数据仓库面试总结
文章目录
- 1.什么是数据仓库?
- 2.ETL是什么?
- 3.数据仓库和数据库的区别(OLTP和OLAP的区别)
- 4.数据仓库和数据集市的区别
- 5.维度分析
- 5.1 什么是维度?
- 5.2什么是指标?
- 6.什么是数仓建模?
- 7.事实表
- 7.维度表
- 8.维度建模的三种模型
- 9.缓慢渐变维(SCD)
- 10.数据仓库分层
- 10.1为什么要分层?
- 10.2数仓分层
- 10.3什么叫做维度退化?
- 11.构建数据仓库相关组件
- 11.1oozie
- 11.2sqoop
1.什么是数据仓库?
- 概念
存储数据的仓库, 主要是用于存储过去既定发生的历史数据, 对这些数据进行数据分析的操作, 从而对未来提供决策支持 - 四大特征
- 面向于主题的: 面向于分析, 分析的内容是什么 什么就是我们的主题
- 集成性: 数据是来源于各个数据源, 将各个数据源数据汇总在一起
- 非易失性(稳定性): 存储在数据仓库中数据都是过去既定发生数据, 这些数据都是相对比较稳定的数据, 不会发生改变
- 时变性: 随着的推移, 原有的分析手段以及原有数据可能都会出现变化(分析手动更换, 以及数据新增)
2.ETL是什么?
抽取 转换 加载
从数据源将数据灌入到ODS层, 以及从ODS层将数据抽取出来, 对数据进行转换处理工作, 最终将数据加载到DW层, 然后DW层对数据进行统计分析, 将统计分析后的数据灌入到DA层, 整个全过程都是属于ETL范畴
狭义上ETL: 从ODS层到DW层过程
3.数据仓库和数据库的区别(OLTP和OLAP的区别)
OLTP:联机事务处理
OLAP:联机分析处理
- 数据库(OLTP): 面向于事务(业务)的 , 主要是用于捕获数据 , 主要是存储的最近一段时间的业务数据, 交互性强,一般不允许出现数据冗余
- 数据仓库(OLAP): 面向于分析(主题)的 , 主要是用于分析数据, 主要是存储的过去历史数据 , 交互性较弱 ,可以允许出现一定的冗余

4.数据仓库和数据集市的区别
-
数据仓库其实指的集团数据中心: 主要是将公司中所有的数据全部都聚集在一起进行相关的处理操作 (ODS层),此操作一般和主题基本没有什么太大的关系
-
数据的集市(小型数据仓库): 在数据仓库基础之上, 基于主题对数据进行抽取处理分析工作, 形成最终分析的结果
一个数据仓库下, 可以有多个数据集市
5.维度分析
5.1 什么是维度?
维度一般指的分析的角度, 看待一个问题的时候, 可以多个角度来看待, 而这些角度指的就是维度
比如: 有一份2020年订单数据, 请尝试分析
可以从时间, 地域 , 商品, 来源 , 用户…
- 维度的分类:
- 定性维度: 指的计算每天 每月 各个的维度 , 一般来说定性维度的字段都是放置在group by 中
- 定量维度: 指的统计某一个具体的维度或者某一个范围下信息, 比如说: 2020年度订单额, 统计20~30岁区间人群的人数 ,一般来说这种维度的字段都是放置在where中
维度的下钻和上卷: 以某一个维度为基准, 往细化统计的过程称为下钻, 往粗粒度称为上卷
比如: 按照 天统计, 如果需要统计出 小时, 指的就是下钻, 如果需要统计 季度 月 年, 称为上卷统计
5.2什么是指标?
指标是衡量事务发展的标准,也叫度量,如价格,销量等;指标可以求和、求平均值等计算。
指标的分类:
- 绝对指标: 计算具体的值指标
count() sum() max() min() avg() - 相对指标: 计算比率问题的指标
转化率, 流失率, 同比
6.什么是数仓建模?
数仓建模指的是如何在hive中构建表, 数仓建模中主要提供两种理论来进行数仓建模操作: 三范式建模和维度建模理论
-
三范式建模: 主要是存在关系型数据库建模方案上, 主要规定了比如建表的每一个表都应该有一个主键, 数据要经历的避免冗余发生等等
-
维度建模: 主要是存在分析性数据库建模方案上, 主要一切以分析为目标, 只要是利于分析的建模, 都是OK的, 允许出现一定的冗余, 表也可以没有主键
维度建模的两个核心概念:事实表和维度表。
7.事实表
事实表: 事实表一般指的就是分析主题所对应的表,每一条数据用于描述一个具体的事实信息, 这些表一般都是一坨主键(外键)和描述事实字段的聚集

