时间系列预测总结
转载自:https://mp.weixin.qq.com/s/B1eh4IcHTnEdv2y0l4MCog
拥有一种可靠的方法来预测和预测未来事件一直是人类的愿望。在数字时代,我们拥有丰富的信息,尤其是时间序列数据。
时间序列是指基于时间刻度维度(天、月、年等)采样和组织的任何数据。预测它将提供有价值的见解,帮助我们做出明智的决策并制定业务战略。时序数据示例包括:
金融市场:股票价格、汇率和交易量。
气候和天气:温度、降雨量和风速。
销售和需求预测:一段时间内的产品销售数据。
网站流量和用户行为:页面浏览量、点击率和转化率。
能源消耗:用电量和能源需求。
传感器数据:来自制造业、医疗保健和运输业传感器的测量值。
社交媒体活动:点赞、评论、分享和关注者数量。
这些示例展示了时间序列数据在业务数据分析的战略领域(如金融、天气、销售、在线分析、能源管理、传感器监控和社交媒体分析)中的多样性。掌握这些领域中每个领域的时间序列机器学习 (ML) 可以在事件预测和有效管理影响趋势、模式和其他波动的因素方面产生显着的好处。
在本文中,我们将踏上使用机器学习技术掌握时间序列分析和预测的旅程。
时序数据中的自动分析和预测:特点和挑战
随着机器学习预测的出现,我们现在拥有强大的工具来分析和发现时间序列数据中的模式。这使我们能够做出准确的预测和预测。让我们了解一下时间序列数据的组成:
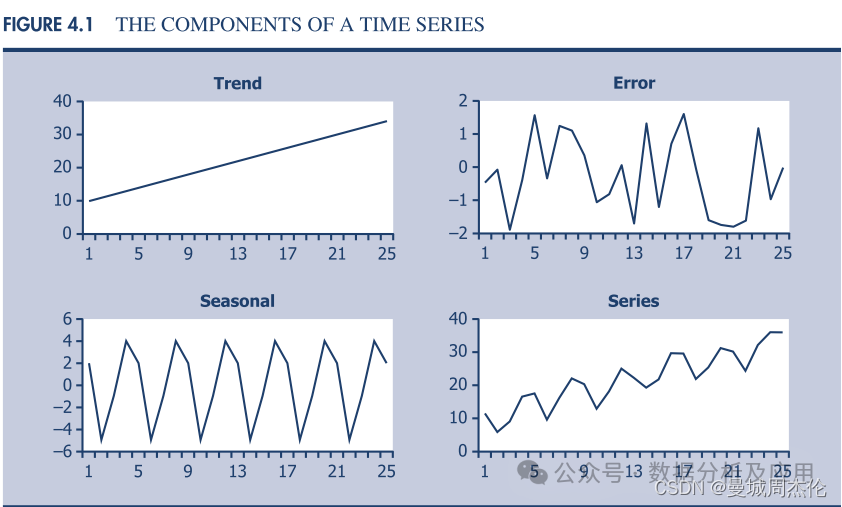
趋势。在时间序列数据理论中,趋势是指值随时间变化的行为。它可以是正的(表示上升趋势)或负的(表示下降趋势)。
季节性。季节性是时间序列数据的一个特征,它以固定的时间间隔显示重复出现的模式。这些模式以恒定的频率重复。
残差。从数据中提取趋势和季节性分量后,剩余部分称为剩余部分或残差。这表示数据中不符合趋势或季节性模式的部分。对这个余数的分析有助于检测时间序列中的异常或意外波动。
周期。当时间序列显示没有固定周期或季节性的重复模式或波动时,它被称为周期性行为。与季节性不同,这些周期不遵循特定且可预测的频率。它们可能是由于外部因素或潜在模式而发生的,而这些因素或潜在模式不容易被趋势或季节性成分捕捉到。
平稳性。当时间序列的统计属性随时间变化保持不变时,它被认为是静止的。这意味着数据的均值、标准差和协方差不会随时间而变化。稳态时间序列更容易分析和建模,因为它们的行为保持一致。
与静态数据分析相比,时间序列数据分析遵循不同的框架。如上一节所述,对时间序列数据的分析首先要解决一些基本问题,例如:
数据是否呈现趋势?
数据中是否存在可识别的模式或季节性?
数据的特征是静止的还是非静止的?
时间序列分析中的关键问题包括识别趋势、模式/季节性和确定平稳性。在静态数据分析中,描述性分析、预测性分析和规范性分析等过程很常见。这些过程适用于时间序列和静态机器学习应用程序。但是,某些指标(例如相关性)在描述性、预测性和规范性框架中的使用方式不同。顺便说一句,这两种类型的数据都可以在自动化ML的帮助下进行处理。
时间序列数据的结构是独一无二的,对分析和预测提出了特定的挑战:
与静态数据不同,时间序列数据本质上是动态的,并且具有基于时间维度的固有顺序。
时间方面增加了复杂性,因为序列中的值取决于过去的观测值,并表现出趋势、季节性和不规则性。
在时间序列数据的上下文中,缺失值表现为时间序列中的间隙。这些差距表示数据观测缺失或不完整的时期。
