流式密集视频字幕
流式密集视频字幕
- 摘要
- 1 Introduction
- Related Work
- 3 Streaming Dense Video Captioning
Streaming Dense Video Captioning
摘要
对于一个密集视频字幕生成模型,预测在视频中时间上定位的字幕,理想情况下应该能够处理长的输入视频,预测丰富、详细的文本描述,并且在处理完整个视频之前能够生成输出。
然而,目前最先进的模型仅处理固定数量的降采样帧,并且在看完整个视频后做出一次完整的预测。
我们提出了一种流式密集视频字幕生成模型,该模型包含两个创新组件:首先,我们提出了一种新的记忆模块,基于对传入令牌的聚类,该模块能够处理任意长度的视频,因为记忆的大小是固定的。
其次,我们开发了一种流式解码算法,使我们的模型能够在处理完整个视频之前做出预测。 我们的模型实现了这种流式处理能力,并在三个密集视频字幕生成基准测试中显著提高了最先进水平:ActivityNet、YouCook2和ViTT。我们的代码发布在https://github.com/google-research/scenic。
1 Introduction
在现代社会的方方面面,视频迅速成为传输信息最普遍的媒体格式之一。大多数为视频理解设计的计算机视觉模型仅处理少量帧,通常只覆盖几秒钟的时间范围[31, 33, 39, 49, 58],且通常限于将这些短片段分类到固定数量的概念中。
为了实现全面、细粒度的视频理解,我们研究了一种密集视频字幕生成任务——在视频中对事件进行时间上的定位并为之生成字幕。这一目标理想的模型应当能够处理长的输入序列——以推理长时间、未修剪的视频——并且能够处理文本空间中的长输出序列,详细描述视频中的所有事件。
先前的密集视频字幕生成工作并未处理长输入或长输出。对于任何长度的视频,现有最先进模型要么以大步长(例如,6帧[48])采样极少数帧[11, 30, 48](即时间下采样),要么对所有帧保持每帧一个特征[51, 59, 65](即空间下采样)。在长文本输出方面,当前模型完全依赖自回归解码[19]在最后生成多个句子。
在这项工作中,我们设计了一个如图1所示的密集视频字幕生成的“流式”模型。我们的流式模型由于拥有记忆机制,不需要同时访问所有输入帧就能处理视频。此外,我们的模型可以在不处理整个输入序列的情况下因果性地产生输出,这得益于一种新的流式解码算法。像我们的这类流式模型本质上适合处理长视频——因为它们一次只摄取一帧。而且,由于输出是流式的,因此在处理完整视频之前就会产生中间预测。这一特性意味着流式模型理论上可以应用于处理实时视频流,正如视频会议、安全和持续监控等应用所需。
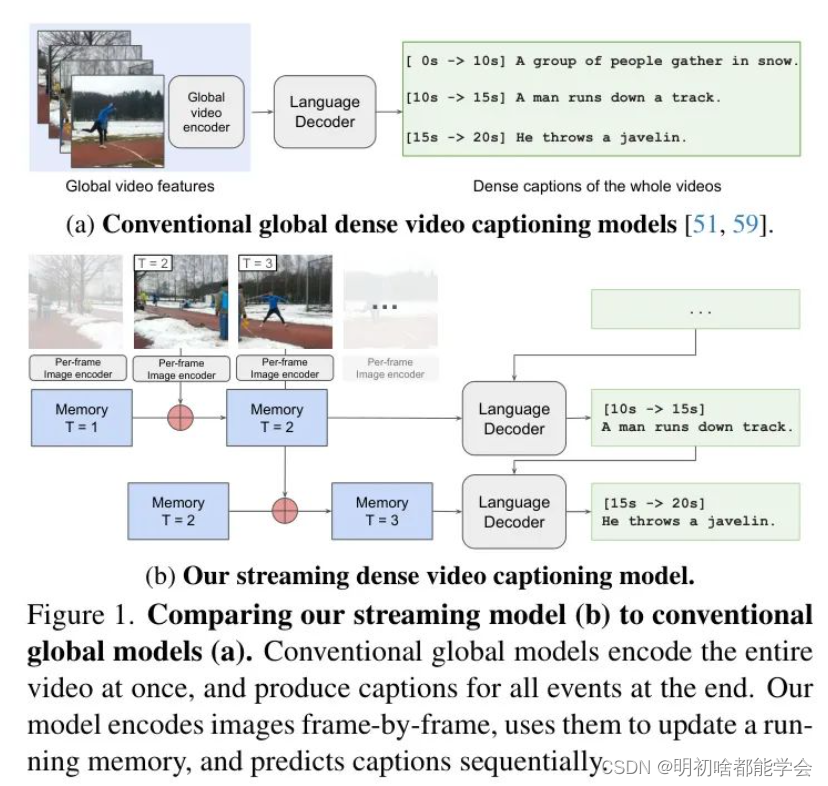
图1:将我们的流式模型(b)与传统的全局模型(a)进行比较。传统的全局模型一次编码整个视频,并在最后为所有事件产生字幕。我们的模型逐帧编码图像,使用它们更新运行中的记忆,并顺序预测字幕。
我们首先提出了一个新颖的记忆机制,一次接收一帧。记忆模型基于K-means聚类,并使用固定数量的簇中心标记在每个时间戳上表示视频。我们展示了这种方法简单而有效,可以处理可变数量的帧,并且在解码时具有固定的计算预算。
为了开发我们的流式模型,我们还提出了一种流式解码算法,并训练我们的网络,使其在特定时间戳的“解码点”(图2)上,根据该时间戳的记忆特征预测在此之前结束的所有事件字幕。因此,我们的网络被训练成在任何视频时间戳上做出预测,而不仅仅是视频结束处,如传统非流式模型那样。此外,我们将早期解码点的预测作为后来解码点的上下文。这一上下文避免了预测重复的事件,并可以作为自然语言总结早期视频的“显式”记忆。我们的流式输出还源于这样一个事实:随着视频长度的增长,我们的记忆将不可避免地在时间上失去信息,因为其大小是有限的。我们通过在处理整个视频之前进行预测来避免这个问题,并通过语言上下文保持早期信息。

