canal部署
定义
- canal组件是一个基于mysql数据库增量日志解析,提供增量数据订阅和消费,支持将增量数据投递到下游消费者(kafka,rocketmq等)或者存储(elasticearch,hbase等)
- canal感知到mysql数据变动,然后解析变动数据,将变动数据发送到mq或者同步到其他数据库,等待进一步业务逻辑处理
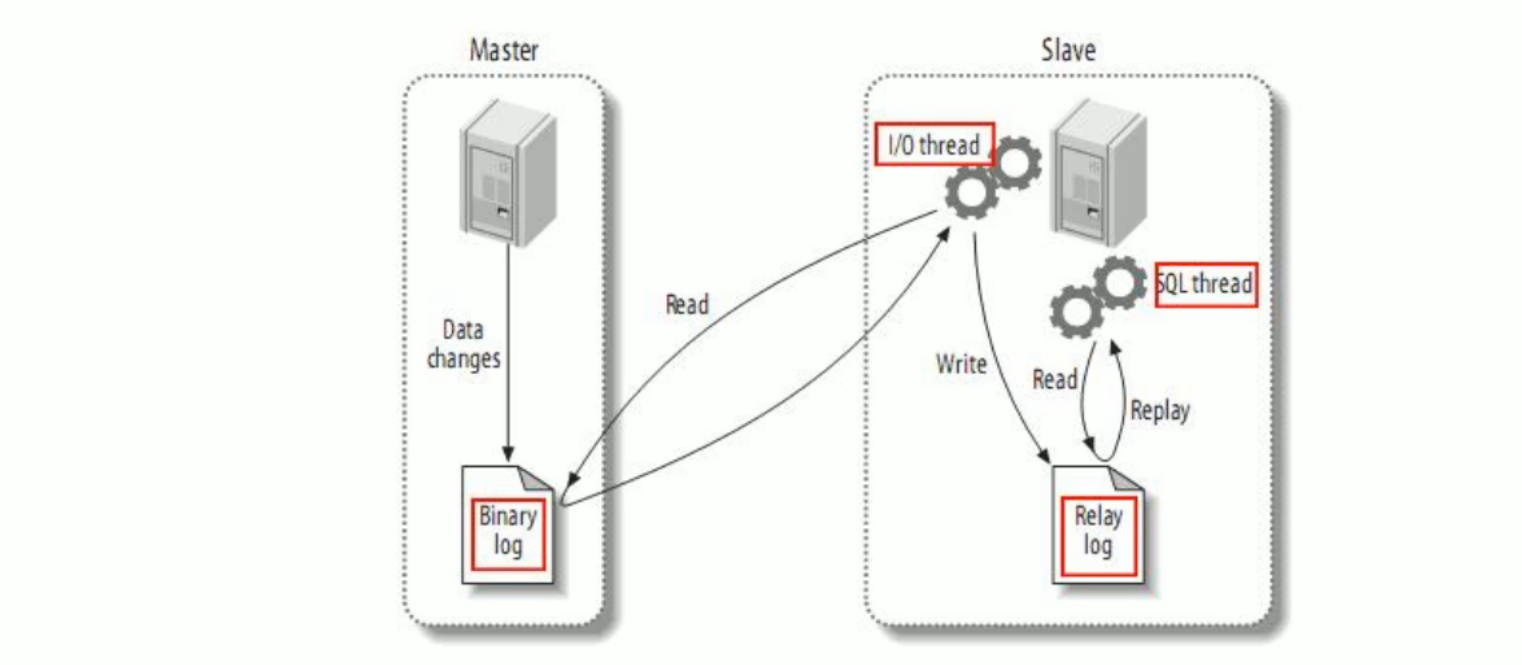
canal的工作原理
- mysql master将数据变更写入到二进制日志binary long,简称binlog
- mysql slave将master的bin log拷贝到它的中继日志relay log
- mysql slave重放relay log操作,将变更数据同步到最新
mysql binlog日志
介绍
- mysql的binlog可以说mysql的最重要的日志,它记录了所有的DDL(表的创建)和DML(数据发生变化)语句,以事件形式记录
- mysql默认情况下是不开启binlog,因为记录binlog日志需要消耗时间,官方给出的数据是有1%的性能损耗
- 一般来说,在下面两场场景下会开启binlog日志
- mysql主从集群部署时,需要将在master端开启binlog,方便将数据同步到slaves中
- 数据恢复了,通过使用mysql binlog工具来使数据恢复
- 一般来说,在下面两场场景下会开启binlog日志
binlog的分类
| 分类 | 介绍 | 优点 | 缺点 |
|---|---|---|---|
| STATEMENT | 语句级别,记录每一次执行写操作的语句相当于row模式节省了空间,但是可能产生的数据不一致,有疑执行时间不同,导致产生的数据不同 | 节省空间 | 可能造成数据不一致 |
| ROW | 行级,记录每次操作后每行记录的变化,假如一个update的sql执行结果是1万行statement只存一条,如果是row的话会把这1万行的结果存着 | 数据绝对一致性,因为不管sql是什么,引用了什么函数,他只记录执行后的效果 | 占用较大空间 |
| MIXED | 是对STATEMENT的升级,如当函数中包含UUID()时,包含AUTO_INCREMENT字段的表被更新时,执行INSERT DELAYED语句时,用UDF时,会按照ROW的方式进行处理 | 节省空间,同时兼顾了一定的一致性 | 还有些极个别情况依旧会造成不一致,另外STATEMENT和mixed对于需要对binlog的监控的情况都不方便 |
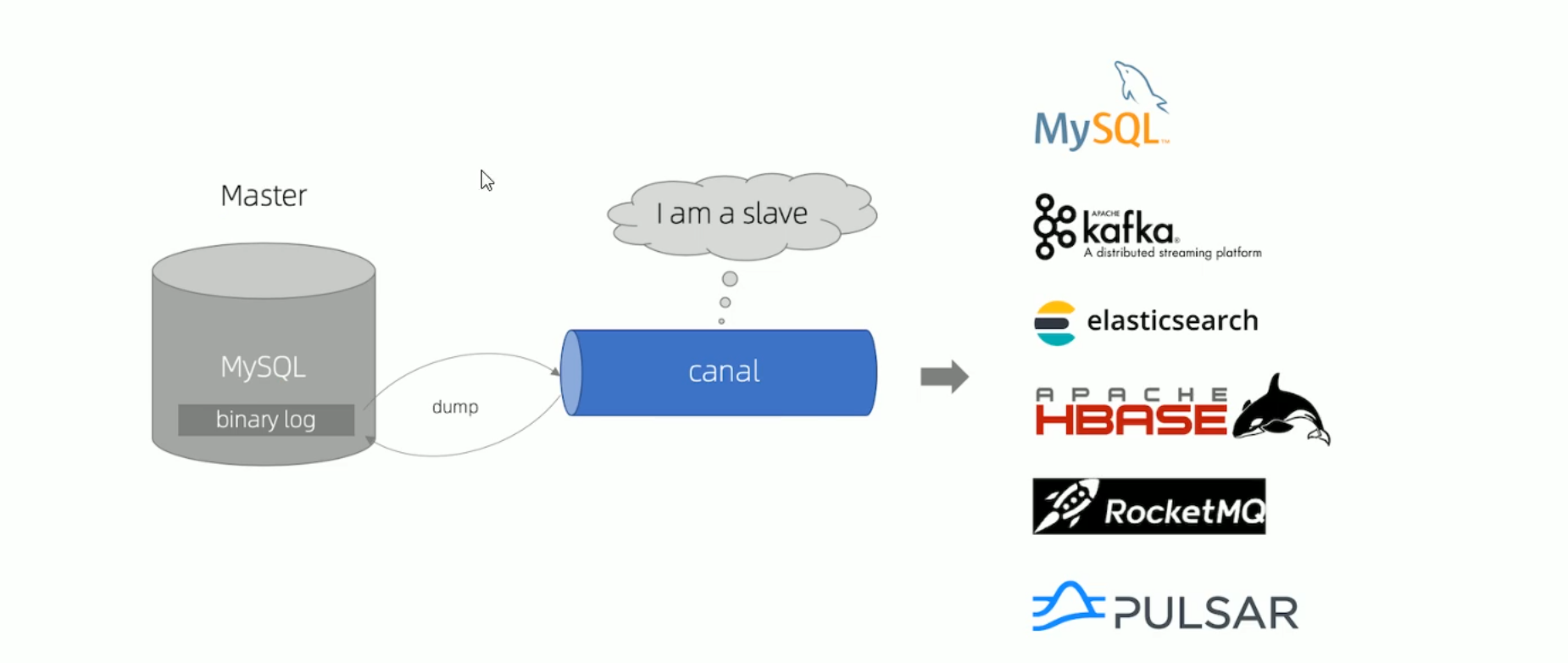
canal工作原理
- canal将自己伪装为mysql slave,向mysql master发送bump协议
- mysql master 收到dump请求,开始推送binary log给slave(canal)
- canal接收并解析binlog日志,得到变更的数据,执行后续逻辑
canal应用场景
数据同步
- canal可以帮助用户进行多种数据同步操作,如实时同步mysql数据到elasticsearch,redis等数据存储介质中

