Java集合——Map、Set和List总结
文章目录
- 一、Collection
- 二、Map、Set、List的不同
- 三、List
- 1、ArrayList
- 2、LinkedList
- 四、Map
- 1、HashMap
- 2、LinkedHashMap
- 3、TreeMap
- 五、Set
一、Collection
Collection 的常用方法
- public boolean add(E e):把给定的对象添加到当前集合中 。
- public void clear():清空集合中所有的元素。
- public boolean remove(E e):把给定的对象在当前集合中删除。
- public boolean contains(E e):判断当前集合中是否包含给定的对象。
- public boolean isEmpty():判断当前集合是否为空。
- public int size():返回集合中元素的个数。
- public Object[] toArray():转换为数组。
当需要数组转换为集合时,使用 Arrays.asList(list)
Collection 的遍历方式
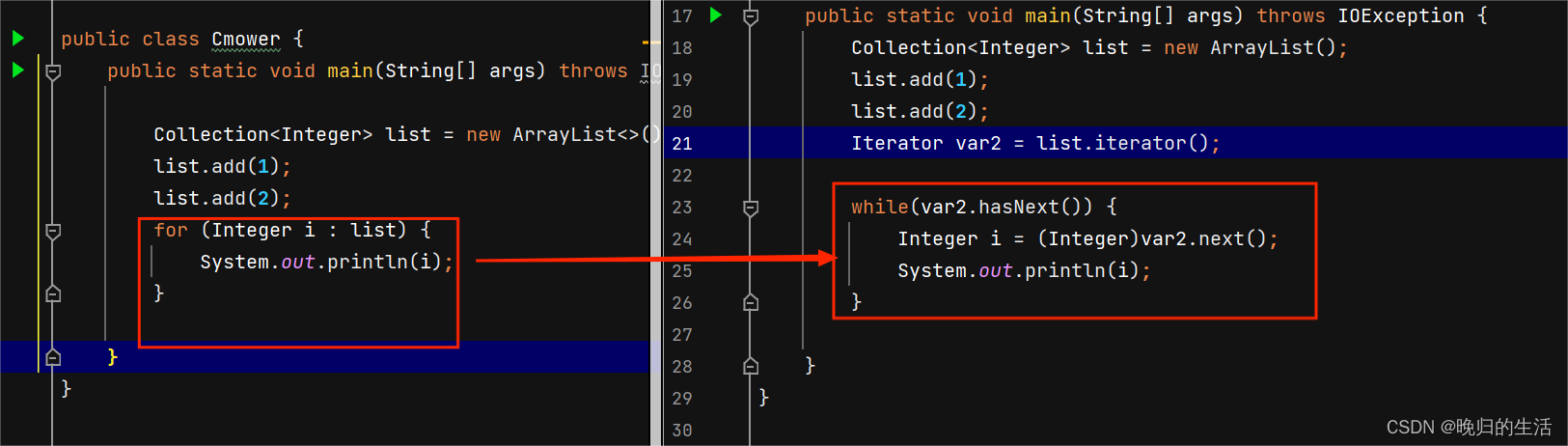
- 迭代器 iterator():获取当前集合迭代对象,然后调用方法
1、hasNext():当前位置是否有数据2、next():返回当前位置,并向后移动Collection<Integer> list = new ArrayList<>();list.add(1);Iterator<Integer> iterator = list.iterator();while (iterator.hasNext()) {System.out.println(iterator.next());}
迭代器遍历注意事项
1、迭代器不可多次获取当前元素,否则会报错,因为每一次获取都会向后移动,你一次判断多次获取,则会越界抛出异常NoSuchElementException
2、迭代器不支持集合自身方法remove(),但支持迭代器对象自身的remove()方法(集合自身的移除方法会导致一些其他元素没有遍历到,到)
Collection<Integer> list = new ArrayList<>();list.add(1);list.add(2);Iterator<Integer> iterator = list.iterator();while (iterator.hasNext()) {if (iterator.next() == 2){// list.remove(1); 此代码报错,不支持iterator.remove();}}System.out.println(list); 输出 [1]
- 增强for
for(数据类型 变量名 :数组或集合){} :支持集合和数组遍历
查看反编译文件,发现增强for(数据类型 变量名 :数组或集合){} 底层是基于iterator迭代器实现的
- Lambda表达式
Lambda表达式是简化函数式接口的内部类方法(函数式接口是指接口,仅且只有一个抽象类方法,被@FunctionalInterface修饰)
forEach(匿名内部类的Lambda的简化表达式)
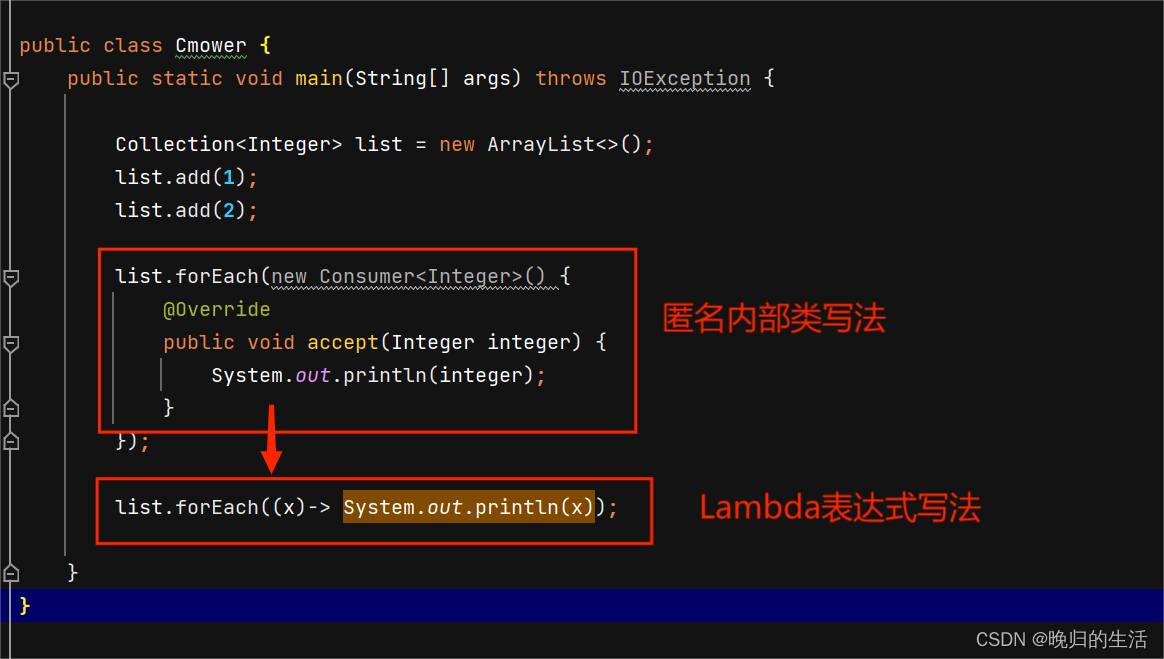
Collection不支持普通for()遍历
二、Map、Set、List的不同
- Collection是单列集合顶级父类接口
- Map是双列集合顶级父类接口
| Map | Set | List |
|---|---|---|
| HashMap | HashSet | ArrayList |
| TreeMap | TreeSet | LinkedList |
| LinkedHashMap | LinkedHaspSet | — |
| 键值对存储数据 | 存取无序 不重复 无索引 | 存取有序 可重复 有索引 |
三、List
- List:有序、可重复、有索引
- 常用特有方法
add(int index , E e)
remove(int index)
set(int index , E e)
get(int index)
- 支持的遍历方式:迭代器遍历、增强for遍历、Lambda遍历、普通for遍历
1、ArrayList
