K8S:常用资源对象操作
文章目录
- 一、使用Replication Controller(RC)、Replica Set(RS) 管理Pod
- 1 Replication Controller(RC)
- 2 Replication Set(RS)
- 二、Deployment的使用
- 1 创建
- 2 滚动升级
- 3 回滚Deployment
- 三、 Pod 自动扩缩容HPA
- 1 使用kubectl autoscale
- 2 不使用kubectl autoscale
- 三、Job 和 Cronjob 的使用
- 1 Job
- 2 CronJob
一、使用Replication Controller(RC)、Replica Set(RS) 管理Pod
如果有一种工具能够来帮助我们管理Pod就好了,Pod不够了自动帮我新增一个,Pod挂了自动帮我在合适的节点上重新启动一个Pod,这样是不是遇到上面的问题我们都不需要手动去解决了。
幸运的是,Kubernetes就为我们提供了这样的资源对象:
- Replication Controller:用来部署、升级Pod
- Replica Set:下一代的Replication Controller
- Deployment:可以更加方便的管理Pod和Replica Set
1 Replication Controller(RC)
Replication Controller简称RC,RC是Kubernetes系统中的核心概念之一,简单来说,RC可以保证在任意时间运行Pod的副本数量,能够保证Pod总是可用的。如果实际Pod数量比指定的多那就结束掉多余的,如果实际数量比指定的少就新启动一些Pod,当Pod失败、被删除或者挂掉后,RC都会去自动创建新的Pod来保证副本数量,所以即使只有一个Pod,我们也应该使用RC来管理我们的Pod。
运行Pod的节点挂了,RC检测到Pod失败了,就会去合适的节点重新启动一个Pod就行,不需要我们手动去新建一个Pod了。如果是第一种情况的话在活动开始之前我们给Pod指定10个副本,结束后将副本数量改成2,这样是不是也远比我们手动去启动、手动去关闭要好得多,而且我们后面还会给大家介绍另外一种资源对象HPA可以根据资源的使用情况来进行自动扩缩容。
现在我们来使用RC来管理我们前面使用的Nginx的Pod,YAML文件如下:
apiVersion: v1
kind: ReplicationController
metadata:name: rc-demolabels:name: rc
spec:replicas: 3selector:name: rctemplate:metadata:labels:name: rcspec:containers:- name: nginx-demoimage: nginxports:- containerPort: 80
上面的YAML文件相对于我们之前的Pod的格式:
- kind:ReplicationController
- spec.replicas: 指定Pod副本数量,默认为1
- spec.selector: RC通过该属性来筛选要控制的Pod
- spec.template: 这里就是我们之前的Pod的定义的模块,但是不需要apiVersion和kind了
- spec.template.metadata.labels: 注意这里的Pod的labels要和spec.selector相同,这样RC就可以来控制当前这个Pod了。
这个YAML文件中的意思就是定义了一个RC资源对象,它的名字叫rc-demo,保证一直会有3个Pod运行,Pod的镜像是nginx镜像。
注意spec.selector和spec.template.metadata.labels这两个字段必须相同,否则会创建失败的,当然我们也可以不写spec.selector,这样就默认与Pod模板中的metadata.labels相同了。所以为了避免不必要的错误的话,不写为好。
然后我们来创建上面的RC对象(保存为 rc-demo.yaml):
$ kubectl create -f rc-demo.yaml
查看RC:
$ kubectl get rc
查看具体信息:
$ kubectl describe rc rc-demo
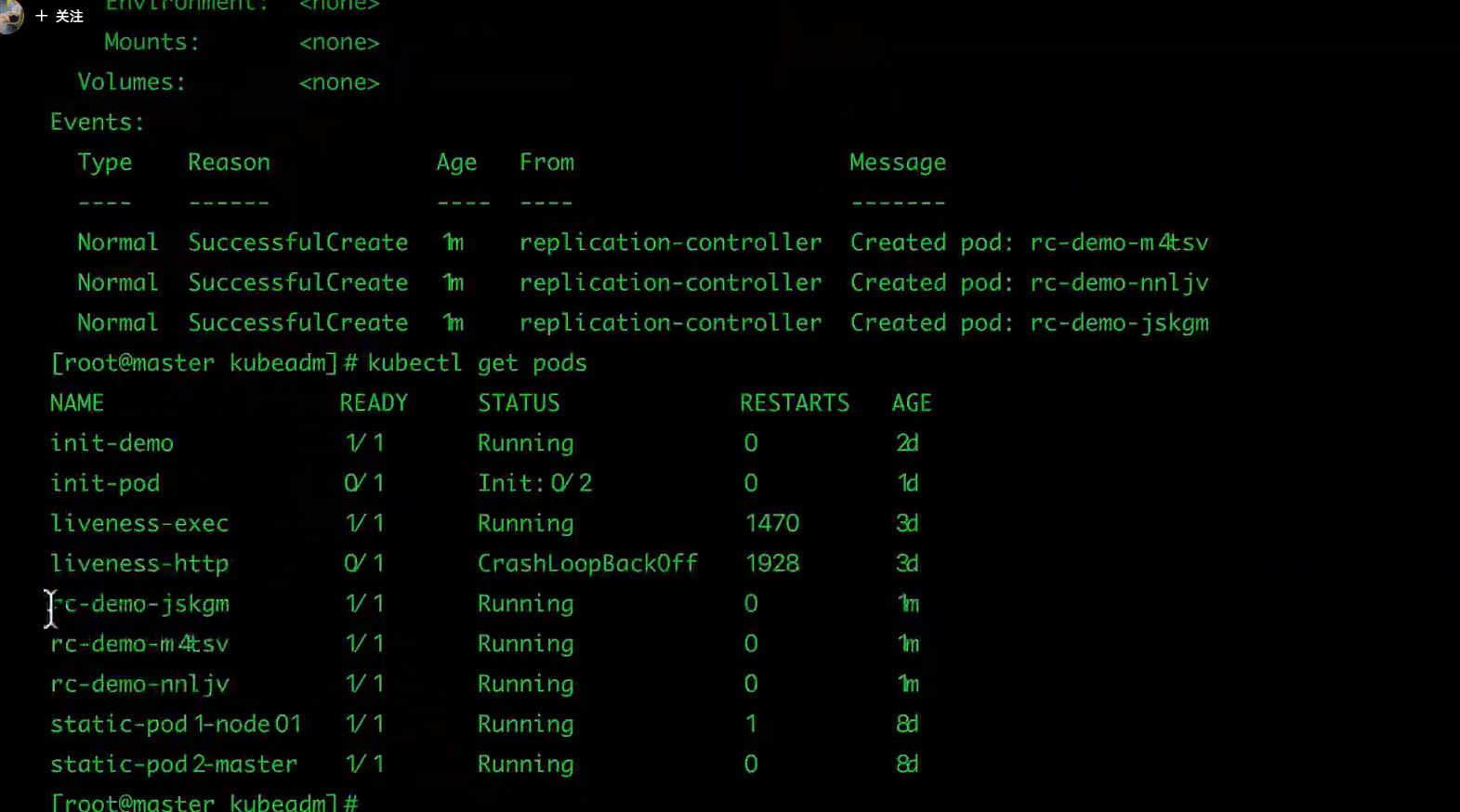
然后我们通过RC来修改下Pod的副本数量为2:
$ kubectl apply -f rc-demo.yaml或者
$ kubectl edit rc rc-demo
而且我们还可以用RC来进行滚动升级,比如我们将镜像地址更改为nginx:1.7.9:
$ kubectl rolling-update rc-demo --image=nginx:1.7.9
但是如果我们的Pod中多个容器的话,就需要通过修改YAML文件来进行修改了:
$ kubectl rolling-update rc-demo -f rc-demo.yaml
RC无法进行回滚操作
- 如果升级完成后出现了新的问题,想要一键回滚到上一个版本的话,使用RC只能用同样的方法把镜像地址替换成之前的,然后重新滚动升级。
2 Replication Set(RS)
Replication Set简称RS,随着Kubernetes的高速发展,官方已经推荐我们使用RS和Deployment来代替RC了,实际上RS和RC的功能基本一致,目前唯一的一个区别就是RC只支持基于等式的selector(env=dev或environment!=qa),但RS还支持基于集合的selector(version in (v1.0, v2.0)),这对复杂的运维管理就非常方便了。
eg:
apiVersion: v1
kind: ReplicationSet
metadata:name: rc-demolabels:name: rc
spec:replicas: 3selector:name: rctemplate:metadata:labels:name: rcspec:containers:- name: nginx-demoimage: nginxports:- containerPort: 80
kubectl命令行工具中关于RC的大部分命令同样适用于我们的RS资源对象。不过我们也很少会去单独使用RS,它主要被Deployment这个更加高层的资源对象使用,除非用户需要自定义升级功能或根本不需要升级Pod,在一般情况下,我们推荐使用Deployment而不直接使用Replica Set。
最后我们总结下关于RC/RS的一些特性和作用吧:
- 大部分情况下,我们可以通过定义一个RC实现的Pod的创建和副本数量的控制
- RC中包含一个完整的Pod定义模块(不包含apiversion和kind)
- RC是通过label selector机制来实现对Pod副本的控制的
- 通过改变RC里面的Pod副本数量,可以实现Pod的扩缩容功能
- 通过改变RC里面的Pod模板中镜像版本,可以实现Pod的滚动升级功能(但是不支持一键回滚,需要用相同的方法去修改镜像地址)
二、Deployment的使用
首先RC是Kubernetes的一个核心概念,当我们把应用部署到集群之后,需要保证应用能够持续稳定的运行,RC就是这个保证的关键,主要功能如下:
- 确保Pod数量:它会确保Kubernetes中有指定数量的Pod在运行,如果少于指定数量的Pod,RC就会创建新的,反之这会删除多余的,保证Pod的副本数量不变。
- 确保Pod健康:当Pod不健康,比如运行出错了,总之无法提供正常服务时,RC也会杀死不健康的Pod,重新创建新的。
- 弹性伸缩:在业务高峰或者低峰的时候,可以用过RC来动态的调整Pod数量来提供资源的利用率,当然我们也提到过如果使用HPA这种资源对象的话可以做到自动伸缩。
- 滚动升级:滚动升级是一种平滑的升级方式,通过逐步替换的策略,保证整体系统的稳定性,
Deployment同样也是Kubernetes系统的一个核心概念,主要职责和RC一样的都是保证Pod的数量和健康,二者大部分功能都是完全一致的,我们可以看成是一个升级版的RC控制器,那Deployment又具备那些新特性呢?
- RC的全部功能:Deployment具备上面描述的RC的全部功能
- 事件和状态查看:可以查看Deployment的升级详细进度和状态
- 回滚:当升级Pod的时候如果出现问题,可以使用回滚操作回滚到之前的任一版本
- 版本记录:每一次对Deployment的操作,都能够保存下来,这也是保证可以回滚到任一版本的基础
- 暂停和启动:对于每一次升级都能够随时暂停和启动
作为对比,我们知道Deployment作为新一代的RC,不仅在功能上更为丰富了,同时我们也说过现在官方也都是推荐使用Deployment来管理Pod的,比如一些官方组件kube-dns、kube-proxy也都是使用的Deployment来管理的,所以当大家在使用的使用也最好使用Deployment来管理Pod。
1 创建
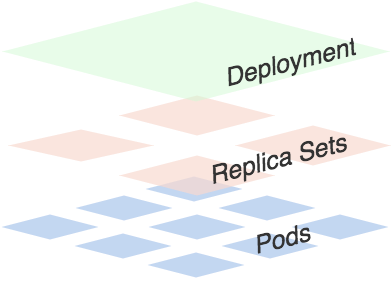
可以看出一个Deployment拥有多个Replica Set,而一个Replica Set拥有一个或多个Pod。
一个Deployment控制多个rs主要是为了支持回滚机制,每当Deployment操作时,Kubernetes会重新生成一个Replica Set并保留,以后有需要的话就可以回滚至之前的状态。
下面创建一个Deployment,它创建了一个Replica Set来启动3个nginx pod,yaml文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploylabels:k8s-app: nginx-demo
spec:replicas: 3selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.7.9ports:- containerPort: 80
将上面内容保存为: nginx-deployment.yaml,执行命令:
$ kubectl create -f nginx-deployment.yaml
deployment "nginx-deploy" created
然后执行一下命令查看刚刚创建的Deployment:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deploy 3 0 0 0 1s隔一会再次执行上面命令:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deploy 3 3 3 3 4m
我们可以看到Deployment已经创建了1个Replica Set了,执行下面的命令查看rs和pod:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deploy-431080787 3 3 3 6m$ kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deploy-431080787-53z8q 1/1 Running 0 7m app=nginx,pod-template-hash=431080787
nginx-deploy-431080787-bhhq0 1/1 Running 0 7m app=nginx,pod-template-hash=431080787
nginx-deploy-431080787-sr44p 1/1 Running 0 7m app=nginx,pod-template-hash=431080787
上面的Deployment的yaml文件中的replicas:3将会保证我们始终有3个POD在运行。
2 滚动升级
现在我们将刚刚保存的yaml文件中的nginx镜像修改为nginx:1.13.3,然后在spec下面添加滚动升级策略:
minReadySeconds: 5
strategy:# indicate which strategy we want for rolling updatetype: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 1
minReadySeconds:
Kubernetes在等待设置的时间后才进行升级
- 如果没有设置该值,Kubernetes会假设该容器启动起来后就提供服务了
- 如果没有设置该值,在某些极端情况下可能会造成服务不正常运行
maxSurge:
- 升级过程中最多可以比原先设置多出的POD数量
- 例如:maxSurage=1,replicas=5,则表示Kubernetes会先启动1一个新的Pod后才删掉一个旧的POD,整个升级过程中最多会有5+1个POD。
maxUnavaible:
- 升级过程中最多有多少个POD处于无法提供服务的状态
