数据挖掘|序列模式挖掘及其算法的python实现
数据挖掘|序列模式挖掘及其算法的python实现
- 1. 序列模式挖掘
- 2. 基本概念
- 3. 序列模式挖掘实例
- 4. 类Apriori算法(GSP算法)
- 4.1 算法思想
- 4.2 算法步骤
- 4.3 基于Python的算法实现
1. 序列模式挖掘
序列(sequence)模式挖掘也称为序列分析。
序列模式发现(Sequential Patterns Discovery)是由R.Agrawal于1995年首先提出的。
序列模式寻找的是事件之间在顺序上的相关性。
- 例如,“凡是买了喷墨打印机的顾客中,80%的人在三个月之后又买了墨盒”,就是一个序列关联规则。对于保险行业,通过分析顾客不同次的购买行为发现,顾客本次购买重疾险,下次购买分红保险,则企业可以通过对重疾险销量的统计来预测分红险的销售量。
序列模式挖掘在交易数据库分析、Web访问日志分析以及通信网络分析等领域具有广泛的应用前景。
2. 基本概念
设 I = i 1 , i 2 , . . . , i n I={i_1,i_2,...,i_n} I=i1,i2,...,in是一个项集,序列就是若事件(元素)组成的有序列表。
一个序列 S e Se Se可表示为 < s 1 , s 2 , . . . , s n > <s_1,s_2,...,s_n> <s1,s2,...,sn>,其中 s j ( j = 1 , 2 , … , n ) s_j(j=1,2, …, n) sj(j=1,2,…,n)为事件,也称为 S e Se Se的元素。
元素由不同的项组成。当元素只包含一项时,一般省去括号,例如, { i 2 } \{i_2\} {i2}一般表示为 i 2 i_2 i2。
元素之间是有顺序的,但元素内的项是无序的,一般定义为词典序。序列包含项的个数称为序列的长度,长度为 L L L的序列记为 L − 序列 L-序列 L−序列。
序列数据库就是元组 < s i d , S e > <sid, Se> <sid,Se>的集合,即有序事件序列组成的数据库,其中 S e Se Se是序列, s i d sid sid 是该序列的序列号。
存在两个序列 α = < a 1 , a 2 , . . . , a n > , β = < b 1 , b 2 , … , b n > \alpha = <a_1, a_2, ...,a_n>, \beta = <b_1, b_2, …, b_n> α=<a1,a2,...,an>,β=<b1,b2,…,bn>,如果存在整数 1 ≤ i 1 < i 2 < … < i n ≤ m 1\leq i_1 < i_2 <…<i_n \leq m 1≤i1<i2<…<in≤m 且 a 1 ⊆ b i 1 , a 2 ⊆ b i 2 , … , a n ⊆ b i n a_1\subseteq b_{i1}, a_2 \subseteq b_{i2}, …, a_n \subseteq b_{in} a1⊆bi1,a2⊆bi2,…,an⊆bin,那么称序列 α \alpha α是 β \beta β 的子序列(subsequence),或者序列 β \beta β 包含 α \alpha α,记作 α ⊆ β \alpha\subseteq \beta α⊆β 。
序列在序列数据库 S e Se Se 中的支持度为序列数据库 S e Se Se 中包含序列 α \alpha α的序列个数除以总的序列数,记为 s u p p o r t ( α ) support (\alpha) support(α)。给定支持度阈值 τ \tau τ,如果序列 α \alpha α在序列数据库中的支持度不低于 τ \tau τ,则称序列 α \alpha α为序列模式(频繁序列)。
3. 序列模式挖掘实例
现有事务数据库如下表1所示,交易中不考虑顾客购买物品的数量,只考虑物品有没有被购买。整理后可得到顾客购物序列库,如表2所示。
- 表1:顾客购物事务数据库
| 时间 | 顾客ID | 购物项集 |
|---|---|---|
| 2023.12.10 | 2 | 10,20 |
| 2023.12.11 | 5 | 90 |
| 2023.12.12 | 2 | 30 |
| 2023.12.13 | 2 | 40,60,70 |
| 2023.12.14 | 4 | 30 |
| 2023.12.15 | 3 | 30,50,70 |
| 2023.12.17 | 1 | 30 |
| 2023.12.17 | 1 | 90 |
| 2023.12.18 | 4 | 40,70 |
| 2023.12.19 | 4 | 90 |
- 表2:顾客购物序列库
| 顾客ID | 顾客购物序列 |
|---|---|
| 1 | <30,90> |
| 2 | <{10,20},30,{40,60,70}> |
| 3 | <{30,50,70}> |
| 4 | <30,{40,70},90> |
| 5 | <90> |
设最小支持度为 25%,从表2中可以看出,<30,90> 是 <30, {40,70},90> 的子序列。两个序列<30,90>、<30,{40,70},90>的支持度都为 40%,因此是序列模式。
4. 类Apriori算法(GSP算法)
序列模式挖掘是在给定序列数据库中找出满足最小支持度阈值的序列模式的过程。
4.1 算法思想
采用分而治之的思想,不断产生序列数据库的多个更小的投影数据库,然后在各个投影数据库上进行序列模式挖掘。
4.2 算法步骤
- 扫描序列数据库,得到长度为 1 1 1的序列模式 L 1 L1 L1,作为初始的种子集。
