大数据分析与内存计算——Spark安装以及Hadoop操作——注意事项
一、Spark安装
1.相关链接
Spark安装和编程实践(Spark3.4.0)_厦大数据库实验室博客 (xmu.edu.cn)
2.安装Spark(Local模式)
按照文章中的步骤安装即可
遇到问题:xshell以及xftp不能使用
解决办法:
在linux使用镜像网站进行下载:wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.5.1/spark-3.5.1-bin-without-hadoop.tgz
二、编程实践
1.使用sbt对Scala独立应用程序进行编译打包
同样在Linux中使用wget下载sbt安装文件sbt-1.9.0.tgz:
wget https://github.com/sbt/sbt/releases/download/v1.9.0/sbt-1.9.0.tgz
注意:由于sbt没有国内镜像,下载较慢(大概两个小时)
2.其他按照上面教程中安装即可
3.实验报告要求:
读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建)
(1)方法 1:使用 hadoop fs -put 命令上传本地文件
1).首先,你需要有一个本地文件,假设你有一个名为 local_test.txt 的本地文件,其中包含你想要写入 HDFS 的内容。
2).使用以下命令将本地文件上传到 HDFS:
如果你是集群,需要打开所有几点,再启动hadoop,否则报错(处于安全模式)
![]()
hadoop fs -put /path/to/local_test.txt /user/data/test.txt
将 /path/to/local_test.txt 替换为你的本地文件的实际路径。
(2)方法 2:直接在 HDFS 上创建文件并写入内容
1).使用 hadoop fs -cat 命令直接在 HDFS 上创建文件并写入内容:
hadoop fs -cat > /user/data/test.txt
这将创建一个名为 test.txt 的空文件。
2).现在你可以写入内容到这个文件中。输入你想要写入的内容,然后按 Ctrl+D 结束输入。
This is the content of the test.txt file.
3).按 Ctrl+D 结束输入后,test.txt 文件将包含你刚刚输入的内容。
请注意,这些命令需要在 Hadoop 集群的节点上运行,或者你需要通过 SSH 登录到集群中的一个节点。如果你的 Hadoop 集群配置了 Web 界面(如 Hue 或 Ambari),你也可以通过 Web 界面来上传文件和查看文件内容。
4.通过如下代码将整个应用程序打包成 JAR(首次运行同样需要下载依赖包 ):
/usr/local/sbt/sbt package注意:这一步要保证你的Linux系统中所有文件夹名称为英文
5.建立一个名为 SimpleApp.scala 的文件
相关代码:
/* SimpleApp.scala */
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.hadoop.conf.Configurationobject SimpleApp {def main(args: Array[String]): Unit = {val conf = new Configuration()val fs = FileSystem.get(conf)val path = new Path("/user/data/test.txt")val isExists = fs.exists(path)if (!isExists) {val outputStream = fs.create(path)outputStream.close()}val inputStream = fs.open(path)val lineCount = scala.io.Source.fromInputStream(inputStream).getLines().sizeprintln(s"File line count: $lineCount")inputStream.close()}