事实表的分类:
- 事务事实表:
保存的是最原子的数据,也称“原子事实表”或“交易事实表”。沟通中常说的事实表,大多指的是事务事实表。 - 周期快照事实表:
周期快照事实表以具有规律性的、可预见的时间间隔来记录事实,时间间隔如每天、每月、每年等等
周期表由事务表加工产生 - 累计快照事实表:
完全覆盖一个事务或产品的生命周期的时间跨度,它通常具有多个日期字段,用来记录整个生命周期中的关键时间点
7.维度表
维度表: 指的在对事实表进行统计分析的时候, 基于某一个维度, 这个维度信息可能在其他表中, 而这些表就是维度表
维度表并不一定存在, 但是维度是一定存在:
比如: 根据用户维度进行统计, 如果在事实表只存储了用户id, 此时需要关联用户表, 这个时候就是维度表
比如: 根据用户维度进行统计, 如果在事实表不仅仅存储了用户id,还存储用户名称, 这个时候有用户维度, 但是不需要用户表的参与, 意味着没有这个维度表
维度表的分类:
-
高基数维度表: 指的表中的数据量是比较庞大的, 而且数据也在发生的变化
例如: 商品表, 用户表 -
低基数维度表: 指的表中的数据量不是特别多, 一般在几十条到几千条左右,而且数据相对比较稳定
例如: 日期表,配置表,区域表
8.维度建模的三种模型
- 星型模型
- 特点: 只有一个事实表, 那么也就意味着只有一个分析的主题, 在事实表的周围围绕了多个维度表, 维度表与维度表之间没有任何的依赖
- 反映数仓发展初期最容易产生模型
- 雪花模型
- 特点: 只有一个事实表, 那么也就意味着只有一个分析的主题, 在事实表的周围围绕了多个维度表, 维度表可以接着关联其他的维度表
- 反映数仓发展出现了畸形产生模型, 这种模型一旦大量出现, 对后期维护是非常繁琐, 同时如果依赖层次越多, SQL分析的难度也会加大
- 此种模型在实际生产中,建议尽量减少这种模型产生
- 星座模型
- 特点: 有多个事实表, 那么也就意味着有了多个分析的主题, 在事实表的周围围绕了多个维度表, 多个事实表在条件符合的情况下, 可以共享维度表
- 反映数仓发展中后期最容易产生模型
9.缓慢渐变维(SCD)
缓慢渐变维,即维度中的属性可能会随着时间发生改变
解决办法:
- SCD1: 直接覆盖, 不维护历史变化数据
主要适用于: 对错误数据处理 - SCD2:不删除、不修改已存在的数据, 当数据发生变更后, 会添加一条新的版本记录的数据, 在建表的时候, 会多加两个字段(起始时间, 截止时间), 通过这两个字段来标记每条数据的起止时间 , 一般称为拉链表
好处: 适用于保存多个历史版本, 方便维护实现
弊端: 会造成数据冗余情况, 导致磁盘占用率提升 - SCD3: 通过在增加列的方式来维护历史变化数据
好处: 减少数据的冗余, 适用于少量历史版本的记录以及磁盘空间不是特别充足情况
弊端: 无法记录更多的历史版本, 以及维护比较繁琐
10.数据仓库分层
10.1为什么要分层?
分层可以使数据层次清晰、依赖关系直观
数据分层却可以给我们带来如下的好处:
- 清晰数据结构:每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解。
- 复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题。
- 便于维护:当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
- 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少重复开发的工作量。
- 高性能:数据仓库的构建将大大缩短获取信息的时间,数据仓库作为数据的集合,所有的信息都可以从数据仓库直接获取,尤其对于海量数据的关联查询和复杂查询,所以数据仓库分层有利于实现复杂的统计需求,提高数据统计的效率。
10.2数仓分层
-
ODS层: 源数据层
作用: 对接数据源, 和数据源的数据保持相同的粒度(将数据源的数据完整的拷贝到ODS层中)
注意:
如果数据来源于文本文件, 可能会需要先对这些文本文件进行预处理(spark)操作, 将其中不规则的数据, 不完整的数据, 脏乱差的数据先过滤掉, 将其转换为一份结构化的数据, 然后灌入到ODS层 -
DW层: 数据仓库层