- 根据长度为 i i i 的种子集 L i ( i ≥ 1 ) L_i (i\geq1) Li(i≥1) 通过连接操作生成长度为 i + 1 i+1 i+1的候选序列模式 C i + 1 C_{i+1} Ci+1;然后扫描序列数据库,计算每个候选序列模式的支持数,产生长度为 i + 1 i+1 i+1的序列模式 L i + 1 L_{i+1} Li+1,并将 L i + 1 L_{i+1} Li+1 作为新的种子集。
- 重复第二步,直到没有新的序列模式或新的候选序列模式产生为止
4.3 基于Python的算法实现
问题:原始序列为:<1,2,3,4>,<{1,5},2,3,4>, <1,3,4,{3,5}>, <1,3,5>, <4,5>,挖掘其中的序列模式。
以下代码是本人自己实现的。感觉原始序列的数据结构使用的不太好,导致子模式识别较为麻烦,可能存在错误,仅保证本算例正确,敬请谅解。
import numpy as np
#子模式判断
def isSubSeq(seq,subseq)->bool:i=0;if len(subseq)>len(seq):return Falsefor sel in subseq:if i >= len(seq):return Falsefor j in range(i,len(seq)):if type(seq[j])==list:if sel in seq[j]:i=j+1breakelif j==len(seq)-1:return Falseelif sel==seq[j]:i=j+1breakelif j==len(seq)-1:return Falseelse:continuereturn True # 获取L1数据集
def getL1(seq):ds=[]for ss in seq:for s in ss:if type(s)==list:for e in s:if [e] not in ds:ds.append([e])else:if [s] not in ds:ds.append([s])return np.array(ds)# 获取L2数据集
def getL2(l1seq)->np.ndarray:ds=[]for i in range(len(l1seq)):for j in range(len(l1seq)):if i != j:#np.append(ds, [l1seq[i],l1seq[j]])ds.append([l1seq[i][0],l1seq[j][0]]) return np.array(ds) # 获取L3数据集
def getL3(l1seq,l2seq):ds=[]for se2 in l2seq:for se1 in l1seq:if se1 not in se2:ds.append(np.append(se2, se1)) return ds
# 获取L4数据集
def getL4(l1seq,l3seq):ds=[]for se3 in l3seq:for se1 in l1seq:if se1 not in se3:ds.append(np.append(se3, se1)) return ds #计算支持度
def calSup(dsq,seq):i=0.0for s in dsq:if isSubSeq(s,seq):i=i+1return i/len(dsq)if __name__ == "__main__":min_support = 0.4 #最小支持度dsq = np.array([[1,2,3,4],[[1,5],2,3,4],[1,3,4,[3,5]],[1,3,5],[4,5]],dtype=object)l1=getL1(dsq)for l in l1:print('序列-1:',l,'的支持度为:',calSup(dsq, l))l2 = getL2(l1)l2seq=[]for i in range(len(l2)):sups=calSup(dsq, l2[i])if sups >=min_support:print('序列-2:',l2[i],'的支持度为:',sups)l2seq.append(l2[i])l3=getL3(l1,l2seq)l3seq=[]for i in range(len(l3)):sups=calSup(dsq, l3[i])if sups >=min_support:print('序列-3:',l3[i],'的支持度为:',sups)l3seq.append(l3[i])l4=getL4(l1,l3seq)l4seq=[]for i in range(len(l4)):sups=calSup(dsq, l4[i])if sups >=min_support:print('序列-4:',l4[i],'的支持度为:',sups)l4seq.append(l4[i])
输出:
序列-1: [1] 的支持度为: 0.8序列-1: [2] 的支持度为: 0.4序列-1: [3] 的支持度为: 0.8序列-1: [4] 的支持度为: 0.8序列-1: [5] 的支持度为: 0.8序列-2: [1 2] 的支持度为: 0.4序列-2: [1 3] 的支持度为: 0.8序列-2: [1 4] 的支持度为: 0.6序列-2: [1 5] 的支持度为: 0.4序列-2: [2 3] 的支持度为: 0.4序列-2: [2 4] 的支持度为: 0.4序列-2: [3 4] 的支持度为: 0.6序列-2: [3 5] 的支持度为: 0.4序列-2: [4 5] 的支持度为: 0.4序列-3: [1 2 3] 的支持度为: 0.4序列-3: [1 2 4] 的支持度为: 0.4序列-3: [1 3 4] 的支持度为: 0.6序列-3: [1 3 5] 的支持度为: 0.4序列-3: [2 3 4] 的支持度为: 0.4序列-4: [1 2 3 4] 的支持度为: 0.4
相关文章:

