机器学习(五) -- 监督学习(2) -- k近邻
系列文章目录及链接
目录
前言
一、K近邻通俗理解及定义
二、原理理解及公式
1、距离度量
四、接口实现
1、鸢尾花数据集介绍
2、API
3、流程
3.1、获取数据
3.2、数据预处理
3.3、特征工程
3.4、knn模型训练
3.5、模型评估
3.6、结果预测
4、超参数搜索-网格搜索
5、优缺点
前言
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
一、K近邻通俗理解及定义
1、什么叫k近邻(What)
K-近邻算法(K Nearest Neighbor)又叫KNN算法。指如果一个样本在特征空间中的k个最相似(特征空间中最近邻)的样本中的大多数属于某一个类别,则该样本也属于这个类别。

(如图,我离小羽最近,所以我也属于武侯区)
2、k近邻的目的(Why)
核心思想:根据你的“邻居”的类别来推断出你的类别
(通过找到找到样本中离我们最近的K个样本,类别中样本数最多的类别就是我的类别)
3、怎么做(How)
K-近邻算法流程:
- 计算已知类别数据集中的点(已知类别点)与当前点(待分类点)之间的距离
- 按距离递增次序排序
- 选取与当前点距离最小的k个点
- 统计前k个点所在的类别出现的频率
- 返回前k个点出现频率最高的类别作为当前点的预测分类
这里就有两个问题:K值怎么取?怎么取确定离我最近呢(怎么确定距离)?
一般手动调节K值大小:
k 值取得过小,容易受到异常点的影响
k 值取得过大,样本不均衡的影响
距离计算:
欧氏距离(距离平方值)
曼哈顿距离 (距离绝对值)
切比雪夫距离(维度的最大值)
明可夫斯基距离
二、原理理解及公式
1、距离度量
距离度量用于计算给定问题空间中两个对象之间的差异,即数据集中的特征。然后可以使用该距离来确定特征之间的相似性, 距离越小特征越相似;
1.1、欧氏距离(Euclidean Distance)
空间中两点间的直线距离。(一般使用方法)
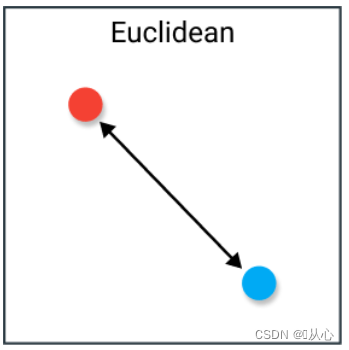
欧式距离也称为l2范数,公式:

1.2、曼哈顿距离(Manhattan Distance)
也称为城市街区距离,因为两个点之间的距离是根据一个点只能以直角移动计算的。这种距离度量通常用于离散和二元属性,这样可以获得真实的路径;

欧式距离也称为l1范数,公式:

1.3、切比雪夫距离(Chebyshev Distance)
切比雪夫距离也称为棋盘距离,二个点之间的距离是其各坐标数值差绝对值的最大值。

欧式距离也称为l-无穷范数,公式:
![]()
1.4、闵氏距离(Minkowski)(闵可夫斯基距离)
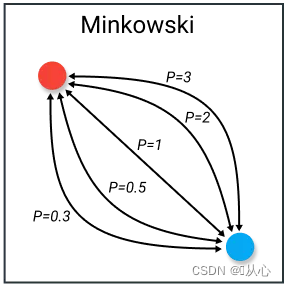

当p = 1 时,即为曼哈顿距离;
当p = 2 时,即为欧氏距离;注:只有欧式距离具有平移不变性;
当p = ∞时,即为切比雪夫距离;
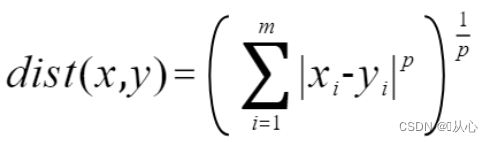
三、**算法实现
四、接口实现
1、鸢尾花数据集介绍
1.1、API
# API
from sklearn.datasets import load_iris1.2、介绍
鸢尾花数据集共收集了三类鸢尾花,即Setosa鸢尾花、Versicolour鸢尾花和Virginica鸢尾花,每一类鸢尾花收集了50条样本记录,共计150条。