如图所示,数据中可能存在明显的差距,这些差距无法通过通常用于静态数据的标准插补策略进行逻辑填充。这些差距在数据集中以明显的空白形式存在,对处理缺失值的传统方法提出了挑战。
为了有效地分析时间序列数据,了解其组成部分(如趋势和季节性)至关重要。此外,时间序列数据可能会表现出不规则的波动和噪声,需要在分析过程中加以考虑。
时间序列算法:优点和缺点
机器学习时间序列算法提供了强大的工具来释放时间序列数据的潜力。这些机制使时间序列分析和预测成为可能,每种机制都有其优点和局限性。了解这些有助于为手头的任务选择正确的算法。让我们探讨一些流行的算法及其优缺点:
ARIMA(自回归综合移动平均线)
ARIMA是一种功能强大的算法,广泛用于时间序列分析。它结合了三个主要组件:
自回归 (AR)
移动平均线 (MA)
时间序列差异。
自回归捕获观测值与一定数量的滞后观测值之间的线性关系。移动平均分量考虑过去预测误差的加权平均值。差分量通过取连续观测值之间的差值来帮助将非平稳数据转换为平稳数据。通过组合这些组件,ARIMA 可以有效地捕获时间序列数据中的趋势、季节性和噪声。
让我们考虑一个银行和金融数据预测的例子。要使用 ARIMA 模型预测公司的股价,首先要获取过去十年的公开股价数据。获得此数据后,可以继续训练 ARIMA 模型。为了确定 ARIMA 模型的适当参数,您需要分析数据中的趋势。这涉及选择使数据平稳所需的时间序列差分 (d) 的顺序。通过检查自相关和偏自相关,您可以确定模型的回归顺序 (p) 和移动平均线顺序 (q)。
要选择最拟合的模型,您可以使用各种性能指标,例如 Akaike 信息准则 (AIC)、贝叶斯信息准则 (BIC)、最大似然率和标准误差。这些指标有助于评估模型的拟合优度,并确保它捕获股票价格数据中的重要特征和模式。通过系统地分析数据并选择最佳参数,ARIMA模型可以提供有关公司股价的宝贵见解和预测。这种方法允许您利用历史趋势和模式在金融领域做出明智的决策和预测。
结论:ARIMA具有简单性和可解释性,适用于短期预测,适用于稳态数据。但是,它可能会遇到复杂的模式和长期依赖关系。
LSTM(长短期记忆)
LSTM 是一种递归神经网络 (RNN),擅长对序列和时间依赖性进行建模。与传统的前馈神经网络不同,LSTM网络具有独特的记忆单元结构,使它们能够在更长的时间段内保留和利用信息。这使得 LSTM 在捕获时间序列数据中的长期依赖关系方面特别有效。LSTM 模型可以学习数据中的复杂模式和关系,使其适用于以下领域的深度学习时间序列:
语音识别
自然语言处理
股市预测。
该网络能够选择性地忘记或记住信息,使其能够处理非平稳时间序列数据并捕获不同时间尺度的时间依赖关系。
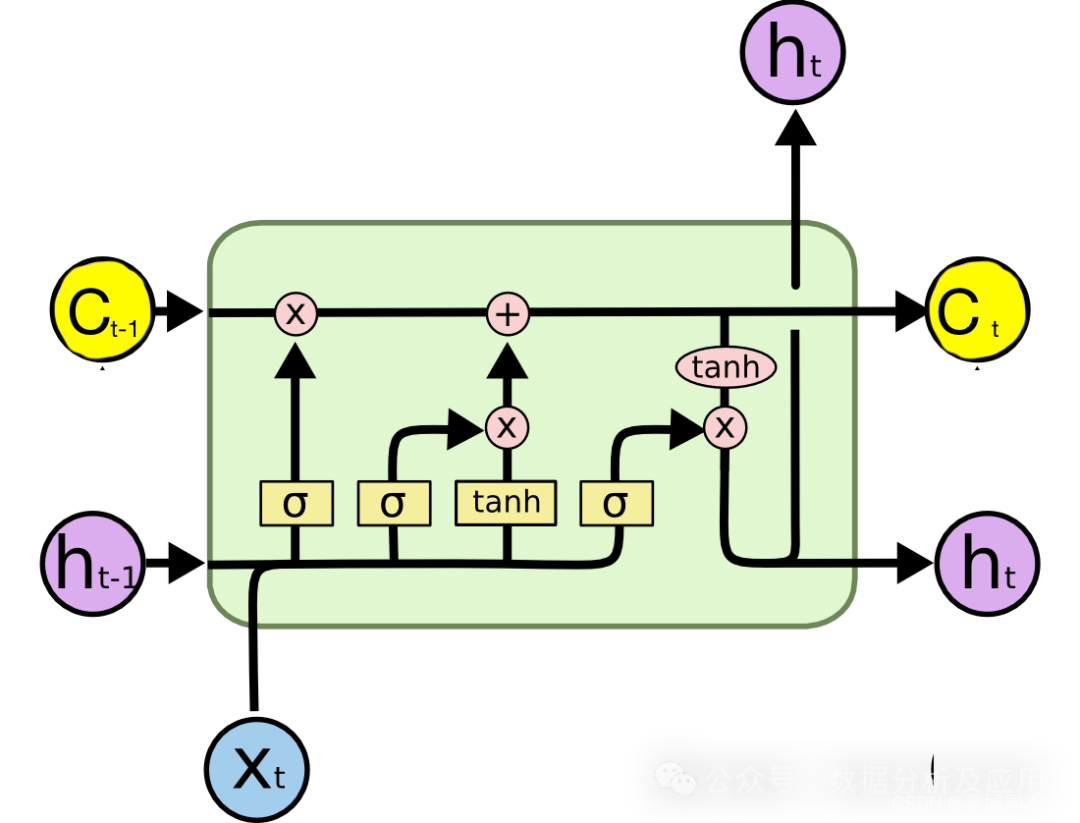
结论:LSTM 在处理非线性模式和长期依赖关系时大放异彩。它从历史数据中学习的能力使其成为一个强大的选择。然而,它需要更多的计算资源和更大的数据集进行训练。
Prophet
Prophet 由 Facebook 开发,是一款专为时间序列预测而设计的强大算法。它利用加法模型来捕获非线性趋势、年度、每周和每日季节性以及假日效应。当应用于具有突出季节性模式和大量历史记录的时间序列数据时,它的表现非常出色。Prophet铂慧的显著优势之一是能够处理缺失数据并适应趋势的变化,同时在处理异常值方面也表现出鲁棒性。
事实证明,Prophet对于具有以下特征的数据集特别有价值:
涵盖跨越数月或数年的重大时间跨度,以每小时、每天或每周的频率捕获细粒度和详细的历史观测结果。
显示同时发生的多个突出的季节性模式。