数据挖掘|序列模式挖掘及其算法的python实现
数据挖掘|序列模式挖掘及其算法的python实现 1. 序列模式挖掘2. 基本概念3. 序列模式挖掘实例4. 类Apriori算法(GSP算法)4.1 算法思想4.2 算法步骤4.3 基于Python的算法实现 1. 序列模式挖掘 序列(sequence)模式挖掘也称为序列分析。 序列模式发现&…...
3. Django 初探路由
3. 初探路由 一个完整的路由包含: 路由地址, 视图函数(或者视图类), 可选变量和路由命名. 本章讲述Django的路由编写规则与使用方法, 内容分为: 路由定义规则, 命名空间与路由命名, 路由的使用方式.3.1 路由定义规则 路由称为URL (Uniform Resource Locator, 统一资源定位符)…...
论文笔记:Large Language Models as Analogical Reasoners
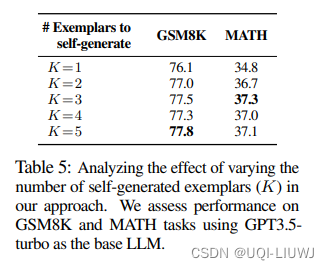
iclr 2024 reviewer打分5558 1 intro 基于CoT prompt的大模型能够更好地解决复杂推理问题 然而传统CoT需要提供相关的例子作为指导,这就增加了人工标注的成本——>Zero-shot CoT避免了人工标注来引导推理 但是对于一些复杂的任务难以完成推理,例如c…...