- ArrayList是List接口实现类,存取有序、可以存储重复元素、可以使用下标操作元素,因为底层是基于数组实现的,在内存中是连续的
- 支持重复数据的插入
- 适合快速查询,但是不适合中间插入和删除操作
- ArrayList实例化后,当你插入第一个数据开始,它的数组大小会变为10;当你插入的数据超过这个数组大小,ArrayList会动态的对数组实现扩容:新数组大小 = 旧数组大小 × 1.5
默认大小
private static final int DEFAULT_CAPACITY = 10;
....
扩容方法
private void grow(int minCapacity) {int oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1); 扩容至原来的1.5倍if (newCapacity - minCapacity < 0) 新的容量小于指定容量的最小值newCapacity = minCapacity; 扩容至指定容量的最小值(第一次就是10)if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); elementData = Arrays.copyOf(elementData, newCapacity); 将数组复制到一个新数组中,长度为 newCapacity
}
>> 相当于除2,而 << 相当于乘2
- 常用方法
| 方法名 | 作用 |
|---|---|
| list.add(“a”) | 直接添加数据 |
| list.add(1, “b”) | 根据索引位置,添加数据 |
| list.contains(“a”) | 判断是否包含数据 |
| list.get(1) | 根据索引位置获取数据 |
| list.indexOf(“a”) | 根据数据本身返回索引位置 |
| list.set(1, “c”) | 根据索引修改数据 |
| list.remove(“a”) | 根据数据本身直接移除数据 |
| list.remove(1) | 根据索引移除数据 |
2、LinkedList
- LinkedList 实现接口 List,存取有序、支持索引操作,底层由双向链表实现,只能从一端开始遍历,查询效率低,在内存中不是连续的
- 因为链表结构,LinkedList 更适合删除插入操作,只需要修改前结点和后一个结点引用指向即可
- 可以插入重复数据
基于添加add(),分析一下源码
1、定义一个集合,并添加数据,看看内部实现
public static void main(String args[]) {LinkedList<Object> list = new LinkedList<>();list.add("a");list.add(1,"b");System.out.println(list);}
2、查看根据索引添加数据的内部实现
public void add(int index, E element) {checkPositionIndex(index); //检查索引是否越界if (index == size) //添加位置在最后一个节点linkLast(element); elselinkBefore(element, node(index)); //任意结点前插入数据}
- 1、如果索引越界则抛出异常 IndexOutOfBoundsException
- 2、索引不越界时,判断是否添加位置是否在最后一个,是则添加,不是则调用 linkBefore() 方法
3、我们看 linkBefore() 中的**node(index)**方法,
Node<E> node(int index) {// assert isElementIndex(index);if (index < (size >> 1)) { //索引在链表左边Node<E> x = first; //获取第一个结点for (int i = 0; i < index; i++) //遍历,并返回index处结点x = x.next;return x;} else { //索引在链表右边Node<E> x = last;for (int i = size - 1; i > index; i--) //遍历,并返回index处结点x = x.prev;return x;}}