- 当maxSurge不为0时,该值也不能为0
- 例如:maxUnavaible=1,则表示Kubernetes整个升级过程中最多会有1个POD处于无法服务的状态。
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:name: nginx-deploynamespace: testlabels:app: nginx-demo
spec:replicas: 3minReadySeconds: 5strategy:type: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 1template:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.13.3ports:- containerPort: 80name: nginxweb然后执行命令:
$ kubectl apply -f nginx-deployment.yaml --record=true
deployment "nginx-deploy" configured
然后我们可以使用rollout命令:
查看状态:kubectl rollout status deployment nginx-deploy
$ kubectl rollout status deployment/nginx-deploy
Waiting for rollout to finish: 1 out of 3 new replicas have been updated..
deployment "nginx-deploy" successfully rolled out暂停升级
$ kubectl rollout pause deployment nginx-deploy继续升级
$ kubectl rollout resume deployment nginx-deploy
升级结束后,继续查看rs的状态:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deploy-2078889897 0 0 0 47m
nginx-deploy-3297445372 3 3 3 42m
nginx-deploy-431080787 0 0 0 1h
根据AGE我们可以看到离我们最近的当前状态是:3,和我们的yaml文件是一致的,证明升级成功了。
用describe命令可以查看升级的全部信息:
kubectl describe deployment nginx-deploy
Name: nginx-deploy
Namespace: default
CreationTimestamp: Wed, 18 Oct 2017 16:58:52 +0800
Labels: k8s-app=nginx-demo
Annotations: deployment.kubernetes.io/revision=3kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"apps/v1","kind":"Deployment","metadata":{"annotations":{},"labels":{"k8s-app":"nginx-demo"},"name":"nginx-deploy","namespace":"defa...
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:Labels: app=nginxContainers:nginx:Image: nginx:1.13.3Port: 80/TCPEnvironment: <none>Mounts: <none>Volumes: <none>
Conditions:Type Status Reason---- ------ ------Progressing True NewReplicaSetAvailableAvailable True MinimumReplicasAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deploy-3297445372 (3/3 replicas created)
Events:FirstSeen LastSeen Count From SubObjectPath Type Reason Message--------- -------- ----- ---- ------------- -------- ------ -------50m 50m 1 deployment-controller Normal ScalingReplicaSet Scaled up replica set nginx-deploy-2078889897 to 145m 45m 1 deployment-controller Normal ScalingReplicaSet Scaled down replica set nginx-deploy-2078889897 to 045m 45m 1 deployment-controller Normal ScalingReplicaSet Scaled up replica set nginx-deploy-3297445372 to 139m 39m 1 deployment-controller Normal ScalingReplicaSet Scaled down replica set nginx-deploy-431080787 to 239m 39m 1 deployment-controller Normal ScalingReplicaSet Scaled up replica set nginx-deploy-3297445372 to 238m 38m 1 deployment-controller Normal ScalingReplicaSet Scaled down replica set nginx-deploy-431080787 to 138m 38m 1 deployment-controller Normal ScalingReplicaSet Scaled up replica set nginx-deploy-3297445372 to 338m 38m 1 deployment-controller Normal ScalingReplicaSet Scaled down replica set nginx-deploy-431080787 to 0
3 回滚Deployment
我们已经能够滚动平滑的升级我们的Deployment了,但是如果升级后的POD出了问题该怎么办?我们能够想到的最好最快的方式当然是回退到上一次能够提供正常工作的版本,Deployment就为我们提供了回滚机制。
首先,查看Deployment的升级历史:
$ kubectl rollout history deployment nginx-deploy
deployments "nginx-deploy"
REVISION CHANGE-CAUSE
1 <none>
2 <none>
3 kubectl apply --filename=Desktop/nginx-deployment.yaml --record=true
从上面的结果可以看出在执行Deployment升级的时候最好带上record参数,便于我们查看历史版本信息。
默认情况下,所有通过kubectl xxxx --record都会被kubernetes记录到etcd进行持久化,这无疑会占用资源,最重要的是,时间久了,当你kubectl get rs时,会有成百上千的垃圾RS返回给你,那时你可能就眼花缭乱了。
上生产时,我们最好通过设置Deployment的.spec.revisionHistoryLimit来限制最大保留的revision number,比如15个版本,回滚的时候一般只会回滚到最近的几个版本就足够了。
其实rollout history中记录的revision都和ReplicaSets一一对应。如果手动delete某个ReplicaSet,对应的rollout history就会被删除,也就是还说你无法回滚到这个revison了。
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:name: nginx-deploynamespace: testlabels:app: nginx-demo
spec:replicas: 3revisionHistoryLimit: 15minReadySeconds: 5strategy:type: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 1template:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxports:- containerPort: 80name: nginxwebrollout history和ReplicaSet的对应关系,可以在kubectl describe rs $RSNAME返回的revision字段中得到,这里的revision就对应着rollout history返回的revison。
同样我们可以使用下面的命令查看单个revison的信息:
$ kubectl rollout history deployment nginx-deploy --revision=3
deployments "nginx-deploy" with revision #3
Pod Template:Labels: app=nginxpod-template-hash=3297445372Annotations: kubernetes.io/change-cause=kubectl apply --filename=nginx-deployment.yaml --record=trueContainers:nginx:Image: nginx:1.13.3Port: 80/TCPEnvironment: <none>Mounts: <none>Volumes: <none>
假如现在要直接回退到当前版本的前一个版本:
$ kubectl rollout undo deployment nginx-deploy
deployment "nginx-deploy" rolled back
当然也可以用revision回退到指定的版本:
$ kubectl rollout undo deployment nginx-deploy --to-revision=2
deployment "nginx-deploy" rolled back
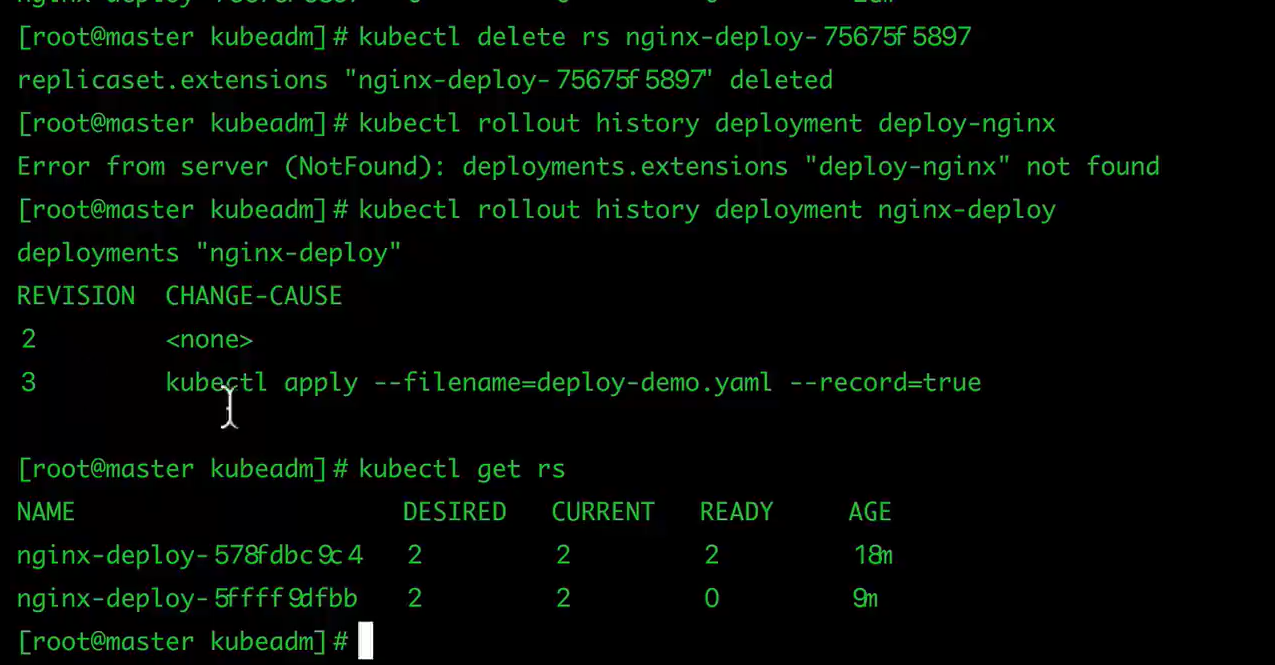
删除一个rs
$ kubectl delete rs nginx-deploy-431080787
三、 Pod 自动扩缩容HPA
手工执行kubectl scale命令和在Dashboard上操作可以实现Pod的扩缩容,但是这样毕竟需要每次去手工操作一次,而且指不定什么时候业务请求量就很大了,所以如果不能做到自动化的去扩缩容的话,这也是一个很麻烦的事情。
Kubernetes为我们提供了这样一个资源对象:Horizontal Pod Autoscaling(Pod水平自动伸缩),简称HPA。HAP通过监控分析RC或者Deployment控制的所有Pod的负载变化情况来确定是否需要调整Pod的副本数量,这是HPA最基本的原理。
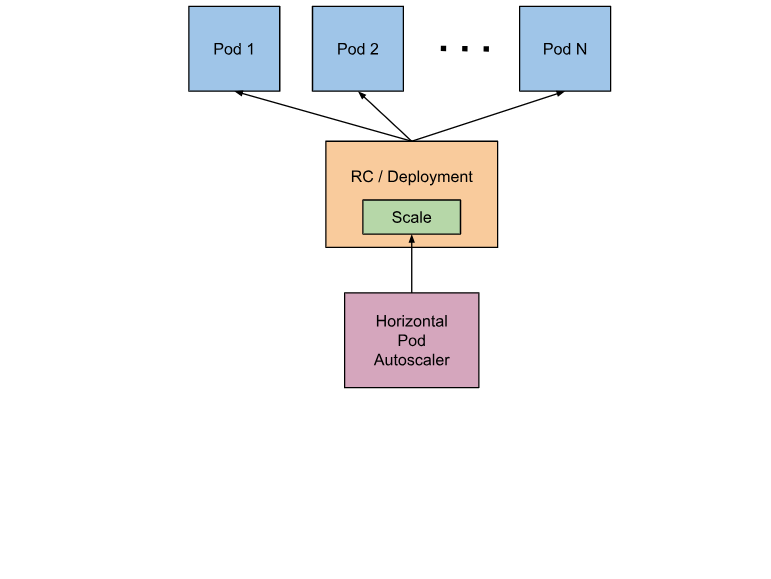
HPA在kubernetes集群中被设计成一个controller
- 我们可以简单的通过kubectl autoscale命令来创建一个HPA资源对象,
- HPA Controller默认30s轮询一次(可通过kube-controller-manager的标志–horizontal-pod-autoscaler-sync-period进行设置),查询指定的资源(RC或者Deployment)中Pod的资源使用率,并且与创建时设定的值和指标做对比,从而实现自动伸缩的功能。
当你创建了HPA后,HPA会从Heapster或者用户自定义的RESTClient端获取每一个一个Pod利用率或原始值的平均值,然后和HPA中定义的指标进行对比,同时计算出需要伸缩的具体值并进行相应的操作。目前,HPA可以从两个地方获取数据:
- Heapster:仅支持CPU使用率
- 自定义监控:
实际上我们已经默认把Heapster(1.4.2 版本)相关的镜像都已经拉取到节点上了,所以接下来我们只需要部署即可:Heapster的github页面。

