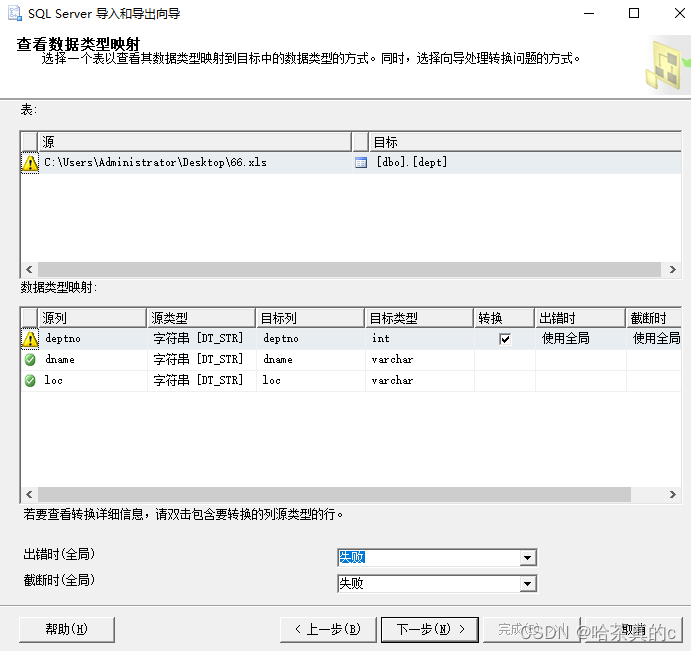
1.6 完成导入
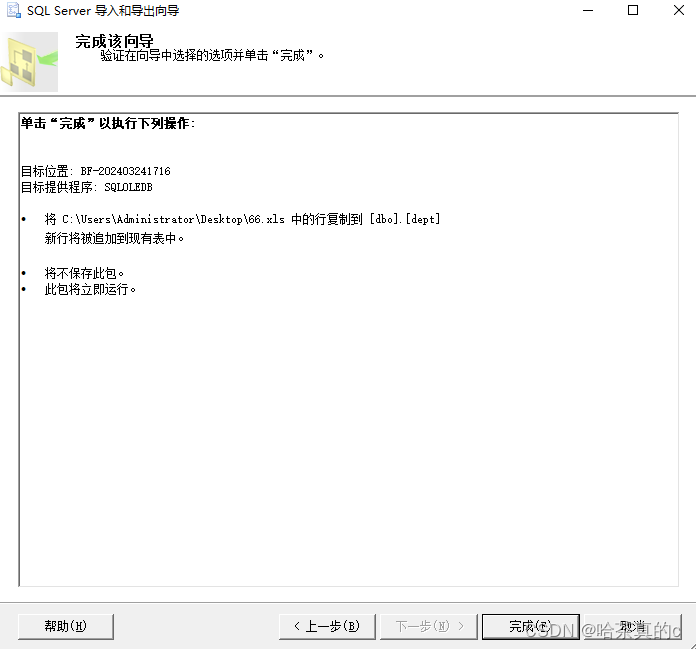
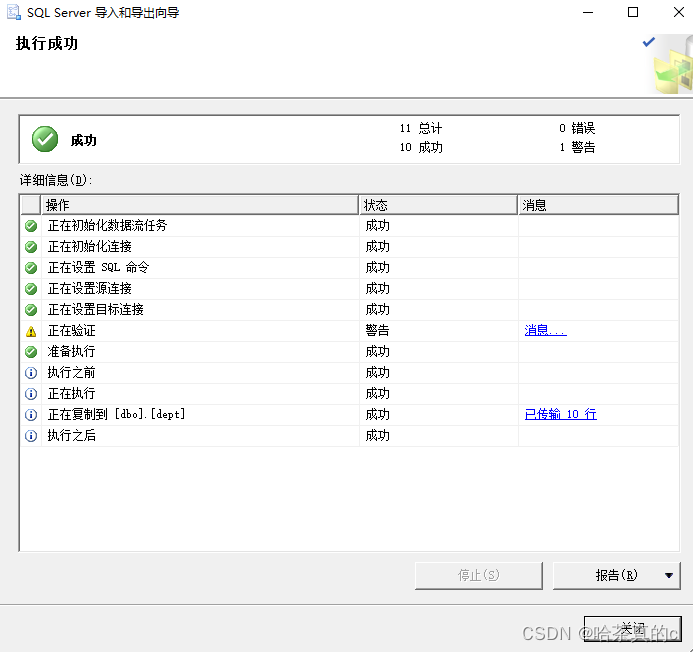
1.7 检查是否导入成功
选择SSMS工具
打开对应的表和数据行
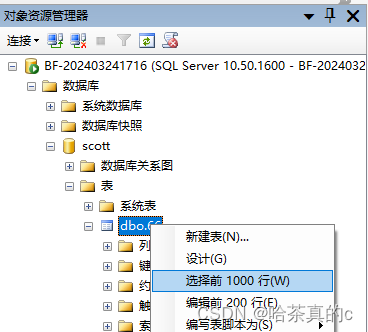
查看数据,可以看到数据导入成功!
SQL Sever 2008 R2 存在的问题:
这是SQLSever2008R2所独有的,其他版本不清楚,自行了解!
对于还未和SQL Sever数据库建立过链接的新建Excel表格无法导入导出数据!
所以咱们需要先让Excel表格和数据库建立连接
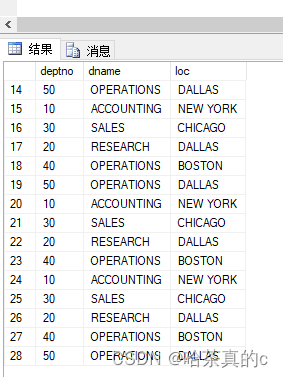
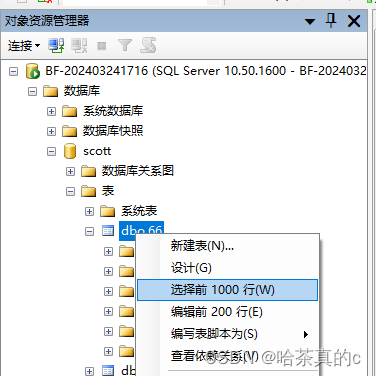
1.1 随便找个表查看表中数据
1.2 选择将结果保存到文件
右键SQL语句框出现如下界面
1.3 右键选择执行
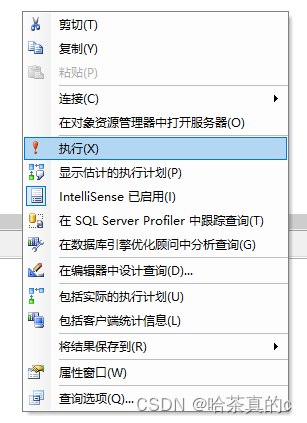
1.4 保存结果
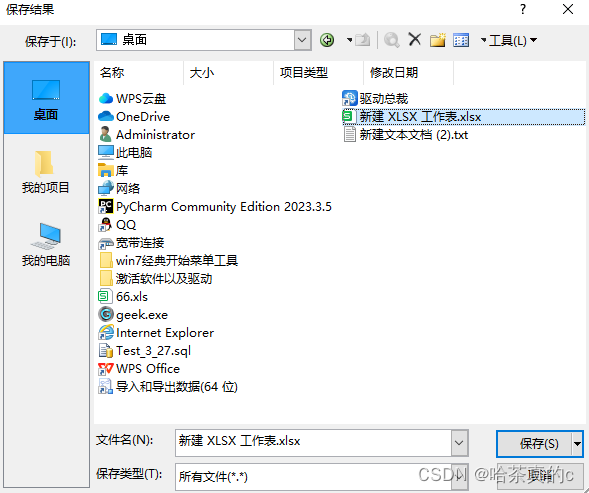
1.5 查看文件
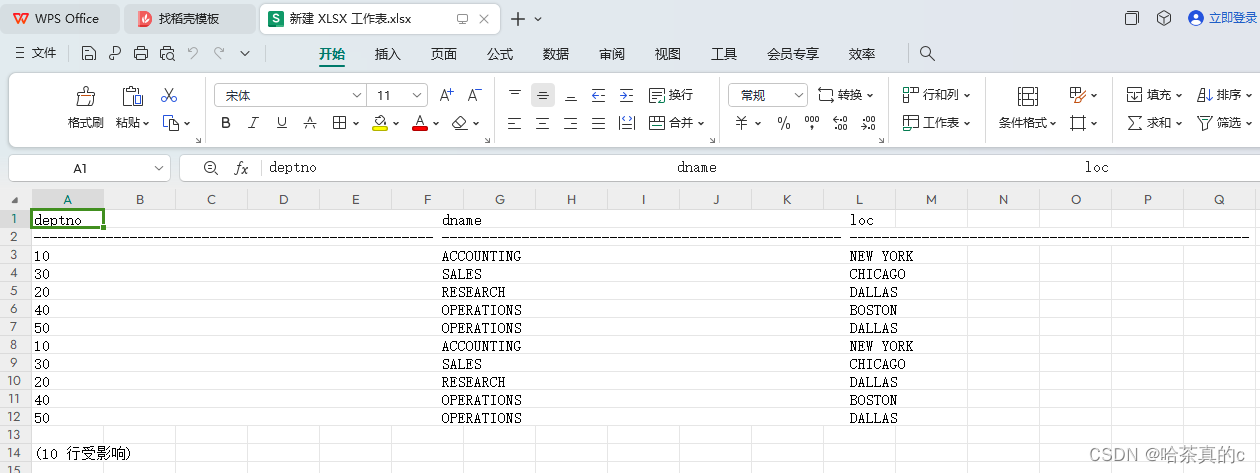
可以看到Excel文件中出现了数据,但是这些数据无法分析(无效数据),将这些数据删除就可以正常进行导入导出。
2. 通过Pycharm(ODBC)的方式
代码如下所示:
import pyodbc
import pandas as pd
# 创建连接字符串
conn_str = (r'DRIVER={SQL Server Native Client 10.0};'r'SERVER=BF-202403241716;'r'DATABASE=scott;'r'Trusted_Connection=Yes;'
)
# 建立连接
cnxn = pyodbc.connect(conn_str)
