Mysql底层原理五:如何设计、用好索引
1.索引的代价
空间上的代价
时间上的代价
每次对表中的数据进⾏增、删、改操作时,都需要去修改各个B+树索引。⽽且我们讲过,B+树每层节点都是按照索引列的值从⼩到⼤的顺序排序⽽组成了双 向链表。不论是叶⼦节点中的记录,还是内节点中的记录(也就是不论是⽤户记录还是⽬录项记录)都是按照索引列的值从⼩到⼤的顺序⽽形成了⼀个单向链 表。⽽增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需要额外的时间进⾏⼀些记录移位,⻚⾯分裂、⻚⾯回收啥的操作来维护好节点和 记录的排序。如果我们建了许多索引,每个索引对应的B+树都要进⾏相关的维护操作,这还能不给性能拖后腿么?
总结:
所以说,一个表上索引建的越多,就会占用越多的存储空间,在增删改的时候性能就会越差。
2.索引适用的条件
为了将索引的效能发挥最大,我们需要对索引由深刻的认识。下面,我们通过查询来更加深入理解索引的使用方式。
1.1 准备
建立表:
CREATE TABLE person_info(id INT NOT NULL auto_increment,name VARCHAR(100) NOT NULL,birthday DATE NOT NULL,phone_number CHAR(11) NOT NULL,country varchar(100) NOT NULL,PRIMARY KEY (id),KEY idx_name_birthday_phone_number (name, birthday, phone_number)
);
对应这个表,有几点需要注意:
- 表中的主键是id,Innodo存储引擎会自动为id生成聚簇索引
- 我们额外定义了⼀个⼆级索引idx_name_birthday_phone_number,它是由3个列组成的联合索引。所以在这个索引对应的B+树的叶⼦节点处存储的⽤户记录 只保留name、birthday、phone_number这三个列的值以及主键id的值,并不会保存country列的值。
直接看一下二级索引的图示:
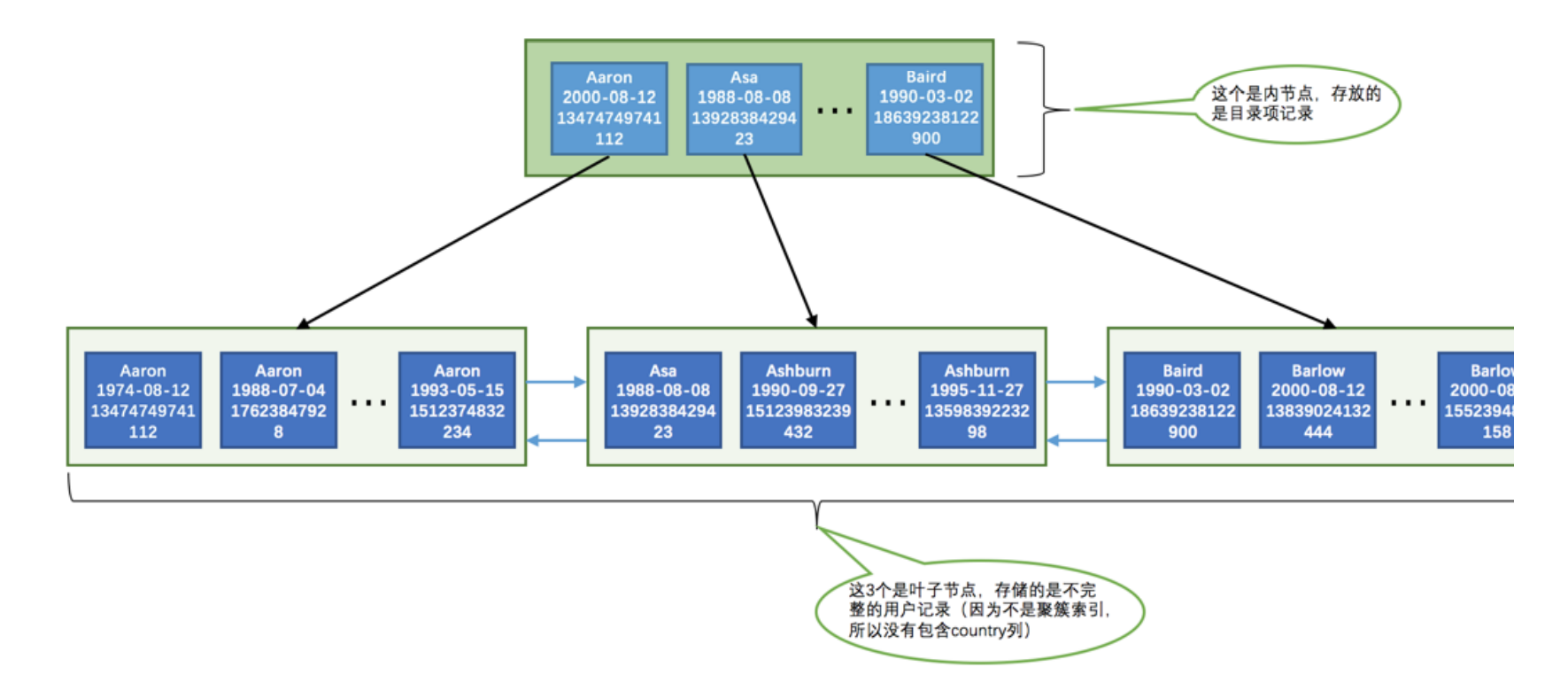
从图中可以看出:
- 先按照name列的值进行升序
- 如果name一样,就按照birthday列进行升序
- 如果birthday一样,就按照phone_numer进行升序
这个排序十分重要,因为只有页面和记录排好序,我们才可以通过二分法快速查找。
1.2 索引发挥作用
1.2.1 全值匹配