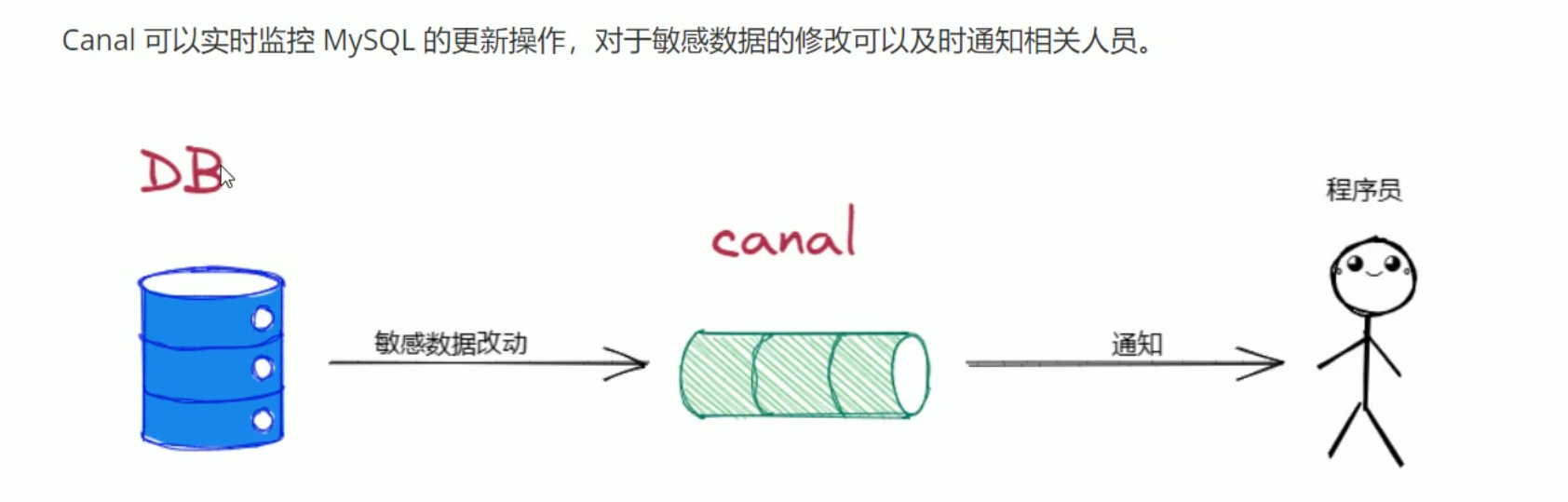
数据库实时监控
- canal可以实时监控mysql的更新操作,对于敏感数据的修改可以及时通知相关人员
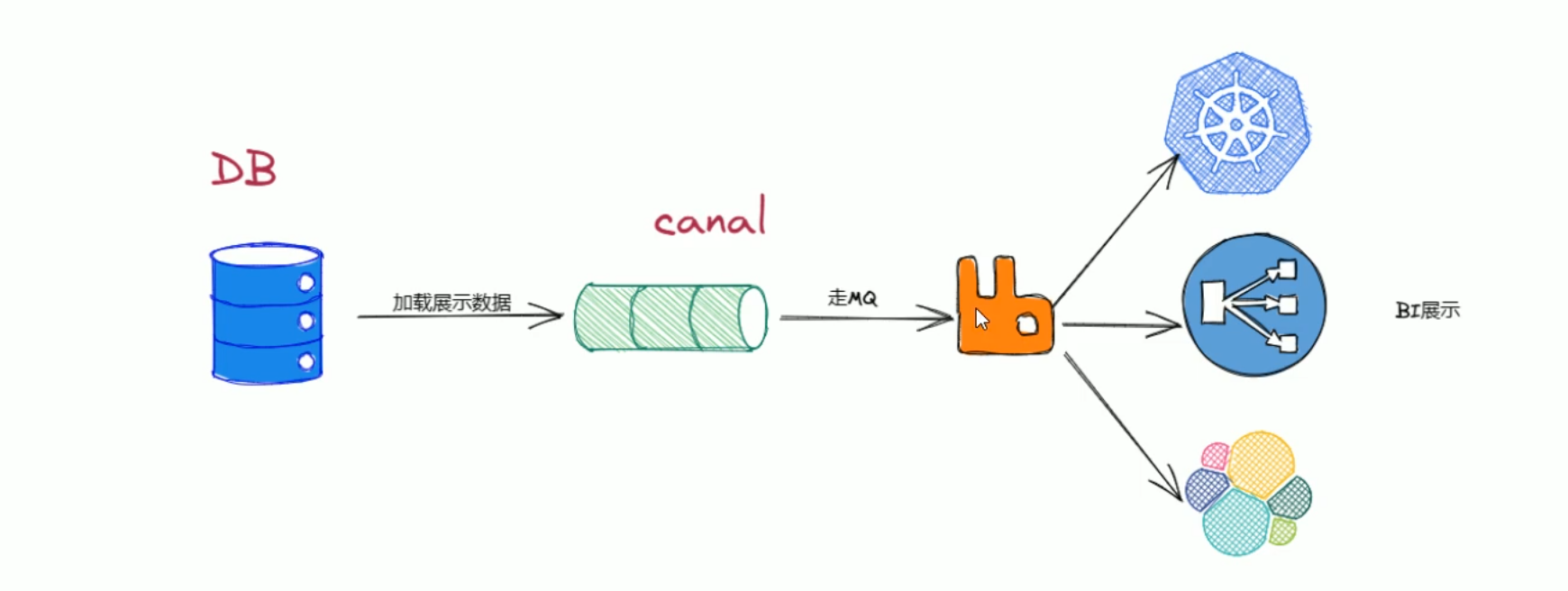
数据分析和挖掘
- canal可以将mysql增量数据投递到kafka等消息队列中,为数据分析和挖掘提供数据来源
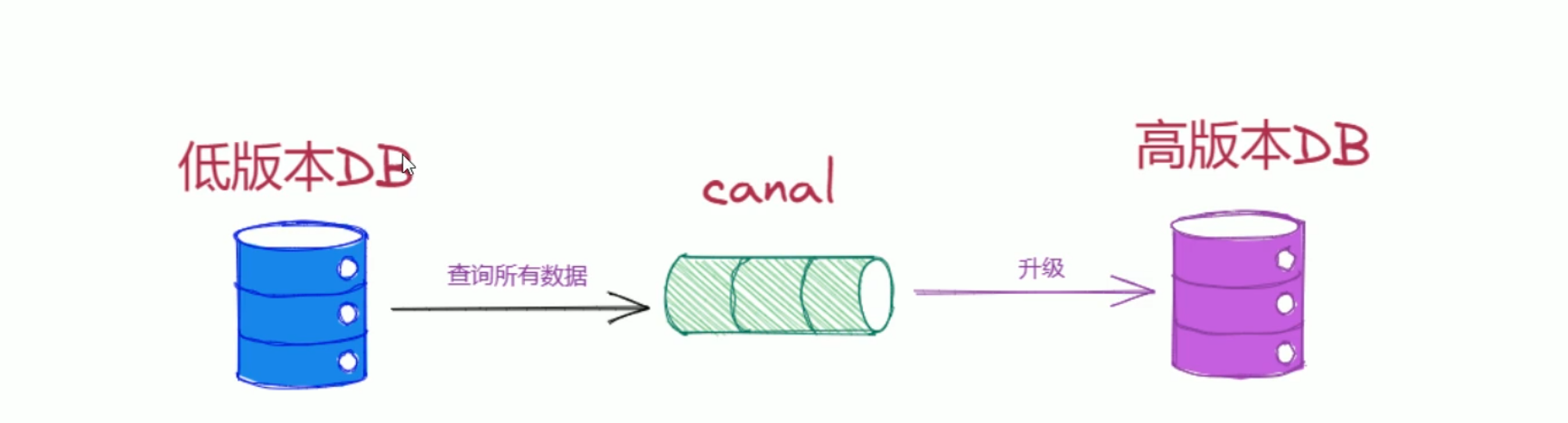
数据库备份
- canal可以将mysql主库上的数据增量日志复制到备库上,实现数据库的备份
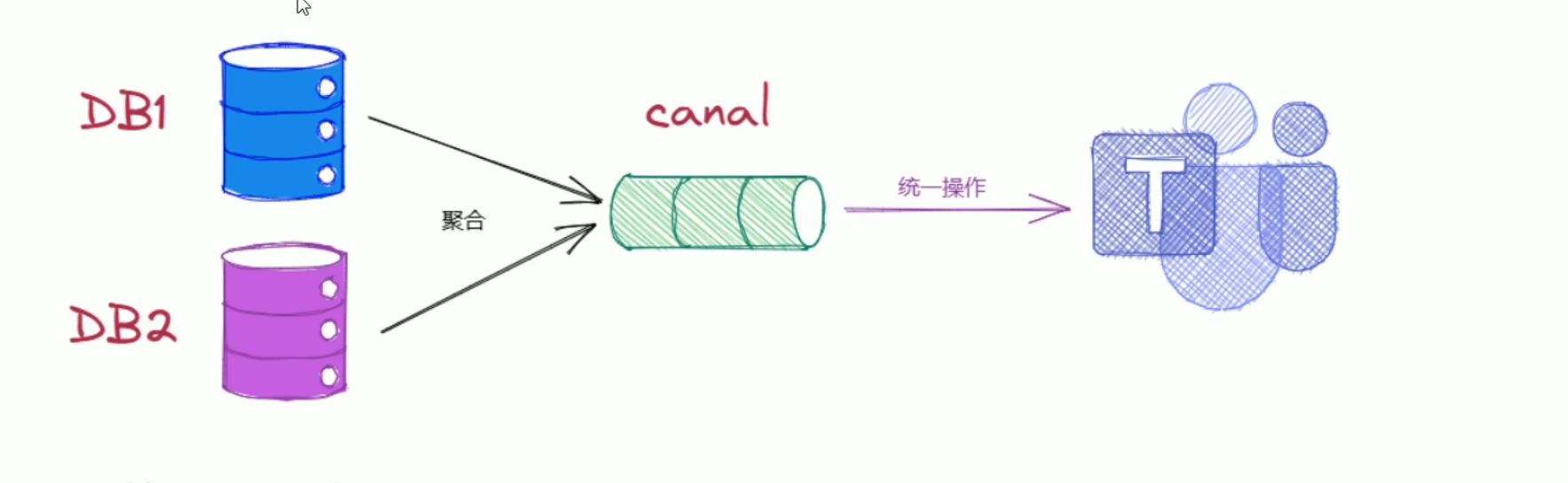
数据集成
- canal可以将多个mysql数据库中的数据进行集成,为数据处理提供更加高效可靠的解决方案
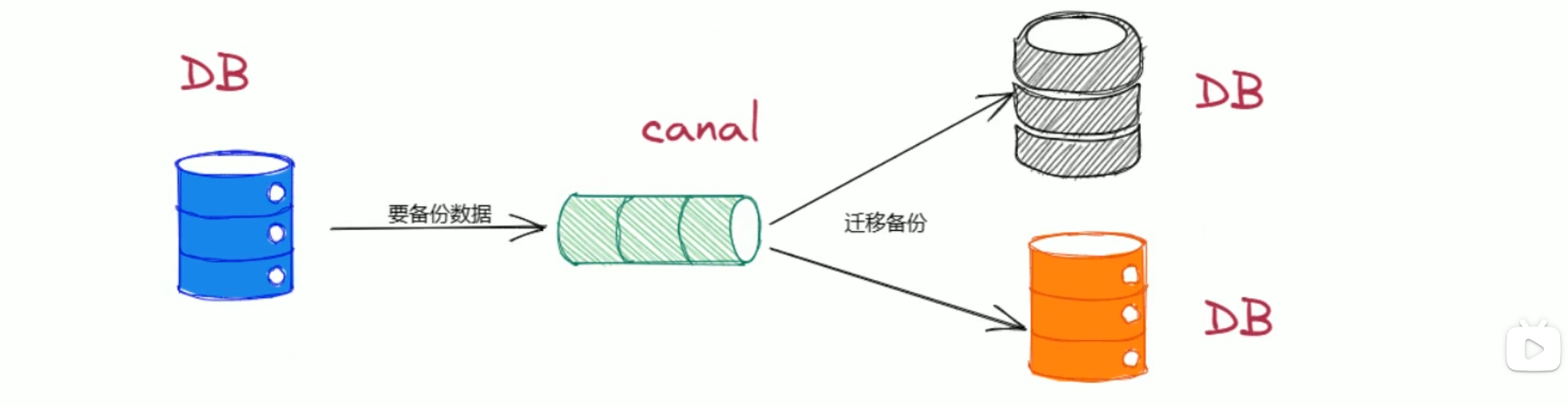
数据库迁移
- canal可以协助完成mysql数据库的辨别升级及数据迁移任务
canal中mysql配置
vim /etc/mysql/my.cnf
[mysqld]
# 设置主服务器唯一ID
server-id=1
# 启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可以设置多个)
binlog-ignore-db=mysql
# 设置需要监听的数据库,不配置表示所有数据库均开启
#binlog-do-db=canal-demo
# 设置logbin格式
binlog_format=row
bind-address = 0.0.0.0
canal下载配置文件
官网下载
tar -zvxf canal.deployer-1.1.7.tar.gz
cd canal
cd conf
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip = 192.168.7.129 # canal的ip
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =canal.zkServers =192.168.5.6:2181 # kafka的端口的和ip
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ, pulsarMQ
canal.serverMode = kafka # 选择同步方式为kafka
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB# binlog ddl isolation
canal.instance.get.ddl.isolation = false# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360#################################################
######### destinations #############
#################################################
canal.destinations = example,script # 需要进行同步的任务,在conf/example文件下,和script下