作用: 进行数据分析的操作- DWD层: 明细层
作用: 用于对ODS层数据进行清洗转换工作 , 以及进行少量的维度退化操作
少量:
1) 将多个事实表的数据合并为一个事实表操作
2) 如果维度表放置在ODS层 一般也是在DWD层完成维度退化 - DWM层: 中间层
作用: 1) 用于进行维度退化操作 2) 用于进行提前聚合操作(周期快照事实表) - DWS层: 业务层
作用: 进行细化维度统计分析操作
- DWD层: 明细层
-
DA层: 数据应用层
作用: 存储DW层分析的结果, 用于对接后续的应用(图表, 推荐系统…)例如:
比如DWS层的数据表完成了基于订单表各项统计结果信息, 但是图表只需要其中销售额, 此时从DWS层将销售额的数据提取出来存储到DA层 -
DIM层: 维度层
作用: 存储维度表数据
10.3什么叫做维度退化?
维度退化是为了减少维度表的关联工作
做法: 将数据分析中可能在维度表中需要使用的字段, 将这些字段退化到事实表中,
这样后续在基于维度统计的时候, 就不需要在关联维度表, 事实表中已经涵盖了维度数据了例如: 订单表, 原有订单表中只有用户id, 当我们需要根据用户维度进行统计分析的时候,
此时需要关联用户表, 找到用户的名称, 那么如果我们提前将用户的名称放置到订单表中,
那么是不是就不需要关联用户表, 而则就是维度退化好处: 减少后续分析的表关联情况
弊端: 造成数据冗余
11.构建数据仓库相关组件
11.1oozie
-
什么是oozie
Oozie是一个用于管理Apache Hadoop作业的工作流调度程序系统。Oozie由Cloudera公司贡献给Apache的基于工作流引擎的开源框架,是用于Hadoop平台的开源的工作流调度引擎,是用来管理Hadoop作业,属于web应用程序,由Oozie client和Oozie Server两个组件构成,Oozie Server运行于Java Servlet容器(Tomcat)中的web程序。
-
什么是工作流?
工作流(Workflow),指“业务过程的部分或整体在计算机应用环境下的自动化”。
-
能够使用工作流完成的业务一般具有什么特点呢?
- 整个业务流程需要周期性重复干
- 整个业务流程可以被划分为多个阶段
- 每一个阶段存在依赖关系,前序没有操作, 后续也无法执行
如果发现实际生产中的某些业务满足了以上特征, 就可以尝试使用工作流来解决
11.2sqoop
一个用户进行数据的导入导出的工具, 主要是将关系型的数据库(MySQL, oracle…)导入到hadoop生态圈(HDFS,HIVE,Hbase…) , 以及将hadoop生态圈数据导出到关系型数据库中
相关文章:
数据仓库面试总结
文章目录 1.什么是数据仓库?2.ETL是什么?3.数据仓库和数据库的区别(OLTP和OLAP的区别)4.数据仓库和数据集市的区别5.维度分析5.1 什么是维度?5.2什么是指标? 6.什么是数仓建模?7.事实表7.维度表…...
git Failed to connect to 你的网址 port 8282: Timed out
git Failed to connect to 你的网址 port 8282: Timed out 出现这个问题的原因是:原来的仓库换了网址,原版网址不可用了。 解决方法如下: 方法一:查看git用户配置是否有如下配置 http.proxyhttp://xxx https.proxyhttp://xxx如果…...
[C++][算法基础]堆排序(堆)
输入一个长度为 n 的整数数列,从小到大输出前 m 小的数。 输入格式 第一行包含整数 n 和 m。 第二行包含 n 个整数,表示整数数列。 输出格式 共一行,包含 m 个整数,表示整数数列中前 m 小的数。 数据范围 1≤m≤n≤&#x…...
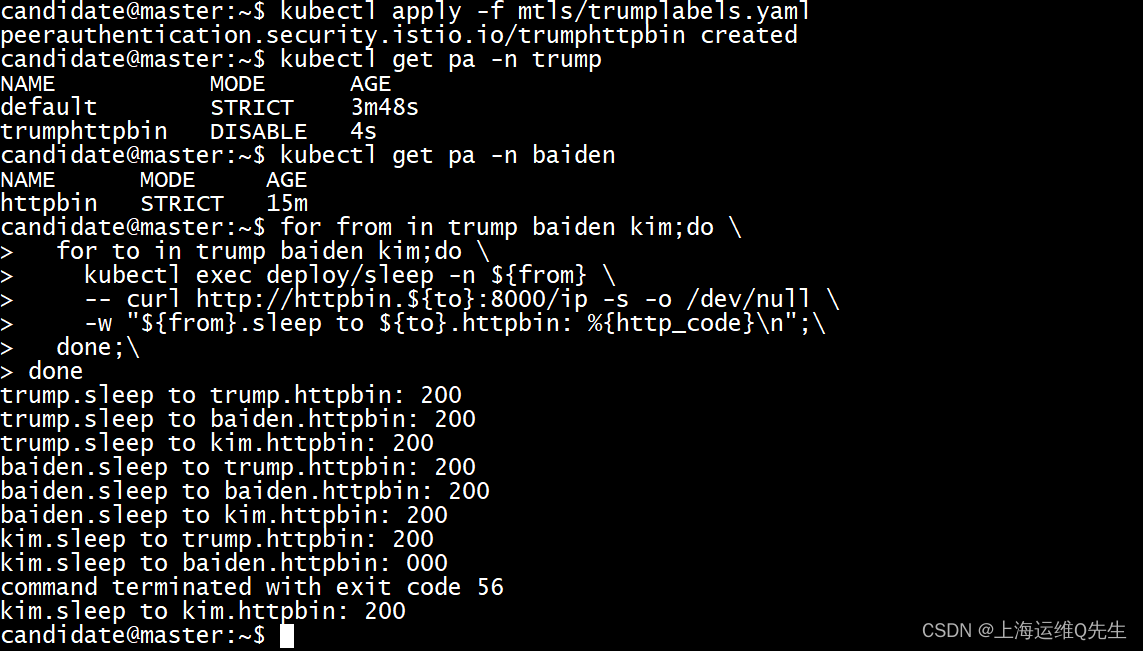
备考ICA----Istio实验15---开启 mTLS 自动双向认证实验
备考ICA----Istio实验15—开启mTLS自动双向认证实验 在某些生成环境下,我们希望微服务和微服务之间使用加密通讯方式来确保不被中间人代理. 默认情况下Istio 使用 PERMISSIVE模式配置目标工作负载,PERMISSIVE模式时,服务可以使用明文通讯.为了只允许双向 TLS 流量,…...