图2:我们的框架说明。 每个帧一次通过图像编码器。基于聚类的记忆模型从开始到当前帧维持压缩的视觉特征。
在特定的帧上,即“解码点”,我们从记忆中解码出字幕和时间戳。如果有的话,早期的文本预测也会作为后续解码
点的语言解码器的前缀传递。我们的模型可以运行在任意长度的视频上,因为记忆具有恒定的大小,还可以在处
理整个视频之前输出预测。
我们在三个流行的密集视频字幕生成数据集上评估了我们的方法:ActivityNet[29]、YouCook2[64]和ViTT[23]。我们的结果显示,与不可避免地使用更少的帧或特征的最先进技术相比,我们的流式模型显著提高了性能,最多提高了11.0 CIDEr点。我们证明了我们的方法在GIT[48]和Vid2Seq[59]架构上具有泛化能力。最后,我们提出的记忆机制也可以应用于段落字幕生成,将基线提高了1-5 CIDEr点。
Related Work
密集视频字幕生成。 密集视频字幕生成需要标注事件,并在时间上对其进行定位。传统上,先前的研究采用两阶段方法,首先在视频中定位事件,然后随后对其进行字幕生成[24, 25, 29, 47, 50]。更近期的端到端方法包括PDVC [66],它使用类似DETR [10]的模型来推断事件字幕和时间戳。Vid2Seq [59]用时间戳标记扩展了语言模型的词汇,使它们能够像常规字幕生成模型一样生成连接的事件字幕。我们也使用了[59]的输出表述,因为它与基础视觉-语言模型[48]整合得很好。一个相关但不同的问题是电影中的音频描述[20, 21, 43],这需要为视障人士生成必须补充对话的字幕,并且经常使用辅助的非因果模型来识别角色或他们的对话[21]。
据我们所知,所有先前的密集字幕生成模型都不是因果模型,因为它们一次编码整个视频。此外,为了处理长视频,它们通常使用经过大幅下采样的视觉特征(通过选择几帧[11, 30, 48],或者每帧进行空间池化特征[51, 59, 65])。相比之下,我们以流式方式处理视频,用一个记忆模块一次处理一个帧的长输入序列,并使用一种新颖的解码算法流输出句子。
长视频的模型。 处理较长视频的常见方式是使用记忆机制来提供过去事件的紧凑表示。使用变压器,记忆可以通过将过去观察的标记作为当前时间步的输入来实现[13, 36, 56]。在视觉中的例子包括[22, 35, 53, 54],它们离线预提取特征并在推理时检索它们,因此不是因果模型。MemViT [55]使用前一时间步的标记激活作为当前时间步的输入。然而,这意味着序列长度会随时间增长,因此它无法处理任意长的视频。将记忆视为将先前观察到的标记压缩成较小、固定大小的集合以在未来的时间步使用的另一种观点。Token Turing Machines [41]使用[40]的标记总结模块总结过去和当前的观察。MovieChat [44]遵循类似的想法,但使用Token Merging [5]的一个变体来进行总结。TeSTra [62]使用指数移动平均来整合视频特征。这种方法的优点是记忆库具有固定大小,因此无论视频的长度如何,计算成本都保持有限。我们的记忆模型具有这一同样理想的属性。然而,我们的记忆基于聚类,使用类似K-means算法的中心来总结每个时间步的标记,我们通过实验证明这优于其他选择。
视频中的因果模型。 我们的流式模型是因果模型,这意味着其输出仅依赖于当前和过去的帧,没有访问未来帧。尽管我们不知道先前的因果模型用于密集视频字幕生成,但在许多其他视觉领域中有因果模型。在线动作检测[14, 28, 62, 63]旨在在实时视频中预测动作标签,不访问未来帧。类似地,在线时间动作定位[7, 26, 42]模型在观察动作后也预测动作的开始和结束时间。大多数对象跟踪[3, 52]和视频对象/实例分割[9, 32, 34]的模型也是因果模型。
上述任务的一个共同主题是模型必须对视频的每个帧进行预测。相比之下,我们专注于密集视频字幕生成[29],这是具有挑战性的,因为输出字幕与视频帧不是一一对应的。我们通过提出一种流式解码算法来解决这一问题。
3 Streaming Dense Video Captioning