如果我们的搜索条件中的列和索引列一致的话,这种情况就称为全值匹配,比方说下面这个条件:
SELECT*
FROMperson_info
WHERENAME = 'Ashburn' AND birthday = '1990-09-27' AND phone_number = '15123983239';
这个查询过程很简单,先按照name,接着birthday,最后phone_numer
如果 where后面的查询条件顺序改一下会有什么影响嘛?
SELECT*
FROMperson_info
WHEREbirthday = '1990-09-27' AND phone_number = '15123983239' AND NAME = 'Ashburn';
答案:没有影响,Mysql查询优化器会按照可以使用索引中列的顺序来决定先使用哪个条件。
1.2.2 匹配最左边列
有时候,我们不想全值匹配,只是通过一个列,比如下面:
SELECT*
FROMperson_info
WHERENAME = 'Ashburn';
或者
SELECT*
FROMperson_info
WHERENAME = 'Ashburn' AND birthday = '1990-09-27';
只要where条件后面按照索引顺序,但又不是全值匹配,都会走索引。因为B+树的数据⻚和记录先是按照name列的值排序的,在name列的值相同的情况下才使⽤birthday列进⾏排序,也就是说name列的值不同的 记录中birthday的值可能是⽆序的。
但是:像下面这种方式就不会走索引了:
SELECT*
FROMperson_info
WHEREbirthday = '1990-09-27';
总结一下:
- 在联合索引时,如果想要使用索引,where 条件后面顺序一定要和索引保持顺序,这有点像找个人一样,刚开始拿姓匹配,如果匹配不上就第二个字,再匹配不上就第三个字。。。
1.2.3 匹配列前缀
走索引:
SELECT*
FROMperson_info
WHERENAME LIKE 'As%';
不走索引:
SELECT * FROM person_info WHERE name LIKE '%As%';
原因:Mysql无法定位记录的位置,因为可能性太多了,可以时AAS,aAS,甚至aAas。只有记录无序,Mysql就无法走索引,只能全表扫描了。
像这种的匹配规则是这样的,其实和列匹配差不多:
- 先比较字符串的第一个字符
- 第一个字符一样就比较第二个字符
- 第二个字符如果一样就比较第三个字符,如果一样,继续往后,不一样就终止。
案例:

1.2.4 匹配范围值
回头看我们idx_name_birthday_phone_number索引的B+树示意图,所有记录都是按照索引列的值从⼩到⼤的顺序排好序的,所以这极⼤的⽅便我们查找索引列的 值在某个范围内的记录。⽐⽅说下边这个查询语句:
走索引:
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow';
不走索引:
SELECT*
FROMperson_info
WHERENAME > 'Asa' AND NAME < 'Barlow' AND birthday > '1980-01-01';
上边这个查询可以分为两个部分:
- 通过条件name > ‘Asa’ AND name < 'Barlow’来对name进⾏范围,查找的结果可能有多条name值不同的记录
- 对这些name值不同的记录继续通过birthday > '1980-01-01’条件继续过滤
这样⼦对于联合索引idx_name_birthday_phone_number来说,只能⽤到name列的部分,⽽⽤不到birthday列的部分,因为只有name值相同的情况下才能⽤ birthday列的值进⾏排序,⽽这个查询中通过name进⾏范围查找的记录中可能并不是按照birthday列进⾏排序的,所以在搜索条件中继续以birthday列进⾏查找 时是⽤不到这个B+树索引的。
总结一下:
**为什么加上个birthday条件就用不上索引,其实说到底,就是通过name查找出来的记录birthday不是有序的。比如说 ASA 1980-01-01、ASAa 1979-01-01、Barlow 1981-01-01取出来的birthday不就无序了嘛 **
1.2.5 精确匹配某一列并范围匹配另外一列
对于同⼀个联合索引来说,虽然对多个列都进⾏范围查找时只能⽤到最左边那个索引列,但是如果左边的列是精确查找,则右边的列可以进⾏范围查找,⽐⽅说 这样:
SELECT*
FROMperson_info
WHERENAME = 'Ashburn' AND birthday > '1980-01-01' AND birthday < '2000-12-31' AND phone_number > '15100000000';
这个查询的条件可以分成3个部分:
- name = ‘Ashburn’,对name列进⾏精确查找,当然可以使⽤B+树索引了。
- birthday > ‘1980-01-01’ AND birthday < ‘2000-12-31’,由于name列是精确查找,所以通过name = 'Ashburn’条件查找后得到的结果的name值都是相 同的,它们会再按照birthday的值进⾏排序。所以此时对birthday列进⾏范围查找是可以⽤到B+树索引的。
- phone_number > ‘15100000000’,通过birthday的范围查找的记录的birthday的值可能不同,所以这个条件⽆法再利⽤B+树索引了,只能遍历上⼀步查询 得到的记录。
同理,下边的查询也是可能用到这个联合索引的:
SELECT*
FROMperson_info
WHERENAME = 'Ashburn' AND birthday = '1980-01-01' AND phone_number > '15100000000';
1.2.6 排序
我们在写查询语句的时候可以通过order by来进行升序。一般情况下,是把数据加载到内存中,然后在使用排序算法在内存中进行排序,但是如果数据集太大,**可能需要通过磁盘来存放中间结果,排序完再返回到客户端。**再磁盘中进行排序慢的和蜗牛一样,这时候通过索引直接取出来,不就不需要排序了吗,是不是特别快,哈哈
SELECT * FROM person_info ORDER BY name, birthday, phone_number LIMIT 10;
这个查询的结果集需要先按照name值排序,如果记录的name值相同,则需要按照birthday来排序,如果birthday的值相同,则需要按照phone_number排序。
使用联合索引排序需要注意事项
1) order by 列的顺序一定要和建立联合索引的顺序一致
2) 等值+order by 其余索引列可以使用联合索引