Hive SchemaTool 命令详解
Hive schematool 是 hive 自带的管理 schema 的相关工具。 列出详细说明 schematool -help直接输入 schematool 或者schematool -help 输出结果如下: usage: schemaTool-alterCatalog <arg> Alter a catalog, requires--catalogLocation an…...

51单片机入门_江协科技_17~18_OB记录的笔记
17. 定时器 17.1. 定时器介绍:51单片机的定时器属于单片机的内部资源,其电路的连接和运转均在单片机内部完成,无需占用CPU外围IO接口; 定时器作用: (1)用于计时系统,可实现软件计时&…...
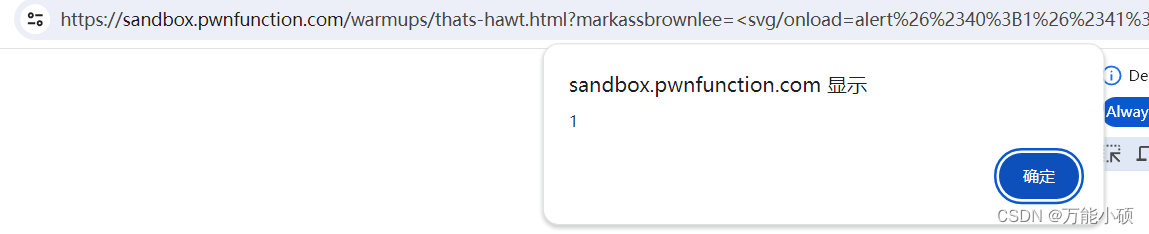
xss.pwnfunction-Ah That‘s Hawt
<svg/onloadalert%26%2340%3B1%26%2341%3B> <svg/>是一个自闭合形式 ,当页面或元素加载完成时,onload 事件会被触发,从而可以执行相应的 JavaScript 函数...