第3章 数据定义语言DDL
文章目录 第3章 DDL语言:数据定义语言3.1 MySQL的数据类型3.2 表的创建:create3.3 表的删除:drop3.4 快速创建表3.5 快速删除表中的数据:truncate3.6 修改表结构:alter 第5章 约束5.1 非空约束:not null5.2…...
C#操作MySQL从入门到精通(7)——对查询数据进行简单过滤
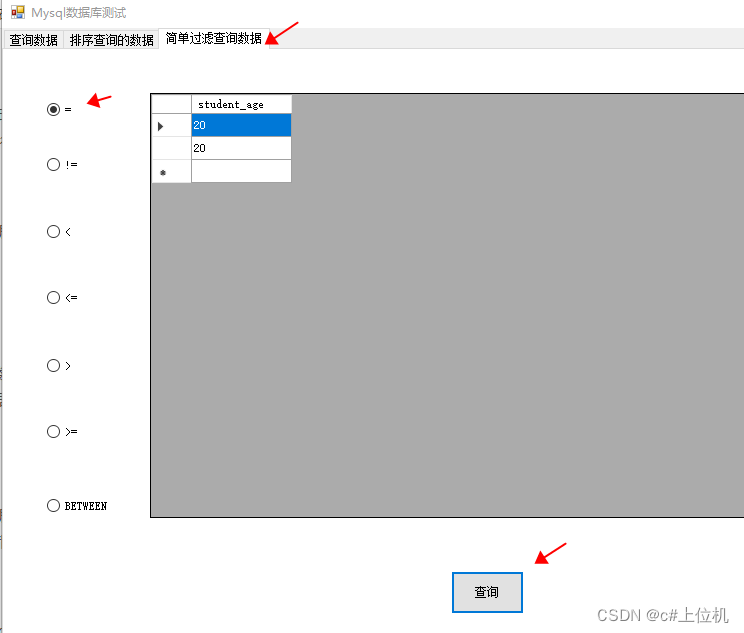
前言 我们在查询数据库中数据的时候,有时候需要剔除一些我们不想要的数据,这时候就需要对数据进行过滤,比如学生信息中,我只需要年龄等于18的,类似这种操作,本文就是详细介绍如何对查询的数据进行初步的过滤。 1、等于操作符 本次查询student_age 等于20的数据,使用我…...
【CVE复现计划】CVE-2024-0195
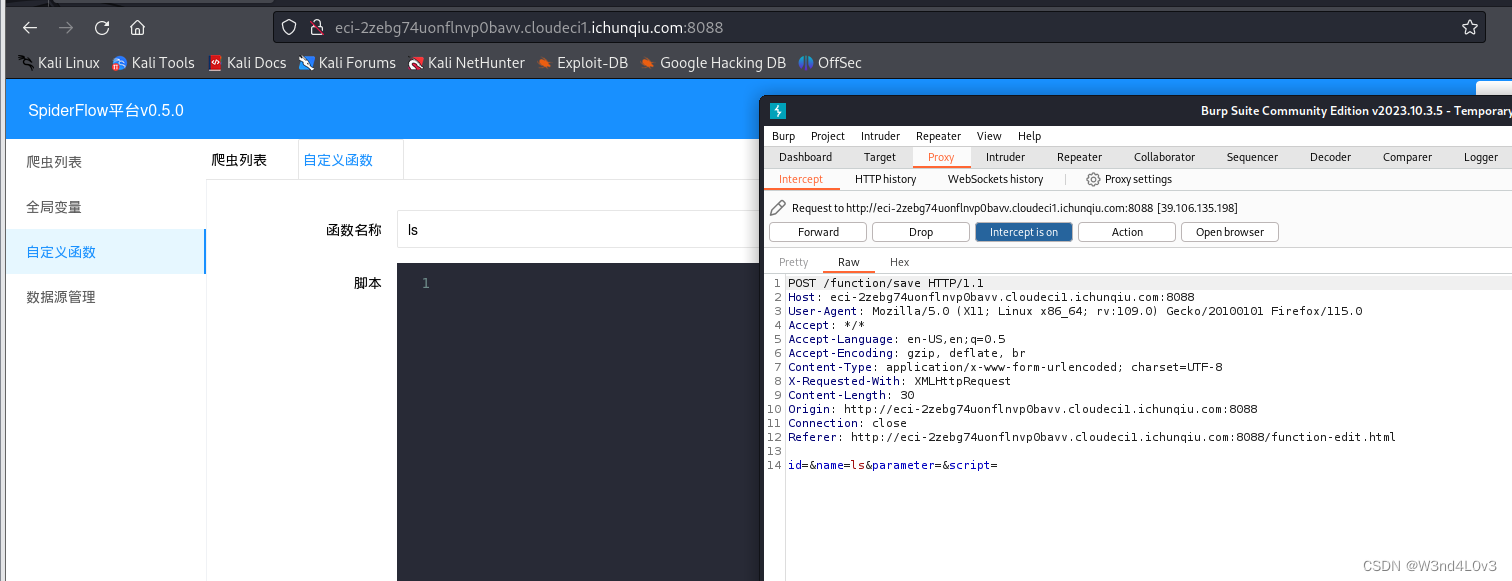