标题生成模型通常由一个视觉编码器和一个文本解码器组成。我们概述了这些方法,并展示了它们如何扩展到密集标题生成。
视觉编码器。 第一步是将视频编码为特征 ,其中 是特征分辨率(对于基于变换器的编码器,这是令牌的数量), 是特征维度。视觉特征编码器 可以是一个原生的视频骨干网络[1, 4],或者是一个应用于每一帧的图像编码器[37, 60]。在后一种情况下,视频特征是图像特征的堆叠,,其中 是每帧的令牌数。我们使用逐帧编码,但不是从整个视频中预先提取它们,而是使用一个记忆机制以因果、流式的方式处理特征(第3.2节),这种方式可以推广到更长的视频时长。
文本解码器。 给定视觉特征 和可选的文本前缀令牌 ,文本解码器 从它们生成一系列单词令牌 。我们使用自回归[19, 45]解码器,它根据之前的单词 和(如果有的话)前缀生成下一个单词令牌 ,即 。注意,在标题生成任务中通常不使用前缀令牌,但在问题回答(QA)任务中使用它们来编码输入问题。具体来说,文本解码器 是一系列在视觉特征 和前缀的词嵌入[38, 48]的连接上操作的变换层[45]。这种架构在图像和视频的标题生成和QA任务中都被证明是有效的[11, 30, 48]。
带时间戳的密集视频标题生成。 结合上述视觉编码器和文本解码器,为视频标题生成提供了一个基本架构。为了将其扩展为带有开始和结束时间戳的多个事件的标题生成,Vid2Seq[59]引入了两项主要修改:首先,它扩展了标题生成模型的词汇表 ,加入了时间令牌 和 ,分别代表开始和结束时间。因此,一个单独的事件表示为 ,且 ,其中 ∣ V ∣ ≤ w s < w e ≤ ∣ v ′ ∣ |V|\leq w^{s}<w^{e}\leq|v^{\prime}| ∣V∣≤ws<we≤∣v′∣, ∣ t ∣ |t| ∣t∣ 是时间令牌的数量。其次,vid2seq按开始时间顺序将所有定时标题连接成一个长的标题: c = " [ c 1 ′ , c 2 ′ , ⋯ , c " n e ′ ] \mathbf{c}="[\mathbf{c}^{\prime}_{1},\mathbf{c}^{\prime}_{2},\cdots,\mathbf{c}" ^{\prime}_{n_{e}}] c="[c1′,c2′,⋯,c"ne′],其中=“” n e n_{e} ne=“” 是事件的数量。因此,密集视频标题生成可以形式化为具有目标=“” c \mathbf{c} c=“” 的标准视频标题生成。<=“” p=“”>
尽管Vid2Seq[59](广义)架构很有效,但它有几个关键局限性:首先,它将整个视频的视觉特征 通过解码器,这意味着它不能有效地扩展到更长的视频和更多的令牌。此外,由于Vid2Seq在处理整个视频后一次预测所有事件标题,它在预测长而详细标题方面存在困难。为了解决这些问题,我们引入了流式密集视频标题生成模型,我们使用一个记忆模块一次处理一个输入,以限制计算成本,并流式输出,这样我们可以在处理整个视频之前做出预测。
相关文章:
流式密集视频字幕
流式密集视频字幕 摘要1 IntroductionRelated Work3 Streaming Dense Video Captioning Streaming Dense Video Captioning 摘要 对于一个密集视频字幕生成模型,预测在视频中时间上定位的字幕,理想情况下应该能够处理长的输入视频,预测丰富、…...
【教程】iOS Swift应用加固
🔒 保护您的iOS应用免受恶意攻击!在本篇博客中,我们将介绍如何使用HTTPCORE DES加密来加固您的应用程序,并优化其安全性。通过以下步骤,您可以确保您的应用在运行过程中不会遭受数据泄露和未授权访问的风险。 摘要 …...
)
新型基础设施建设(新基建)
新型基础设施建设(新基建)主要包括七个方面,即5G基站建设、特高压、城际高速铁路和城市轨道交通、新能源汽车充电桩、大数据中心、人工智能和工业互联网。 以下是新型基础设施的详细内容: 一、5G基站建设。5G网络的扩展和优化&a…...