看到返回值和内部代码实现,可知主要作用即返回指定元素索引处的节点。现在返回 linkBefore(element, node(index))
void linkBefore(E e, Node<E> succ) {// assert succ != null;final Node<E> pred = succ.prev; 获取索引处前一结点final Node<E> newNode = new Node<>(pred, e, succ); 新建一个新的结点succ.prev = newNode; 索引处的前指针指向新结点if (pred == null) 如果前结点为空,则新结点变为头节点first = newNode;elsepred.next = newNode; 否则,前结点的向后指针指向新结点size++; 长度加一modCount++; 表示修改次数加一}
看了上面代码,大致应该知道添加内部代码实现流程,其他的方法就不一一列举,有兴趣去看看源码即可
四、Map
- key不支持重复,value可以重复,如果key重复则value会被覆盖
- 常用方法:
(1)put(K key, V value)
(2)get(Object key)
(3)size()
(4)clear()
(5)isEmpty ()
(6)remove(Object key)
(7)values():获取全部值
(8)keySet() :获取全部键
(9)containsKey():是否包含键
(10)containsValue():是否包含值
(11)putAll():把一个map添加进另一个map
(12)entrySet():获取全部集合内所有对象数据
- 遍历方式:
1、键遍历获取值:可以根据keySet()获取全部键,使用增强for()遍历
2、键值对遍历获取值:可以根据entrySet()获取一个set集合数据,再使用增强for()遍历,getKey()可以获取键,getValue()获取值
3、 Lambda遍历:底层其实就是键值对遍历map.forEach((k, v) -> {System.out.println(v);});
1、HashMap
1、 HashMap 底层由哈希表(数组、链表、红黑树)实现
2、HashMap 初始默认大小是16,负载因子是0.75,当填充元素达到扩容要求时,HashMap会自动扩容,每次扩容是旧数组的两倍
3、HashMap实现接口Map,所有是无序的、不支持重复、无索引
HashMap细节:
1、HashMap添加数据,如果此时数组大小正好插满了12(16×0.75)个时,如果当前发生冲突则数组扩容,如果没有发生冲突则不扩容
2、当数组大小大于或者等于64时,才会把链表大于8的转换为红黑树
2、LinkedHashMap
LinkedHashMap:有序、不重复、无索引,底层由哈希表(数组、链表、红黑树)实现,并且维护了一个双向链表机制
3、TreeMap
按照key的大小升序排序,不重复、无索引,底层基于红黑树实现
五、Set
Set:无序、不可重复、无索引
- 常用方法:几乎都是Collection的方法
- HashSet:存取无序、不可重复、无索引操作,底层由哈希表(数组、链表、红黑树)实现
- 如果自定义对象,需要重写hashCod()和equal()方法,实现不可重复
- LinkedHashSet:存取有序、不可重复、无索引操作,底层由哈希表(数组、链表、红黑树)实现,并且维护了一个双向链表机制
- TreeSet:内部升序排序、不可重复、无索引操作,基于红黑树实现
-
数值包装类型和字符串这两种对象可以升序排序
-
其他对象不可以排序,但是可以自定义排序规则
-
排序规则
- 实现接口 Comparable,自定义compareTo()方法
- 调用有参构造器,设置Comparator对象,实现compare()方法
- 如果两则都实现了,则选择就近原则,选择Comparator对象比较
相关文章:
Java集合——Map、Set和List总结
文章目录 一、Collection二、Map、Set、List的不同三、List1、ArrayList2、LinkedList 四、Map1、HashMap2、LinkedHashMap3、TreeMap 五、Set 一、Collection Collection 的常用方法 public boolean add(E e):把给定的对象添加到当前集合中 。public void clear(…...