3) ASC、DESC混用
对于联合索引进行排序的场景,要求各个列要么都是ASC排序,要么都是DESC排序

但是,对于先按照name升序,再按照birthday降序的话,比如这样的:
SELECT * FROM person_info ORDER BY name, birthday DESC LIMIT 10;
这样如果使用索引的话,过程是这样的:
- 先从索引的最左边确定name列最⼩的值,然后找到name列等于该值的所有记录,然后从name列等于该值的最右边的那条记录开始往左找10条记录。
- 如果name列等于最⼩的值的记录不⾜10条,再继续往右找name值第⼆⼩的记录,重复上边那个过程,直到找到10条记录为⽌。
累不累,累啊,对于索引的使用一点也不高效,设计Mysql觉得这样还不如直接文件排序来的快,所以联合索引的各个排序列的排序顺序必须是一样的
1】 where子句中出现非排序使用到的索引列,如果说:
SELECT * FROM person_info WHERE country = 'China' ORDER BY name LIMIT 10;
这个查询是把符合条件的数据先查询出来然后排序,这样是使用不到索引的。
2】 排序列包含非同一个索引的列
有时候⽤来排序的多个列不是⼀个索引⾥的,这种情况也不能使⽤索引进⾏排序,⽐⽅说:
SELECT * FROM person_info ORDER BY name, country LIMIT 10;
name和country并不属于⼀个联合索引中的列,所以⽆法使⽤索引进⾏排序,⾄于为啥我就不想再唠叨了,⾃⼰⽤前边的理论⾃⼰捋⼀捋把~
3】 排序列使用了复杂的表达式
要想使⽤索引进⾏排序操作,必须保证索引列是以单独列的形式出现,⽽不是修饰过的形式,⽐⽅说这样:
SELECT * FROM person_info ORDER BY UPPER(name) LIMIT 10;
使⽤了UPPER函数修饰过的列就不是单独的列啦,这样就⽆法使⽤索引进⾏排序啦。
1.2.7 分组
有时候我们为了⽅便统计表中的⼀些信息,会把表中的记录按照某些列进⾏分组。⽐如下边这个分组查询:
SELECT NAME,birthday,phone_number,COUNT( * )
FROMperson_info
GROUP BYNAME,birthday,phone_number
这个查询相当于做了这3次分组操作:
- 先按照name分组,把所有name相同的分成一个个大组
- 一个个大组再按照birthday分成一个个小组
- 一个个小组再按照phone_numer分成一个个更小的组

3.回表的代价
这个东西对于我来说,很好理解就放张整图了:

索引覆盖
问题:回表的代价这么大,我们怎么减少拿?
为了彻底告别回表操作带来的性能损耗,我们建议:最好在查询列表⾥只包含索引列,⽐如这样:
SELECT NAME,birthday,phone_number
FROMperson_info
WHERENAME > 'Asa' AND NAME < 'Barlow'
因为我们只查询name, birthday, phone_number这三个索引列的值,所以只需要通过联合索引就可以得到,就可以不用聚簇索引回表查询 剩余列,也就是country的值了。 我们把这种只查询索引排序列的方式称之为索引覆盖
排序操作也优先使用索引覆盖的方式查询,比方说这个查询:
SELECT NAME,birthday,phone_number
FROMperson_info
ORDER BYNAME,birthday,phone_number;
虽然这个查询中没有LIMIT⼦句,但是采⽤了覆盖索引,所以查询优化器就会直接使⽤idx_name_birthday_phone_number索引进⾏排序⽽不需要回表操作了。
当然,如果业务需要查询出索引以外的列,那还是以保证业务需求为重。但是我们很不⿎励⽤*号作为查询列表,最好把我们需要查询的列依次标明。
4.如何挑选索引
4.1 只为搜索、排序或者分组的列创建索引
只为出现在WHERE⼦句中的列、连接⼦句中的连接列,或者出现在ORDER BY或GROUP BY⼦句中的列创建索引。而出现在查询列表中的列就不没必要建立索引了:
SELECT birthday, country FROM person_name WHERE name = 'Ashburn';
像查询列表中的birthday、country这两个列就不需要建⽴索引,我们只需要为出现在WHERE⼦句中的name列创建索引就可以了。
4.2 考虑列的基数
列的基数指的是某一列中不重复数据的个数,比方说某个列包含值2, 5, 8, 2, 5, 8, 2, 5, 8,虽然有9条记录,但该列的基数却是3。也就是说,在记录⾏数⼀ 定的情况下,列的基数越⼤,该列中的值越分散,列的基数越⼩,该列中的值越集中。
- 这个列的基数指标⾮常重要,直接影响我们是否能有效的利⽤索引。假设某 个列的基数为1,也就是所有记录在该列中的值都⼀样,那为该列建⽴索引是没有⽤的,因为所有值都⼀样就⽆法排序,⽆法进⾏快速查找了
- 如果某个建⽴ 了⼆级索引的列的重复值特别多,那么使⽤这个⼆级索引查出的记录还可能要做回表操作,这样性能损耗就更⼤了
最好为那些列的基数⼤的列 建⽴索引,为基数太⼩列的建⽴索引效果可能不好。
4.3 索引列的类型尽量小
我们在定义表结构的时候要显示的指定列的类型,以整数类型为理,以整数类型为例,有TINYINT、MEDIUMINT、INT、BIGINT这几种,它们占用的存储空间依次递增,我们这里所说的类型大小指的就是 **该类型表示的数据范围大小。**能表示的整数范围当然也是依次递增,如果我们想要对某个整数列建⽴索引的话,在表示的整数范围允许 的情况下,尽量让索引列使⽤较⼩的类型, 比如,我们能用INT就不要使用BIGINT,能使⽤MEDIUMINT就不要使⽤INT,这是因为:
- 数据类型越⼩,在查询时进⾏的⽐较操作越快(这是CPU层次的东东)
- 数据类型越⼩,索引占⽤的存储空间就越少,在⼀个数据⻚内就可以放下更多的记录,从⽽减少磁盘I/O带来的性能损耗,也就意味着可以把更多的数据⻚缓 存在内存中,从⽽加快读写效率。
这个建议对于表的主键来说更加适⽤,因为不仅是聚簇索引中会存储主键值,其他所有的⼆级索引的节点处都会存储⼀份记录的主键值,如果主键适⽤更⼩的数 据类型,也就意味着节省更多的存储空间和更⾼效的I/O。
4.4 索引字符串的前缀