# 创建游标对象
cursor = cnxn.cursor()
# 执行SQL查询
query = "SELECT * FROM dbo.salgrade"
cursor.execute(query)
# 获取查询结果
data1 = cursor.fetchall()
print(type(data1))
print(data1)# 获取列名
columns1 = [column[0] for column in cursor.description]
print(type(columns1))
print(columns1)# 将元组列表展开为一维数组
data1 = [list(item) for item in data1]
print(type(data1))
print(data1)# 将结果转换为DataFrame
df1 = pd.DataFrame(data1, columns=columns1)
print(df1)# 将数据写入Excel文件
df1.to_excel('output.xlsx', index=False)# 关闭数据库连接
cursor.close()
cnxn.close()
关键点1:连接方式
数据库是:SQL Sever 2008 R2 所以这里采用的连接方式是SQL Sever Native Client 10.0 如果是更新的版本应该是16或者其他
(可以问问ChartGPT)
# 创建连接字符串
conn_str = (r'DRIVER={SQL Server Native Client 10.0};'r'SERVER=BF-202403241716;'r'DATABASE=scott;'r'Trusted_Connection=Yes;'
)
具体的服务器和数据库按照自己的来,这里我SQL Sever通过验证的方式是Windows验证,所以这里r'Trusted_Connection=Yes;' 如果有用户密码,请使用用户密码的方式登录。
关键点2:元组列表需要转换为一维数组(???)
# 将元组列表展开为一维数组
data1 = [list(item) for item in data1]