蓝桥杯 第 9 场 小白入门赛 字符迁移
题目: 3.字符迁移【算法赛】 - 蓝桥云课 (lanqiao.cn) 思路: 此题通过把小写字母映射成数字,进行差分即可。 AC代码: #include<iostream> #include<cstring> #include<algorithm>using namespace std;typed…...

泰迪智能科技人工智能应用工程师(中级)特训营
随着人工智能技术的迅猛发展和应用的不断拓展,掌握人工智能技术已成为现代职业发展和企业创新的关键。为此,人工智能技能提升特训营应运而生,以全面、系统的课程设置,帮助学员深入掌握相关的理论知识,实践操作技能。特…...
【数据结构】考研真题攻克与重点知识点剖析 - 第 6 篇:图
前言 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图与王道考研课程,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术…...

java的基本数据类型
在Java编程语言中,基本数据类型是构成Java程序的基础元素,它们用于存储简单值。Java的基本数据类型可以分为两大类:原始类型(Primitive Types)和引用类型(Reference Types)。原始类型包括整型、…...

0104练习与思考题-算法基础-算法导论第三版
2.3-1 归并示意图 问题:使用图2-4作为模型,说明归并排序再数组 A ( 3 , 41 , 52 , 26 , 38 , 57 , 9 , 49 ) A(3,41,52,26,38,57,9,49) A(3,41,52,26,38,57,9,49)上的操作。图示: tips::有不少在线算法可视化工具(软…...
烤羊肉串引来的思考--命令模式
1.1 吃羊肉串! 烧烤摊旁边等着拿肉串的人七嘴八舌地叫开了。场面有些混乱,由于人实在太多,烤羊肉串的老板已经分不清谁是谁,造成分发错误,收钱错误,烤肉质量不过关等。 外面打游击烤羊肉串和这种开门店做烤…...