Python学习从0开始——005数据结构
Python学习从0开始——005数据结构 一、列表list二、元组和序列三、集合四、字典五、循环技巧六、条件控制七、序列和其它类型的比较 一、列表list 不是所有数据都可以排序或比较。例如,[None, ‘hello’, 10] 就不可排序,因为整数不能与字符串对比&…...
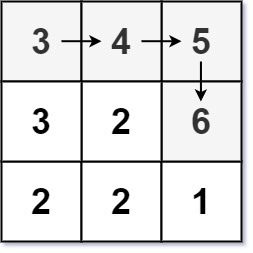
力扣每日一题:LCR112--矩阵中的最长递增路径
题目 给定一个 m x n 整数矩阵 matrix ,找出其中 最长递增路径 的长度。 对于每个单元格,你可以往上,下,左,右四个方向移动。 不能 在 对角线 方向上移动或移动到 边界外(即不允许环绕)。 示例…...

树莓派部署yolov5实现目标检测(ubuntu22.04.3)
最近两天搞了一下树莓派部署yolov5,有点难搞(这个东西有点老,版本冲突有些包废弃了等等) 最后换到ubuntu系统弄了,下面是我的整体步骤(建议先使能一下ssh(最下面有),结合…...
2024 年最新使用 Wechaty 开源框架搭建部署微信机器人(微信群智能客服案例)
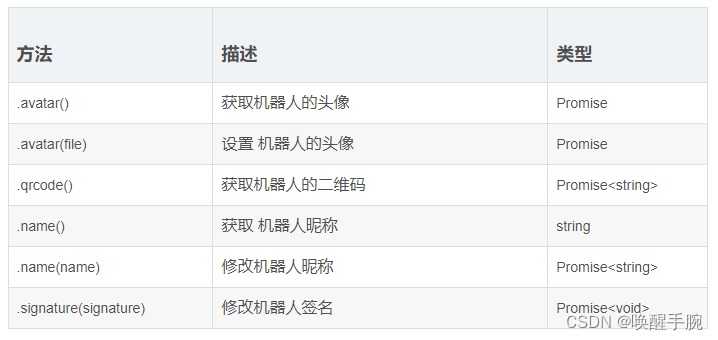
读取联系人信息 获取当前机器人账号全部联系人信息 bot.on(ready, async () > {console.log("机器人准备完毕!!!")let contactList await bot.Contact.findAll()for (let index 0; index < contactList.length; index) {…...
Redis从入门到精通(九)Redis实战(六)基于Redis队列实现异步秒杀下单
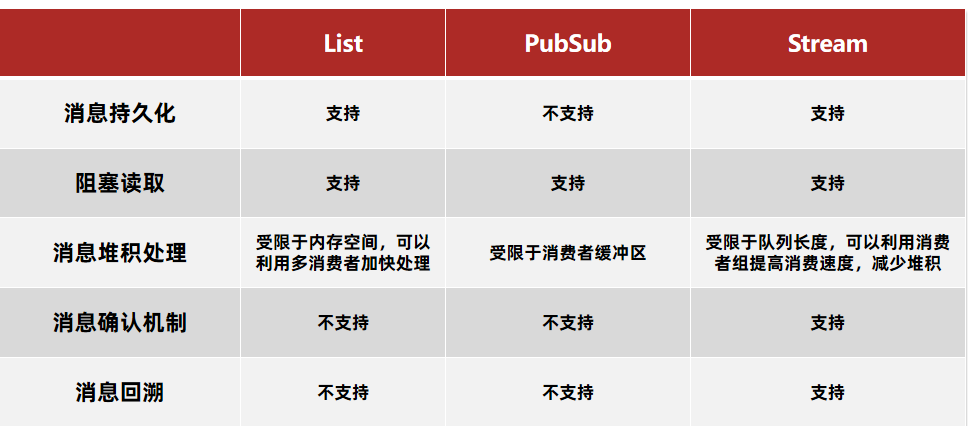
↑↑↑请在文章开头处下载测试项目源代码↑↑↑ 文章目录 前言4.5 分布式锁-Redisson4.5.4 Redission锁重试4.5.5 WatchDog机制4.5.5 MutiLock原理 4.6 秒杀优化4.6.1 优化方案4.6.2 完成秒杀优化 4.7 Redis消息队列4.7.1 基于List实现消息队列4.7.2 基于PubSub的消息队列4.7.…...
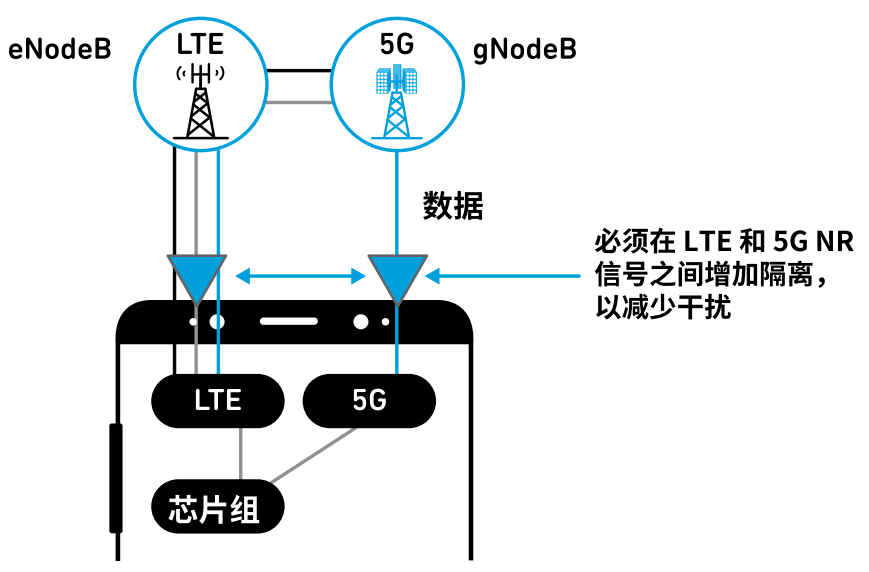
什么是多路复用器滤波器
本章将更深入地介绍多路复用器滤波器,以及它们如何用于各种应用中。您将了解到多路复用器如何帮助设计人员创造出更复杂的无线产品。 了解多路复用器 多路复用器是一组射频(RF)滤波器,它们组合在一起,但不会彼此加载,可以在输出之…...
Severt和tomcat的使用(补充)
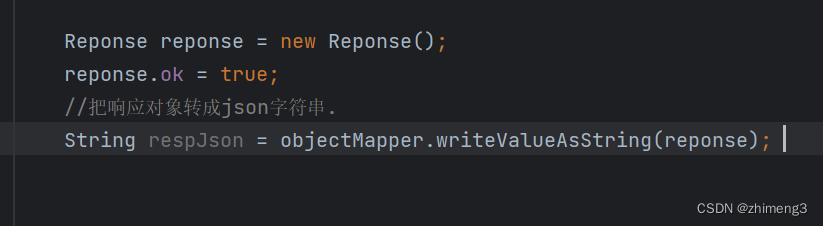
打包程序 在pom.xml中添加上述代码之后打包时会生成war包并且包的名称是test 默认情况打的是jar包.jar里量但是tomcat要求的是war包. war包Tomcat专属的压缩包. war里面不光有.class还有一些tomcat要求的配置文件(web.xml等)还有前端的一些代码(html, css, js) 点击其右边的m…...