Python TensorFlow 2.6 获取 MNIST 数据
Python TensorFlow 2.6 获取 MNIST 数据 2 Python TensorFlow 2.6 获取 MNIST 数据1.1 获取 MNIST 数据1.2 检查 MNIST 数据 2 Python 将npz数据保存为txt3 Java 获取数据并使用SVM训练4 Python 测试SVM准确度 2 Python TensorFlow 2.6 获取 MNIST 数据 1.1 获取 MNIST 数据 …...

EChart简单入门
echart的安装就细不讲了,直接去官网下,实在不会的直接用cdn,省的一番口舌。 cdn.staticfile.net/echarts/4.3.0/echarts.min.js 正入话题哈 什么是EChart? EChart 是一个使用 JavaScript 实现的开源可视化库,Echart支持多种常…...
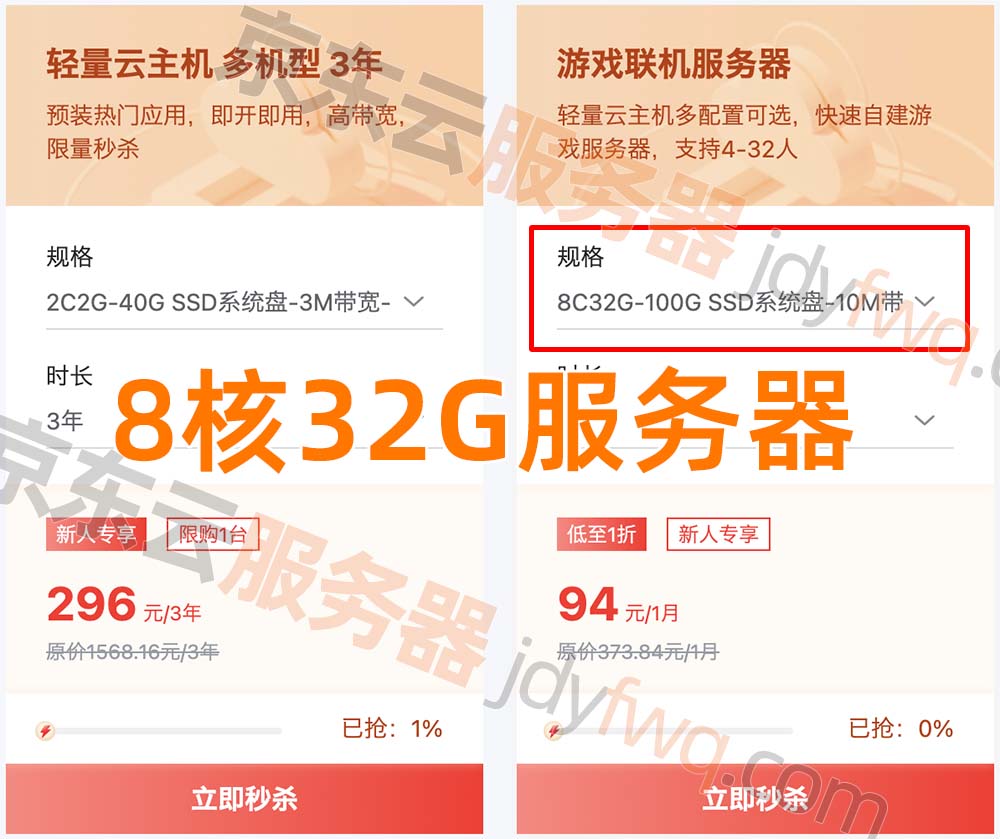
阿里云8核32G云服务器租用优惠价格表,包括腾讯云和京东云
8核32G云服务器租用优惠价格表,云服务器吧yunfuwuqiba.com整理阿里云8核32G服务器、腾讯云8核32G和京东云8C32G云主机配置报价,腾讯云和京东云是轻量应用服务器,阿里云是云服务器ECS: 阿里云8核32G服务器 阿里云8核32G服务器价格…...