数据集包括4个属性,分别为花萼的长、花萼的宽、花瓣的长和花瓣的宽。单位是cm。
iris = load_iris()print("鸢尾花数据集的键",iris.keys())
# "数据--特征值","目标值","","目标名","描述","特征名","文件名","数据模型名"print(iris.data.shape)print("鸢尾花数据集特征值名字是:",iris.feature_names)
# sepal length 花萼长度、sepal width 花萼宽度、petal length 花瓣长度、petal width 花瓣宽度(单位是cm)print("鸢尾花数据集目标值名字是:",iris.target_names)
# Setosa(山鸢尾)、Versicolour(杂色鸢尾)、Virginica(维吉尼亚鸢尾) 其他属性:
其他属性:
print("鸢尾花数据集的返回值:\n", iris)
# 返回值类型是bunch--是一个字典类型# 既可以使用[]输出也可以使用.输出
print("鸢尾花数据集特征值是:",iris["data"])
# print("数据集特征值是:",iris.data)
print("鸢尾花数据集目标值是:",iris.target)print("鸢尾花数据集的描述是:",iris.DESCR)1.3、查看数据分布(两个特征)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
np.random.seed(1734)#将生成的交互式图嵌入notebook中
%matplotlib notebook #将生成的静态图嵌入notebook中
%matplotlib inlineplt.rcParams['font.sans-serif'] = 'SimHei' # 设置字体为SimHei # 显示中文
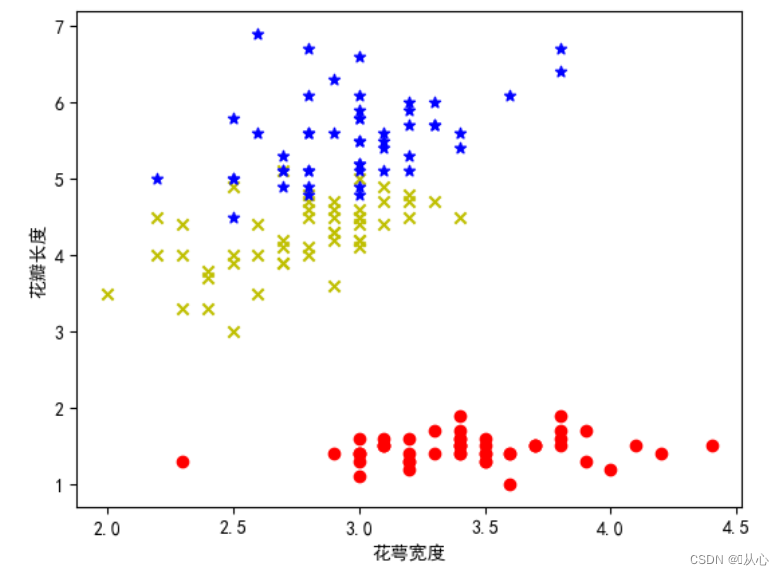
plt.rcParams['axes.unicode_minus']=False # 修复负号问题from sklearn.datasets import load_irisiris = load_iris()# 取150个样本,取中间两列特征,花萼宽度和花瓣长度
x=iris.data[0:150,1:3]
y=iris.target[0:150]#分别取前两类样本,0和1
samples_0 = x[y==0, :]#把y=0,即Iris-setosa的样本取出来
samples_1 = x[y==1, :]#把y=1,即Iris-versicolo的样本取出来
samples_2 = x[y==2, :]#把y=2,即Iris-virginica的样本取出来# 可视化
plt.figure()
plt.scatter(samples_0[:,0],samples_0[:,1],marker='o',color='r')
plt.scatter(samples_1[:,0],samples_1[:,1],marker='x',color='y')
plt.scatter(samples_2[:,0],samples_2[:,1],marker='*',color='b')
plt.xlabel('花萼宽度')
plt.ylabel('花瓣长度')
plt.show()
2、API
sklearn.neighbors.KNbeighborsClassifer导入:
from sklearn.neighbors import KNeighborsClassifier语法:
KNbeighborsClassifer(n_neighbors=5,algorithm='auto')n_neighbors: 默认为5,就是K近邻中的K值 Algorithm:{'auto','ball_tree','kd_tree','brute'}auto:可以理解为算法自己决定合适的搜索算法ball_tree:克服kd树高维失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。kd_tree:构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。brute:线性扫描,当训练集很大时,计算非常耗时3、流程
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifier3.1、获取数据
# 载入数据
iris = load_iris()
# print(iris)3.2、数据预处理
# 划分数据集
x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=1473) 
3.3、特征工程
进行KNN时,一般要进行无量纲化。
3.4、knn模型训练
# 实例化一个预估器
knn = KNeighborsClassifier(n_neighbors=3)# 模型训练
knn.fit(x_train, y_train) 
3.5、模型评估
# 模型评估# 用模型计算测试值,得到预测值
y_pred = knn.predict(x_test)# 准确率
print("预测的准确率",knn.score(x_test,y_test))# 一样的哦
from sklearn.metrics import accuracy_score
print("预测的准确率",accuracy_score(y_test,y_pred))一般用准确率就行,