JavaEE初阶——多线程(一)
T04BF 👋专栏: 算法|JAVA|MySQL|C语言 🫵 小比特 大梦想 此篇文章与大家分享多线程的第一部分:引入线程以及创建多线程的几种方式 此文章是建立在前一篇文章进程的基础上的 如果有不足的或者错误的请您指出! 1.认识线程 我们知道现代的cpu大多都是多核心…...

MongoDB主从复制模式基于银河麒麟V10系统
MongoDB主从复制模式基于银河麒麟V10系统 背景介绍 MongoDB自4.0版本开始已经不再建议使用传统的master/slave复制架构,而是全面采用了复制集(Replica Sets)作为标准的复制和高可用性解决方案。 复制集是MongoDB的一种数据复制和高可用性机制,通过异步同步数据至多个服务…...
Vue使用高德地图
1.在高德平台注册账号 2.我的 > 管理管理中添加Key 3.安装依赖 npm i amap/amap-jsapi-loader --save 或 yarn add amap/amap-jsapi-loader --save 4.导入 AMapLoade import AMapLoader from amap/amap-jsapi-loader; 5.直接上代码,做好了注释(初始化…...
)
2024-04-07(复盘前端)
---HTML 1.HTMl骨架 html:整个网页 head:网页头部,用来存放给浏览器看的信息,如css body:网页主体,用来存放给用户看的信息,例如图片和文字 2.标题标签中h1标签只能使用一次,其…...
SpringCloud学习(10)-SpringCloudAlibaba-Nacos服务注册、配置中心
Spring Cloud Alibaba 参考文档 Spring Cloud Alibaba 参考文档 nacos下载Nacos 快速开始 直接进入bin包 运行cmd命令:startup.cmd -m standalone 运行成功后通过http://localhost:8848/nacos进入nacos可视化页面,账号密码默认都是nacos Nacos服务注…...