}
注意:上述代码中的val path = new Path("/user/data/test.txt"),要替换为你的test.txt的路径
6.在simple.sbt中添加如下内容,声明该独立应用程序的信息以及与 Spark 的依赖关系:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.12.18"
libraryDependencies += "org.apache.hadoop" % "hadoop-client" % "2.10.1"
注意:你的scala和hadoop版本要与代码中的相同
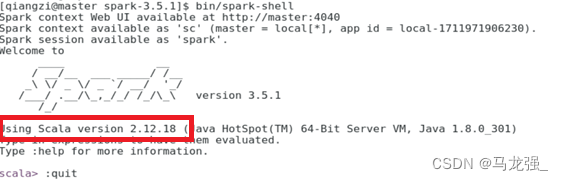
7.通过 spark-submit 运行程序
教程给的指令缺少文件编码格式,需要指定编码格式,以下为修改后的指令
/usr/local/spark-3.5.1/bin/spark-submit --class "SimpleApp" --driver-java-options "-Dfile.encoding=UTF-8" ~/sparkapp/target/scala-2.12/simple-project_2.12-1.0.jar/usr/local/spark-3.5.1/bin/spark-submit --class "SimpleApp" --driver-java-options "-Dfile.encoding=UTF-8" ~/sparkapp/target/scala-2.12/simple-project_2.12-1.0.jar 2>&1 | grep "Lines with a:"注意:需要更改你的spark安装路径
相关文章:
大数据分析与内存计算——Spark安装以及Hadoop操作——注意事项
一、Spark安装 1.相关链接 Spark安装和编程实践(Spark3.4.0)_厦大数据库实验室博客 (xmu.edu.cn) 2.安装Spark(Local模式) 按照文章中的步骤安装即可 遇到问题:xshell以及xftp不能使用 解决办法: 在…...
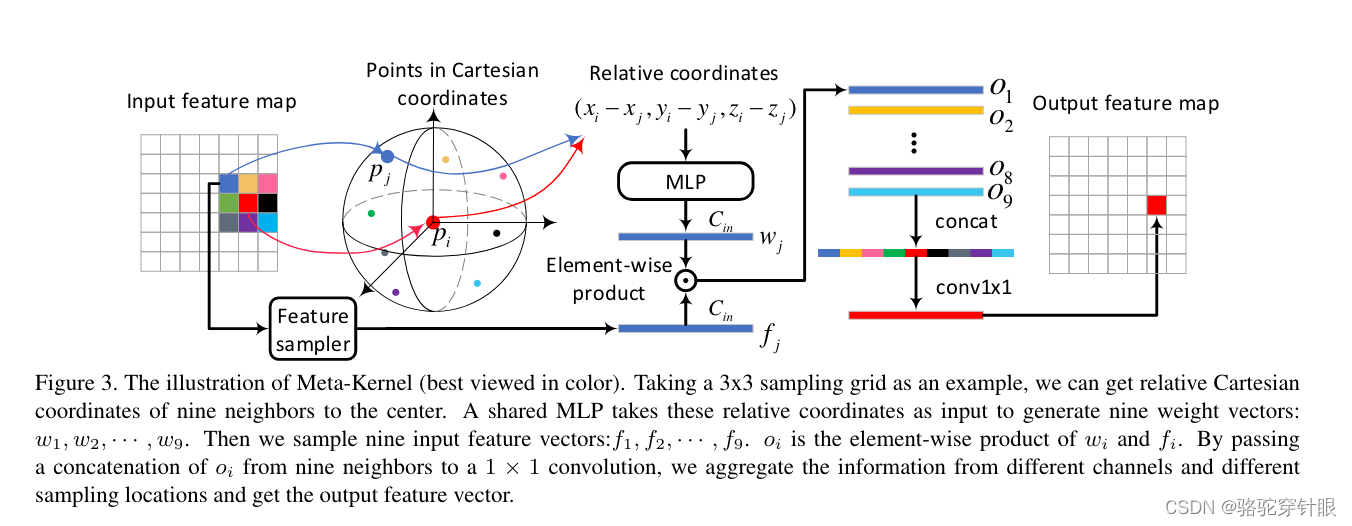
论文阅读RangeDet: In Defense of Range View for LiDAR-based 3D Object Detection
文章目录 RangeDet: In Defense of Range View for LiDAR-based 3D Object Detection问题笛卡尔坐标结构图Meta-Kernel Convolution RangeDet: In Defense of Range View for LiDAR-based 3D Object Detection 论文:https://arxiv.org/pdf/2103.10039.pdf 代码&…...
3D模型格式转换工具HOOPS Exchange如何将3D文件加载到PRC数据结构中?
HOOPS Exchange是一款高效的数据访问工具,专为开发人员设计,用于在不同的CAD(计算机辅助设计)系统之间进行高保真的数据转换和交换。由Tech Soft 3D公司开发,它支持广泛的CAD文件格式,包括但不限于AutoCAD的…...
c# wpf Template ContentTemplate
1.概要 1.1 定义内容的外观 2.2 要点分析 2.代码 <Window x:Class"WpfApp2.Window1"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winfx/2006/xaml"xmlns:d"http://schem…...