heapster.yaml中的image: gcr.io/google_containers/heapster-amd64:v1.3.0可能需要依据本地的image tag进行修改。
grafana.yaml(类似dashboard)中的image: gcr.io/google_containers/heapster-grafana-amd64:v4.2.0可能需要依据本地的image tag进行修改。
我们将该目录下面的yaml文件保存到我们的集群上,然后使用kubectl命令行工具创建即可.
执行所有的yaml文件
kubectl create -f .
查看某个pod的运行日志:
kubectl logs -f heapster-676cc864c6 -n kube-system
通过yaml文件删除pod
kubectl delete -f heapster.yaml
问题:直接启动heapster会出现以下问题:heapster没有权限
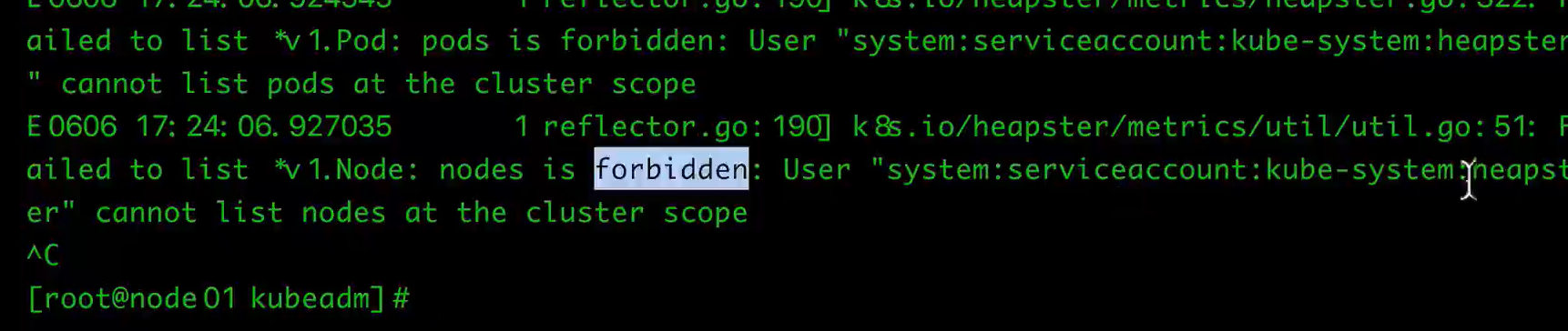
需要将heapster绑定到cluster-admin
---
apiVersion: v1
kind: ServiceAccount
metadata:name: heapsternamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: heapster-admin
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: cluster-admin
subjects:
- kind: ServiceAccountname: heapsternamespace: kube-system
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:name: heapsternamespace: kube-system
spec:replicas: 1template:metadata:labels:task: monitoringk8s-app: heapsterspec:serviceAccountName: heapstercontainers:- name: heapsterimage: gcr.io/google_containers/heapster-amd64:v1.3.0imagePullPolicy: IfNotPresentcommand:- /heapster- --source=kubernetes:https://kubernetes.default- --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086
---
apiVersion: v1
kind: Service
metadata:labels:task: monitoring# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)# If you are NOT using this as an addon, you should comment out this line.kubernetes.io/cluster-service: 'true'kubernetes.io/name: Heapstername: heapsternamespace: kube-system
spec:ports:- port: 80targetPort: 8082selector:k8s-app: heapster
重新kubectl delete yaml、kubectl reate即可
另外创建完成后,如果需要在Dashboard当中看到监控图表,我们还需要在Dashboard中配置上我们的heapster-host。
为了能够创建HPA,可能需要修改master上的kube-controller-manager.yaml