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = falsecanal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xmlcanal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = localcanal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 192.168.5.6:9092 # kafka的IP地址和端口
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0kafka.kerberos.enable = false
kafka.kerberos.krb5.file = ../conf/kerberos/krb5.conf
kafka.kerberos.jaas.file = ../conf/kerberos/jaas.conf# sasl demo
# kafka.sasl.jaas.config = org.apache.kafka.common.security.scram.ScramLoginModule required \\n username=\"alice\" \\npassword="alice-secret\";
# kafka.sasl.mechanism = SCRAM-SHA-512
# kafka.security.protocol = SASL_PLAINTEXT##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = test
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.deliveryMode =##################################################
######### Pulsar #############
##################################################
pulsarmq.serverUrl =
pulsarmq.roleToken =
pulsarmq.topicTenantPrefix =配置任务
vim canal/conf/example
vim instance.properties
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0# enable gtid use true/false
canal.instance.gtidon=false# position info
canal.instance.master.address=192.168.7.129:3306 # 数据库的ip和端口
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=# username/password
canal.instance.dbUsername=canal # 数据库的用户名
canal.instance.dbPassword=docker211102 # 数据库的密码
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==# table regex
canal.instance.filter.regex=script\\..* #监控script这个数据库下面的所有的表
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch# mq config
canal.mq.topic=example # 将数据发送到example这个主题里面
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,topic2:mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.enableDynamicQueuePartition=false
#canal.mq.partitionsNum=3
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#
# multi stream for polardbx
canal.instance.multi.stream.on=false
#################################################vim canal/conf/script
vim instance.properties
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0# enable gtid use true/false
canal.instance.gtidon=false# position info
canal.instance.master.address=192.168.7.129:3306 # 数据库的ip和端口
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=# username/password
canal.instance.dbUsername=canal # 数据库的用户名
canal.instance.dbPassword=docker211102 # 数据库的密码
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==# table regex
canal.instance.filter.regex=canal-demo\\..* # 监控cancl-demo这个库下面的所有表
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch# mq config
canal.mq.topic=script # 将数据发送到script这个主题里面
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,topic2:mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.enableDynamicQueuePartition=false
#canal.mq.partitionsNum=3
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#
# multi stream for polardbx
canal.instance.multi.stream.on=false
#################################################相关文章:
canal部署
定义 canal组件是一个基于mysql数据库增量日志解析,提供增量数据订阅和消费,支持将增量数据投递到下游消费者(kafka,rocketmq等)或者存储(elasticearch,hbase等)canal感知到mysql数据变动&…...