纳入事先已知的重大不规则事件。
包含缺失的数据点或值得注意的异常值。
展示接近饱和点的非线性增长趋势。
增长函数用作捕获数据潜在趋势的模型。这个概念与那些具有基本数学知识的人通常知道的熟悉的线性和逻辑函数相一致。然而,Facebook Prophet引入了一个新概念,它允许增长趋势灵活地适应数据中的特定点,称为“变化点”。变化点表示数据中发生明显方向偏移的时刻。
这些点标志着增长模式发生变化的转变,使Prophet铂慧能够有效地捕捉和适应趋势随时间的变化。Prophet作为加法回归模型运行,包含分段线性或逻辑增长曲线趋势。它包含使用傅里叶级数建模的年度季节性分量和使用虚拟变量建模的每周季节性分量。通过利用这些功能,Prophet铂慧可以有效地捕捉上述数据集特征中固有的复杂性。
结论:Prophet专注于业务预测,能够有效地处理季节性和假日效应。但是,它可能无法捕获复杂的交互,并且可能需要仔细的特征工程。
时间序列预测的实用技巧
要利用时间序列机器学习的强大功能进行预测,有以下实用技巧:
-
预处理数据
清理数据、处理缺失值并解决异常值。如果需要,应用归一化或差分等技术来实现平稳性。 -
时间序列特征工程
提取有意义的特征,以捕获数据中的基础模式。考虑滞后变量、滚动统计量或傅里叶变换来捕捉季节性。 -
选择合适的模型
深入了解各种算法的功能和约束,并仔细选择最适合您独特时间序列的算法。在可解释性和复杂性之间取得平衡,以找到最佳解决方案。 -
将训练和测试分开
将数据划分为不同的训练集和测试集,确保测试集代表看不见的未来数据。通过评估模型在测试集上的预测来评估模型的性能。 -
微调超参数
通过网格搜索或贝叶斯优化等技术优化所选算法的超参数。此迭代过程通过查找最佳设置组合来帮助优化模型的性能。 -
集成学习
通过结合多个模型的预测来提高准确性并减少偏差。Ensembling 利用各个模型的优势来创建更强大、更可靠的预测解决方案。
时间序列预测的应用
-
能耗预测
时间序列深度学习模型可以预测能源消耗模式,使能源供应商能够根据预期天气、季节、人口变化等众多因素优化其供需管理、降低成本并提高可持续性。 -
股票市场预测
交易者和投资者可以利用深度学习时间序列算法的强大功能来分析复杂的股票市场数据,准确预测趋势,发现盈利交易的潜在机会,并有效管理风险。通过利用循环神经网络和长短期记忆模型等先进技术,这些算法可以捕获市场中复杂的模式和依赖关系,为做出明智的投资决策提供有价值的见解。 -
零售业需求预测
机器学习技术可用于分析历史销售数据并预测零售行业对各种产品的未来需求。这有助于零售商优化库存管理,确保产品可用性,并最大限度地减少积压或缺货,从而提高客户满意度和盈利能力。
不同场景中,数据建模基本上大同小异,如下简单示例使用LSTM进行预测时间序列:
import numpy as np
from keras.models import Sequential
from keras.layers import LSTM, Dense
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler # 假设你有一个名为 timeseries_data 的一维numpy数组,代表你的时间序列数据
# timeseries_data = np.array(...) # 预处理数据:标准化,并创建监督学习问题所需的输入和输出
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(timeseries_data.reshape(-1, 1)) # 创建一个监督学习问题,即使用过去的数据点来预测下一个数据点