空和null是两回事
文章目录 前言 StringUtils1. 空(empty):字符串:集合: 2. null:引用类型变量:基本类型变量: 3. isBlank总结: 前言 StringUtils 提示:这里可以添加本文要记录…...

UNIAPP(小程序)每十个文章中间一个广告
三十秒刷新一次广告 ad-intervals"30" <template><view style"margin: 30rpx;"><view class"" v-for"(item,index) in 100"><!-- 广告 --><view style"margin-bottom: 20rpx;" v-if"(inde…...

pip包安装用国内镜像源
一:临时用国内源 可以在使用pip的时候加参数-i https://pypi.tuna.tsinghua.edu.cn/simple 例如:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspider,这样就会从清华这边的镜像去安装pyspider库 清华:https://py…...

uniapp:小程序腾讯地图程序文件qqmap-wx-jssdk.js 文件一直找不到无法导入
先看问题: 在使用腾讯地图api时无法导入到qqmap-wx-jssdk.js文件 解决方法:1、打开qqmap-wx-jssdk.js最后一行 然后导入:这里是我的路径位置,可以根据自己的路径位置进行更改导入 最后在生命周期函数中输出: 运行效果…...
)
如何物理控制另一台电脑以及无网络用作副屏(现成设备和使用)
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 控制另一台电脑有很多方法&…...

Aurora8b10b(1)IP核介绍并基于IP核进行设计
文章目录 前言一、IP核设置二、基于IP核进行设计2.1、设计框图2.2、aurora_8b10b_0模块2.3、aurora_8b10b_0_CLOCK_MODULE2.4、aurora_8b10b_0_SUPPORT_RESET_LOGIC2.5、aurora8b10b_channel模块2.6、IBUFDS_GTE2模块2.7、aurora_8b10b_0_gt_common_wrapper模块2.8、aurora8b10…...
基于Springboot的美发管理系统(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的美发管理系统(有报告)。Javaee项目,springboot项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构&…...

最新测试技术
在软件测试领域,随着技术的不断进步和行业需求的变化,新的测试技术和方法不断涌现。以下是一些最新的测试技术,它们正在塑造着软件测试的未来: 人工智能和机器学习(AI/ML)在测试中的应用 人工智能和机器学习正在被集成到软件测试中,以提高测试的自动化水平和效率。AI可…...

【算法】初识算法
尽量不说废话 算法 一、数据结构二、排序算法三、检索算法四、字符算类型算法五、递归算法六、贪心算法七、动态规划八、归一化算法后记 我们这里指的算法,是作为程序员在计算机编程时运用到的算法。 算法是一个庞大的体系,主要包括以下内容:…...

HomeBrew 安装与应用
目录 前言一、安装 HomeBrew二、使用 HomeBrew1、使用 brew 查看已安装的软件包2、使用 brew 安装软件包3、使用 brew 升级已安装的软件包4、brew 还有哪些命令呢? 前言 在 macOS(或Linux)系统里,默认是没有软件包的管理器的&…...
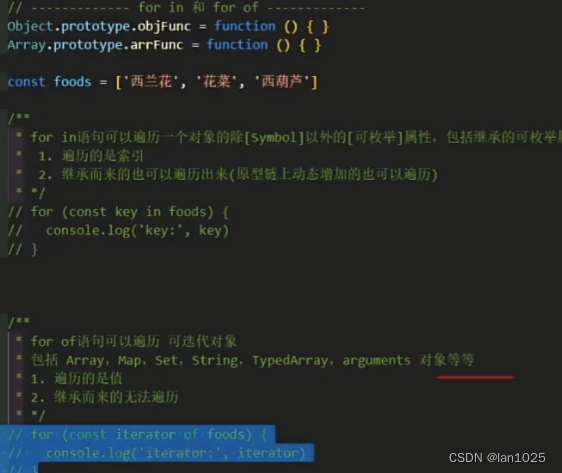
JS详解-设计模式
工厂模式: 单例模式: // 1、定义一个类class SingleTon{// 2、添加私有静态属性static #instance// 3、添加静态方法static getInstance(){// 4、判断实例是否存在if(!this.#instance){// 5、实例不存在,创建实例this.#instance new Single…...

探寻马来西亚服务器托管的优势与魅力
随着全球跨境业务的不断增加,境外服务器成为越来越受欢迎的选择。在这其中,马来西亚服务器备受关注,其机房通常位于马来西亚首都吉隆坡。对于客户群体主要分布在东南亚、澳大利亚和新西兰等地区的用户来说,马来西亚服务器是一个理…...