001集——在线网络学习快速完成——16倍速度
在线网络学习快进方法如下: 电脑下载 Microsoft edge 浏览器,有的电脑是自带的 1、点击右上角… 2、点击"扩展" 3、点击"管理扩展" 4、点击"获取 Microsoft edge 扩展" 5、搜索框里搜" global " 6、获取"…...
golang web 开发 —— gin 框架 (gorm 链接 mysql)
目录 1. 介绍 2. 环境 3. gin 3.1 gin提供的常见路由 3.2 gin的分组 main.go router.go 代码结构 3.3 gin 提供的Json方法 main.go route.go common.go user.go order.go 3.4 gin框架下如何获取传递来的参数 第一种是GET请求后面直接 /拼上传递的参数 第二种是…...
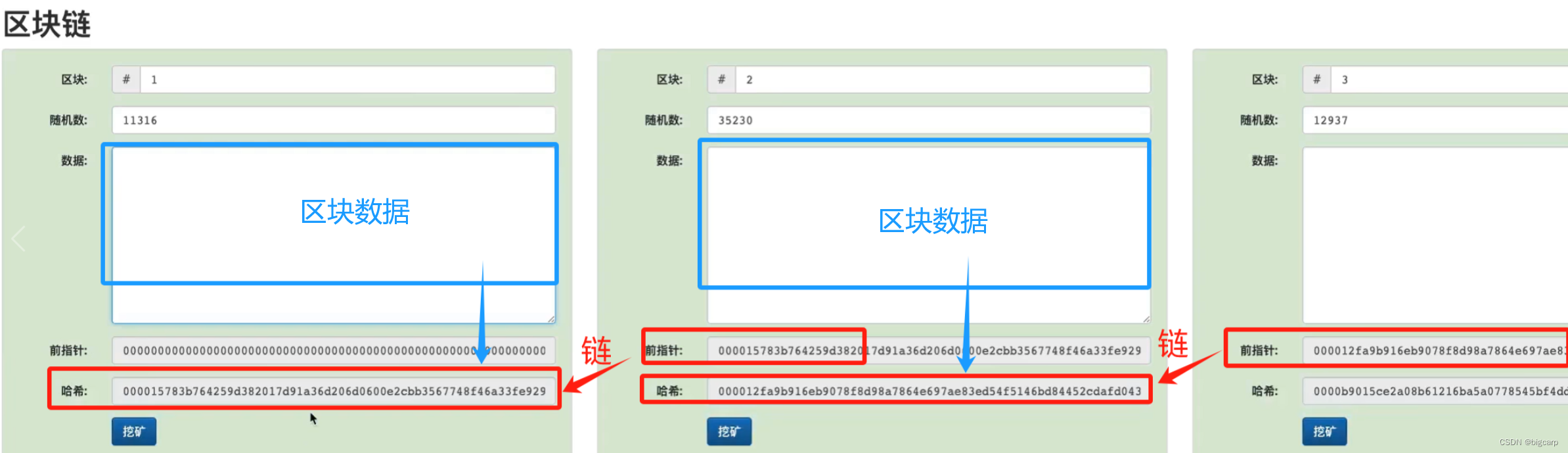
区块链相关概念
区块链是什么,就算是做计算机技术开发的程序员,100个当中都没有几个能把这个概念理解明白,更不要说讲清楚了。那对于普通人来说,就更扯了。 除了“挖矿”表面意思似乎比较好理解外,其他的基础概念真TMD绕。 去中心化、…...
文章解读与仿真程序复现思路——电力系统自动化EI\CSCD\北大核心《考虑灵活爬坡产品的虚拟电厂两阶段分布鲁棒优化运营策略》
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》 论文与完整源程序_电网论文源程序的博客-CSDN博客https://blog.csdn.net/liang674027206/category_12531414.html 电网论文源程序-CSDN博客电网论文源…...
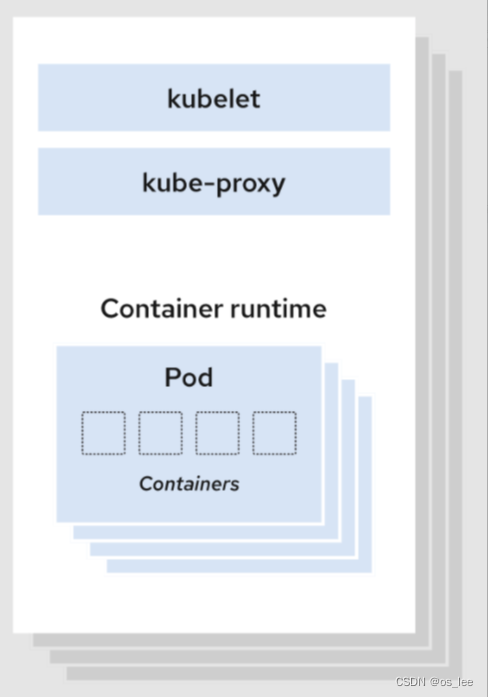
2.k8s架构
目录 k8s集群架构 控制平面 kube-apiserver kube-scheduler etcd kube-controller-manager node 组件 kubelet kube-proxy 容器运行时(Container Runtime) cloud-controller-manager 相关概念 k8s集群架构 一个Kubernetes集群至少包含一个控制…...