def create_dataset(dataset, look_back=1): X, Y = [], [] for i in range(len(dataset)-look_back-1): a = dataset[i:(i+look_back), 0] X.append(a) Y.append(dataset[i + look_back, 0]) return np.array(X), np.array(Y) look_back = 3 # 假设我们使用过去3个时间点来预测下一个点
X, y = create_dataset(scaled_data, look_back) # 将数据划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 重塑输入数据,以适应LSTM的输入要求:[samples, time steps, features]
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1)) # 构建LSTM模型
model = Sequential()
model.add(LSTM(4, input_shape=(look_back, 1)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam') # 训练模型
model.fit(X_train, y_train, epochs=100, batch_size=1, verbose=2) # 预测
train_predict = model.predict(X_train)
test_predict = model.predict(X_test) # 反标准化预测结果
train_predict = scaler.inverse_transform(train_predict)
y_train = scaler.inverse_transform([y_train])
test_predict = scaler.inverse_transform(test_predict)
y_test = scaler.inverse_transform([y_test]) # 评估模型
train_score = np.sqrt(np.mean(((train_predict - y_train) ** 2))
print('Train Score: %.2f RMSE' % (train_score))
test_score = np.sqrt(np.mean(((test_predict - y_test) ** 2))
print('Test Score: %.2f RMSE' % (test_score))
结论
机器学习解锁了时间序列数据中隐藏的宝石。了解独特的挑战并选择合适的算法可以实现准确的预测。通过仔细的数据预处理、特征工程、模型选择和性能评估,我们利用机器学习的力量来战胜时间序列问题。
相关文章:
时间系列预测总结
转载自:https://mp.weixin.qq.com/s/B1eh4IcHTnEdv2y0l4MCog 拥有一种可靠的方法来预测和预测未来事件一直是人类的愿望。在数字时代,我们拥有丰富的信息,尤其是时间序列数据。 时间序列是指基于时间刻度维度(天、月、年等&…...