# 将预测值与真实值比较
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))用分类报告【详情请看机器学习(四) -- 模型评估(2)-分类报告】
精确率(precision)、召回率(recall)、F1 值(F1-score)和样本数目(support)

3.6、结果预测
经过模型评估后通过的模型可以代入真实值进行预测。
4、超参数搜索-网格搜索
网格搜索法(Grid Search)是一种在机器学习中用于确定最佳模型超参数的方法之一。
超参数是指在训练模型之前需要手动设置的参数。
4.1、API:
sklearn.model_selection.GridSearchCV导入:
from sklearn.model_selection import GridSearchCV语法:
gs=GridSearchCV(estimator,param_grid,…,cv=’3’)estimator:要优化的模型对象。param_grid:指定参数的候选值范围,可以是一个字典或列表。cv:交叉验证参数,默认None,使用三折交叉验证。gs.fit():运行网格搜索gs.best_estimator_:返回在交叉验证中选择的最佳估计器。
gs.best_params_:返回在交叉验证中选择的最佳参数组合。
gs.best_score_:返回在交叉验证中选择的最佳评分。
gs.cv_results_:返回一个字典,具体用法模型不同参数下交叉验证的结果。
gs.scorer_:返回用于评分的评估器。
gs.n_splits_:返回交叉验证折叠数。
4.2、实践:
![]()
# 构造参数列表
param = {"n_neighbors": [3, 5, 10, 12, 15]}# 进行网格搜索,cv=3是3折交叉验证
gs = GridSearchCV(knn, param_grid=param, cv=3)gs.fit(x_train, y_train) #你给它的x_train,它又分为训练集,验证集# 预测准确率,为了给大家看看
print("在测试集上准确率:", gs.score(x_test, y_test))print("在交叉验证当中最好的结果:", gs.best_score_)print("选择最好的模型是:", gs.best_estimator_)print("最好的参数是 ", gs.best_params_)# print("每个超参数每次交叉验证的结果:", gs.cv_results_)
有关交叉验证移步【机器学习(四) -- 模型评估(1)】
5、优缺点
5.1、优点:
- 简单,易于理解,易于实现
- 分类回归都可以用
5.2、缺点:
- 必须指定K值,K值选择不当则分类精度不能保证
-
需要算每个测试点与训练集的距离,当训练集较大时,计算量相当大,时间复杂度高,特别是特征数量比较大的时候。需要大量的内存,空间复杂度高。
-
懒惰算法,对测试样本分类时的计算量大,内存开销大
相关文章:
机器学习(五) -- 监督学习(2) -- k近邻
系列文章目录及链接 目录 前言 一、K近邻通俗理解及定义 二、原理理解及公式 1、距离度量 四、接口实现 1、鸢尾花数据集介绍 2、API 3、流程 3.1、获取数据 3.2、数据预处理 3.3、特征工程 3.4、knn模型训练 3.5、模型评估 3.6、结果预测 4、超参数搜索-网格搜…...