4.5 让索引列在比较表达式中单独出现
假设表中有一个整数列my_col,我们为这个列建立索引,下面两个where子句虽然语义上是一致的,但在执行效率上却有很大差别:
- WHERE my_col * 2 < 4
- WHERE my_col < 4/2
第1个WHERE⼦句中my_col列并不是以单独列的形式出现的,⽽是以my_col * 2这样的表达式的形式出现的,存储引擎会依次遍历所有的记录,计算这个表达式的 值是不是⼩于4,所以这种情况下是使⽤不到为my_col列建⽴的B+树索引的。⽽第2个WHERE⼦句中my_col列并是以单独列的形式出现的,这样的情况可以直接使 ⽤B+树索引。
如果索引列在⽐较表达式中不是以单独列的形式出现,⽽是以某个表达式,或者函数调⽤形式出现的话,是⽤不到索引的。
4.6 主键选择-最好是自增
我们知道,对于⼀个使⽤InnoDB存储引擎的表来说,在我们没有显式的创建索引时,表中的数据实际上都是存储在聚簇索引的叶⼦节点的。⽽记录⼜是存储在数据 ⻚中的,数据⻚和记录⼜是按照记录主键值从⼩到⼤的顺序进⾏排序,所以如果我们插⼊的记录的主键值是依次增⼤的话,那我们每插满⼀个数据⻚就换到下⼀ 个数据⻚继续插,⽽如果我们插⼊的主键值忽⼤忽⼩的话,这就⽐较麻烦了,假设某个数据⻚存储的记录已经满了,它存储的主键值在1~100之间:

可这个数据⻚已经满了啊,再插进来咋办呢?我们需要把当前⻚⾯分裂成两个⻚⾯,把本⻚中的⼀些记录移动到新创建的这个⻚中。⻚⾯分裂和记录移位意味着 什么?意味着:性能损耗。所以如果我们想尽量避免这样⽆谓的性能损耗,最好让插⼊的记录的主键值依次递增,这样就不会发⽣这样的性能损耗了。所以我们建议:让主键具有AUTO_INCREMENT,让存储引擎⾃⼰为表⽣成主键,⽽不是我们⼿动插⼊,比如说我们可以这么定义person_info表:

4.7 冗余和重复索引
有时候有的人有意或者无意的就对同一列创建了多个索引,比方说这样写建表语句:

我们知道,通过 idx_name_birthday_phone_number索引就可以对 name进行快读搜索,再创建一个专门针对 name列的索引就算是一个 **冗余索引,**维护这个索引只 会增加维护的成本,并不会对搜索有什么好处。
另外一种情况就是,我们对某个列重复建立索引,比方说这样:

我们看到,c1既是主键、⼜给它定义为⼀个唯⼀索引,还给它定义了⼀个普通索引,可是主键本身就会⽣成聚簇索引,所以定义的唯⼀索引和普通索引是重复 的,这种情况要避免。
5.总结
5.1 B+树索引在空间和时间上都有代价,所以没事⼉别瞎建索引。
5.2 B+树索引适⽤于下边这些情况:
- 全值匹配
- 匹配左边的列
- 匹配范围值
- 精确匹配某⼀列并范围匹配另外⼀列
- 用于排序
- 用于分组
这里我自己的总结:怎么判断走不走索引?可以看一下这个操作之前的数据是否是有序的,Mysql能不能快速查询,还是得一个个查询,有序的并且能够快速查询(就像快速扫描一样)肯定是能走索引的。
5.3 在使用索引时要注意以下事项:
- 只为⽤于搜索、排序或分组的列创建索引
- 为列的基数⼤的列创建索引
- 索引列的类型尽量⼩
- 可以只对字符串值的前缀建⽴索引 只有索引列在⽐较表达式中单独出现才可以适
- 为了尽可能少的让聚簇索引发⽣⻚⾯分裂和记录移位的情况,建议让主键拥有AUTO_INCREMENT属性。
- 定位并删除表中的重复和冗余索引
- 尽量使⽤覆盖索引进⾏查询,避免回表带来的性能损耗。
相关文章:
Mysql底层原理五:如何设计、用好索引
1.索引的代价 空间上的代价 时间上的代价 每次对表中的数据进⾏增、删、改操作时,都需要去修改各个B树索引。⽽且我们讲过,B树每层节点都是按照索引列的值从⼩到⼤的顺序排序⽽组成了双 向链表。不论是叶⼦节点中的记录,还是内节点中的记录&a…...

python学习杂记
做为一个接近40岁的人,开始学习python会有什么结果?反正很迷茫,思维方式也开始下降了,希望可以学得好吧 早期做的是前端开发,java也有所接触,但是都学得不精,后来转做项目管理,把技…...

C# Socket发送、接收结构体
Socket发送:Socket的使用 一、Socket发送结构体 结构体如下: [StructLayout(LayoutKind.Sequential, Pack 1)] public struct OutPoint_ST {public int LeftheartX;public int LeftHeartY;public float WidthHeart;public int RightHeartX;public in…...
ics-05-攻防世界
题目 点了半天只有设备维护中心能进去 御剑扫一下 找到一个css 没什么用 再点击云平台设备维护中心url发生了变化 设备维护中心http://61.147.171.105:65103/index.php?pageindex试一下php伪协议 php://filter/readconvert.base64-encode/resourceindex.php base64解一下…...
之事件流事件委托其他事件)
Web API(三)之事件流事件委托其他事件
Web API(三)之事件流&事件委托&其他事件 事件流捕获和冒泡事件捕获事件冒泡阻止冒泡解绑事件两种注册事件的区别事件委托其他事件页面加载事件元素滚动事件页面滚动事件-获取位置页面滚动事件-滚动到指定的坐标页面尺寸事件元素尺寸与位置元素尺寸与位置-尺寸...
SSL证书的作用是什么?
SSL证书让网站和用户之间安全传输信息,就像给网络对话加了一把密码锁。它主要做四件事: 1. 证明身份: - 像警察局一样,有个叫“证书颁发机构”的家伙负责检查网站是不是真的。网站要向它证明自己是谁(比如,…...