NineData创始人CEO叶正盛受邀参加『数据技术嘉年华』的技术大会
4月13日,NineData 创始人&CEO叶正盛受邀参加第13届『数据技术嘉年华』的技术大会。将和数据领域的技术爱好者一起相聚,并分享《NineData在10000公里跨云数据库间实时数据复制技术原理与实践》主题内容。 分享嘉宾 叶正盛,NineData CEO …...

nginx访问路径映射资源目录
Nginx映射资源目录是指在Nginx配置文件中设定规则,使得当客户端向Nginx服务器发送请求访问某个URL时,Nginx能够将该URL映射到服务器本地的实际文件目录,从而正确地提供该目录下的静态资源(如HTML、CSS、JavaScript、图片、视频等文…...

数据挖掘|序列模式挖掘及其算法的python实现
数据挖掘|序列模式挖掘及其算法的python实现 1. 序列模式挖掘2. 基本概念3. 序列模式挖掘实例4. 类Apriori算法(GSP算法)4.1 算法思想4.2 算法步骤4.3 基于Python的算法实现 1. 序列模式挖掘 序列(sequence)模式挖掘也称为序列分析。 序列模式发现&…...
3. Django 初探路由
3. 初探路由 一个完整的路由包含: 路由地址, 视图函数(或者视图类), 可选变量和路由命名. 本章讲述Django的路由编写规则与使用方法, 内容分为: 路由定义规则, 命名空间与路由命名, 路由的使用方式.3.1 路由定义规则 路由称为URL (Uniform Resource Locator, 统一资源定位符)…...
论文笔记:Large Language Models as Analogical Reasoners
iclr 2024 reviewer打分5558 1 intro 基于CoT prompt的大模型能够更好地解决复杂推理问题 然而传统CoT需要提供相关的例子作为指导,这就增加了人工标注的成本——>Zero-shot CoT避免了人工标注来引导推理 但是对于一些复杂的任务难以完成推理,例如c…...