设计模式,工厂方法模式
工厂方法模式概述 工厂方法模式,是对简单工厂模式的进一步抽象和推广。以我个人理解,工厂方法模式就是对生产工厂的抽象,就是用一个生产工厂的工厂来进行目标对象的创建。 工厂方法模式的角色组成和简单工厂方法相比,创建了一个…...

WPF中嵌入3D模型通用结构
背景:wpf本身有提供3D的绘制,但是自己通过代码描绘出3D是比较困难的。3D库helix-toolkit支持调用第三方生成的模型,比如Blender这些,所以在wpf上使用3D就变得非常简单。这里是一个通过helix-toolkit库调用第三方生成的3d模型的样例…...

举个例子说明联邦学习
学习目标: 一周掌握 Java 入门知识 学习内容: 联邦学习是一种机器学习方法,它允许多个参与者协同训练一个共享模型,同时保持各自数据的隐私。 联邦学习概念(例子): 假设有三家医院,它们都希望…...

【Python】免费的图片/图标网站
专栏文章索引:Python 有问题可私聊:QQ:3375119339 这里是我收集的几个免费的图片/图标网站: iconfont-阿里巴巴矢量图标库icon(.ico)INCONFINDER(.ico)...
)
Pytorch中的nn.Embedding()
模块的输入是一个索引列表,输出是相应的词嵌入。 Embedding.weight(Tensor)–形状模块(num_embeddings,Embedding_dim)的可学习权重,初始化自(0,1)。 也就是…...

WebSocketServer后端配置,精简版
首先需要maven配置 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId><version>2.1.3.RELEASE</version></dependency> 然后加上配置类 这段代码是一个Spri…...

Python程序设计 多重循环(二)
1.打印数字图形 输入n(n<9),输出由数字组成的直角三角图形。例如,输入5,输出图形如下 nint(input("")) #开始 for i in range(1,n1):for j in range(1,i1):print(j,end"")print()#结束 2.打印字符图形 …...
)
前端面试题--CSS系列(一)
CSS系列--持续更新中 1.CSS预处理器有哪些类型,有什么区别2.盒模型是什么,有哪两种类型3.css选择器有哪些,优先级是怎样的,哪些属性可以继承4. 说说em/px/rem/vh/vw的区别5.元素实现水平垂直居中的方法有哪些,如果元素…...
VSCode好用插件
由于现在还是使用vue2,所以本文只记录vue2开发中好用的插件。 美化类插件不介绍了,那些貌似对生产力起不到什么大的帮助,纯粹的“唯心主义”罢了,但是如果你有兴趣的话可以查看上一篇博客:VSCode美化 1. vuter 简介&…...

Vue3:对ref、reactive的一个性能优化API
一、情景说明 我们知道,在Vue3中,想要创建响应式的变量,就要用到ref、reactive来包裹一下数据即可。 但是,这里有个损耗性能的地方 就是,被它包裹的数据,都会构建成响应式的,无论多少层次&…...
Python 用pygame简简单单实现一个打砖块
# -*- coding: utf-8 -*- # # # Copyright (C) 2024 , Inc. All Rights Reserved # # # Time : 2024/3/30 14:34 # Author : 赫凯 # Email : hekaiiii163.com # File : ballgame.py # Software: PyCharm import math import randomimport pygame import sys#…...