皮具5G智能制造工厂数字孪生可视化平台,推进企业数字化转型
皮具5G智能制造工厂数字孪生可视化平台,推进企业数字化转型。随着信息技术的快速发展,数字化转型已成为企业提升竞争力、实现可持续发展的关键路径。皮具行业,作为一个传统的手工制造业,正面临着巨大的市场变革和技术挑战。如何在…...
)
RH850从0搭建Autosar开发环境【3X】- Davinci Configurator之Port模块配置详解(MCAL配置)
Port模块配置详解 前言一、如何添加Port模块?1.1 导入Port模块二、Port模块详细配置说明2.1 Port模块问题解决2.2 Port模块配置步骤2.2.1 数据手册查找Port对应的Group2.2.2 配置Port为CAN功能2.2.3 选择芯片型号总结前言 我们还差一个Port模块进行配置io的复用功能选择。就是…...
多叉树题目:子树中标签相同的结点数
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法思路和算法代码复杂度分析 题目 标题和出处 标题:子树中标签相同的结点数 出处:1519. 子树中标签相同的结点数 难度 5 级 题目描述 要求 给你一个树(即一个连通的无向无环图…...
帝国CMS模板源码整站安装说明(图文)
安装步骤 第一步:先把得到的文件解压缩,把文件通过FTP传到空间里。(请不要把类似www.lengleng.net这个文件夹传到FTP,请传这个大文件夹下面的所有文件夹和文件到空间根目录,请不要上传到2级目录,除非你自己…...

物联网系统未来的发展趋势
一、引言 物联网系统作为新一代的信息技术,正在逐渐改变我们的生活和工作方式。随着物联网技术的不断发展和应用场景的拓展,未来物联网系统的发展趋势将更加明显。本文将从技术、应用、安全等方面探讨物联网系统未来的发展趋势。 二、技术发展趋势 1.…...

基于支持 GPT 的服务的初创公司
Kafkai:多语言长篇内容生成,AI写作的新趋势 介绍 随着生成式预训练 Transformer (GPT) 的出现,技术世界正在见证范式转变。 这种人工智能驱动的创新不仅仅是一种转瞬即逝的趋势,而是一种趋势。 它已成为科技行业的基石,…...
基于springboot实现教师人事档案管理系统项目【项目源码+论文说明】
基于springboot实现IT技术交流和分享平台系统演示 摘要 我国科学技术的不断发展,计算机的应用日渐成熟,其强大的功能给人们留下深刻的印象,它已经应用到了人类社会的各个层次的领域,发挥着重要的不可替换的作用。信息管理作为计算…...

上行上传rsync+inotify
引言 使用inotify通知接口,可以用来监控文件系统的各种变化情况,如文件存取、删除、移动、修改等。利用这一机制,可以非常方便地实现文件异动告警、增量备份,并针对目录或文件的变化及时作出响应。 将inotify机制与rsync工具相结合…...

借助ChatGPT写作:打造学术论文中的亮点与互动
ChatGPT无限次数:点击直达 打造学术论文中的亮点与互动 引言 学术论文是学术界交流思想、探讨问题和展示研究成果的重要形式。如何使学术论文在众多作品中脱颖而出,吸引读者的眼球并激发互动,是每位研究者都关注的问题。本文将介绍如何借助ChatGPT这一…...
)
逐步学习Go-sync.Mutex(详解与实战)
概述 Go中提供了互斥锁:sync.Mutex。sync.Mutex提供了以下方法: type Mutex // 加锁。如果已经有goroutine持有了锁,那么就阻塞等待直到持有锁 func (m *Mutex) Lock()// 尝试加锁。如果加锁成功就返回true,否则返回失败 func (m…...
)
每日三道面试题之 Java并发编程 (一)
1.为什么要使用并发编程 并发编程是一种允许多个操作同时进行的编程技术,这种技术在现代软件开发中非常重要,原因如下: 充分利用多核处理器:现代计算机通常都拥有多核处理器,通过并发编程,可以让每个核心独…...