print(type(data1))
print(data1)
<class 'list'>
[(1, 700, 1200), (2, 1201, 1400), (3, 1401, 2000), (4, 2001, 3000), (5, 3001, 9999)]
<class 'list'>
[[1, 700, 1200], [2, 1201, 1400], [3, 1401, 2000], [4, 2001, 3000], [5, 3001, 9999]]grade losal hisal
0 1 700 1200
1 2 1201 1400
2 3 1401 2000
3 4 2001 3000
4 5 3001 9999
需要将元组列表展开为一维数组
原因:data1 是一个包含元组的列表,每个元组都是一个行,但是传递给DataFrame的每行数据应该是一维的,如果不进行转换,那么传递的数据就是二维的
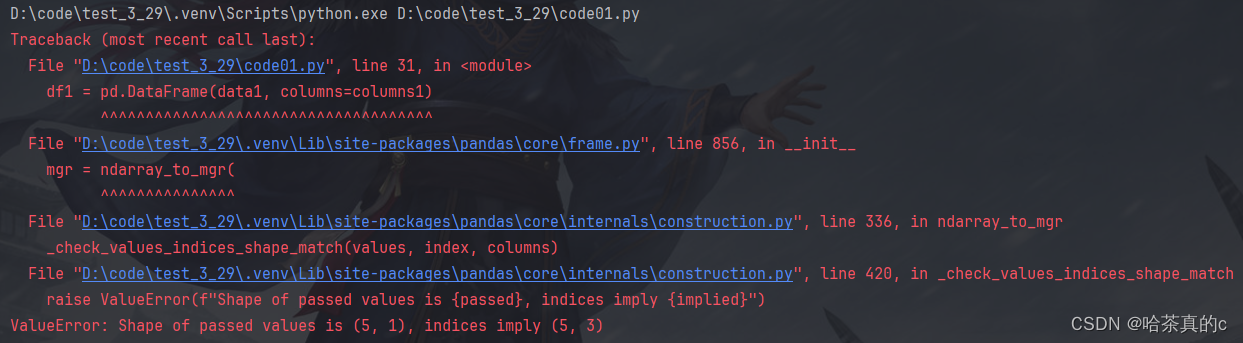
会出现如下类型不匹配的报错==(解决了半天,还是有点不理解)==
import pyodbc
import pandas as pd# 假设data是cursor.fetchall()返回的结果,它是一个包含元组的列表
data = [(1, 700, 1200), (2, 1201, 1400), (3, 1401, 2000), (4, 2001, 3000), (5, 3001, 9999)]
print(type(data))
print(data)
# 获取列名
columns = ['grade', 'losal', 'hisal'] # 确保这些列名与您的表中的列名相匹配
print(type(columns))
print(columns)# 将结果转换为DataFrame
df = pd.DataFrame(list(data), columns=columns)
print(df)
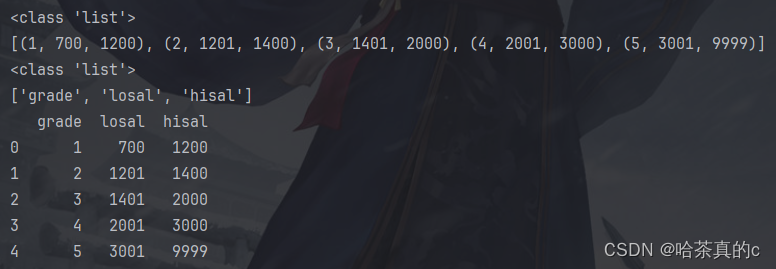
code2当中代码如上,同样还是一个包含元组的列表,但是就是可以转换成DataFrame的形式==(很奇怪啊)==