xss.pwnfunction-Ligma
首先用jsFuckhttps://jsfuck.com/ [][(![][])[[]](![][])[![]![]](![][])[![]](!![][])[[]]][([][(![][])[[]](![][])[![]![]](![][])[![]](!![][])[[]]][])[![]![]![]](!![][][(![][])[[]](![][])[![]![]](![][])[![]](!![][])[[]]])[![][[]]]([][[]][])[![]](![][])[![]![]!…...

分布式限流——Redis实现令牌桶算法
令牌桶算法 令牌桶算法(Token Bucket Algorithm)是一种广泛使用的流量控制(流量整形)和速率限制算法。这个算法能够控制网络数据的传输速率,确保数据传输的平滑性,防止网络拥堵,同时也被应用于…...
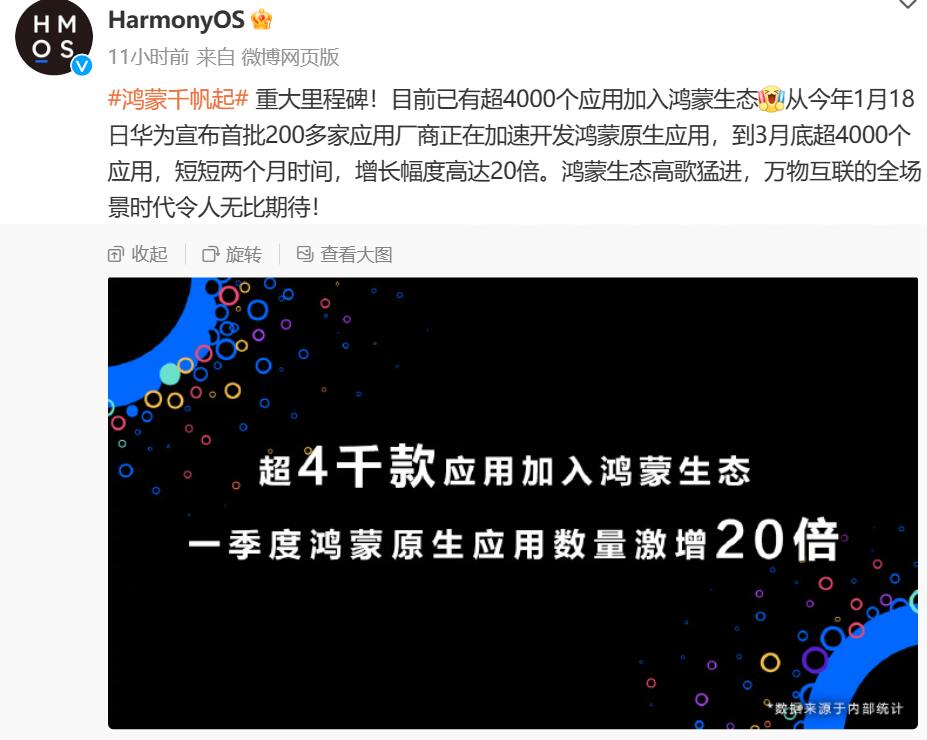
鸿蒙原生应用已超4000个!
鸿蒙原生应用已超4000个! 来自 HarmonyOS 微博近期消息,#鸿蒙千帆起# 重大里程碑!目前已有超4000个应用加入鸿蒙生态。从今年1月18日华为宣布首批200多家应用厂商正在加速开发鸿蒙原生应用,到3月底超4000个应用,短短…...
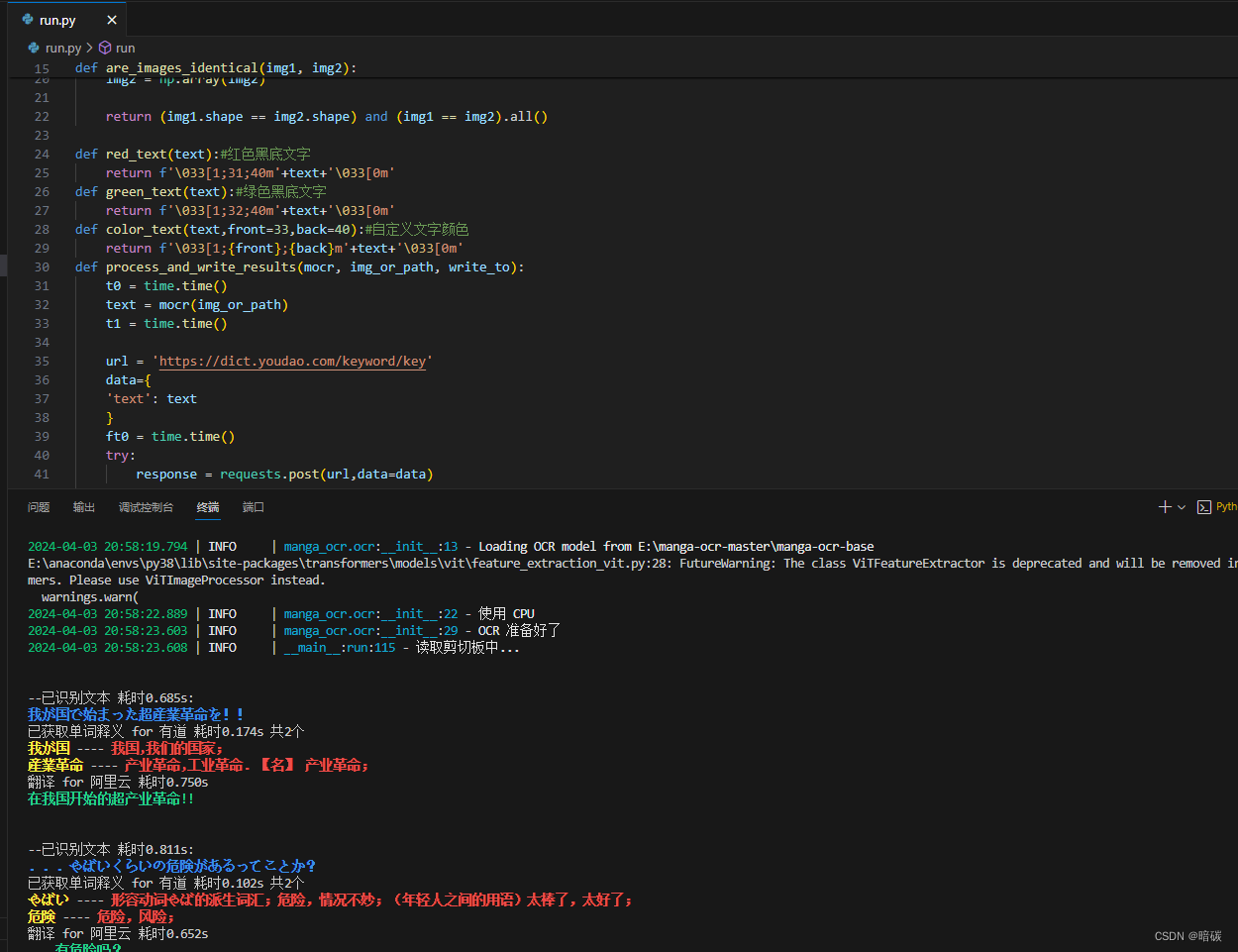
manga-ocr漫画日文ocr
github 下载 解压 anaconda新建环境 conda create -n manga_ocr python3.8 激活环境 conda activate manga_ocr cd到解压目录 cd /d manga-ocr-master 安装依赖包 pip install -r requirements.txt pip3 install manga-ocr 下载离线model huggingface 123云盘 解压到一个目录…...