车身稳定控制系统原理是什么?
车身稳定控制系统(Electronic Stability Control,ESC)是一种先进的车辆动态控制系统,其主要原理是通过传感器监测车辆的各项状态,包括车速、转向角度、侧倾角等,然后通过电子控制单元(ECU&#…...

vue3前端加载动画 lottie-web 的简单使用案例
什么是 Lottie Lottie 是 Airbnb 发布的一款开源动画库,它适用于 Android、iOS、Web 和 Windows 的库。 它提供了一套从设计师使用 AE(Adobe After Effects)到各端开发者实现动画的工具流。 UED 提供动画 json 文件即可, 开发者就…...
基于java+springboot+vue实现的健身房管理系统(文末源码+Lw)23-223
摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装健身房管理系统软件来发挥其高效地信息处理的作用…...

告别时序噩梦:Vivado的report_qor_suggestions从导出RQS到导入生效全流程避坑指南
告别时序噩梦:Vivado的report_qor_suggestions从导出RQS到导入生效全流程避坑指南 在FPGA设计流程中,时序收敛问题往往成为工程师的"最后一公里"难题。当设计复杂度达到一定规模时,传统的手动优化方式不仅效率低下,还可…...

Linux用户的终极翻译助手:3种智能翻译方式完全指南
Linux用户的终极翻译助手:3种智能翻译方式完全指南 【免费下载链接】CuteTranslation Linux屏幕取词翻译软件 项目地址: https://gitcode.com/gh_mirrors/cu/CuteTranslation 你是否曾在Linux系统中阅读英文文档时频繁切换浏览器查词?是否因为图片…...
)
Arcgis新手必看:用‘焦点统计’和‘设为空函数’搞定栅格数据清洗(附避坑要点)
ArcGIS栅格数据清洗实战:焦点统计与设为空函数的高效应用指南 当你第一次拿到一份满是噪点的DEM数据或存在异常值的土地利用分类图时,那种手足无措的感觉我深有体会。栅格数据清洗是GIS分析中看似简单却暗藏玄机的关键步骤,一个不当的参数设置…...

2026年阿里云OpenClaw/Hermes Agent配置Token Plan集成步骤解析
2026年阿里云OpenClaw/Hermes Agent配置Token Plan集成步骤解析。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

如何用BilibiliDown轻松搞定B站视频下载:新手到高手的完整指南
如何用BilibiliDown轻松搞定B站视频下载:新手到高手的完整指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_m…...

LPA分层审核指标是什么?读懂LPA分层审核指标才能评估审核有效性
在工厂的质量管理体系运行中,LPA(分层过程审核)是确保标准作业落地、问题及时发现和整改的有力工具。但很多企业推行LPA后,仅仅关注有没有做审核,却忽略了审核做得怎么样。结果,审核表填了一大摞࿰…...

2026 免费在线照片换背景底色怎么做?详细操作方法 + 工具实测
想要快速改变照片背景底色却不知道怎么操作?本文为你盘点了最实用的免费在线照片换背景底色工具,涵盖详细的操作步骤和使用场景,让你轻松搞定各类背景处理需求。为什么需要在线换背景底色?在日常生活中,很多时候我们拍…...
)
别再手动复制粘贴了!C++20 assign函数让你的容器操作效率翻倍(附vector/deque实战代码)
C20 assign函数:告别低效循环,解锁现代容器操作新范式 在C日常开发中,容器操作占据了大量编码时间。你是否还在为以下场景烦恼:需要将一个vector的部分元素复制到另一个容器时,不得不写冗长的循环;当要重置…...
)
告别HAL库:用GD32标准库为RT-Thread打造轻量级驱动(以F4系列为例)
告别HAL库:用GD32标准库为RT-Thread打造轻量级驱动(以F4系列为例) 在嵌入式开发领域,HAL库因其跨平台兼容性和易用性广受欢迎,但对于追求极致性能和精简代码的开发者而言,标准库往往能带来更直接的硬件控制…...

如何永久免费使用IDM下载管理器:无需破解的智能重置方案
如何永久免费使用IDM下载管理器:无需破解的智能重置方案 【免费下载链接】idm-trial-reset Use IDM forever without cracking 项目地址: https://gitcode.com/gh_mirrors/id/idm-trial-reset 想要永久免费使用Internet Download Manager这款强大的下载加速工…...