第3章 数据定义语言DDL
文章目录 第3章 DDL语言:数据定义语言3.1 MySQL的数据类型3.2 表的创建:create3.3 表的删除:drop3.4 快速创建表3.5 快速删除表中的数据:truncate3.6 修改表结构:alter 第5章 约束5.1 非空约束:not null5.2…...
C#操作MySQL从入门到精通(7)——对查询数据进行简单过滤
前言 我们在查询数据库中数据的时候,有时候需要剔除一些我们不想要的数据,这时候就需要对数据进行过滤,比如学生信息中,我只需要年龄等于18的,类似这种操作,本文就是详细介绍如何对查询的数据进行初步的过滤。 1、等于操作符 本次查询student_age 等于20的数据,使用我…...
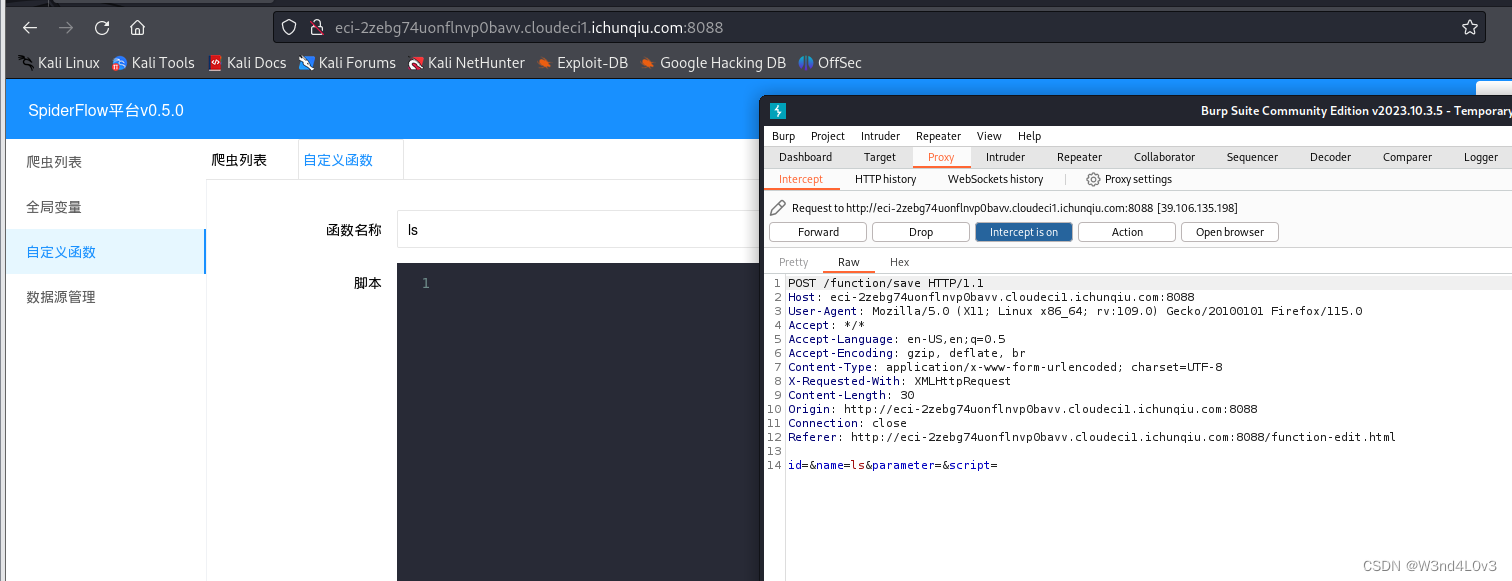
【CVE复现计划】CVE-2024-0195
CVE-2024-0195 简介: SpiderFlow是新一代开源爬虫平台,以图形化方式定义爬虫流程,不写代码即可完成爬虫。基于springbootlayui开发的前后端不分离,也可以进行二次开发。该系统/function/save接口存在RCE漏洞,攻击者可以构造恶意命…...
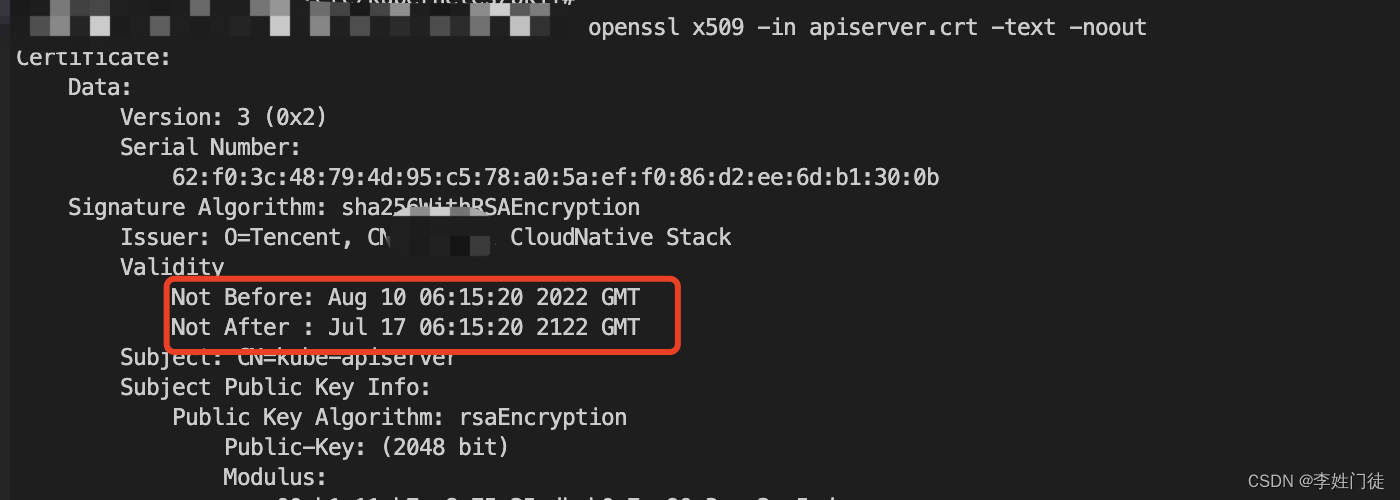
k8s的ca以及相关证书签发流程
k8s的ca以及相关证书签发流程 1. kube-apiserver相关证书说明2. 生成CA凭证1.1. 生成CA私钥1.2. 生成CA证书 2. 生成kube-apiserver凭证2.1. 生成kube-apiserver私钥2.2. 生成kube-apiserver证书请求2.3. 生成kube-apiserver证书 3. 疑问和思考4. 参考文档 对于网站类的应用&am…...