需要在command中增加下面的命令(修改完毕,则自动更新):
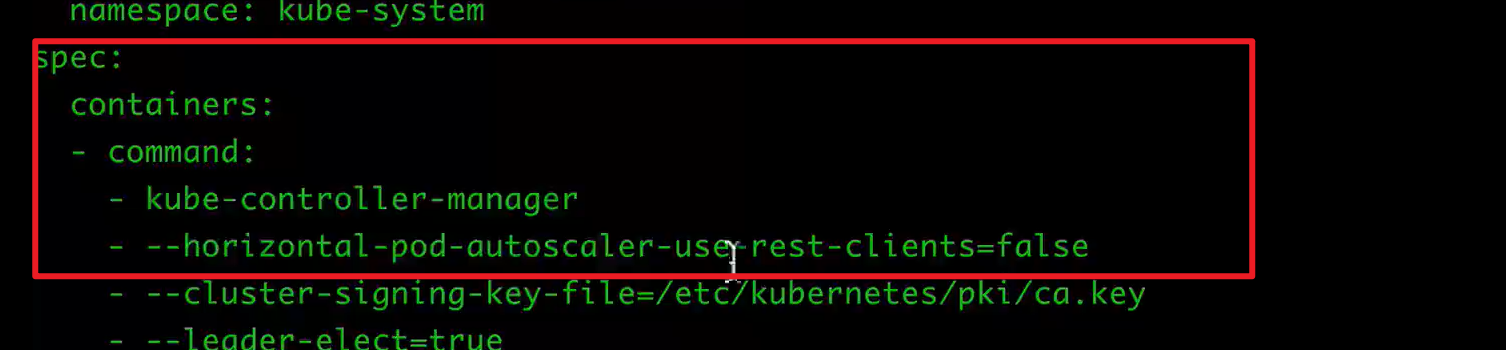
1 使用kubectl autoscale
我们来创建一个Deployment管理的Nginx Pod,然后利用HPA来进行自动扩缩容。
定义Deployment的YAML文件如下:(hap-deploy-demo.yaml)
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:name: hpa-demolabels:app: hpa
spec:revisionHistoryLimit: 15minReadySeconds: 5strategy:type: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 1template:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxresources:requests:cpu: 100mports:- containerPort: 80
然后创建Deployment
$ kubectl create -f hpa-deploy-demo.yaml
现在我们来创建一个HPA,可以使用kubectl autoscale命令来创建:
$ kubectl autoscale deployment hpa-nginx-deploy --cpu-percent=10 --min=1 --max=10
deployment "hpa-nginx-deploy" autoscaled
···
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 0% 1 10 13s
此命令创建了一个关联资源 hpa-nginx-deploy 的HPA,最小的 pod 副本数为1,最大为10。HPA会根据设定的 cpu使用率(10%)动态的增加或者减少pod数量。
现在我们来增大负载进行测试,我们来创建一个busybox,并且循环访问上面创建的服务。
$ kubectl run -i --tty load-generator --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # while true; do wget -q -O- http://172.16.255.60:4000; done
下图可以看到,HPA已经开始工作。
kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 29% 1 10 27m
同时我们查看相关资源hpa-nginx-deploy的副本数量,副本数量已经从原来的1变成了3。
$ kubectl get deployment hpa-nginx-deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
hpa-nginx-deploy 3 3 3 3 4d
同时再次查看HPA,由于副本数量的增加,使用率也保持在了10%左右。
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 9% 1 10 35m
同样的这个时候我们来关掉busybox来减少负载,然后等待一段时间观察下HPA和Deployment对象
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 0% 1 10 48m
$ kubectl get deployment hpa-nginx-deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
hpa-nginx-deploy 1 1 1 1 4d
可以看到副本数量已经由3变为1。
2 不使用kubectl autoscale
使用已经创建成功的hpa
$ kubectl get hpa hpa-nginx-deploy -o yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:creationTimestamp: 2017-06-29T08:04:08Zname: nginxtestnamespace: defaultresourceVersion: "951016361"selfLink: /apis/autoscaling/v1/namespaces/default/horizontalpodautoscalers/nginxtestuid: 86febb63-5ca1-11e7-aaef-5254004e79a3
spec:maxReplicas: 5 //资源最大副本数minReplicas: 1 //资源最小副本数scaleTargetRef:apiVersion: apps/v1kind: Deployment //需要伸缩的资源类型name: nginxtest //需要伸缩的资源名称targetCPUUtilizationPercentage: 50 //触发伸缩的cpu使用率
status:currentCPUUtilizationPercentage: 48 //当前资源下pod的cpu使用率currentReplicas: 1 //当前的副本数desiredReplicas: 2 //期望的副本数lastScaleTime: 2017-07-03T06:32:19Z