Python 描述符
文章目录 类型:数据描述符:方法描述符:描述符的要包括以下几点:方法描述符实现缓存 描述符(Descriptor)是 Python 中一个非常强大的特性,它允许我们自定义属性的访问行为。使用描述符,我们可以创建一些特殊的属性,在访问这些属性时执行自定义…...

Go语言创建HTTP服务器
Web服务器可提供网页、Web服务和文件,而Go语言为创建Web服务器提供了强大的支持。 1.通过Hello World Web 服务器宣告您的存在 标准库中的net/http包提供了多种创建HTTP服务器的方法,它还提供了一个基本的路由器。 package mainimport ("net/http" )func helloWo…...

【LeetCode热题100】【栈】柱状图中最大的矩形
题目链接:84. 柱状图中最大的矩形 - 力扣(LeetCode) 要找最大的矩形就是要找以每根柱子为高度往两边延申的边界,要作为柱子的边界就必须高度不能低于该柱子,否则矩形无法同高,也就是需要找出以每根柱子为高…...
谷歌浏览器插件开发速成指南:弹窗
诸神缄默不语-个人CSDN博文目录 本文介绍谷歌浏览器插件开发的入门教程,阅读完本文后应该就能开发一个简单的“hello world”插件,效果是出现写有“Hello Extensions”的弹窗。 作为系列文章的第一篇,本文还希望读者阅读后能够简要了解在此基…...

Lakehouse 大数据概念
“Lakehouse” 是一个相对新的概念,是大数据理论中的一个重要发展方向。它试图结合传统的数据湖(Data Lake)和数据仓库(Data Warehouse)的优点,以创造一种更为灵活和强大的数据管理体系。 在传统的大数据架构中,数据湖用于存储原始、未加工的数据,而数据仓库则用于存储…...
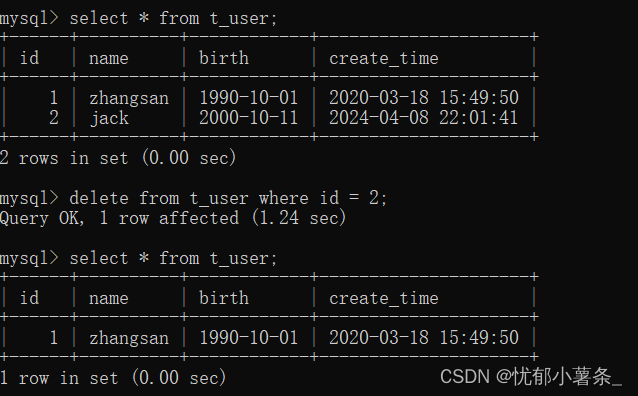
MySQL学习笔记(二)
1、把查询结果中去除重复记录 2、连接查询 从一张表中单独查询,称为单表查询。emp表和dept表联合起来查询数据,从emp表中取员工名字,从dept表中取部门名字,这种跨表查询,多张表联合起来查询数据,被称为连…...