思迈特软件与上海德拓签署战略合作协议,携手赋能企业数字化转型
3月27日,广州思迈特软件有限公司(简称“思迈特软件”)与上海德拓信息技术有限公司(简称“德拓信息”)正式签约建立战略合作伙伴关系。双方将在数字化转型、数据服务、数据应用以及市场资源等多个领域展开深度合作&…...

【快捷部署】015_Minio(latest)
📣【快捷部署系列】015期信息 编号选型版本操作系统部署形式部署模式复检时间015MiniolatestCentOS 7.XDocker单机2024-04-09 一、快捷部署 #!/bin/bash ################################################################################# # 作者:c…...

<网络安全>《72 微课堂<什么是靶场?>》
1 简介 网络安全靶场是一种模拟真实网络环境的技术或平台。 网络安全靶场基于虚拟化技术,能够模拟网络架构、系统设备、业务流程的运行状态及运行环境,用于支持网络安全相关的学习、研究、检验、竞赛和演习等活动,旨在提高人员及机构的网络…...

Golang | Leetcode Golang题解之第18题四数之和
题目: 题解: func fourSum(nums []int, target int) (quadruplets [][]int) {sort.Ints(nums)n : len(nums)for i : 0; i < n-3 && nums[i]nums[i1]nums[i2]nums[i3] < target; i {if i > 0 && nums[i] nums[i-1] || nums[i]…...

自动驾驶中的传感器融合算法:卡尔曼滤波器和扩展卡尔曼滤波器
自动驾驶中的传感器融合算法:卡尔曼滤波器和扩展卡尔曼滤波器 附赠自动驾驶学习资料和量产经验:链接 介绍: 追踪静止和移动的目标是自动驾驶技术领域最为需要的核心技术之一。来源于多种传感器的信号,包括摄像头,雷达…...
基于ssm的星空游戏购买下载平台的设计与实现论文
摘 要 随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势,商品交易当然也不能排除在外,随着商品交易管理的不断成熟,它彻底改变了过去传统的经营管理方式,不仅使商品…...

DSOX6004A是德科技DSOX6004A示波器
181/2461/8938产品概述: 特点: 是德科技DSOX6004A具有7合1集成功能,结合了数字通道、串行协议分析、内置双通道波形发生器、频率响应分析、内置数字万用表和带累加器的内置10位计数器。1千兆赫至6千兆赫4个模拟通道在12.1英寸电容式多点触摸屏上轻松查…...

golang 使用 cipher、aes 实现 oauth2 验证
在Go语言中,crypto/cipher包提供了加密和解密消息的功能。这个包实现了各种加密算法,如AES、DES、3DES、RC4等,以及相应的模式,如ECB、CBC、CFB、OFB、CTR等。以下是如何使用crypto/cipher包进行加密和解密操作的基本步骤…...
LLMs之FreeGPT35:FreeGPT35的简介、安装和使用方法、案例应用之详细攻略
LLMs之FreeGPT35:FreeGPT35的简介、安装和使用方法、案例应用之详细攻略 目录 FreeGPT35的简介 FreeGPT35的安装和使用方法 1、部署和启动服务 Node 2、使用 Docker 部署服务: 运行 Docker 容器以部署服务 使用 Docker Compose 进行更方便的容器化…...