CVE-2024-0195 简介: SpiderFlow是新一代开源爬虫平台,以图形化方式定义爬虫流程,不写代码即可完成爬虫。基于springbootlayui开发的前后端不分离,也可以进行二次开发。该系统/function/save接口存在RCE漏洞,攻击者可以构造恶意命…...
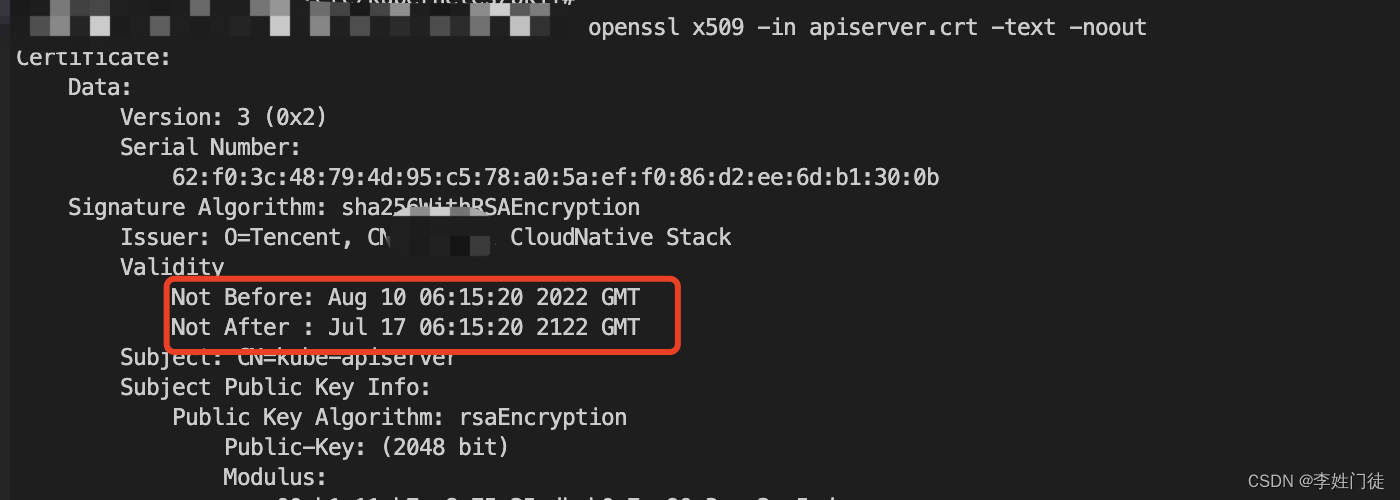
k8s的ca以及相关证书签发流程
k8s的ca以及相关证书签发流程 1. kube-apiserver相关证书说明2. 生成CA凭证1.1. 生成CA私钥1.2. 生成CA证书 2. 生成kube-apiserver凭证2.1. 生成kube-apiserver私钥2.2. 生成kube-apiserver证书请求2.3. 生成kube-apiserver证书 3. 疑问和思考4. 参考文档 对于网站类的应用&am…...