【.NET全栈】ZedGraph图表库的介绍和应用
文章目录 一、ZedGraph介绍ZedGraph的特点ZedGraph的缺点使用注意事项 二、ZedGraph官网三、ZedGraph的应用四、ZedGraph的高端应用五、、总结 一、ZedGraph介绍 ZedGraph 是一个用于绘制图表和图形的开源.NET图表库。它提供了丰富的功能和灵活性,可以用于创建各种…...

vivado 设计调试
设计调试 对 FPGA 或 ACAP 设计进行调试是一个多步骤迭代式流程。与大多数复杂问题的处理方式一样 , 最好先将 FPGA 或 ACAP 设计调试流程细分为多个小部分 , 以便集中精力使设计中的每一小部分能逐一正常运行 , 而不是尝试一次性让整 个…...

Python3 replace()函数使用详解:字符串的艺术转换
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …...

【C++】用红黑树封装map和set
我们之前学的map和set在stl源码中都是用红黑树封装实现的,当然,我们也可以模拟来实现一下。在实现之前,我们也可以看一下stl源码是如何实现的。我们上篇博客写的红黑树里面只是一个pair对象,这对于set来说显然是不合适的ÿ…...

一些好玩的东西
这里写目录标题 递归1.递归打印数组和链表?代码实现原理讲解二叉树的 前 中 后 序位置 参考文章 递归 1.递归打印数组和链表? 平常我们打印数组和链表都是 迭代 就好了今天学到一个新思路–>不仅可以轻松正着打印数组和链表 , 还能轻松倒着打印(用的是二叉树的前中后序遍…...

微电网优化:基于巨型犰狳优化算法(Giant Armadillo Optimization,GAO)的微电网优化(提供MATLAB代码)
一、微电网优化模型 微电网是一个相对独立的本地化电力单元,用户现场的分布式发电可以支持用电需求。为此,您的微电网将接入、监控、预测和控制您本地的分布式能源系统,同时强化供电系统的弹性,保障您的用电更经济。您可以在连接…...

java锁
乐观锁 乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,采取在写时先读出…...

QA测试开发工程师面试题满分问答6: 如何判断接口功能正常?从QA的角度设计测试用例
判断接口功能是否正常的方法之一是设计并执行相关的测试用例。下面是从测试QA的角度设计接口测试用例的一些建议,包括功能、边界、异常、链路、上下游和并发等方面: 通过综合考虑这些测试维度,并设计相应的测试用例,可以更全面地评估接口的功能、性能、安全性、数据一致…...

vue 双向绑定
双向绑定:双方其中一方改变,另外一方也会跟着改变。 data() { return {inputValue: ,list: [],message: hello,checked: true,radio: ,select: [],options: [{text: A, value:{value: A}},{text: B, value:{value: B}},{text: C, value:{value: C}}], }…...