关键点3:import导包
如果直接从官网进行下载的话,速度可能会很慢,而且有时候还会断开连接,所以可以选择一些国内的镜像网站
pip install some-package -i https://pypi.tuna.tsinghua.edu.cn/simple
以下这种方式就很慢:
(.venv) PS D:\code\test_3_29> pip install openpyxl
Collecting openpyxlDownloading openpyxl-3.1.2-py2.py3-none-any.whl.metadata (2.5 kB)
Collecting et-xmlfile (from openpyxl)Downloading et_xmlfile-1.1.0-py3-none-any.whl.metadata (1.8 kB)
Downloading openpyxl-3.1.2-py2.py3-none-any.whl (249 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 250.0/250.0 kB 547.4 kB/s eta 0:00:00
Downloading et_xmlfile-1.1.0-py3-none-any.whl (4.7 kB)
Installing collected packages: et-xmlfile, openpyxl
Successfully installed et-xmlfile-1.1.0 openpyxl-3.1.2
成功结果如下:
方法放在gitee上了,自取哟!
相关文章:
【SQL Server】2. 将数据导入导出到Excel表格当中
最开始,博主介绍一下自己的环境:SQL Sever 2008 R2 SQL Sever 大致都差不多 1. 通过自带软件的方式 首先找到下载SQL Sever中提供的导入导出工具 如果开始界面没有找到自己下载的路径 C:\Program Files\Microsoft SQL Server\100\DTS\Binn下的DTSWiz…...