使用生成的HPA重新创建一个HPA
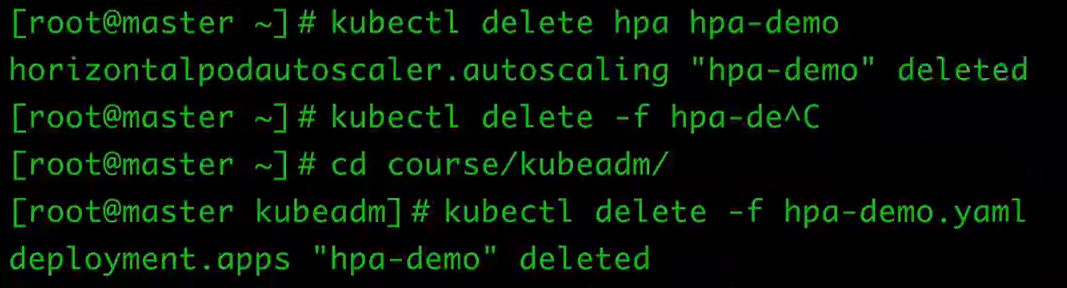
删除hpa
kubectl delete hpa hpa-demo删除deployments
kubectl delete -f hpa-demo.yaml
将生成的yaml追加到hap-deploy-demo.yaml,得到的内容如下:
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:name: hpa-demolabels:app: hpa
spec:revisionHistoryLimit: 15minReadySeconds: 5strategy:type: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 1template:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxresources:requests:cpu: 100mports:- containerPort: 80---
5apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:name: hpa-demonamespace: default
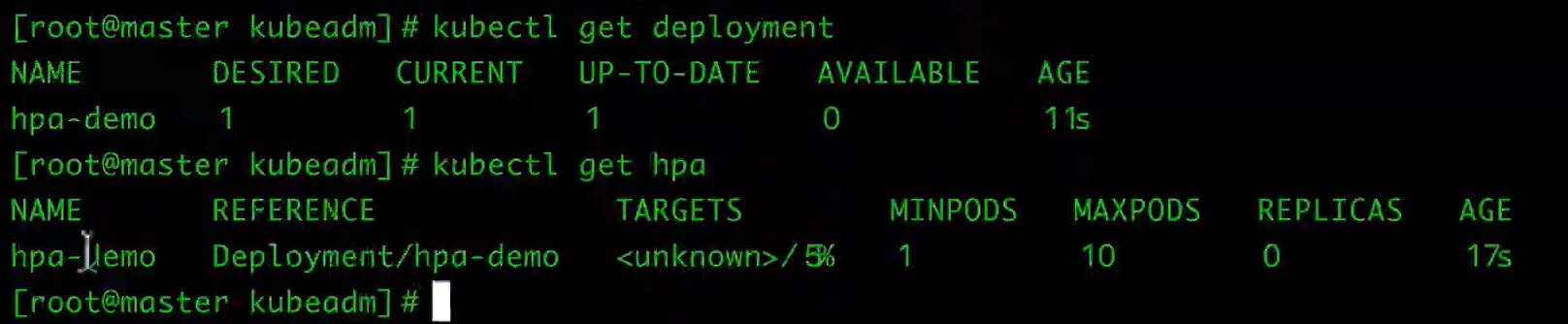
spec:maxReplicas: 10minReplicas: 1scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: hpa-demotargetCPUUtilizationPercentage: 5重新创建
kubectl create -f hpa-demo.yaml