思迈特软件与上海德拓签署战略合作协议,携手赋能企业数字化转型
3月27日,广州思迈特软件有限公司(简称“思迈特软件”)与上海德拓信息技术有限公司(简称“德拓信息”)正式签约建立战略合作伙伴关系。双方将在数字化转型、数据服务、数据应用以及市场资源等多个领域展开深度合作&…...

【快捷部署】015_Minio(latest)
📣【快捷部署系列】015期信息 编号选型版本操作系统部署形式部署模式复检时间015MiniolatestCentOS 7.XDocker单机2024-04-09 一、快捷部署 #!/bin/bash ################################################################################# # 作者:c…...

<网络安全>《72 微课堂<什么是靶场?>》
1 简介 网络安全靶场是一种模拟真实网络环境的技术或平台。 网络安全靶场基于虚拟化技术,能够模拟网络架构、系统设备、业务流程的运行状态及运行环境,用于支持网络安全相关的学习、研究、检验、竞赛和演习等活动,旨在提高人员及机构的网络…...

Golang | Leetcode Golang题解之第18题四数之和
题目: 题解: func fourSum(nums []int, target int) (quadruplets [][]int) {sort.Ints(nums)n : len(nums)for i : 0; i < n-3 && nums[i]nums[i1]nums[i2]nums[i3] < target; i {if i > 0 && nums[i] nums[i-1] || nums[i]…...

自动驾驶中的传感器融合算法:卡尔曼滤波器和扩展卡尔曼滤波器
自动驾驶中的传感器融合算法:卡尔曼滤波器和扩展卡尔曼滤波器 附赠自动驾驶学习资料和量产经验:链接 介绍: 追踪静止和移动的目标是自动驾驶技术领域最为需要的核心技术之一。来源于多种传感器的信号,包括摄像头,雷达…...
基于ssm的星空游戏购买下载平台的设计与实现论文
摘 要 随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势,商品交易当然也不能排除在外,随着商品交易管理的不断成熟,它彻底改变了过去传统的经营管理方式,不仅使商品…...

DSOX6004A是德科技DSOX6004A示波器
181/2461/8938产品概述: 特点: 是德科技DSOX6004A具有7合1集成功能,结合了数字通道、串行协议分析、内置双通道波形发生器、频率响应分析、内置数字万用表和带累加器的内置10位计数器。1千兆赫至6千兆赫4个模拟通道在12.1英寸电容式多点触摸屏上轻松查…...

golang 使用 cipher、aes 实现 oauth2 验证
在Go语言中,crypto/cipher包提供了加密和解密消息的功能。这个包实现了各种加密算法,如AES、DES、3DES、RC4等,以及相应的模式,如ECB、CBC、CFB、OFB、CTR等。以下是如何使用crypto/cipher包进行加密和解密操作的基本步骤…...
LLMs之FreeGPT35:FreeGPT35的简介、安装和使用方法、案例应用之详细攻略
LLMs之FreeGPT35:FreeGPT35的简介、安装和使用方法、案例应用之详细攻略 目录 FreeGPT35的简介 FreeGPT35的安装和使用方法 1、部署和启动服务 Node 2、使用 Docker 部署服务: 运行 Docker 容器以部署服务 使用 Docker Compose 进行更方便的容器化…...

【力扣一刷】代码随想录day32(贪心算法part2:122.买卖股票的最佳时机II、55. 跳跃游戏、45.跳跃游戏II )
目录 【122.买卖股票的最佳时机II】中等题 方法一 贪心算法 方法二 动态规划 【55. 跳跃游戏】中等题 【尝试】 递归 (超时) 方法 贪心算法 【45.跳跃游戏II】中等题 方法 贪心算法 【122.买卖股票的最佳时机II】中等题(偏简单࿰…...
安卓远离手机app
软件介绍 远离手机是专门为防止年轻人上瘾而打造的生活管理类的软件,适度用手机,保护眼睛,节约时间。 下载 安卓远离手机app...
yolov5旋转目标检测遥感图像检测-无人机旋转目标检测(代码和原理)
YOLOv5(You Only Look Once version 5)是一个流行且高效的实时目标检测深度学习模型,最初设计用于处理图像中的水平矩形边界框目标。然而,对于旋转目标检测,通常需要对原始YOLOv5架构进行扩展或修改,以便能…...