虚幻UE5数字孪生蓝图开发教程
一、背景 这几年,智慧城市/智慧交通/智慧水利等飞速发展,骑士特意为大家做了一个这块的学习路线。 二、这是学习大纲 1.给虚幻UE5初学者准备的智慧城市/数字孪生蓝图开发教程 https://www.bilibili.com/video/BV1894y1u78G 2.UE5数字孪生蓝图开发教学…...

七、Mybatis-缓存
文章目录 缓存一级缓存二级缓存1.概念2.二级缓存开启的条件:3.使二级缓存失效的情况:4.在mapper配置文件中添加的cache标签可以设置一些属性:5.MyBatis缓存查询的顺序 缓存 一级缓存 级别为sqlSession,Mybatis默认开启一级缓存。 使一级缓存失效的四种…...
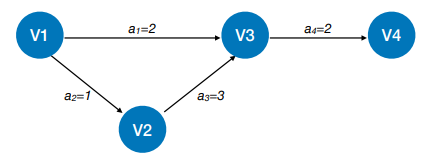
数据结构(六)——图的应用
6.4 图的应用 6.4.1 最小生成树 对于⼀个带权连通⽆向图G (V, E),⽣成树不同,每棵树的权(即树中所有边上的权值之和)也可能不同。设R为G的所有⽣成树的集合,若T为R中边的权值之和最小的生成树,则T称为G的…...
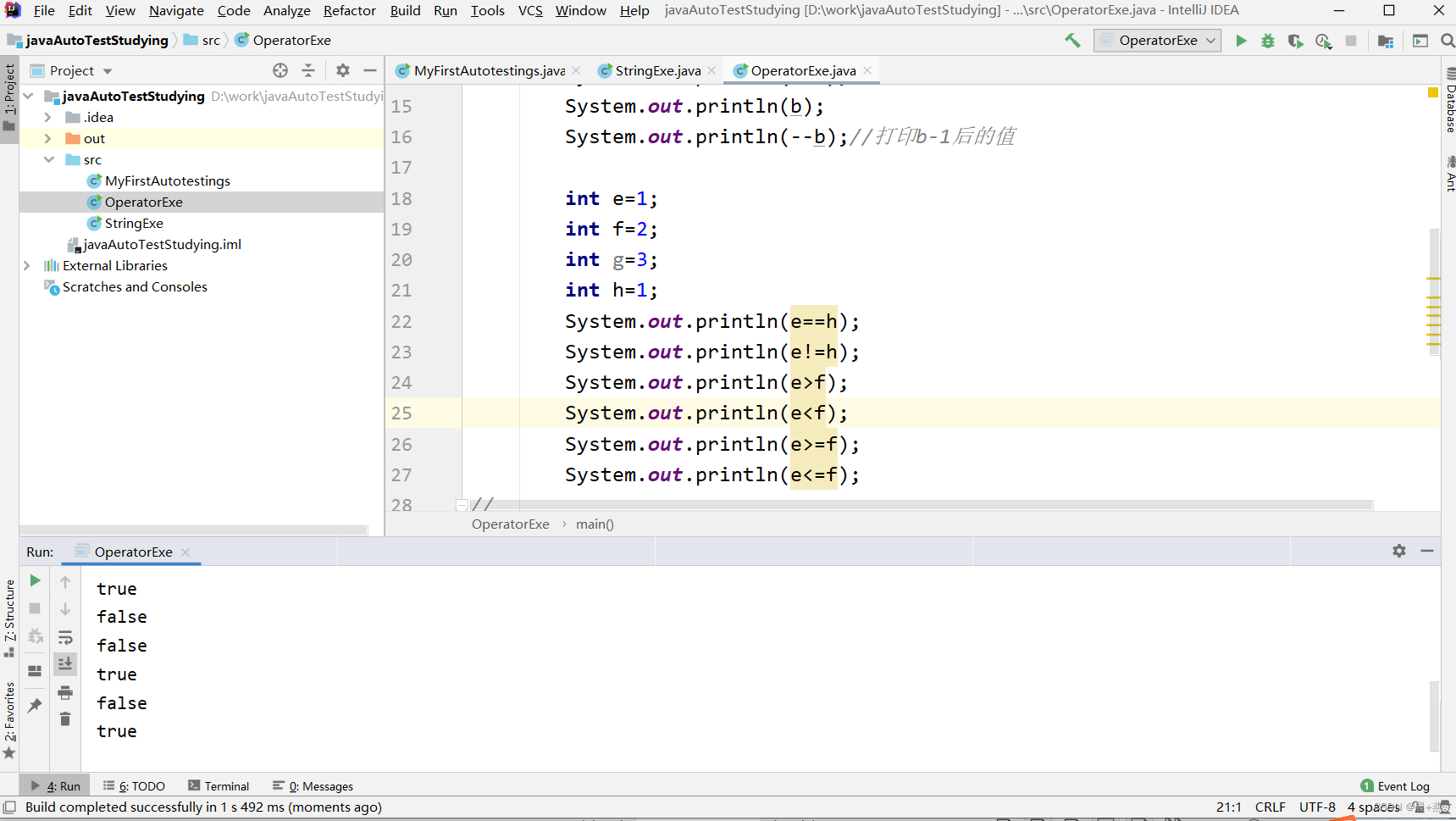
java自动化测试学习-03-06java基础之运算符
运算符 算术运算符 运算符含义举例加法,运算符两侧的值相加ab等于10-减法,运算符左侧减右侧的值a-b等于6*乘法,运算符左侧的值乘以右侧的值a*b等于16/除法,运算符左侧的值除以右侧的值a/b等于4%取余,运算符左侧的值除…...