Verilog语法——按位取反“~“和位宽扩展的优先级
前言 先说结论,如下图所示,在Verilog中“~ ”按位取反的优先级是最高的,但是在等式计算时,有时候会遇到位宽扩展,此时需要注意的是位宽扩展的优先级高于“~”。 验证 仿真代码,下面代码验证的是“~”按位取…...
Navicat工具使用
Navicat的本质: 在创立连接时提前拥有了数据库用户名和密码 双击数据库时,相当于建立了一个链接关系 点击运行时,远程执行命令,就像在xshell上操作Linux服务器一样,将图像化操作转换成SQL语句去后台执行 一、打开Navi…...
——mv、rm、which、find)
linux常用指令(一)——mv、rm、which、find
mv命令: 用于查看文件内容 语法:mv 参数1 参数2 参数1,linux路径,表示被移动的文件或文件夹 参数2,linux路径,表示要移动去的地方,如果目标不存在,则进行改名 rm命令:…...
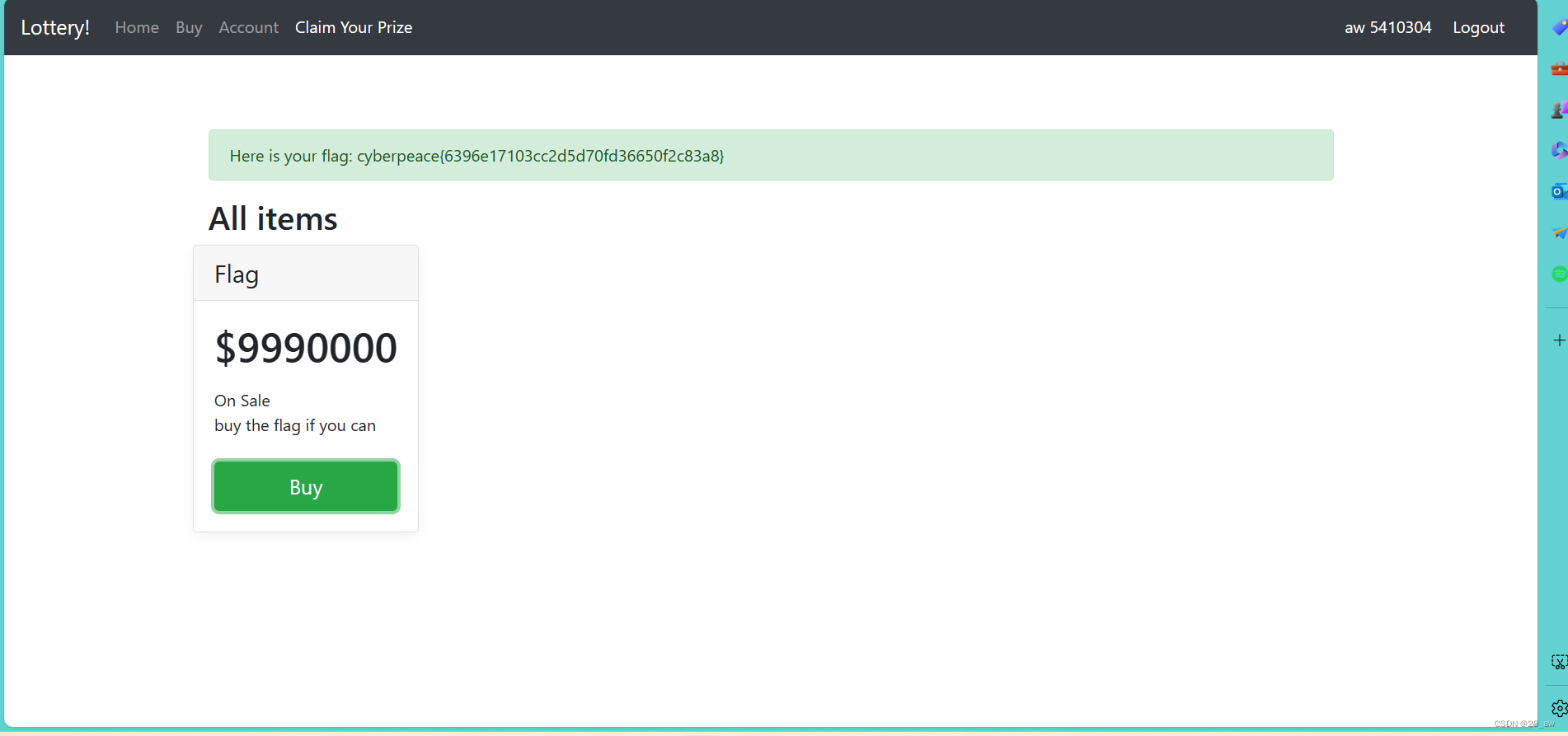
lottery-攻防世界
题目 flag在这里要用钱买,这是个赌博网站。注册个账号,然后输入七位数字,中奖会得到相应奖励。 githacker获取网站源码 ,但是找到了flag文件但是没用。 bp 抓包发现api.php,并且出现我们的输入数字。 根据题目给的附…...