STL、Vector和Set的讲解和例题分析
STL STL(Standard Template Library,标准模板库)是C标准库的一部分,它提供了一系列通用的编程组件,包括容器、迭代器、算法和函数对象等。STL是C中实现泛型编程的核心,它允许程序员使用模板编写与数…...

Android 13 aosp hiddenapi config
Android 11 hiddenapi路径 frameworks/base/config/hiddenapi-greylist-packages.txtAndroid 13 hiddenapi路径 frameworks/base/boot/hiddenapi/hiddenapi-unsupported-packages.txt...

数据仓库面试总结
文章目录 1.什么是数据仓库?2.ETL是什么?3.数据仓库和数据库的区别(OLTP和OLAP的区别)4.数据仓库和数据集市的区别5.维度分析5.1 什么是维度?5.2什么是指标? 6.什么是数仓建模?7.事实表7.维度表…...
git Failed to connect to 你的网址 port 8282: Timed out
git Failed to connect to 你的网址 port 8282: Timed out 出现这个问题的原因是:原来的仓库换了网址,原版网址不可用了。 解决方法如下: 方法一:查看git用户配置是否有如下配置 http.proxyhttp://xxx https.proxyhttp://xxx如果…...
[C++][算法基础]堆排序(堆)
输入一个长度为 n 的整数数列,从小到大输出前 m 小的数。 输入格式 第一行包含整数 n 和 m。 第二行包含 n 个整数,表示整数数列。 输出格式 共一行,包含 m 个整数,表示整数数列中前 m 小的数。 数据范围 1≤m≤n≤&#x…...
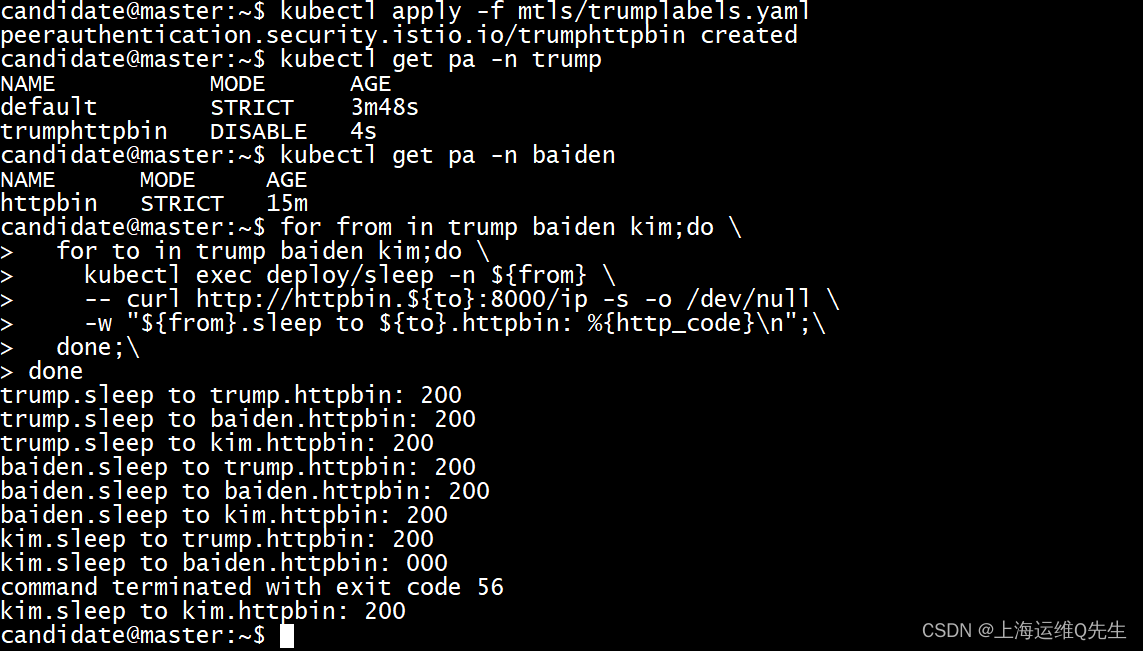
备考ICA----Istio实验15---开启 mTLS 自动双向认证实验
备考ICA----Istio实验15—开启mTLS自动双向认证实验 在某些生成环境下,我们希望微服务和微服务之间使用加密通讯方式来确保不被中间人代理. 默认情况下Istio 使用 PERMISSIVE模式配置目标工作负载,PERMISSIVE模式时,服务可以使用明文通讯.为了只允许双向 TLS 流量,…...