基于JAVA+SSM+VUE的前后端分离的大学竞赛管理系统
一、项目背景介绍: 随着互联网技术的快速发展,大学竞赛管理系统已经成为了各个高校组织和管理各类学术竞赛的重要工具。传统的大学竞赛管理系统往往采用前后端混合的开发模式,导致系统的性能和可维护性受到限制。为了提高系统的开发效率和用户…...

音频转换工具 Bigasoft FLAC Converter for Mac
Bigasoft FLAC Converter for Mac是一款专为Mac用户设计的音频转换工具,它能够将FLAC音频文件高效、高质量地转换为其他常见的音频格式,如MP3、AAC等。这款软件具有直观易用的界面,使用户能够轻松上手,无需复杂的操作步骤即可完成…...

洛谷 P4554 小明的游戏
思路:双端队列。 其实一开始你可以用BFS进行实验,由于我们需要找最小的费用,所以我们在BFS的时候可以这样想:在我们遍历到第一块板子的时候,在找周围的路时,我们可以改成这样的判断:如果周围的…...
序列化案例实操(统计每一个手机号耗费的总上行流量、总下行流量、总流量)
文章目录 序列化概述自定义bean对象实现序列化接口(Writable)案例需求编写MapReduce程序运行结果 序列化概述 序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化&…...