软考113-上午题-【计算机网络】-IPv6、无线网络、Windows命令
一、IPv6 IPv6 具有长达 128 位的地址空间,可以彻底解决 IPv4 地址不足的问题。由于 IPv4 地址是32 位二进制,所能表示的IP 地址个数为 2^32 4 294 967 29640 亿,因而在因特网上约有 40亿个P 地址。 由 32 位的IPv4 升级至 128 位的IPv6&am…...
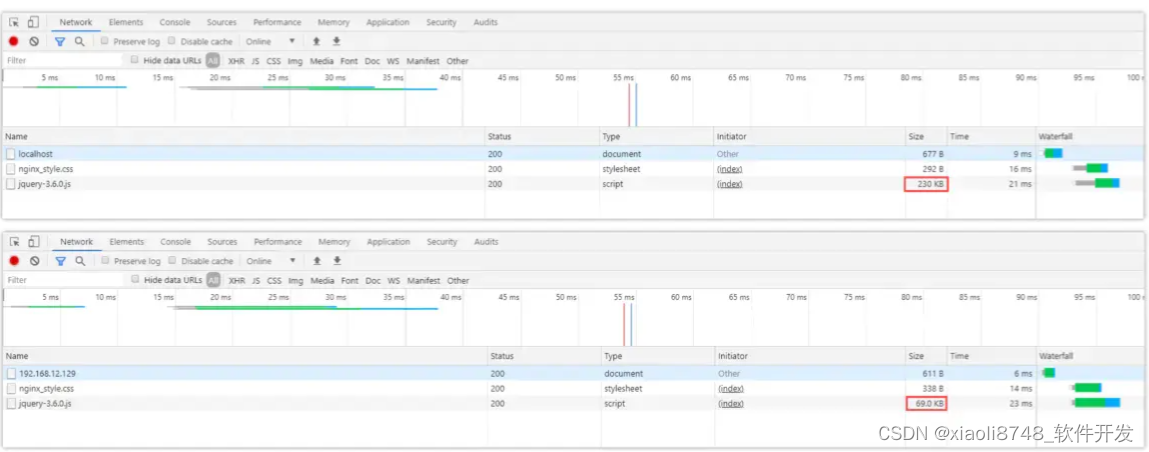
深入浅出 -- 系统架构之负载均衡Nginx资源压缩
一、Nginx资源压缩 建立在动静分离的基础之上,如果一个静态资源的Size越小,那么自然传输速度会更快,同时也会更节省带宽,因此我们在部署项目时,也可以通过Nginx对于静态资源实现压缩传输,一方面可以节省带宽…...
基于jsp+Spring boot+mybatis的图书管理系统设计和实现
基于jspSpring bootmybatis的图书管理系统设计和实现 博主介绍:多年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 央顺技术团队 Java毕设项目精品实战案例《1000套》 欢迎点赞 收藏 ⭐留言 文末获…...