三、Job 和 Cronjob 的使用
Job负责处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。而CronJob则就是在Job上加上了时间调度。
1 Job
我们用Job这个资源对象来创建一个任务,我们定一个Job来执行一个倒计时的任务,定义YAML文件:
apiVersion: batch/v1
kind: Job
metadata:name: job-demo
spec:template:metadata:name: job-demospec:restartPolicy: Nevercontainers:- name: counterimage: busyboxcommand:- "bin/sh"- "-c"- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
注意Job的RestartPolicy仅支持Never和OnFailure两种,不支持Always,我们知道Job就相当于来执行一个批处理任务,执行完就结束了,如果支持Always的话是不是就陷入了死循环了?
然后来创建该Job,保存为job-demo.yaml:
$ kubectl create -f ./job.yaml
job "job-demo" created
然后我们可以查看当前的Job资源对象:
$ kubectl get jobs
$ kubectl describe job job-demo
注意查看我们的Pod的状态,同样我们可以通过kubectl logs来查看当前任务的执行结果。
$ kubectl logs job-demo-p6zst
2 CronJob
期性地在给定时间点运行。这个实际上和我们Linux中的crontab就非常类似了。
一个CronJob对象其实就对应中crontab文件中的一行,它根据配置的时间格式周期性地运行一个Job,格式和crontab也是一样的。
crontab的格式如下:
分 时 日 月 星期 要运行的命令
第1列分钟0~59
第2列小时0~23)
第3列日1~31
第4列月1~12
第5列星期0~7(0和7表示星期天)
第6列要运行的命令
现在,我们用CronJob来管理我们上面的Job任务,
apiVersion: batch/v2alpha1
kind: CronJob
metadata:name: cronjob-demo
spec:schedule: "*/1 * * * *"jobTemplate:spec:template:spec:restartPolicy: OnFailurecontainers:- name: helloimage: busyboxargs:- "bin/sh"- "-c"- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
我们这里的Kind是CronJob了,要注意的是.spec.schedule字段是必须填写的,用来指定任务运行的周期,格式就和crontab一样,另外一个字段是.spec.jobTemplate, 用来指定需要运行的任务,格式当然和Job是一致的。
还有一些值得我们关注的字段.spec.successfulJobsHistoryLimit和.spec.failedJobsHistoryLimit,表示历史限制,是可选的字段。它们指定了可以保留多少完成和失败的Job,默认没有限制,所有成功和失败的Job都会被保留。然而,当运行一个Cron Job时,Job可以很快就堆积很多,所以一般推荐设置这两个字段的值。如果设置限制的值为 0,那么相关类型的Job完成后将不会被保留。
接下来我们来创建这个cronjob
$ kubectl create -f cronjob-demo.yaml
cronjob "cronjob-demo" created
当然,也可以用kubectl run来创建一个CronJob:
kubectl run hello --schedule="*/1 * * * *" --restart=OnFailure --image=busybox -- /bin/sh -c "date; echo Hello from the Kubernetes cluster"
$ kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST-SCHEDULE
hello */1 * * * * False 0 <none>
$ kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
hello-1202039034 1 1 49s
$ pods=$(kubectl get pods --selector=job-name=hello-1202039034 --output=jsonpath={.items..metadata.name} -a)
$ kubectl logs $pods
Mon Aug 29 21:34:09 UTC 2016
Hello from the Kubernetes cluster
一旦不再需要 Cron Job,简单地可以使用 kubectl 命令删除它:
$ kubectl delete cronjob hello
cronjob "hello" deleted
这将会终止正在创建的 Job。
然而,运行中的 Job 将不会被终止,不会删除 Job 或 它们的 Pod。为了清理那些 Job 和 Pod,需要列出该 Cron Job 创建的全部 Job,然后删除它们:
$ kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
hello-1201907962 1 1 11m
hello-1202039034 1 1 8m
...$ kubectl delete jobs hello-1201907962 hello-1202039034 ...
job "hello-1201907962" deleted
job "hello-1202039034" deleted
...
一旦 Job 被删除,由 Job 创建的 Pod 也会被删除。注意,所有由名称为 “hello” 的 Cron Job 创建的 Job 会以前缀字符串 “hello-” 进行命名。如果想要删除当前 Namespace 中的所有 Job,可以通过命令 kubectl delete jobs --all 立刻删除它们。
CronJob的某个job与pod之间的对应关系如下:
$ kubectl get cronjob
$ kubectl get jobs
$ kubectl get pods
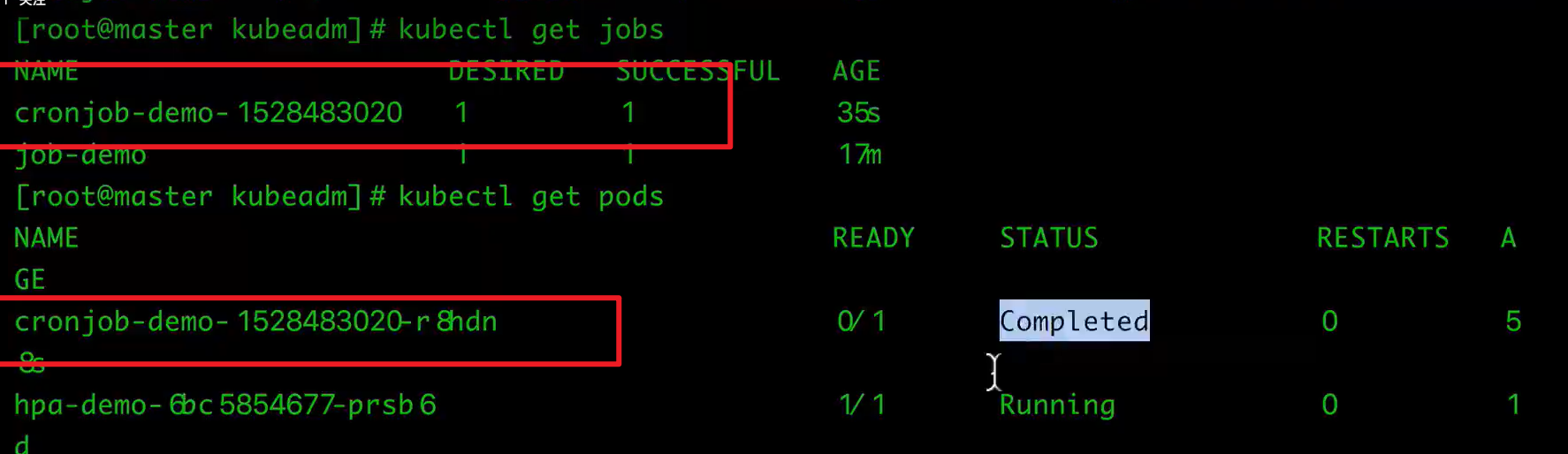
看下job的对应的pod的log,无法直接查看某个cronjob的log
$ kubectl logs cronjob-demo-12XXX
删除CronJob
$ kubectl delte cronjob cronjob-demo
或者
$ kubectl delete -f cronjob-demo.yaml
相关文章:
K8S:常用资源对象操作
文章目录 一、使用Replication Controller(RC)、Replica Set(RS) 管理Pod1 Replication Controller(RC)2 Replication Set(RS) 二、Deployment的使用1 创建2 滚动升级3 回滚Deployment三、 Pod 自动扩缩容HPA1 使用kubectl autosc…...