python--异常处理
异常处理 例一: try: #可能出现异常代码 except: #如果程序异常,则立刻进入这儿 [finally: #不管是否捕获异常,finally语法快必须要执行!!! #资源关闭,等各种非常重要的操作&…...
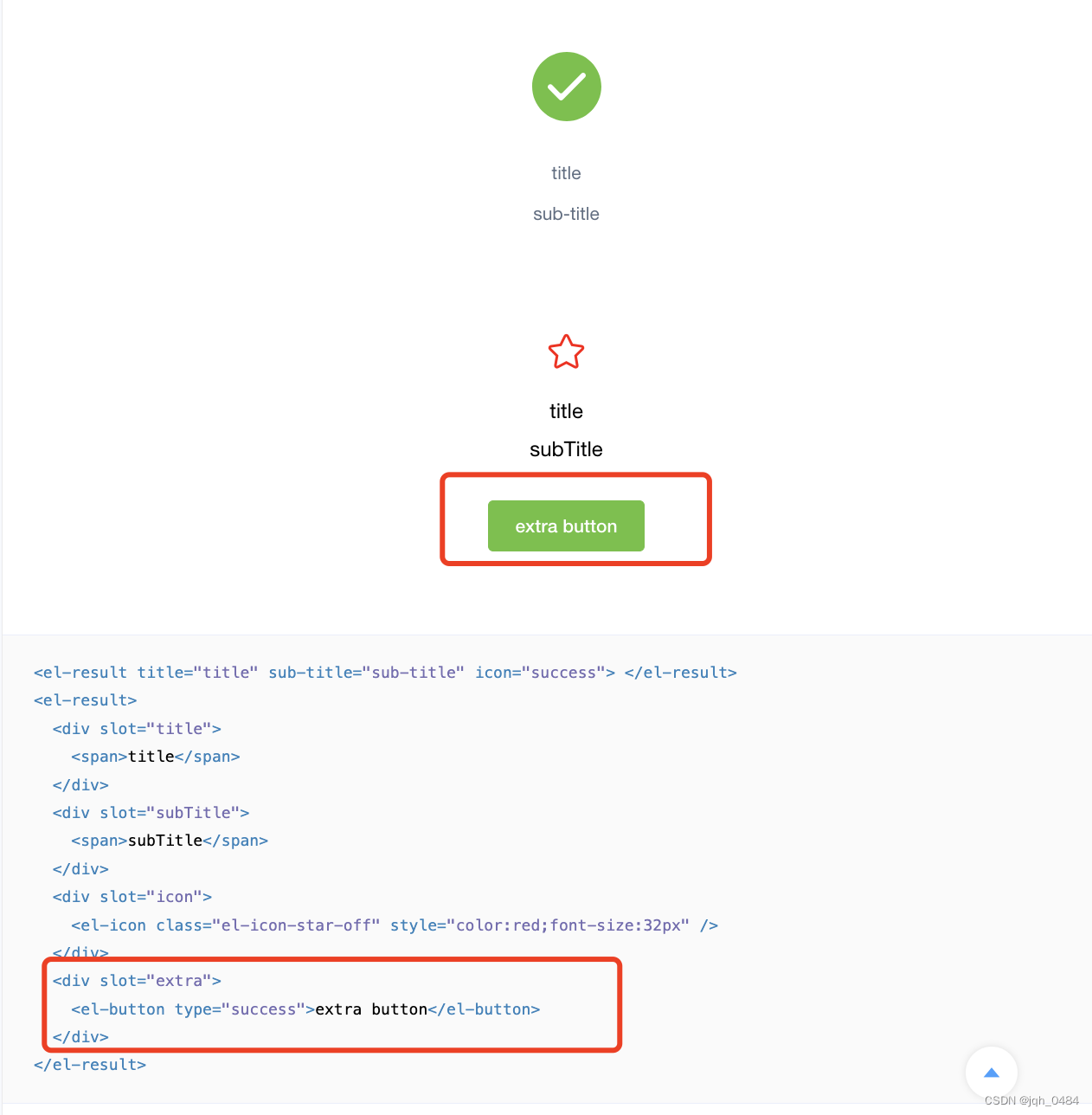
element-ui result 组件源码分享
今日简单分享 result 组件的源码实现,主要从以下三个方面: 1、result 组件页面结构 2、result 组件属性 3、result 组件 slot 一、result 组件页面结构 二、result 组件属性 2.1 title 属性,标题,类型 string,无默…...