Hive SchemaTool 命令详解
Hive schematool 是 hive 自带的管理 schema 的相关工具。 列出详细说明 schematool -help直接输入 schematool 或者schematool -help 输出结果如下: usage: schemaTool-alterCatalog <arg> Alter a catalog, requires--catalogLocation an…...

51单片机入门_江协科技_17~18_OB记录的笔记
17. 定时器 17.1. 定时器介绍:51单片机的定时器属于单片机的内部资源,其电路的连接和运转均在单片机内部完成,无需占用CPU外围IO接口; 定时器作用: (1)用于计时系统,可实现软件计时&…...
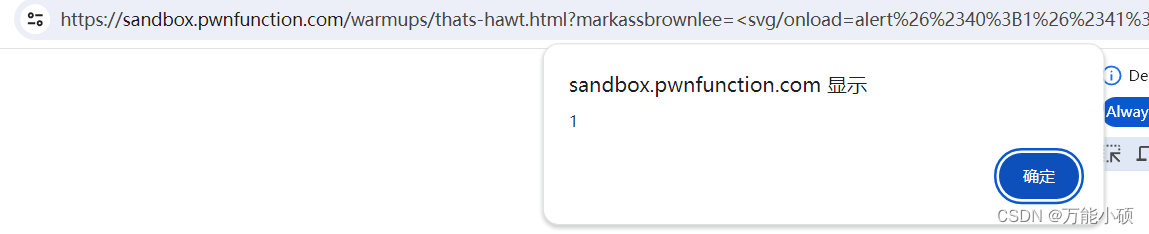
xss.pwnfunction-Ah That‘s Hawt
<svg/onloadalert%26%2340%3B1%26%2341%3B> <svg/>是一个自闭合形式 ,当页面或元素加载完成时,onload 事件会被触发,从而可以执行相应的 JavaScript 函数...

Python学习从0开始——005数据结构
Python学习从0开始——005数据结构 一、列表list二、元组和序列三、集合四、字典五、循环技巧六、条件控制七、序列和其它类型的比较 一、列表list 不是所有数据都可以排序或比较。例如,[None, ‘hello’, 10] 就不可排序,因为整数不能与字符串对比&…...

STM32驱动WS2812灯珠颜色错乱?可能是你的GRB顺序和位序搞反了!
STM32驱动WS2812灯珠颜色错乱?GRB顺序与位序的深度解析 当你第一次用STM32成功点亮WS2812灯珠时,那种成就感难以言表。但紧接着,你可能遇到了一个令人困惑的问题:明明在代码里设置了纯红色(255, 0, 0)&…...

SFT与RL:AI训练的黄金搭档,何时介入才能事半功倍?
本文探讨了SFT(监督微调)和RL(强化学习)在AI训练中的协同作用。SFT负责建立模型的基础能力,确保其遵循格式和指令;RL在此基础上优化输出质量,使其更符合人类使用习惯。文章详细分析了何时进行RL…...

ansys 2021r1明明已经卸载了,但是开始菜单还存在一些图标,这个是什么原因?是没有卸载干净吗?-需要重新开始菜单卸载。
ansys 2021r1明明已经卸载了,但是开始菜单还存在一些图标,这个是什么原因?是没有卸载干净吗? 开始菜单残留图标通常不是因为软件未卸载干净,而是快捷方式文件未被自动删除。即使ANSYS 2021 R1已通过控制面板或自带卸载程序完全移除,其在“开始菜单”中的快捷方式仍可能…...

Claude Code Skill 最佳实践:5 分钟封一个,6 条要点 + 团队共享
👉 这是一个或许对你有用的社群🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料: 《项目实战(视频)》:从书中学,往事上…...

React可访问性开发:如何构建符合A11y标准的React组件
React可访问性开发:如何构建符合A11y标准的React组件 【免费下载链接】react-faq A collection of links to help answer your questions about React.js 项目地址: https://gitcode.com/gh_mirrors/re/react-faq React作为现代前端开发的主流框架࿰…...

告别卡顿与隐私担忧:用Docker Compose在1核1G VPS上部署高性能RustDesk私有服务器
在1核1G VPS上构建高性能RustDesk私有化服务的完整指南 远程协作已成为现代工作流中不可或缺的一环,而数据隐私和连接稳定性则是技术爱好者最关注的核心问题。开源远程桌面解决方案RustDesk以其轻量级架构和自托管能力,为追求完全控制权的用户提供了理想…...

Dify工作流终极指南:50+模板一键导入,零基础也能快速上手AI自动化
Dify工作流终极指南:50模板一键导入,零基础也能快速上手AI自动化 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Tren…...

为什么你的NotebookLM总“读不懂”Nature论文?生信老炮拆解7类专业语义断层及5种Prompt工程修复方案
更多请点击: https://kaifayun.com 第一章:NotebookLM生物技术研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,专为知识密集型工作流设计。在生物技术领域,它可高效整合海量文献、实验报告与基因组数据库摘要&#x…...

Kubernetes原生部署Jenkins:全栈方案与生产级实践指南
1. 项目概述:一个为Kubernetes而生的Jenkins全栈部署方案在容器化和云原生技术席卷全球的今天,Jenkins作为持续集成与持续交付领域的常青树,其部署形态也正经历着深刻的变革。直接将Jenkins部署在物理机或虚拟机上,虽然简单直接&a…...

告别背包焦虑!泰坦之旅终极装备管理神器完全指南
告别背包焦虑!泰坦之旅终极装备管理神器完全指南 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 还在为《泰坦之旅》中堆积如山的传奇装备无处存放而烦恼吗&…...