使用 LLMLingua-2 压缩 GPT-4 和 Claude 提示
原文地址:Compress GPT-4 and Claude prompts with LLMLingua-2 2024 年 4 月 1 日 向大型语言模型(LLM)发送的提示长度越短,推理速度就会越快,成本也会越低。因此,提示压缩已经成为LLM研究的热门领域。 …...

编程大牛坚持了 10 年的 10 个编程好习惯
目录 1.多看官方文档 2.面向搜索引擎编程 3.规范命名 4.认真注释 5.不要重复造轮子 6.多读多写代码 7.预留开发时间 8.大胆重构 9.师傅领进门 10.多阅读源码 1.多看官方文档 不要被这几个字吓到,官方文档其实都是宝藏。 一个成熟的技术诞生,…...
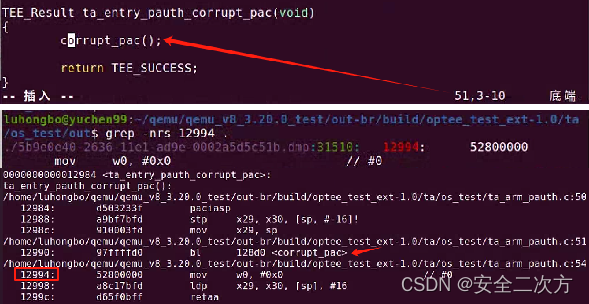
QEMU上PAC功能验证与异常解析
PAC功能如何验证?PAC检查失败时发生什么?问题如何定位?本博客主要探讨这些问题。...
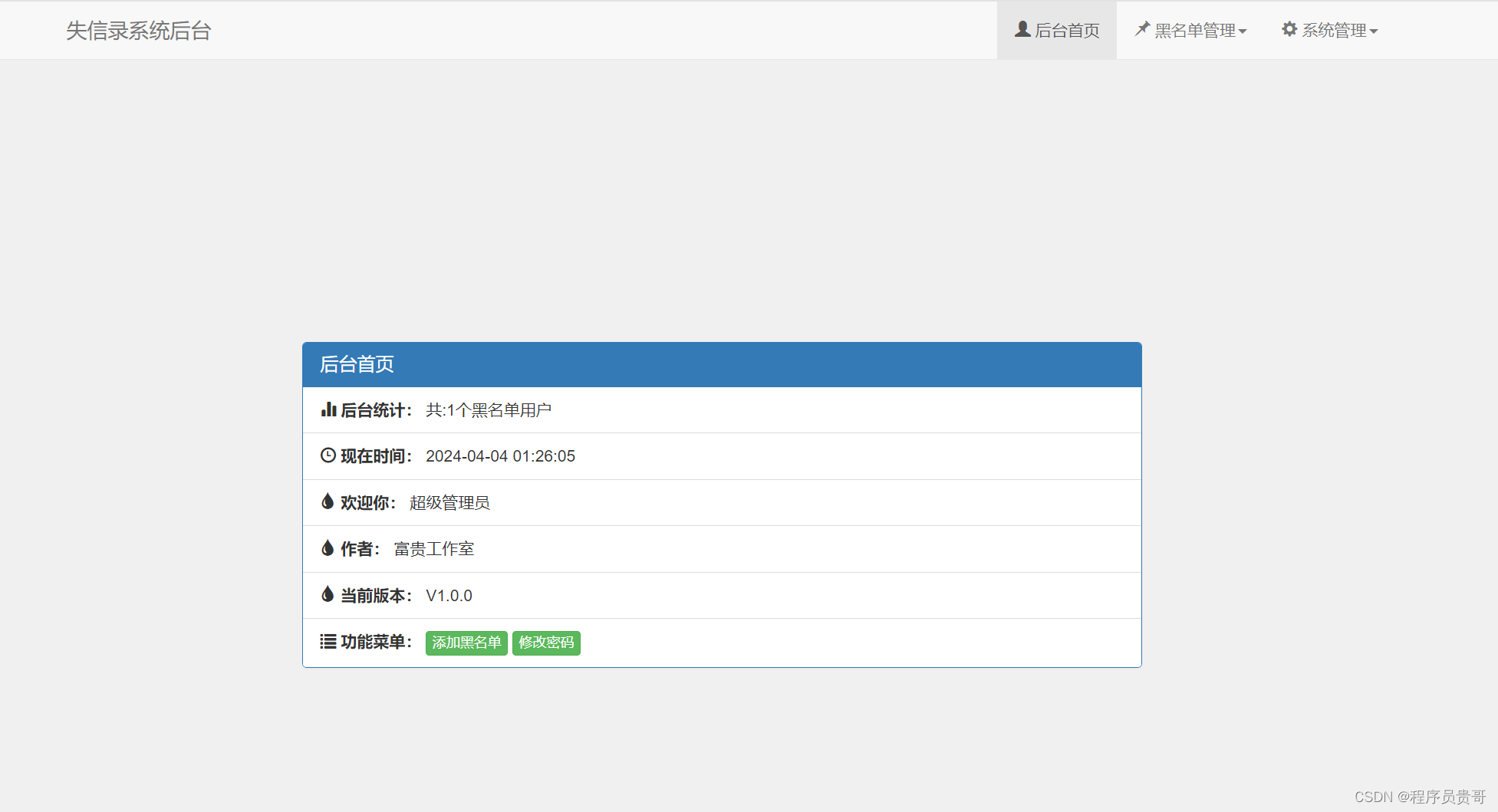
简约轻量-失信录系统源码
失信录系统-最新骗子收录查询系统源码 首页查询: 举报收录页: 后台管理页: 失信录系统 V1.0.0 更新内容: 1.用户查询,举报功能 2.界面独立开发 3.拥有后台管理功能 4.xss,sql安全过滤 5.平台用户查询 6.用户中心(待完…...