企业级应用awesome-stock-resources:商业项目合规使用终极指南
企业级应用awesome-stock-resources:商业项目合规使用终极指南 【免费下载链接】awesome-stock-resources :city_sunrise: A collection of links for free stock photography, video and Illustration websites 项目地址: https://gitcode.com/gh_mirrors/aw/awe…...

软考高级信息系统项目管理师备考笔记-第14章项目沟通管理
第14章项目沟通管理备考知识点及历年真题 一、历年真题分布 2023年5月 选择题3分 案例6分 2023年11月 选择题3分 案例5分第一批、案例10分第二批 2024年5月 选择题3分 案例16分第一批 2025年5月 选择题2分 案例4分第一批、案例9分第二批 二、备考学习笔记 14.1 …...
Windows 11任务栏透明化神器:TranslucentTB让你的桌面焕然一新!
Windows 11任务栏透明化神器:TranslucentTB让你的桌面焕然一新! 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你…...

NotebookLM笔记整理实战指南:5步打造自动关联知识图谱的智能笔记系统
更多请点击: https://intelliparadigm.com 第一章:NotebookLM笔记整理实战指南:5步打造自动关联知识图谱的智能笔记系统 NotebookLM 是 Google 推出的面向研究者与开发者的第一方 AI 笔记工具,其核心能力在于基于用户上传文档构建…...

从DP-V0到DP-V2:一文讲透Profibus-DP三大版本的核心差异与工业现场选型建议
从DP-V0到DP-V2:Profibus-DP三大版本的核心差异与工业现场选型指南 在工业自动化领域,实时通信协议的选型往往直接决定生产线的响应速度、诊断能力和系统扩展性。作为制造业自动化系统中应用最广泛的现场总线之一,Profibus-DP历经三次重大版本…...

终极指南:完整解锁ComfyUI Impact Pack图像增强功能
终极指南:完整解锁ComfyUI Impact Pack图像增强功能 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: https://gi…...

ROS2机械臂实战:ros2_control、moveit2与move_group核心问题排查与解决
1. ROS2机械臂开发中的常见问题与调试思路 最近在做一个ROS2机械臂项目,用到了ros2_control、moveit2和move_group这几个核心组件。说实话,从零开始搭建这套系统踩了不少坑,特别是硬件接口初始化、控制器配置这些环节。今天就把我遇到的一些典…...

Audacity音频编辑完全手册:从零开始制作专业音频作品
Audacity音频编辑完全手册:从零开始制作专业音频作品 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity 想制作播客却不知道如何剪辑?需要为视频添加背景音乐但找不到合适的工具?或…...

长期使用Token Plan套餐,我的大模型调用成本降低了多少
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐,我的大模型调用成本降低了多少 1. 从按量付费到套餐订阅的转变 在深度使用大模型API进行项目…...
Windows 11任务栏透明化完整教程:TranslucentTB让你的桌面焕然一新
Windows 11任务栏透明化完整教程:TranslucentTB让你的桌面焕然一新 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 想让Windo…...