VRRP虚拟路由实验(思科)
一,技术简介 VRRP(Virtual Router Redundancy Protocol)是一种网络协议,用于实现路由器冗余,提高网络可靠性和容错能力。VRRP允许多台路由器共享一个虚拟IP地址,其中一台路由器被选为Master,负…...
SpringBoot通用模块--文件上传开发(阿里云OSS)
文件上传,是指将本地图片、视频、音频等文件上传到服务器上,可以供其他用户浏览或下载的过程。文件上传在项目中应用非常广泛,我们经常发抖音、发朋友圈都用到了文件上传功能。 实现文件上传服务,需要有存储的支持,那…...

Fecify 商品标签功能
关于商品标签 商品标签是指商家可以在展示商品时,自己创建一个自定义标签,可自定义某个关键词或短语。这样顾客在浏览商城时,只需要通过标签就能看到更直观的展示信息。 商品标签可以按照用户的属性、行为、偏好等进行分类,标签要…...
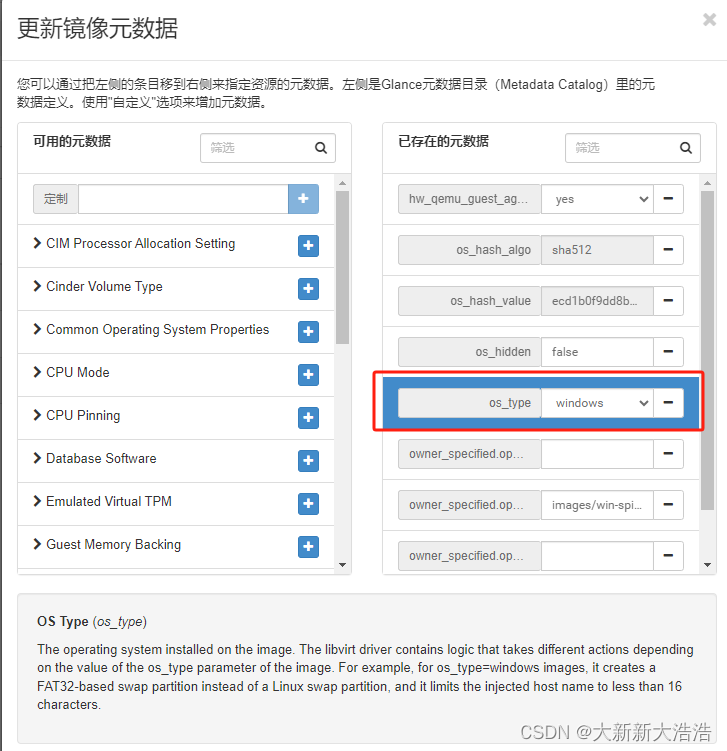
openstack中windows虚拟机时间显示异常问题处理
文章目录 一、问题描述二、元数据信息总结 一、问题描述 openstack创建出windows虚拟机的时候,发现时间和当前时间相差8小时,用起来很难受。 参考:https://www.cnblogs.com/hraa0101/p/11365238.html 二、元数据信息 通过设置镜像的元数据…...

很牛的一套仓库管理系统,免费复用【带源码】
今天给大家分享一套基于SpringbootVue的仓库管理系统源码,在实际项目中可以直接复用。(免费提供,文末自取) 一、系统运行图(设计报告和接口文档) 1、登陆页面 2、物品信息管理 3、设计报告包含接口文档 二、系统搭建视频教程 …...

Spark 部署与应用程序交互简单使用说明
文章目录 前言步骤一:下载安装包Spark的目录和文件 步骤二:使用Scala或PySpark Shell本地 shell 运行 步骤3:理解Spark应用中的概念Spark Application and SparkSessionSpark JobsSpark StagesSpark Tasks 转换、立即执行操作和延迟求值窄变换和宽变换 S…...