算法刷题应用知识补充--基础算法、数据结构篇
这里写目录标题 枚举结 排序结 模拟结 二分题结 高精度加、乘题结 减题结 除题结 结 位运算(均是拷贝运算,不会影响原数据,这点要注意)&、|、^位运算特性细节知识补充对于n-1的理解异或来实现数字交换找到只出现一次的数据&am…...

ngnix的反向代理是什么?有什么作用?
1、Nginx的反向代理是什么? Nginx的反向代理是一种网络架构模式,其中Nginx服务器作为前端服务器,接收客户端的请求,然后将这些请求转发给后端服务器(例如Java应用程序服务器)。在这个过程中,客…...

Windows程序设计课程作业-1
文章目录 1. 作业内容2. 设计思路分析与难点3. 代码实现3.1 接口定义3.2 工厂类实现3.3 委托和事件3.4 主函数3.5 代码运行结果 4. 代码地址5. 总结&改进思路6. 阅读参考 1. 作业内容 使用 C# 编码(涉及类、接口、委托等关键知识点),实现…...

2024年河北省网络建设与运维-省赛-nginx 和tomcat 服务服务步骤
题目: 5.nginx 和tomcat 服务 任务描述:利用系统自带tomcat,搭建 Tomcat网站。 (1)配置 linux2 为 nginx 服务器,网站目录为/www/nginx,默认文档 index.html 的内容为“HelloNginx”…...
CentOS下部署ftp服务
要在linux部署ftp服务首先需要安装vsftpd服务 yum install vsftpd -y 安装完成后需要启动vsftpd服务 systemctl start vsftpd 为了能够访问ftp的端口,需要在防火墙中开启ftp的端口21,否则在使用ftp连接的时候会报错No route to host. 执行如下命令为f…...
伦敦银几点开盘?为什么交易不了?
近期是西方的假期,伦敦银市场因而休市。很多朋友看到之前伦敦银上涨那么厉害,正摩拳擦掌准备入场大展拳脚,然而现在却吃了一个大瘪:怎么我刚准备好大展拳脚,结果却没有开盘呢?到底伦敦银几点开盘࿱…...

快手开放平台对接内容管理demo
其中包括用户授权,获取accessToken,获取用户信息,自动上传视频,发布视频,视频列表,删除视频等 <?php namespace app\controller;use app\BaseController; use think\Exception; use think\facade\App;…...

2024年32款数据分析工具分五大类总览
数据分析工具在现代商业和科学中扮演着不可或缺的角色,为组织和个人提供了深入洞察和明智决策的能力。这些工具不仅能够处理大规模的数据集,还能通过强大的分析和可视化功能揭示隐藏在数据背后的模式和趋势。数据分析工具软件主要可以划分为以下五个类别…...
WPS的JS宏如何批量实现文字的超链接
表格中需要对文字进行超链接,每个链接指引到不同的地址。例如: 实现如下表格中,文件名称超级链接到对应的文件路径上,点击对应的文件名称,即可打开对应的文件。 序号文件名称文件路径1变更申请与处理表.xls文档\系统…...