云手机提供私域流量变现方案
当今数字营销领域,私域流量是一座巨大的金矿,然而并非人人能够轻易挖掘。一家营销公司面临着利用社交、社区、自媒体等应用积累私域流量,并通过销售产品、推送广告等方式实现流量变现的挑战与困境。本文将详细介绍这家公司是如何通过云手机&a…...

LSPatch:无需Root的Android应用模块化终极指南
LSPatch:无需Root的Android应用模块化终极指南 【免费下载链接】LSPatch LSPatch: A non-root Xposed framework extending from LSPosed 项目地址: https://gitcode.com/gh_mirrors/ls/LSPatch 你是否曾经羡慕iOS的越狱插件,却因Android设备未ro…...

低空经济崛起,实干企业的“品牌失语”危机比“黑飞”更可怕!
最近,低空经济成为热词。从浙江移动发布的低空智联网“4S”安全服务矩阵,到无人机在医疗、巡检、物流等领域的广泛应用,我们看到了一个万亿级市场的技术底座正在快速搭建。然而,在另一片我们称之为“AI空域”的新战场,…...

ESP32 ADC采样率上不去?实测DMA模式下的真实性能与避坑指南
ESP32 ADC DMA模式性能深度优化:突破2MSPS采样率的关键策略 在物联网边缘计算领域,ESP32凭借其出色的性价比和丰富的外设资源,已成为众多高速数据采集项目的首选方案。当开发者尝试将ESP32的ADC采样率推向理论极限时,往往会遭遇现…...

WinFlexBison深度解析:Windows平台编译工具链的完整解决方案
WinFlexBison深度解析:Windows平台编译工具链的完整解决方案 【免费下载链接】winflexbison Main winflexbision repository 项目地址: https://gitcode.com/gh_mirrors/wi/winflexbison 在Windows平台上开发编译器、解释器或复杂文本解析器时,开…...

Node js 后端服务如何优雅集成 Taotoken 提供的多模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 后端服务如何优雅集成 Taotoken 提供的多模型能力 应用场景类,描述一个 Node.js 后端服务需要动态选择不同大模…...

claude code用户如何通过taotoken解决账号封禁与token不足难题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何通过 Taotoken 解决账号封禁与 Token 不足难题 对于深度依赖 Claude Code 作为编程助手的开发者而言…...

Linux只读挂载保护排查方法
Linux只读挂载保护排查方法本文面向具备一定 Linux 基础的技术人员,围绕只读挂载保护展开,重点讨论写入隔离、配置保护和异常诊断。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起…...

不止VSIN!Cadence PSpice仿真库SOURCE.OLB里还有哪些宝藏信号源?实战对比与选型指南
不止VSIN!Cadence PSpice仿真库SOURCE.OLB里还有哪些宝藏信号源?实战对比与选型指南 在电路仿真设计中,信号源的选择往往决定了仿真结果的准确性与实用性。许多工程师对PSpice中的VSIN元件较为熟悉,却忽略了SOURCE.OLB库中其他丰富…...

实测Taotoken多模型聚合调用的响应延迟与稳定性观感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken多模型聚合调用的响应延迟与稳定性观感 在项目开发中,我们常常需要接入不同的大模型来满足多样化的需求。…...

3步解决网盘下载限速难题:一站式直链解析工具实战指南
3步解决网盘下载限速难题:一站式直链解析工具实战指南 【免费下载链接】netdisk-fast-download 聚合多种主流网盘的直链解析下载服务, 一键解析下载,已支持夸克网盘/uc网盘/蓝奏云/蓝奏优享/小飞机盘/123云盘等. 支持文件夹分享解析. 体验地址: https://…...