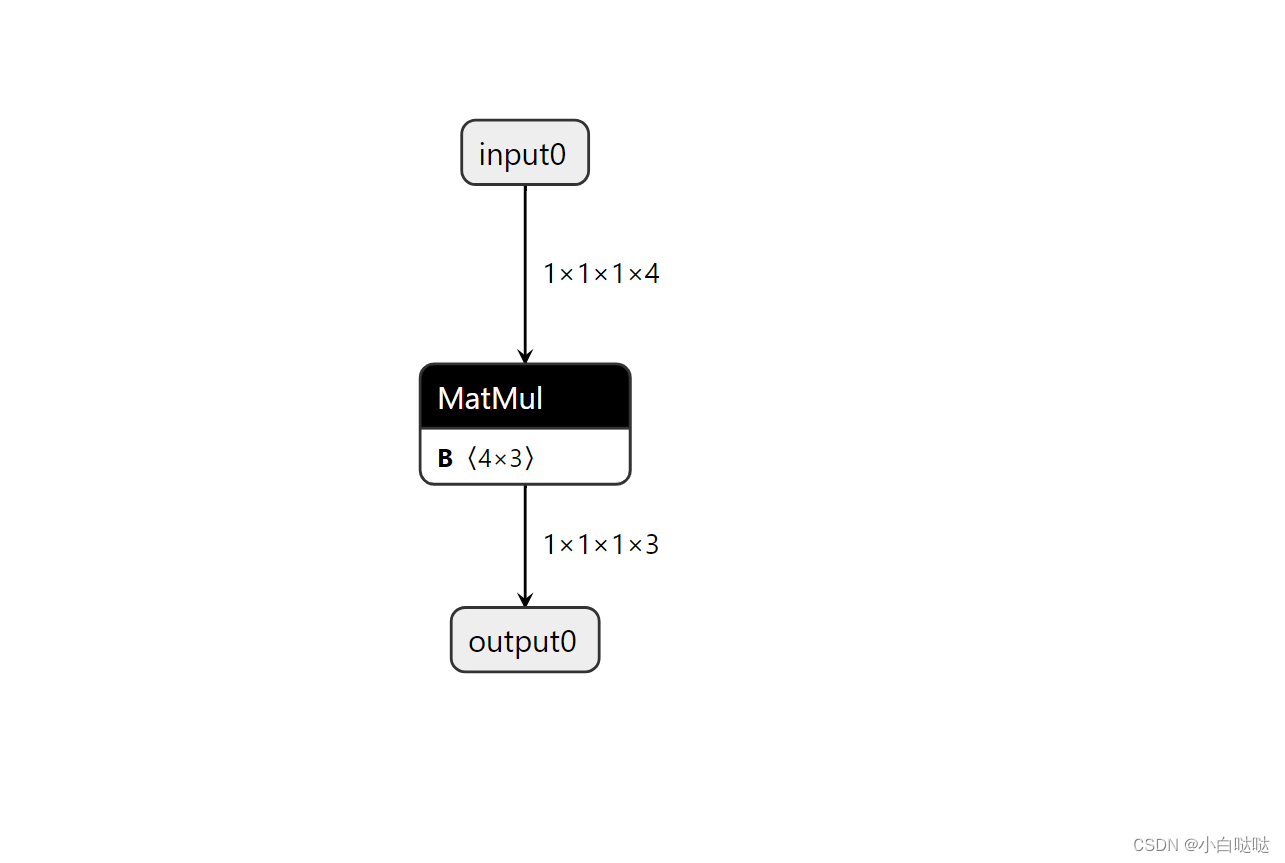
Pytorch转onnx
pytorch 转 onnx 模型需要函数 torch.onnx.export。 def export(model: Union[torch.nn.Module, torch.jit.ScriptModule, torch.jit.ScriptFunction],args: Union[Tuple[Any, ...], torch.Tensor],f: Union[str, io.BytesIO],export_params: bool True,verbose: bool False…...
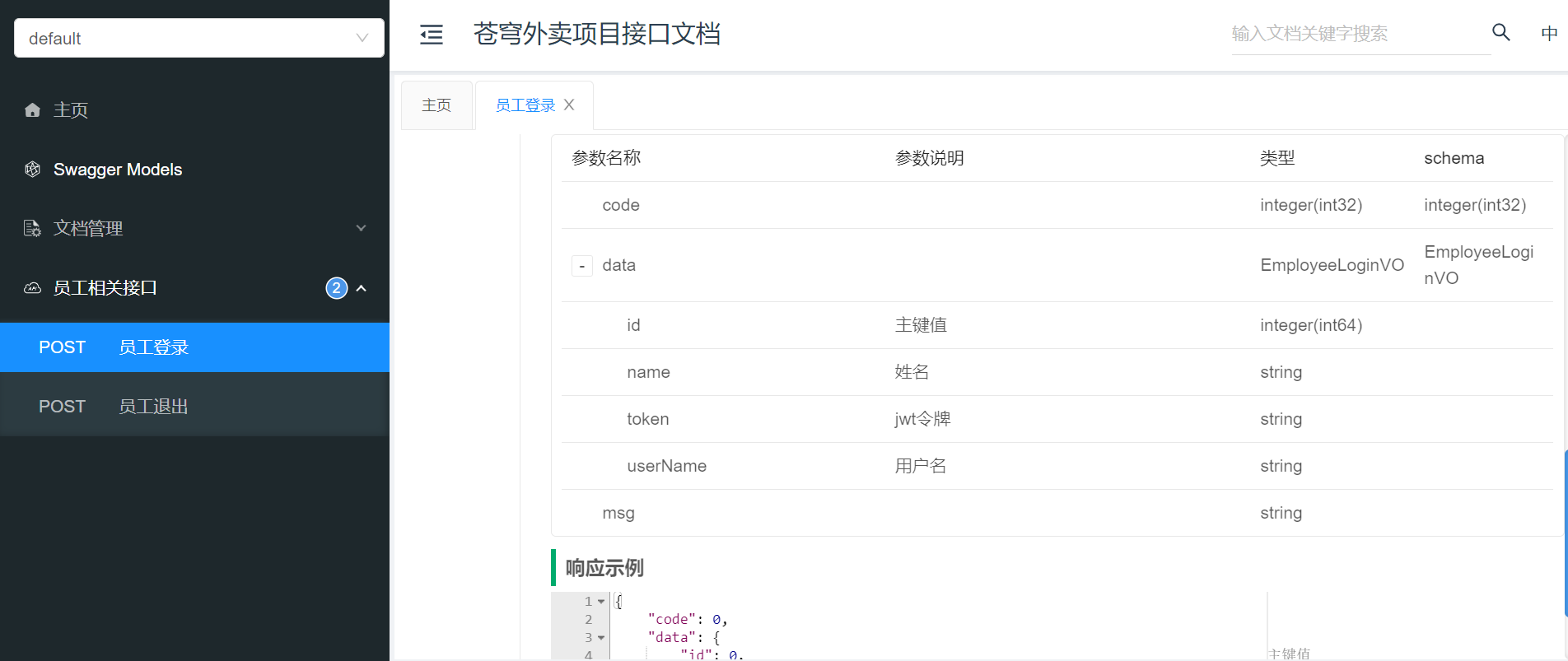
苍穹外卖——项目搭建
一、项目介绍以及环境搭建 1.苍穹外卖项目介绍 1.1项目介绍 本项目(苍穹外卖)是专门为餐饮企业(餐厅、饭店)定制的一款软件产品,包括 系统管理后台 和 小程序端应用 两部分。其中系统管理后台主要提供给餐饮企业内部员…...