【力扣一刷】代码随想录day32(贪心算法part2:122.买卖股票的最佳时机II、55. 跳跃游戏、45.跳跃游戏II )
目录 【122.买卖股票的最佳时机II】中等题 方法一 贪心算法 方法二 动态规划 【55. 跳跃游戏】中等题 【尝试】 递归 (超时) 方法 贪心算法 【45.跳跃游戏II】中等题 方法 贪心算法 【122.买卖股票的最佳时机II】中等题(偏简单࿰…...

从零打造专属机械键盘:基于CircuitPython的USB HID输入设备实践
1. 项目概述:打造你的专属“一键”键盘如果你对市面上千篇一律的键盘感到厌倦,或者一直想亲手制作一个独一无二的输入设备,那么这个项目就是为你准备的。今天,我们不谈那些复杂的全尺寸客制化键盘,而是从一个精巧、有趣…...

NotebookLM问答功能深度解析:如何用3步配置让AI精准理解你的PDF/网页文档?
更多请点击: https://intelliparadigm.com 第一章:NotebookLM问答功能深度解析:如何用3步配置让AI精准理解你的PDF/网页文档? NotebookLM 是 Google 推出的面向研究者与知识工作者的实验性 AI 工具,其核心能力在于基于…...

STM32 FSMC/FMC接口详解:地址映射、时序配置与实战优化
1. 项目概述:深入理解STM32的FSMC/FMC接口在嵌入式开发中,尤其是涉及大屏显示、高速数据采集或复杂外部设备交互的项目里,我们常常会遇到一个绕不开的“硬骨头”——如何让STM32单片机高效、稳定地与外部并行存储器或设备通信。这时ÿ…...

EvoAgentX智能体开发框架:模块化架构与进化引擎解析
1. 项目概述:一个面向未来的智能体开发框架最近在探索智能体(Agent)开发领域时,我遇到了一个名为“EvoAgentX”的项目。这个名字本身就很有意思,“Evo”暗示着进化,“AgentX”则指向了智能体及其无限的可能…...

如何彻底移除Windows Defender:13项核心服务完整卸载与系统性能优化终极指南
如何彻底移除Windows Defender:13项核心服务完整卸载与系统性能优化终极指南 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitco…...

终极AMD Ryzen硬件掌控工具:从新手到专家的完整调试指南
终极AMD Ryzen硬件掌控工具:从新手到专家的完整调试指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://…...

Rusted PackFile Manager:Total War模组开发的终极解决方案,3分钟快速上手指南
Rusted PackFile Manager:Total War模组开发的终极解决方案,3分钟快速上手指南 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total …...

Windows终极优化神器:WinUtil - 一键解决系统安装、优化、修复的完整指南
Windows终极优化神器:WinUtil - 一键解决系统安装、优化、修复的完整指南 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 你是否厌…...

新时代的信息茧房
大家有没有发现:信息爆炸 2.0 时代,获取真知为何反而更难了? 人类正身处信息传播最为便捷的时代。移动互联网的普及与信息技术的迭代升级,让知识获取变得前所未有的低廉易得。迈入 AI 时代后,这一发展进程更是被推至全…...

SoC设计全流程解析:从架构到流片的核心步骤与挑战
1. 项目概述:从“黑盒子”到“城市蓝图”每次拿起手机,我们都在与一个极其复杂的微型“城市”互动。这个城市,就是SoC。对于很多刚入行的朋友,甚至是一些有经验的软件工程师来说,SoC常常像一个“黑盒子”——我们知道它…...