0203逆矩阵-矩阵及其运算-线性代数
文章目录 一、逆矩阵的定义、性质和求法二、逆矩阵的初步应用结语 一、逆矩阵的定义、性质和求法 定义7 对于 n n n阶矩阵A,如果有一个 n n n阶矩阵B,使 A B B A E ABBAE ABBAE 则说矩阵A是可逆的,并把矩阵B称为A的逆矩阵,简称逆…...
加州大学欧文分校英语基础语法专项课程03:Simple Past Tense 学习笔记(完结)
Learn English: Beginning Grammar Specialization Specialization Certificate course 3: Simple Past Tense Course Certificate 本文是学习 https://www.coursera.org/learn/simple-past-tense 这门课的学习笔记,如有侵权,请联系删除。…...
基于Java微信小程序的医院挂号小程序,附源码
博主介绍:✌IT徐师兄、7年大厂程序员经历。全网粉丝15W、csdn博客专家、掘金/华为云//InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇dz…...

7.网络编程-安全
目录 引言 Session Cookie JWT (JSON Web Token) 网络攻击 CSRF DDoS 其他常见网络攻击类型及应对措施 引言 Session、Cookie 和 JWT 都是Web开发中用于实现用户状态管理和身份验证的技术。它们各自有不同的特点和应用场景: Session Session 是一种服务器…...

信息泄露漏洞的JS整改方案
引言 🛡️ 日常工作中,我们经常会面临线上环境被第三方安全厂商扫描出JS信息泄露漏洞的情况,这给我们的系统安全带来了潜在威胁。但幸运的是,对于这类漏洞的整改并不复杂。本文将介绍几种可行的整改方法,以及其中一种…...

WKWebView的使用
一、简介 在iOS中,WKWebView是WebKit框架提供的一个用于展示网页内容的控件,相比UIWebView有更好的性能和功能。 以下是在iOS中使用WKWebView的基本步骤: 1.1 导入WebKit框架 import WebKit1.2 创建WKWebView实例 let webView WKWebVie…...

iOS MT19937随机数生成,结合AES-CBC加密算法实现。
按处理顺序说明: 1. 生成随机数序列字符串函数 生成方法MT19937,初始种子seed,利用C库方法,生成: #include <random> //C 库头文件引入NSString * JKJMT19937Seed(uint32_t seed) {NSLog("MT19937Seed种…...

阿里云2024年优惠券获取方法及使用教程详解
阿里云是阿里巴巴集团旗下的云计算服务提供商,是全球领先的云计算及人工智能科技公司之一。提供免费试用、云服务器、云数据库、云安全、云企业应用等云计算服务,以及大数据、人工智能服务、精准定制基于场景的行业解决方案。 阿里云2024年优惠券的获取方…...

hadoop中hdfs的fsimage文件与edits文件
hadoop中hdfs的fsimage文件与edits文件的作用 首先,我们抛出fsimage和edits文件的功能描述。 Fsimage文件: HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的 所有目录和文件inode的序列化信息。 Edits文件:存放HDFS文件系统的所有更…...

最新版两款不同版SEO超级外链工具PHP源码
可根据个人感觉喜好自行任意选择不同版本使用(版V1或版V2) 请将zip文件全部解压缩即可访问! 源码全部开源,支持上传二级目录访问 已更新增加大量高质量外链(若需要增加修改其他外链请打开txt文件)修复优…...

终极指南:如何在Windows电脑上实现AirPlay 2无线投屏功能
终极指南:如何在Windows电脑上实现AirPlay 2无线投屏功能 【免费下载链接】airplay2-win Airplay2 for windows 项目地址: https://gitcode.com/gh_mirrors/ai/airplay2-win 还在为Windows电脑无法接收iPhone、iPad或Mac的屏幕镜像而烦恼吗?Airpl…...

LaTeX列表排版避坑指南:用enumitem包轻松解决编号重置、缩进和对齐问题
LaTeX列表排版避坑指南:用enumitem包轻松解决编号重置、缩进和对齐问题 在撰写学术论文、技术文档或法律条款时,列表结构是组织内容的重要工具。但LaTeX默认的列表环境往往让用户陷入编号混乱、缩进不一致的泥潭。本文将深入剖析这些痛点的根源ÿ…...

汇顶科技入围GSA奖项:中国芯片设计公司的战略聚焦与成长路径分析
1. 项目概述:一次里程碑式的行业认可最近在半导体圈子里,一个消息引起了不小的波澜:汇顶科技成功入围了全球半导体联盟(GSA)2019年度的两大奖项提名。对于不熟悉这个领域的朋友来说,这或许只是一个普通的公…...

RakkasJS深度解析:基于Bun的全栈React框架性能与迁移实践
1. 项目概述:下一代全栈React框架的探索如果你和我一样,在过去几年里深度使用过Next.js、Remix或者SvelteKit这类全栈框架,那你肯定对它们带来的开发体验又爱又恨。爱的是它们统一了前后端,让全栈开发变得前所未有的顺畅ÿ…...

独立开发者如何利用Taotoken的Token Plan有效控制项目预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken的Token Plan有效控制项目预算 对于独立开发者或小型团队而言,在构建AI应用时,…...

IDM激活脚本终极指南:三步永久免费解锁下载神器
IDM激活脚本终极指南:三步永久免费解锁下载神器 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 还在为IDM试用期到期而烦恼?每次看到&quo…...

Hyper-V DDA图形工具:5分钟完成GPU直通的终极指南
Hyper-V DDA图形工具:5分钟完成GPU直通的终极指南 【免费下载链接】DDA 实现Hyper-V离散设备分配功能的图形界面工具。A GUI Tool For Hyper-Vs Discrete Device Assignment(DDA). 项目地址: https://gitcode.com/gh_mirrors/dd/DDA 还在为复杂的Hyper-V离散…...

制造业数字鸿沟的终结者:零依赖STL到STEP转换引擎的技术突破与应用实践
制造业数字鸿沟的终结者:零依赖STL到STEP转换引擎的技术突破与应用实践 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造与工业4.0的浪潮中,制造业企业面临着…...

SAP KO88结算时,如何用BADI_FINS_ACDOC_POSTING_EVENTS把成本中心塞进自定义字段?
SAP KO88结算实战:通过BADI_FINS_ACDOC_POSTING_EVENTS实现成本中心到自定义字段的精准映射 在SAP工单结算(KO88)的复杂业务场景中,财务凭证的标准化字段往往无法满足企业多维度的分析需求。特别是当需要将特定成本中心信息映射到…...

3步解锁鸣潮120帧:你的终极游戏体验优化指南
3步解锁鸣潮120帧:你的终极游戏体验优化指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 还在为《鸣潮》游戏中的60帧限制而烦恼吗?明明拥有强大的硬件配置,却无法充…...