keil 使用UTF8格式的文件,但是printf打印中文已经是乱码的问题
文件格式是UTF8 无bom格式 打开文件显示是正常的 编译器选择的是ANSI格式 编译依旧产生警告 在 Project → Options → C/C → Misc Controls 添加 --no-multibyte-chars就可以解决; 但是ai给我这个方案,我还没有尝试 –wide-chars 示例是这样的 wchar_…...

ROS2导航SLAM建图实战:从Gazebo仿真到真实地图构建
1. 环境准备与基础配置 第一次接触ROS2导航和SLAM建图的朋友可能会觉得配置环境很复杂,其实只要跟着步骤一步步来,半小时就能搞定。我用的是一台装了Ubuntu 20.04的笔记本,ROS2版本选择Foxy,这个组合最稳定。记得先更新系统&#…...

为Claude Code配置Taotoken解决封号与Token不足困扰
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken解决封号与Token不足困扰 应用场景类,针对频繁使用Claude Code作为编程助手但受限于官方限制…...

PHP反序列化漏洞实战:从CTFshow F5杯‘eazy-unserialize’两道题,到文件包含与协议利用的完整避坑指南
PHP反序列化漏洞实战:从CTF题目到真实漏洞利用的深度解析 在CTF竞赛中,PHP反序列化漏洞一直是Web安全方向的热门考点。这类漏洞不仅考验选手对PHP语言特性的理解,更要求具备将多个知识点串联运用的能力。本文将以一道典型CTF题目为例…...
:无监督拓扑保持的高维数据可视化与聚类)
自组织映射(SOM):无监督拓扑保持的高维数据可视化与聚类
1. 什么是自组织映射(SOM)?它到底能帮你解决什么实际问题?我第一次在客户现场看到SOM落地,是在一家做工业设备预测性维护的公司。他们有上百台传感器,每台每秒产生十几维的振动、温度、电流数据,…...

基于Python与aiogram构建多模型AI助手:集成GPT-4、Claude与Gemini的Telegram机器人开发实践
1. 项目概述:一个多模型AI助手的自研之路 最近在折腾一个挺有意思的玩意儿,我把它叫做“AIAssistantBot”。简单来说,这是一个跑在Telegram上的机器人,但它不是那种只会回复固定指令的“傻”机器人。它的核心是整合了市面上几家主…...

基于Node.js与Telegraf构建支持双历法的Telegram天气机器人
1. 项目概述:一个功能完备的Telegram天气机器人 最近在做一个需要集成天气信息的小项目,顺手就把之前写的一个Telegram天气机器人翻新重构了一遍。这个机器人不只是简单地查询温度,它融合了实时天气、24小时预报,并且特别加入了波…...

如何绕过Cursor Pro试用限制:技术原理与实战指南
如何绕过Cursor Pro试用限制:技术原理与实战指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial re…...

高校vs中小学气象站:核心区别
绝大多数普通校园气象站仅适合中小学可视化科普展示,数据精度低、无原始数据导出、无开放接口、参数单一,完全无法满足高校教学科研需求。中小学设备:侧重外观展示、简单数据观看、趣味科普,精度普通、数据封闭、无科研溯源能力&a…...

AI助手碳核算技能:基于MCP协议与CCDB数据库的实战指南
1. 项目概述:当AI助手学会“碳核算” 如果你是一名开发者、数据分析师,或者任何需要处理碳排放相关工作的从业者,最近可能被一个词频繁刷屏:AI Agent。我们总希望手边的AI编程助手(比如Cursor、Claude Code࿰…...