前端入门系列-HTML-HTML常见标签(注释,标题,段落,换行)
🌈个人主页:羽晨同学 💫个人格言:“成为自己未来的主人~” HTML常见标签 注释标签 注释不会显示在界面上,目的是提高代码的可读性 <!---这是一个注释----> 注释的原则 要和代码逻辑一致尽量使用中文不要传递负能量 …...
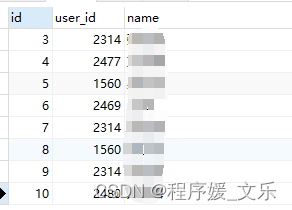
【mysql 第3-10条记录怎么查】
mysql 第3-10条记录怎么查 在MySQL中,如果你想要查询第3到第10条记录,你通常会使用LIMIT和OFFSET子句。但是,需要注意的是,LIMIT和OFFSET是基于结果集的行数来工作的,而不是基于记录的物理位置。这意味着它们通常与某种…...
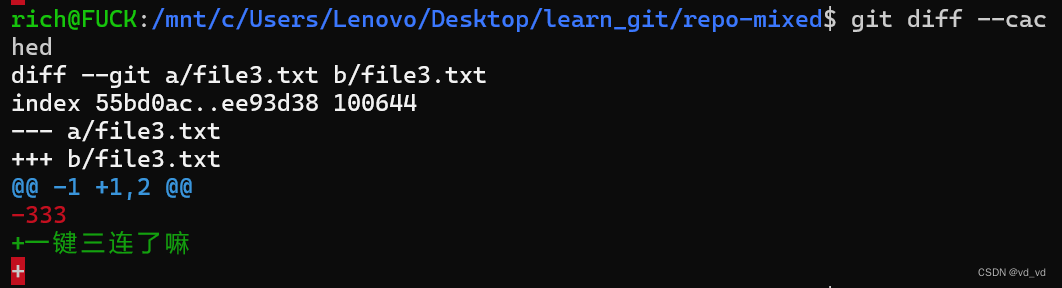
1.Git是用来干嘛的
本文章学习于【GeekHour】一小时Git教程,来自bilibili Git就是一个文件管理系统,这样说吧,当多个人同时在操作一个文件的同时,很容易造成紊乱,git就是保证文件不紊乱产生的 包括集中式管理系统和分布式管理系统 听懂…...
Git安装教程(图文安装)
Git Bash是git(版本管理器)中提供的一个命令行工具,外观类似于Windows系统内置的cmd命令行工具。 可以将Git Bash看作是一个终端模拟器,它提供了类似于Linux和Unix系统下Bash Shell环境的功能。通过Git Bash,用户可以在Windows系统中运行基于…...

SpringData ElasticSearch - 简化开发,完美适配 Spring 生态
目录 一、SpringData ElasticSearch 1.1、环境配置 1.2、创建实体类 1.3、ElasticsearchRestTemplate 的使用 1.3.1、创建索引 设置映射 1.3.2、创建索引映射注意事项(必看) 1.3.3、简单的增删改查 1.3.4、搜索 1.4、ElasticsearchRepository …...

突破!AI机器人拥有嗅觉!仿生嗅觉芯片研究登上Nature子刊
我们一直梦想着让AI与人类能够更加相似,赋予它们视觉与听觉。而让机器人拥有嗅觉一直以来面临着巨大的困难。 香港科技大学范志勇教授领导的研究团队凭借最新研发的仿生嗅觉芯片(BOC)在这一领域取得了重大突破。该研究成果目前已被发表到IF …...
前端接口防止重复请求实现方案
前言 前段时间老板心血来潮,要我们前端组对整个的项目都做一下接口防止重复请求的处理(似乎是有用户通过一些快速点击薅到了一些优惠券啥的)。。。听到这个需求,第一反应就是,防止薅羊毛最保险的方案不还是在服务端加…...
)
【leetcode面试经典150题】13.除自身以外数组的乘积(C++)
【leetcode面试经典150题】专栏系列将为准备暑期实习生以及秋招的同学们提高在面试时的经典面试算法题的思路和想法。本专栏将以一题多解和精简算法思路为主,题解使用C语言。(若有使用其他语言的同学也可了解题解思路,本质上语法内容一致&…...

网络编程核心概念解析:IP地址、端口号与网络字节序深度探讨
⭐小白苦学IT的博客主页 ⭐初学者必看:Linux操作系统入门 ⭐代码仓库:Linux代码仓库 ❤关注我一起讨论和学习Linux系统 本节重点 认识IP地址, 端口号, 网络字节序等网络编程中的基本概念; 1.前言 网络编程,作为现代信息社会中的一项核心技术&…...
))
突破编程_C++_网络编程(TCPIP 四层模型(网络层(1))
1 网络层概述 TCP/IP 四层模型中的网络层是模型中的核心组成部分,它主要负责处理数据包的路由和转发,确保数据能够在源主机和目标主机之间准确地传输。 一、主要功能 网络层的主要功能是实现数据包的选路和转发。当数据从应用层传输到传输层后&#x…...