深入理解指针2:数组名理解、一维数组传参本质、二级指针、指针数组和数组指针、函数中指针变量
目录 1、数组名理解 2、一维数组传参本质 3、二级指针 4、指针数组和数组指针 5、函数指针变量 1、数组名理解 首先来看一段代码: int main() {int arr[10] { 1,2,3,4,5,6,7,8,9,10 };printf("%d\n", sizeof(arr));return 0; } 输出的结果是&…...

机器人碰撞检测2:FCL库进阶实战与性能优化
1. 从基础到进阶:FCL库在机器人运动规划中的角色 第一次接触FCL库时,你可能已经体验过它强大的基础碰撞检测功能。但当机器人需要在一个充满动态障碍物的工厂环境中自主导航,或者机械臂要在密集货架上精准抓取物品时,简单的两两碰…...

终极免费macOS应用清理工具:让你的Mac告别数字垃圾
终极免费macOS应用清理工具:让你的Mac告别数字垃圾 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经遇到过这样的困扰:明明…...

告别虚拟机卡顿:在VMware 17上为RHEL 9.2分配CPU和内存的黄金法则
告别虚拟机卡顿:在VMware 17上为RHEL 9.2分配CPU和内存的黄金法则 当你在VMware Workstation 17上运行RHEL 9.2时,是否经常遇到编译速度慢、桌面响应延迟甚至整个系统卡死的情况?这很可能是因为你没有根据宿主机的实际硬件情况科学分配虚拟资…...

开发者效率工具集claw:从Unix哲学到现代开发工作流集成
1. 项目概述:一个为开发者打造的“瑞士军刀”式工具集最近在GitHub上闲逛,发现了一个名为opsyhq/claw的项目,它的名字和图标(一个爪子)一下子就抓住了我的眼球。点进去一看,简介很简单:“A coll…...

终极指南:使用EdgeRemover专业卸载工具彻底移除Microsoft Edge浏览器
终极指南:使用EdgeRemover专业卸载工具彻底移除Microsoft Edge浏览器 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRem…...

从零构建AI智能体:核心架构、ReAct模式与实战指南
1. 项目概述:从零构建AI智能体的核心价值最近在GitHub上看到一个挺有意思的项目,叫pguso/ai-agents-from-scratch。光看名字,很多朋友可能就心动了——“从零开始构建AI智能体”,听起来就像是把那些神秘的大模型应用开发黑盒给彻底…...

APK Installer终极指南:在Windows电脑上快速安装Android应用的完整方案
APK Installer终极指南:在Windows电脑上快速安装Android应用的完整方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了在电脑和手机之间来回传…...

终极无边框游戏窗口指南:三步实现无缝多任务体验
终极无边框游戏窗口指南:三步实现无缝多任务体验 【免费下载链接】Borderless-Gaming Play your favorite games in a borderless window; no more time consuming alt-tabs. 项目地址: https://gitcode.com/gh_mirrors/bo/Borderless-Gaming 你是否厌倦了在…...

基于电阻分压网络的传感器复用与蓝牙报警系统设计
1. 项目概述 在物联网和智能家居领域,报警系统是一个经典且实用的入门项目。它不仅是学习嵌入式开发的绝佳起点,更能直接解决现实生活中的安防需求。市面上成熟的商业报警系统往往价格不菲且功能固化,而基于开源硬件和软件的自制方案…...

Bootstrap5 侧边栏导航
Bootstrap5 侧边栏导航 随着Web技术的发展,用户界面(UI)设计越来越受到重视。Bootstrap作为一个流行的前端框架,它为开发者提供了丰富的组件和工具,以快速构建响应式、移动优先的网站和应用程序。在Bootstrap 5中,侧边栏导航是一个重要的组件,它可以帮助用户在网站或应…...