OKCC外呼中心配置的电话系统规则
OKCC外呼中心配置电话系统规则可能涉及多个方面,包括呼叫路由、自动化流程、电话接听策略等。以下是一般步骤及注意事项: 呼叫路由配置: 确定呼叫中心的呼叫路由策略,包括如何分配呼叫给不同的坐席或部门。设置呼叫路由规则&#…...

3分钟上手Mermaid Live Editor:零代码绘制专业图表的终极解决方案
3分钟上手Mermaid Live Editor:零代码绘制专业图表的终极解决方案 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-…...

别被“逻辑“吓退了,入门级数字化认证根本不需要你是学霸
很多人一听到“数字化认证”“AI考试”“逻辑题”,脑子里立刻浮现两种画面:一种是数学特别强的人在刷题,另一种是自己看不懂专业词,直接劝退。可真到企业实习、岗位转型、项目落地时你会发现,职场需要的往往不是“学霸…...

别再手动写滤波器了!用Simulink DSP工具箱5分钟搞定一个可调带宽IIR滤波器
别再手动写滤波器了!用Simulink DSP工具箱5分钟搞定一个可调带宽IIR滤波器 信号处理工程师的日常工作中,滤波器设计是个绕不开的话题。无论是音频处理、通信系统还是生物医学信号分析,我们总需要根据不同的应用场景调整滤波器参数。传统方法中…...

PyCharm 运行 FastAPI 接口请求阻塞?竟是后台多进程残留导致
问题描述在 PyCharm 中启动 FastAPI 项目进程后,使用 Postman 发起接口请求出现明显阻塞现象,不仅请求迟迟无法得到响应,项目控制台也完全接收不到任何请求日志,接口调用彻底失效。 问题根源分析日常开发中习惯性直接关闭运行终端…...

如何用MPC-HC打造专业级音频体验:终极音频重采样配置指南
如何用MPC-HC打造专业级音频体验:终极音频重采样配置指南 【免费下载链接】mpc-hc MPC-HCs main repository. For support use our Trac: https://trac.mpc-hc.org/ 项目地址: https://gitcode.com/gh_mirrors/mpc/mpc-hc 你是否曾经在观看电影或听音乐时&am…...

基于Vercel AI SDK与Next.js 14构建智能编程助手:从架构到部署实战
1. 项目概述:一个面向开发者的AI编程助手脚手架最近在GitHub上看到一个挺有意思的项目,叫vercel-labs/coding-agent-template。光看名字,你大概能猜到,这是一个跟AI编程助手相关的模板项目。没错,它本质上是一个预先配…...

2026本地视频怎么去水印?5款免费去水印软件对比和实用方法指南
很多人都遇到过这个问题:辛辛苦苦保存下来的视频、素材库里的片段,上面都贴了水印,想要二次编辑或重新发布时,这些水印就成了"眼中钉"。本地视频怎么去水印?2026年有哪些靠谱的免费去水印方法?今…...

Claude Code Skill 最佳实践:5 分钟封一个,6 条要点 + 团队共享
👉 这是一个或许对你有用的社群🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料: 《项目实战(视频)》:从书中学,往事上…...

电脑自动干活不是梦|OpenClaw小龙虾本地AI智能体Windows部署详细步骤
核心亮点:零代码门槛|全程可视化|无需手动配环境|内置所有依赖|28 万 Tokens 额度 下载地址:OpenClaw Windows 一键部署包 v2.7.5 文章标签:#OpenClaw #小龙虾 AI #本地 AI 智能体 #Windows 一键…...

从零打造专属机械键盘:基于CircuitPython的USB HID输入设备实践
1. 项目概述:打造你的专属“一键”键盘如果你对市面上千篇一律的键盘感到厌倦,或者一直想亲手制作一个独一无二的输入设备,那么这个项目就是为你准备的。今天,我们不谈那些复杂的全尺寸客制化键盘,而是从一个精巧、有趣…...