Java | Leetcode Java题解之第9题回文数
题目: 题解: class Solution {public boolean isPalindrome(int x) {// 特殊情况:// 如上所述,当 x < 0 时,x 不是回文数。// 同样地,如果数字的最后一位是 0,为了使该数字为回文࿰…...

python-flask-djangol框架的校园餐厅菜品自选系统
目录 技术选型核心功能模块数据库设计开发流程部署方案关键代码示例测试重点 项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作 技术选型 使用Python的Flask或Django框架作为后端基础。Flask适合轻量级快速开发,Djan…...

OpenClaw可视化监控:为nanobot任务添加Web仪表盘
OpenClaw可视化监控:为nanobot任务添加Web仪表盘 1. 为什么需要可视化监控? 去年夏天,我部署了一个基于OpenClaw的nanobot自动化任务,用于定时抓取行业动态并生成日报。最初几周运行良好,直到某天早上发现连续三天的…...

Antares ESP MQTT库:ESP32/ESP8266接入Antares物联网平台指南
1. 项目概述Antares ESP MQTT 是一款专为 ESP32 和 ESP8266 平台设计的轻量级 Arduino 库,旨在大幅降低接入 Telkom Indonesia 运营的 Antares IoT 平台的开发门槛。其核心价值不在于实现 MQTT 协议栈(该职责由 PubSubClient 承担)࿰…...

【Zynq 进阶一】深度解析 PetaLinux 存储布局:NAND Flash 分区与 DDR 内存分配全攻略
【Zynq 进阶】深度解析 PetaLinux 存储布局:NAND Flash 分区与 DDR 内存分配全攻略 文章目录【Zynq 进阶】深度解析 PetaLinux 存储布局:NAND Flash 分区与 DDR 内存分配全攻略📝 前言📦 第一部分:大局观——NAND 与 D…...

LibreHardwareMonitor:5分钟掌握免费开源硬件监控的终极指南
LibreHardwareMonitor:5分钟掌握免费开源硬件监控的终极指南 【免费下载链接】LibreHardwareMonitor Libre Hardware Monitor, home of the fork of Open Hardware Monitor 项目地址: https://gitcode.com/GitHub_Trending/li/LibreHardwareMonitor 想要实时…...

OpenAI Triton项目中的相关技术对比:多面体编译与调度语言
OpenAI Triton项目中的相关技术对比:多面体编译与调度语言 【免费下载链接】triton Development repository for the Triton language and compiler 项目地址: https://gitcode.com/GitHub_Trending/tri/triton 引言 在深度学习编译器领域,OpenA…...

OpenClaw入门到精通:GLM-4.7-Flash自动化全流程解析
OpenClaw入门到精通:GLM-4.7-Flash自动化全流程解析 1. 为什么选择OpenClawGLM-4.7-Flash组合 去年冬天,当我第一次尝试用Python脚本批量处理公司周报时,发现传统自动化工具在面对非结构化数据时显得力不从心。直到接触了OpenClaw这个能直接…...
)
Delphi 终极实战:将自定义控件打包成 BPL,安装到 Delphi 工具栏(组件库实战)
前面我们手写了专属 UI 组件库(MyUIClass.pas),但如果你想在以后的项目中一键调用这些控件,而不是每次都复制粘贴代码,那就必须将它们打包成 Delphi 组件包(BPL 文件)。学会这篇,你将…...

[路径保护]解决中文路径乱码:从名称错乱到Unicode支持的实践指南
[路径保护]解决中文路径乱码:从名称错乱到Unicode支持的实践指南 【免费下载链接】calibre-do-not-translate-my-path Switch my calibre library from ascii path to plain Unicode path. 将我的书库从拼音目录切换至非纯英文(中文)命名 项…...

E-Hentai Downloader 终极使用指南:从零开始掌握开源项目配置教程
E-Hentai Downloader 终极使用指南:从零开始掌握开源项目配置教程 【免费下载链接】E-Hentai-Downloader Download E-Hentai archive as zip file 项目地址: https://gitcode.com/gh_mirrors/eh/E-Hentai-Downloader 你是否经常在E-Hentai网站上遇到下载困难…...