【二分查找】Leetcode 点名
题目解析 LCR 173. 点名 算法讲解 1. 哈希表 class Solution { public:int takeAttendance(vector<int>& nums) {map<int, int> Hash;for(auto n : nums) Hash[n];for(int i 0; i < nums[nums.size() - 1]; i){if(Hash[i] 0)return i;}return nums.si…...

JS中的运算符
1.&& 逻辑与 &&会从左到右执行表达式,直到某个表达式的运行结果返回false,如果全部为true,则返回最后一个中表达式的执行结果 console.log(1 && 2) // 2 console.log(1&&10&&15) // 15 console.log(1&&0&&am…...

Solidworks PDM二次开发实战:文件夹权限与数据卡配置详解
1. Solidworks PDM二次开发入门指南 如果你正在使用Solidworks PDM管理产品数据,可能会遇到需要批量创建文件夹并设置权限的场景。比如新项目启动时,需要为不同部门创建标准化的文件夹结构,同时设置工程师只读、管理员完全控制的权限规则。手…...

Linuxbonding链路异常定位实战
Linuxbonding链路异常定位实战这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...

Python自动化Excel数据抓取:OpenClaw技能实战指南
1. 项目概述:从Excel表格到智能数据抓取如果你每天的工作都离不开Excel,并且经常需要从各种网页、文档甚至PDF里手动复制粘贴数据,然后费劲地整理到表格里,那你一定对“Excel大师”这个称号既向往又头疼。我们总希望Excel能更“聪…...

AI驱动代码审查:Cursor与Git工作流融合实践
1. 项目概述:当AI代码助手遇上代码审查最近在GitHub上看到一个挺有意思的项目,叫guinacio/cursor-review。光看名字,你可能会觉得这又是一个普通的代码审查工具,但点进去仔细研究,你会发现它的核心思路非常巧妙&#x…...

Path of Building:3个步骤从Build小白到规划大师的完整指南
Path of Building:3个步骤从Build小白到规划大师的完整指南 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding Path of Building作为流放之路玩家最信赖的Build规…...

TPU柔性材料3D打印GoPro车载支架:从减震原理到实战拍摄全指南
1. 项目概述与设计思路我一直对第一人称视角(FPV)拍摄很着迷,尤其是那种能贴着地面、模拟小车视角疾驰的画面,动态感和沉浸感是手持拍摄无法比拟的。市面上的运动相机车载支架要么是硬连接,颠簸起来画面抖动得厉害&…...

开源技能图谱工具SkillPort:Go语言构建的知识管理利器
1. 项目概述:一个技能图谱与知识管理的开源利器 最近在整理个人技术栈和团队知识库时,我一直在寻找一个能直观展示技能关联、又能深度管理学习路径的工具。市面上的笔记软件要么太“平”,只能线性记录;要么太“重”,像…...

避坑指南:在Unity 2022 LTS中配置XCharts插件时遇到的3个常见问题及解决方法
Unity 2022 LTS中XCharts插件实战避坑手册 当数据可视化成为现代应用的核心需求时,Unity开发者常会选择XCharts这类开源图表插件来快速实现专业级图表展示。但在实际项目落地过程中,版本兼容性、环境配置和平台适配等问题往往会让开发进程意外卡壳。本文…...

Unity区域加载系统:实现开放世界无缝加载与内存优化
1. 项目概述:一个高效、可扩展的Unity区域加载系统 最近在做一个开放世界风格的项目,场景大了之后,加载卡顿和内存管理就成了老大难问题。传统的Unity场景加载,要么一股脑全塞进内存,要么就得自己写一堆脚本来手动控制…...
如何构建鲁棒的点云局部描述符)
从理论到实践:三维形状上下文(3DSC)如何构建鲁棒的点云局部描述符
1. 为什么我们需要三维形状上下文(3DSC) 想象一下你正在玩一个拼图游戏,但所有碎片都被随机撒上了胡椒粉,有些碎片还被书本盖住了一角。这就是计算机处理含噪声、遮挡的点云数据时的真实处境。在机器人导航、自动驾驶或者工业质检中,我们经常…...